
- 1mysql-xtrabackup 备份恢复_xtrabackup迁移mysql
- 2AI在线文章转换:轻松摆脱文字转录困扰_ai在线转换文章
- 3shell 在线 linux,在线就能用的Linux我给你找好了
- 4[机缘参悟-127] :人的思想体系与架构:三观(世界观、人生观、价值观)详解_人的思想分为几点内容
- 5《MATLAB 神经网络43个案例分析》:第20章 LIBSVM-FarutoUltimate工具箱及GUI版本介绍与使用
- 6jQuery ui effects详细用法_$effect详解
- 7testbench写法注意事项_为什么testbench不用非阻塞赋值
- 8解析葵花熊胆痔灵膏/栓 大广赛赛题细节及顶尖作品分享_葵花熊胆痔灵膏市场分析
- 9FPGA 的数字信号处理:重写 FIR 逻辑以满足时序要求
- 10IDEA项目实践——创建Java项目以及创建Maven项目案例、使用数据库连接池创建项目简介_idea新建java项目
MQ之初识kafka
赞
踩
1. MQ简介
1.1 MQ的诞生背景
以前网络上的计算机(或者说不同的进程)传递数据,通信都是点对点的,而且要实现相同的协议(HTTP、 TCP、WebService)。1983 年的时候,有个在 MIT 工作的印度小伙突发奇想,能不能发明一种专门用来通 信的中间件,就像主板(BUS)一样,把不同的软件集成起来呢?于是他搞了一家公司(Teknekron),开发 了世界上第一个消息队列软件 The Information Bus(TIB)。
1.2 什么是MQ
MQ全称是Message Queue,直译过来叫消息队列,在消息的传输中用于保存消息的容器,主要是作为分布式应用之间实现异步通信的方式。
主要由三部分组成,分别是 生产者、消息服务端和消费者
生产者( Producer ),是生产消息的一端,相当于消息的发起方,主要负责载业务信息的消息的创建。消息服务端( Server ),是处理消息的单元,本质就是用来创建和保存消息队列,它主要负责消息的存储、投递以及跟消息队列相关的附加功能。消息服务端是整个消息队列最核心的组成部分。第三个是消费者( Consumer ),是消费消息的一端,主要是根据消息所承载的信息去处理各种业务逻辑。
