
- 1云服务器SpringBoot 2.x + netty-socketIO 报错 java.net.BindException: Cannot assign requested address: bind_nettyserver exception is java net bingexception
- 2Spark常用算子详解汇总 : 实战案例、Java版本、Scala版本_spark算子综合案例 - java篇
- 3Android 系统日志(Log) JNI实现流程源码分析_android系统log
- 4【UI自动化测试】Selenium 自动化遇见 shadow-root 元素定位处理方法_自动化测试 定位 shadow
- 5OpenCV裁剪图像任意区域_opencv如何裁剪指定区域
- 6音频资料_ac3文件头格式分析
- 7【网络安全的神秘世界】JavaScript
- 8Jenkins设置svn授权
- 9关于Curator学习过程问题_maxretries too large (30). pinning to 29
- 10GitHub Copilot插件_github copilot paypal怎么填
redis集群客户端_干货:一文详解Redis集群原理核心内容(建议收藏)
赞
踩

推荐阅读:互联网公司面试必问的Redis相关高频题库文档
集群原理
一个系统建立集群主要需要解决两个问题:数据同步问题和集群容错问题。
Naive方案
一个简单粗暴的方案是部署多台一模一样的Redis服务,再用负载均衡来分摊压力以及监控服务状态。这种方案的优势在于容错简单,只要有一台存活,整个集群就仍然可用。但是它的问题在于保证这些Redis服务的数据一致时,会导致大量数据同步操作,反而影响性能和稳定性。
Redis集群方案
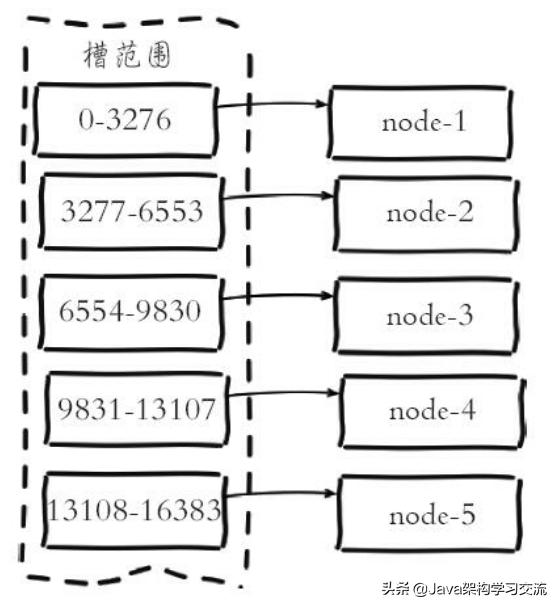
Redis集群方案基于分而治之的思想。Redis中数据都是以Key-Value形式存储的,而不同Key的数据之间是相互独立的。因此可以将Key按照某种规则划分成多个分区,将不同分区的数据存放在不同的节点上。这个方案类似数据结构中哈希表的结构。在Redis集群的实现中,使用哈希算法(公式是CRC16(Key) mod 16383)将Key映射到0~16383范围的整数。这样每个整数对应存储了若干个Key-Value数据,这样一个整数对应的抽象存储称为一个槽(slot)。每个Redis Cluster的节点——准确讲是master节点——负责一定范围的槽,所有节点组成的集群覆盖了0~16383整个范围的槽。
据说任何计算机问题都可以通过增加一个中间层来解决。槽的概念也是这么一层。它介于数据和节点之间,简化了扩容和收缩操作的难度。数据和槽的映射关系由固定算法完成,不需要维护,节点只需维护自身和槽的映射关系。
Slave
上面的方案只是解决了性能扩展的问题,集群的故障容错能力并没有提升。提高容错能力的方法一般为使用某种备份/冗余手段。负责一定数量的槽的节点被称为master节点。为了增加集群稳定性,每个master节点可以配置若干个备份节点——称为slave节点。Slave节点一般作为冷备份保存master节点的数据,在master节点宕机时替换master节点。在一些数据访问压力比较大的情况下,slave节点也可以提供读取数据的功能,不过slave节点的数据实时性会略差一下。而写数据的操作则只能通过master节点进行。
请求重定向
当Redis节点接收到对某个key的命令时,如果这个key对应的槽不在自己的负责范围内,则返回MOVED重定向错误,通知客户端到正确的节点去访问数据。
如果频繁出现重定向错误,势必会影响访问的性能。由于从key映射到槽的算法是固定公开的,客户端可以在内部维护槽到节点的映射关系,访问数据时可以自己通过key计算出槽,然后找到正确的节点,减少重定向错误。目前大部分开发语言的Redis客户端都会实现这个策略。这个地址https://redis.io/clients可以查看主流语言的Redis客户端。
节点通信
尽管不同节点存储的数据相互独立,这些节点仍然需要相互通信以同步节点状态信息。Redis集群采用P2P的Gossip协议,节点之间不断地通信交换信息,最终所有节点的状态都会达成一致。常用的Gossip消息有下面几种:
- ping消息:每个节点不断地向其他节点发起ping消息,用于检测节点是否在线和交换节点状态信息。
- pong消息:收到ping、meet消息时的响应消息。
- meet消息:新节点加入消息。
- fail消息:节点下线消息。
- forget消息:忘记节点消息,使一个节点下线。这个命令必须在60秒内在所有节点执行,否则超过60秒后该节点重新参与消息交换。实践中不建议直接使用forget命令来操作节点下线。
节点下线
当某个节点出现问题时,需要一定的传播时间让多数master节点认为该节点确实不可用,才能标记标记该节点真正下线。Redis集群的节点下线包括两个环节:主观下线(pfail)和客观下线(fail)。
- 主观下线:当节点A在cluster-node-timeout时间内和节点B通信(ping-pong消息)一直失败,则节点A认为节点B不可用,标记为主观下线,并将状态消息传播给其他节点。
