
- 1golang使用energy开发GUI桌面程序,CEF,LCL_golang energy
- 2nginx-ingress配置跨域_nginx-ingress 跨域
- 3LeetCode 简单算法题_given n= 6, pn/=[-3, 4, 3, -2, 2, 5],k=4 we can se
- 4c#反射用法
- 5APT攻击各阶段简介_apt攻击步骤
- 6python——绩点计算_python绩点计算
- 7AI绘画——了解AI绘画爆火原因与工具,并生成几个端午绘画小作品
- 8回归预测 | MATLAB实现CNN(卷积神经网络)多输入单输出_matlab中卷积神经输出层
- 9java多线程测试websocket demo(使用文件流)
- 10MySQL insert into select锁表的问题(上)_mysql tables in use 2, locked 2
论文解读:多任务学习之PLE算法
赞
踩
多任务学习之PLE算法
一、背景
在推荐领域,多目标已经成为了业界的主流,各大公司的各种业务场景,基本都是基于多目标的框架来搭建推荐系统。然而在现有的多目标模型中,很难同时对多个目标进行优化,通常会出现负迁移(negative transfer)和跷跷板现象(seesaw phenomenon)。
1.1、为什么要多目标建模
- 多任务场景下,多个任务会从不同的角度学习特征,增强模型泛化能力来提升收益,最常见的就是通过增加优化目标,比如在信息流推荐领域中的点击,时长,评论,点赞等多个维度,比如在电商领域的点击和转化;
- 共享参数,不额外增加资源的前提下变相增加参数规模。推荐系统的核心是embedding,对于相关的多个目标,比如点击/时长等,用户及相关特征的重合或者接近的,多个任务共享这部分参数可以极大的节省离线和在线资源;
- 用数据更多的任务指导学习数据较少的任务。一般常见的就是某个任务的数据量较少,期望能通过大数据训练较好的模型指导稀疏数据场景下的模型,比如点击率和转化率,一跳场景和二跳场景;
- 冷启模型的快速收敛。将冷启模型和收敛模型同时训练,帮助冷启模型可以在一个相对正确的方向上快速收敛;
