
- 1git&github自学(8):发起Pull Request_pull requests
- 22022.11.20 第9次周报
- 3esp32cam和esp32-s3烧录human_face_detect实现人脸识别_quad_psram: psram id read error: 0x00ffffff, psram
- 4PHP-人员权限管理(RBAC)_php实现权限rubc
- 5Linux sysctl 网络相关参数_fwmark_reflect
- 6《Git与Github使用笔记》分享3款Git可视化工具_github可视化管理工具
- 7YOLOv8最新改进系列:融合最新顶会提出的HCANet网络中卷积和注意力融合模块(CAFM),有效提升小目标检测性能,大幅度拉升目标检测效果!遥遥领先!
- 8hive:函数:collect_list和collect_set (行转列-多行转单行)_collect_set 分列
- 9Java初阶(类和对象 ---- > 基础概念)_java类和对象的基本概念
- 10中国大学生计算机设计大赛之小程序开发全过程_计算机设计大赛小程序开发
Hive on Spark环境搭建(解决Hive3.1.2和Spark3.0.x版本冲突)_解决执行spark.sql兼容hive3.1
赞
踩
搭建数仓必要环境的注意事项
使用Hive做元数据存储和HQL解析,Spark做实际计算。(Hive on Spark)
Hive 使用3.1.2版本,Spark 使用3.0.3版本 。
由于Hive 3.1.2 和 Spark 3.0.3不兼容,需要修改Hive中关于Spark的源码和依赖引用。
重新编译Hive
下载Hive 3.1.2源码 ,上传并解压
apache-hive-3.1.2-src.tar.gz
下载Linux版IDEA,安装到带有桌面的Linux上。(使用root操作IDEA,bin/idea.sh打开idea)
用idea打开apache-hive-3.1.2-src,首先修改pom.xml
修改pom.xml,将spark.version改为3.0.3,scala.version改为2.12.15,scala.binary.version改为2.12 和 SPARK_SCALA_VERSION改为2.12
(修改前配置一下IDEA的maven使用的settings的位置)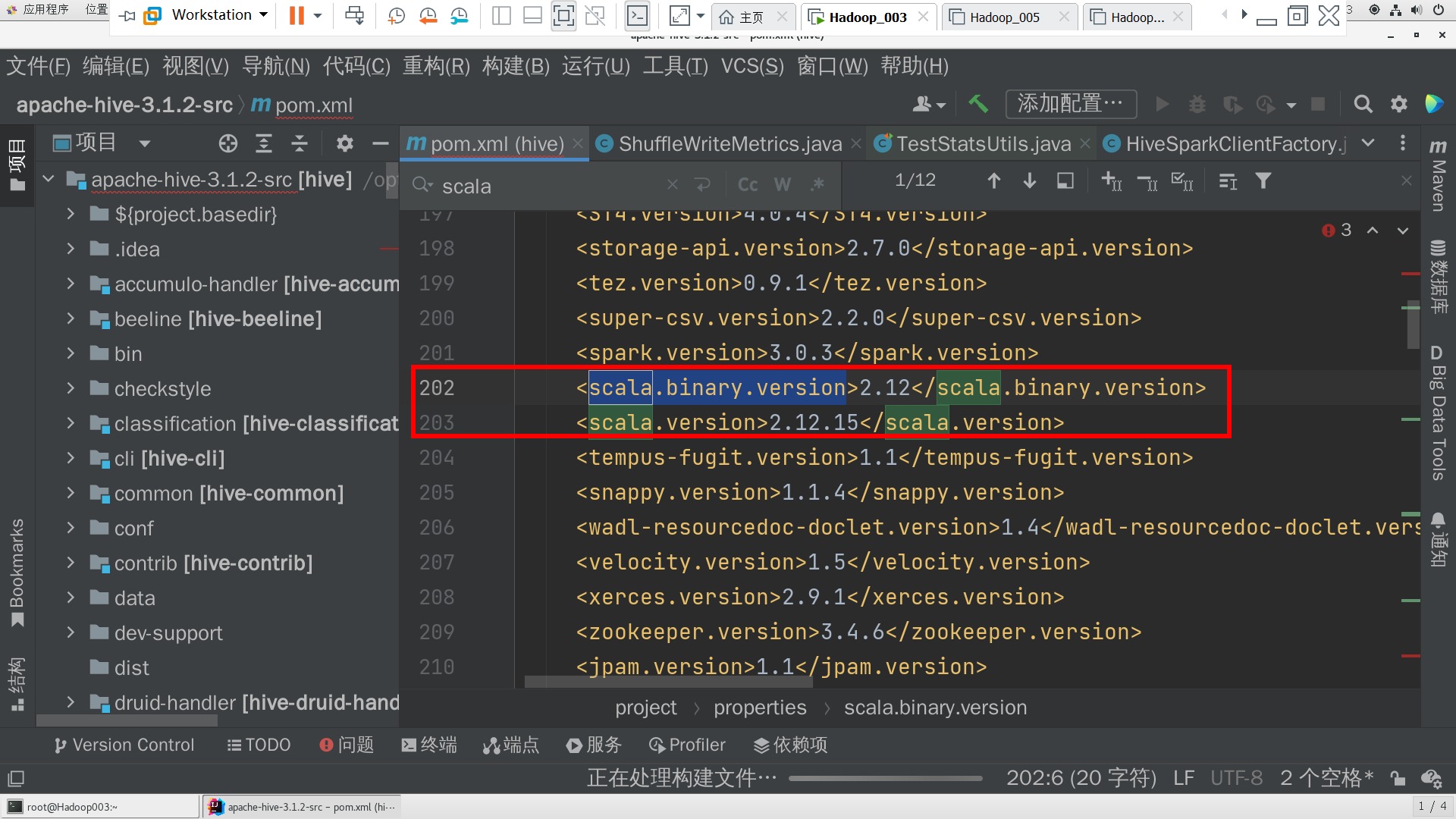


在shell命令行中,进入hive src目录,执行mvn命令进行install,安装依赖
