
- 1三种传统Seq2Seq的框图,简单理解_seq2seq模型框架
- 2Unity相关API调用时机_简述常见的start、update和fixedupdate这三个方法的调用特点。
- 3数据结构:图--拓扑排序_数据结构拓扑图
- 4android log系统_droidlogic
- 5【Redis入门篇】| Redis的Java客户端
- 6c语言中如何定义一个pos函数,c语言中函数 Pos(40, 12);是什么意思?
- 7—【动态规划】凸多边形最优三角剖分_有关规模为n+1的凸多边形(v0,v1,...,vn)最优三角剖分问题,设凸多边形vi-1...vj
- 8LeetCode 144 ——二叉树的前序遍历
- 9【分布式计算框架】Spark 集群搭建与示例运行 | RDD算子入门_spark 分布式计算技术
- 10高级英语(张汉熙版)第一册学习笔记(原文及全文翻译)——2 - Hiroshima-The “Liveliest“ City in Japan (excerpts)(广岛——日本“最有活力”的城市)_hiroshima高级英语翻译
一文带你入门知识图谱多跳问答
赞
踩
点击下面卡片,关注我呀,每天给你送来AI技术干货!

作者 | 蔡健宇
来自 | MIRA Lab
一、简介
1. 什么是问答?
问答 (Question Answering) 是自然语言处理 (Natural Language Processing) 的一个重要研究领域。在该领域中,研究者们旨在构建出这样一种系统:它可以针对人类以「自然语言形式」提出的问题自动地给出答案。
问答这一领域的研究成果已经早已普及我们每个人的生活。例如,当你清晨起床询问你的智能语音助手 “今天天气怎么样”时,你会得到类似这样的回答:“今天是晴天,温度 15-22 摄氏度”。
与传统的信息检索以及数据库检索不同的是,问答这一领域旨在研究那些以「自然语言形式」给出的问题,而非结构化的查询语言,这更符合日常生活中的应用场景。但自然语言的模糊性也为问题的准确理解带来了很大困难。
同时,问答的数据源可能是多种多样的。在不同的场景下,结构化的知识图谱以及无结构的文本均有可能是潜在的数据源。因此,针对不同的数据源研究相应的推理算法也是当前问答领域的热门方向之一。
因此,总结一下,构建一个高质量问答系统的关键点在于:
准确的问题理解技术
针对不同的数据源设计合适的推理算法
本文将重点针对以「知识图谱」为主要数据源的问答场景(知识图谱问答)进行介绍。首先,我们回顾一下知识图谱的相关概念与定义。
2. 什么是知识图谱 ?
知识图谱 (Knowledge Graph) 是一种以「多关系有向图」形式存储人类「知识」的数据结构。知识图谱中的每个节点表示一个实体,两个节点之间的有向边表示它们之间的关系。例如,<姚明> 是一个实体,<上海> 也是一个实体,它们之间的关系是 <出生于>。这样的一个三元组 <姚明,出生于,上海> 表示一个事实 (Fact)。
同样作为问答的数据源,与无结构的文本数据相比,结构化的知识图谱以一种更加清晰、准确的方式表示人类知识,从而为高质量的问答系统的构建带来了前所未有的发展机遇。
3. 什么是知识图谱问答?