- 有更多反馈和指导的模型指导学习其他模型。最常见的就是在精排阶段或者重排序阶段有一些"精准"评分用来指导更上层的粗排或者召回模型;
- 多个模型合并为一个模型后的线上资源多路请求可以合并为一路,减少请求资源;
- 减少多模型的维护成本。有很多策略和架构同学减少维护多个"相似"模型的需求是强烈的,一般一个模型有数据链条,离线训练任务,在线任务等多个环节,如果能合并成一个任务会极大的减轻工作量;
- 混合数据中训练不同任务。由于数据生成或者任务形式的不同,常见的需求是期望不同的数据训练不同的模型(比如mlp塔),而不是所有数据都训练每个模型。
1.2、业界做法
文章列出了当时业界对于多目标建模的一些算法模型,如下图所示:
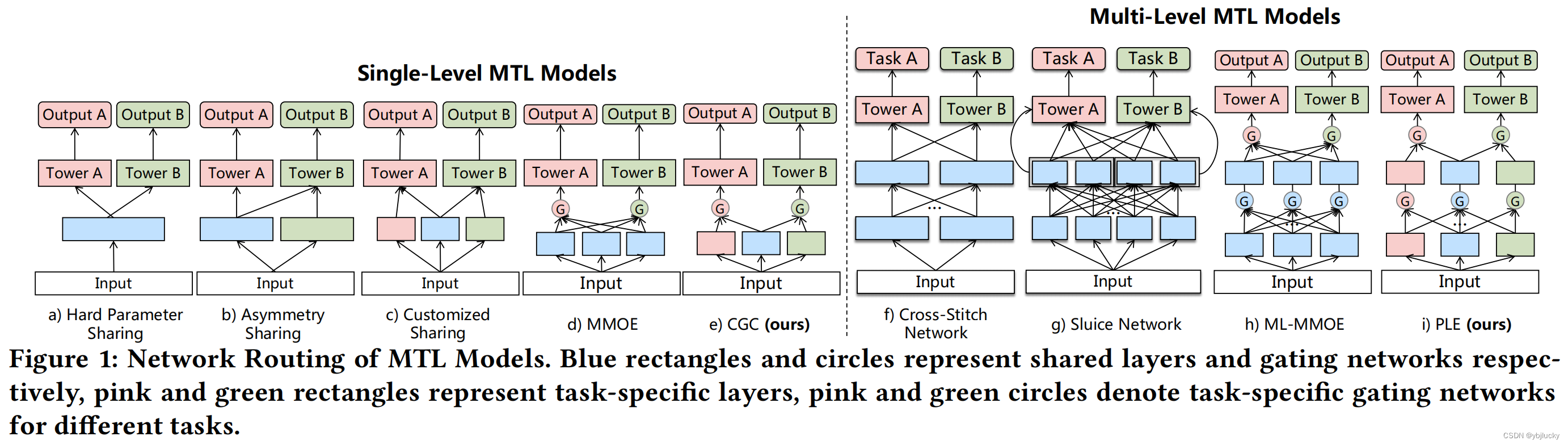
论文指出,对于相关性较差的多任务,使用hard parameter sharing方式的网络结构,诸如shared-bottom、cross-stitch network和 sluice network等算法结构,存在负迁移和跷跷板现象,因为任务冲突或相关性较差,导致模型无法有效地进行参数学习。