
- 1SSL证书安装后网站还是显示不安全_ssl证书配置完成后访问仍然提示需要输入账号和密码
- 2认沽期权行权后得到的是股票还是资金?
- 3Android:手把手带你入门跨平台UI开发框架Flutter,看完这篇_android flutter框架
- 4C++|设计模式(一)|单例模式与多线程
- 5vue2流星雨(可调角度)
- 6数字IC-1.8 子模块组建整模块-动态数码管设计代码实例_动态数码管的设计
- 7《淘宝技术这十年》读书总结_淘宝技术这10年
- 8C# Socket通信从入门到精通(21)——Tcp客户端判断与服务器断开连接的三种方法以及C#代码实现_c# socket判断客户端断开
- 9[1267]Sourcetree安装教程及使用_sourcetree安装步骤
- 10AI 大模型_ai大模型学习
C++两万字长文总结_一个基类容器可以插入子类对象吗
赞
踩
C++磅薄深邃,浩瀚如烟,让人又爱又恨,爱的是一切尽在掌控之中,恨的是掌控一切太难,大佬们睿智的头脑,演化出无数经典,被广大的信众奉为圭臬,后继者孜孜不倦,这门古老的语言也不断进化,泛发出新的生机。学习C++三年有余,一直想对其做一个整体的总结的,可能是管中窥豹,只见树木,不见森林,但确实是这几年爱之深,恨之切,不断积累钻研,反复被摩擦而又有所顿悟,缓慢前行而理解渐深的一个阶段性的总结,期间也手撸过STL,LevelDb这些经典的项目,也参与过大型C++项目的开发,也囫囵吞枣的看过不少书,回想起来还是学了不少东西。一直觉得, C++是一门充满魔鬼与细节的语言,不同阶段水平对其都有不同的感悟和理解,如果假装大佬模样,简单的甩出几句: 面向对象是灾难,虚函数一无是处,指针是大坑,新特性只是语法糖,这样看起来似乎不是新手了,但是一定是没有认真思考过这门语言。本文尽量从宏观的角度去感悟C++,尽量不做细节展开,一些主要的知识点也以思维导图的方式做简单回顾总结,具体细节,希望在后面更多文章中再做探讨。
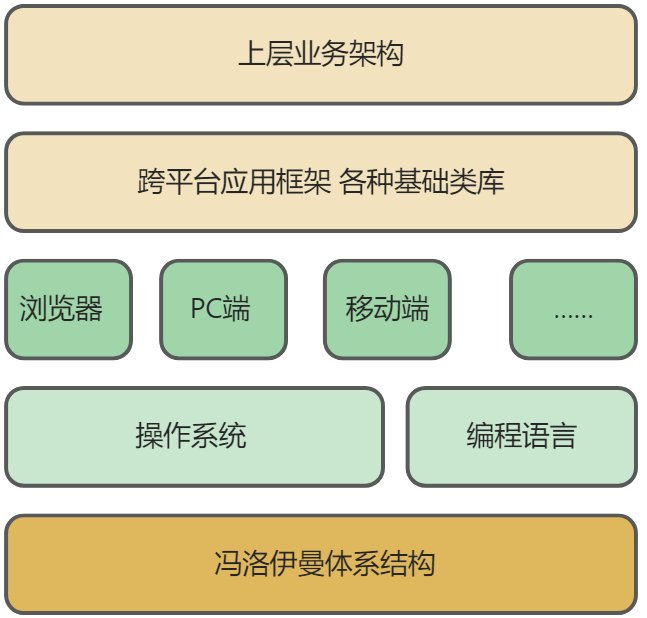
一、从计算机的视角来看
冯洛伊曼体系
冯洛伊曼体系将计算机结构抽象为三大部分,输入输出设备是计算机和外界交互的入口,存储器是数据和指令存储的容器,中央处理器是计算机的大脑。CPU是计算机最核心的组建,事实上CPU是一个笨笨的大脑,它只会重复的干着读取指令,执行指令这样一件简单的事情,但是不要怀疑,它干的真的很快。

冯洛伊曼体系为计算机大厦奠定了坚实的基础,它以一种及其简洁的方式界定了计算机的能力,即解决一切可以用计算解决的问题。这一定义和数学上的函数y= F(x) 非常相似,你给它一个输入,经过一系列运算,就能给你一个输出。这是一种简介而又充满力量的抽象,纳须弥于芥子,以此为基,计算机的大厦拔地而起,岿然屹立。
硬件的工作方式是简单,暴力,大力出奇迹,他们只孜孜不倦的处理着二进制数据,维护着计算机这个复杂的状态机。但是这种方式显然不适合人类,人类面临的是更错综复杂而又具体的问题,人类并不善于处理二进制问题,于是更上层的软件出现了。软件是用魔法打败魔法,用复杂的二进制去解决更复杂的二进制问题,从机器码到汇编到高级语言,到各种基础类库和框架体系,软件也逐渐从根生长出茂密的森林。
软件的基础是编程语言,计算机发展至今,已经诞生了不知道多少们编程语言,但能够经久不衰,日益壮大,拥趸众多的语言其实不多。而C++,便是这万千种编程语言中最为璀璨的一颗之一。她既保留了底层硬件的直接访问途径,又具有完整的高级抽象,兼容并包,内修心法,外练招式,是程序员不可或缺的一环。
从硬件到软件到上层应用,每一层都将自己的能力封装起来,为上一层提供丰富的服务,这种服务就是能力边界的抽象,上层不用直接和底层的繁琐细节打交道,软件不需要过多的了解硬件,框架不需要过多的了解语言层面的实现, 在这简单的几层抽象体系体系下,可以总结一下计算机的科学的本质:
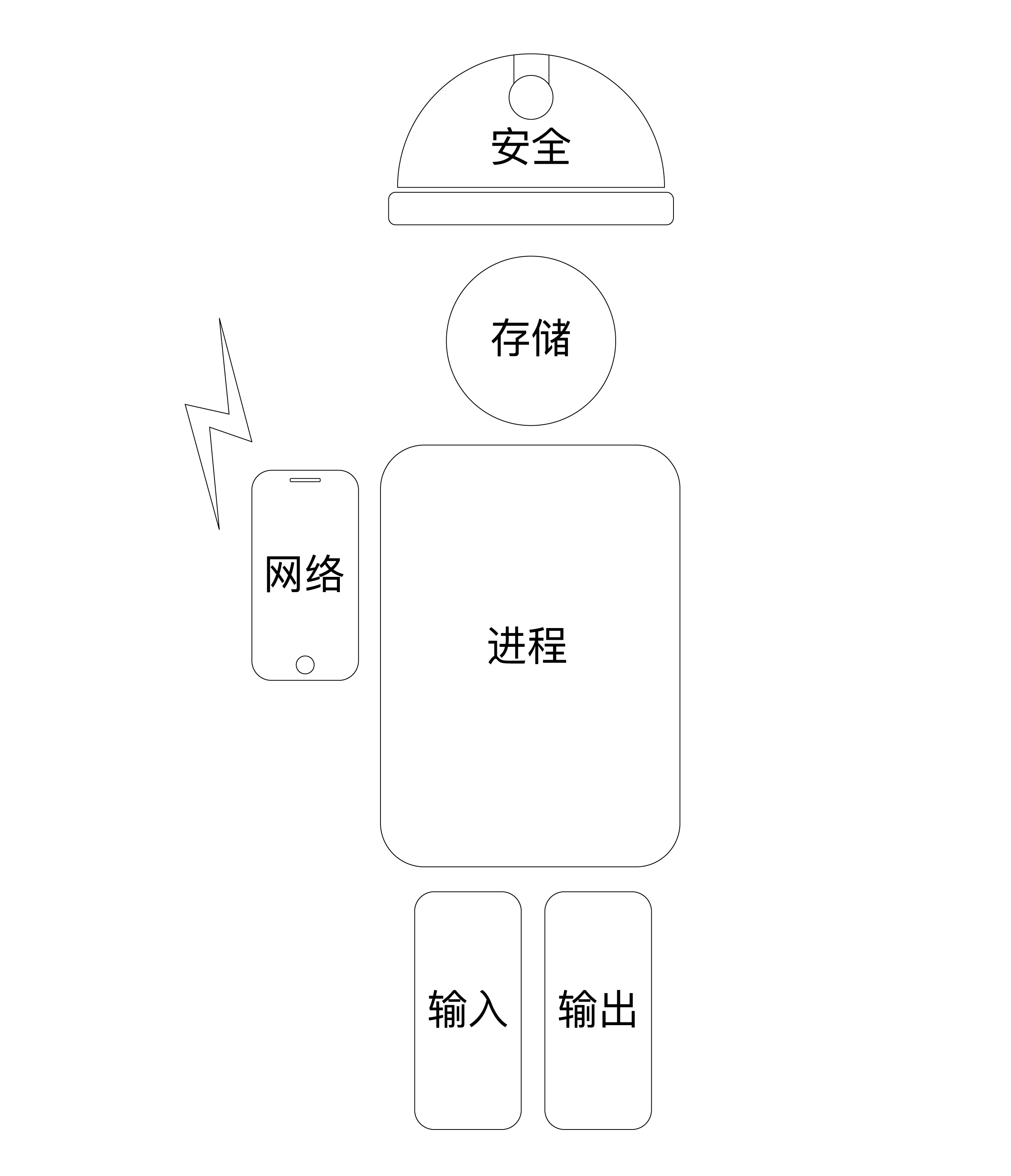
怎么在硬件层次解决问题?
- 硬件的性能:浮点运算能力,多处理器,并发,GPU等
- 硬件的协同: 硬件资源调度配合 , 系统中断 ,IO等
- 硬件的稳定性安全性:保证逻辑执行的准确性,稳定性等
怎么在软件层次解决问题?