知识图谱问答 (Question Answering over Knowledge Graphs),顾名思义,指的是使用知识图谱作为主要数据源的问答场景。对于给定的问题,我们基于知识图谱进行推理从而得到答案。这一技术已经被业界广泛地使用于相关智能搜索与推荐业务中,其中最著名的当属谷歌的搜索引擎业务。
例如,对于这样一个比较简单的问题 “姚明的出生地是哪里?”,谷歌通过知识图谱中 <姚明,出生于,上海> 这个三元组得到答案是 <上海> 这一实体。
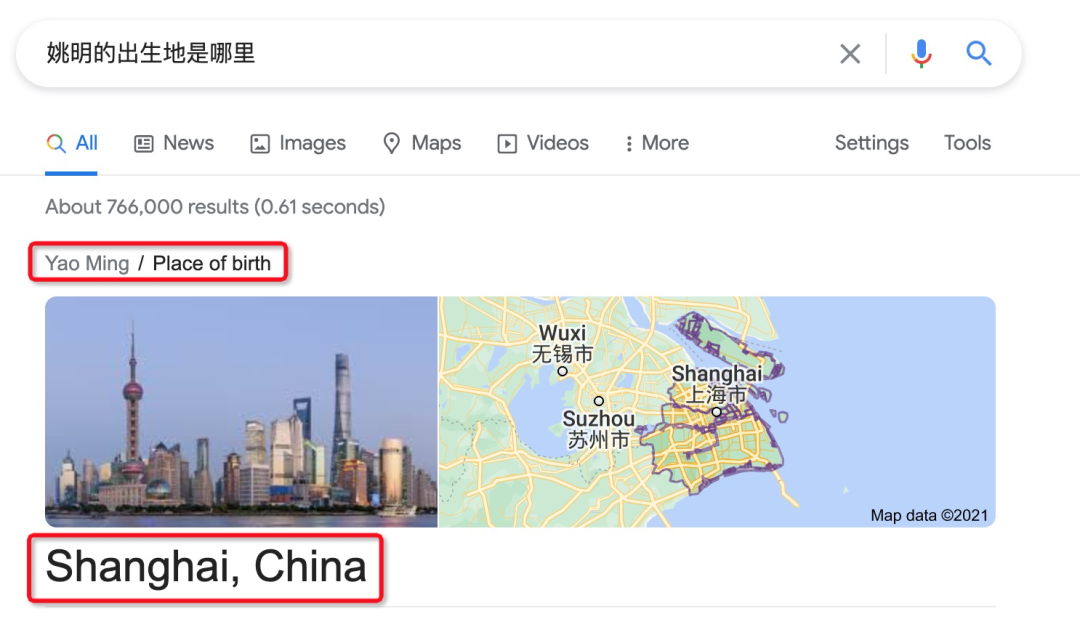
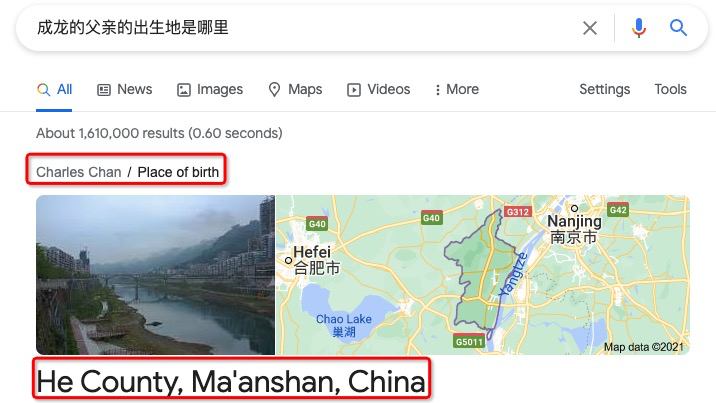
对于更加复杂的一些问题,如 “成龙的父亲的出生地是哪里?”,谷歌依然可以通过知识图谱中的多个三元组 <成龙,父亲,房道龙 (Charles Chan)>,<房道龙,出生地,和县> 得到答案是实体 <和县>。
接下来,为了更好地介绍知识图谱问答领域的发展,我们需要先明确几个基本概念:
「主题实体」:主题实体指的是出现在问题中的实体。例如,对于问题 “姚明的出生地是哪里?”,我们通过 "姚明" 这一字符串判断主题实体是 <姚明> ,它也是后续推理流程中的推理起点。理论上一个问题中的主题实体不限个数,但在后面介绍的知识图谱多跳问答领域中,一般假设一个问题中只存在一个主题实体。
「答案实体」:理论上问题的答案未必是一个实体,例如 ”中国在北京奥运会获得的金牌有多少枚?“ 的答案是一个数字。但在后面介绍的知识图谱多跳问答领域中,一般假设问题的答案是知识图谱中的一个实体,即答案实体。
二、知识图谱问答的发展简史
接下来,本文将从两个维度简要介绍知识图谱问答的发展历史。
一方面,按照所研究的问题 (Question) 的难易程度,知识图谱问答领域的发展可分为两个阶段:早期的 「Simple QA」 以及当前主流的 「Complex QA」。
另一方面,按照建模方式的不同,知识图谱问答领域的工作可分为两个流派:「语义解析」 (Semantic Parsing) 与 「信息检索」 (Information Retrieval)。
1. 问题难度:Simple QA & Complex QA
(1). Simple QA
在知识图谱问答领域发展的早期,研究者们主要针对 Simple QA 这种较为简单的场景开展研究 [1, 2, 3]。Simple QA 研究的是那些「可以使用单个三元组推理出答案」的问题,这些问题也被称为 Simple Questions 。
例如,对于 “姚明的出生地是哪里?” 这一问题,我们可以通过知识图谱中的单个三元组 <姚明,出生于,上海> 得到答案是 <上海> 这个实体。
(2). Complex QA
经过一段时间的研究,Simple QA 场景中已经发展出了许多成熟且实用的方法。因此,研究者们转而研究更为复杂的问题 (Complex Questions)。这些问题更契合实际应用中的复杂场景,而这一研究方向也被称为 Complex QA [4, 5]。
简单地说,Complex Questions 是 Simple Questions 的补集,即「无法使用单个三元组」回答的问题。在实际的研究中,研究者们主要关注以下类型的问题:
「带约束的问题」:例如:”谁是第一届温网男单冠军?“。该问题中的 "第一届" 表示一种对答案实体的约束。
「多跳问题」:例如:”成龙主演电影的导演是哪些人?“。该问题需要使用多个三元组所形成的多跳推理路径才能够回答。例如:通过这些三元组 <成龙,主演,新警察故事>, <新警察故事,导演,陈木胜>,我们推理出 <陈木胜> 是一个正确答案。
本文之后将主要结合多跳问题这一研究场景(知识图谱多跳问答)进行详细介绍。
2. 建模方式:Semantic Parsing & Information Retrieval
(1). Semantic Parsing
语义解析 (Semantic Parsing) 类方法旨在将问题解析为可执行的图数据库「查询语句」 (如 SPARQL),然后通过执行该语句找到答案。
对于 Simple Questions,语义解析类方法旨在将问题解析为一个头实体 与一个关系 ,即 (h, r, ?) 的形式。例如,对于 "姚明的出生地是哪里?" 这一问题,可以解析出头实体 <姚明> 与关系 <出生地>,并得到伪查询语句 <姚明,出生地,?>。随后通过执行该查询语句得到答案 <上海>。
对于 Complex Questions,语义解析类方法将它们解析为一种 查询图 (Query Graph) [4]。例如,对于 ”成龙第一部主演的电影的导演是谁?“ 这一复杂问题,我们可以将其解析为以下查询图。
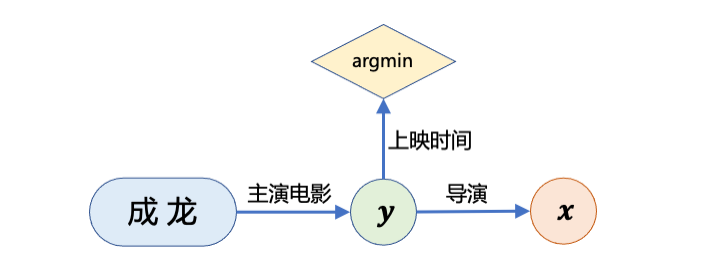
当我们执行这张查询图所表示的查询语句时,我们首先找到成龙主演的所有电影 ,再通过 argmin 这一约束从中筛选出上映时间最早的电影。对于这部筛选出来的电影,我们进一步查询出它的导演是 ,并作为答案返回。
(2). Information Retrieval
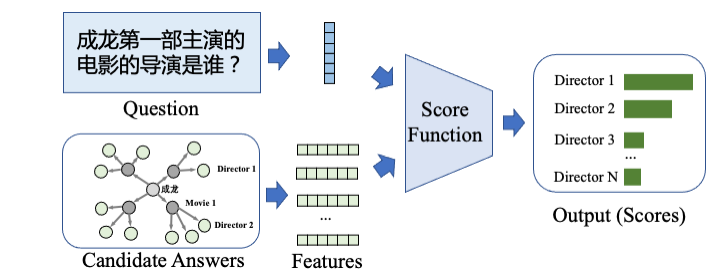
信息检索 (Information Retrieval) 类方法 [5] 旨在从问题与候选答案中提取出它们的特征,并基于这些特征设计相应的打分函数以衡量 ”问题-候选答案“ 的语义相关性,最终得分最高的候选答案被作为预测答案输出。下图给出了信息检索类模型的处理流程。
三、知识图谱多跳问答
本节将结合一些重点工作对 「知识图谱多跳问答」 这一方向进行介绍。从问题的难易程度这一视角来看,多跳问答属于 Complex QA 这一领域;从模型的流派这一视角来看,多跳问答这一方向中的模型的主流是信息检索这一流派,因此我们接下来也将重点结合这一流派进行介绍。
通俗来说,多跳问题 (Multi-hop Questions) 指的是那些需要知识图谱 「多跳推理」 才能回答的问题。例如,若要回答 ”成龙主演电影的导演是哪些人?“ 这一问题,则需要多个三元组所形成的多跳推理路径 <成龙,主演,新警察故事>, <新警察故事,导演,陈木胜> 才能够回答。
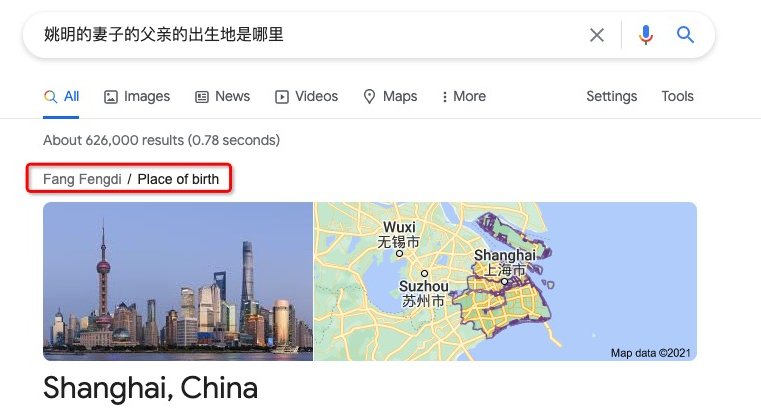
这种类型的问题在实际应用中十分普遍,但想要构建出一个高准确率的知识图谱多跳问答系统却并非易事。下图展示了一个谷歌搜索中的 Bad Case。