MMoE算法提出共享专家网络,每个任务通过自有gate网络对专家网络输出进行加权组合(门控机制),共享专家网络相当于应用 multi-head self-attention 学习不同的子空间表征。
本文提出CGC网络,显示的分开共享专家网络和任务特定网络,减轻模型学到的共享信息和特有场景信息之间的参数干扰。虽然MMoE模型在理论上可以得到同样的解,但是在实际训练过程中很难收敛到这种情况。

二、论文方案
2.1、CGC结构
CGC网络结构如下图所示:
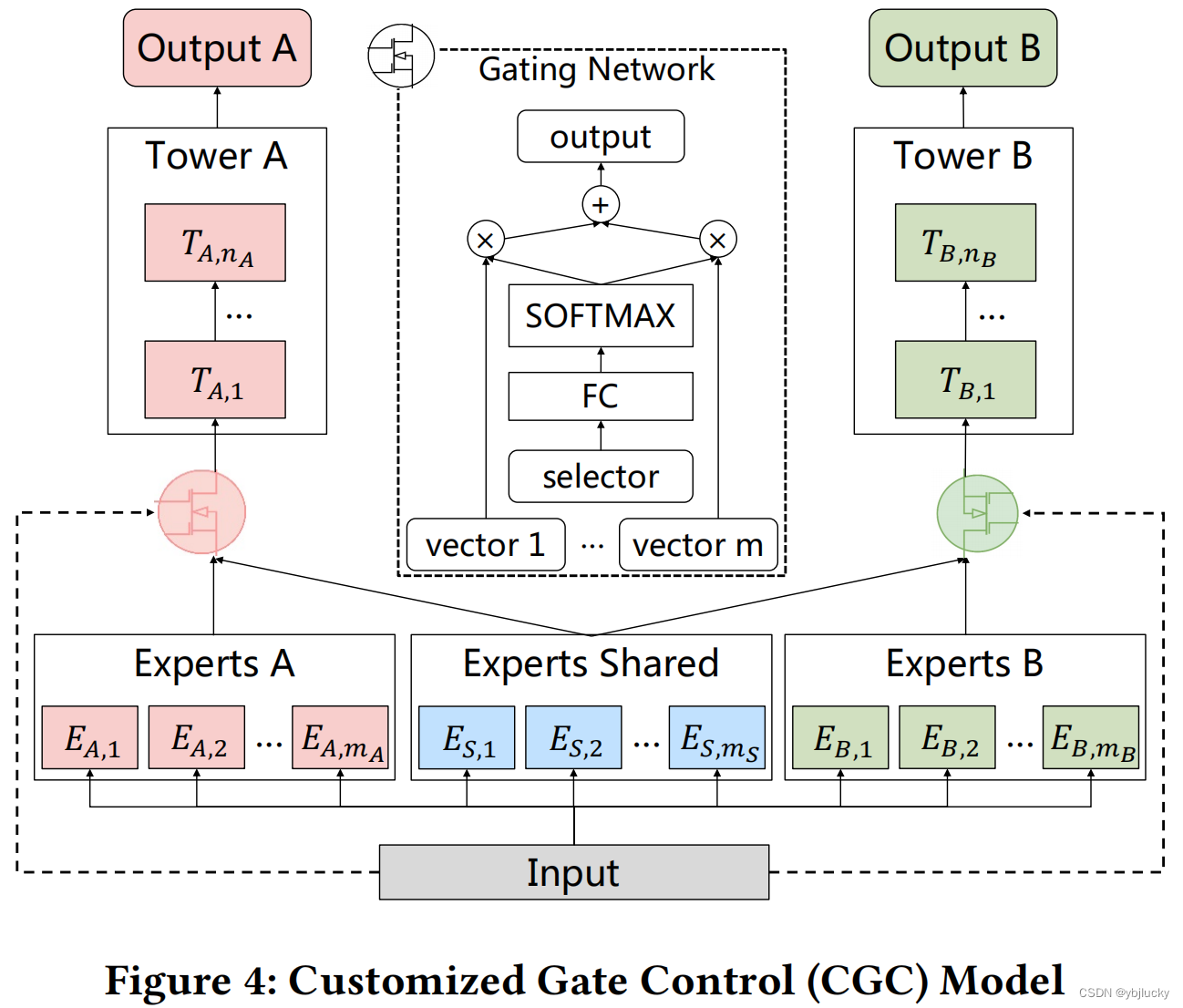
CGC包含shared experts和task-specific expert,expert module由多个子网络组成,子网络的个数和网络结构都是超参数;上层由多任务网络构成,每一个多任务网络(towerA和towerB)的输入都是由gating网络进行加权控制,每一个子任务的gating网络的输入包括两部分,其中一部分是本任务下的task-specific的experts和shared的experts组成,输入input作为gating network的selector。