- 操作系统,对资源的调度和利用
- 对硬件抽象,提供面向操作系统的统一接口
- 对软件抽象,提供面向编程的统一接口
自最底层到最顶层,随处可见c++身影,其丛深的深度足够深,但在不同层次所关注的重点不一样,正是C++的纵深性,造成其复杂性,让人常有不识庐山真面目,只缘身在此山中之感。古语云,学诗,功夫在诗外,对于C++,亦是如此:学C++功夫在C++之外。
二、从编程语言来看
编程语言
编程语言是一套逻辑符号语言和标准规范的合集,通过一套语法,语义,关键字,逻辑符号定义了描绘程序世界的语言。这套语言,只有人类认识,机器是不认识的,因而编程语言实现的关键是编译器,由编译器将代码翻译成机器指令,这样人类和机器之间的沟壑被打通。
第一门面向程序员的高级语言是汇编语言,虽然我没学过汇编语言,但是偶尔碰到疑难杂症,调试的时候跳转到汇编代码,由于汇编代码几乎是指令的简单映射,因而也能看懂个一二, 还是挺能装一装有点技术含量的。那么问题来了,汇编语言是第一门编程语言,那么是什么语言编写了汇编编译器? 总不能是他自己吧?我没有去挖掘过这个问题,我想应该是上古时期优秀的计算机科学家,用机器码编写了汇编编译器,想想也是很痛苦。
不过,编程语言是可以自举的,是可以不断进化的,汇编语言现在不是有了吗,好,那我用汇编语言编写一个更牛逼汇编编译器可以吧,我用更牛逼的汇编编译器可以编译更复杂的汇编语言了,还不过瘾,我又用汇编写了一个C语言编译器,然后又用c语言写了一个更更厉害的汇编编译器,怎么样,这波套娃是不是很厉害。从机器指令到底层汇编,C语言,Fortran语言,再到高层抽象的C++,Java,Python,生产力逐渐释放~
C++语言基本要素
编程语言至少包含如下三要素, 基本上有这三个要素就能定义一切能够用计算描述的世界了
- 循环和条件分支:让你具有做选择和做重复工作的能力
- 变量和基本运算:计算世界的基本表达
- 函数:定义复杂的计算过程
循环和条件分支
C++中的循环和条件分支是控制程序执行流程的基本结构,以下是 C++ 中常用的循环和条件分支结构
条件语句 if、else if、else
- if (condition1) {
- } else if (condition2) {
- } else {
- }
switch 语句
- switch (expression) {
- case value1:
- break;
- case value2:
- break;
- default:
- }
循环结构 for 循环
- for (int i = 0; i < 10; ++i) {
- // 循环体,重复执行10次
- }
循环结构 - while 循环
- int i = 0;
- while (i < 10) {// 循环体,重复执行直到条件不满足
- ++i;
- }
循环结构 - do-while 循环
- int i = 0;
- do {// 循环体,至少执行一次,然后检查条件
- ++i;
- } while (i < 10);
循环和选择是复杂程序流程的基本,可以说这些内容占了程序的80%,但是可能和想的不一样,优秀的代码要尽量避免复杂的循环和选择,一方面,代码应该尽量追求简介明了,复杂的代码不易于阅读和维护。另一方面,分支选择是会影响性能的。用复杂的if else逻辑来翻译业务流程很简单,但是经过巧妙设计,干掉复杂的分支选择则需要一定的功夫。在性能方面,分支选择涉及到指令跳转,cpu指令流水线的工作方式,会进行分支预测,从而提高指令处理效率,如果分支选择过于复杂,自然会影响到指令流水线工厂的效率,有一个小技巧就是将大概率执行的if分支写在前面,有些编译器还提供if-likely,unlikely这样的写法,C++20也加入了likely,unlikely属性关键字,用以优化效率。
变量和运算
编程语言可以分为静态类型和动态类型两类,在静态类型语言中,变量的类型在编译时就已经确定,程序员在声明变量时必须明确指定变量的类型。编译器会进行类型检查,确保变量在使用时符合其声明的类型。如果存在类型不匹配的错误,编译时就会产生错误,C,C++,Java这些都是强静态类型。在动态类型语言中,如python,jave script,变量的类型是在运行时确定的。程序员无需显式声明变量的类型,变量的类型可以随时改变。类型检查通常是在运行时进行的,动态类型就少了很多类型相关的负担。
C++数据类型
C++有多种数据类型,对于数据类型,要理解两点,一是数据的表示方式,如有符号还是无符号,浮点数编码等,二是数据的内存布局,不同类型的数据在内存中的长度不同,表示的范围也不同,需要注意大数溢出的问题,复合数据类型,如结构体还有内存对齐的问题。
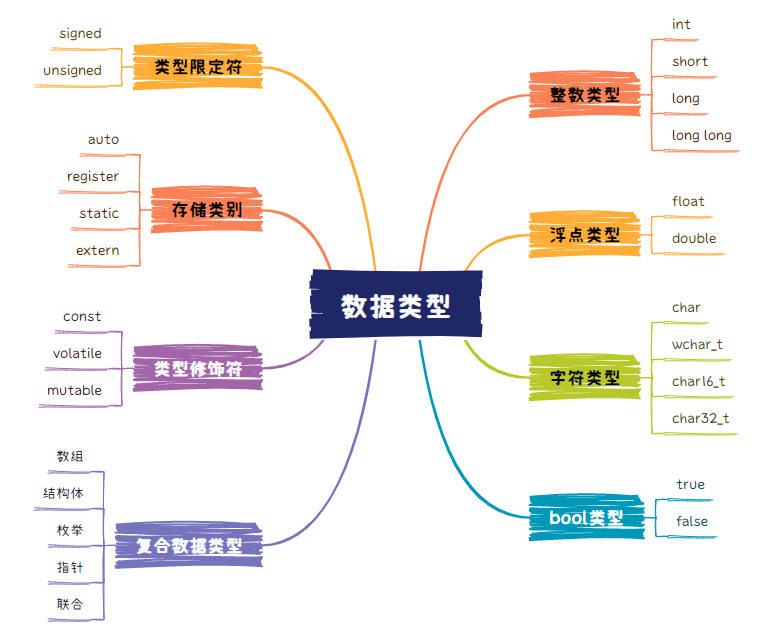
C++还具有丰富的类型修饰符和类型别名的能力,允许程序员在需要时创建更复杂的数据结构,如typedef和using,合理的用用typedef,可以减轻很多类型的负担。
对于不同的机器,数据的表示还有大小端之分,小端即数据的低位存储在低地址,高位存储在高地址,如下为检测大小端的简单代码。
- // true: 小端
- // false: 大端
- bool IsLittleEndian()
- {
- uint16_t num = 1;
- return (*reinterpret_cast<uint8_t*>(&num) == 1);
- }
左值和右值
C++中,左值 和右值是两个很重要的概念,注意值类别和类型是两个完全不同的概念,c++中左值右值类别的划分还是挺复杂的,可以参考下图
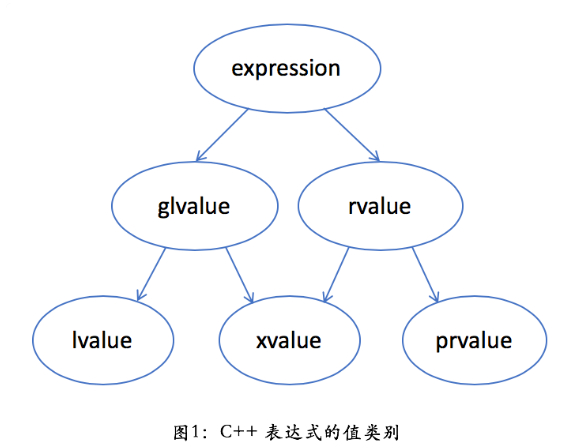
我们先理解一下这些名词的字面含义:左值lvalue是通常可以放在等号左边的表达式,右值rvalue 是通常只能放在等号右边的表达式,glvalue是广义左值,xvalue 将亡值(expiring value),prvalue 是纯右值(pure rvalue),左值 lvalue 是有标识符、可以取地址的表达式,最常见的情况有:
- 变量、函数或数据成员的名字
- 返回左值引用的表达式,如 ++x、x = 1、cout << ' '
- 字符串字面量如 "hello world"
在函数调用时,左值可以绑定到左值引用的参数,如 T&。一个常量只能绑定到常左值引用,如 const T&。
反之,纯右值 prvalue 是没有标识符、不可以取地址的表达式,一般也称之为“临时对象”。最常见的情况有:
- 返回非引用类型的表达式,如 x++、x + 1、make_shared<int>(42)
- 除字符串字面量之外的字面量,如 42、true
xvalue不是很好理解,可以参考一下如下比较官方一点的解释:
An xvalue (an “eXpiring” value) also refers to an object, usually near the end of its lifetime (so that its resources may be moved, for example). An xvalue is the result of certain kinds of expressions involving rvalue references. [ Example: The result of calling a function whose return type is an rvalue reference is an xvalue. ]
类型推导
- auto一点也不auto
为了增量类型的易用性,C++引入了auto关键字,用于自动类型推导,但其实auto一点也不auto,auto背后其实和模板参数推导有着一套同源的规则,当然这套规则其实也是非常复杂,没有个长篇大论是说不完。这里有个小技巧,如果你肉眼一下子能看出来的类型,编译器也应该很容易看出来,这个用auto自然用的很得心应手,如果是个很复杂的场景,那就不用auto就完事了~
- template<class T>
- void func(ParamType param);
- func(expr)
- //当用auto推导expr的类型时,相当于推导上面模板中的T
- move啥也没移动
move其实啥也没move,只是把类型强转成右值引用,以便于函数重载,但是仔细想想,其实move也"移动"了一点东西,那就是临时对象的资源,浪费了也是浪费,还不如移动给我,从这种意义上看,move叫做rvalue_cast,move构造函数叫swap构造函数,这样还更容易理解,但是啰里巴嗦。
- template <typename T>
- typename remove_reference<T>::type&& move(T&& t){
- return static_cast<typename remove_reference<T>::type&&>(t);
- }
- forward一点也不完美
完美转发是为了解决模板参数推导过程中,值类别丢失的情况,在如下场景中,param无论是左值还是右值,在调用other_func(para)时,都变成了左值,因为其是具名的,可取地址的,所以就出现了forward,将左值转发为左值,右值转发为右值,至于引用折叠这种“唬人”的概念,那纯粹就是为了给下面的推导规则安个名分而已,不然当T的类型时&&,&时,T&& &&,T& &&这种怪异的符号又代表什么意思呢,干脆就把它折叠吧。
- template<class T>
- void func(T&& param){
- call other_func(param);
- }
函数和方法
函数是一段可执行逻辑流程,是程序最小粒度的功能实现体,如果说冯洛伊曼体系将计算机抽象成了一个大的函数,那么这个大的函数其实是由无数个小函数组成,
自定义函数
C++里大部分的函数以类的成员函数出现,当然也能像C语言那样定义全局的函数或者仅编译单元内部可见的static函数。
- 应用函数
- 库函数
- 函数申明和定义:
- 函数参数:
- 函数重载:
- 递归函数:
- 函数指针:
- Lambda 表达式:
系统调用
除了自定义函数,还有一类重要的系统调用函数,系统调用通常通过操作系统提供的系统库函数与系统资源打交道,如文件读写,线程创建,内存分派。系统调用的开销是相对较高的,因为它涉及从用户空间切换到内核空间,执行一些特权操作,然后再返回用户空间。这种上下文切换和特权级别的变化会引入额外的开销。尽管系统调用的开销较高,但它是访问底层硬件和操作系统功能的必要手段,而且许多应用程序在整体性能上并不受其明显影响。
内联函数
C++通过inline关键字标识一个函数为内联函数,但是inline函数不一定能够内联,是否内联还要和当前编译器的优化有关。内联能提高函数的执行效率,为什么不把所有的函数都定义成内联函数?如果所有的函数都是内联函数,还用得着“内联”这个关 键字吗?内联是以代码膨胀(复制)为代价,仅仅省去了函数调用的开销,从而提高函数的执行效率。如果执行函数体内代码的时间,相比于函数调用的开销较大, 那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。内联函数并不是一个增强性能的灵丹妙药。只有当函数非常短小的时候它才能得到我们想要的效果,但是如果函数并不是很短而且 在很多地方都被调用的话,那么将会使得可执行体的体积增大。
类的高级抽象
Class是数据和函数的高级抽象,虽然C++保留了多范式编成,Class并非必须,但是大部分的C++程序都在和类打交道。类最关键的特性就是封装,所谓的封装就是对事物本质的抽象,封装也延续了一切皆数据+操作的思想。用类来表示高级的数据结构是看起来很自然的事情,对象成了程序之中最主要的实体。

类与对象:
- 类是一种用户定义的数据类型,用于封装数据和方法。对象是类的实例。类定义了对象的属性和行为。
封装:
- 封装是一种将类的数据和方法包装在一起的机制,通过访问修饰符(public、private、protected)控制对类成员的访问。
继承:
- 继承允许一个类(子类)基于另一个类(父类)的属性和方法构建。子类可以继承父类的特性,并可以添加或覆盖部分功能。
多态:
- 多态允许以一种统一的方式处理不同类型的对象,通过虚函数实现运行时多态,一段代码具体行为取决于对象的真实类型。
抽象类与接口:
- 抽象类包含纯虚函数,不能被实例化,用于定义接口。接口是一个类的抽象表示,它规定了一组方法,但没有提供实现。
类的基本组件
- 类定义:
- 成员变量和成员函数:
- 访问控制:public、private和protected
- 构造函数和析构函数:
- 拷贝赋值和移动:
- this 指针:
is-a关系
C++中继承的关系表示的是is a的关系,即Derived is a kind of Based,其实我觉得这里继承的概念有点不是很准确,继承的概念是从父哪里得到了什么,儿子继承了父亲的财产,这偏重于特性的继承和代码的复用,而类的继承的更关注的应该是对象概念的泛化和实现,即父类是一般性,子类是特化,每一个子类都拥有父类一样的特性。儿子继承父亲,这是理所当然,但是说儿子是父亲,这是说不通的。
说起C++继承,也是让许多人诟病,继承体系一单铺展开来,就再无回头路,代码的维护和拓展必将走向灾难。复杂的继承体系本身就是一种父子相互耦合的实现,如果需要修改,将会牵一发而动全身,可能需要修改所有的子类,违背了开闭原则
当然,继承是比较符合人的直觉的一种设计思路,在设计大型软件时,第一思路是确定类的派生架构体系,仿佛这种派生架构体系构成了程序的整体架构。
继承的主要目的,应该是实现多态,而不是代码复用,因而在设计类的派生关系时,应该思考对象是否是is a的关系,继承层次也不要太深
has-a关系
has-a是组合(composition)的概念。通过组合,一个类可以包含另一个类的对象,从而实现代码的重用和灵活性。这种关系通常用于描述一种"has-a"关系,即一个类包含另一个类的实例作为其一部分。例如,一个Car类可能包含一个Engine类的实例,因为汽车拥有引擎("has an Engine")。
如果你在实际开发中,能够体会到“组合优于继承”,那么我觉得你对面向对象又有了更深一步的理解。
对象之间的关系
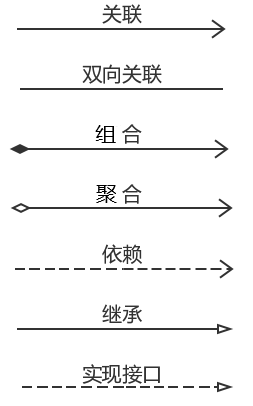
软件运行的过程就是不同的对象之间相互交流,协作,完场数据的处理。对象之间的关系也很重要,我们可以通过UML的方式,来表示类之间的关系:
- 泛化关系
- 实现关系
- 依赖关系
- 关联关系
- 聚合关系
- 组合关系
泛化和实现是同种类型的抽象和具体的关系,依赖,关联,聚合,组合表示不同类型对象之间的相互关系,一般认为这些关系的强弱程度为:组合>聚合>关联>依赖。
✍️以桌子为例来说明一下各种关系:桌子为泛化,餐桌为实现,桌子和木头是依赖关系, 桌子和桌子上的果盘 是关联关系, 桌子和桌布聚合关系, 桌子和桌腿是组合关系。
一般通过UML(Unified modeling language ,统一建模语言),以符号图标的形式只管的表示类之前复杂的关系。
C++其他主要特性
指针
指针也是一种变量类型,它存储另一个变量的地址。我们通过type*来声明指针类型,需要在使用前进行初始化,使用解引用操作符*访问指针指向的内存中的值。对于类对象,可以通过->访问成员,->本质上也是一种操作符重载,表示指针所指向的对象。在C++中指针无处不在,正是指针赋予了C++与内存打交道的能力,当然能力越大,责任越大,这种能力的背后是C++程序员更高心智负担。
- 指针和动态内存分配
- 指针运算
- 指针和数组
- 指针和函数
- 智能指针
指针的精妙之处在于见微知著,以小博大
- 指针的大小书固定的,但是却能引用任意大小的数据,这在函数参数传递,和类的前置申明方面有着绝佳的应用
- 指针,指向一个地址,更是指向一块内存的起始地址,通过地址和长度,可以方便的索引一组在内存中连续的对象,最典型的例子就是数组
指针最核心的思想就是映射,一个指针可以映射一块连续内存,只要知道这块内存的地址,元素的类型和元素的个数,就能通过简单的指针偏移访问内存块中所有的对象,有以小见大,四两拨千斤之效。
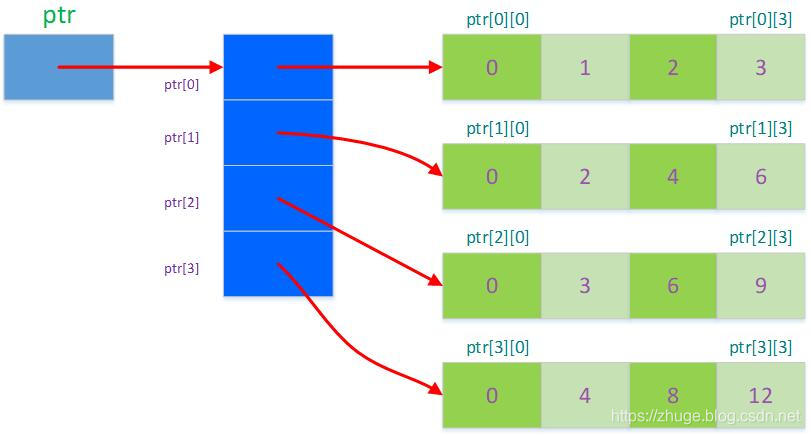
指针本身也是一个变量,这个变量自身可以取地址,这个变量的值是一个地址, 指针类型决定了怎么去解析指针变量存储的地址里面的数据。由于指针本身是变量,因而可以套娃定义多级指针,但是这会让大大增加指针的复杂性。这里我有一个经验就是,遇到一个复杂的指针场景,不妨站在编译器的角度思考一下,从你给的指针信息出发,我该怎么去解释某一块内存,如果能够正确的解释,就是正确的使用指针了。
指针和引用
指针和引用在一定程度上是等价的,引用变量在功能上等于一个指针常量,即一旦指向某一个单元就不能在指向别处。那么既然引用和指针等价,为什么还需要引用?
