
- 1ImportError: DLL load failed: 找不到指定的模块 解决方案汇总_importerror:dll load failed
- 2缓存踩踏:Facebook史上最严重的宕机事件分析
- 3ContextCapture(Smart3D)总结(1)——构建空三模型(S3C,OSGB,DOM)_contextcapture进行空三
- 4Kubernetes API Server 认证机制_token-auth-file
- 5[源码和文档分享]基于python的中文聊天机器人
- 6成功解决自己写的模块包导入问题ModuleNotFoundError: No module named ‘core‘报错_modulenotfounderror: no module named 'core
- 7几种常见算法的介绍及复杂度分析 _因式分解 复杂度 n
- 8有哪些好用不火的软件?_实验楼怎么样csdn
- 9程序员的实用神器,16款程序员生产力工具推荐_代码调试需要什么软件
- 10MySQL用户和权限管理_将school数据库的操作权限赋予数据库用户张三
Deepseek-Coder技术文档阅读和预处理探索_deepseek coder
赞
踩
家族组成
https://huggingface.co/deepseek-ai?search_models=Deepseek-coder

效果展示
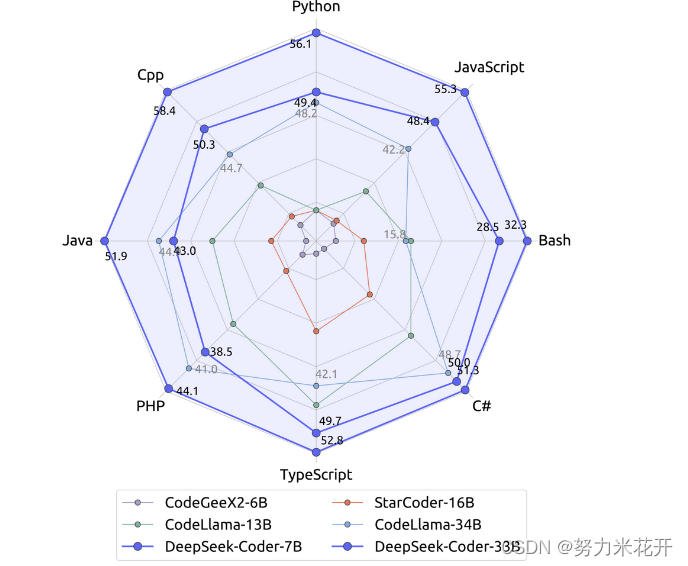
效果可以说是全方位的碾压其他的coder大模型。
数据处理
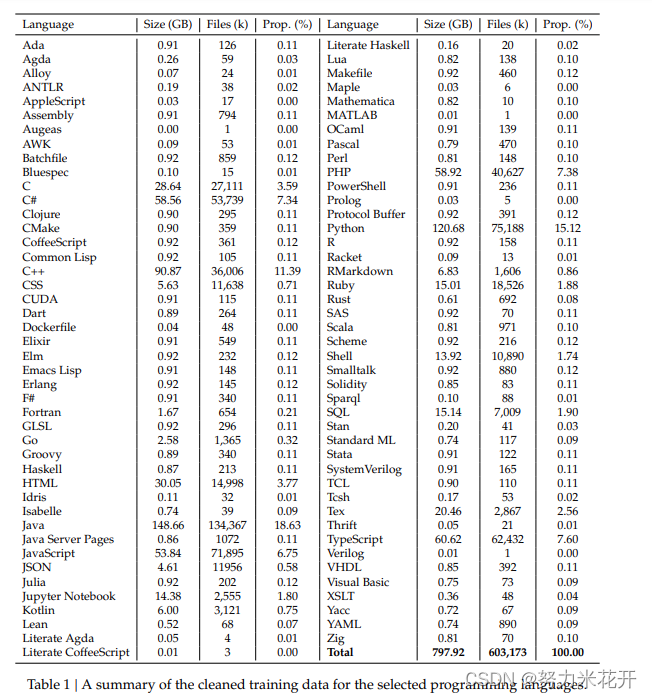
