
- 1SpringBoot整合ES高级查询_springboot整合es常用查询
- 2【Git】在 Linux 系统中使用 apt 包管理器来安装 Git LFS_git lfs install
- 3C++串口编程_c++串口库
- 4从软件工程师到IT猎头:说说跳槽那点事_软件开发转通信技术工程
- 5那个时候我不小心建立了一个间谍应用
- 6safari请求usdz文件不能看到webAR的效果_usdz模型浏览器不支持
- 7Python 内置函数详解_python内置函数详解
- 8【异常解决】Java运行时发生 java.lang.NoClassDefFoundError: Could not initialize class com.iot.alarm.ProcAlar
- 9USB EHCI Driver_ehci_poll_ass
- 10MySQL-sql语句-DCL语句_mysql中常用的sql的dcl语句
【python】关于import相关知识总结_python import 绝对路径
赞
踩
1. 在import中的相对路径和绝对路径
- # py文件:所有以.py结尾的文件
- # py脚本:不被import,能直接运行的py文件,一般会import别的py文件
- # python包:被import使用,一般不能直接运行的py文件,一般只包含函数/类,调试时需要调用if __main__语句
-
-
- # 搜索路径
- # 指python以 绝对路径 形式导入包时的所有可能路径前缀,整个程序不管在哪个py文件里 搜索路径 是相同的
- # 默认 搜索路径 按顺序包括:程序入口py脚本的当前路径、python包安装路径,当存在重名时,注意顺序问题
- # 程序入口py脚本的当前路径只有一个,指整个程序入口的唯一py脚本的当前路径,如下是 搜索路径 查看方式
- import sys
- print(sys.path) # 整个程序不管import多少个python包,其程序入口只有一个py脚本
- # sys.path.append("/xx/xx/xx") # 增加 搜索路径 的方式
-
-
- # 绝对路径
- # 是以 搜索路径 为前缀,拼接下面xxx后形成完整的python包调用路径
- import xxx # xxx可以是文件夹/py包文件
- from xxx import abc # xxx可以是文件夹/py包文件,abc可以是文件夹/py包文件/变量/函数/类
-
- # 相对路径
- # 是以 当前执行import语句所在py文件的路径 为参考,拼接下面的.xxx/..xxx后形成完整的python包调用路径
- # 但是需要注意,相对路径 只能在python包中使用,不能在程序入口py脚本里使用,否则会报错
- # 当单独调试python包时,调用if __main__语句,相对路径同样报错,原因是此时py文件变py脚本不再是python包
- from .xxx import xxx # 当前路径
- from ..xxx import xxx # 当前路径的上一级路径

2. __init__.py脚本在import中作用
在X文件夹下的__init__.py文件的作用是,让python解析器知晓X模块下包含哪些子模块,以便在非import语句中使用“.”运算符时,能够访问到X模块下的子模块,当然相应的在__init__.py文件中需要有相应正确的python语句,否则也无效。如果在X文件夹中不存在__init__.py文件,那不能在非import语句中使用“.”运算符进行子模块的访问,只能在import语句中直接导入py文件中的类/函数/变量,不能导入模块。例如:import xxx.yyy.a和from xxx.yyy import a,如果yyy是py文件,a是该文件中的类/函数/变量,在没有__init__.py文件的情况下是可以成功使用的;但如果a是py文件,且yyy文件夹下没有正确的__init__.py文件,那就会报错,原因是python解析器不知道yyy文件夹下有哪些子模块。
2.1 在 __init__.py中import语句
测试目录结构和测试代码如下:
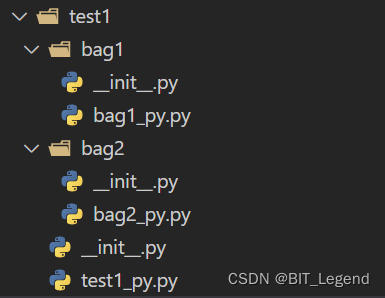
- ##################################################
- # test1_py.py
- print("this is test1")
- test1_v = 0
-
- # __init__.py test1
- print("this is test1 __init__")
- from . import bag1
- from . import bag2
- from . import test1
-
- from .bag1 import bag1_py
-
- ##################################################
- # bag1_py.py
- print("this is bag1")
- bag1_v = 1
-
- # __init__.py bag1
- print("this is bag1 __init__")
- from . import bag1_py
-
- ##################################################
- # bag2_py.py
- print("this is bag2")
- bag2_v = 2
-
- # __init__.py bag2
- print("this is bag2 __init__")
测试结果如下:
- # No.1
- print("#################################################### 1")
