
- 1Python插入排序
- 2解析葵花熊胆痔灵膏/栓 大广赛赛题细节及顶尖作品分享_葵花熊胆痔灵膏市场分析
- 3Prometheus监控kafka+jvm_promethues监控kafka remotejmx
- 4HJ4 字符串分隔_print("{0:0<8s}".format(l[i:i+8]))
- 5实验七 基于广度优先搜索的六度空间 理论验证_实验七 基于广度优先搜索的六度空间 理论验证 一、实验目的 1.掌握图的邻接矩阵和
- 6Java 观察者模式(Observer Pattern)详解_观察者模式java
- 7数据库常用命令——单表查询_数据库查看表命令
- 850w字+的Android技术类校招面试题汇总,国内一线互联网公司面试题汇总
- 9广义表+ADT+C语言实现_c实现广义表并且画图
- 10微信小程序wifi接口wx.getWifiList报错解决_getwifilist:fail fail:require permission desc
决策树分类任务实战(python 代码详解)_决策树分类实战
赞
踩
目录
(二) 预测测试集,返回每个测试样本的分类/回归结果:predict
②accuracy_score(y_pred,y_test)
(四)查看特征重要性:feature_importances_
(七) 生成决策树模型的性能报告-classification_report 函数
一、导入库、数据集、并划分训练集和测试集
- # 导入所需的库
- import numpy as np
- import pandas as pd
- import matplotlib.pyplot as plt
- from sklearn import tree
- from sklearn.datasets import load_iris
- from sklearn.model_selection import train_test_split
- from sklearn.metrics import accuracy_score
- from sklearn.tree import DecisionTreeClassifier
-
-
- # 导入鸢尾花数据集
- iris = load_iris()
- X = iris.data # 特征
- y = iris.target # 类别
- feature_names = iris.feature_names # 特征名称
- class_names = iris.target_names # 类别名称
-
- # 将数据集划分为训练集和测试集,比例为 6:4
- X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.4, random_state=30)
二、参数调优
这一部分介绍两种方法进行最优参数的选择
第一种方法时通过for循环
第二种方法是网格调参
两种方法本质上是一样的
同时每种方法下又详细介绍了如何对单参数调参,和多参数同时调参
此外呢,又介绍了怎么结合K折交叉验证进行参数的选择
(一)第一种调参方法:for循环
(1)单参数优化
①单参数优化(无K折交叉验证)
下边是对一个参数,即max_depth决策树的最大深度进行最优参数选择
- # 建模训练
- score_list1=[]
- for i in np.arange(2, 6, 1):
- clf = DecisionTreeClassifier(criterion="entropy", max_depth=i, min_samples_split=2, min_samples_leaf=2,random_state=0)
- clf = clf.fit(X_train, y_train)
- score = clf.score(X_test, y_test)
- score_list1.append(score) # 保存得分
- # 绘制得分
- plt.plot(np.arange(2, 6), score_list1, color="red")
- plt.xticks(np.arange(2, 6, 1)) # 设置横坐标刻度为整数
- plt.show()
结果如下,x轴代表最大深度max_depth的取值,纵轴代表各个最大深度下模型在测试集上对应的准确率 。结果表明,最大深度在2或者3时模型准确率达到最大,之后决策树的最大深度增加,模型的准确率会下降,图中深度为4或者5,模型的准确率持平。
这里只是示例,可以选择其他最大深度进行验证。