训练数据的选择:一共是87%的源代码,10%的英文的代码相关的自然语言预料,3%的中文的代码不相关的自然语言预料。英文预料来自于GitHub’s Markdown and StackExchange,用于增强模型的关于代码概念的理解能力和解决类似于库使用和问题修复相关的问题解决能力的。中文预料来自于高质量的文章,用于提升模型的中文理解能力。
所有的处理步骤可以分为下图中的五个步骤,其中步骤一和步骤二在论文中合并来说了。

步骤1:从 GitHub 收集代码数据,并利用过滤规则高效地筛选数据。
一共选择了87种编程语言;
1. 在语言的选择时需要规定每个后缀名对应的语言类型,需要过滤掉同一个后缀对应多中语言的文件,需要过滤掉没有价值的后缀名文件。
2. 另外采用了starcoder中相同的方式来过滤低质量的代码,过滤后的代码只有过滤前代码的32.8%;这个过程主要是过滤掉数据量重的文件(比如样例数据等等)
1.1 预料选择——语言选择
构建一个从语言到后缀名的表单,这样在遍历到某个文件的时候,可以快速将文件进行归类。
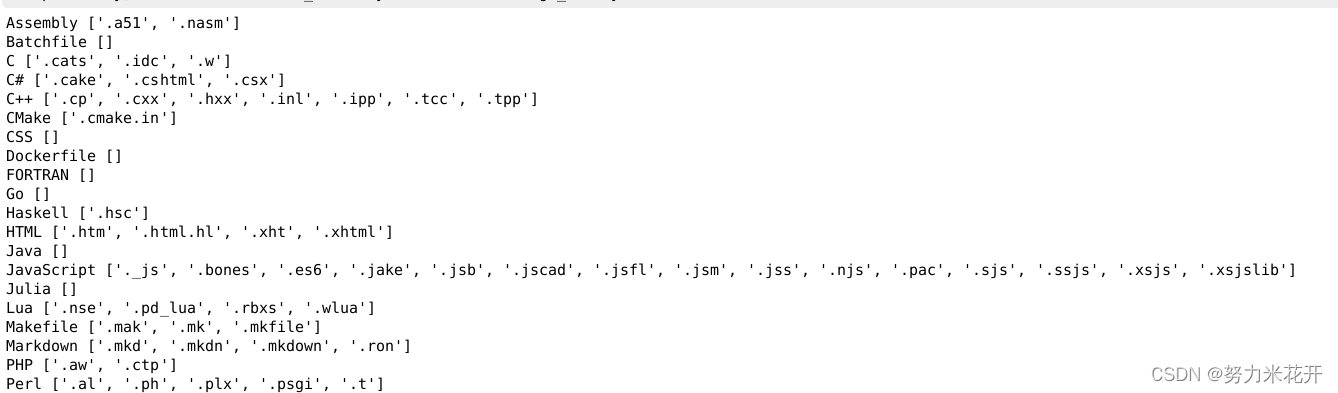
a. 对于同一个后缀名可能存在多种语言映射的情况,对后缀名强行确保一个唯一的语言类型(删除或者唯一指定)
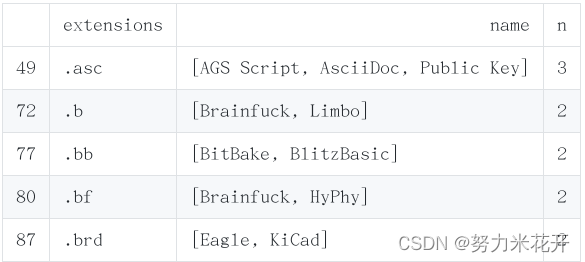
b. 对于同一个语言的不同表示进行统一规定

c. 对于没有价值的后缀名文件,直接删除

1.2 识别个人信息并实现匿名化处理
主要用于检查姓名、email、IP地址、密码、ssh登录信息等等。
a. 训练一个命名实体识别的NLP模型
