
- 1基于PPYOLOE+的水下生物目标检测_为什么要做水下显著目标检测
- 2vue2 百度地图点聚合_vue2 百度地图实现点聚合
- 3月入8.3k,新传文科生转行5G网络优化工程师,张雪峰:这专业,报考就打晕…
- 4信息安全人才这么受欢迎,为何从业者这么少?_信息安全从业者的低替代性
- 5Android Camera相机以及相机程序开发实例_android.hardware.camera 例程
- 6c#执行php,致PHP程序员:快速执行C#代码片段 快速运行C#代码 调试C# C#写人文件操作...
- 7ros源码分析(三)ros::spin( )背后发生的事_couldn't register subscriber on topic [/]
- 8数据库分页大全
- 9微信小程序登录后端
- 10小程序可以通过以下几种方式下发消息_小程序怎么给用户推送消息
正则表达式-学习笔记_正则表达式禁止输入特殊字符
赞
踩
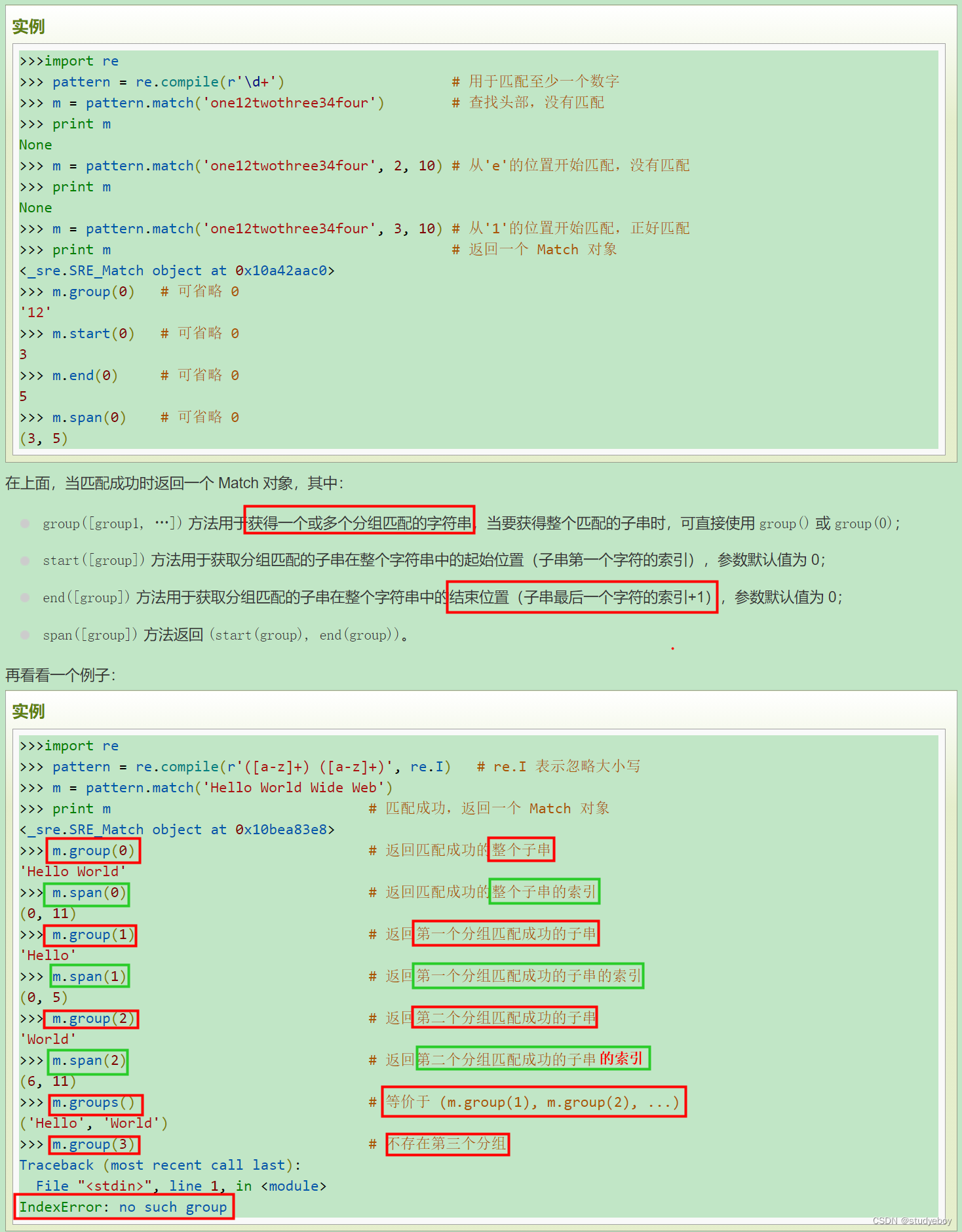