gating网络是一个FC结构(结构可调),获得不同子网络所占的权重大小,得到不同任务下gating网络的加权和。CGC网络结构保证了,每个子任务会根据输入来对task-specific和shared两部分的expert vector进行加权求和,再经过每个子任务的tower就得到了对应子任务的输出。
2.2、PLE结构
PLE网络结构如下图所示:
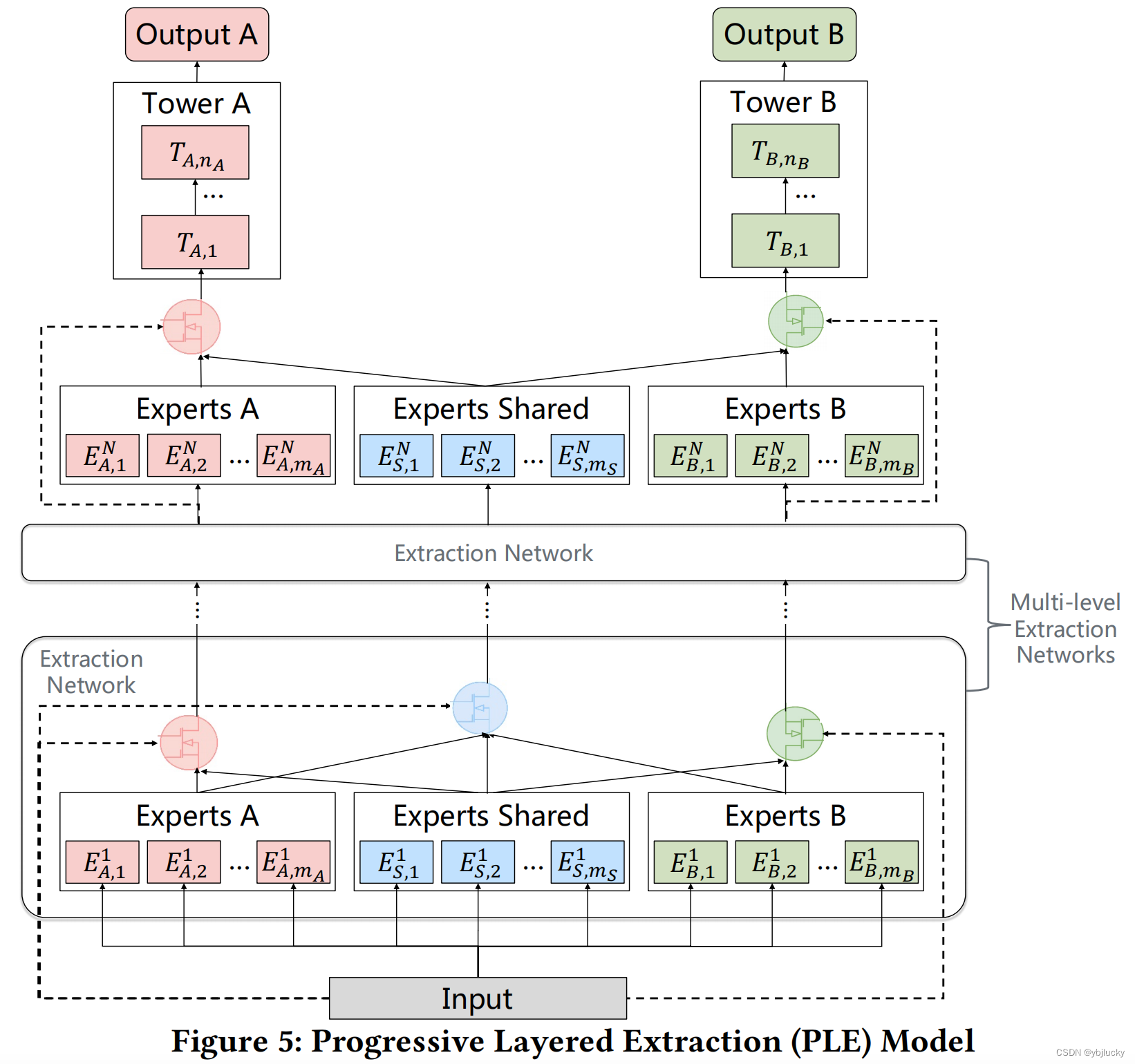
可以直观的看出,CGC网络是一种single-level的网络结构,而PLE网络结构就是将CGC拓展到了multi-level下。
不同的是:
- 在底层的Extraction网络中,除了各个子任务的gating network外,还包含有一个share部分的gating network,这部分gating network的输入包含了所有input,而各个子任务的gating network的输入是task-specific和share两部分;