何为生产者? 何为消息队列?何为消费者? 举个例子,如下图,第一阶段是爸爸点对点的把书送到儿子手中,即为我们的点对点通信,但后面爸爸发现这种方式即耗时又费力,因此买了个书架,每次只用把书放到书架上就行了,儿子在规定时间内去学完就可以了,后面妈妈也发现了这个好处,于是她也向书架中放书,小明的姐姐也可以去书架上消费。爸爸妈妈就是我们的生产者,书架就是一个消息队列,小明以及小明的姐姐就是消费者。

1.3 MQ的应用场景
1.3.1 应用解耦
由上图可以看出,后面引入了书架后,爸爸就不需要单独给小明书了,因此这是一种应用的解耦。比如我们下面的例子,订单系统模块直接调用库存系统模块,依赖性太强,当某天库存系统出问题时,连带的订单系统模块就也有问题了,我们引入了MQ以后,订单系统只用把消息发布到MQ即可,不管库存系统暂时有没有问题,等它没有问题的时候再去MQ中订阅消息

1.3.2 异步提速
如下图所示,没有使用MQ之前。用户注册,发送邮件,发送短信是同步的,总耗时300ms,而引入MQ之后,用户注册后,只用把消息发送给MQ,然后MQ异步分别发送注册邮件和发送注册短信,注册成功的总耗时就只有110ms.因此MQ可以起到异步提速的作用

1.3.3 限流削峰
几个例子,大家都去饭店吃过饭把,当饭店特别火爆的时候,店长怎么处理了,肯定是不会让你滚蛋把,而是给你一个票进行排队,那么这些排队的方式就是一个削峰的场景,排队的这些号码就是我们的MQ;也就是说,当没有MQ的时候,我们的服务器处理能力有限,当请求全部涌入进来时,就会造成服务器极大的压力,甚至承受不住。当我们引入MQ之后,就可以先把这个请求放到MQ中,服务器根据自己的处理能力去MQ中拿。
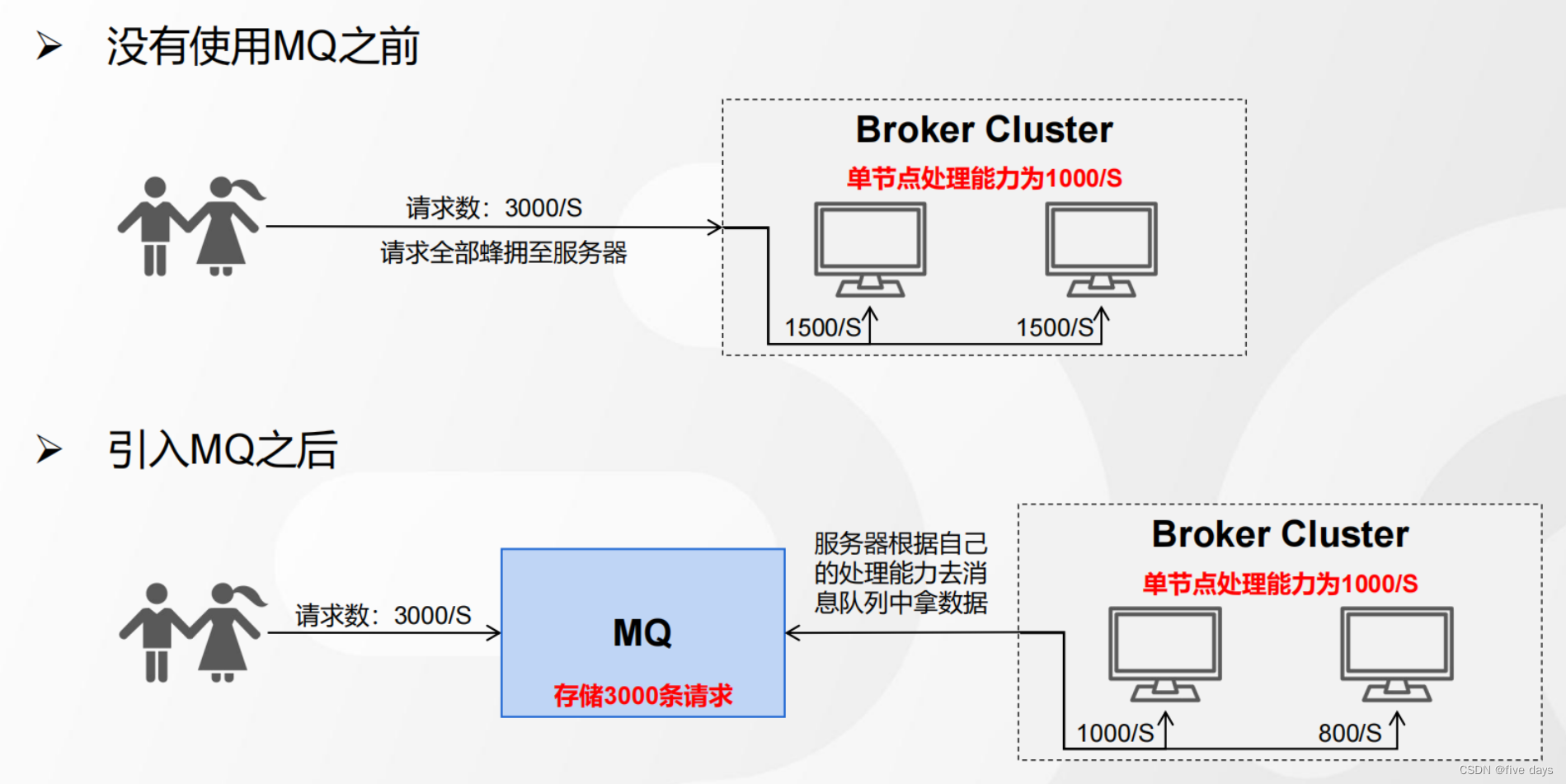
2. Kafka重要组件
kafka是MQ的一种,基于TCP的二进制协议。内部是通过长度来分隔。单机吞吐量支持十万级别。时效性延迟在ms级以内,高可用性,kafaka是分布式的,一个数据多个读本,少数机器宕机,不会丢失数量,不会导致不可用。经过参数的优化配置,消息可以做到0丢失。功能上较为简单,主要支持简单的MQ功能,在大数据领域的实时计算以及日志采集被大规模使用。那么kafaka由哪些组件组成的呢?