经非官方考古研究,最初引入引用的原因是为了解决指针在某些运算符重载的情况下表现得非常拧巴,假设有如下示例中的一个数组类,通常需要重载[]操作符,用于通过下标访问数组元素,如果operator[]的返回值是指针,那么通过[]运算符对数组赋值只能写成*(a[0]) = 10,显然啰哩吧嗦。但是如果返回一个引用,就可以直接写成a[0] = 10,简洁明了。
- class IntArray
- {
- public:
- //int* operator[](size_t i); //返回指针
- int& operator[](size_t i); //返回应用
- };
-
- IntArray arr;
- //*(a[0]) = 10;
- arr[0] = 10;
也许类似于上面的例子,是“引用”这个语言特性的引入契机,但引用相对于指针还有更多的优势:
- 从语法上,指针取值和访问成员的写法是:*ptr 和 ptr->foo,而引用的写法是 ref 和 ref.foo
- 引用可以 直接把函数的返回值当做左值,直接对函数的返回值进行修改,例如cout<<1<<2;
- 引用在一些场景有更强的语义,如果一个函数,void foo(const char *bar),这么定义的话,这个bar指向的到底是一个char对象,还是一个char字串?或者还有可能是个nullptr?相反,如果是void foo(const char &bar),就没有那么多问题了,你很清楚,这是一个char对象。
- 指针可以为空,使用指针的地方需要对指针要做nullptr检查,指针可以不赋初值,所以容易出错忘记赋值
- 引用必须初始化,并且不能更改指代对象,指针可以更改指代对象,更灵活也更容易出错
所以,究竟用指针还是引用?也不用纠结,能用引用就用引用吧。
const-mutable-volatile
我觉得学习C+的第一道分水岭,就是对const的理解,如果你能对const有较为深入的理解和应用,说明C++已经达到了一个还不错的水平,const虽然短小,但是用处却很大,至少有如下用途
- 常量声明,常量特性
- 指针和const,分为底层cosnt和顶层const
- const引用
- const成员函数,只读特性
- const 对象,const 对象只能调用 const 成员函数,因为这样可以确保不修改对象的状态。
- 常量表达式(constexpr),constexpr 表示在编译时计算的常量表达式。
mutable,用于修饰成员变量,表示即使在 const 成员函数中,该成员变量仍然可以被修改。volatile一般用于告诉编译器不要对变量进行优化,我们可以看一看如下这个有趣的示例, 如果不加volatile,程序会输出1024,因为此时,NUM已经被编译器优化为一个常量数字,对其更改也就不起作用了。
- // 需要加上volati le修饰,运行时才能看到效果
- const volatile int NUM = 1024;
- auto ptr = (int*) (&NUM);
- *ptr = 2048;
- cout << NUM << endl; // 输出2048
引用语义下的const
引用语义下,const修饰的是变量本尊,因而有很强的语义在里面,在const作为参数或者返回值时,能接收什么样的实参,能用什么类型去接受返回值,一条原则是:变量的限制可以增强,但是不能减弱
- const& 形参 可以传const对象 也可以传非const 对象
- 如果不希望发生拷贝,就用引用
- 如果不希望参数发生改变,就传const&
- 如果希望返回本尊,就返回引用,但是不要传局部变量的引用
- const 引用 可以用非cosnt 值初始化,但是不能通过cosnt 引用去改变这个值,可以直接去改变这个值
值语义下的const
- 值语义形参
- void fun(obj)
- //传const 非const 对象都一样,反正都是copy参数
- 顶层const
- fun(obj* const)
- //当形参有顶层const时,传递给它常量对象或非常量对象都是可以的,obj不变,obj指向的对象无所谓
- 底层const
- fun(const obj *)//可以传入常量 或 非常量
- //可以使用非常量对象初始化一个底层const形参,但是反过来不行。
- cont obj* p = new obj;
- obj* p1= p; //这样是不行的。
比较让人迷惑,也是新手容易写出来,明眼看上去没啥问题,但是成熟的代码里一般不会有的情况。
const值语义的形参,不管传递的参数是否是cosnt,都会进行copy,对一个copy的临时副本进行const限制,我想大多数场景下是没什么用处的,既然你想传copy的参数,说明你不想在函数体内改变原来参数,既然函数体内不会改变这个参数,那么对其进行cosnt限制,是不是显得有些多余?
- //const值语义形参
- void fun(const obj) //传const 非const 对象都一样,反正都是copy参数
const返回值,我们来推测一下这种写法的意图,一是限制返回值的修改,返回值是一个拷贝的对象(姑且不考虑RVO),是一个右值,如何修改? 而是限制必须用一个const变量来承接返回值,即const obj p= fun(), 或 const obj& p = fun(); 这个能限制住吗? 我直接写obj p = fun(), 一样没问题,多一次copy而已。
- //const 返回值
- const obj fun() //函数返回值是const没什么意义,返回值是copy的,无法约束其为const
const 和引用或者指针放在一起才有语义上的意义,如果不是指针或引用,都是对象copy,const一般是没有什么意义的。
const 形参导致的重载
顶层const不影响传入函数的对象,一个拥有顶层const的形参无法和另一个没有顶层const的形参区分开来。
- //都是传的copy,无法区分
- void test(A a);
- void test(const A a); // redeclares
- void test(A*);
- void test(A* const); // redeclares
如果形参是某种类型的指针或引用,则通过区分其指向的对象是常量还是非常量可以实现函数重载,此时的const是底层的。当我们传递给重载函数一个非常量对象或者指向非常量对象的指针时,编译器会优先选用非常量版本的函数。
- void test(A&);
- void test(const A&); // overload function
- void test(A*);
- void test(const A*); // overload function
const和指针的引用
由于指针本身也是一个变量,因而指针也有引用,一般有如下用法
- void f(int*& ptr) {
- ptr = new int();
- }
-
- void f(int* const&) { //引用的是 指针常量
- }
-
- void ff(const int* &) { // 引用的是 常量指针
- }
-
- int* p = new int(10);
- f(p); // ok
- ff(p); //error
- const int* pp = new int(10);
- ff(pp); //ok
对象所有权
在C++中,对象所有权是指对于内存分配的对象,谁负责管理其生命周期和释放相关的内存。
栈上对象
对于栈上的对象,对象分配在函数栈,其生命周期与包含它的作用域相对应,当程序执行离开该作用域时,栈上的对象会自动被销毁,由于栈展开机制(stack unwinding),可以确保栈上的对象即使在抛出异常时也能得到正确的销毁,这也是RAII的基础。
- void exampleFunction() {
- MyObject obj; // 对象 obj 在这个作用域内,将在作用域结束时自动销毁
- }
堆上对象:
当对象通过动态内存分配(使用 new)分配在堆上时,需要手动管理其生命周期和释放相关内存,这需要使用 delete 来释放对象和防止内存泄漏,一般不推荐下面这样的写法,如果你说你有5年编程经验,然后写出下面的代码,别人一定会说,你是去年从Java转过来的吧。
- void exampleFunction() {
- // 对象 obj 在堆上分配
- MyObject* obj = new MyObject;
- // 使用 obj
- // 释放内存
- delete obj;
- }
智能指针:
为了更安全和方便地管理动态分配的内存,C++提供了智能指针,如shared_ptr和unique_ptr,这些指针可以自动管理对象的生命周期,减少手动释放内存的负担。
- shared_ptr标识共享所有权,共享对象不被任何对象引用时结束生命周期
- unique_ptr标识独享所有权,对象的生命周期与其所有者相同,但是对象的所有权可以转移,
- weak_ptr,是为了解决循环依赖,共享计数无法归0的问题而提出的一种指针。
在C++11之前,有一个auto_ptr,但是其存在一个致命的缺陷,就是复值运算符中,对象的所有权不明析,直到C++11,move的引入,让unique_ptr的复制运算具有移动语义,明确的告诉调用方,所有权的转移。
对象所有权的传递:
- 当对象在函数之间传递时,需要注意所有权的转移。通过引用或指针传递对象可以共享所有权或传递所有权。
- void transferOwnership(MyObject*& obj) {
- // 传递所有权
- obj = new MyObject;
- }
-
- int main() {
- MyObject* sharedObj = nullptr;
- transferOwnership(sharedObj);
-
- // 使用 sharedObj
-
- // 需要手动释放内存
- delete sharedObj;
- return 0;
- }
总体而言,C++开发者需要谨慎处理对象的所有权,特别是在使用动态内存分配时。使用智能指针和遵循良好的内存管理实践可以有效减少内存泄漏和悬挂指针的风险。
Callable,可调用对象
在C++中,除了一般性的函数,还有函数指针,函数对象,即带状态的函数,lambda表达式,即闭包,还有function,bind,这些丰富了函数的世界,我们可以统称这些为Callable,可调用对象。特别function和bind相结合,能产生巨大的威力。
- 函数指针
- 函数对象(Functor)
- Lambda 表达式:
- std::function:
- std::bind:
借助上面的一些特性,我们可以写一个传递任意参数的万能函数~
- class UniversalCallable {
- public:
- UniversalCallable() = delete;
- UniversalCallable(const UniversalCallable&) = delete;
- void operator=(const UniversalCallable&) = delete;
-
- template <typename F, typename... Args>
- UniversalCallable(F&& f, Args&&... args) {
- func_ = std::bind(std::forward<F>(f), std::forward<Args>(args)...);
- }
-
- void operator()(void){
- func_();
- }
-
- private:
- std::function<void()> func_;
- };