已有的模型为StartPII(https://huggingface.co/bigcode/starpii),论文可以参考StarCoder: May The Source Be With You。
如果需要自己训练,可以采用代码https://github.com/bigcode-project/bigcode-dataset/tree/main/pii实现自己训练。
该模型可以是实现在A100-80G环境下,通过800 GPU-hours识别800G数据量中的PII元素。对于检测到的私密元素,通过下面这些tokens来替换:, , , ;对于IP地址则通过从5~个相同类型的合成的、私有的、非面向internet的IP地址中随机选择一个IP地址。
b. 采用正则表达式的方式
b.1 传统的正则表达式用于检测时间、IP地址、email地址
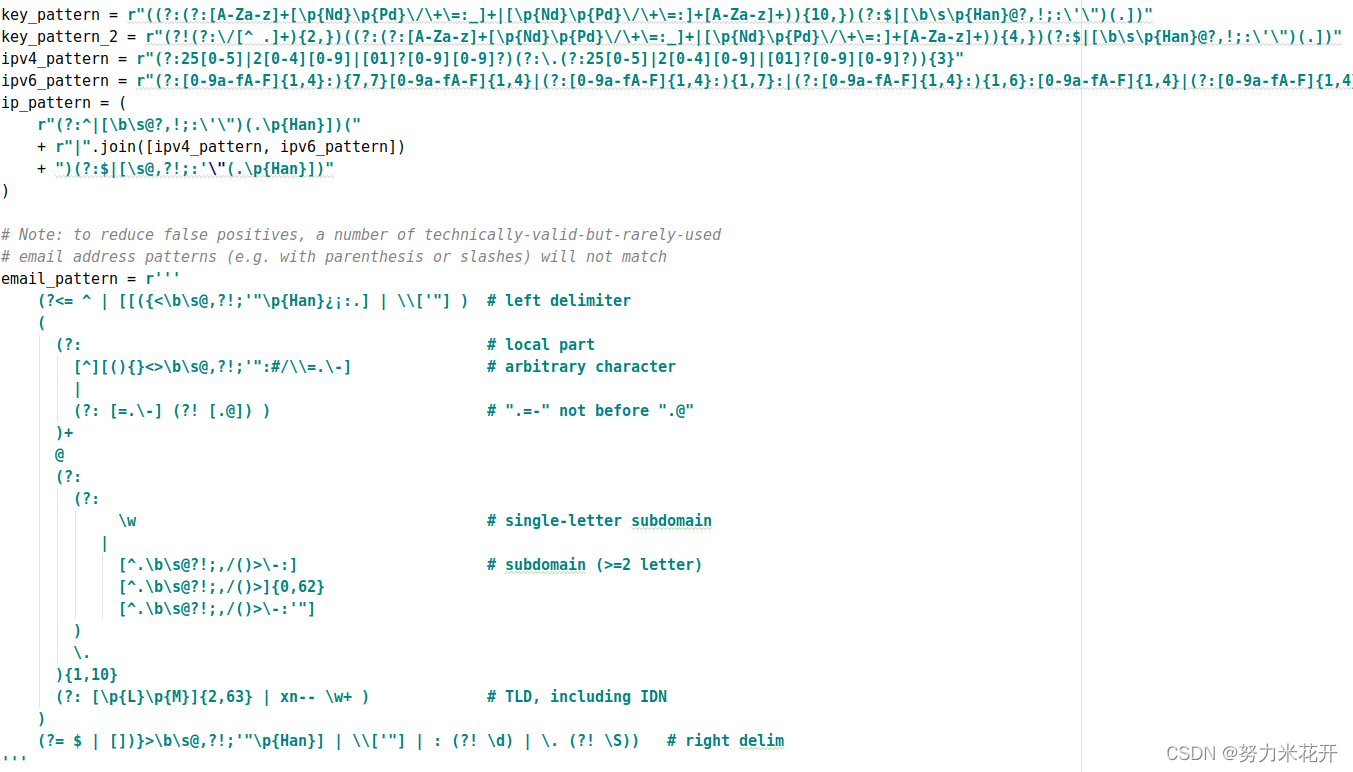
b.2采用开源项目detect-secrets来检测cicd代码中可能存在的秘钥
detect-secrets是一个用于在github上检测自动部署环节是否会存在私密泄露风险的代码。
然后用随机生成的秘钥替换代码中的秘钥。
1.3 预处理过滤低质量代码
a. 统计单行长度、统计字母数字占比。单行长度小于1000,字母数字占比大于25;
b. github上打星的数量,打星数量大于5的代码;
c. 过滤注释,如果文件的注释/总字母0.8,那么进行过滤;
d. 基于特定的tokenizer模型生成token,然后计算len(text)/len(token)小于阈值,则需要删除。认为代码的丰富度(fertility)不够?