2.1 Broker

1.Broker就是Kafka的服务器,用于存储和管理消息,默认是9092的端口
2.生产者和Broker建立连接,将消息发送到服务器上、存储起来
3.消费者跟Broker建立连接,订阅和消费服务器上存储的消息
2.2 Record

1.客户端之间传输的数据叫做消息,在Kafka中也叫Record(记录)
2.Record在客户端中是一个KV键值对(ProducerRecord、ConsumerRecord)
3.Record在服务端中的存储格式也是KV键值对(RecordBatch 或 Record)
2.3 Rroducer
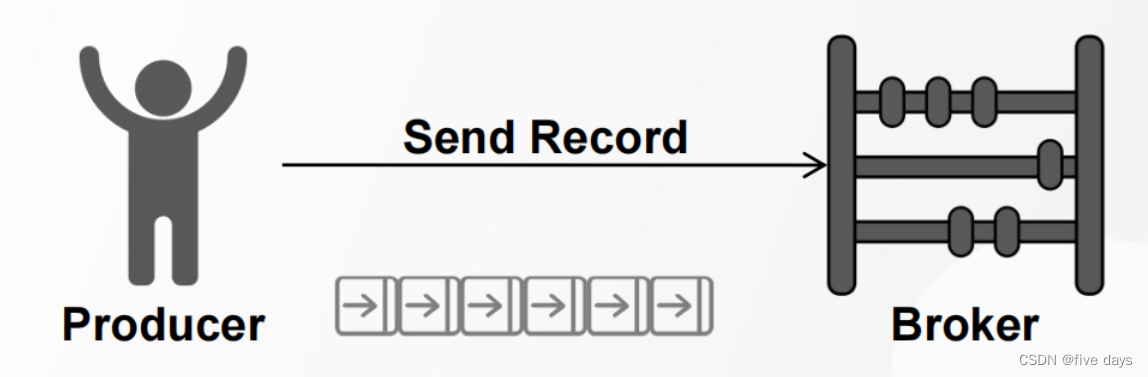
1.发送消息的一方叫做生产者
2.Kafka为提升消息发送速率,生产者默认采用批量发送的方式发送消息至Broker
3.Kafka为提升消息发送速率,生产者默认采用批量发送的方式发送消息至Broker
2.4 Consumer
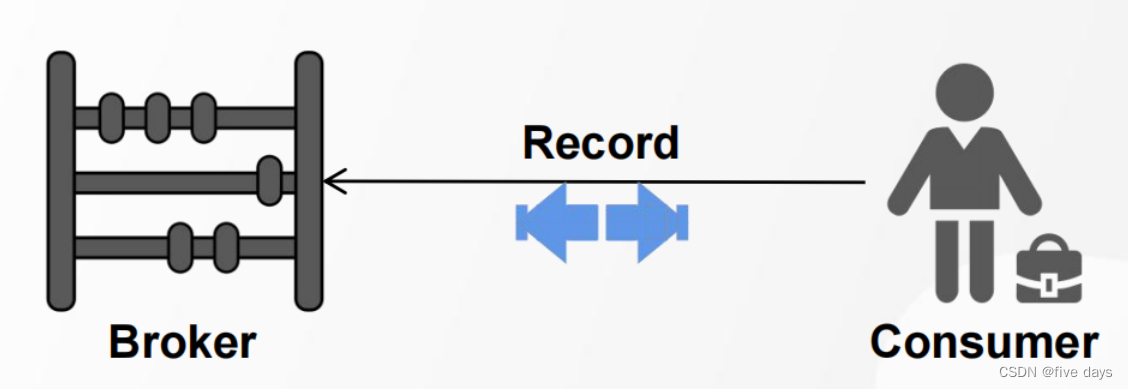
1. 订阅、接收消息的一方叫做消费者
2. 消费者端获取消息有两种模式:Pull模式[拉]、Push模式[推]
3. Pull模式,消费者可以自己控制一次到底获取多少条消息(max.poll.records)
2.5 Topic
在Broken中会采用topi主题的方式用来划分不同的业务线