/opt/module/maven-3.8.5/bin/mvn clean -DskipTests -Pdist -Dmaven.javadoc.skip=true install
- 1
编译报错SparkCounter.java存在问题,打开idea,找到该java文件,并对源码进行分析。
根据编译报错,及官网API,发现
org.apache.spark.Accumulator 已不存在
org.apache.spark.AccumulatorParam 已不存在
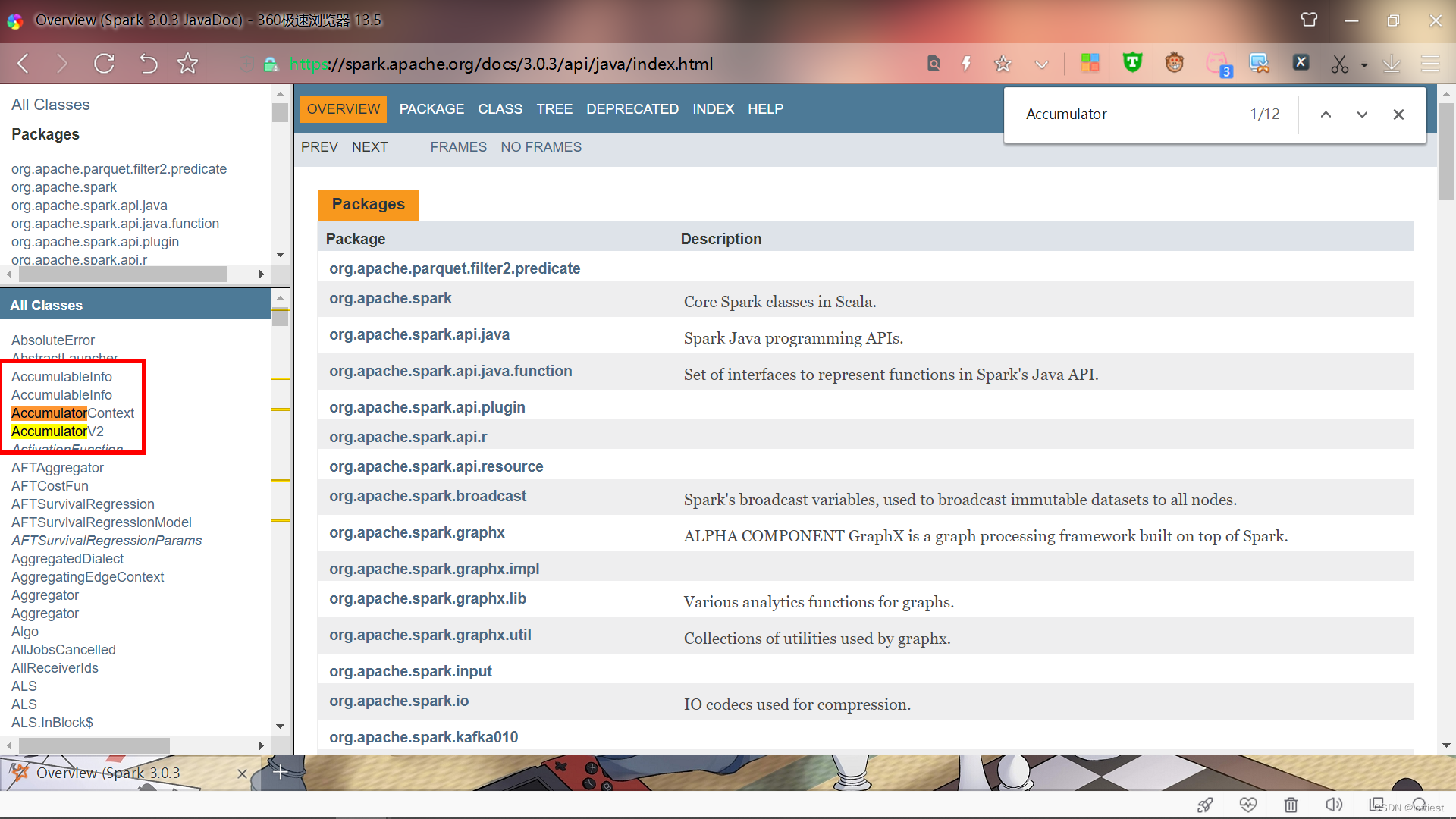
这两个类由 AccumulatorV2代替
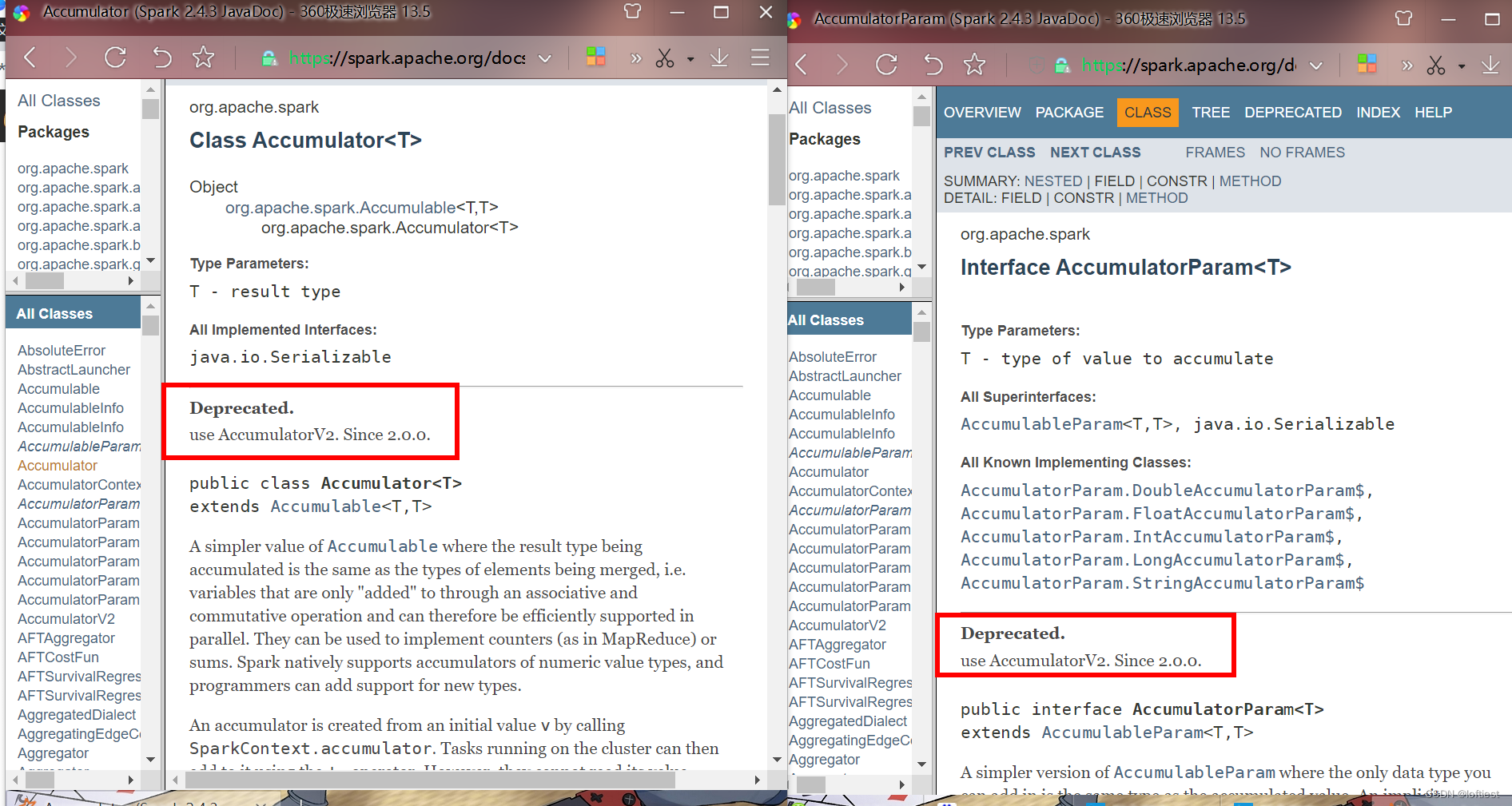
对累加器使用及获取进行修改
import java.io.Serializable; import org.apache.spark.api.java.JavaSparkContext; // org.apache.spark.Accumulator已被删除,由以下类代替 import org.apache.spark.util.LongAccumulator; // org.apache.spark.AccumulatorParam已被删除,一并删除它的实现类 public class SparkCounter implements Serializable { private String name; private String displayName; private LongAccumulator accumulator; private long accumValue; public SparkCounter() {} private SparkCounter(String name, String displayName, long value) { this.name = name; this.displayName = displayName; this.accumValue = value; } public SparkCounter(String name, String displayName, String groupName, long initValue, JavaSparkContext sparkContext) { this.name = name; this.displayName = displayName; String accumulatorName = groupName + "_" + name; // 修改累加器的获取方式 this.accumulator = JavaSparkContext.toSparkContext(sparkContext).longAccumulator(accumulatorName); // 添加参数值 this.accumulator.setValue(initValue); } public long getValue() { if (this.accumulator != null) return this.accumulator.value().longValue(); return this.accumValue; } public void increment(long incr) { this.accumulator.add(incr); } public String getName() { return this.name; } public String getDisplayName() { return this.displayName; } public void setDisplayName(String displayName) { this.displayName = displayName; } SparkCounter snapshot() { return new SparkCounter(this.name, this.displayName, this.accumulator.value().longValue()); } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
修改完成后,重新在shell命令行安装依赖。
编译报错 ShuffleWriteMetrics.java 的方法使用存在问题,找到该文件,同样的方式,查询相关类。
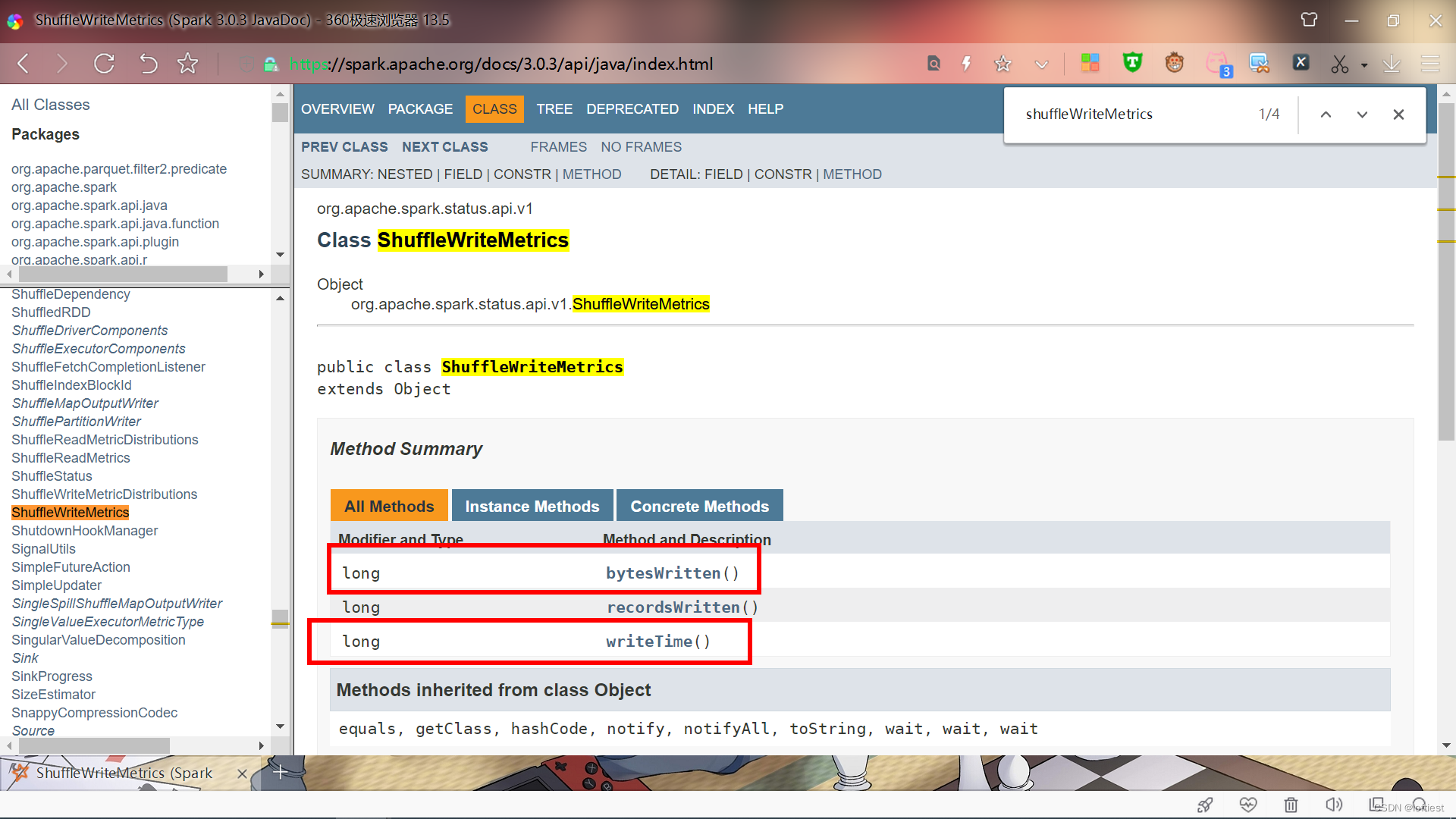
metrics.shuffleWriteMetrics().ShuffleBytesWritten()不存在,从名称看类似的方法为bytesWritten()
metrics.shuffleWriteMetrics().ShuffleWriteTime()同样不存在,修改为writeTime()
修改两个方法
import java.io.Serializable; import org.apache.spark.executor.TaskMetrics; import org.apache.hadoop.hive.common.classification.InterfaceAudience; /** * Metrics pertaining to writing