- 在上层Extraction Network中input不再是原始的input向量,而是底层Extraction Network网络各个gating network输出结果的fusion result。
笔者在百度从事精排算法,发现百度内PLE算法应用,有上层Extraction Network的gating network输入是底层input向量,auc+千二。
2.3、损失函数
1)训练样本空间为全部任务的样本空间的并集,每个任务计算loss时只考虑这个任务的样本空间;
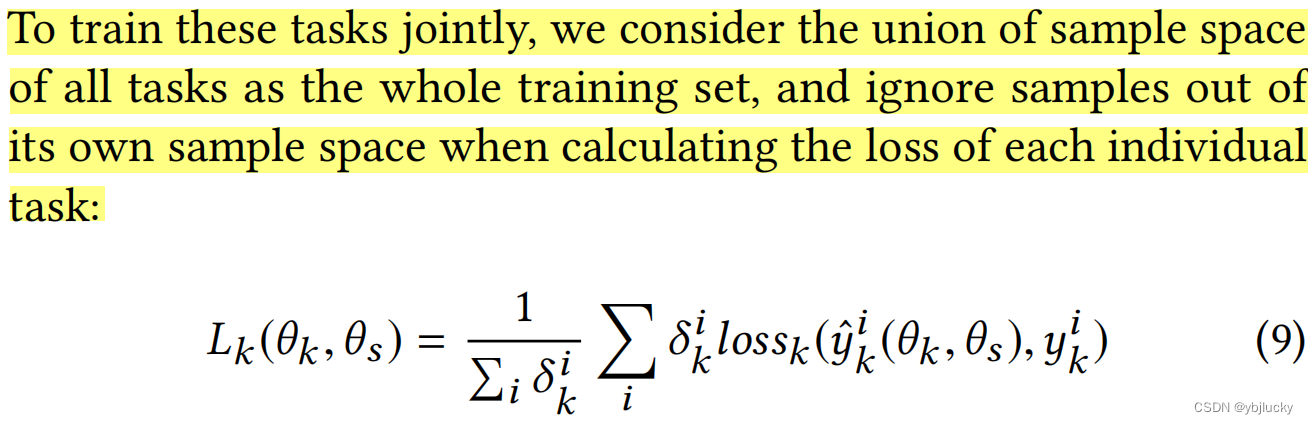
2)不同任务之间的权重设定:论文提出一种自适应动态调节的方案,在训练过程中调整不同任务之间的权重;

最终损失函数为:
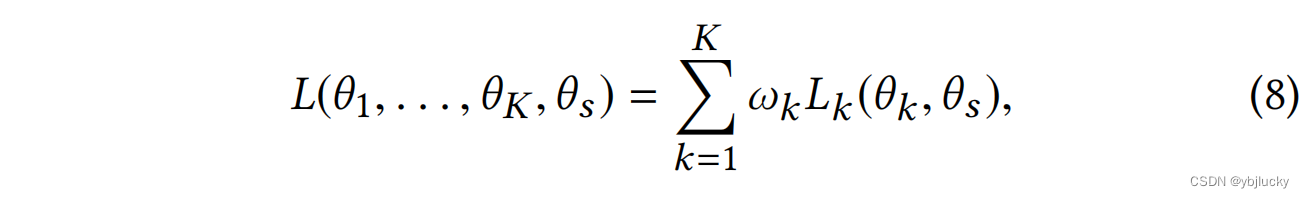
三、实验效果
3.1、线上A/B test
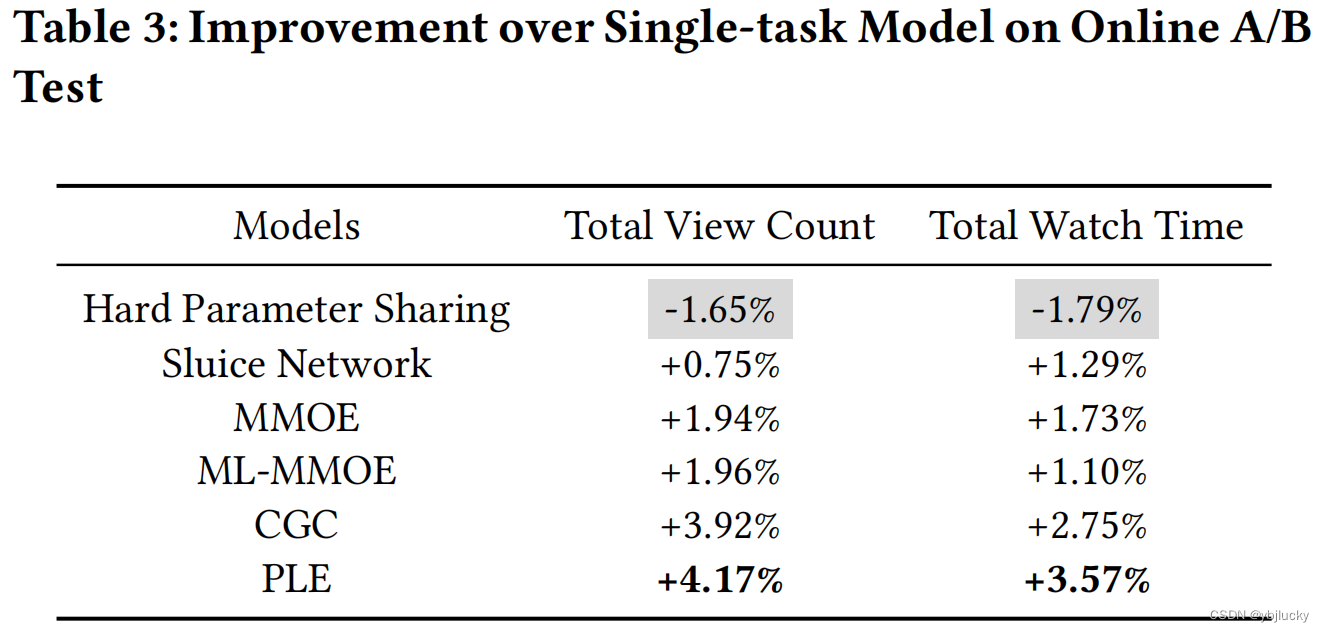