②单参数+K折交叉验证 优化
首先导入了KFold,然后创建了一个五折交叉验证的实例。
在循环中,我们使用kf.split()来获取训练集和测试集的索引,然后根据这些索引划分数据集。接下来,我们使用训练集拟合模型,并在测试集上计算得分。
最后,我们将每次迭代的得分求平均并添加到score_list1中
- from sklearn.model_selection import KFold
- import numpy as np
- from sklearn.tree import DecisionTreeClassifier
-
- score_list1 = []
- kf = KFold(n_splits=5, shuffle=True, random_state=0)
-
- for i in np.arange(2, 6, 1):
- clf = DecisionTreeClassifier(criterion="entropy", max_depth=i, min_samples_split=2, min_samples_leaf=2, random_state=0)
- scores = []
- for train_index, test_index in kf.split(X_train):
- X_train_fold, X_test_fold = X_train[train_index], X_train[test_index]
- y_train_fold, y_test_fold = y_train[train_index], y_train[test_index]
- clf.fit(X_train_fold, y_train_fold)
- score = clf.score(X_test_fold, y_test_fold)
- scores.append(score)
- score_list1.append(np.mean(scores))
- # 绘制得分
- plt.plot(np.arange(2, 6), score_list1, color="red")
- plt.xticks(np.arange(2, 6, 1)) # 设置横坐标刻度为整数
- plt.show()
结果如下,发现最大深度在2、3、4、5时模型的准确率相同。

当不同深度的决策树模型在特定评估指标(如准确率)上表现相同时,我们可以参考以下几个方面来选择决策树的最大深度:
模型复杂度与过拟合风险、可解释性、计算资源和效率集成方法、业务需求和应用场景等,一般情况下,如果准确率相同,倾向于选择深度较小的决策树,因为它往往具有更好的泛化能力和较低的复杂度。但如果在其他重要指标上有显著差异,也应该考虑这些因素的影响。
当然,面对具体情况时,即使不同深度的决策树模型在准确率上表现出相同的水平,选择最合适的最大深度仍需细致考量。例如,当最大深度从3层增加到4层时,尽管准确率不变,但若4层决策树能揭示更多关于数据潜在规律的有价值信息,或者有助于提升模型的可解释性和完整性,那么在这种情况下,选择4层深度的决策树可能更为合适。
(2)多参数优化
①多参数优化(无K折交叉验证)
- # 初始化变量
- max_score = -np.inf # 初始化最大得分为负无穷大
- best_params_history = [] # 初始化历史最佳参数列表
- score_list = []
-
- # 建模训练
- for i in np.arange(2, 6, 1):
- for j in np.arange(2, 10, 2):
- for t in np.arange(2, 10, 2):
- clf = DecisionTreeClassifier(criterion="entropy", max_depth=i, min_samples_split=j, min_samples_leaf=t, random_state=0)
- clf = clf.fit(X_train, y_train)
- score = clf.score(X_test, y_test)
- score_list.append(score) # 保存得分
-
- # 检查当前得分是否等于最大得分
- if score >= max_score: # 使用 >= 而不是 >,这样当得分相同时也会记录
- max_score = score # 更新最大得分
- best_params_history.append((i, j, t)) # 添加当前最优参数到历史最优参数列表
-
- # 展示结果
- print("All best parameters sets when the max score was achieved:")
- for params in best_params_history:
- print(f"i={params[0]}, j={params[1]}, t={params[2]}")
-
- print(f"Max score: {max_score}")
-
- # 绘制得分
- plt.plot(np.arange(1, len(score_list) + 1), score_list, color="red")
- plt.show()
参数介绍:
本章节中主要采用了前三个参数的调参。
-
max_depth: 决策树的最大深度,用于控制树的复杂度。限制树的深度可以防止过拟合,因为它限制了树可以学习的规则的数量。 -
min_samples_split: 节点分裂的最小样本数。决策树在节点分裂时会考虑这个参数,如果节点的样本数少于这个值,则不会继续分裂。 -
min_samples_leaf: 叶节点的最小样本数。在叶节点分裂时,如果分裂后每个子节点的样本数少于这个值,则不会继续分裂,从而控制了叶节点的大小。 -
min_impurity_decrease 是决策树算法中的一个重要参数,主要用于控制决策树的增长过程,防止过拟合。当算法在构建决策树时,会尝试在每个内部节点划分数据集,以期降低决策树的不纯度(对于分类问题是基尼不纯度或信息熵,对于回归问题是均方误差)。min_impurity_decrease 参数规定了一个阈值,要求在进行节点划分时,至少能带来这么大的不纯度下降量。也就是说,只有当划分后的子节点相较于父节点的不纯度减少量大于等于 min_impurity_decrease 所设定的阈值时,才会继续划分该节点。
如果当前节点划分后,所有可能的子节点不纯度减小量都不满足此条件,则该节点会被标记为叶子节点,不再向下生长。
通过设置合适的 min_impurity_decrease 参数,可以限制决策树的精细化程度,有利于防止过拟合,提高模型的泛化能力。 -
max_features ,用来控制在构建决策树时每个节点分裂时考虑的最大特征数。
当你设置 max_features=3,这意味着在决策树进行节点划分时,每次都将从所有特征中最多随机选择3个特征来评估最佳分割点。换句话说,在确定每个内部节点如何划分数据集时,算法只会考虑最多3个特征作为候选特征,从中选取信息增益(或者其他衡量标准,如基尼不纯度)最高的那个特征进行分割。这个参数有助于防止过拟合,尤其是在特征数量较多的情况下,通过限制决策树对特征的选择范围,能够构建出更为泛化的模型。 -
max_leaf_nodes是决策树算法中的一个参数,用于指定最大叶子节点数。通过限制最大叶子节点数,可以控制决策树的复杂度,进而防止过拟合。当设置了max_leaf_nodes参数时,算法会在构建树的过程中尝试保持叶子节点数不超过指定值。
这些参数可以帮助控制决策树的生长过程,防止过拟合,并提高模型的泛化能力。
综上所示,六个剪枝参数:
决策树可以很好地处理分类问题,但常会由于节点数过多致使过拟合问题的出现,于是出现了控制预剪枝、后剪枝等的剪枝参数,这也是决策树算法实现过程中需要调节的很重要的参数。
max_depth: 控制最大深度
min_samples_leaf: 限定一个节点在分枝后的每个子节点都必须包含至少min_samples_leaf个训练样本,否则分枝就不会发生,或者,分枝会朝着满足每个子节点都包含min_samples_leaf个样本的方向去发生
min_samples_split: 限定一个节点必须要包含至少min_samples_split个训练样本,这个节点才允许被分枝,否则分枝就不会发生
max_features:用暴力方法限制特征数量,相较而言要通过减少特征数量来防止过拟合的话,用PCA、随机森林等降维和特征选择方法更好
min_impurity_decrease:限制信息增益的大小,信息增益小于设定数值的分枝不会发生
max_leaf_nodes是决策树算法中的一个参数,用于指定最大叶子节点数。
结果如下:
结果给出了,每次取得最大分数时,对应的参数值的选取,并且给出了最大分数。
以及每组参数选择对应的分数图。