e. 基于显示文本/代码比例实现HTML文件的过滤
f. 过滤xml文件,过滤很大的或者很小的json和.yaml文件
其他的可选预处理
g. 过滤github上的issues
h. 过滤github上的commits
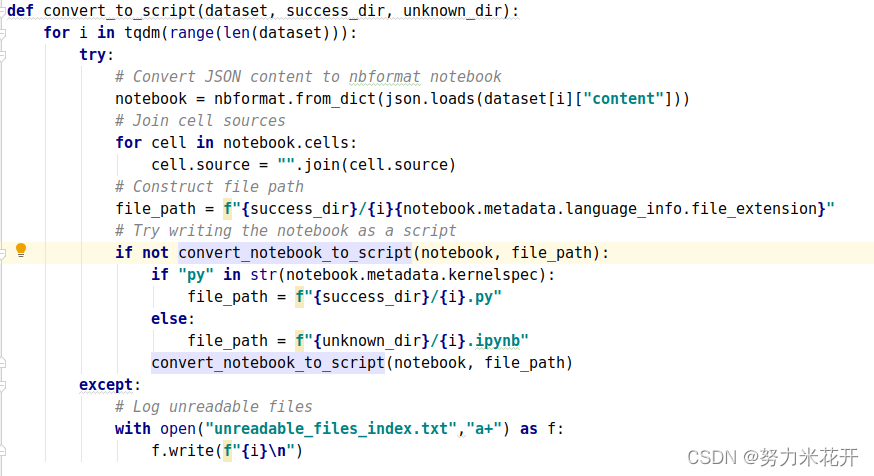
i. 将json格式保存的github上的jupyter_notebook转换为script格式
步骤2:解析同一项目中代码文件之间的依赖关系,根据它们的依赖关系重新排列文件位置。
在之前的大模型训练中,只关注文件级别的源代码,忽略了同一个项目中的不同文件之间的关联关系。但是现实的使用情况却相反,大模型必须处理整个项目级别的代码场景。在处理预料的过程中,作者团队首先将代码按照彼此之间的依赖关系排序,确保在生成语料的时候,被依赖的文件内容在前面,依赖的文件内容在后面。这种排序是通过拓扑算法实现的,在实现时,采用python文件中的import、C#代码中的using和C语言中的include来实现识别该文件的依赖文件的。
实现的算法如下所示,不同于传统的拓扑排序,这里不是从入度为0的点开始的,而是从入度最小的点(也就是文件)开始的,这意味着允许代码中出现环的情况。

步骤3:组织依赖文件,并使用项目级别的 minhash 算法进行去重。
为什么需要去重,因为研究表明去重训练数据可以有效的提升LLM模型的表现。之前有一篇论文是关于如何对训练数据进行near-deduplication(Transactions on Machine Learning Research,2022)。和之前这篇论文的区别是,之前的这篇文章是针对文件级别的去重,但是在这里不合适,因为这里的代码是项目级的,如果去除了内部的文件,会影响彼此之间的依赖,影响整个项目的结构。因此是将整个项目的代码看成一个整体样本,然后再项目上实现去重算法。
步骤4:进一步过滤掉低质量的代码
例如语法错误或可读性差的代码、和测试数据集一致的代码
这里和步骤1中提到的采用过滤规则来过滤低质量的代码不同,这里的代码过滤采用了一个编译器以及一个质量评估模型,来进一步的减少低质量的代码数据。这里的低质量数据包括:拼写错误的,低可读性的,低模块化的。
除了删除低质量的代码, 为了确保预训练数据不被来自测试集数据污染(比如类似HumanEval和MBPP等普遍存在于GitHub上),我们采纳了一个n-gram过滤方法:如果一段代码包含与测试数据中任何10-gram字符串相同的内容,则会被从预训练数据中删除。
4.1 删除评估基准中的测试样本
a. 完全匹配法去除
训练时需要删除评估标准数据集中的测试样例,比如
1. HumanEval
2. MBPP
3. APPS
4. GSM8K
5. DS-1000 benchmark
采用完全匹配的方式,逐个查找预料中是否存在上述评估数据集中的测试样例/描述、prompts等等信息。
b. MinHash和LSH(局部敏感哈希)实现准完全匹配
同样的将需要检测的评估数据集加载之后,对于每条语料通过minhash或者LSH的方式计算相似度,如果相似度高于阈值,那么就进行预料的删除操作。
数据汇总
模型的训练策略
简单的来说
步骤1:使用 4K 的窗口大小在 1.8 万亿单词上进行模型的预训练。数据由87% 的代码,10%的代码相关内容(比如github上的markdown文本和StackExchange上的内容)以及3%的与代码无关的中文语言。