PLE在浏览量和观看时长上的提升是非常明显。
3.2、不同相关性任务的效果
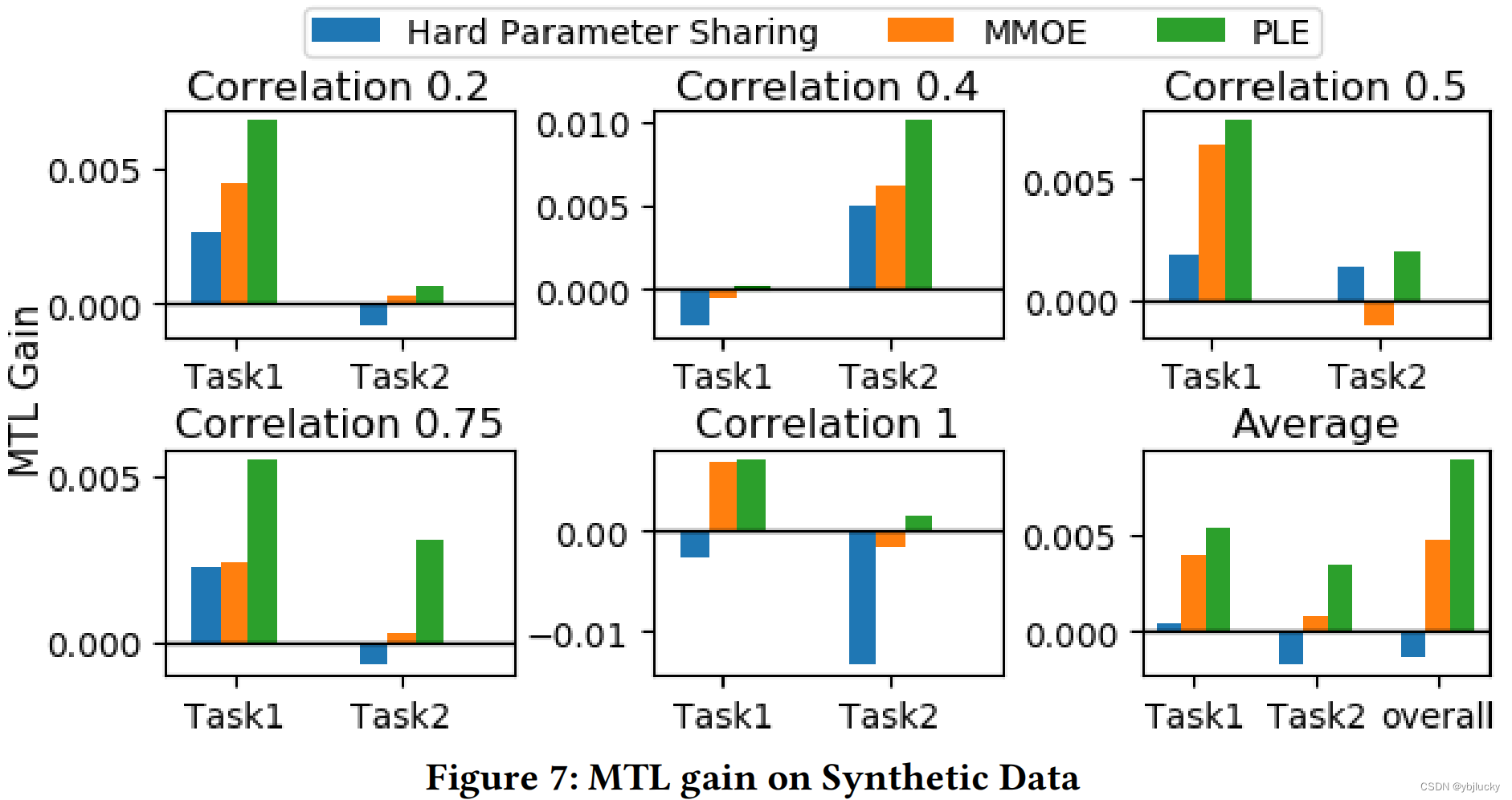
可以看出,在不同任务相关性前提下,PLE模型效果都远超其它模型;
3.3、MMoE和PLE不同experts网络的输出
论文对比了MMoE和PLE不同experts网络的输出均值,对比两者的expert utilization。
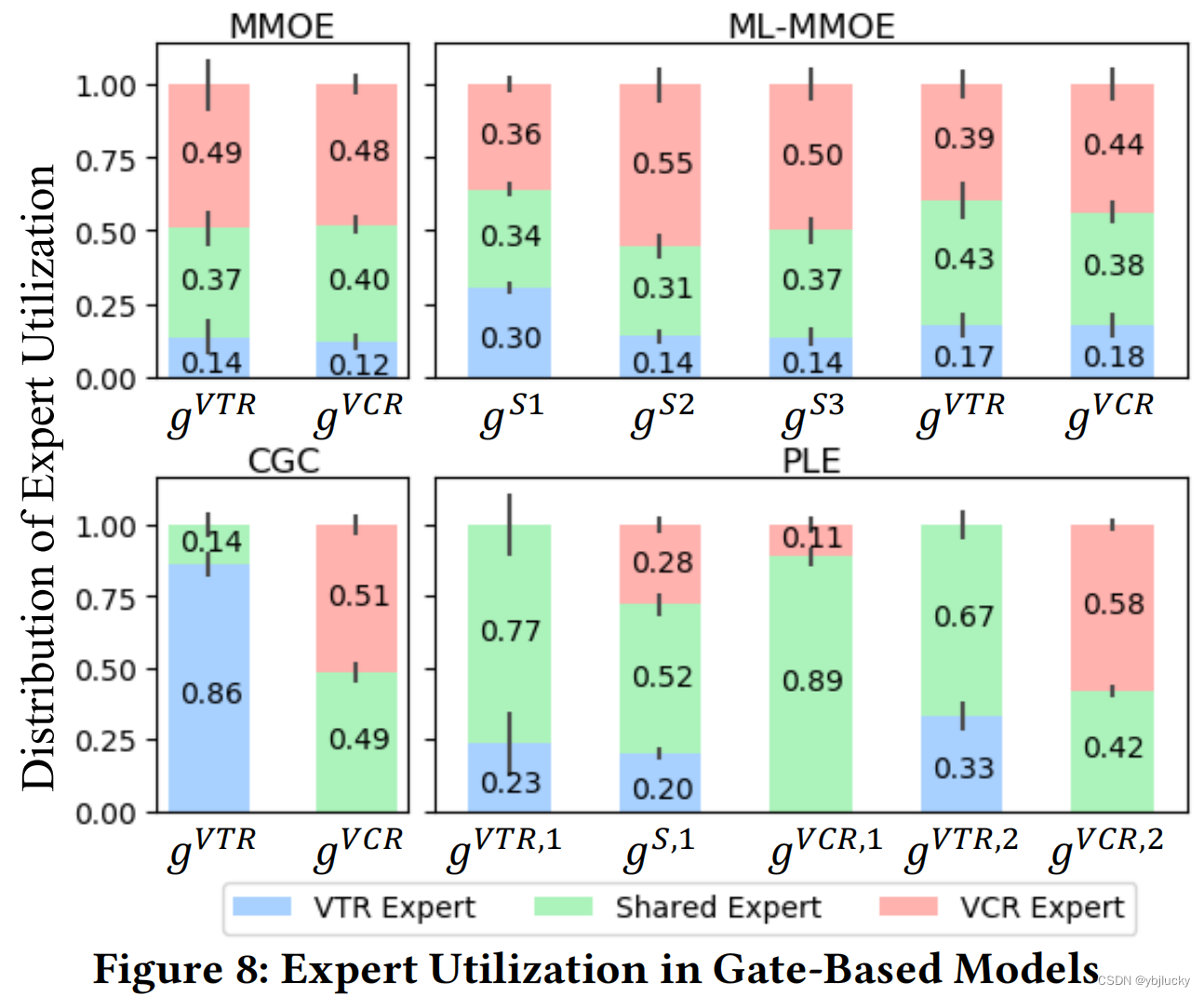
其中bars的高度和垂直短线分别表示权重的平均值和标准差。
从中可以看出:
- CGC 中VTR 和 VCR两任务权重显著不同,而 MMOE 中的权重非常相似,这表明 CGC结构有助于更好地区分不同专家;
- MMOE 和 ML-MMOE 中的所有专家都没有零权重,说明在实践中没有先验知识的情况下,MMOE 和 ML-MMOE 很难收敛到CGC 和 PLE 的结构,尽管存在理论上的可能性。
- druid jar包
com.alibaba [详细] 赞
踩


