
- 1海豚调度DolphinScheduler入门学习
- 2295. 数据流的中位数
- 3运行stable-diffusion-webui-directml时报RuntimeError: Torch is not able to use GPU的错误解决办法_stable diffusion安装无法使用gpu
- 4【mysql 查询一年中的所有月份】_mysql 获取一年中所有月份
- 5BAT实习内推笔试卷(第一场)_给定一个长度不小于2的数组arr,实现一个函数调整arr,要么让所有的偶数下标都是偶
- 6探索Focalboard:一款强大的开源看板管理工具
- 7关于思科AP因证书过期无法自动上线WLC问题_config ap cert-expiry-ignore mic enable
- 8AI工具新革命:从ChatGPT到Sora,生成式AI改变世界_chatgpt、sora先后问世
- 9Vue3.4正式发布,更快、更强、更好用_vue 3.4
- 10蚁群算法用于航路规划的matlab简单实现_matlab 蚁群算法
CHATGLM3应用指南——数据处理_chatglm3 数据存在哪里
赞
踩
大型语言模型的培训依赖于海量且多样化的数据资源。构建高品质的训练数据集对于这些模型的开发至关重要。尽管截至2023年9月,对于大规模模型的理论分析和解释仍不甚完善,且对于训练所用语言数据的精确说明和界定尚显不足,但广泛的研究共识认为,训练数据对于提升语言模型的性能和样本的泛化能力起着核心作用。历史研究表明,为了增强模型的泛化和适应性,预训练数据应包含多种形式,如互联网内容、书籍、学术论文、百科全书以及社交媒体内容等,并且应尽可能广泛地覆盖不同的领域、语种、文化背景和不同的观点。本文将阐述目前大型语言模型训练数据的主要来源、处理技术、预训练数据对模型性能的影响评估,以及一些常用的开源数据集等方面的信息。
一、数据来源
大规模语言模型的开发依赖于广泛而多元的数据资源。研究文献详细阐述了人类在训练GPT-3模型时主要利用的数据源,这包括经筛选的CommonCrawl数据集、WebText2、Books1、Books2以及英文版Wikipedia等。例如,CommonCrawl的初始数据量高达45TB,筛选后仅剩570GB。通过分词技术处理上述资料,大约产生了5000亿个词元。为了确保模型能够利用高品质数据进行学习,GPT-3的训练过程中根据数据来源的差异调整了采样权重。在完成3000亿词元的训练量时,英文版Wikipedia的数据平均被循环利用了3.4次,而CommonCrawl和Books2的数据循环使用率分别仅为0.44次和0.43次。鉴于CommonCrawl数据集的筛选工作极为复杂,Meta公司的研究团队在训练OP模型时采纳了结合RoBERTa、Pile[68]以及PushShift.io Reddit数据的策略。考虑到这些数据集主要以英文为主,OPT模型也从CommonCrawl中提取了一部分非英文数据以丰富训练语料。大型语言模型所需的数据资源大致可分为通用数据和专业数据两类。通用数据涵盖了网页内容、图书、新闻报道、对话文本等,以其庞大的规模、多样性和易于获取的特点,为大型语言模型提供了基础的语言建模和泛化能力。而专业数据则包括多语言资料、科学文献、编程代码以及特定领域的专有信息等,这些在预训练阶段的引入,能够显著增强大型语言模型解决特定任务的能力。
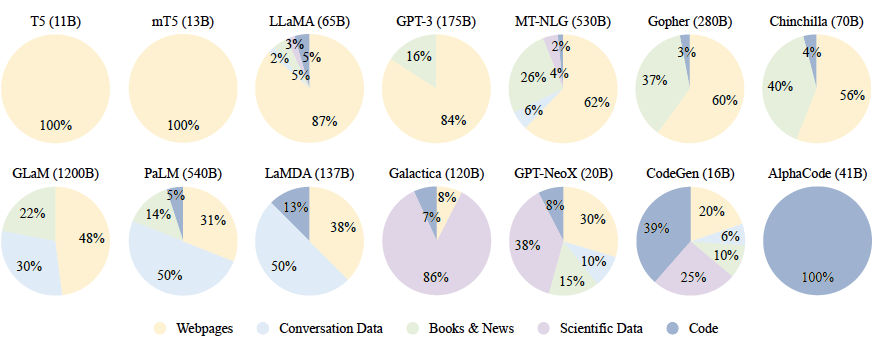
图1 典型大语言模型所使用数量类型的分布
1.1 通用数据
通用数据在大型语言模型训练数据中占比通常非常高,主要包括网页、书籍、对话文本等类型,为大型语言模型提供了大规模且多样的训练数据。网页(Webpages)是通用数据中数量最大的一类。随着互联网的大规模普及,人们通过网站、论坛、博客、APP等各种类型网站和应用,创造了海量的数据。根据2016年Google公开的数据,其搜索引擎索处理了超过130万亿网页¹。网页数据所包含的海量内容,使得语言模型能够获得多样化的语言知识并增强其泛化能力。爬取和处理这些海量网页内容并不是一件容易的事情,因此一些研究人员构建了包括ClueWeb09、ClueWeb12、SogouT-16、CommonCrawl等在内的开源网页数据集。