1. Topic(主题)是一个逻辑概念,可以理解为一组消息的集合
2. 生产者和消费者通过Topic进行消息的写入和读取
3. 生产者发送消息时,若Topic不存在,是否自动创建:auto.create.topics.enable(但一般禁用,因为不便于维护)
2.6 Partition
在一个topic中,当数据量特别大的时候,就会极大的影响我们的查询效率,就好比mysql的分库分表,因此在kafka中,也引入了一个partition分区的这样的一个概念,从而提升查询效率,也实现了消息的负载均衡。

1. 所谓分区(Partition)就是把一个Topic分成几个不同的部分
2. 一个Topic可以在创建时划分成多个分区
3. 若没有指定分区数,默认分区数为1,通过参数可修改(num.partitions)
4. Kafka中修改分区的规则:可加、不可减
可以指定以下参数进行配置 为不同的topic主题配置对应的partition分区
./kafka-topics.sh --create --topic TopicA --bootstrap-server 192.168.61.100:9092 --replication-factor 1 --partitions 3
./kafka-topics.sh --create --topic TopicB --bootstrap-server 192.168.61.100:9092 --replication-factor 1 --partitions 3
2.7 Replica机制(副本机制)
partition虽然实现了消息的负载,但还是在一台服务器上,并没有实现真正意义上的负载均衡,因此引入了replica副本机制,实现真正的负载均衡

1. Replica(副本)是Partition(分区)的副本,每个分区可以有若干个副本
2. 副本必须在不同的Broker节点上,副本包括了主从节点(Leader、Follower)
3. 服务端可以通过参数控制默认副本数(offsets.topic.replication.factor)
副本的配置可以通过replication-factor参数指定
sh kafka-topics.sh --create --topic TopicA --bootstrap-server 192.168.61.100:9092 --replication-factor 3 --partitions 3
2.7 Segment
每一个partition里面都有一个log文件,当这个文件越来越大的时候,也会影响查询效率,因此kafka又引进了一个segment段的概念,来提升查询的效率。

1.Segment(段)的目的是:将一个分区中的数据划分、存储到不同的文件中
