
- 1【云开发笔记NO.22】运用云原生产品打造技术中台
- 2【STM32嵌入式系统设计与开发】——14PWM(pwm脉宽输入应用)
- 3ZED使用指南(八)Depth Sensing_zed算法的作用
- 4iOS 国际化异常:read failed: Couldn‘t parse property list because the input data was in an invalid format_validation failed: couldn't parse property list be
- 5激光雷达考试基础知识_根据测距原理,扫描仪分为哪几类、各自的特点及-|||-应用领域。
- 6深入理解GO语言——GC垃圾回收二
- 7Axure 8 - 中继器实战篇_axure中继器的作用,可以做什么
- 8完整代码||算术表达式求解(C++)_c++算数表达式求值代码
- 9web3.js简介与入门
- 10机器学习——模型融合:平均法
基于MobileNet(v1-v3)全系列不同参数量级模型开发构建果树图像病虫害识别分析系统,实验量化对比不同模型性能
赞
踩
最近正好项目中在做一些识别相关的内容,我也陆陆续续写了一些实验性质的博文用于对自己使用过的模型进行真实数据的评测对比分析,感兴趣的话可以自行移步阅读即可:
《移动端轻量级模型开发谁更胜一筹,efficientnet、mobilenetv2、mobilenetv3、ghostnet、mnasnet、shufflenetv2驾驶危险行为识别模型对比开发测试》
《图像识别模型哪家强?19款经典CNN模型实践出真知【以眼疾识别数据为基准,对比MobileNet系列/EfficientNet系列/VGG系列/ResNet系列/i、xception系列】》
《基于轻量级卷积神经网络模型实践Fruits360果蔬识别——自主构建CNN模型、轻量化改造设计lenet、alexnet、vgg16、vgg19和mobilenet共六种CNN模型实验对比分析》
《基于轻量级模型GHoshNet开发构建眼球眼疾识别分析系统,构建全方位多层次参数对比分析实验》
在前文中草药数据集的建模实践中我们已经有过相似的实践了,感兴趣的话可以自行移步阅读即可:
《基于MobileNet(v1-v3)全系列不同参数量级模型开发构建中草药图像识别分析系统,实验量化对比不同模型性能》
本文的主要目的是想要以基准数据集【果树病虫害图像数据集】为例,开发构建MobileNetNet全系列不同参数量级的模型,之后在同样的测试数据集上进行评测对比分析。
数据集中共包含5种类别数据,清单如下:
- AlternariaBoltch
- BrownSpot
- GreySpot
- Mosaic
- Rust
简单看下部分数据实例:




MobileNet模型是一种轻量级的卷积神经网络模型,主要用于在移动设备和嵌入式设备上进行实时图像分类和目标检测。发展迭代至今已经演变出来了v1-v3三个大版本,其中v3版本包含了large和small两款不同参数量级的模型。
MobileNetV1:
MobileNetV1利用分组卷积降低网络的计算量,并将分组卷积应用到极致,即网络的分组数与网络的channel数量相等,使网络的计算量减到最低。但这样会导致channel之间的交互缺失,所以作者又使用了point-wise conv,即使用1x1的卷积进行channel之间的融合。同时,MobileNetV1还采用了直筒结构。
MobileNetV2:
MobileNetV2引入了bottleneck结构,并将bottleneck结构变成了纺锤型。与ResNet不同,MobileNetV2先放大特征图的尺寸,再缩小尺寸,以增加感受野。同时,MobileNetV2去掉了Residual Block最后的ReLU激活函数。这些改进使得MobileNetV2在保持高性能的同时进一步降低了模型大小和计算量。
MobileNetV3:
MobileNetV3是MobileNet系列的最新版本,它采用了AutoML的方法为给定的问题找到最佳的神经网络架构。MobileNetV3提出了两种模型大小的配置:Large和Small。
MobileNetV3-Large:
MobileNetV3-Large在构建模型时采用了多个创新性的技术。首先,它综合了MobileNetV1和MobileNetV2的优点,包括分组卷积、1x1的卷积进行channel之间的融合、以及纺锤型的bottleneck结构。其次,MobileNetV3-Large引入了特有的bneck结构,该结构综合了以下四个特点:
MobileNetV2的具有线性瓶颈的逆残差结构(the inverted residual with linear bottleneck)。即先利用1x1卷积进行升维度,再进行下面的操作,并具有残差边。
MobileNetV1的深度可分离卷积(depthwise separable convolutions)。在输入1x1卷积进行升维度后,进行3x3深度可分离卷积。
轻量级的注意力模型。这个注意力机制的作用方式是调整每个通道的权重。
利用h-swish代替swish函数。在结构中使用了h-swish激活函数,代替swish函数,减少运算量,提高性能。
此外,MobileNetV3-Large还使用了线性瓶颈结构来进一步减少模型的参数数量和计算量。线性瓶颈结构是一种将输入通道数和输出通道数都进行压缩的结构,它可以将模型的参数数量和计算量降低到最小。
MobileNetV3-Small:
相对于MobileNetV3-Large,MobileNetV3-Small更注重模型的轻量级和计算效率。它采用了深度可分离卷积来减少模型的参数数量和计算量,从而实现在低功耗设备上的高效运算。同时,MobileNetV3-Small还采用了线性瓶颈结构和残差连接等技术来提高模型的分类性能和训练稳定性。
训练集占比75%,测试集占比25%,所有模型按照相同的数据集配比进行实验对比分析,计算准确率、精确率、召回率和F1值四种指标。结果详情如下所示:
- {
- "mobilenetv1": {
- "accuracy": 0.9512459371614301,
- "precision": 0.9512331254424208,
- "recall": 0.9514884485305615,
- "f1": 0.9513002786442215
- },
- "mobilenetv2": {
- "accuracy": 0.9501625135427952,
- "precision": 0.950015636253364,
- "recall": 0.950273617930165,
- "f1": 0.9500211293141753
- },
- "mobilenetv3l": {
- "accuracy": 0.9420368364030336,
- "precision": 0.9418049945974225,
- "recall": 0.9425591124073058,
- "f1": 0.9418471067672947
- },
- "mobilenetv3s": {
- "accuracy": 0.9328277356446371,
- "precision": 0.9332787181277038,
- "recall": 0.9320153835377836,
- "f1": 0.9320941935987763
- }
- }
简单介绍下上述使用的四种指标:
准确率(Accuracy):即分类器正确分类的样本数占总样本数的比例,通常用于评估分类模型的整体预测能力。计算公式为:准确率 = (TP + TN) / (TP + TN + FP + FN),其中 TP 表示真正例(分类器将正例正确分类的样本数)、TN 表示真负例(分类器将负例正确分类的样本数)、FP 表示假正例(分类器将负例错误分类为正例的样本数)、FN 表示假负例(分类器将正例错误分类为负例的样本数)。
精确率(Precision):即分类器预测为正例中实际为正例的样本数占预测为正例的样本数的比例。精确率评估分类器在预测为正例时的准确程度,可以避免过多地预测假正例。计算公式为:精确率 = TP / (TP + FP)。
召回率(Recall):即分类器正确预测为正例的样本数占实际为正例的样本数的比例。召回率评估分类器在实际为正例时的识别能力,可以避免漏掉过多的真正例。计算公式为:召回率 = TP / (TP + FN)。
F1 值(F1-score):综合考虑精确率和召回率,是精确率和召回率的调和平均数。F1 值在评估分类器综合表现时很有用,因为它同时关注了分类器的预测准确性和识别能力。计算公式为:F1 值 = 2 * (精确率 * 召回率) / (精确率 + 召回率)。 F1 值的取值范围在 0 到 1 之间,值越大表示分类器的综合表现越好。
为了能够直观清晰地对比不同模型的评测结果,这里对其进行可视化分析,如下所示:
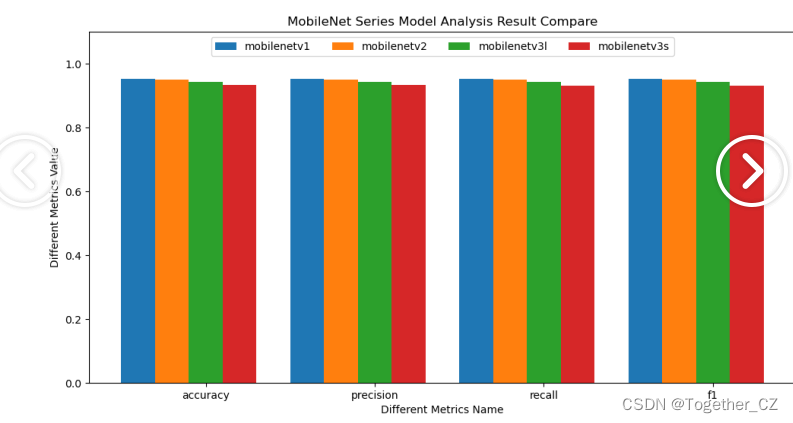
从全系列模型对比效果来看:MobileNetv1取得了最优的效果,MobileNetv2与v1十分相近,MobileNetv3l次之,MobileNetv3s最低,感兴趣的话也都可以自行动手尝试下。

