
热门标签
热门文章
- 1开源软件:引领技术创新、商业模式与安全的融合_开源软件在各行业的应用案例1.互联网行业:
- 2VsCode配置c/c++环境_vscode配置c++环境
- 3创建react项目_新建react嘤嘤
- 4postgresql数据库允许某些网段内远程访问_pg数据库设置访问连接网段区间
- 5Open AI宫斗始末:董事会开除CEO再复职,这场闹剧终于结束了!_奥尔特曼最近被开除后旋又复职
- 6托管c++与c#的转化四--数组与类_托管c++ 数组
- 7【SparkSQL】DSL风格的API函数和SQL函数_sparksql dsl
- 8PyInstaller库—Python第三方库—程序打包_pyinstaller打包第三方库文件
- 9浏览器前进与后退的秘密——栈 (栈的理解与实现)
- 10es根据条件删除数据_es 按条件delete数据
当前位置: article > 正文
使用pytorch搭建卷积神经网络
作者:繁依Fanyi0 | 2024-06-06 09:34:19
赞
踩
pytorch搭建卷积神经网络
基于吴恩达老师的深度学习作业,老师所用的是tensorflow,而且版本较老,因为近期接触的是pytorch,打算自己通过pytorch来搭建。
Dataset:
class CNNTrainDataSet(Dataset): def __init__(self, data_file, transform=None, target_transform=None): self.transform = transform self.target_transform = target_transform data = h5py.File(data_file, 'r') # 这里的内容以实际情况为准 self.train_set_x_orig = data['train_set_x'] self.train_set_y_orig = data['train_set_y'] def __len__(self): return len(self.train_set_y_orig) def __getitem__(self, idx): x = self.train_set_x_orig[idx] y = self.train_set_y_orig[idx] if self.transform: x = self.transform(x) if self.target_transform: y = self.target_transform(y) return x, y # 测试数据集 class CNNTestDataSet(Dataset): def __init__(self, data_file, transform=None, target_transform=None): self.transform = transform self.target_transform = target_transform data = h5py.File(data_file, 'r') self.test_set_x_orig = data['test_set_x'] self.test_set_y_orig = data['test_set_y'] def __len__(self): return len(self.test_set_y_orig) def __getitem__(self, idx): x = self.test_set_x_orig[idx] y = self.test_set_y_orig[idx] if self.transform: x = self.transform(x) if self.target_transform: y = self.target_transform(y) return x, y

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
# 主函数main.py
# Loading the data
train_data = CNNTrainDataSet(
data_file='datasets/train_signs.h5',
transform=Lambda(lambda x: torch.tensor(x / 255).permute(2, 0, 1).float()), # HWC转CHW
target_transform=Lambda(lambda x: torch.tensor(x))
)
test_data = CNNTestDataSet(
data_file='datasets/test_signs.h5',
transform=Lambda(lambda x: torch.tensor(x / 255).permute(2, 0, 1).float()),
target_transform=Lambda(lambda x: torch.tensor(x))
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
获取到数据集后加载到dataloader打乱
# shuffle the data
train_loader = DataLoader(train_data, batch_size=90, shuffle=True)
test_loader = DataLoader(test_data, batch_size=10, shuffle=True)
- 1
- 2
- 3
图片示例:
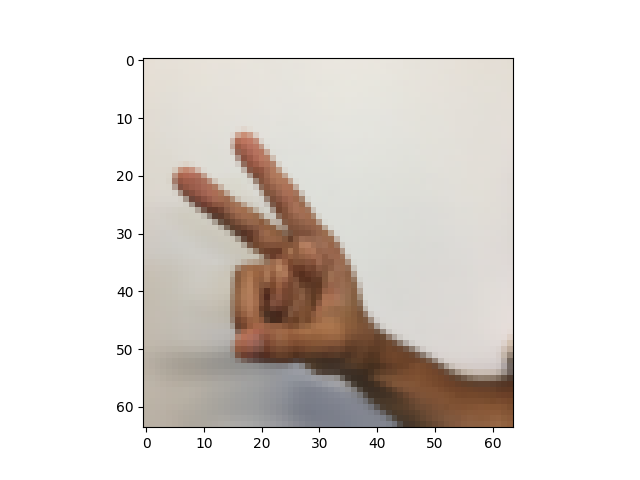
index = 6
plt.imshow(train_data.train_set_x_orig[index])
print('y = ' + str(train_data.train_set_y_orig[index]))
plt.show()
- 1
- 2
- 3
- 4
y = 2
- 1
检查数据大小:
print('number of training examples = ' + str(train_data.__len__()))
print('number of test examples = ' + str(test_data.__len__()))
print('X_train shape = ' + str(train_data.train_set_x_orig.shape))
print('Y_train shape = ' + str(train_data.train_set_y_orig.shape))
print('X_test shape = ' + str(test_data.test_set_x_orig.shape))