2.每个 Segment 至少由 1 个数据文件和 2 个索引文件构成, 3 个文件是成套出现的3.引入段带来的意义:3.1 加快查询效率3.2 删除数据时减少逐条 IO4. Segment 大小控制4.1 按时间周期生成( log.roll.hours )4.2 按文件大小生成( log.segment.bytes )
2.8 Consumer Group
假设生产者生产消息速度很快。势必就会造成大量的消息堆积,入口快,对应的出口就也很快,因此需要采用一些策略来提升消息的消费速率,假设我没用消费者组,则来了几个消费者,我们怎么直到要消费这个主题topic呢?所以才有了消费者组的概念,让这个组去订阅这个主题。
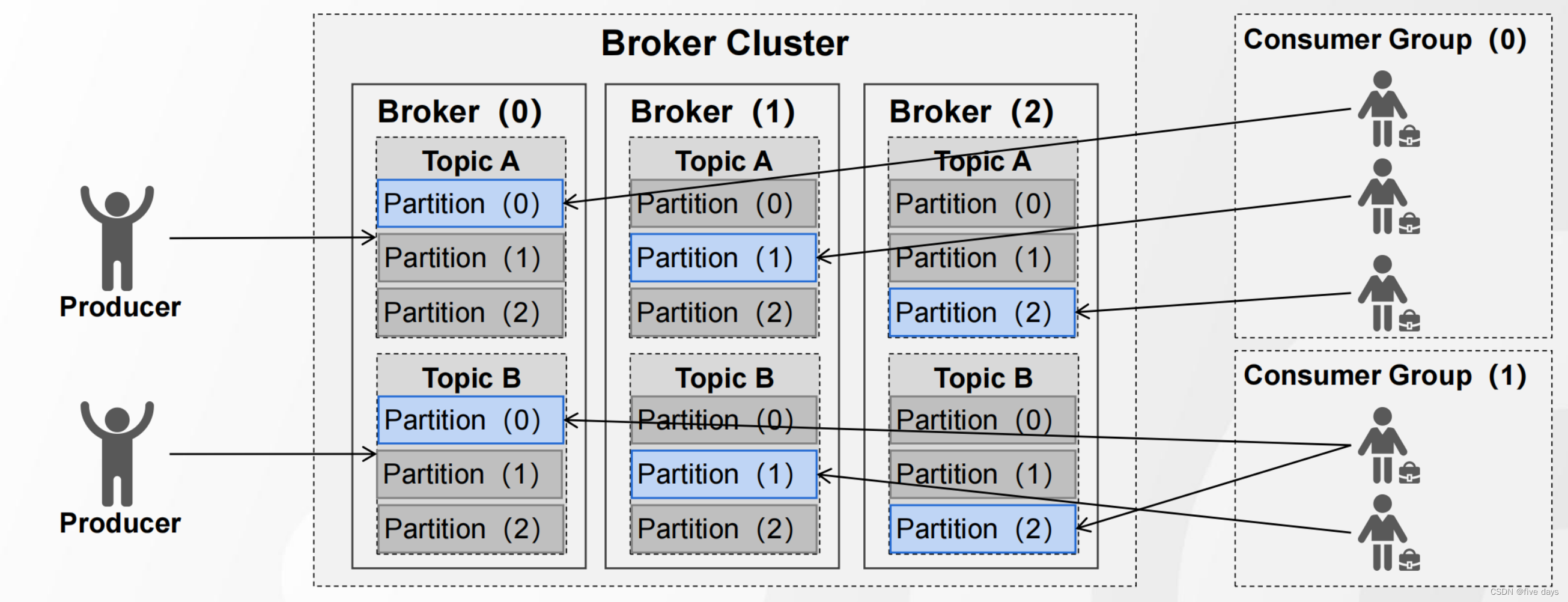
1. 使用消费者组,提升消费效率和吞吐量
2. 同一个Group中的消费者,不能消费相同的Partition(group id相同,在一个组中)
2.9 Cunsumer Offset

在kafka中,消息消费完后,并不会立即删除,假设我们消费完前面的两个消息后,服务节点挂了,我们再次重启服务的时候,是不是希望从第3个节点开始消费,于是就引入了偏移量consumer offset。

Offset(偏移量)的目的在于:记录消费者的消费位置
Kafka 现行版本将 Offset 保存在服务器( __consumer_offsets )主题中
3. Kafka整体架构