我们尝试在谷歌搜索中输入以下问题 ”姚明的妻子的父亲的出生地是哪里?“。对于该问题,正确的推理路径为 。但是,谷歌却错误地将问题解析成了以下推理路径 。由于姚明的母亲(父亲的妻子)是方凤娣 (Fang Fengdi),谷歌将她的出生地作为答案返回。由此可见,知识图谱多跳问答是一个极具挑战性的任务。
接下来,我们将结合近年的几个重要工作对知识图谱多跳问答这一领域的发展进行介绍。在开篇的简介中,我们提到高质量问答系统的构建包含两个关键点:问题理解与推理算法。知识图谱多跳问答也不例外。接下来要介绍的几篇工作也正是围绕这两个关键点展开。
(1). VRN:端到端的问题理解
知识图谱问答中,问题理解的首要目标就是识别问题中的主题实体 (Topic Entity)。在之前的例子中,如 “姚明的出生地是哪里?”,我们通过 "姚明" 这一字符串判断主题实体是 <姚明> ,它也是后续推理流程中的推理起点。
之前的一些工作 [6] 通过文本匹配的方式来识别主题实体,但在实际应用场景中这种方式易受噪声(自然语言的模糊性和错别字)影响。在这些情况下,如果我们将知识图谱问答分为主题实体识别与知识推理这两个独立的阶段,那么在主题实体识别这一阶段产生的错误往往会传递到知识推理这一阶段,从而对最终预测结果产生严重的影响。
为了解决这一问题,VRN [5] 提出了一个端到端 (end-to-end) 的框架。它将主题实体识别与知识推理这两个模块以端到端的方式融合起来,从而训练过程中的 loss 会直接反馈到主题实体识别模块,有助于更准确地在噪声环境中识别出正确的主题实体。
为了实现 ”端到端“ 这一目标,VRN 进行了以下概率建模。对于给定的问题 ,它的正确答案是实体 的概率表示为 。问题 中的主题实体是实体 的概率表示为 。给定主题实体是 的情况下,问题 的答案是 的概率表示为 。从而得到,
其中 表示的是实体识别这一流程, 表示的是知识推理这一流程。本质上,VRN 是将主题实体 建模为隐变量,然后以全概率公式的形式表示 。
接下来介绍的三个工作主要围绕推理算法进行研究。更具体地,这些工作主要针对知识图谱「链接缺失」 (incomplete) 这一真实场景下的推理算法进行研究。
(2). GraftNet: 基于多源数据的问答
真实应用场景下的知识图谱往往是存在链接缺失问题的,即一部分正确的三元组(事实)没有被包含进知识图谱中。而这些缺失的三元组可能对于准确地回答给定的问题至关重要。
为了解决这一问题,GraftNet [7] 采取了以下措施:
使用无结构的文本数据作为结构化的知识图谱数据的补充;
提出了一个图神经网络模型 (GNN),它可以在文本与知识图谱组成的混合类型数据上进行推理并得到答案。
对于无结构的文本数据,GraftNet 将每个文档 (document) 看做一个节点,并融入知识图谱结构中:如果该文档中包含某个实体 ,那么就在这个文档与实体 之间建立连接。下图展示了一个直观的例子。
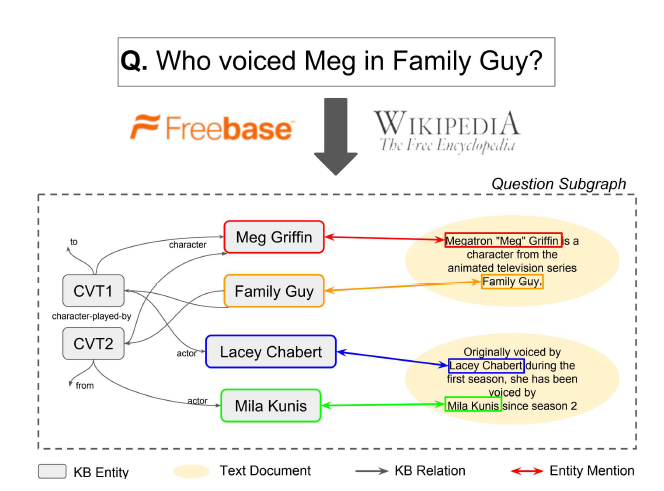
基于这种由知识图谱与文档数据组成的图结构,GraftNet 设计了一个 GNN 用于推理,大致流程如下:
对给定的问题 (假定主题实体 已知),使用 Personalized PageRank (PPR) 算法提取出以 为中心的子图。最终的候选答案实体便被限定在该子图中,这个子图中实体的集合也就是候选答案集合。