步骤2:使用 16K 的窗口在 2 千亿单词进一步进行预训练,从而得到基础版本模型(DeepSeek-Coder-Base)。
步骤3:使用 20 亿单词的指令数据进行微调,得到经过指令调优的模型(DeepSeek-Coder-Instruct)。

预训练任务
训练任务可以分为两种,一种是Next Token Prediction,一种是Fill-in-the-Middle(FIM)。
这里重点讲一下FIM。
由于编程语言中的特定依赖性,仅根据上文预测下文是不够的,典型的常见如代码补全,需要基于给定上文和后续文本生成相应插入代码。因此我们沿用前人提出的提出了FIM(Fill-in-the-Middle)方法,即:填补中间代码的预训练方法。
这种方法涉及将文本随机分成三部分(Prefix、Middle、Suffix),然后将Prefix和Suffix顺序打乱来预测Middle。具体来说,我们采用了两种不同新的数据拼接模式:PSM(Prefix-Suffix-Middle)和SPM(Suffix-Prefix-Middle)。这两种模式对于增强模型处理代码中各种结构排列的能力非常重要。考虑到尽量保持自然序列关系,最终我们选择了PSM模式。
在如何选择FIM预训练任务的超参数这块,采用了下面的实验方式。采用DeepSeek-Coder-Base 1.3B模型用于验证,只采用python预料进行实验。采用HumanEval-FIM评估数据集作为评估指标,这个评估指标是通过遮蔽代码中的一行,让模型来预测缺失的一行代码的方式进行测试的。在训练过程中,采用不同的训练方式。
从实验结果来看,图3的中间结果是HumanEval-FIM的评估结果,采用100%的FIM预料训练确实可以获得较好的单行代码补全能力,但是这种方式在左侧和右侧的代码完成能力都最差。最后实验取了50%比率的FIM来作为最终的训练策略。

对于FIM任务来说,构建的训练样例中有三个额外的符号。
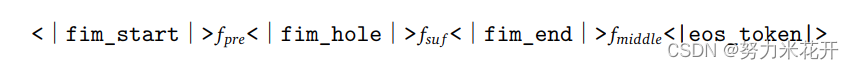
采用的tokenizer策略:采用HuggingFace Tokenizer library训练Byte PairEncoding (BPE) tokenizers。最终的词汇量为32000。
模型结构
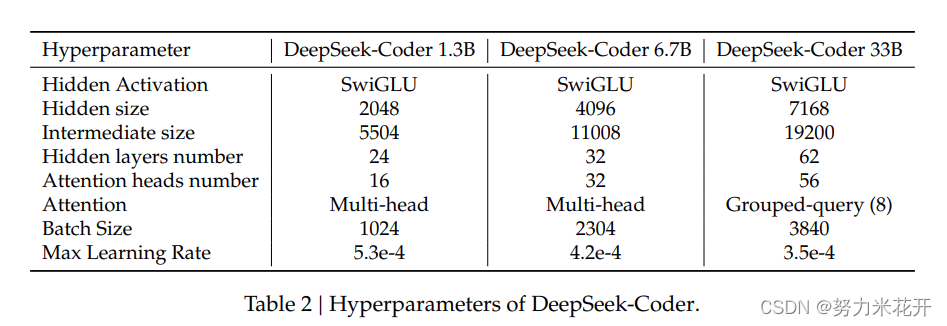
Model ArchitectureWe develop a range of models with varying parameters to cater to diverse applications, includingmodels with 1.3B, 6.7B, and 33B parameters. These models are built upon the same frameworkas the DeepSeek Large Language Model (LLM) outlined by DeepSeek-AI (2024). Each model is adecoder-only Transformer, incorporating Rotary Position Embedding (RoPE) as described by