- from test1.test1_py import test1_v as a
- from test1.bag1.bag1_py import bag1_v as b
- from test1.bag2.bag2_py import bag2_v as c
- print(a+b+c)
-
- # result:
- #################################################### 1
- this is test1 __init__
- this is bag1 __init__
- this is bag1
- this is bag2 __init__
- this is test1
- this is bag2
- 3
-
- # 这说明:
- # 1. 所有import x语句或from x import x语句所经过的路径下的__init__.py文件都会被执行一遍
- # 2. 所有被导入类/函数/变量所在的python包会被完整的执行一遍
- -----------------------------------------------------------------------------------------
-
- # No.2
- print("#################################################### 2")
- from test1 import test1_py
- from test1.bag1 import bag1_py
- from test1.bag2 import bag2_py
- print(test1_py.test1_v + bag1_py.bag1_v + bag2_py.bag2_v)
-
- # result:
- #################################################### 2
- this is test1 __init__
- this is bag1 __init__
- this is bag1
- this is bag2 __init__
- this is test1
- this is bag2
- 3
-
- # 这说明:
- # 1. from x import x语句最后的import部分可以是类/函数/变量或者py文件
- -----------------------------------------------------------------------------------------
-
- # No.3
- print("#################################################### 3")
- from test1 import test1_py
- from test1 import bag1
- from test1 import bag2
- print(test1_py.test1_v + bag1.bag1_py.bag1_v)
- print(test1_py.test1_v + bag1.bag1_py.bag1_v + bag2.bag2_py.bag2_v) # 运行报错
-
- # result:
- #################################################### 3
- this is test1 __init__
- this is bag1 __init__
- this is bag1
- this is bag2 __init__
- this is test1
- 1
- Traceback (most recent call last):
- File "main.py", line 21, in <module>
- print(test1_py.test1_v + bag1.bag1_py.bag1_v + bag2.bag2_py.bag2_v)
- AttributeError: module 'test1.bag2' has no attribute 'bag2_py'
-
- # 这说明:
- # 1. 最后一句报错的原因是在bag2文件夹下的__init__.py文件中,没有写from . import bag2_py,
- # 所以python解析器无法获知在bag2这一级之下包含哪些包,进而无法完成访问操作,所以在某级文件夹下
- # 没有__init__.py文件或者文件中没有通过import语句写清楚该文件夹下所包含的子文件或子包时,
- # python解析器无法通过.操作获取子文件或子包下的类/函数/变量,这就是__init__.py文件的第一个作用
- -----------------------------------------------------------------------------------------
-
- # No.4
- print("#################################################### 4")
- import test1
- print(test1.test1_py.test1_v + test1.bag1_py.bag1_v) # 注意跨级访问
- print(test1.test1_py.test1_v + test1.bag1.bag1_py.bag1_v)
- print(test1.test1_py.test1_v + test1.bag1.bag1_py.bag1_v + test1.bag2_py.bag2.bag2_v) # 运行报错
-
- # result:
- #################################################### 4