print('Y_test shape = ' + str(test_data.test_set_y_orig.shape))
- 1
- 2
- 3
- 4
- 5
- 6
number of training examples = 1080
number of test examples = 120
X_train shape = (1080, 64, 64, 3)
Y_train shape = (1080,)
X_test shape = (120, 64, 64, 3)
Y_test shape = (120,)
- 1
- 2
- 3
- 4
- 5
- 6
搭建卷积神经网络:
class ConvolutionNeuralNetwork(nn.Module): def __init__(self): super(ConvolutionNeuralNetwork, self).__init__() self.conv1 = nn.Sequential( nn.Conv2d(3, 8, kernel_size=(4, 4), stride=(1, 1)), nn.ReLU(), nn.MaxPool2d(kernel_size=(8, 8), stride=8), ) self.conv2 = nn.Sequential( nn.Conv2d(8, 16, kernel_size=(2, 2), stride=(1, 1)), nn.ReLU(), nn.MaxPool2d(kernel_size=(4, 4), stride=4), ) self.fc = nn.Sequential( nn.Flatten(), nn.Linear(16, 6) ) def forward(self, x): x = self.conv1(x) x = self.conv2(x) x = self.fc(x) return x
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
将模型载入到硬件设备:
# define hardware
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# load device
model = ConvolutionNeuralNetwork().to(device)
- 1
- 2
- 3
- 4
- 5
定义参数:
# parameter
epoch = 100
learning_rate = 0.009
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), learning_rate)
- 1
- 2
- 3
- 4
- 5
训练函数:
def train_loop(loader, model, loss_fn, optimizer, epoch, train):
for epoch in range(epoch):
for batch, (x, y) in enumerate(loader):
batch_x = Variable(x)
batch_y = Variable(y)
res = model(batch_x)
loss = loss_fn(res, batch_y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if batch % 12 == 0:
print(loss)
torch.save(model, 'model.pth') # 保存模型
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
训练:
train_loop(train_loader, model, loss_fn, optimizer, epoch, train_data)
- 1
测试函数:
def test_loop(loader, model, loss_fn):
# 这里的训练都是抽出一部分,没有进行全体的测试
size = len(loader.dataset)
num_batches = len(loader)
test_loss, accuracy = 0, 0
with torch.no_grad():
for Batch, (x, y) in enumerate(loader):
pred = model(x)
test_loss += loss_fn(pred, y).item()
accuracy += (pred.argmax(1) == y).type(torch.float).sum().item()
test_loss /= num_batches
accuracy /= size
print(f"Test Error: \n Accuracy: {(100 * accuracy):>0.1f}%, Avg loss: {test_loss:>8f} \n")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
测试:
model = torch.load('model.pth')
test_loop(train_loader, model, loss_fn) # 训练集准确率
test_loop(test_loader, model, loss_fn) # 测试集准确率
- 1
- 2
- 3
因为mini_batch下降的特点,每次的训练结果都不太一样,这里我得到了以下的结果:
Test Error:
Accuracy: 81.9%, Avg loss: 0.512246
Test Error:
Accuracy: 77.5%, Avg loss: 0.595191
- 1
- 2
- 3
- 4
看着还行。附上引入的库:
import h5py
import torch
from cnn_myutils import * # 自定义的工具类
from torchvision.transforms import ToTensor, Lambda
from torch.utils.data import DataLoader
import matplotlib.pyplot as plt
from torch import nn
import numpy as np
import torchvision.models as models
from torch.utils.data import Dataset
from torch.autograd import Variable
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/繁依Fanyi0/article/detail/680443
推荐阅读
相关标签