但是,这些爬取的网络数据虽然包含大量高质量的文本,如维基百科,但也包含非常多的低质量的文本,如垃圾邮件等。因此,如何过滤和处理网页以提高质量数据对于大型语言模型训练来说非常重要。对话数据(Conversation Text)是指包含两个或更多参与者之间交流的文本内容。对话数据包含书面形式的对话、聊天记录、论坛帖子、社交媒体评论等。当前的一些研究也表明,对话数据可以有效增强语言模型的对话能力,并潜在地提高其在多种问答任务上的表现。对话数据可以通过收集、清洗、归并等过程从社会媒体、论坛、邮件组等构建。相较于网页数据,对话数据收集和处理更加困难,数据数量也相对少非常多。常见的对话数据集包括PushShift.io Reddit、Ubuntu Dialogue Corpus、Douban Conversation Corpus、Chromium Conversations Corpus等。此外,文献也提出了如何使用大型语言模型自动生成对话数据的UltraChat方法。书籍(Book)是人类知识的主要积累方式之一,从古代经典著作到现代学术著述,书籍承载了丰富多样的人类思想。书籍通常包含广泛的词汇,包括专业术语、文学表达以及各种主题词汇
通过引入书籍作为训练材料,语言模型得以接触丰富的词汇资源,这极大地提升了模型对不同领域和主题的理解力。与其他类型的语料相比,书籍通常提供了更加丰富和完整的长篇文本材料,它们是获取长文本书面语数据的主要,有时甚至是唯一来源。书籍中的完整句子和段落结构使得语言模型能够学习并理解上下文之间的联系,这对于模型把握句子的复杂结构、逻辑关系以及语义连贯性至关重要。书籍内容包括了多种文体和风格,如小说、科学论著、历史文献等,训练时使用这些书籍数据能够让模型掌握多样的写作风格和表达技巧,从而增强模型在处理各类文本时的能力。然而,由于版权的限制,能够开源使用的书籍数据集并不多见。目前,大型语言模型的研究工作常常采用Pile数据集中的Books3和Bookcorpus2数据集作为训练资源。
2.1 专业数据
专业数据虽在大型通用语言模型的训练数据中所占比重不高,但其对于提升模型在特定下游任务中的表现具有关键性作用。专业数据的类型繁多,而目前大型语言模型训练中常用的专业数据主要包括以下三类:
1. 多语言数据:这类数据包含了除英语以外的多种语言资源,它们对于构建能够理解和生成多语言文本的模型至关重要。多语言数据的引入能够帮助模型更好地服务于全球用户,提高其跨语言的交流能力和文化敏感性。
2. 科学文本:科学文本包括但不限于学术论文、研究报告、专业期刊等,这些文本通常包含专业术语和复杂概念。通过训练模型理解和处理这类文本,可以显著提高模型在学术研究和专业知识领域的应用能力。
3. 代码:代码数据涉及各种编程语言的源代码,这对于开发能够理解和生成代码的模型尤为重要。模型通过学习代码的结构和语法,可以在软件开发、代码审查和自动编程等任务中发挥作用。
二、数据处理
大语言模型的相关研究表明,数据质量对于模型的影响非常大。因此在收集到各类型数据之后,需要对数据进行处理,去除低质量数据、重复数据、有害信息、个人隐私等内容[14, 85]。典型的数据处理过程如图3.1所示,主要包含质量过滤、冗余去除、隐私消除、词元切分等几个步骤。本节将依次介绍上述内容。

图2 典型大语言模型数据处理流程图
2.1 低质过滤
互联网上的数据质量参差不齐,无论是OpenAI 联合创始人Andrej Karpathy 在微软Build 2023的报告,还是当前的一些研究都表明,训练数据的质量对于大语言模型效果具有非常重要的影响。因此,如何从收集到的数据中删除低质量数据成为大语言模型训练中的重要步骤。大语言模型训练中所使用的低质量数据过滤方法可以大致分为两类:基于分类器的方法和基于启发式的方法。基于分类器的方法目标是训练文本质量判断模型,并利用该模型识别并过滤低质量数据。GPT-3、PALM 以及GLam模型在训练数据构造时都使用了基于分类器的方法。 采用基于特征哈希的线性分类器(Feature Hash Based Linear Classifier),可以非常高效地完成文本质量判断。该分类器使用一组精选文本(维基百科、书籍和一些选定的网站)进行训练,目标是将与训练数据类似的网页给定较高分数。利用这个分类器可以评估网页的内容质量。在实际应用中,还可以通过使用Pareto 分布对网页进行采样,根据其得分选择合适的阈值,从而选定合适的数据集合。但是,一些研究也发现,基于分类器的方法可能会删除包含方言或者口语的高质量文本,从而损失一定的多样性。基于启发式的方法则通过一组精心设计的规则来消除低质量文本,BLOOM 和Gopher采用了基于启发式的方法。这些启发式规则主要包括:
• 语言过滤:如果一个大语言模型仅关注一种或者几种语言,那么就可以大幅度的过滤掉数据中其他语言的文本。
• 指标过滤:利用评测指标也可以过滤低质量文本。例如,可以使用语言模型对于给定文本的困惑度(Perplexity)进行计算,利用该值可以过滤掉非自然的句子。
• 统计特征过滤:针对文本内容可以计算包括标点符号分布、符号字比(Symbol-to-Word Ratio)、句子长度等等在内的统计特征,利用这些特征过滤低质量数据。
• 关键词过滤:根据特定的关键词集,可以识别和删除文本中的噪声或无用元素,例如,HTML标签、超链接以及冒犯性词语等。
在大语言模型出现之前,在自然语言处理领域已经开展了很多文章质量判断(Text Quality Evaluation)相关研究,主要应用于搜索引擎、社会媒体、推荐系统、广告排序以及作文评分等任务中。
在搜索和推荐系统中,结果的内容质量是影响用户体验的的重要因素之一,因此,此前很多工作都是针对用户生成内容(User-Generated Content,UGC)质量进行判断。自动作文评分也是文章质量判断领域的一个重要子任务,自1998 年文献[87] 提出了使用贝叶斯分类器进行作文评分预测以来,基于SVM[88]、CNN-RNN[89]、BERT[90, 91] 等方法的作文评分算法也相继提出,并取得了较大的进展。这些方法也都可以应用于大语言模型预训练数据过滤中。但是由于预训练数据量非常大,并且对于质量判断的准确率并不要求非常高,因此一些基于深度学习以及基于预训练的方法还没有应用于低质过滤过滤中。
2.2 冗余去除
文献指出大语言模型训练语料库中的重复数据,会降低语言模型的多样性,并可能导致训练过程不稳定,从而影响模型性能。因此,需要对预训练语料库中的重复进行处理,去除其中的冗余部分。文本冗余发现(Text Duplicate Detection)也称为文本重复检测,是自然语言处理和信息检索中的基础任务之一,其目标是发现不同粒度上的文本重复,包括句子、段落以及文档等不同级别。冗余去除就是在不同的粒度上进行去除重复内容,包括句子、文档和数据集等粒度的重复。在句子级别上,文献 指出,包含重复单词或短语的句子很可能造成语言建模中引入重复的模式。这对语言模型来说会产生非常严重的影响,使得模型在预测时容易陷入重复循环(RepetitionLoops)。例如,使用GPT-2 模型,对于给定的上下文:“In a shocking finding, scientist discovereda herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Evenmore surprising to the researchers was the fact that the unicorns spoke perfect English.”。如果使用束搜索(Beam Search),在设置b = 32 时,模型就会产生如下输出,进入了重复循环模式。“Thestudy, published in the Proceedings of the National Academy of Sciences of the United States of America(PNAS), was conducted by researchers from the Universidad Nacional Autónoma de México (UNAM)and the Universidad Nacional Autónoma de México (UNAM/Universidad Nacional Autónoma de México/ Universidad Nacional Autónoma de México/Universidad Nacional Autónoma de México/Universidad Nacional Autónoma de ...”。由于重复循环对于语言模型生成的文本质量有非常大的影响,因此在预训练语料中需要删除这些包含大量重复单词或者短语的句子。
RefinedWeb 构造过程中也进行了句子级别的过滤。使用了文献所提出的过滤方法,提取并过滤文档间超过一定长度的相同字符串。给定两个文档xi 和xj,其中存在长度为k 的公共子串xa...a+ki = xb...b+kj 。当k ⩾ 50 时,就将其中一个子串过滤。公共子串匹配的关键是如何高效完成字符串匹配,文献[64] 将整个文档D 转换为一个超长的字符串序列S,之后构造序列S 的后缀数组(Suffix Array)A。