使用多层 GNN 迭代更新实体、文档的表示,使得图中的每个节点可以感知到多跳邻居的信息。最终基于更新后的实体表示计算每个候选实体的得分。详细内容请见原文 [7]。
至于为什么要裁剪出子图,这是由于实际应用中知识图谱的实体数量过于庞大,如果将实体全集作为候选答案实体集,则会大大增加从中寻找正确答案的难度。因此,提前对实体进行筛选,只保留一小部分与问题相关的实体作为候选答案是一个明智的选择。
(3). PullNet: 动态子图拓展
虽然 GraftNet 取得了不错的效果,但该方法依然存在着一些问题。例如,GraftNet 为了减小候选答案实体集合的大小,使用 PPR 算法提取出以主题实体为中心的子图。但这些子图往往过大,而且有时并没有将正确答案囊括进来 [8]。
为了解决这一问题,PullNet [8] 提出了一种动态的子图拓展方法。具体地,该算法将子图初始化为主题实体 ,随后迭代地将与问题相关程度高的邻居实体拓展进子图,并同时使用 GNN 更新子图中节点的表示。
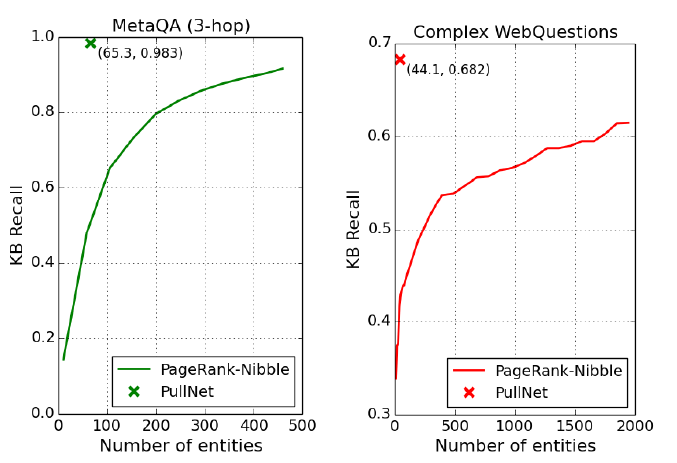
图7展示了 PullNet 相比 GraftNet 在子图提取上的优势,其中x-轴表示提取出的子图大小(子图中的实体数量),y-轴表示正确答案实体的召回率,即正确答案被包含在子图中的百分比,PageRank-Nibble 表示 GraftNet 所使用的子图提取方法。以左图 MetaQA (3-hop) 数据集为例,GraftNet 如果想要达到 0.9 左右的召回率,则需要将子图中的实体数量增大至 500 左右,而 PullNet 只需要动态地拓展出实体数量大小为 65 左右的子图,便可以轻松达到 0.983 的召回率。
(4). EmbedKGQA: 基于链接预测思路的问答方法
与 GraftNet 以及 PullNet 使用 GNN 进行推理思路不同的是,EmbedKGQA [9] 借鉴了知识图谱链接预测 (Link Prediction) 的思路以实现在链接缺失的知识图谱上的推理。
知识图谱链接预测指的是给定一个三元组中的头实体(或尾实体)与关系,对尾实体(或头实体)进行预测的任务,即 (h, r, ?) 或 (?, r, t)。给定一个问题 ,EmbedKGQA [9] 将该问题中的主题实体 看做头实体,将问题 看做一个关系,要预测的尾实体则是该问题的答案。也就是说,EmbedKGQA 将多跳问答建模成 。
这样的思路虽然简单,但也行之有效。总的来说,在知识图谱链接缺失的场景下,GraftNet 与 PullNet 从数据的角度出发,采取了使用文本数据 ”补全“ 知识图谱的思路,同时针对这种混合类型数据设计专门的推理算法。EmbedKGQA 则是从模型的角度出发,直接借鉴了链接预测这种比较成熟的建模思路。
四、总结
构建高质量问答系统的关键在于「准确的问题理解」与「针对相应的数据源设计合适的推理算法」。从问题理解的角度,知识图多跳问答近期工作主要关注于如何准确地识别问题中的实体。从推理算法的角度,近期的工作主要关注:1) 如何降低候选实体集合大小,同时减小对正确答案召回率的影响;2): 如何在链接缺失的知识图谱上进行推理。