类型擦除和泛型
类型擦除就是将原有类型消除或者隐藏,这是一种泛型的思维,因为很多时候并不需要关心具体类型是什么或者根本就不需要这个类型,通过类型擦除可以获取很多好处,例如更好的扩展性、消除耦合以及一些重复行为,使程序更加简洁高效,c++中类型擦除方式主要有以下五种:
- 多态, 虚函数
- 模板,鸭子类型,CPRT
- 容器,基类容器可以放任何子类对象
- function和bind
- Lambda闭包
访问权限可见性
对于一个复杂的程序世界,不同的对象和组件之间需要有一些森严等级的约束,才能维护良好的秩序,才不至于看起来一团糟,难以维护。类的成员和方法公私分明,读写分明,编译单元内部的方法,就不要让外部可见,模块之间交互的接口清晰明了,不同模块的符号相互隔离等等让一个大型工程不至于快速的走向腐烂。
- 成员访问权限
-
- public
- protected
- private
- friend友元
- 继承权限
-
- public,protect
- private极少见,implemented-in-terms-of
- const常量和只读
-
- 常量
- 只读接口
- 可见性
-
- namespace
- static:Internal Linkage
- extern :External Linkage
- API
-
- 接口可见性
zero overhead
C++是一门强调极度强调运行时性能的语言,Zero Overhead是C++语言设计中的一种原则,也可以称之为C++的设计哲学,这一原则包含两方面的理解:
- 不需要为没有使用到的语言特性付出代价,即我不用这个特性,就不必要为其承担性能开销
- 使用某种语言特性,不应该引入运行时额外开销,即所有解释抽象的工作都放在编译时完成
这个原则的目标是在使用C++的高级抽象和特性时,仍然能够获得与手动编写低级代码相当的性能。也正是这样的原则,导致C++在新的特性拓展方面表现得非常的慎重和保守
用对象内存布局举例,对于一个类,如果没有定义任何虚函数,也没有继承任何定义了虚函数的类,那么这个类的对象在内存中的布局与 C 语言的 struct 基本就是一致的,没有多余的虚表。
- 你没有用到虚函数带来的运行时多态特性,就不需要付出虚表带来的运行时开销。
- 你用到了「用类来抽象数据」这个特性,它没有带来任何额外的运行时开销,跟你分别单独操纵类的成员是一样的效率(虚函数的调用只是虚表指针的偏移,效率极高)。
尽管C++的设计追求"Zero Overhead",但并不是所有的C++特性都能完全做到零开销。以下是一些可能违背"Zero Overhead"原则的C++特性:
虚函数(Virtual Functions)和动态多态性:
- 虚函数的使用可能引入运行时的虚函数表(vtable)查找开销,特别是在深度继承层次中。动态多态性的实现可能会带来额外的开销。
RTTI(Run-Time Type Information):
- 使用dynamic_cast和typeid等运行时类型信息的功能可能引入额外的运行时开销。
异常处理(Exception Handling):
- 使用异常处理机制可能导致一定的运行时开销,抛出异常和处理异常可能对性能产生影响。
智能指针的引用计数:
- std::shared_ptr的引用计数机制可能引入一定的开销,尤其是在高并发环境中。
需要注意的是,以上列举的特性并不是绝对的,而是在特定的使用场景和实现情况下可能引入一些运行时开销。
回顾C++的和其演化过程
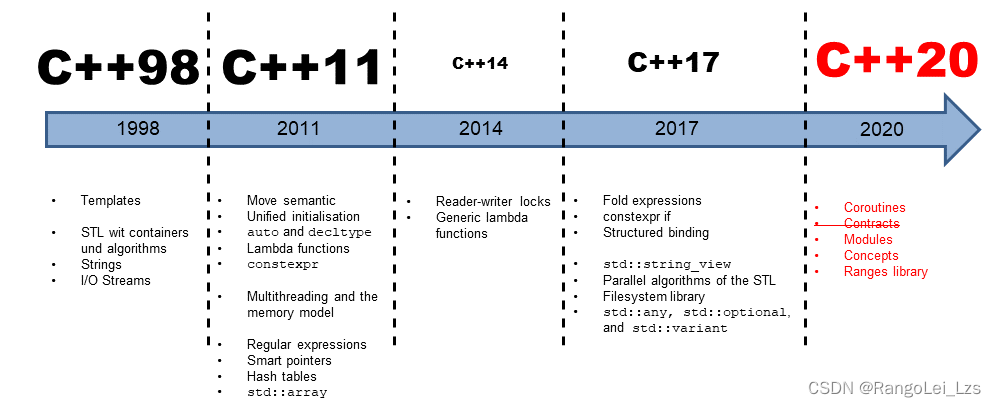
C++98 是C++语言的第一个国际标准,于1998年发布,下面是C++98的一些核心特性:
- 标准模板库(STL)
- 类和对象
- 函数重载
- 运算符重载
- 友元函数和友元类
- 动态内存管理
- 异常处理
- 模板编程
- 命名空间
- 引用
- const 关键字
- 操作符 new 和 delete
- 类型转换操作符
- 内联函数
这些特性为C++提供了强大的编程能力,C++98的发布标志着C++成为一门成熟、标准化的面向对象编程语言。
C++11 是C++语言的第一次重大更新,于2011年发布,它引入了许多新特性和改进,之后又快速推出了C++14,C++17版本,C++涅槃重生,变成Modern C++。
- 自动类型推导(auto)
- 基于范围的for循环
- nullptr
- 智能指针
- 右值引用和移动语义
- Lambda 表达式
- 初始化列表
- 强枚举类型enum class
- 并发编程支持
- 删除和默认函数
- decltype 关键字、
- 静态断言(static_assert)。
C++20是最新标准,继续在C++的表现力、可读性和可维护性方面进行提升,还使C++更加适合现代软件开发的需求,C++20最核心的改动为如下四点,简称Big Four。
- 概念(Concepts)
- 模块(Modules)
- Ranges库
- 协程(Coroutines)
三、从编程范式来来看
编程范式是一种编程风格或思想模式,它定义了如何组织和结构化代码以解决问题,不同的编程范式强调不同的概念和原则,C++是一门多范式编成语言
- 过程式编程,过程式编程是一种基于过程的编程范式,它将程序分解为一系列的过程或函数,主要关注数据的操作,C语言是一个经典的过程式编程语言
- 面向对象编程,面向对象编程是一种将程序组织为对象的编程范式,每个对象都包含数据和相关的操作。面向对象关注数据的封装、继承和多态性,Java、C++、Python等语言支持面向对象编程
- 函数式编程,函数式编程是一种基于函数的编程范式,它将计算视为数学函数的求值,函数式编程最核心的主张就是变量不可变,函数尽可能没有副作用
- 泛型编程,泛型编程侧重于使用抽象和泛化的方式来编写通用的、可复用的代码,C++中的模板是一种泛型编程的例子
C++面向对象
面向对象编程是C++主要的也是应用最多的编程范式,面向对象在过程式的基础上,引入了对象(类)和对象方法(类成员函数),它主张尽可能把方法(其实就是过程)归纳到合适的对象(类)上,不主张全局函数(过程)。面向对象的核心思想是引入契约,基于对象这样一个概念对代码的使用进行抽象和封装。它有两个显著的优点,其一是某种类型的对象有哪些方法一目了然,而不像过程式编程,数据结构和过程的关系是非常松散的。其二是信息的封装,面向对象不主张绕过对象的使用接口侵入到对象的内部实现细节。因为这样做破坏了信息的封装,降低了类的可复用性,有一天对象的内部实现方式改变了,依赖该对象的相关代码也需要跟着调整。面向对象还有一个至关重要的概念是接口。通过接口,我们可以优雅地实现过程式编程中很费劲才能做到的一个能力:多态。由于对象和对象方法的强关联,我们可以引入接口来抽象不同对象相同的行为。这样不同对象就可以用相同的代码来实现类似的复杂行为,这就是多态了。
在实际工作中,我们往往以面向对象的方式写着面向过程的代码,面向对象的核心在于分解,将复杂的场景分解成一个个职责较为单一的类,并让他们巧妙地连接在一起,相互协调和互不纠缠。实际中,我们喜欢写大而全的类,喜欢构建复杂的派生体系,喜欢到处封装一些所谓的工具函数,喜欢在一个函数里处理所有的场景。
C++泛型编程特性
C++是强静态类型语言,有着严格和繁琐的类型系统,程序员仅仅为了处理不同的类型,不得不写出大量重复的代码,这显然无法让人容忍,于是便出现了泛型编程,泛型编程是一种允许编写不依赖于具体数据类型的通用代码的编程范式,C++ 的泛型编程特性主要通过模板实现,以下是 C++ 泛型编程的一些关键特性
模板(Templates):
模板是 C++ 中实现泛型编程的主要机制。它允许编写通用的类和函数,其中的类型或值可以在使用时指定。有两种主要类型的模板:函数模板和类模板。
- // 函数模板
- template <typename T>
- T add(T a, T b) {
- return a + b;
- }
-
- // 类模板
- template <typename T>
- class Pair {
- public:
- T first, second;
- Pair(T f, T s) : first(f), second(s) {}
- };
模板参数推导:
C++ 会尝试根据函数或类模板参数的使用情况推导实际的模板参数类型。这使得在调用模板时不必显式指定模板参数。
- int result = add(3, 5); // 模板参数推导为 int
- Pair<double> myPair(1.2, 3.4); // 模板参数推导为 double
模板特化:
模板特化允许为特定的模板参数提供定制的实现。这在需要处理特殊类型或行为时非常有用。
- // 普通模板
- template <typename T>
- void print() {
- cout << "Generic template" << endl;
- }
-
- // 模板特化
- template <>
- void print<int>() {
- cout << "Specialized template for int" << endl;
- }
模板元编程(Template Metaprogramming):
模板元编程是一种在编译时执行的编程技术,允许在模板中进行复杂的计算和逻辑。通过递归实现,它可以用于生成类型或值。
- template <int N>
- struct Factorial {
- static const int value = N * Factorial<N - 1>::value;
- };
-
- template <>
- struct Factorial<0> {
- static const int value = 1;
- };
模板函数重载:
可以在模板中使用多个不同的函数实现,根据参数类型或数量的不同进行选择。这被称为函数模板重载。
- template <typename T>
- T max(T a, T b) {
- return (a > b) ? a : b;
- }
-
- template <typename T>
- T max(T a, T b, T c) {
- return max(max(a, b), c);
- }
C++ 的泛型编程使得代码更具有通用性和可重用性,可以针对不同的数据类型和需求编写一套通用的代码。模板是实现这种灵活性的核心工具,它在 C++ 中广泛用于标准库和许多应用程序框架。
鸭子类型 (Duck Typing):
鸭子类型是一种动态类型的概念,它关注对象的行为而不是类型。鸭子类型的基本思想是,只要一个对象具有特定的行为或方法,它就可以被视为具有某个类型,无需显式地继承或实现接口。
在 C++ 中,鸭子类型的思想可以通过模板和函数重载来实现,即编写与对象行为相关的通用代码,而不依赖于特定的类型。
- // 鸭子类型示例
- template <typename T>
- void quack(const T& duck) {
- duck.quack();
- }
-
- struct MallardDuck {
- void quack() const {
- cout << "Quack, quack!" << endl;
- }
- };
-
- struct RubberDuck {
- void quack() const {
- cout << "Squeak, squeak!" << endl;
- }
- };
-
- int main() {
- MallardDuck mallard;
- RubberDuck rubber;
-
- quack(mallard); // 输出: Quack, quack!
- quack(rubber); // 输出: Squeak, squeak!