- this is test1 __init__
- this is bag1 __init__
- this is bag1
- this is bag2 __init__
- this is test1
- 1
- 1
- Traceback (most recent call last):
- File "main.py", line 28, in <module>
- print(test1.test1_py.test1_v + test1.bag1.bag1_py.bag1_v + test1.bag2_py.bag2.bag2_v)
- AttributeError: module 'test1' has no attribute 'bag2_py'
-
- # 这说明:
- # 1. 第一个print语句存在跨级访问,访问bag1_py时跨过了bag1,原因是在test1文件夹下的__init__.py中
- # 有from .bag1 import bag1_py语句,相当于告诉了python解析器在test1下一级存在bag1_py子模块
- # 当然这也不会影响原本的非跨级访问
- # 2. 最后一个print语句报错的原因同实验3,在bag2文件夹下的__init__.py文件中,没有写from . import bag2_py
- -----------------------------------------------------------------------------------------
2.2 在 __init__.py中__all__变量
测试目录结构和测试代码如下:

- ##################################################
- # test2_py.py
- print("this is test2")
- test2_v = 0
-
- # __init__.py test2
- print("this is test2 __init__")
- __all__ = ["test2_py", "bag1" , "bag2"]
-
- ##################################################
- # bag1_py.py
- print("this is bag1")
- bag1_v = 1
-
- # __init__.py bag1
- print("this is bag1 __init__")
- __all__ = ["bag1_py"]
-
- ##################################################
- # bag2_py.py
- print("this is bag2")
- bag2_v = 2
-
- # __init__.py bag2
- print("this is bag2 __init__")
测试结果如下:
- # No.1
- print("#################################################### 1")
- from test2 import *
- print(test2_py.test2_v)
- print(bag1.bag1_py.bag1_v) # 运行报错
- print(bag2.bag2_py.bag2_v) # 运行报错
-
- # result:
- #################################################### 1
- this is test2 __init__
- this is test2
- this is bag1 __init__
- this is bag2 __init__
- 0
- Traceback (most recent call last):
- File "main.py", line 34, in <module>
- print(bag1.bag1_py.bag1_v)
- AttributeError: module 'test2.bag1' has no attribute 'bag1_py'
-
- # 这说明:
- # 1. 在__init__.py文件中__all__变量的作用是告诉python解析器,在当前文件夹下所包含的python包,但是
- # 其仅仅在from import * 语句下才有效,这也解释了为何后两个print语句运行报错,原因是在bag1和bag2文件夹
- # 下的__init__.py文件中,仅仅包含__all__变量,不包含import的内容
- -----------------------------------------------------------------------------------------
-
- # No.2
- print("#################################################### 2")
- from test2.bag1 import *
- print(bag1_py.bag1_v)
- from test2.bag2 import *
- print(bag2_py.bag2_v) # 运行报错
-
- # result:
- #################################################### 2
- this is test2 __init__
- this is bag1 __init__
- this is bag1
- 1
- this is bag2 __init__
- Traceback (most recent call last):
- File "main.py", line 42, in <module>