Reference
[1] Berant, Jonathan et al. “Semantic Parsing on Freebase from Question-Answer Pairs.” EMNLP (2013).[2] Yih, Wen-tau et al. “Semantic Parsing for Single-Relation Question Answering.” ACL (2014).
[3] Bordes, Antoine et al. “Large-scale Simple Question Answering with Memory Networks.” ArXiv abs/1506.02075 (2015)
[4] Yih, Wen-tau et al. “Semantic Parsing via Staged Query Graph Generation: Question Answering with Knowledge Base.” ACL (2015).
[5] Zhang, Yuyu et al. “Variational Reasoning for Question Answering with Knowledge Graph.” AAAI (2018).
[6] Miller, Alexander H. et al. “Key-Value Memory Networks for Directly Reading Documents.” EMNLP (2016).
[7] Sun, Haitian et al. “Open Domain Question Answering Using Early Fusion of Knowledge Bases and Text.” EMNLP (2018).
[8] Sun, Haitian et al. “PullNet: Open Domain Question Answering with Iterative Retrieval on Knowledge Bases and Text.” EMNLP (2019).
[9] Saxena, Apoorv et al. “Improving Multi-hop Question Answering over Knowledge Graphs using Knowledge Base Embeddings.” ACL (2020).
注:封面图部分取自 http://people.virginia.edu/~jl6qk/sp20-graph-mining/lec2.pdf
作者简介:蔡健宇,2019年毕业于东南大学,获得工学学士学位。现于中国科学技术大学电子工程与信息科学系的 MIRA Lab 实验室攻读研究生,师从王杰教授。研究兴趣包括知识表示与知识推理。
说个正事哈
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心 。
。
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
点击上面卡片,关注我呀,每天推送AI技术干货~
整理不易,还望给个在看!