-
- return 0;
- }
C++ 重载决议
C++ 重载决议(Overload Resolution)是指在进行函数调用时,编译器会根据提供的参数列表和函数声明信息,决定应该调用哪个重载函数的过程。重载决议是在编译期间完成的,它涉及到了函数的参数匹配、类型转换、模板推导等多个方面,是C++ 语言中非常复杂的一个部分。
重载决议的过程包括两个阶段:候选函数的筛选和最佳匹配函数的选择。
- 在候选函数的筛选阶段,编译器会根据函数名和参数数量来筛选出所有与调用匹配的函数,并将它们作为候选函数。如果在这个阶段没有找到任何一个候选函数,那么就会发生编译错误。
- 在最佳匹配函数的选择阶段,编译器会从候选函数中选择最合适的函数作为实际调用的函数。这个过程中会考虑函数参数的精确匹配、隐式类型转换、模板参数推导等多个因素,并通过一个特殊的算法来确定最佳匹配函数。
需要注意的是,如果出现了多个函数都可以作为最佳匹配函数的情况,那么就会发生二义性错误,编译器无法决定使用哪个函数,从而产生编译错误。为了避免这种情况,我们可以通过提供更精确的函数重载声明来帮助编译器进行决议。
SFINAE (Substitution Failure Is Not An Error):
- SFINAE 是 C++ 模板系统中的一种机制,用于在模板实例化时避免编译错误。当在模板实例化的过程中出现类型替换失败时,不会导致整个程序编译失败,而是会选择另一个合适的模板。
SFINAE 常常与模板的 enable_if,type_traits结合使用,通过模板参数的条件约束来选择是否匹配模板,如下实例中,std::enable_if 用于创建一个条件,只有在模板参数 T 是整数类型时,printNumber 才会被匹配。如果传递的是非整数类型,SFINAE 机制将导致编译器选择另一个匹配的模板,如果找不到匹配的模板就会报编译错误。
- // 使用 SFINAE 避免非整数类型调用
- template <typename T, typename = std::enable_if<std::is_integral_v<T>>::type>
- void printNumber(T number) {
- cout << number << endl;
- }
-
- int main() {
- printNumber(42); // 输出: 42
- //printNumber("hello"); // 编译错误,非整数类型
- return 0;
- }
enable_if的实现其实非常简单,就是给第一个模板参数为true时定义了一个偏特化版本,并且定义了内嵌类型type,在模板匹配时如果第一个参数为false,则匹配到通用版本,而通用版本没有内嵌类型type,因而模板匹配失败,会报编译错误。
- template <bool _Test, class _Ty = void>
- struct enable_if {}; // no member "type" when !_Test
-
- template <class _Ty>
- struct enable_if<true, _Ty> { // type is _Ty for _Test
- using type = _Ty;
- };
函数式编程
C++ 函数式编程(Functional Programming)是一种编程范式,它强调使用纯函数、不可变性和高阶函数等概念。尽管 C++ 是一门多范式的语言,主要支持过程式和面向对象编程,但它也提供了一些函数式编程的特性。以下是一些与 C++ 函数式编程相关的特性:
Lambda 表达式:
- Lambda 表达式是 C++11 引入的一个功能,允许在代码中直接定义匿名函数。Lambda 表达式使得函数可以作为一等公民,方便在算法和其他地方使用。
- auto add = [](int a, int b) -> int {
- return a + b;
- };
-
- int result = add(3, 4); // 结果为 7
标准库中的函数对象:
- C++ 标准库提供了一些函数对象(Functors),如 std::function、std::bind、std::plus 等。这些函数对象可以用于在算法中传递函数,并支持函数式编程的一些概念。
- #include <functional>
- std::function<int(int, int)> add = [](int a, int b) -> int {
- return a + b;
- };
-
- int result = add(3, 4); // 结果为 7
四、从编程技术要素点来看
计算机组成原理,程序之本
编程时,理解计算机组成原理,提高对计算机系统的整体理解是很重要的,程序的运行世界是基于计算机体系结构的,只有对这个"根本"有一定的了解,才能编写出高效可靠、并能充分的榨取硬件的性能程序。
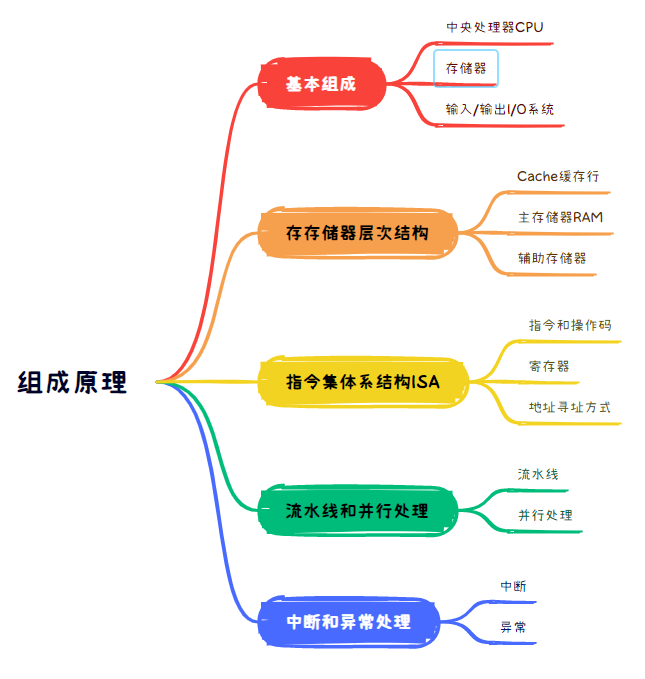
操作系统,内功心法
操作系统在计算机系统中充当着核心的管理者和协调者的角色。操作系统的主要作用是为用户和应用程序提供一个方便、高效、安全的计算环境,管理计算机硬件资源,使得多个任务能够并发运行,并提供对外部设备和网络的统一接口。
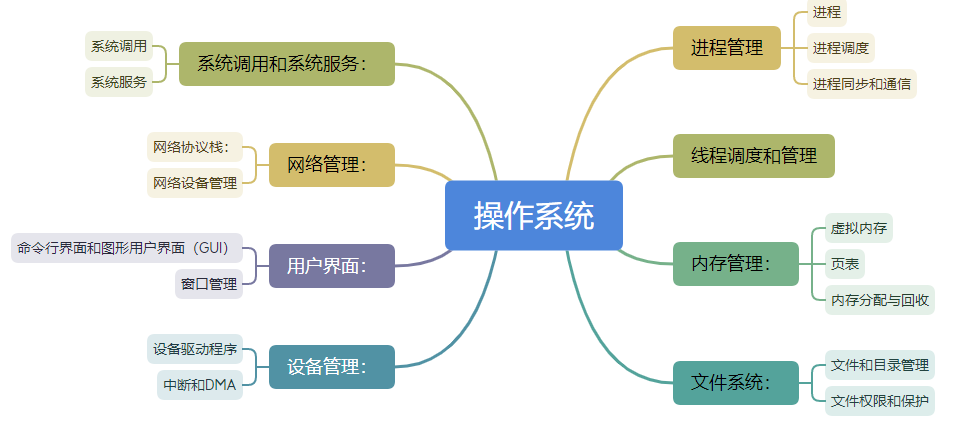
操作系统把 CPU 的时间切成一段段时间片,每个时间片只运行某一个软件,这个时间片给软件 A,下一个时间片给软件 B,因为时间片很小,我们会感觉这些软件同时都在运行。这种分时间片实现的多任务系统,我们把它叫分时系统。分时系统的原理说起来比较简单,把当前任务状态先保存起来,把另一个任务的状态恢复,并把执行权交给它即可,大部分操作系统提供了两套对任务的抽象:进程和线程。
进程是计算机中运行的程序的实例,代表一个独立的执行单元,进程是操作系统分配资源的单位,具有独立的内存空间和系统资源。虚拟内存机制提供了一个抽象的地址空间,在每一个进程的眼里,自己是独享整个虚拟内存空间,当真正需要使用到物理内存是,才将虚拟内存映射到真是物理内存,这在一定程度上,打破了内存对程序的限制。
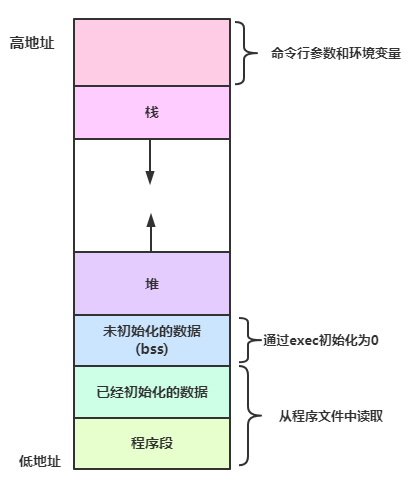
线程(Thread)是进程中的一个执行单元,共享进程的内存空间和资源,线程是 CPU 调度的基本单位。
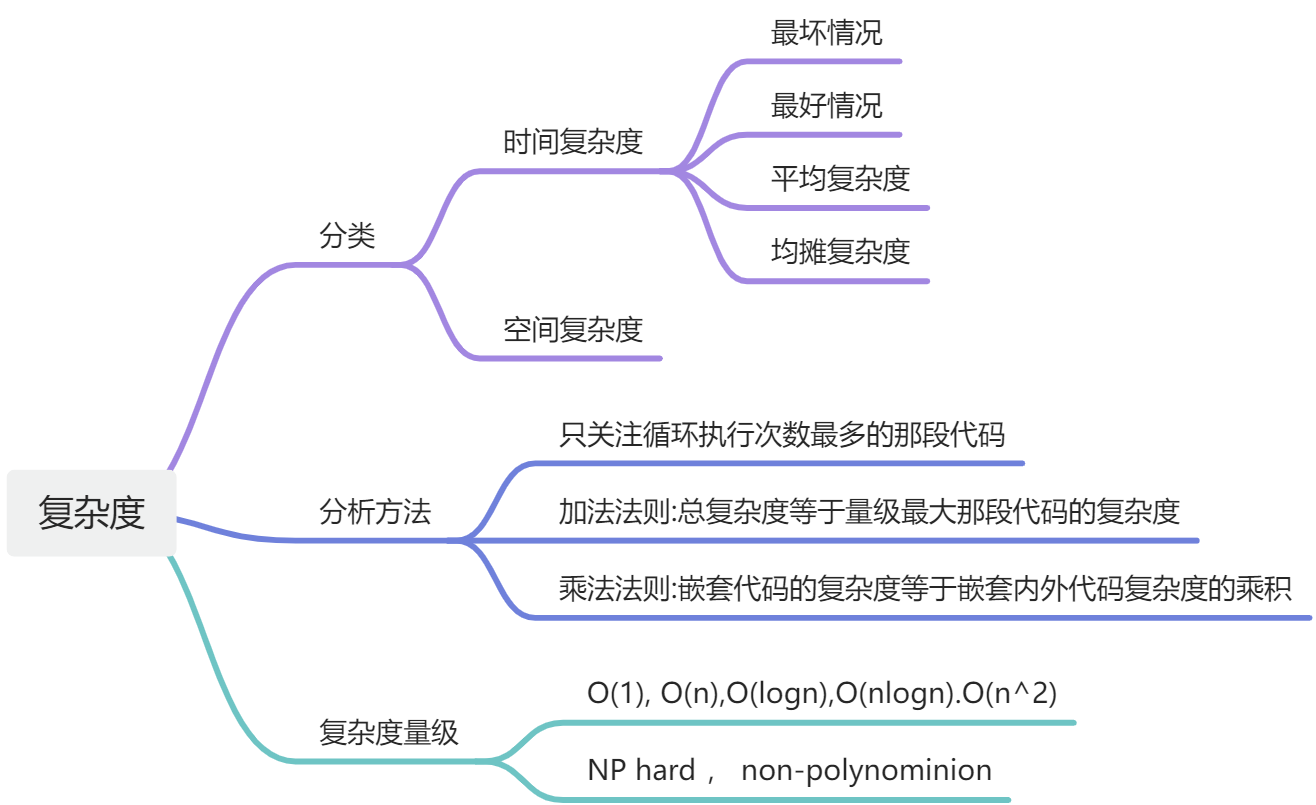
数据结构和算法 ,基本招式
复杂度分析
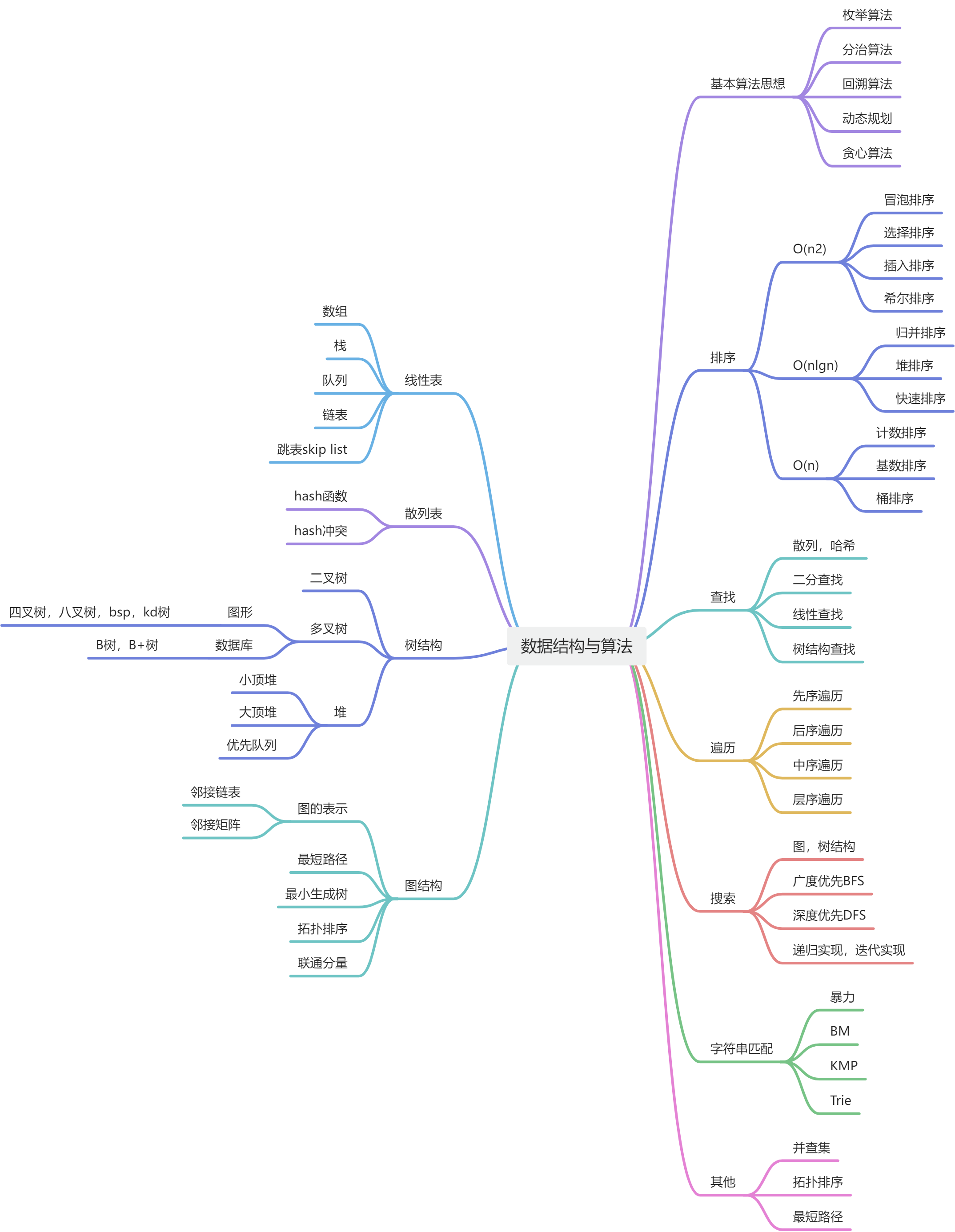
常用数据结构和算法
一切算法的本质都是枚举,只不过枚举的过程有巧妙和笨重之分,算法其实就是借助各种数据结构或者步骤去除暴力枚举过程中无用的部分,从而更高效的找到问题的解,如下这些算法和数据结构需要了然于行,运用自如。
标准库STL
好在,不用一切轮子从头造,C++ STL(Standard Template Library)是 C++ 标准库的一部分,提供了丰富的泛型数据结构和算法。STL 包括多个组件,其中主要的三个组件是容器(Containers)、算法(Algorithms)和迭代器(Iterators),以下是 C++ STL 的一些主要特性:
容器(Containers):容器是用于存储和管理数据的数据结构。STL 提供了多种容器,包括:
- 序列容器(Sequence Containers):vector、deque、list、forward_list,提供按顺序存储和访问元素的功能。
- 关联容器(Associative Containers):set、map、multiset、multimap,提供基于键值对的数据存储。
- 容器适配器(Container Adapters):stack、queue、priority_queue,提供特定的数据结构接口。
算法(Algorithms):
- STL 包含了丰富的算法,用于在容器上执行各种操作。这些算法包括排序、查找、合并、转换等,可用于各种容器类型。
迭代器(Iterators):
- 迭代器是一种类似指针的对象,用于遍历容器中的元素。STL 提供了多种迭代器类型,包括输入迭代器、输出迭代器、前向迭代器、双向迭代器和随机访问迭代器。
函数对象(Functors):
- 函数对象是一种可调用对象,可以像函数一样使用。STL 中的很多算法可以接受函数对象作为参数,用于自定义操作。
分配器(Allocator):
- 分配器用于管理容器中元素的内存分配和释放。每个容器都有一个关联的分配器,它负责处理容器元素的内存管理。分配器是 STL 中的一个底层概念,通常在使用容器时不需要直接操作。
那么STL标准库是如何为不同的算法和不同的类型抽象出一套统一的易用的数据结构和算法接口的呢?
