
热门标签
热门文章
- 1[C++] OpenCasCade空间几何库的模型展现_怎么用opencascade显示几何模型
- 2微信小程序——CSS3渐变_小程序文字渐变
- 3关于uni.downloadFile与uni.saveFiled文件名不一,解决方案思路_uni.savefile 自定义文件名
- 4Linux下wget命令详解_wget -o和-o区别 保存文件
- 5【UE4】UE4蓝图基础
- 6WRF模型运行教程(ububtu系统)-- IV-1.模型相关文件参数说明【namelist.wps文件、namelist.input文件】
- 7虚拟机上网设置——桥接模式 & NAT模式_虚拟机桥接模式
- 8Kali Linux安装与使用指南_kali安装常用工具
- 9info testing mysql_诺亚舟教育网SQL注入漏洞(涉及近170w用户信息)
- 10判断所给日期是否是当天_long日期如何判断是否为当天
当前位置: article > 正文
(scala)spark+jieba分词加载用户自定义词典worker端不起作用的Bug_pyspark jieba work不起作用
作者:菜鸟追梦旅行 | 2024-03-15 17:42:10
赞
踩
pyspark jieba work不起作用
如果在udf外面加载用户自定义词典,我们的worker端的分词还是按照jieba自带的库进行分词,这样的分词结果肯定是不符合我们的要求(我也是在使用了很长的时间之后才发现这个问题)
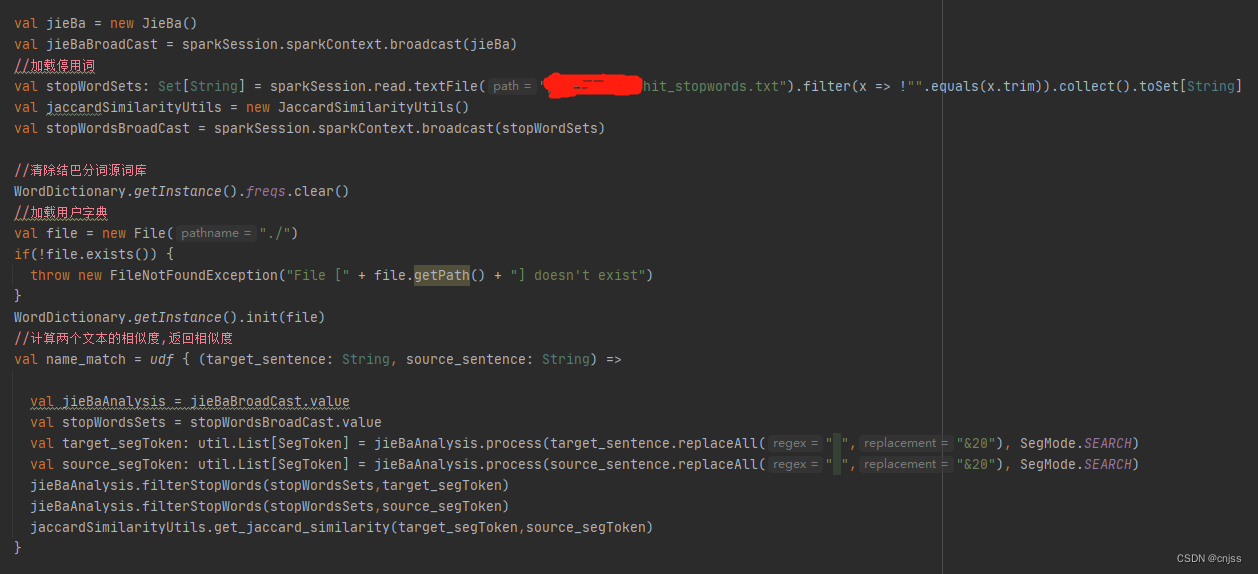
我们把driver加载自定义词典放到worker去,即可解决
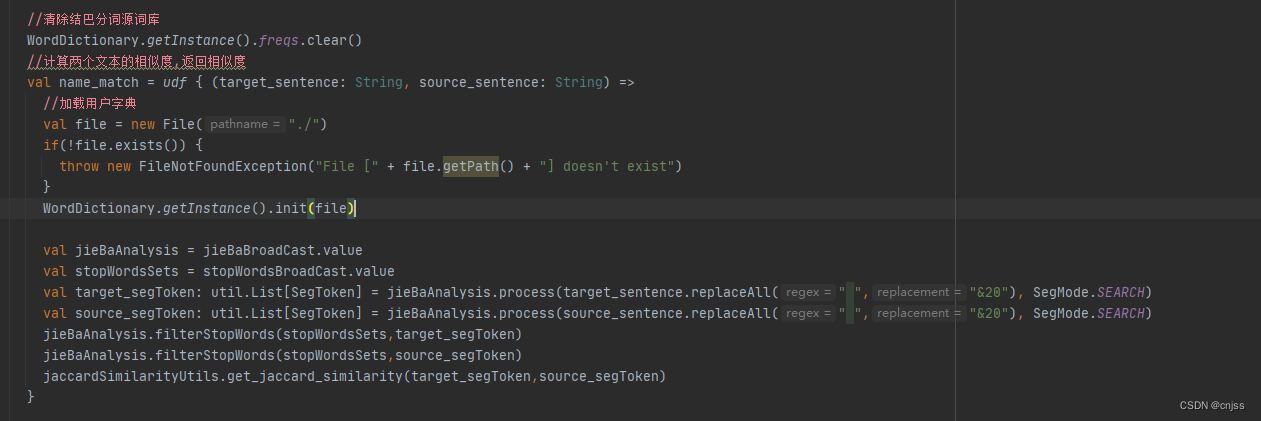
这样即可,不过这里需要注意的是如果,你想完全使用自己的词典,你就需要 WordDictionary.getInstance().freqs.clear(),但是这个只能清除driver端,如果想清除worker端的源词库,不能在udf里面clear(),实际情况中,写在udf里加载用户自定义词典一个worker只加载一次,但是clear(),每次记录都会清除,最后导致worker端既没有源词库也没有自定义词库,目前的解决方法是手动删除jieba的jar包中的dict.txt文件,根源上解决
声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop】
推荐阅读
相关标签