Suet al. (2023). Notably, the DeepSeek 33B model integrates Grouped-Query-Attention (GQA) witha group size of 8, enhancing both training and inference efficiency. Additionally, we employFlashAttention v2 (Dao, 2023) to expedite the computation involved in the attention mechanism.The architectural details of our models are summarized in Table 2.
训练采用的框架为HAI-LLM (High-Flyer, 2023) ,训练的集群中有两类节点,一类是A100,每个节点配置了8GPUs,通过NVLink网桥互联;H800也是8GPU的节点互联,通过NVLink和NVSwitch技术实现互联。在A100和H800集群之间通过InfiniBand实现互联。
扩充输入文本长度
采用RoPE技术实现扩充默认文本窗口。重新配置了RoPE的参数,并采用了线性缩放策略,将缩放因子从1增加到4,并将基础频率从10000改为100000。修改了配置的模型使用了512的Batch Size和16K的序列长度继续训练了1000步。理论上,最终的模型能够处理64K的上下文。但我们实验发现,16K内窗口内的模型结果比较可靠。
指令微调
指令微调采用了高质量的数据来增强基础模型DeepSeek-Coder-Base的指令遵循能力。数据遵循e Alpaca Instruction format(https://github.com/tatsu-lab/stanford_alpaca)项目中的结构。For training, we use a cosine schedule with 100 warm-up steps and an initial learning rate 1e-5. We also use a batch size of 4M tokens and 2B tokens in total.
在alpaca结构中,数据被组织成下面两种形式进行训练,其中instruction表示需要执行的任务,Input表示输入,output表示期望的输出。
在52K的数据中,40% 的数据是有input,其余数据没有input。比如如果instruction是“给出文章的总结”,那么input就是原始的文章内容,因此采用下面挂的第一种数据结构。。如果instruction是“给出保持健康的三个建议”,那么input为空,所以采用第二种数据结构。
alpaca提供了52K的指令对齐数据https://raw.githubusercontent.com/tatsu-lab/stanford_alpaca/main/alpaca_data.json
使用的prompt
- Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
-
- ### Instruction:
- {instruction}
-
- ### Input:
- {input}
-
- ### Response:

