
- 1蓝桥杯试题及答案分享(Python版)_蓝桥杯python真题
- 2mysql --batch --skip-column-name --execute 使用
- 3vue引入外部文件_Vue项目中引入外部文件(css、js、less)
- 4算法 求素数(三种方法.线性筛选法)_线性筛法求素数代码
- 5MVC,MVP,MVVM区别
- 6字节跳动秋招提前批(计算机视觉工程师)_字节跳动笔试邀请函计算机视觉工程师-极光-北京
- 72023前端面试题系列-- JS 篇_判断函数的返回值类型,如果是值类型,返回创建的对象。如果是引用类型,就返回这个
- 8鲁班-h5带你把项目跑起来_鲁班h5
- 9Docker基本原理与基础概念_( ).容器和虚拟机具有类似的资源隔离和分配优势,但功能不同,因为容器是虚拟化
- 10Qt开发上位机软件建立经典蓝牙通讯_qt蓝牙通信
为什么说大模型微调是每个人都必备的核心技能?
赞
踩
▼最近直播超级多,预约保你有收获
近期直播:《基于开源 LLM 大模型的微调(Fine tuning)实战》
0 —
为什么要对 LLM 大模型进行微调(Fine tuning)?
LLM 大模型(比如:ChatGPT-4.0)已经很强大了,为什么还需要微调?
主要有如下 4 点原因:
第一、缺乏专有数据,比如:企业内部的私有数据。
第二、缺乏最新数据,比如:GPT-4的训练数据截止到2021年9月。
第三、预训练成本高,比如:GPG-3 预训练成本为140万美金。
第四、提升数据安全性,比如:企业私有数据是不能传递给第三方大模型的,基于开源大模型的微调才能满足业务的需求。
— 1 —
如何对 LLM 大模型进行微调(Fine tuning)?
从参数规模的角度,对大模型进行微调(Fine tuning)有两条技术路线:
第一、对全量的参数,进行全量的训练,叫做全量微调 Full Fine Tuning,简称 FFT。
第二、只对部分参数进行训练,叫做 Parameter-Efficient Fine Tuning,简称 FEFT。
FFT 的原理,就是用特定的数据,对 LLM 大模型进行训练,将 W 变成 W`,W` 相比 W ,最大的改进点就是在上述特定数据领域的表现会好很多。
但 FFT 也会带来一些问题,主要有以下两个:
第一、训练的成本会比较高,因为微调的参数量跟预训练的是一样多;
第二、灾难性遗忘(Catastrophic Forgetting),用特定训练数据去微调可能会把这个领域的表现变好,但也可能会把原来表现好的别的领域的能力变差。比如:把 LLM 大模型的编程能力进行了调优,有可能会导致在文学创造等方面能力降低,如何在微调的过程中,同时兼顾各个能力维度,目前也是学术界研究的热点之一。
PEFT 主要解决就是 FFT 存在的上述两个问题,PEFT 也是目前比较主流的微调方案。
从训练数据的来源和训练方法的角度,LLM 大模型的微调有以下几条技术路线:
第一、监督式微调 Supervised Fine Tuning,简称 SFT,这个方案主要是用人工标注的数据,用传统机器学习中监督学习的方法,对 LLM 大模型进行微调。
第二、基于人类反馈的强化学习微调 Reinforcement Learning from Human Feedback,简称 RLHF。这个方案的主要特点是把人类反馈,通过强化学习方式,引入到对 LLM 大模型的微调中,让 LLM 大模型生成结果,更加符合人类的期望。
第三、基于 AI 反馈的强化学习微调 Reinforcement Learning with AI Feedback),简称 RLAIF。这个原理和 RLHF 类似,但是反馈的来源是 AI。这里是想解决反馈系统的效率问题,因为收集人类反馈,相对来说成本会比较高、效率比较低。比如:ChatGPT-4.0 通过训练奖励模型来对 LLM 大模型的回答进行打分,激励 ChatGPT-4.0 正向迭代优化。
不同的分类角度,只是侧重点不一样,对同一个 LLM 大模型的微调,也不局限于某一个方案,可以多个方案组合调优。
微调的最终目的,是能够在可控成本的前提下,尽可能地提升 LLM 大模型在特定领域的综合能力。
— 2 —
主流部分参数 PEFT 微调(Fine tuning)方案剖析
第一、Prompt Tuning,它的出发点Prompt-tuning 给每个任务定义了自己的 Prompt,拼接到数据上作为输入,同时 freeze 预训练模型进行训练,在没有加额外层的情况下,可以看到随着模型体积增大效果越来越好,最终追上了 LLM 大模型精调的效果。
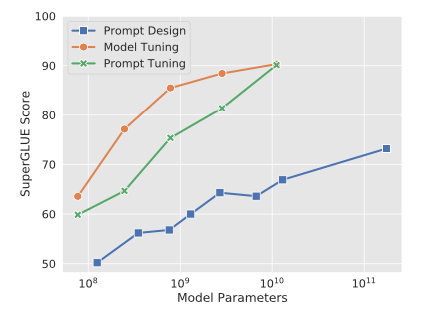
第二、Prefix Tuning,基于 Prompt Engineering 的实践表明,在不改变 LLM 大模型的前提下,在 Prompt 中添加适当的条件,可以引导LLM 大模型有更加出色的表现。
Prefix Tuning 和 Prompt Tuning 是类似的,只是在具体实现上有一些差异。
Prompt Tuning 是在 Embedding 嵌入环节,在输入序列 X 前面加特定的Token。
而 Prefix Tuning 是在 Transformer 的 Encoder 和 Decoder 的网络中都加一些特定的前缀。
具体是将 Y = WX 中的 W,变成 W` = [Wp; W],Y = W`X。
Prefix Tuning 保证了基座大模型本身是不变的,在推理的过程中,按需在 W 前面拼接一些参数。
第三、LoRA,LoRA 的实现思想很简单,如下图所示,就是冻结一个预训练模型的矩阵参数,并选择用 A 和 B 矩阵来替代,在下游任务时只更新 A 和 B。
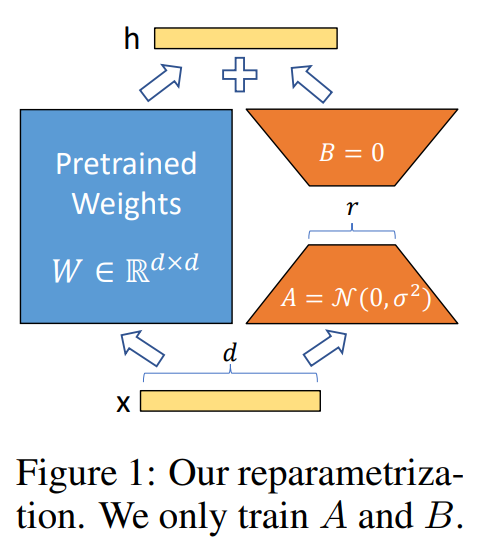
LoRA 有一个假设:我们现在看到的这些 LLM 大语言模型,它们都是被过度参数化的。而过度参数化的大模型背后,都有一个低维的本质模型。
大模型参数很多,但并不是所有的参数都是发挥同样作用的,大模型中一部分参数,是非常重要的,是影响大模型生成结果的关键参数,这部分关键参数就是上面提到的低维的本质模型。
结合上图来看,LoRA 的实现包括以下几步:
首先, 要适配特定的下游任务,要训练一个特定的模型,将 Y=WX 变成 Y=(W+∆W)X,这里面 ∆W 主是我们要微调得到的结果;
其次,将 ∆W 进行低维分解 ∆W=AB (∆W为 m * n 维,A 为 m * r 维,B 为 r * n 维,r 就是上述假设中的低维);
接下来,用特定的训练数据,训练出 A 和 B 即可得到 ∆W,在推理的过程中直接将 ∆W 加到 W 上去,再没有额外的成本。
另外,如果要用 LoRA 适配不同的场景,切换也非常方便,做简单的矩阵加法即可:(W + ∆W) - ∆W + ∆W`。
第四、QLoRA,结合上述流程
QLoRA 就是量化版的 LoRA,量化,是一种在保证模型效果基本不降低的前提下,通过降低参数的精度,来减少模型对于计算资源的需求的方法。
量化的核心目标是降成本,降训练成本,特别是降后期的推理成本。
QLoRA 是在 LoRA 的基础上,进行了进一步的量化,将原本用 16bit 表示的参数,降为用 4bit 来表示,可以在保证模型效果的同时,极大地降低成本。
比如:65B的 LLaMA 的微调要 780GB 的 GPU 内存,而用了 QLoRA 之后,只需要 48GB。效果相当惊人!
除了以上微调方法外,还有 Adapter、P tuning、P tuning V2等微调方案。
— 3—
免费超干货 LLM 大模型直播
为了帮助同学们掌握好 LLM 大模型的微调技术,本周日晚8点,我会开一场直播和同学们深度聊聊大模型的技术、分布式训练和参数高效微调,请同学点击下方按钮预约直播,咱们本周日晚8点不见不散哦~~
近期直播:《基于开源 LLM 大模型的微调(Fine tuning)实战》
END