- print(bag2_py.bag2_v)
- NameError: name 'bag2_py' is not defined
-
- # 这说明:
- # 1. 在整个程序中,同一个__init__.py文件python包不管被调用多少次,都仅仅运行一次
- # 2. 运行报错原因同实验1
- -----------------------------------------------------------------------------------------
参考连接:Python 中的 __init__.py 和__all__ 详解 - 知乎
3. 模块导入与函数调用的区别
测试目录结构和测试代码如下:
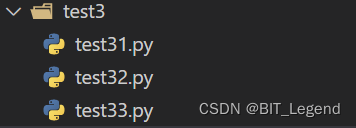
- ##################################################
- # test31.py
- a = [0]
-
- ##################################################
- # test32.py
- from .test31 import a
- a.append(1)
-
- ##################################################
- # test33.py
- from .test31 import a
- a.append(2)
测试结果如下:
- # No.1
- print("#################################################### 1")
- import test3.test31
- print(test3.test31.a)
- from test3.test32 import a
- print(a, test3.test31.a)
- from test3.test33 import a
- print(a, test3.test31.a)
-
- result:
- #################################################### 1
- [0]
- [0, 1] [0, 1]
- [0, 1, 2] [0, 1, 2]
-
- # 这说明:
- # 1. 在import xxx语句被执行时,被导入模块所在的py文件会被完整执行一遍,其生成的所有类/函数/变量会
- # 存在xxx这个局部范围内,外部无法直接访问,且这个局部范围内的所有数据在程序运行结束前并不会自动消失
- # 访问这个局部范围内数据的方式有两种,第一是xxx.name的方式,第二是from xxx import name,所以
- # 在python编程中,不要随便引入无用的python包或者在引入python包时引入了过大的范围,否则会浪费内存
- # 2. 在程序的整个运算过程中,每个被import的python包仅仅会被执行一次
- -----------------------------------------------------------------------------------------
-
- # No.2
- print("#################################################### 2")
- import test3.test32 # 其首先调用test31生成a,然后调用test32修改a,整个过程都是隐式的,用户看不到a
- from test3.test33 import a
- print(a)
-
- result:
- #################################################### 2
- [0, 1, 2]
-
- # 这说明:
- # 1. 在import xxx语句被执行时,被导入模块所在的py文件会被完整执行一遍,其生成的所有类/函数/变量会
- # 存在xxx这个局部范围内,且这些类/函数/变量允许被隐式调用,并不强迫显式调用
通过上面的实验可以发现模块导入与函数调用的区别非常大。
函数调用时,函数体内的程序会被执行一遍,但函数调用结束后,内存中仅仅会保留return的数据,其它数据均会被自动删除,且函数再次被调用时,函数体内的程序会重新执行一遍。
模块导入时,模块内的程序会被执行一遍,且不要求显式执行,但模块导入完成后,内存中的抽象局部范围内会完整的保存所有数据,直至程序运行结束,且模块再次被导入时,模块内的程序不会再被执行。
4. mmcv中的模块导入
mmcv是建立在torch基础上的深度学习库,其封装性和模块化更好,但是相应带来的问题是调试不方便。mmcv的基础是注册机制,注册机制将类定义和类调用进行了隔离,所有类事先定义好并写入一个注册器字典中,在类被调用时,直接从字典中寻找相应的类然后使用。所以当调用某个类时,如果想要查看类的定义,以及类是在何时被写入注册器字典的,这个都变得非常麻烦。如果想要查看类的定义,需要去安装路径或当前路径中一层层翻找。最麻烦的是寻找该类是在何时被写入注册器字典的,这个就牵扯到前面所讲的“相对路径与绝对路径”和“import相关知识”。具体案例如下所示。
目录结构和相关代码如下:(mmdet3d下有datasets,datasets下有pipelines,pipelines下有loading.py)
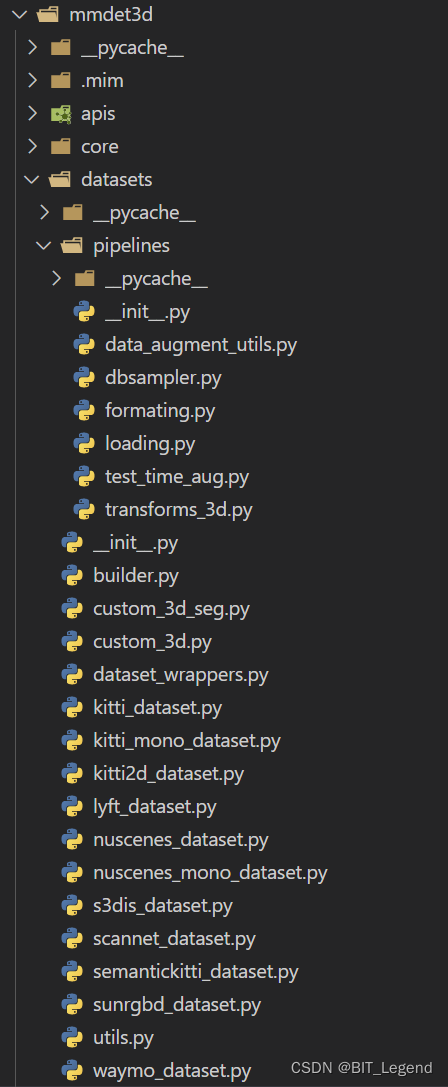
- ##################################################
- # __init__.py datasets
-
- # Copyright (c) OpenMMLab. All rights reserved.
