
热门标签
热门文章
- 1Python批量采集亚马逊商品数据
- 2flink 1.18 sql gateway /sql gateway jdbc
- 3golang 环境搭建_golang环境搭建
- 4unity做一个简单的见缝插针游戏_unity见缝插针游戏
- 5【第114期】五大经典风控系统全面解读
- 6知云文献翻译安装教程_阅读英文文献的好帮手_知云文献翻译官网
- 7云计算——ACA学习 云计算分类_(1) idc云。 (2)企业云。 (3)云存储系统。 (4)虚拟桌面云。
- 8Kali Linux菜单中各工具功能大全_kali 智能电表
- 9【Redis】基于Docker安装Redis(详细步骤)
- 10LLM之makeMoE:makeMoE的简介、安装和使用方法、案例应用之详细攻略
当前位置: article > 正文
python 登录新浪微博爬取粉丝信息
作者:代码创新者 | 2024-02-03 14:23:22
赞
踩
python 登录新浪微博爬取粉丝信息
最近有个小需求,爬取新浪微博的粉丝信息,弄了好几天,终于搞定,送上代码:
环境:
系统:windows 7
版本:python 3.3
IDE: PyCharm 4.0.4
参考:http://blog.csdn.net/crystal_zero/article/details/51154632
- #!/usr/bin/env python3
- # -*- coding: utf-8 -*-
- import time
- import base64
- import rsa
- import binascii
- import requests
- import re
- import random
- try:
- import cookielib
- except:
- import http.cookiejar as cookielib
-
- try:
- from PIL import Image
- except:
- pass
- try:
- from urllib.parse import quote_plus
- except:
- from urllib import quote_plus
-
- '''
- 如果没有开启登录保护,不用输入验证码就可以登录
- 如果开启登录保护,需要输入验证码
- '''
-
-
- # 构造 Request headers
- agent = 'Mozilla/5.0 (Windows NT 6.3; WOW64; rv:41.0) Gecko/20100101 Firefox/41.0'
- headers = {
- # "Host": "www.weibo.com",
- 'User-Agent': agent
- }
-
- session = requests.session()
- session.cookies = cookielib.LWPCookieJar(filename='cookies')
- try:
- session.cookies.load(ignore_discard=True)
- except:
- print("Cookie 未能加载")
-
-
- # 访问 初始页面带上 cookie
- index_url = "http://weibo.com/login.php"
- try:
- session.get(index_url, headers=headers, timeout=2)
- except:
- session.get(index_url, headers=headers)
- try:
- input = raw_input
- except:
- pass
-
-
- def get_su(username):
- """
- 对 email 地址和手机号码 先 javascript 中 encodeURIComponent
- 对应 Python 3 中的是 urllib.parse.quote_plus
- 然后在 base64 加密后decode
- """
- username_quote = quote_plus(username)
- username_base64 = base64.b64encode(username_quote.encode("utf-8"))
- return username_base64.decode("utf-8")
-
-
- # 预登陆获得 servertime, nonce, pubkey, rsakv
- def get_server_data(su):
- pre_url = "http://login.sina.com.cn/sso/prelogin.php?entry=weibo&callback=sinaSSOController.preloginCallBack&su="
- pre_url = pre_url + su + "&rsakt=mod&checkpin=1&client=ssologin.js(v1.4.18)&_="
- pre_url = pre_url + str(int(time.time() * 1000))
- pre_data_res = session.get(pre_url, headers=headers)
-
- sever_data = eval(pre_data_res.content.decode("utf-8").replace("sinaSSOController.preloginCallBack", ''))
-
- return sever_data
-
-
- # print(sever_data)
-
-
- def get_password(password, servertime, nonce, pubkey):
- rsaPublickey = int(pubkey, 16)
- key = rsa.PublicKey(rsaPublickey, 65537) # 创建公钥