该数组包含在该序列中的所有后缀的按字典顺序排列的列表。具体而言,后缀数组A是一个整数数组,其中每个元素表示S 中的一个后缀的起始位置。按照字典顺序,A中的元素按照后缀的字典顺序排列。例如,序列“banana”的后缀包括“banana”,“anana”,“nana”,“ana”,“na”和“a”,对应的后缀数组A 为[6, 4, 2, 1, 5, 3]。根据数组A,可以很容易的找出相同的子串。如果S i..i+|s| = S j..j+|s|,那么i 和j 在数组A 中一定在紧邻的位置上。
文献 中设计了并行的后缀数组构造方法,针对Wiki-40B 训练语料(约包含4GB 文本内容),使用拥有96 核CPU 以及768GB 内存的服务器,可以在2.3 分钟内完成计算。对于包含350GB 文本的C4 数据集合,仅需要12 小时可以完成后缀数组构造。在文档级别上,大部分大语言模型都是依靠文档之间的表面特征相似度(例如n-gram 重叠比例)进行检测并删除重复文档[33, 37, 64, 94]。
LLaMA 采用CCNet的处理模式,首先将文档拆分为段落,并把所有字符转换为小写字符、将数字替换为占位符,以及删除所有Unicode 标点符号和重音符号来对每个段落进行规范化处理。然后,使用为SHA-1 方法为每个段落计算一个哈希码(Hash Code),并使用前64 位数字作为键。最后,利用每个段落的键进行重复判断。RefinedWeb[64]首先去除掉页面中菜单、标题、页脚、广告等内容,仅抽取页面中的主要内容。在此基础上,在文档级别进行过滤,采用与文献提到类似的方法,使用n-gram 重叠程度来衡量句子、段落以及文档的相似度。如果重复程度超过预先设定的阈值,则会过滤掉重复段落或文档。
此外,数据集层面也可能存在一定数量的重复情况,比如很多大语言模型预训练集合都会包含GitHub、Wikipedia、C4 等数据集。还需要特别注意的是,预训练语料中混入测试语料,从而造成数据集污染的情况。在实际产生预训练数据时,需要从数据集、文档以及句子三个级别去除重复,这对于改善语言模型的训练具有重要的作用[14, 96]
2.3 隐私消除
由于绝大多数预训练数据源于互联网,因此不可避免地会包含涉及敏感或个人信息(PersonallyIdentifiable Information,PII)的用户生成内容,这可能会增加隐私泄露的风险。如图2.2所示,输入前缀词“East Stroudsburg Stroudsburg”,语言模型在此基础上补全了姓名、电子邮件地址、电话号码、传真号码以及实际地址。这些信息都是模型从预训练语料中学习得到的。因此,有非常必要从预训练语料库中删除包含个人身份信息的内容。
删除隐私数据最直接的方法是采用基于规则的算法,BigScience ROOTS Corpus 构建过程从大语言模型中获得隐私数据的例子中就是采用了基于命名实体识别的方法,利用命名实体识别算法检测姓名、地址和电话号码等个人信息内容并进行删除或者替换。该方法使用了基于Transformer 的模型,并结合机器翻译技术,可以处理超过100 种语言的文本,消除其中的隐私信息。该算法被集成在muliwai 类库中。
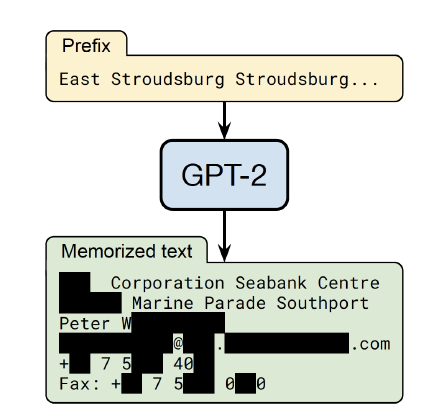
图3 从大语言模型中获得隐私数据的例子
2.4 词元切分
传统的自然语言处理通常以单词为基本处理单元,模型都依赖预先确定的词表V,在编码输入词序列时,这些词表示模型只能处理词表中存在的词。因此,在使用中,如果遇到不在词表中的未登录词,模型无法为其生成对应的表示,只能给予这些未登录词(Out-of-vocabulary,OOV)一个默认的通用表示。在深度学习模型中,词表示模型会预先在词表中加入一个默认的“[UNK]”(unknown)标识,表示未知词,并在训练的过程中将[UNK] 的向量作为词表示矩阵的一部分一起训练,通过引入某些相应机制来更新[UNK] 向量的参数。在使用时,对于全部的未登录词,都使用[UNK] 的向量作为这些词的表示向量。此外,基于固定词表的词表示模型对词表大小的选择比较敏感。当词表大小过小时,未登录词的比例较高,影响模型性能。而当词表大小过大时,大量低频词出现在词表中,而这些词的词向量很难得到充分学习。理想模式下,词表示模型应能覆盖绝大部分的输入词,并避免词表过大所造成的数据稀疏问题。
为了缓解未登录词问题,一些工作通过利用亚词级别的信息构造词表示向量。一种直接的解决思路是为输入建立字符级别表示,并通过字符向量的组合来获得每个单词的表示,以解决数据稀疏问题。然而,单词中的词根、词缀等构词模式往往跨越多个字符,基于字符表示的方法很难学习跨度较大的模式。为了充分学习这些构词模式,研究人员们提出了子词词元化(Subword Tokenization)方法,试图缓解上文介绍的未登录词问题。词元表示模型会维护一个词元词表,其中既存在完整的单词,也存在形如“c”, “re”, “ing”等单词部分信息,称为子词。词元表示模型对词表中的每个词元计算一个定长向量表示,供下游模型使用。对于输入的词序列,词元表示模型将每个词拆分为词表内的词元。例如,将单词“reborn”拆分为“re”和“born”。模型随后查询每个词元的表示,将输入重新组成为词元表示序列。当下游模型需要计算一个单词或词组的表示时,可以将对应范围内的词元表示合成为需要的表示。因此,词元表示模型能够较好地解决自然语言处理系统中未登录词的问题。词元分析(Tokenization)目标是将原始文本分割成由词元(Token)序列的过程。词元切分也是数据预处理中至关重要的一步。
字节对编码(Byte Pair Encoding,BPE)模型[99] 是一种常见的子词词元模型。该模型所采用的词表包含最常见的单词以及高频出现的子词。在使用中,常见词通常本身位于BPE 词表中,而罕见词通常能被分解为若干个包含在BPE 词表中的词元,从而大幅度降低未登录词的比例。BPE算法包括两个部分:(1)词元词表的确定;(2)全词切分为词元以及词元合并为全词的方法。计算过程如图4所示。
首先,确定语料库中全词的词表和词频,然后将每个单词切分为单个字符的序列,并在序列最后添加符号“</w>”作为单词结尾的标识。比如单词“low”被切分为序列“l␣o␣w␣</w>”。所切分出的序列元素称为字节,即每个单词都切分为字节的序列。之后,按照每个字节序列的相邻字节对和单词的词频,统计每个相邻字节对的出现频率,合并出现频率最高的字节对,将其作为新的词元加入词表,并将全部单词中的该字节对合并为新的单一字节。如图4所示,在第一次迭代时,出现频率最高的字节对是(e,s),故将“es”作为词元加入词表,并将全部序列中相邻的(e,s)字节对合并为es 字节。重复这一步骤,直至BPE 词元词表的大小达到指定的预设值,或没有可合并的字节对为止。
在词元词表确定之后,对于输入词序列中未在词表中的全词进行切分,BPE 算法对词表中的词元按从长到短的顺序进行遍历,用每一个词元和当前序列中的全词或未完全切分为词元的部分进行匹配,将其切分为该词元和剩余部分的序列。例如,对于单词“lowest</w>”,首先通过匹配词元“est</w>”将其切分为“low”, “est</w>”的序列,再通过匹配词元“low”,确定其最终切分结果为“low”, “est</w>”的序列。通过这样的过程,BPE 尽量将序列中的词切分成已知的词元。在遍历词元词表后,对于切分得到的词元序列,为每个词元查询词元表示,构成词元表示序列。若出现未登录词元,即未出现在BPE 词表中的词元,则采取和未登录词类似的方式,为其赋予相同的表示,最终获得输入的词元表示序列。
此外,字节级(Byte-level)BPE 通过将字节视为合并的基本符号,用来改善多语言语料库(例如包含非ASCII 字符的文本)的分词质量。GPT-2、BART 和LLaMA 等大语言模型都采用了这种分词方法。原始LLaMA 的词表大小是32K,并且主要根据英文进行训练,因此,很多汉字都没有直接出现在词表中,需要字节来支持所有的中文字符,由2 个或者3 个Byte Token 才能拼成一个完整的汉字。
对于使用了字节对编码的大语言模型,其输出序列也是词元序列。对于原始输出,根据终结语符</w> 的位置确定每个单词的范围,合并范围内的词元,将输出重新组合为词序列,作为最终的结果。WordPiece也是一种常见的词元分析算法,最初应用于语音搜索系统。此后,该算法做为BERT 的分词器。WordPiece 与BPE 有非常相似的思想,都是通过迭代地合并连续的词元,但在合并的选择标准上略有不同。为了进行合并,WordPiece 需要首先训练一个语言模型,并用该语言模型对所有可能的词元对进行评分。在每次合并时,选择使得训练数据似然概率增加最多的词元对。
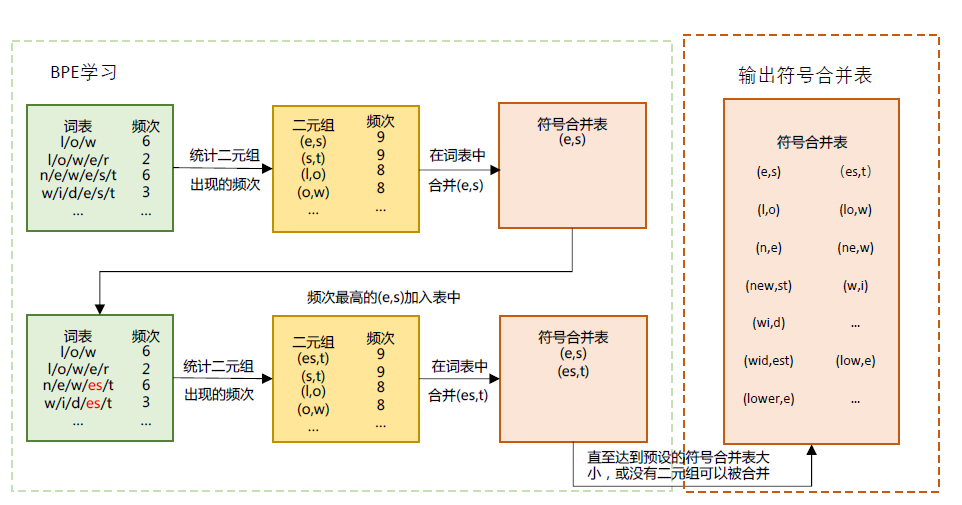
图4 BPE 模型中词元词表的计算过程
由于Google 并没有发布其WordPiece 算法的官方实现,HuggingFace 在其在线NLP 课程中提供了一种更直观的选择度量方法:一个词元对的评分是根据训练语料库中两个词元的共现计数除以它们各自的出现计数的乘积。计算公式如下所示:

Unigram 词元分析 是另外一种应用于大语言模型的词元分析方法,T5 和mBART 采用该方法构建词元分析器。不同于BPE 和WordPiece,Unigram 词元分析从一个足够大的可能词元集合开始,然后迭代地从当前列表中删除词元,直到达到预期的词汇表大小为止。基于训练好的Unigram语言模型,使用从当前词汇表中删除某个字词后,训练语料库似然性的增加量作为选择标准。为了估计一元语言(Unigram)模型,采用了期望最大化(Expectation–Maximization,EM)算法:每次迭代中,首先根据旧的语言模型找到当前最佳的单词切分方式,然后重新估计一元语言单元概率以更新语言模型。在这个过程中,使用动态规划算法(如维特比算法)来高效地找到给定语言模型时单词的最佳分解方式。以HuggingFace NLP 课程中介绍的Byte Pair Encoding 代码为例,介绍BPE 方法的构建和使
用,代码实现如下所示:
- from transformers import AutoTokenizer
- from collections import defaultdict
- corpus = [
- "This is the Hugging Face Course.",
- "This chapter is about tokenization.",
- "This section shows several tokenizer algorithms.",
- "Hopefully, you will be able to understand how they are trained and generate tokens.",
- ]
- # 使用GPT-2 tokenizer 将输入分解为单词:
- tokenizer = AutoTokenizer.from_pretrained("gpt2")
- word_freqs = defaultdict(int)
- for text in corpus:
- words_with_offsets = tokenizer.backend_tokenizer.pre_tokenizer.pre_tokenize_str(text)
- new_words = [word for word, offset in words_with_offsets]
- for word in new_words:
- word_freqs[word] += 1
- # 计算基础词典, 这里使用语料库中的所有字符:
- alphabet = []
- for word in word_freqs.keys():
- for letter in word:
- if letter not in alphabet:
- alphabet.append(letter)
- alphabet.sort()
- # 增加特殊Token 在字典的开头,GPT-2 中仅有一个特殊Token``<|endoftext|>''表示文本结束
- vocab = ["<|endoftext|>"] + alphabet.copy()
-
- # 将单词切分为字符
- splits = {word: [c for c in word] for word in word_freqs.keys()}
- #compute_pair_freqs 函数用于计算字典中所有词元对的频率
- def compute_pair_freqs(splits):
- pair_freqs = defaultdict(int)
- for word, freq in word_freqs.items():
- split = splits[word]
- if len(split) == 1:
- continue
- for i in range(len(split) - 1):
- pair = (split[i], split[i + 1])
- pair_freqs[pair] += freq
- return pair_freqs
