
- 1one piece_娜美_01_one piece hentai
- 2CrossOver软件2023破解激活码_crossover-wine注册
- 3Spring Boot(四):Thymeleaf 使用详解_spring thymeleaf
- 4NX+Ubuntu18.04+ROS Realsense(RealSenseD435i )的安装与使用_realsense安装
- 5记录:rosdep update
- 6js通过a标签的方式下载文件并对其重命名的完整方案_a标签下载文件重命名
- 7JavaScript中的Array.prototype.forEach()方法(简介+重写)_js array.prototype.foreach
- 8leetcode 94 二叉树的中序遍历(java)_lecode中树的输入root = [1,null,3,2,4,null,5,6]是怎么转化成节点的
- 9R语言入门笔记2.1
- 10c#--正则表达式(项目常用)_c# 正则表达式 数字
HttpRunner自动化之响应中文乱码处理
赞
踩
响应中文乱码:
当调用接口,响应正文返回的中文是乱码时,一般是响应正文的编码格式不为 utf-8 导致,此时需要根据实际的编码格式处理
示例:
图1中 extract 提取title标题,output 输出 title 变量值,如下图2可见,输出的变量值成了乱码,图3的报告中可以看到响应的编码为 ISO-8859-1
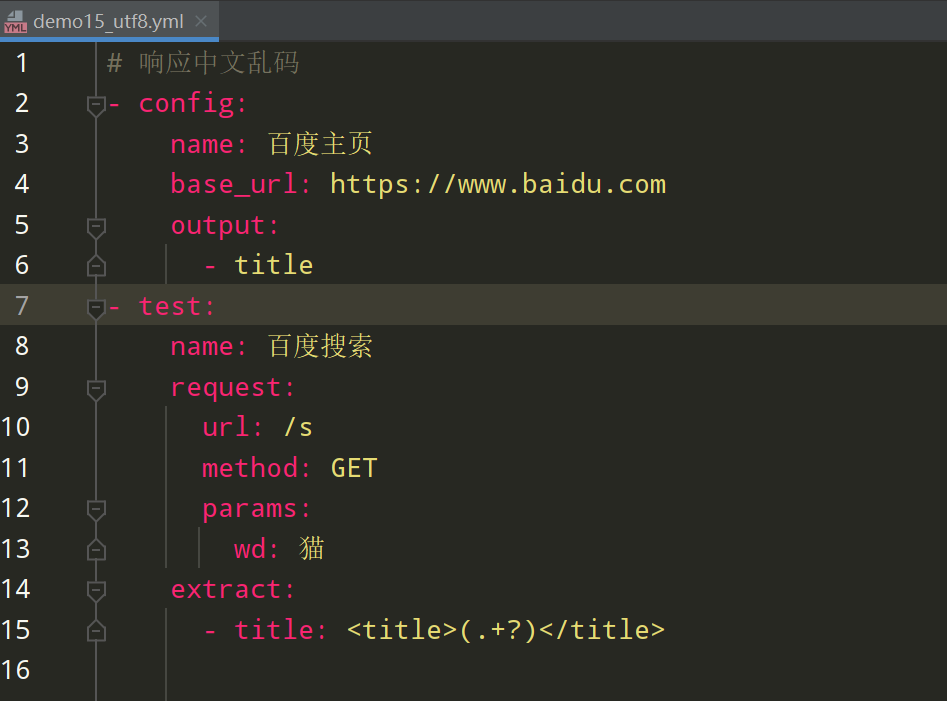


解决方式如下:
方式一,添加headers头部信息,如下图
4个关键字必须:
User-Agent: *****
Accept: *****
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9

上述头部信息关键字,可通过F12键获取

yaml示例:
添加headers头部信息,如下图

添加头部执行后,输出的变量值为utf-8 中文编码;如下图

方式二,通过 debugtalk.py 辅助函数编写代码然后yaml文件中调用;
python中内置函数 encode() 和 decode() ,encode()是编码、decode()是解码
debugtalk.py文件的代码如下:
# encode编码 decode解码
# iso8859-1 编码,解码成 utf-8
def iso8859_to_utf8(str):
return str.encode("iso8859-1").decode("utf-8")
# utf-8 编码,解码成 iso8859-1
def utf8_to_iso8859(str):
return str.encode("utf-8").decode("iso8859-1")
# unicode_escape 编码,解码成 utf-8
def unicode_escape_to_utf8(str):
return str.encode("unicode_escape").decode("utf-8")
在yaml文件中,断言引用函数需要加引号 " ",如下图

测试报告展示成功,断言成功,如下图:

上述是通过utf-8进行断言比对,还可以通过 iso8859-1 进行断言比对;如下图:
variables: 变量;
把预期结果先做个变量然后转成和实际结果一样的编码,最后再通过断言进行比对,如下图:

测试报告展示成功,断言成功,如下图:

最后感谢每一个认真阅读我文章的人,礼尚往来总是要有的,这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,虽然不是什么很值钱的东西,如果你用得到的话可以直接拿走:

这些资料,对于【软件测试】的朋友来说应该是最全面最完整的备战仓库,这个仓库也陪伴上万个测试工程师们走过最艰难的路程,希望也能帮助到你!