- message = str(servertime) + '\t' + str(nonce) + '\n' + str(password) # 拼接明文js加密文件中得到
- message = message.encode("utf-8")
- passwd = rsa.encrypt(message, key) # 加密
- passwd = binascii.b2a_hex(passwd) # 将加密信息转换为16进制。
- return passwd
-
-
- def get_cha(pcid):
- cha_url = "http://login.sina.com.cn/cgi/pin.php?r="
- cha_url = cha_url + str(int(random.random() * 100000000)) + "&s=0&p="
- cha_url = cha_url + pcid
- cha_page = session.get(cha_url, headers=headers)
- with open("cha.jpg", 'wb') as f:
- f.write(cha_page.content)
- f.close()
- try:
- im = Image.open("cha.jpg")
- im.show()
- im.close()
- except:
- print(u"请到当前目录下,找到验证码后输入")
-
-
- def login(username, password):
- # su 是加密后的用户名
- su = get_su(username)
- sever_data = get_server_data(su)
- servertime = sever_data["servertime"]
- nonce = sever_data['nonce']
- rsakv = sever_data["rsakv"]
- pubkey = sever_data["pubkey"]
- showpin = sever_data["showpin"]
- password_secret = get_password(password, servertime, nonce, pubkey)
-
- postdata = {
- 'entry': 'weibo',
- 'gateway': '1',
- 'from': '',
- 'savestate': '7',
- 'useticket': '1',
- 'pagerefer': "http://login.sina.com.cn/sso/logout.php?entry=miniblog&r=http%3A%2F%2Fweibo.com%2Flogout.php%3Fbackurl",
- 'vsnf': '1',
- 'su': su,
- 'service': 'miniblog',
- 'servertime': servertime,
- 'nonce': nonce,
- 'pwencode': 'rsa2',
- 'rsakv': rsakv,
- 'sp': password_secret,
- 'sr': '1366*768',
- 'encoding': 'UTF-8',
- 'prelt': '115',
- 'url': 'http://weibo.com/ajaxlogin.php?framelogin=1&callback=parent.sinaSSOController.feedBackUrlCallBack',
- 'returntype': 'META'
- }
- login_url = 'http://login.sina.com.cn/sso/login.php?client=ssologin.js(v1.4.18)'
- if showpin == 0:
- login_page = session.post(login_url, data=postdata, headers=headers)
- else:
- pcid = sever_data["pcid"]
- get_cha(pcid)
- postdata['door'] = input(u"请输入验证码")
- login_page = session.post(login_url, data=postdata, headers=headers)
- login_loop = (login_page.content.decode("GBK"))
- # print(login_loop)
- pa = r'location\.replace\([\'"](.*?)[\'"]\)'
- loop_url = re.findall(pa, login_loop)[0]
- # print(loop_url)
- # 此出还可以加上一个是否登录成功的判断,下次改进的时候写上
- login_index = session.get(loop_url, headers=headers)
- uuid = login_index.text
- uuid_pa = r'"uniqueid":"(.*?)"'
- uuid_res = re.findall(uuid_pa, uuid, re.S)[0]
- web_weibo_url = "http://weibo.com/%s/profile?topnav=1&wvr=6&is_all=1" % uuid_res
- weibo_page = session.get(web_weibo_url, headers=headers)
- weibo_pa = r'<title>(.*?)</title>'
- # print(weibo_page.content.decode("utf-8"))
- contents = re.findall(weibo_pa, weibo_page.content.decode("utf-8", 'ignore'), re.S)