-
- #merge_pair 函数用于合并词元对
- def merge_pair(a, b, splits):
- for word in word_freqs:
- split = splits[word]
- if len(split) == 1:
- continue
- i = 0
- while i < len(split) - 1:
- if split[i] == a and split[i + 1] == b:
- split = split[:i] + [a + b] + split[i + 2 :]
- else:
- i += 1
- splits[word] = split
- return splits
- # 迭代训练,每次选取得分最高词元对进行合并,直到字典大小达到设置目标为止:
- vocab_size = 50
-
- while len(vocab) < vocab_size:
- pair_freqs = compute_pair_freqs(splits)
- best_pair = ""
- max_freq = None
- for pair, freq in pair_freqs.items():
- if max_freq is None or max_freq < freq:
- best_pair = pair
- max_freq = freq
- splits = merge_pair(*best_pair, splits)
- merges[best_pair] = best_pair[0] + best_pair[1]
- vocab.append(best_pair[0] + best_pair[1])
- # 训练完成后,tokenize 函数用于给定文本进行词元切分
- def tokenize(text):
- pre_tokenize_result = tokenizer._tokenizer.pre_tokenizer.pre_tokenize_str(text)
- pre_tokenized_text = [word for word, offset in pre_tokenize_result]
- splits = [[l for l in word] for word in pre_tokenized_text]
- for pair, merge in merges.items():
- for idx, split in enumerate(splits):
- i = 0
- while i < len(split) - 1:
- if split[i] == pair[0] and split[i + 1] == pair[1]:
- split = split[:i] + [merge] + split[i + 2 :]
- else:
- i += 1
- splits[idx] = split
- return sum(splits, [])
- tokenize("This is not a token.")

Huggingface 的transformer 类中已经集成了很多分词器,可以直接使用。例如,利用BERT 分词器获得输入“I have a new GPU!”的词元代码如下所示:
- >>> from transformers import BertTokenizer
- >>> tokenizer = BertTokenizer.from_pretrained("bert-base-uncased")
- >>> tokenizer.tokenize("I have a new GPU!")
- ["i", "have", "a", "new", "gp", "##u", "!"]
参考内容:
(1) 收藏丨30个大语言模型训练相关的数据集分享 - 知乎. https://zhuanlan.zhihu.com/p/612243919.
(2) 大语言模型训练数据常见的4种处理方法 - 知乎. https://zhuanlan.zhihu.com/p/673045395.
(3)《大规模语言模型:从理论到实践》张奇等著. —北京:电子工业出版社
(4) 大语言模型综述 - Renmin University of China. http://ai.ruc.edu.cn/research/science/20230605100.html.