shuffle data. */@InterfaceAudience.Private public class ShuffleWriteMetrics implements Serializable { /** Number of bytes written for the shuffle by tasks. */ public final long shuffleBytesWritten; /** Time tasks spent blocking on writes to disk or buffer cache, in nanoseconds. */ public final long shuffleWriteTime; private ShuffleWriteMetrics() { // For Serialization only. this(0L, 0L); } public ShuffleWriteMetrics( long shuffleBytesWritten, long shuffleWriteTime) { this.shuffleBytesWritten = shuffleBytesWritten; this.shuffleWriteTime = shuffleWriteTime; } public ShuffleWriteMetrics(TaskMetrics metrics) { // metrics.shuffleWriteMetrics().ShuffleBytesWritten()不存在,从名称看类似的方法为bytesWritten() // metrics.shuffleWriteMetrics().ShuffleWriteTime()同样不存在,修改为writeTime() this(metrics.shuffleWriteMetrics().bytesWritten(), metrics.shuffleWriteMetrics().writeTime()); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
修改后,重新安装依赖。
编译报错提示org.spark_project.guava····· 不存在,找到相关报错的java文件,修改import org.spark_project.guava.collect.Sets;为 import org.sparkproject.guava.collect.Sets;。保存后,重新安装依赖,未出现编译报错。
使用打包命令,将项目打包
mvn clean -DskipTests package -Pdist