②多参数+K折交叉验证 优化
- # 初始化变量
- max_score = -np.inf # 初始化最大得分为负无穷大
- best_params_history = [] # 初始化历史最佳参数列表
- score_list = []
-
- # 建模训练
- for i in np.arange(2, 6, 1):
- for j in np.arange(2, 10, 2):
- for t in np.arange(2, 10, 2):
- clf = DecisionTreeClassifier(criterion="entropy", max_depth=i, min_samples_split=j, min_samples_leaf=t, random_state=0)
- scores = []
- for train_index, test_index in kf.split(X_train):
- X_train_fold, X_test_fold = X_train[train_index], X_train[test_index]
- y_train_fold, y_test_fold = y_train[train_index], y_train[test_index]
- clf.fit(X_train_fold, y_train_fold)
- score = clf.score(X_test_fold, y_test_fold)
- scores.append(score)
- score=np.mean(scores)
- score_list.append(np.mean(scores))
-
- # 检查当前得分是否等于最大得分
- if score >= max_score: # 使用 >= 而不是 >,这样当得分相同时也会记录
- max_score = score # 更新最大得分
- best_params_history.append((i, j, t)) # 添加当前最优参数到历史最优参数列表
-
- # 展示结果
- print("All best parameters sets when the max score was achieved:")
- for params in best_params_history:
- print(f"i={params[0]}, j={params[1]}, t={params[2]}")
-
- print(f"Max score: {max_score}")
-
- # 绘制得分
- plt.plot(np.arange(1, len(score_list) + 1), score_list, color="red")
- plt.show()