- from mmdet.datasets.builder import build_dataloader
- from .builder import DATASETS, build_dataset
- from .custom_3d import Custom3DDataset
- from .custom_3d_seg import Custom3DSegDataset
- from .kitti_dataset import KittiDataset
- from .kitti_mono_dataset import KittiMonoDataset
- from .lyft_dataset import LyftDataset
- from .nuscenes_dataset import NuScenesDataset
- from .nuscenes_mono_dataset import NuScenesMonoDataset
- # yapf: disable
- from .pipelines import (BackgroundPointsFilter, GlobalAlignment,
- GlobalRotScaleTrans, IndoorPatchPointSample,
- IndoorPointSample, LoadAnnotations3D,
- LoadPointsFromFile, LoadPointsFromMultiSweeps,
- NormalizePointsColor, ObjectNameFilter, ObjectNoise,
- ObjectRangeFilter, ObjectSample, PointSample,
- PointShuffle, PointsRangeFilter, RandomDropPointsColor,
- RandomFlip3D, RandomJitterPoints,
- VoxelBasedPointSampler)
- # yapf: enable
- from .s3dis_dataset import S3DISDataset, S3DISSegDataset
- from .scannet_dataset import ScanNetDataset, ScanNetSegDataset
- from .semantickitti_dataset import SemanticKITTIDataset
- from .sunrgbd_dataset import SUNRGBDDataset
- from .utils import get_loading_pipeline
- from .waymo_dataset import WaymoDataset
-
- __all__ = [
- 'KittiDataset', 'KittiMonoDataset', 'build_dataloader', 'DATASETS',
- 'build_dataset', 'NuScenesDataset', 'NuScenesMonoDataset', 'LyftDataset',
- 'ObjectSample', 'RandomFlip3D', 'ObjectNoise', 'GlobalRotScaleTrans',
- 'PointShuffle', 'ObjectRangeFilter', 'PointsRangeFilter',
- 'LoadPointsFromFile', 'S3DISSegDataset', 'S3DISDataset',
- 'NormalizePointsColor', 'IndoorPatchPointSample', 'IndoorPointSample',
- 'PointSample', 'LoadAnnotations3D', 'GlobalAlignment', 'SUNRGBDDataset',
- 'ScanNetDataset', 'ScanNetSegDataset', 'SemanticKITTIDataset',
- 'Custom3DDataset', 'Custom3DSegDataset', 'LoadPointsFromMultiSweeps',
- 'WaymoDataset', 'BackgroundPointsFilter', 'VoxelBasedPointSampler',
- 'get_loading_pipeline', 'RandomDropPointsColor', 'RandomJitterPoints',
- 'ObjectNameFilter'
- ]
-
-
- ##################################################
- # __init__.py pipelines
-
- # Copyright (c) OpenMMLab. All rights reserved.
- from mmdet.datasets.pipelines import Compose
- from .dbsampler import DataBaseSampler
- from .formating import Collect3D, DefaultFormatBundle, DefaultFormatBundle3D
- from .loading import (LoadAnnotations3D, LoadImageFromFileMono3D,
- LoadMultiViewImageFromFiles, LoadPointsFromFile,
- LoadPointsFromMultiSweeps, NormalizePointsColor,
- PointSegClassMapping, ImageViewAugmentation, BEVDataAugmentation)
- from .test_time_aug import MultiScaleFlipAug3D
- from .transforms_3d import (BackgroundPointsFilter, GlobalAlignment,
- GlobalRotScaleTrans, IndoorPatchPointSample,
- IndoorPointSample, ObjectNameFilter, ObjectNoise,
- ObjectRangeFilter, ObjectSample, PointSample,
- PointShuffle, PointsRangeFilter,
- RandomDropPointsColor, RandomFlip3D,
- RandomJitterPoints, VoxelBasedPointSampler)
-
- __all__ = [
- 'ObjectSample', 'RandomFlip3D', 'ObjectNoise', 'GlobalRotScaleTrans',
- 'PointShuffle', 'ObjectRangeFilter', 'PointsRangeFilter', 'Collect3D',
- 'Compose', 'LoadMultiViewImageFromFiles', 'LoadPointsFromFile',
- 'DefaultFormatBundle', 'DefaultFormatBundle3D', 'DataBaseSampler',
- 'NormalizePointsColor', 'LoadAnnotations3D', 'IndoorPointSample',
- 'PointSample', 'PointSegClassMapping', 'MultiScaleFlipAug3D',
- 'LoadPointsFromMultiSweeps', 'BackgroundPointsFilter',
- 'VoxelBasedPointSampler', 'GlobalAlignment', 'IndoorPatchPointSample',
- 'LoadImageFromFileMono3D', 'ObjectNameFilter', 'RandomDropPointsColor',
- 'RandomJitterPoints', 'ImageViewAugmentation', 'BEVDataAugmentation'
- ]
-
-
- ##################################################
- # loading.py
-
- # Copyright (c) OpenMMLab. All rights reserved.
- import cv2
- import mmcv
- import numpy as np
-
- from mmdet3d.core.points import BasePoints, get_points_type
- from mmdet.datasets.builder import PIPELINES
- from mmdet.datasets.pipelines import LoadAnnotations, LoadImageFromFile
-
- @PIPELINES.register_module(force=True)
- class LoadMultiViewImagesFromFiles(object):
- """Load multi channel images from a list of separate channel files.
- Expects results['img_filename'] to be a list of filenames.