一是STL的实现依赖模板,而非OOP的封装继承与多态
二是使用迭代器,抽象了对数据的访问,使得算法只需要接收迭代器,而不是具体的容器类型
三是Ducking Type,允许模板类型可以调用未经申明的接口,只需要模板实例的参数类型确实含有这个成员,就不会有错误。
四是type_traits,通过type_triat处理与类型相关的信息,进行函数重载。
内存管理,名门正宗
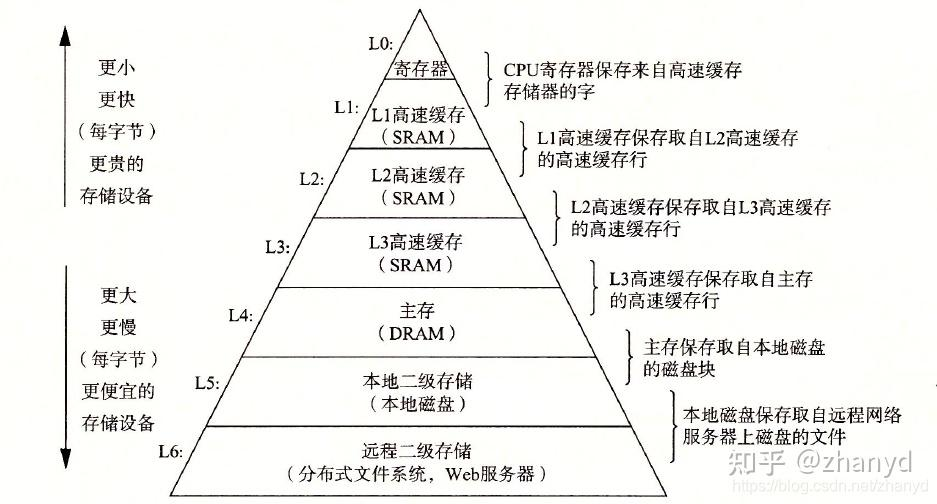
关于内存知识,我们首先需要知道存储设备是分层的,在计算存储体系中一般有如下的金字塔结构的存储设备,我们往往说的内存,主要是主存。
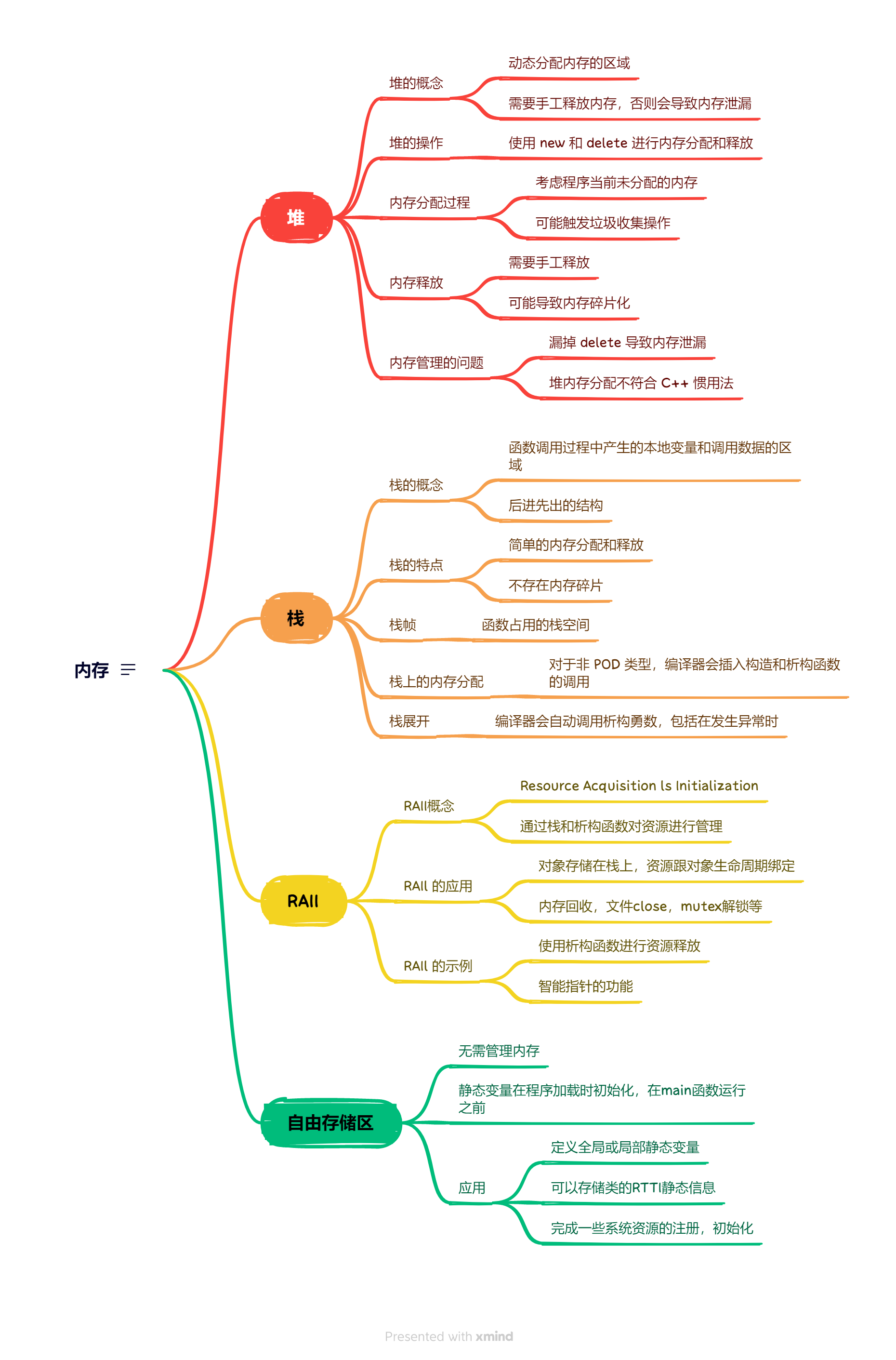
C++内存管理基本知识点
- 堆
-
- 堆的概念
-
-
- 动态分配内存的区域
- 需要手工释放内存,否则会导致内存泄漏
-
-
- 堆的操作
-
-
- 使用 new 和 delete 进行内存分配和释放
-
-
- 内存分配过程
-
-
- 考虑程序当前未分配的内存
- 可能触发垃圾收集操作
-
-
- 内存释放
-
-
- 需要手工释放
- 可能导致内存碎片化
-
-
- 内存管理的问题
-
-
- 漏掉 delete 导致内存泄漏
- 堆内存分配不符合 C++ 惯用法
-
- 栈
-
- 栈的概念
-
-
- 函数调用过程中产生的本地变量和调用数据的区域
- 后进先出的结构
-
-
- 栈的特点
-
-
- 简单的内存分配和释放
- 不存在内存碎片
-
-
- 栈帧
-
-
- 函数占用的栈空间
-
-
- 栈上的内存分配
-
-
- 对于非 POD 类型,编译器会插入构造和析构函数的调用
-
-
- 栈展开
-
-
- 编译器会自动调用析构勇数,包括在发生异常时
-
- RAII
-
- RAII概念
-
-
- Resource Acquisition ls Initialization
- 通过栈和析构函数对资源进行管理
-
-
- RAIl 的应用
-
-
- 对象存储在栈上,资源跟对象生命周期绑定
- 内存回收,文件close,mutex解锁等
-
-
- RAIl 的示例
-
-
- 使用析构函数进行资源释放
- 智能指针的功能
-
- 自由存储区
-
- 无序管理内存
- 静态变量在程序加载时初始化,在main函数运行之前
- 应用
-
-
- 定义全局或局部静态变量
- 可以存储类的RTTI静态信息
- 完成一些系统资源的注册,初始化
-
C++的内存管理是个让人比较头疼的问题,不像Java,Python等有自动垃圾回收机制,C++更多的依托于RAII机制进行自动内存回收管理,合理的运用ARII机制,能减轻不少痛苦。
自定义内存管理
一般使用C++的默认内存分配机制就可以了,但C++仍然提供了丰富的用于内存分配定制的能力。
- 通过重载operator new,定制内存分配行为
- 通过placement new实现在已有内存上构建对象
- 通过内存池,自主管理内存应用和回收
- RAII,自动内存回收,合理使用RAII,可以让life easy

内存局部性原理
局部性原理包括如下两个维度
- 时间局部性:访问一个内存单元后,不久后可能再次访问它
- 空间局部性: 访问一个内存单元后,不久后可能访问其附近的内存单元
即程序在一段时间内所访问的地址,可能集中在一定范围之内,这是因为指令通常是顺序存放、顺序执行的,数据一般是以向量、数组、表等形式簇聚存储的,并且程序在循环中重复访问这些数据。
类似于人的工作方式,将重要的事情和资料放在手边,计算机会将数据放在高速缓存里面,从而提高数据访问的效率,所以为了提高内存使用效率,不妨:
- 尽量让数据紧凑的存放在内存之中
- 尽量让程序按照内存顺序访问数据,而不是到处跳转
并发,第一次思维的挑战
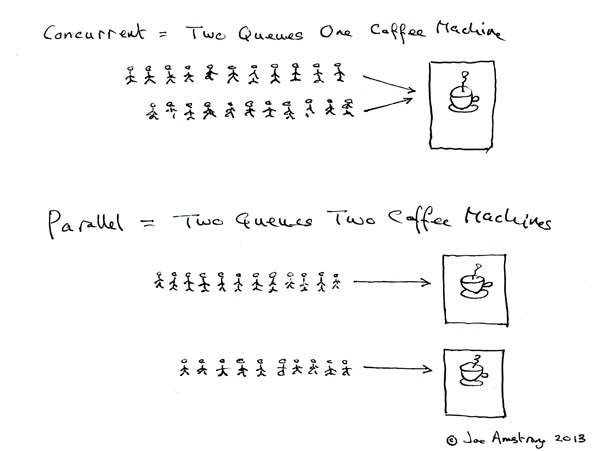
并行和并发
一台咖啡机轮流给两个队列制作咖啡,看起来两个队列在同时接咖啡,这是并发。两台咖啡机同事给两条队制作咖啡,这是真正的并行。
C++并发知识点
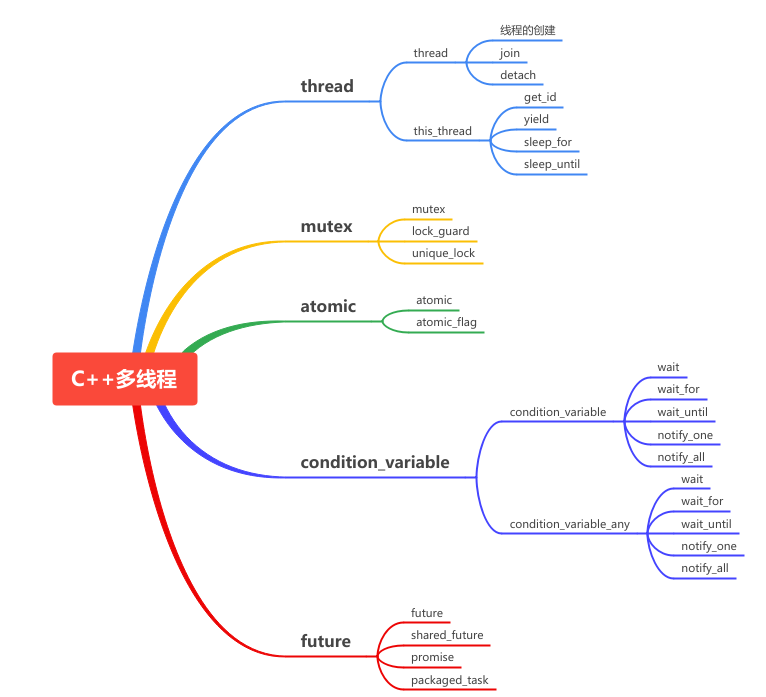
并发是一种思维模式的转变,一切不再那么有序,可控,但是你又得通过一些手段来控制这些不可控的的执行体洪流,让其执行的结果看起来是有序的正确的,C++ 的并发编程涉及到多线程、互斥锁、条件变量、原子操作等概念
同步,异步
- 同步(Synchronous)
- 同步指的是程序按照预定的顺序一步步地执行,每个操作都要等待上一个操作完成后才能继续执行。这意味着程序会阻塞,即在执行某个任务时,程序会停下来等待这个任务完成,然后再继续。
- 同一线程的函数调用,是天然的同步,我们一般关注的同步是运行在不同线程的并发任务的同步,一般通过mutex,condition_variable来实现同步机制。
- 同步通常很直观,易于理解和调试,但可能会导致程序在执行IO、网络请求等耗时操作时出现阻塞,降低程序的效率和响应性。
- 异步(Asynchronous)
- 异步指的是程序在执行某个任务时,不会等待这个任务完成,而是继续执行后续的任务。异步操作通常通过回调函数、promise、async/await等机制来处理。异步编程可以提高程序的并发性和响应性,尤其在IO密集型任务中,避免了线程或进程的等待,提高了程序的性能。常见的异步场景包括网络请求、文件读写、定时任务等。
协程,第二次思维挑战
多线程让程序变得无序,出现条件竞争,但是能够提升程序性能,那协程又是什么呢?协程是一种轻量级的线程,但与传统的线程不同,协程由程序员主动控制,可以在需要时暂停、保存当前状态,然后在需要时恢复执行。
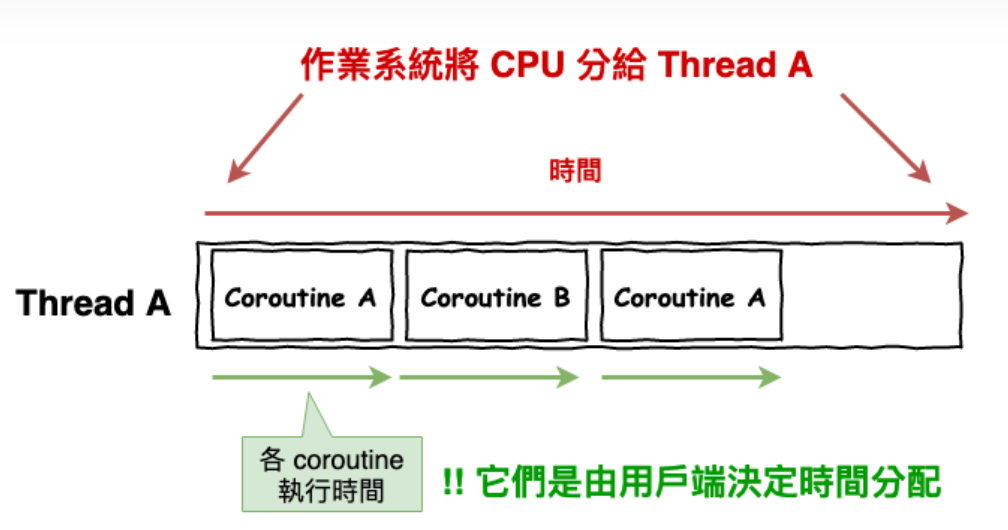
如下为boost协程库,Boost.Coroutine的一个例子,可以感受一下协程的工作流程
-
- boost::coroutines::symmetric_coroutine<int>::call_type lzs( // constructor does NOT enter coroutine-function
- [&](boost::coroutines::symmetric_coroutine<int>::yield_type& yield) {
- std::cout << 3 << std::endl;
- yield();
- std::cout << 4 << std::endl;
- });
-
- int main()
- {
- std::cout <<1 << std::endl;
- lzs(0);
- std::cout << 2 << std::endl;
- lzs(0);
- std::cout << 5 << std::endl;
- }
-
- //输出: 1 3 2 4 5 ,程序在两个函数之间交替执行。
协程从根本上改变了函数执行的流程,以前是调用函数,等待函数执行完,获取函数返回值,有了协程,可以在任意函数之间切换,恢复,关键这些函数是运行在一个线程里面的,因而不会有条件竞争问题,这种模式,让我们得以同步的方式写出异步的代码。
协程有什么黑魔法吗?当然没有,协程也只是一段执行体,这一点和线程无异,差别在于线程是由操作系统调度的,可以通过一些同步原语控制线程的秩序,OS也是通过切换上下文的方式来挂起和恢复线程,从而实现调度。那么,协程的调度同样也是靠保存和恢复协程函数的上下文,所谓的上下文,不过是一堆数据和指令,语言自带的协程是编译器给你施加上上下文备份的魔法,基于库实现的协程则需要自己去干这些底层的累活。
异常处理
关于异常,用还是不用,这是个问题。在代码编写过程中,有大量的代码都是在进行防御性编程,即处理各种可能会发生的异常,以保证软件的稳定性,C++从语言层面上提供了异常的处理机制,那么到底该不该用异常呢。
代码风格
首先是否使用异常机制,决定了你的代码风格,两种典型的风格如下:
- try{
- }
- catch(){
- }
- catch(){
- }
-
- int ret = func();
- if(ret == 1)
- {
- }
- else if(ret ==2)
- {
-
- }
错误码的方式,需要在函数调用流程中层层传递错误码,并且在每层函数中都得写错误码相关处理代码。
而使用异常可以在比较顶层的某个地方集中处理内部抛出的不同类型的异常。
Exception开销
不使用异常的顾虑一般是异常会带来一定的开销
- 代码膨胀
- 性能开销
异常安全
写异常安全的代码,异常安全不是不发生异常,而是异常发生后,仍然能保持程序的一致性和稳定性,其实就是函数在发生异常的时候不会泄露资源或者不会发生任何数据结构的破坏。有一个经典的异常安全的例子:std::stack的pop()为什么不返回栈顶元素,而是返回void?