- 客观下线:当一个节点被集群内多数master节点标记为主观下线后,则触发客观下线流程,标记该节点真正下线。
故障恢复
一个持有槽的master节点客观下线后,集群会从slave节点中选出一个提升为master节点来替换它。Redis集群使用选举-投票的算法来挑选slave节点。一个slave节点必须获得包括故障的master节点在内的多数master节点的投票后才能被提升为master节点。假设集群规模为3主3从,则必须至少有2个主节点存活才能执行故障恢复。如果部署时将2个主节点部署到同一台服务器上,则该服务器不幸宕机后集群无法执行故障恢复。
默认情况下,Redis集群如果有master节点不可用,即有一些槽没有负责的节点,则整个集群不可用。也就是说当一个master节点故障,到故障恢复的这段时间,整个集群都处于不可用的状态。这对于一些业务来说是不可忍受的。可以在配置中将cluster-require-full-coverage配置为no,那么master节点故障时只会影响访问它负责的相关槽的数据,不影响对其他节点的访问。
搭建集群
启动新节点
修改Redis配置文件以启动集群模式:
# 开启集群模式cluster-enabled yes# 节点超时时间,单位毫秒cluster-node-timeout 15000# 集群节点信息文件cluster-config-file "nodes-6379.conf"然后启动新节点。
发送meet消息将节点组成集群
使用客户端发起命令cluster ,节点会发送meet消息将指定IP和端口的新节点加入集群。

分配槽
上一步执行完后我们得到的是一个还没有负责任何槽的“空”集群。为了使集群可用,我们需要将16384个槽都分配到master节点数。
在客户端执行cluster add addslots {...}命令,将~范围的槽都分配给当前客户端所连接的节点。将所有的槽都分配给master节点后,执行cluster nodes命令,查看各个节点负责的槽,以及节点的ID。
接下来还需要分配slave节点。使用客户端连接待分配的slave节点,执行cluster replicate 命令,将该节点分配为指定的master节点的备份。
使用命令直接创建集群
在Redis 5版本中redis-cli客户端新增了集群操作命令。
如下所示,直接使用命令创建一个3主3从的集群:
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1如果你用的是旧版本的Redis,可以使用官方提供的redis-trib.rb脚本来创建集群:
./redis-trib.rb create --replicas 1 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005集群伸缩
扩容
扩容操作与创建集群操作类似,不同的在于最后一步是将槽从已有的节点迁移到新节点。
- 启动新节点:同创建集群。
- 将新节点加入到集群:使用redis-cli --cluster add-node命令将新节点加入集群(内部使用meet消息实现)。
- 迁移槽和数据:添加新节点后,需要将一些槽和数据从旧节点迁移到新节点。使用命令redis-cli --cluster reshard进行槽迁移操作。
收缩
为了安全删除节点,Redis集群只能下线没有负责槽的节点。因此如果要下线有负责槽的master节点,则需要先将它负责的槽迁移到其他节点。
- 迁移槽。使用命令redis-cli --cluster reshard将待删除节点的槽都迁移到其他节点。
- 忘记节点。使用命令redis-cli --cluster del-node删除节点(内部使用forget消息实现)。
集群配置工具
如果你的redis-cli版本低于5,那么可以使用redis-trib.rb脚本来完成上面的命令。点击这里查看redis-cli和redis-trib.rb操作集群的命令。
持久化
Redis有RDB和AOF两种持久化策略。
一个RDB持久化的坑
RDB持久化神坑:
- 即使设置了save ""试图关闭RDB,然而RDB持久化仍然有可能会触发。
- 从节点全量复制(比如新增从节点时),主节点触发RDB持久化产生RDB文件。然后发送RDB文件给从节点。最后该从节点和对应的主节点都会有RDB文件。
- 执行shutdown时,如果没有开启AOF,也会触发RDB持久化。
- 不管save如何设置,只要RDB文件存在,redis启动时就会去加载该文件。
后果:
- 如果关闭了RDB持久化(以及AOF持久化),那么当Redis重启时,则会加载上一次从节点全量复制或者执行shutdown时保存的RDB文件。而这个RDB文件很可能是一份过时已久的数据。
- Cluster模式下,Redis重启并从RDB文件恢复数据后,如果没有读取到cluster-config-file中nodes的配置,则标记自己为单独的master并占用从RDB中恢复的数据的Key对应的槽,导致此节点无法再加入其它集群。
关注我,后续更多干货奉上!
左下角“了解更多”小彩蛋!