- Args:
- to_float32 (bool): Whether to convert the img to float32.
- Defaults to False.
- color_type (str): Color type of the file. Defaults to 'unchanged'.
- """
-
- def __init__(self, to_float32=False, color_type='unchanged'):
- self.to_float32 = to_float32
- self.color_type = color_type
测试结果如下:
- # No.1
- print("#################################################### 1")
- from mmdet3d.datasets.pipelines.loading import PIPELINES
- print(type(PIPELINES.module_dict))
- print(len([key for key in PIPELINES.module_dict]))
- print(PIPELINES.module_dict["LoadMultiViewImagesFromFiles"])
- print("end")
-
- result:
- #################################################### 1
- <class 'dict'>
- 67
- <class 'mmdet3d.datasets.pipelines.loading.LoadMultiViewImagesFromFiles'>
- end
-
- # 这说明:
- # 1. 在调用from mmdet3d.datasets.pipelines.loading import PIPELINES这句话时,会执行loading
- # 这个python包,相应的会执行包中的from mmdet.datasets.builder import PIPELINES,此时PIPELINES
- # 这个类对象已经定义完成并写入了很多基础类,然后执行包中的LoadMultiViewImagesFromFiles类定义,
- # 并写入PIPELINES这个类对象,所以我们可以确定LoadMultiViewImagesFromFiles这个类写入PIPELINES
- # 的时刻,但是依然无法确定PIPELINES这个类的定义时刻,以及基础类写入的时刻,事实上PIPELINES类在整个
- # 程序运行过程中会被调用多次,但仅仅第一次调用时有效,此时才会定义这个类对象,但想要确定哪一次调用
- # 才是第一次调用,这个非常困难,也没有必要知道,如果在调试程序时,发现某类对象没有,那就加上import
- # 语句进行调用就可以了,如果该类对象已经有了,那就直接使用,这正是mmcv对新手非常不友好的地方之一
- -----------------------------------------------------------------------------------------
mmdet,mmseg和mmdet3d包在通过import语句直接导入时,例如:import mmdet3d,其仅仅是检查版本号,并不解析实际有效功能的__init__.py文件,需要具体功能时,需要导入更深层次的模块,例如:import mmdet3d.datasets。mmdet3d最外层的__init__.py文件代码如下:
- # Copyright (c) OpenMMLab. All rights reserved.
- import mmcv
-
- import mmdet
- import mmseg
- from .version import __version__, short_version
-
-
- def digit_version(version_str):
- digit_version = []
- for x in version_str.split('.'):
- if x.isdigit():
- digit_version.append(int(x))
- elif x.find('rc') != -1:
- patch_version = x.split('rc')
- digit_version.append(int(patch_version[0]) - 1)
- digit_version.append(int(patch_version[1]))
- return digit_version
-
-
- mmcv_minimum_version = '1.3.8'
- mmcv_maximum_version = '1.4.0'
- mmcv_version = digit_version(mmcv.__version__)
-
-
- assert (mmcv_version >= digit_version(mmcv_minimum_version)
- and mmcv_version <= digit_version(mmcv_maximum_version)), \
- f'MMCV=={mmcv.__version__} is used but incompatible. ' \
- f'Please install mmcv>={mmcv_minimum_version}, <={mmcv_maximum_version}.'
-
- mmdet_minimum_version = '2.14.0'
- mmdet_maximum_version = '3.0.0'
- mmdet_version = digit_version(mmdet.__version__)
- assert (mmdet_version >= digit_version(mmdet_minimum_version)
- and mmdet_version <= digit_version(mmdet_maximum_version)), \
- f'MMDET=={mmdet.__version__} is used but incompatible. ' \
- f'Please install mmdet>={mmdet_minimum_version}, ' \
- f'<={mmdet_maximum_version}.'
-
- mmseg_minimum_version = '0.14.1'
- mmseg_maximum_version = '1.0.0'
- mmseg_version = digit_version(mmseg.__version__)
- assert (mmseg_version >= digit_version(mmseg_minimum_version)
- and mmseg_version <= digit_version(mmseg_maximum_version)), \
- f'MMSEG=={mmseg.__version__} is used but incompatible. ' \
- f'Please install mmseg>={mmseg_minimum_version}, ' \
- f'<={mmseg_maximum_version}.'
-
- __all__ = ['__version__', 'short_version']