- if len(contents):
- userID = contents[0]
- print(u"欢迎你 %s, 你在正在使用 xchaoinfo 写的模拟登录微博" % userID)
- session.cookies.save()
- return True
- else:
- return False
-
-
- def getWeiboPageContent(url):
- import requests
- from selenium import webdriver
- import time
- # webdriver.DesiredCapabilities.PHANTOMJS['phantomjs.page.customHeaders.Cookie'] = 'SINAGLOBAL=3955422793326.2764.1451802953297; wb_publish_vip_1888964862=2; YF-Page-G0=9a31b867b34a0b4839fa27a4ab6ec79f; _s_tentry=123.sogou.com; Apache=3233757158741.355.1460597853009; ULV=1460597853022:23:7:4:3233757158741.355.1460597853009:1460533608651; YF-V5-G0=24e0459613d3bbdec61239bc81c89e13; YF-Ugrow-G0=3a02f95fa8b3c9dc73c74bc9f2ca4fc6; login_sid_t=9c9ff740ffffbdf23415b871aa319ec0; TC-Ugrow-G0=e66b2e50a7e7f417f6cc12eec600f517; TC-V5-G0=7e5b74ea4beaaa98b5f592db11c2eeb9; myuid=5898063885; TC-Page-G0=1e758cd0025b6b0d876f76c087f85f2c; wvr=6; SSOLoginState=1460604791; un=1654916845@qq.com; user_active=201604141220; user_unver=b37741d33507619aa07b6d512be0dd67; SUS=SID-5898063885-1460616073-XD-a0vlz-c7f218016d290c52b4297371d3942ce7; SUE=es%3D5ec8e6a39470b9d75e4cf930977a7449%26ev%3Dv1%26es2%3D2b500477fcc5dc1560b4aee4d5ca9be5%26rs0%3Daeb6LPcKR9mfwMB31yJquO6NSXgRd9BpSLAcKEdCQjtUOM7pIzDblRVIOOItI22Uc6pLjTxUc6k7s0zIgIxar9JlVdPjOiHEGijE2ucUP6GjFv%252BJWntWR7szF3qcWknPBJzemeHiThBGRF0bAcNFHcH%252BY9VfrTaIVjXCUsO93B8%253D%26rv%3D0; SUP=cv%3D1%26bt%3D1460616073%26et%3D1460702473%26d%3Dc909%26i%3D2ce7%26us%3D1%26vf%3D0%26vt%3D0%26ac%3D27%26st%3D0%26uid%3D5898063885%26name%3D1654916845%2540qq.com%26nick%3Dforfun2016%26fmp%3D%26lcp%3D; SUB=_2A256C0vZDeTxGeNG4loR9i3EwzmIHXVZYToRrDV8PUJbvNAPLXX2kW9LHet_3CJqcXTqa57ddP1X0MxCpd6bSA..; SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WhFdfTB9.lOPTcSpGQskYri5JpX5K-t; SUHB=0z1QUpglvHBm_i; ALF=1492143611; UOR=far.tooold.cn,widget.weibo.com,login.sina.com.cn; WBtopGlobal_register_version=ab9111fb56d70a2b'
-
- #这个地方可以设置 header, 代理等一些参数
- cap = webdriver.DesiredCapabilities.PHANTOMJS
- cap["phantomjs.page.settings.resourceTimeout"] = 1000
- cap["phantomjs.page.settings.loadImages"] = False
- cap["phantomjs.page.settings.disk-cache"] = True
- cap["phantomjs.page.customHeaders.Cookie"] = 'SINAGLOBAL=1090764576516.7528.1472895523482;' \
- 'ULV=1473054803412:3:3:2:8569250075753.363.1473054803408:1472968709618;' \
- 'SCF=AsEbWSFBj4yI1a200LCVvAmkggqyRCHJ705_J2slnQgOZiIr6H6PjN2HTWiP8y_wK4rtnl9XPpwDIkzi3Do0iHg.;' \
- 'SUHB=0wn1u-A905WJz_;' \
- 'un=18704027874;' \
- 'UOR=,,www.baidu.com;' \
- 'wvr=6;' \
- 'SUBP=0033WrSXqPxfM725Ws9jqgMF55529P9D9WFwo9sl7cB8PE.FyBvPnqYc5JpX5K2hUgL.Foq7eKe0S0.7SKz2dJLoIEBLxK-LBo2LBK5LxK.L1KzL1-qLxK-LB.eL1heLxK-LBo2LBK5t;' \
- 'YF-Ugrow-G0=1eba44dbebf62c27ae66e16d40e02964;' \
- 'YF-V5-G0=5f9bd778c31f9e6f413e97a1d464047a;' \
- 'YF-Page-G0=8ec35b246bb5b68c13549804abd380dc;' \
- 'WBtopGlobal_register_version=370d73e0c771001f;' \
- 'login_sid_t=1a1f99aaff13878558a61d66c6b9c0a4;' \
- '_s_tentry=www.baidu.com;' \
- 'Apache=8569250075753.363.1473054803408;' \
- 'SSOLoginState=1473054827;' \
- 'SUB=_2A256yvvYDeTxGeBO6lES9yfMzj6IHXVZvmoQrDV8PUJbmtBeLWyjkW8OibLNYiqudnUDwBp6GgtGcUnFuQ..' #我删掉了一大部分
-
- driver = webdriver.PhantomJS(executable_path="D:\\phantomjs-2.1.1-windows\\bin\\phantomjs.exe", desired_capabilities=cap)
- driver.set_window_size(1120, 1100)
- # print(url)
- driver.get(url)
-
- page_source = driver.page_source
- # print(t)
- #
- # contents = driver.find_elements_by_tag_name("<a>")
- #
- # for content in contents:
- # print(content.text)
- return page_source
-
-
- from lib3 import spider
- from lib3 import fileWriter
- import os
- import sys
-
- class weiboSpider:
- def __init__(self,userAgent,userName,password):
- self.sp = spider.Spider(userAgent)
- self.loginStatus = login(userName, password)
- def go(self,url):
- status = True
- pageIndex = 1
- while status == True:
- fix = str(pageIndex)+"#Pl_Official_HisRelation__63"
- curUrl = url+fix
- print(curUrl)
- status = self.parse(curUrl)
- pageIndex += 1
- def cur_file_dir(self):
- #获取脚本路径
- path = sys.path[0]
- #判断为脚本文件还是py2exe编译后的文件,如果是脚本文件,则返回的是脚本的目录,如果是py2exe编译后的文件,则返回的是编译后的文件路径
- if os.path.isdir(path):
- return path
- elif os.path.isfile(path):
- return os.path.dirname(path)
-
- def saveData(self,fansUrl,fansId):
- fHandle = fileWriter.FileWriter(self.cur_file_dir(),'zhiHuData.txt','a')
- fHandle.write(fansUrl+'\t'+fansId+'\r\n')
- fHandle.close()
-
- def parse(self,url):
- if self.loginStatus == True:
- content = getWeiboPageContent(url)
- strPattern = '''<a class="S_txt1" target="_blank" usercard=".*?" href="(.*?)">(.*?)</a>'''
- resultsList = self.sp.parseReg(content,strPattern,2)
- if len(resultsList):
- for i in range(0,len(resultsList)):
- fansUrl = "http://wei.com"+resultsList[i][0]
- fansId = resultsList[i][1]
- self.saveData(fansUrl,fansId)
- print(fansUrl,fansId)
- return True
- else:
- print("no data")
- return False
-
- else:
- print("sorry,can not login weibo")
-
- if __name__ == "__main__":
- demo = weiboSpider('Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko','在此填写用户名','密码')
-
- demo.go('http://weibo.com/p/1005053810677006/follow?relate=fans&page=')

上面引用的lib3是我自己写的一个http接口
fileWriter.py
- __author__ = 'zhengjinwei'
- #coding=utf-8
- import os
-
-
-
- class FileWriter:
- def __init__(self,fileDir,fileName,format):
- self.mkDir(fileDir)
- self.f = open(fileDir+u"/"+fileName,format)
-
- def mkDir(self,path):
- isExists = os.path.exists(path)
- if not isExists:
- os.makedirs(path)
- def write(self,contents):
- return self.f.write(contents)
-
- def close(self):
- self.f.close()
- #coding:utf-8
- __author__ = 'zhengjinwei'
-
- import re
- import requests
-
- try:
- import cookielib
- except:
- import http.cookiejar as cookielib
-
-
- class Spider:
- def __init__(self,userAgent):
-
- self.user_agent = userAgent
- self.headers = {
- 'User-Agent' : self.user_agent
- }
- def getHttp(self,url,param=None):
- return requests.get(url,param,headers=self.headers)
-
- def postHttp(self,url,postData=None):
- return requests.post(url, data=postData,headers=self.headers)
-
- def sessionPostHttp(self,url,param=None):
- session = requests.session()
- session.cookies = cookielib.LWPCookieJar(filename='cookies')
- try:
- session.cookies.load(ignore_discard=True)
- print(url,param)
- return session.post(url,data=param,json=None,headers=self.headers)
- except:
- print("Cookie 未能加载")
- return None
-
- def sessionGetHttp(self,url,param=None):
- session = requests.session()
- session.cookies = cookielib.LWPCookieJar(filename='cookies')
- try:
- session.cookies.load(ignore_discard=True)
- return session.get(url, headers=self.headers, allow_redirects=False)
- except:
- print("Cookie 未能加载")
- return None
- def parseReg(self,content,strPattern,count):
- pattern = re.compile(strPattern,re.S)
- items = re.findall(pattern,content)
-
- contents=[]
-
- for item in items:
- temArr = []
- for i in range(0,count):
- temArr.append(item[i])
- contents.append(temArr)
-
- return contents
-
- def getContents(self,url,strPattern,count,method="get",param=None):
- page = ""
- if method == "get":
- page = self.getHttp(url,param).text
- else:
- page = self.postHttp(url,param).text
-
- pattern = re.compile(strPattern,re.S)
- items = re.findall(pattern,page)
- contents=[]
-
- for item in items:
- temArr = []
- for i in range(0,count):
- temArr.append(item[i])
- contents.append(temArr)
-
- return contents
-
-
-
- # demo = Spider("Mozilla/5.0 (Windows NT 6.1; WOW64; Trident/7.0; rv:11.0) like Gecko")
- #
- # t = demo.getHttp("https://www.baidu.com/index.php?tn=02049043_23_pg")
-
-
-
-
效果图:
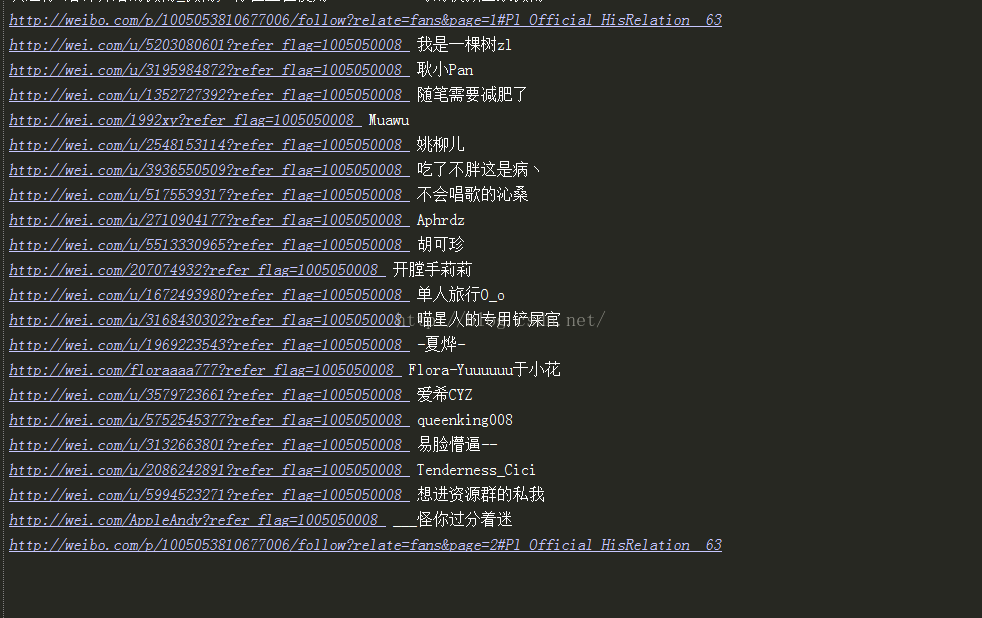
注意事项:
1,新浪微博本身有查看限制,只能查看到前5页的数据
2,爬虫工具可以使用火狐浏览器,装上fireDebug 插件用于拦截消息,获取cookie和其他参数
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/article/detail/56786?site
推荐阅读




相关标签