(二)第二种调参方法:网格搜索法
(1)单参数调参
①单参数优化(无K折交叉验证)
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import KFold
- kf = KFold(n_splits=5, shuffle=True, random_state=0)
- parameters={"max_depth":[1,2,3,4,5,6]}
- clf=DecisionTreeClassifier()
- grid_search=GridSearchCV(clf,parameters)
-
- #传入训练集数据并开始进行参数调优
- grid_search.fit(X_train,y_train)
- grid_search.best_params_
- print("最优参数: ", grid_search.best_params_)
- print("最优得分: ", grid_search.best_score_)
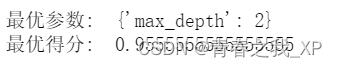
②单参数+K折交叉验证 优化
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import KFold
- kf = KFold(n_splits=5, shuffle=True, random_state=0)
- parameters={"max_depth":[1,2,3,4,5,6]}
- clf=DecisionTreeClassifier()
- grid_search=GridSearchCV(clf,parameters,cv=kf)
-
- #传入训练集数据并开始进行参数调优
- grid_search.fit(X_train,y_train)
- grid_search.best_params_
- print("最优参数: ", grid_search.best_params_)
- print("最优得分: ", grid_search.best_score_)

(2)多参数调参
①多参数优化(无K折交叉验证)
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import KFold
- kf = KFold(n_splits=5, shuffle=True, random_state=0)
- parameters={"max_depth":[1,2,3,4,5,6],"criterion":["gini","entropy"],"min_samples_split":[2,3,4,5,6,7,8,9]}
- clf=DecisionTreeClassifier()
- grid_search=GridSearchCV(clf,parameters)
-
- #传入训练集数据并开始进行参数调优
- grid_search.fit(X_train,y_train)
- grid_search.best_params_
- print("最优参数: ", grid_search.best_params_)
- print("最优得分: ", grid_search.best_score_)
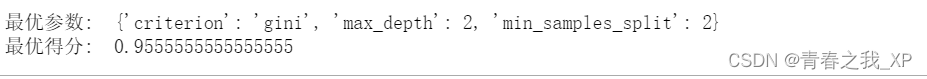
②多参数+K折交叉验证 优化
- from sklearn.model_selection import GridSearchCV
- from sklearn.model_selection import KFold
- kf = KFold(n_splits=5, shuffle=True, random_state=0)
- parameters={"max_depth":[1,2,3,4,5,6],"criterion":["gini","entropy"],"min_samples_split":[2,3,4,5,6,7,8,9]}
- clf=DecisionTreeClassifier()
- grid_search=GridSearchCV(clf,parameters,cv=kf)
-
- #传入训练集数据并开始进行参数调优
- grid_search.fit(X_train,y_train)
- grid_search.best_params_
- print("最优参数: ", grid_search.best_params_)
- print("最优得分: ", grid_search.best_score_)