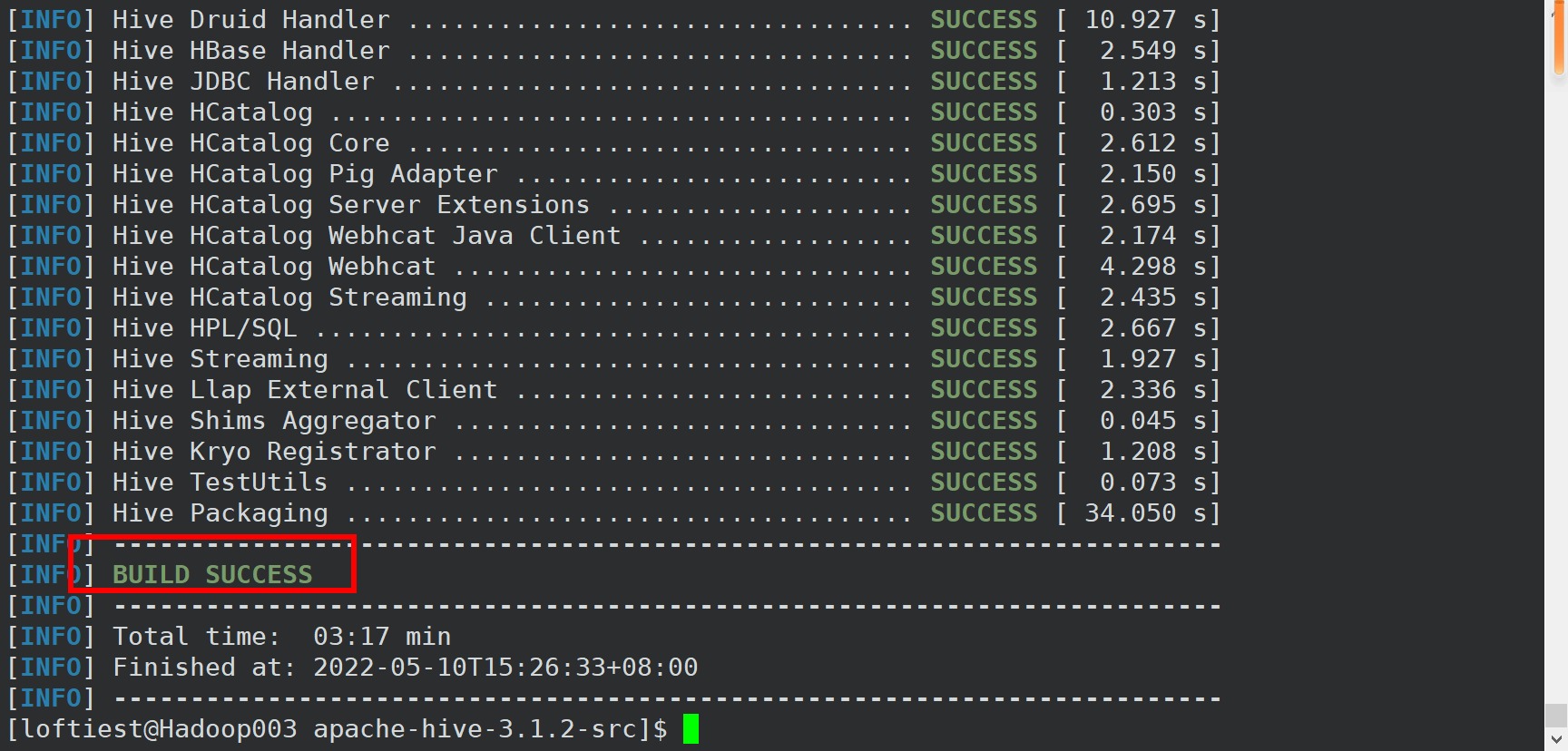
tar包在源码目录下的packaging/target目录下

将之前的hive目录改名后,解压该tar,并将目录名改为之前hive的目录名
到新hive的conf目录下删除所有文件,将旧hive的conf目录下的文件全部复制到新hive/conf目录下。
将新hive目录下的guava jar包删除,从旧hive中复制高版本的guava到新hive下。
启动hive shell
hive
表和之前相同,表示新hive可以连接mysql
hive> show tables; OK ads_order_by_province city_info dept dim_base_province dwd_order_info emp kylin_intermediate_test_cube_a037695a_6137_c92b_b144_fd8368d1e5d1 kylin_intermediate_test_cube_d175e611_bf3d_0304_b510_0f36cfdd1ffc product_info staff_hive user_visit_action Time taken: 0.75 seconds, Fetched: 11 row(s) hive> show databases; OK default Time taken: 0.019 seconds, Fetched: 1 row(s)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
此时,hive还不能使用Spark作为计算任务的引擎,还需要后续的配置。
Spark部署
使用yarn模式,及spark只负责计算,资源等调度由yarn进行。
Spark安装
解压缩文件
tar -zxvf *.tar.gz -C [path]
更改文件名
mv oldname newname
环境配置
修改yarn-site.xml
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<discription>是否检测任务使用的物理内存,超出将其停掉</discription>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<discription>是否检测任务使用的虚拟内存,超出将其停掉</discription>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
修改spark-env.sh文件
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export JAVA_HOME=/opt/module/jdk1.8.0_301
- 1
- 2
修改spark-default-conf
spark.yarn.historyServer.address Hadoop003:18989
spark.history.ui.port 18989
- 1
- 2
- 3
高可用及历史服务其配置同上
启动集群
配置了高可用,先启动zk
再启动hadoop
最后启动spark的history
提交任务
命令:
bin/spark-submit --class org.apache.spark.examples.SparkPi --master yarn ./examples/jars/spark-examples_2.12-3.0.3.jar 15
–master 选择yarn,
打开yarn的网页端

运行完毕后,查看history
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RGCTpLM5-1655790186502)(https://pic.imgdb.cn/item/61ff5e532ab3f51d917ac6d7.jpg =650x)]

Hive On Spark配置
在hive根目录下的conf目录下创建 hive-defaults.conf
spark.master yarn
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hacluster/directory
spark.executor.memory 1g
spark.driver.memeory 1g
- 1
- 2
- 3
- 4
- 5
到spark官网下载一份不带依赖的tar包,上传并解压
将刚解压的spark的jar包全都上传到HDFS,能减少每次执行任务时上传的数据量。
# 创建存放jar包的目录
hadoop fs -mkdir /sparkJars
# 上传jar包
hadoop fs -put jars/* /sparkJars
- 1
- 2
- 3
- 4
- 5
在hive-site.xml文件中添加jars位置的配置参数 和 hive的执行引擎的配置参数
<property>
<name>spark.yarn.jars</name>
<value>hdfs://hacluster/sparkJars/*</value>
</property>
<property>
<name>hive.execution.engine</name>
<value>spark</value>
</property>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
到hive 源码下的spark-client/target 目录下,将hive-spark-client-3.1.2.jar复制或移动到 hive/lib 目录下。如果该jar包不存在,可以在spark-client 目录下执行maven的打包命令。(创建spark客户端必须jar包)
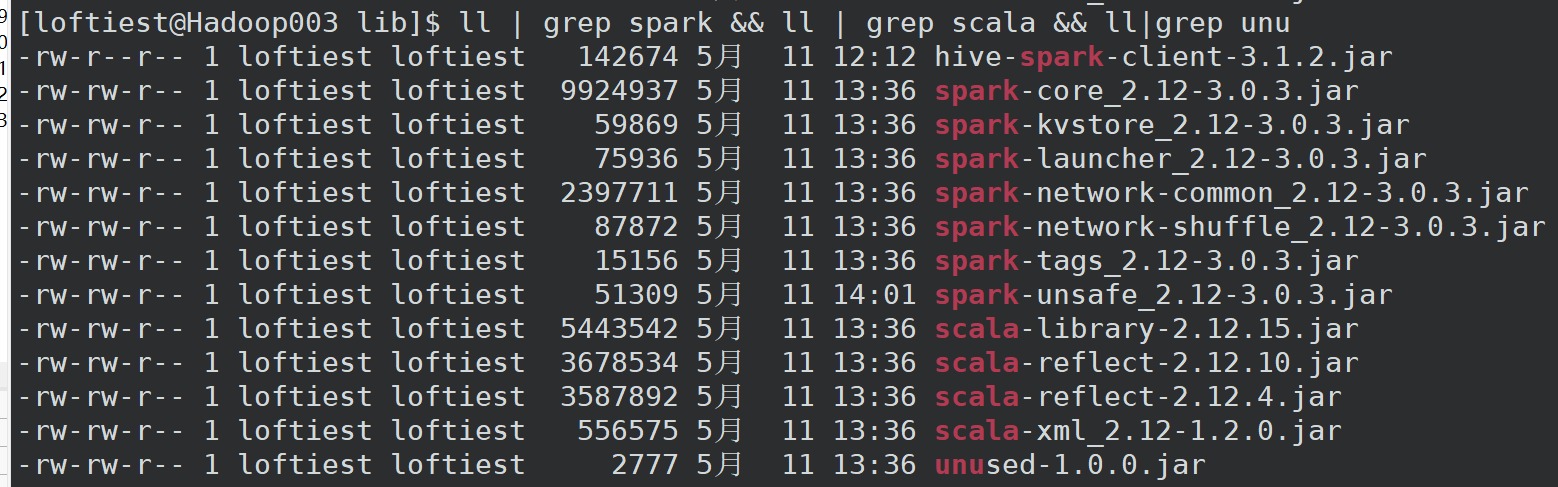
此后,再到/root/.m2/repository/org/apache/spark目录下,将所有关于spark的目录中的jar包,复制到 hive/lib 目录下(创建spark客户端必须jar包)
[root@Hadoop003 spark]# pwd
/root/.m2/repository/org/apache/spark
[root@Hadoop003 spark]# ll | grep 12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-core_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-kvstore_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-launcher_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-network-common_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-network-shuffle_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-parent_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-tags_2.12
drwxr-xr-x 3 root root 19 5月 10 22:17 spark-unsafe_2.12
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
再到/root/.m2/repository/org/scala-lang 目录下将如下三个文件中的jar包 复制到 hive/lib 目录下(spark客户端所需的语言)
[root@Hadoop003 scala-lang]# pwd
/root/.m2/repository/org/scala-lang
[root@Hadoop003 scala-lang]# ll | grep scala-
drwxr-xr-x 3 root root 20 5月 10 21:57 scala-compiler
drwxr-xr-x 4 root root 35 5月 10 22:17 scala-library
drwxr-xr-x 6 root root 64 5月 10 22:17 scala-reflect
- 1
- 2
- 3
- 4
- 5
- 6
再到/root/.m2/repository/org/spark-project/spark/unused/1.0.0 目录下,将unused jar包复制到 hive/lib目录下。
[root@Hadoop003 1.0.0]# ll
总用量 20
-rw-r--r-- 1 root root 228 5月 10 22:17 _remote.repositories
-rw-r--r-- 1 root root 2777 5月 10 22:17 unused-1.0.0.jar
-rw-r--r-- 1 root root 40 5月 10 22:17 unused-1.0.0.jar.sha1
-rw-r--r-- 1 root root 2356 5月 10 21:57 unused-1.0.0.pom
-rw-r--r-- 1 root root 40 5月 10 21:57 unused-1.0.0.pom.sha1
[root@Hadoop003 1.0.0]# pwd
/root/.m2/repository/org/spark-project/spark/unused/1.0.0
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
总共需要额外添加的jar包如下。
Hive On Spark 测试
开启zookeeper和hadoop。
进入hive shell。
向测试表中插入数据
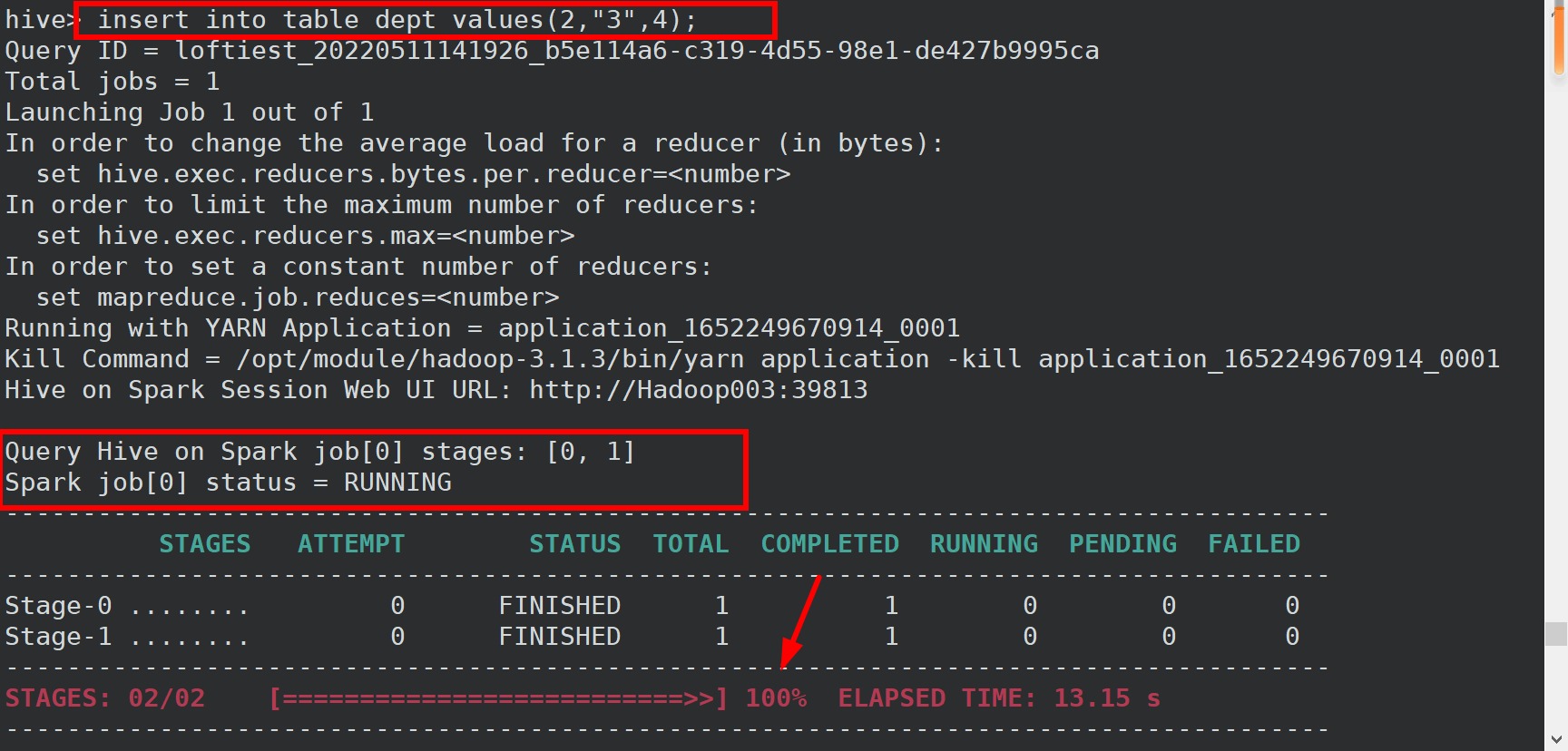
Yarn 环境配置
需要增加AM的资源比例,防止比例在0.1时的实际内存过小,导致不能执行多个任务。
相关参数
yarn.scheduler.capacity.maximum-am-resource-percent
默认0.1,修改为0.7-0.8 。
修改完成后,分发到其他节点,然后重启yarn