假设pop()返回栈顶元素的副本(如果返回,只能是副本,pop完栈顶元素不复存在),但是拷贝栈顶元素的过程可能发生异常,即栈顶元素弹出,但是未能成功返回的情况,这样栈顶元素就会丢失。假设如果拷贝发生异常,栈顶元素就不弹出,即pop()失败,那么需要额外的返回值告诉调用者pop失败,这样pop接口设计又非常拧巴。
插件化,功能拓展
C++ 的插件机制是通过动态链接库(DLL)或共享库(Shared Library)来实现的。插件是一种可在运行时加载和卸载的模块,通常用于在现有程序中添加或扩展功能
定义插件接口:
- 插件的核心是定义一个插件接口,其中包含插件应该实现的纯虚函数,这个接口定义了插件与宿主程序之间的通信规范。
- // 插件接口定义
- class PluginInterface {
- public:
- virtual void execute() = 0;
- virtual ~PluginInterface() = default;
- };
实现插件:
- 插件开发者根据插件接口实现具体的插件类。这个类将包含插件的具体功能实现。
- // 具体插件实现
- class MyPlugin : public PluginInterface {
- public:
- void execute() override {
- // 实现插件功能
- std::cout << "Executing MyPlugin" << std::endl;
- }
- };
插件工厂函数:
- 为了实现插件的动态创建,插件可以提供一个工厂函数,通过这个函数在宿主程序中创建插件实例。
- // 插件工厂函数
- extern "C" PluginInterface* createPlugin() {
- return new MyPlugin();
- }
编译和加载插件:
- 将插件代码编译成动态链接库DLL
- 宿主程序在运行时通过LoadLibrary加载动态库,并通过GetProcAddress获取插件工厂函数,调用次函数实例化插件。
反射系统
反射(Reflection)是指在运行时检查、获取和操作程序结构(如类、对象、方法、属性)的能力,反射允许程序在运行时动态地获取有关类型信息、访问对象属性和调用对象方法。
在传统的C++中,没有像一些其他语言(如Java和Python)中那样提供直接的反射机制。然而,C++中可以通过一些技术和库实现类似的反射能力,以下是一些在C++中实现反射的方法和能力:
C++ RTTI
C++提供了RTTI机制,通过使用typeid运算符和dynamic_cast关键字,可以在运行时获取对象的类型信息。
RTTI允许程序动态地检查对象的类型,但其范围相对有限,主要用于基于继承的多态情况。
- #include <iostream>
- #include <typeinfo>
-
- class Base {
- public:
- virtual ~Base() {}
- };
-
- class Derived : public Base {};
-
- int main() {
- Base* basePtr = new Derived();
-
- if (typeid(*basePtr) == typeid(Derived)) {
- std::cout << "Object is of type Derived." << std::endl;
- }
-
- delete basePtr;
- return 0;
- }
手动实现反射
开发者可以手动实现一些反射机制,通过在类中添加元数据信息,如名称、属性等,然后使用这些信息在运行时执行操作,例如Qt中的moc系统,就是经典的反射实现之一。手动实现一个反射系统看起来很高大上,其实原理非常简单。需要有一个地方记录所有类的派生关系,每个类需要有一个东西记录类的类名,成员等信息。这些信息是和类相关的,而不是与具体实例对象相关的问题,那么你应该已经想到了,静态变量最适合干这件事情,我们可以给每个类定义一个静态成员用于存储这些反射信息,可以通过定义一些宏,用于初始化这些信息。然后我们将所有类的反射信息静态成员集中注册到某一个反射管理模块,这样就是一个反射系统的雏形了。
Qt的moc实现采用了另外一种方式,无需手动定义反射信息,而是通过文件扫描的方式自动读取源码文件,提取类的相关信息,压缩到一个字符串信息之中,这一过程完全由moc系统在后台给你加戏,虽然厚重但功能强大。
库和框架,百家之长
- GUI
- 图形引擎
- 构建:
- 标准库
- Boost库
- 日志
- Crash Dump
- Tracy
- 内存检测
- 单元测试
……等等等
五、从程序生命周期来看
纵观程序的生命周期,我们可以大致将其分为四个阶段: 编码期,预处理期,编译期,运行期。程序员大部分的工作可能是编码和运行期的Debug。
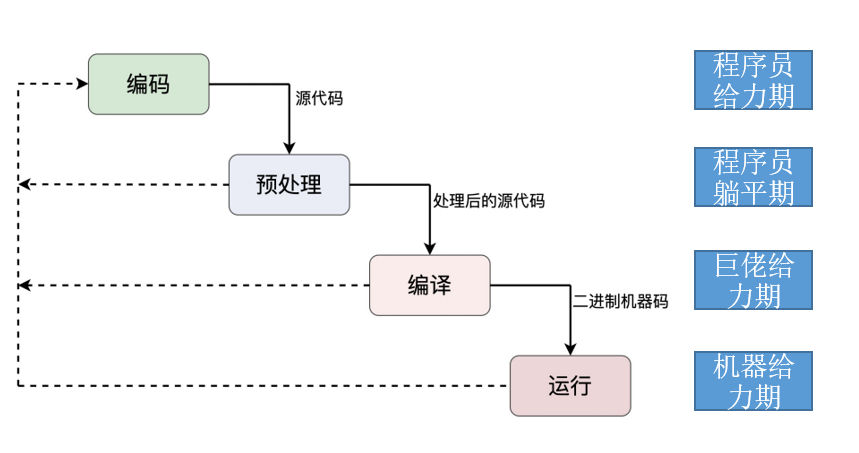
编码阶段
代码规范
C++以严苛的规范而闻名,一般公司和团队都会制定自己的代码规范,也有一些经典的公开的代码规范,比如Google C++ Style,代码规范主要涵盖如下:
- 命名规范
- 注释规范
- 代码风格,Format
- 语言特性限制等
编写高质量代码
- 可维护性
- 可读性
- 可扩展性
- 灵活性
- 简洁性(简单、复杂)
- 可 复用性
- 可测试性
C++代码魔鬼细节众多,C++程序员写代码的时候注定背负荆棘前行,我觉得最难的是知道什么是好代码,什么是Bad smell的代码,这需要经验的积累。
如何设计一个类的check list
编写一个C++类分为两个方面,一是对业务模型数据模型的抽象,这个决定了你的类是什么样的。二是类的具体实现,这个是技术层次的提现。类可以千变万化,但是类的代码该怎么写却有一些一般性的规则。
- 类的继承体系
- 方法和成员
- 对象的初始化
- big three/five,构造函数 ,拷贝构造函数、赋值运算符,移动构造函数、移动赋值运算符,析构函数,委托构造函数
- public / protected / private
- 传值和传引用以及传指针
- const语义,const 成员,const形参
- 智能指针作为类的成员
- 模板类 、 模板函数
- 接口和实现分离
- 标准库使用
- 异常处理
- 线程安全及可重入
预处理阶段
头文件的引入
同过#include引入头文件,就是简单粗暴的将头文件的内容包含进来。
宏替换
预处理阶段另一主要工作是完成宏替换,合理使用宏,可以简化很多重复代码,玩出很多花活
- #include guard
- #ifndef —XX_HH_
- #define _XX-HH_
- ... //头文件
- #endif //_XX_H__
- 定义命名空间
- 条件编译

- 源文件信息宏 FILE LINE
编译阶段
一个简单的hello world程序的编译一般要经历如下的几个过程,编译完后的目标一般可分为Application和Library

Application
Application是可以直接运行的exe文件,以main函数作为入口函数,但是在main函数运行前后程序还干了不少活。在面函数运行之前,会完成全局对象和静态对象的初始化,运行时库的初始化工作。main() 函数执行之后,程序会析构全局对象和静态对象,并清理运行时库。
Library
Library一般是提供给被人调用的库文件,包括静态链接库和动态链接库
- 静态库: 在编译时被链接到目标程序中,链接器将库的代码和数据复制到目标程序中,生成一个独立的可执行文件。
- 动态库:作为单独的模块,提供给其他模块共享调用,程序有需要时才会链接,可以在运行时动态加载,一个进程内同一dll只需要加载一次,并通过引用计数进行管理。
运行阶段
动态链接库的加载
隐式加载
隐式加载又叫载入时加载,指在主程序载入内存时搜索DLL,并将DLL载入内存。隐式加载也会有静态链接库的问题,如果程序稍大,加载时间就会过长,用户不能接受。隐式加载需要在编译阶段知道库的lib文件和.h头文件,需要通过_declspec(dllimport),_declspec(dllexport)告诉编译器其为其他dll的符号。
显式加载
显式加载又叫运行时加载,指主程序在运行过程中需要DLL中的函数时再加载。显式加载是将较大的程序分开加载的,程序运行时只需要将主程序载入内存,软件打开速度快,用户体验好。在显式链接中,程序员在代码中明确指定要加载的共享库,并在运行时通过编程接口(通常是操作系统提供的一组函数)进行加载和链接。显式加载一般使用操作系统提供的加载函数LoadLibrary,GetProcAddress(Linux/Unix 中的 dlopen,dlsym)加载共享库,并获取共享库中的符号(函数或变量)的地址。显式链接提供了更大的灵活性,因为程序员可以在运行时动态地选择加载哪些库,以及在何时加载它们,这使得模块的热插拔成为可能。
Debug
- GDB,Visual Studio Debugger等调试工具的使用