从第2章我们简单了解到了kafka的各个组件以及各个组件的基本作用,那么kafka的一个整体架构是怎么样的呢?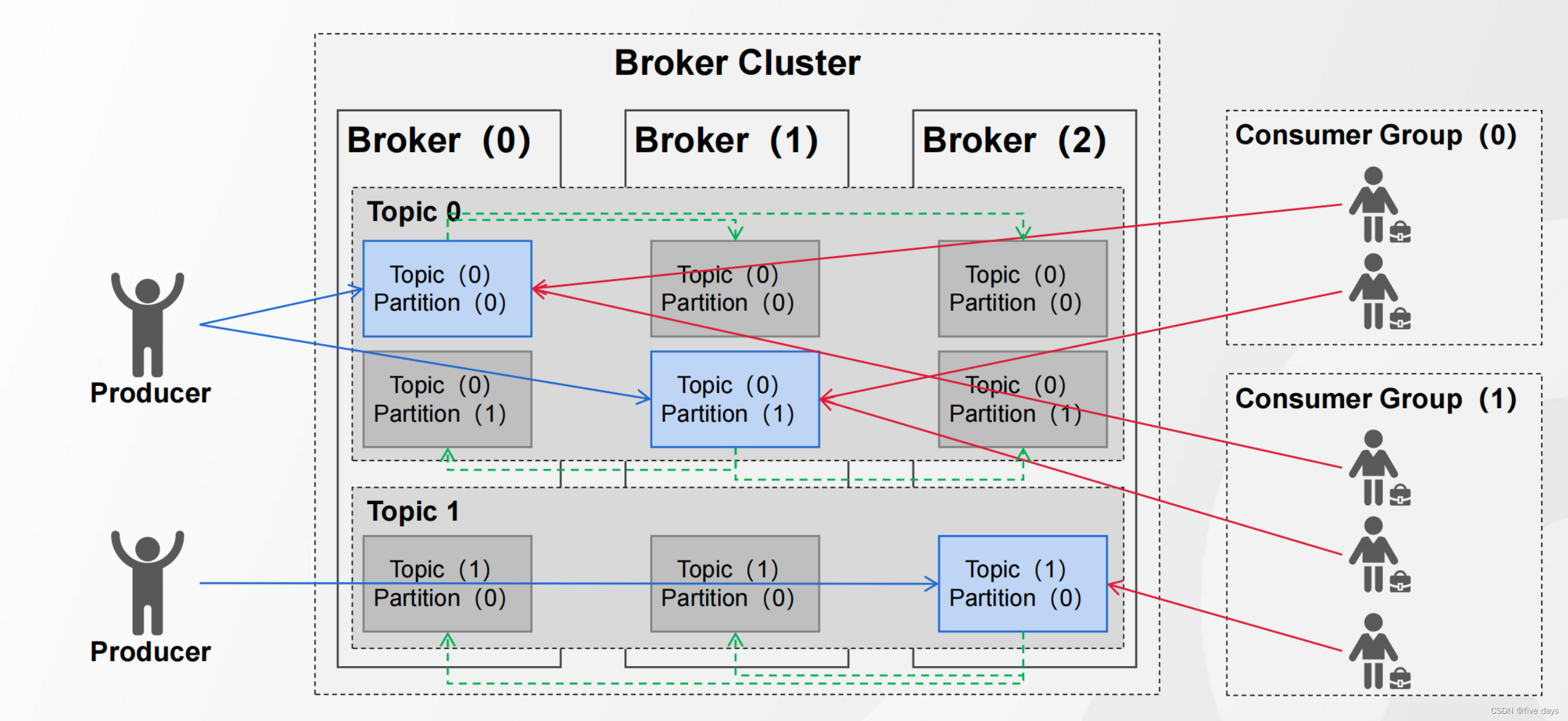
生产者producer向broker中的topic发送消息,消息的存储会有一个主分区叫做leader,实现负载均衡,消息分别保存在不同服务器的leader上面,然后在另外的两个服务器上有两个副本叫做follow,由leader异步同步数据到follow中,保证了数据的可靠性。consumer端,又分为不同的group,每个group中的消费者去这些分区中订阅。
4. Kafka特性
kafa要想保证消息的可靠性,就必须落到磁盘中,那么既然kafka是要跟磁盘进行IO的,那又是如何保证高吞吐,低延迟的呢? 主要有以下4个特性
- 磁盘顺序IO
- 索引
- 批量读写和压缩算法
- 零拷贝
4.1 磁盘顺序IO
磁盘随机IO和磁盘顺序IO
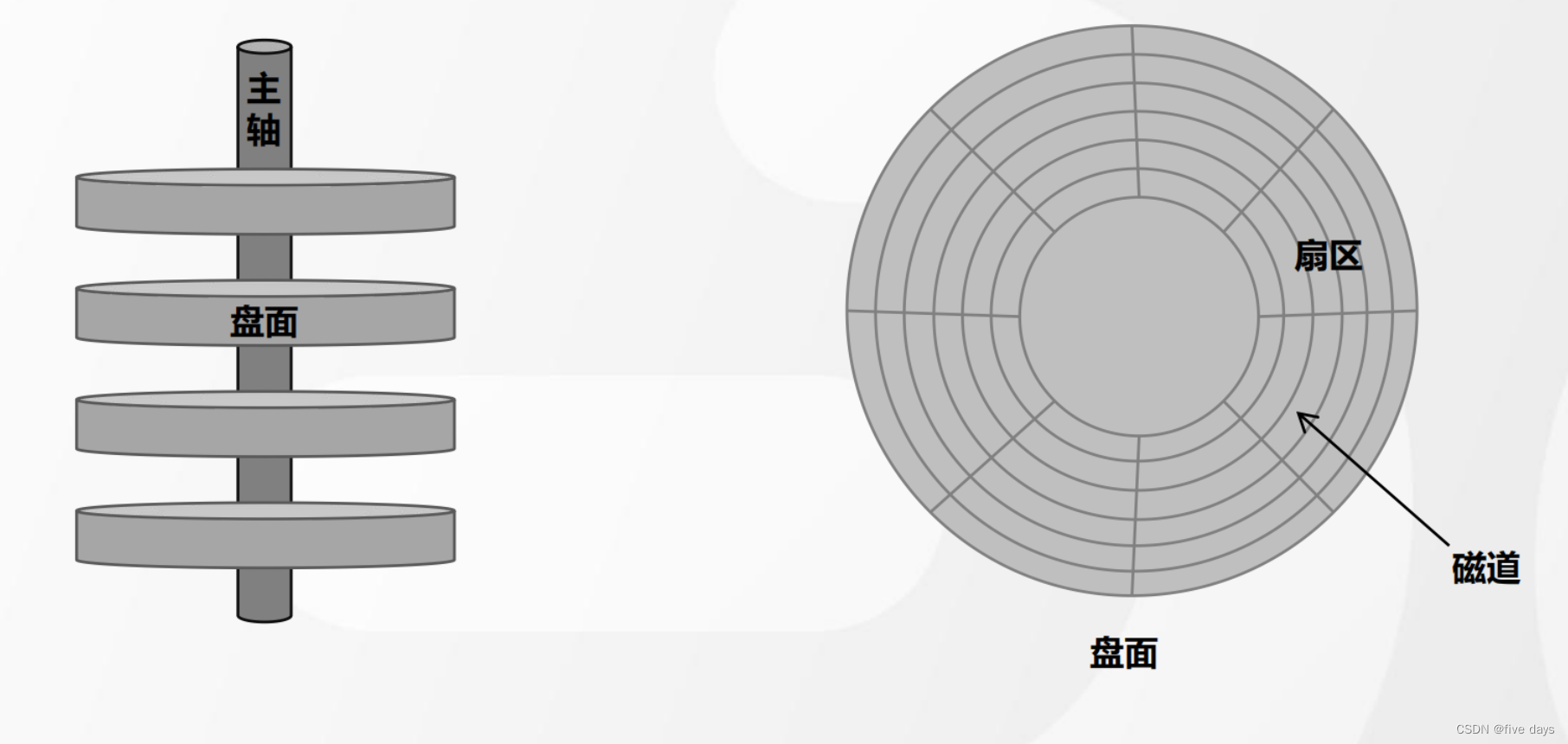
如下图,磁盘交互的主要时间消耗主要在磁盘选址中。磁盘的构成如上图所示,是一个个的扇区和磁道构成的,随机IO的数据存储是分散性的,因此选址比较浪费时间,而磁盘顺序IO是几种存储追加的形式,一旦确定了一个物理地址,后面的存储就在这个物理地址后面追加,因此寻址的时候,可能只需要一次寻址就可以了。磁盘顺序IO的读写速度是不逊于内存读写的。