总结:
在进行参数调优时,确实需要注意到两个重要的方面,即多参数调优和单参数调优的区别,以及参数范围的选择问题。为了更加严谨地进行模型调优,可以采取以下优化措施:
1. 多参数调优 vs. 单参数调优:
* 对于需要调整多个参数的情况,推荐使用多参数调优方法,如GridSearchCV()或RandomizedSearchCV(),以全面考虑不同参数组合对模型性能的影响。
* 对于单一参数的调优,确实可以采用单参数调优的方式,但需要注意单参数调优可能会忽略到多个参数之间的交互影响,因此在选择调优方法时应根据具体情况进行权衡。
2. 参数范围的选择:
* 在使用GridSearchCV()等函数进行参数调优时,如果得到的最优值位于参数范围的边界值,有可能存在更优的参数取值,此时需要考虑扩大参数搜索范围。
* 为了更全面地搜索参数空间,可以根据实际情况逐步扩大参数范围,以确保找到模型性能的最优组合。
总的来说,在进行模型参数调优时,应当充分考虑参数之间的交互影响,选择适当的调优方法,并不断优化参数范围,以获得更好的模型性能。这样可以确保模型在拟合和泛化能力上都达到较好的平衡,提高模型的预测准确性。
三、构建决策树模型并预测
前边我们介绍了如何选取最优参数,假如我们得到的最优参数是max_depth=2, min_samples_split=2, min_samples_leaf=2
(一)构建模型
- clf = DecisionTreeClassifier(criterion="entropy", max_depth=2, min_samples_split=2, min_samples_leaf=2,random_state=0)
- clf = clf.fit(X_train, y_train)
(二) 预测测试集,返回每个测试样本的分类/回归结果:predict
clf.predict(X_test)
- y_pred=clf.predict(X_test)
- a=pd.DataFrame()
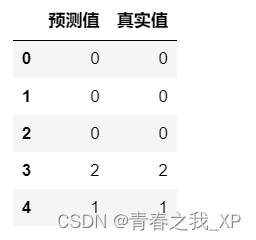
- a["预测值"]=y_pred
- a["真实值"]=y_test
- a[:5]
前五行数据如下:
(三)决策树模型在测试集上的预测分数/准确率
① clf.score(X_test, y_test)
- score = clf.score(X_test, y_test)
- score

②accuracy_score(y_pred,y_test)
- from sklearn.metrics import accuracy_score
- accuracy=accuracy_score(y_pred,y_test)
- accuracy

两种方法分析:
accuracy_score和clf.score都是用来评估分类模型的性能指标,但它们之间有一些区别。
accuracy_score(y_pred, y_test):这个函数计算的是模型在测试集上的准确率,即正确预测的样本数占总样本数的比例。其中,y_pred是模型在测试集上的预测结果,y_test是测试集的真实标签。
clf.score(X_test, y_test):这个方法是scikit-learn中分类器对象的方法,用于计算模型在测试集上的准确率。它会自动使用模型对测试集进行预测,并将预测结果与真实标签进行比较,从而得到准确率。
总的来说,这两种方法都可以用来评估分类模型在测试集上的表现,但accuracy_score需要手动传入预测结果,而clf.score则直接使用分类器对象对测试集进行预测。两者得到的准确率值应该是一致的,只是计算方式略有不同。
(四)查看特征重要性:feature_importances_
clf.feature_importances_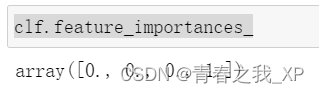
[*zip(feature_names,clf.feature_importances_)]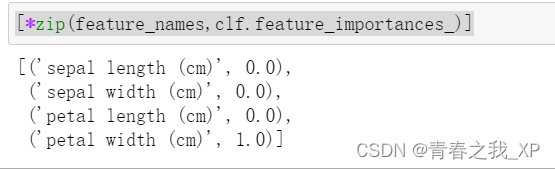
- # 如果特征变量很多,可以使用如下代码将特征名称和特征重要性一一对应,以方便查看
- features=iris.feature_names # 特征名称
- importances=clf.feature_importances_
- df=pd.DataFrame()
- df["特征名称"]=features
- df["特征重要性"]=importances
- df.sort_values("特征重要性",ascending=False)

(五)预测各个类别的概率
- y_pred_proba=clf.predict_proba(X_test)#是一个三维数组
- b=pd.DataFrame(y_pred_proba,columns=["0类概率","1类概率","2类概率"])
- b[:5]
前五行数据如下:
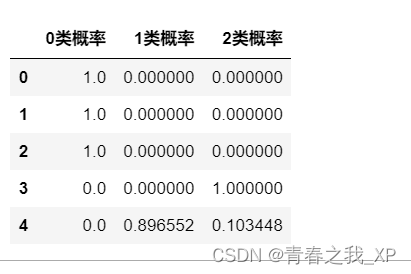
在决策树中,clf.predict_proba 方法用于获取样本在每个类别上的概率预测。决策树模型在预测样本属于每个类别的概率时,通常采用以下原理进行计算:
-
叶子节点中样本的类别比例:在决策树的训练过程中,每个叶子节点会包含一定数量的训练样本。当进行预测时,样本通过决策树的分支最终到达一个叶子节点。在叶子节点中,可以统计该节点中各个类别样本的比例。
-
类别概率的计算:对于一个给定的测试样本,通过决策树的遍历找到其所在的叶子节点。然后,可以根据该叶子节点中各个类别样本的比例来计算该样本属于每个类别的概率。通常采用的方法是将该叶子节点中每个类别的样本比例作为该样本属于该类别的概率。
-
归一化:最后,为了确保每个类别的概率值在 0 到 1 之间,并且所有类别的概率之和为 1,通常会对概率值进行归一化处理,例如采用 softmax 函数。
总的来说,clf.predict_proba 方法在决策树中是基于叶子节点中样本的类别比例来计算样本属于每个类别的概率。这种方法简单直观,同时也能提供对样本属于不同类别的置信度信息。
(六)计算混淆矩阵
- table = pd.crosstab(y_test, y_pred, rownames=['Actual'], colnames=['Predicted'])
- table

- from sklearn.metrics import confusion_matrix
- cm = confusion_matrix(y_test, y_pred)
- cm

- from sklearn import metrics
- metrics.plot_confusion_matrix(clf, X_test, y_test)
- plt.show()

(七) 生成决策树模型的性能报告-classification_report 函数
- from sklearn.metrics import classification_report
- # 输出评估指标
- print(classification_report(y_test, y_pred))

①精确度(Precision):针对每个类别,精确度表示被分类器正确分类的样本数占该类别所有被分类为该类别的样本数的比例。精确度越高,分类器将正类别的样本正确地分类为正类别的能力越强。
②召回率(Recall):针对每个类别,召回率表示被分类器正确分类的样本数占该类别所有实际正样本数的比例。召回率越高,分类器将正类别的样本正确地识别为正类别的能力越强。
③F1 值:精确度和召回率的加权平均值,是精确度和召回率的调和平均值。它提供了一个综合性能指标,对分类器的整体性能进行评估。
④支持数(Support):每个类别在测试集中的样本数量。
⑤加权平均值:报告的最后一行显示了各项指标的加权平均值,其中包括精确度、召回率和 F1 值。这些加权平均值对应于各个类别样本的比例。
在分析这些结果时,您可以关注以下几点:
对于哪些类别,模型的性能较好?哪些类别的性能较差? 模型的整体性能如何?F1 值较高通常表示模型具有较好的平衡性能。 是否有任何类别存在偏差?例如,某些类别的召回率较低可能意味着模型对于这些类别的识别能力较弱。
(八)画出决策树
(1)程序中直接画出决策树
画决策树需要用到 tree.export_graphviz 函数,在 tree.export_graphviz 函数中,class_names 参数用于指定分类目标变量(类标签)的名字,这些名字将会显示在决策树图中的叶节点上。该参数的具体值应该是一个列表或者数组,其元素顺序与模型所预测的类别顺序保持一致。
这里class_names 列表中的第一个元素对应于模型类别序号 0,第二个对应于类别序号 1。
在已经训练好的 scikit-learn 分类器 clf 中,类别顺序可以通过访问 clf.classes_ 获取。
- clf.classes_
- # 因此,正确设置 class_names 的方法可能是这样的:
- #class_names = list(clf.classes_)