- 输出日志信息
- 单步断点调试
Profile工具
- 内存分析工具,内存泄漏检测
- cpu性能分析,性能瓶颈
六、从软件设计来看
软件为什么需要设计,能跑不就行了吗? 当然不行,如果你跑了,别人看着你写的一对屎山代码怎么办?
软件设计的目的是抵御变化。如果一个软件上了规模,需要长期开发,拓展,维护那么必须有着良好的架构和设计,本章我们就从从软件设计的一些基本原则来谈一谈C++软件设计。
抽象和接口
面向抽象编程,面向接口编程一直是软件开发的核心思想。接口的威力要在几千年年前的活字印刷术上就得到了深刻的体现: 印刷板定义接口规范,只要活字模型遵守这些规范就能组装到印刷版上,印刷版不必与具体的字模耦合在一起,这样字模可以轻松的组合,创造无限可能。
- 可维护:修改的话只需要修改某一个字;
- 可复用:别的字可以重新拿来用;
- 可扩展:如果要加字,只需要刻新字;
- 灵活性好:横排竖排都可以。
面向对象编程过程中,通过抽象类和纯虚接口将程序的耦合度降低,使程序更加的灵活,容易修改,并且易于复用。在软件的发展过程中,前任已经给我们总结了丰富的经验,留下了宝贵的智慧,这些就是设计原则和设计模式。
设计原则
面向对象编程中的五个设计原则,通常称为 SOLID 原则,是由Robert C. Martin等人提出的一组设计原则,旨在帮助开发者创建可维护、灵活和可扩展的软件。这五个原则分别是
单一职责原则(Single Responsibility Principle - SRP)
- 一个类应该只有一个引起变化的原因,即一个类应该只有一个职责。
- 这意味着一个类应该只负责一个相关的功能或任务,避免一个类承担过多的责任,以提高类的内聚性和可维护性。
开闭原则(Open/Closed Principle - OCP)
- 软件实体(类、模块、函数等)应该对扩展开放,对修改关闭。
- 这意味着在不修改现有代码的情况下,通过添加新代码来扩展系统的功能。这可以通过使用抽象类、接口和设计模式来实现。
里氏替换原则(Liskov Substitution Principle - LSP)
- 所有派生类(子类)必须能够替换其基类(父类)而不影响程序的正确性。
- 这强调了继承关系的正确性,即子类应该保持基类的行为,而不引入新的行为。
接口隔离原则(Interface Segregation Principle - ISP)
- 不应该强迫一个类实现它用不到的接口。
- 接口应该是客户端需要的最小接口集,避免一个类依赖于它不需要的接口,提高接口的可维护性。
依赖反转原则(Dependency Inversion Principle - DIP)
- 高层模块不应该依赖于低层模块,二者都应该依赖于抽象。抽象不应该依赖于细节,细节应该依赖于抽象。
- 这意味着应该通过接口或抽象类来定义高层模块和低层模块之间的关系,而不是通过具体实现。
我觉得依赖反转是这些原则里面最重要的一条,他能从根本上指导你如何避免模块之间的耦合。依赖反转原则里的依赖抽象而不是以来细节比较好理解,那么反转又是什么意思,谁依赖谁,又如何反转,我们可以通过如下的一个例子来说明一下DIP原则
✍️我设计了一个大House ,准备使用苹果的智能家居系统的,配备全套的智能家电。可是等到我真的装修的时候,发现我预算不足,只能配备小米的智能家居系统,于是我不得不连夜更改了House的设计,将所有用到苹果智能家居系统的地方全部换成了小米系统,后来,A股发生了一些不愉快的事情,你应该也知道,我连小米智能家居系统也买不起了,我不得不去淘宝上去买一些家具,于是我又不得不去更改我的大House的设计。这里你应该已经敏锐的察觉到问题所在,因为顶层依赖了底层的具体实现细节。DIP原则教我们怎么做,首先设计一个大house ,给大House设计了一个抽象的家居系统,并定义了家居系统的规格,价格等接口协议,现在只要我们实际的家居系统能符合House定下的规范,就能安装到House,而不用重新设计House以适配实际家居系统。高层模块的House不依赖底层实际的家居系统,而是依赖抽象的家居系统,底层的实际家居系统,不依赖高层,而是依赖高层定义的抽象协议接口。原先的依赖关系,由高层依赖底层反转到底层依赖高层的抽象协议。
设计模式
设计模式是经过实践验证的,能为特定上下文中某些类型的问题提供经验和指导的方法或套路,在软件开发中,合理利用设计模式可以方便的创建可重用、可维护和可扩展的代码,对于一些低质量的代码,我们也可以考虑用设计模式进行重构。软件设计的一些基本原则和设计模式其实是脱离了既定的编程语言,但在不同的编程语言里可能或有些许差异的表现。就C++而言,软件设计其实是要解决对象的创建以及对象之间的协作的问题。



通过画出不同设计模式实现的UML类图,不难发现不同的设计模式中,一个最大的特点就是一个类持有另一个类的抽象基类指针,两个关联的类之间,通过虚接口进行交互,在运行时,由多态机制将行为派发到具体的实现上,从而避免了实现细节上的耦合。
对于一些设计原则和设计模式的的概念你可能不一定能够准确的说出,但是实际开发中你可能已经在不经意间使用各种设计原则和设计模式,如果你能不是的回顾一下这些概念,可能更容易的正确的使用这些设计模式。

SDK,API的设计
设计模式更多关注对象之间的关系,再往上来看,模块之间,软件之间也需要交互协作,这个时候就需要考虑软件对外暴露的API接口设计和SDK工具。
API(Application Programming Interface)是一组定义、规范和工具,用于构建应用程序和软件组件之间的交互,API定义了可在软件中使用的功能、协议和数据格式。
- API通常包括函数、类、协议、数据结构等。API用于描述软件组件之间的接口,使得它们能够有效地通信和互操作。
- 开发者使用API来访问和利用已有软件或服务的功能,而无需了解其内部实现。API提供了一种标准的方式来进行集成和交互。
对于平台软件开发或者需要提供用户二次开发能力的软件,一般需要提供相关SDK(Software Development Kit),SDK是一个开发工具包,通常包含一组工具、库、文档和示例代码,旨在帮助开发者构建软件应用程序。
七、从产品视角来看
C++主要应用领域
前面几章都是从技术的角度来看C++,任何技术都是服务于产品开发,技术是手段,产品才是目的,现在我们站在产品的视角来看一看C++。C++是全能型语言,但是对于不同的领域却有各自更合适的语言,下面是一些著名的用到 C++ 的场合:
- 大型桌面应用程序(如 Adobe Photoshop、Google Chrome 和 Microsoft Office)
- 大型网站后台(如 Google 的搜索引擎)
- 游戏(如 StarCraft)和游戏引擎(如 Unreal 和 Unity)
- 编译器(如 LLVM/Clang 和 GCC)
- 解释器(如 Java 虚拟机和 V8 JavaScript 引擎)
- 实时控制(如战斗机的飞行控制和火星车的自动驾驶系统)
- 视觉和智能引擎(如 OpenCV、TensorFlow)
- 数据库(如 Microsoft SQL Server、MySQL 和 MongoDB)
- 工业软件如CAD,CAE软件
C++在这些邻域仍然占据着统治地位,得益于C++在如下几个方面的优势
抽象能力:意味着较高的开发效率,同时,更重要的是,不会因抽象而降低性能。
性能:这不用多说了,就是快并且占用资源少。
功耗:这是近年来我们越来越关注的问题,跟性能直接相关,性能好了功耗自然就低。
产品开发流程中的技术栈
C++ 软件开发的全流程中,涉及到多个阶段,不同阶段的技术需求也不一样,纵观软件整个生命周期,编码开发阶段其实只占了很少一部分,在不同的阶段需要运用不同的技术和工具,所以单单从掌握语言层面的技术是不够的,下面这些可能更加面向生产力的技术和工具。
- UML需求分析和设计工具
- 项目构建工具,如Cmake,IDE
- 静态检测,代码质量检测
- 单元测试,
- 自动化测试
- 版本控制
- 日志系统
- 持续集成
没有人能掌握所有的技术栈,单兵作战的时代已经不复存在,也许在技术够用的时候,就应该抽身出来,多看看技术外的东西。
总结
从最底层的冯洛伊曼体系到上层的计算机结构大厦,到各行各业广泛的软件产品,知识是呈现出倒金字塔体系的。对于不同层次的知识,我们也需要根据自身方向和精力做出取舍,我觉得也可以用8/2定律
- 底层原理: 了解宏观 , 理解原理,掌握基础20%
- 基础组件: 常用知识,20% - 80%之间
- 上层工具: 工作必备,熟练掌握80%
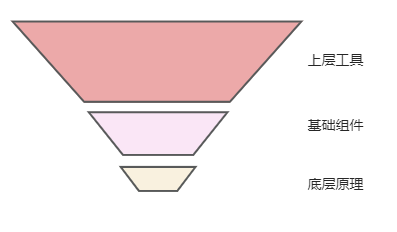
作为一名程序员,对技术要了然于心,运用自如,深入浅出,入心入理。也要学会不断提升认知的视角,从代码视角到技术视角 ,从技术视角到软件视角 ,从软件视角到产品视角,从产品视角到行业视角,从行业视角到生态视角。最后以一句话总结:
学习编程如果有什么箴言,那一定是:“纸上得来终觉浅,绝知此事要躬行”。