4.2 索引
Broker 端原理数据存储Offset 索引、时间戳索引、稀疏索引
4.3 批量处理和压缩传递
收发消息时批量处理压缩算法进行压缩后传递
4.4 零拷贝
在了解零拷贝前,我们先来看一个传统的IO
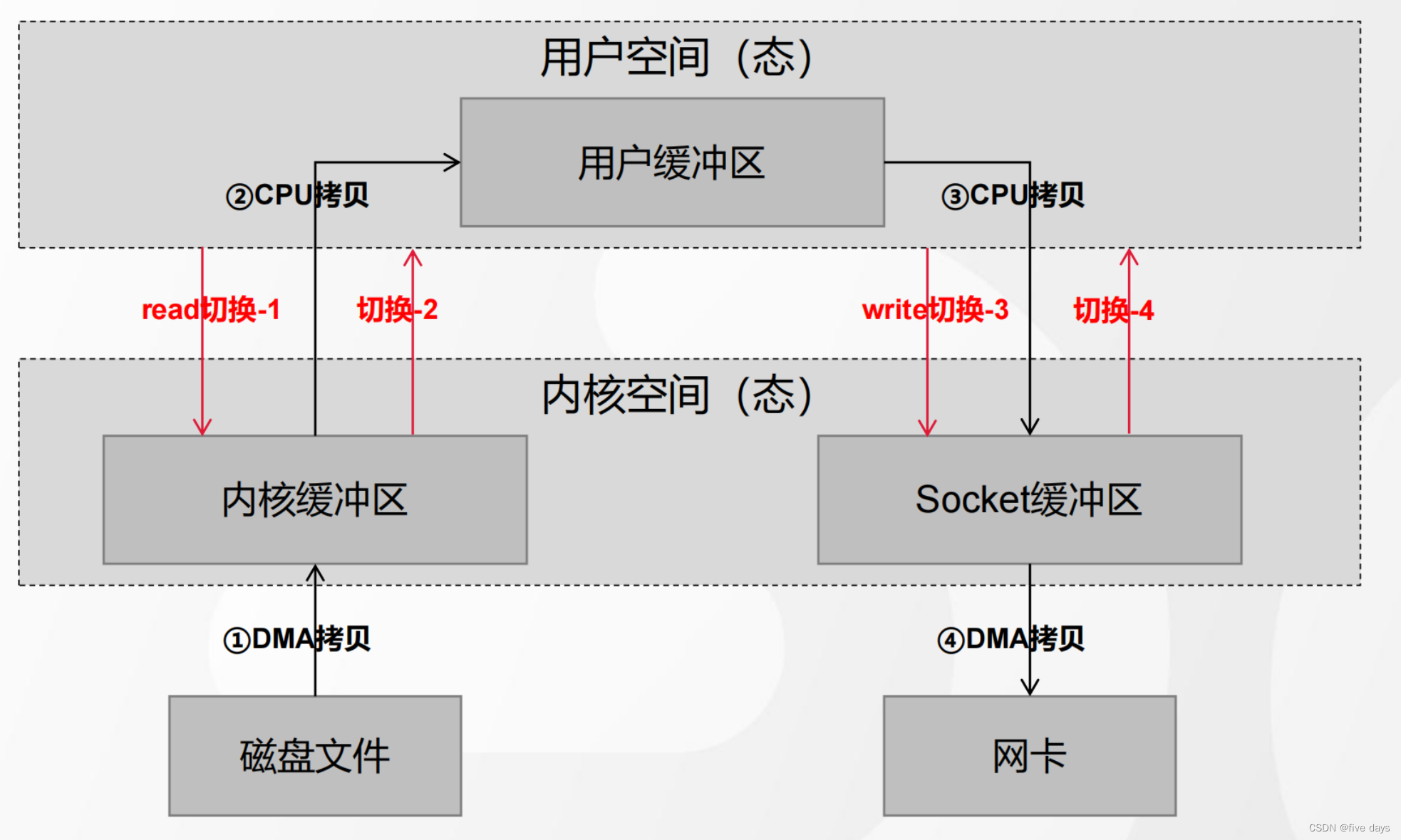
我们直到,在计算机层面是会分为用户态和内核态的,这主要是为了保护操作系统,防止用户空间的进程操作到内核中。有了这么的一个概念,我们从用户程序中读写磁盘的数据,就难免要去与内核空间进行交互,那么传统的交互方式是怎么样的呢?
我们从用户空间出发,会先进行read从内核空间中读取。内核空间中的磁盘数据经由DMA拷贝到内核态中,然后会在经过PU拷贝到用户态中,用户态在经过拷贝到网络的sockect缓冲区,随后DMA拷贝到网卡中,也就是我们的网络交互传输的一个IO设备中。可以看到,传统的io形式经历了4次的用户态与内核态的交互,会大大的降低响应速度。因此kafak引入了一个零拷贝的技术。

直接从内核态的内核缓冲区经SG-DMA拷贝到网卡中。
5. 总结
本文主要从宏观的角度上介绍了消息队列MQ的背景、原理以及应用场景。随后分析了现在主流的MQ技术的落地Kafka,先是认识了kafka的各个组件,整体架构设计,还有kafak能够实现高吞吐低延时的一些保证特性,先大概有个整体的认识,随后会对每个模块进行详细的展开阐述以及原理分析。