类别标签需要是字符串类
- #类别标签需要是字符串类
- class_labels = clf.classes_.tolist() # 将numpy数组转换为Python列表
- class_names = [str(label) for label in class_labels]
- import graphviz
- plt.rcParams['font.sans-serif'] = ['SimHei']
-
- dot_data = tree.export_graphviz(clf,out_file = None,
- feature_names= feature_names, class_names=class_names,
- filled=True, rounded=True)
- dot_data=dot_data.replace('helvetica', 'SimHei')
- graph = graphviz.Source(dot_data)
-
- graph
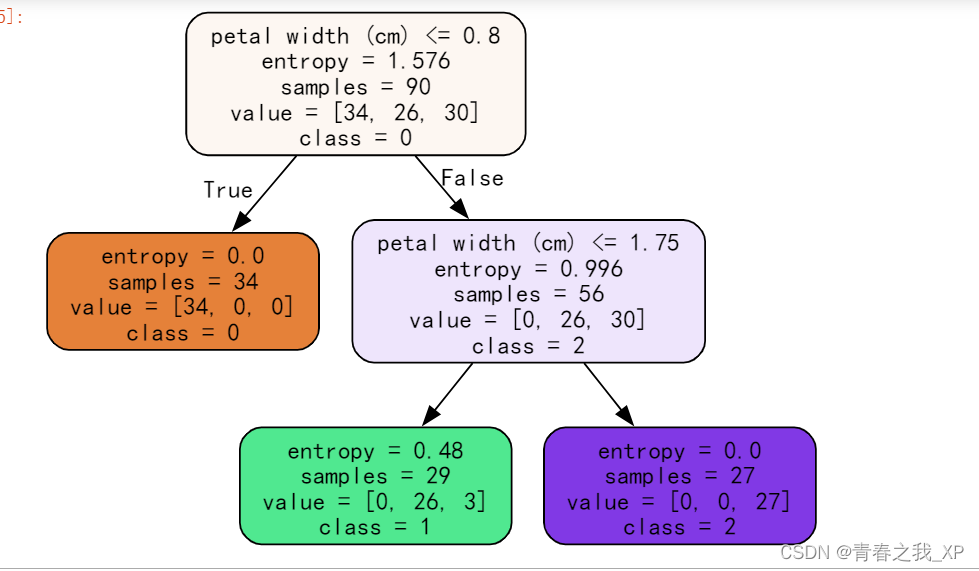
(2)将画出的决策树保存为pdf格式
graph.render("decision_tree") # 保存为 decision_tree.pdf 文件
(3)将画出的决策树保存为png格式
- graph.format = 'png' # 指定保存为 PNG 格式
- graph.render("decision_tree_image") # 保存为 decision_tree_image.png 文件

(九) 查看叶子节点数量
- n_leaves = clf.tree_.n_leaves
- print("Number of leaves in the decision tree:", n_leaves)

(十) 返回每个测试样本所在叶子节点的索引:apply
- clf.apply(X_test)
- #clf.apply(X_test)可以帮助我们理解测试数据集中的样本在训练好的分类器中的位置,从而进行更深入的分析和应用

补充:
①如果你想基于信息增益(或者基尼指数)来设定一个硬性阈值,若小于某一个阈值,则决策树不再向下分裂,在sklearn中直接通过参数设置并不支持。若想实现类似效果,可能需要自定义决策树算法或在模型建立后进行后处理。
②预剪枝和后剪枝是决策树中常用的剪枝方法,它们旨在优化决策树模型,使其具有更好的拟合和泛化能力。下面我对它们进行进一步优化,以使得描述更加清晰:
-
预剪枝:在构造决策树的过程中,对每个节点在进行划分之前进行评估。如果当前节点的划分不能提高泛化能力,就停止划分,将当前节点标记为叶节点。这种方法的优点是可以在树的生长过程中就尽量减少过拟合,但是可能会导致决策树过于简单,无法充分表达数据的复杂关系。
-
后剪枝:首先生成一颗完整的决策树,然后自底向上地对内部节点进行考察。如果将某个内部节点变为叶节点可以提升整体泛化性能,则执行此替换。后剪枝相比于预剪枝来说,更加灵活,因为它在决策树构造完成之后才进行剪枝,可以更充分地利用数据信息,但相应的计算成本较高。在商业实战中,前剪枝应用得更广泛,参数调优其实也起到了一定的前剪枝作用。
总结来说,预剪枝是一种边构造边剪枝的方法,而后剪枝则是在构造完整棵树之后再进行剪枝。选择哪种方法取决于具体情况,预剪枝适用于数据量较大的情况下,能够在早期防止过拟合,而后剪枝则适用于需要更好泛化能力的情况下,但会相对耗费更多计算资源。
在商业实战中,前剪枝应用得更广泛,参数调优其实也起到了一定的前剪枝作用。