正则表达式(Regular Expression)是一种文本模式,包括普通字符(例如:a到z之间的字母)和特殊字符(称为“元字符”)。正则表达式使用单个字符串来描述、匹配一系列匹配某个句法规则的字符串。
正则表达式-简介

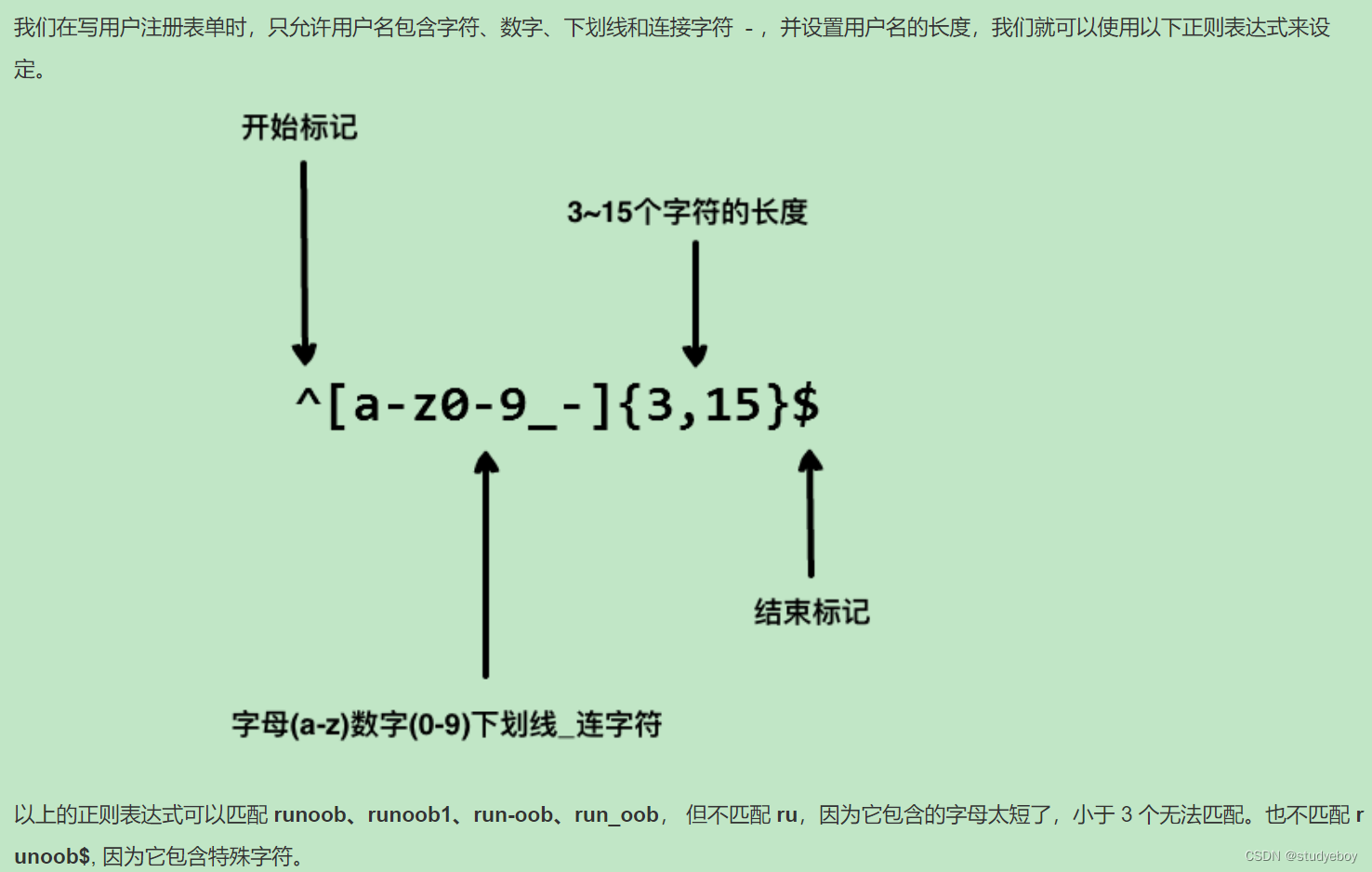
Python正则表达式
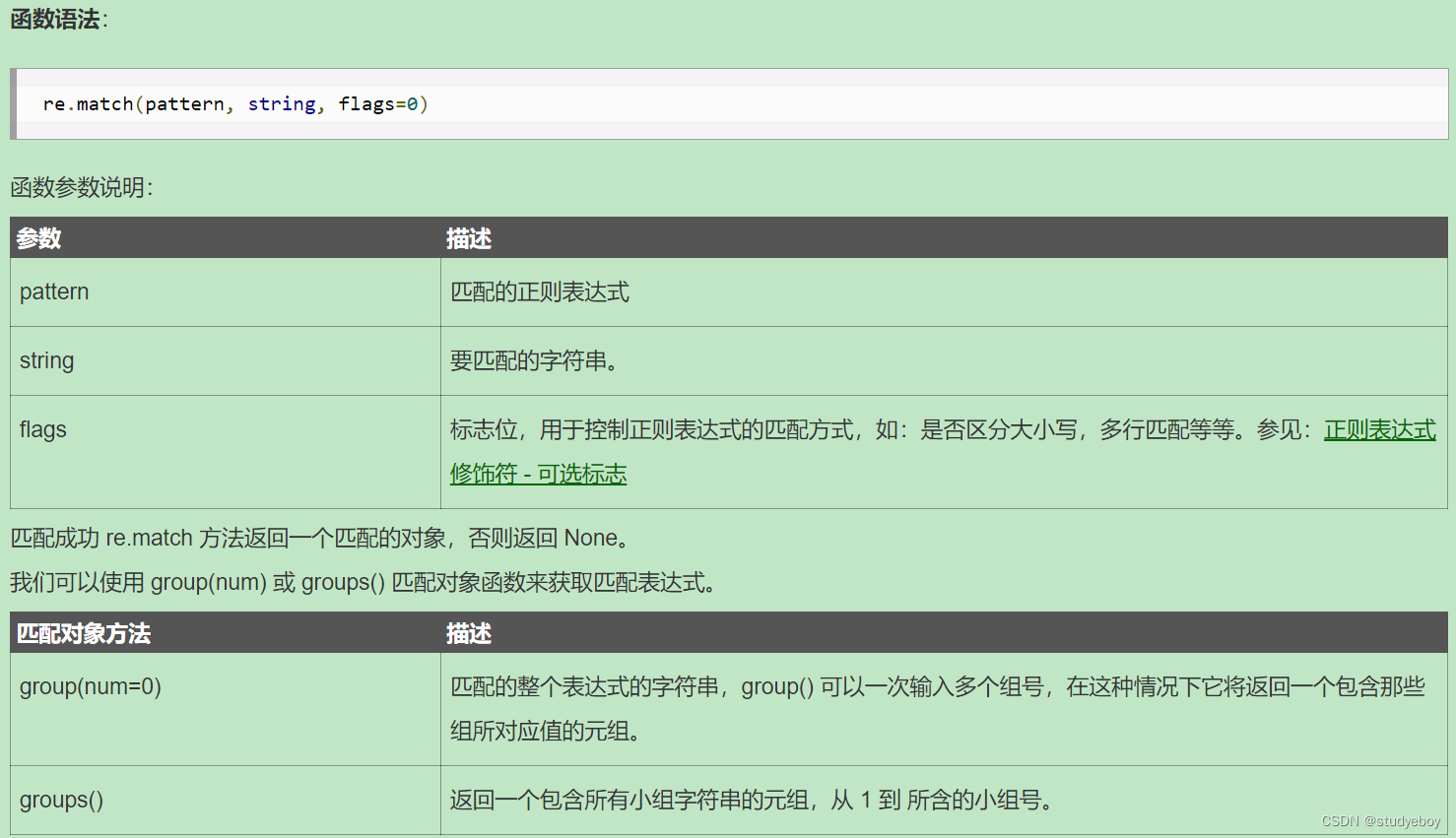
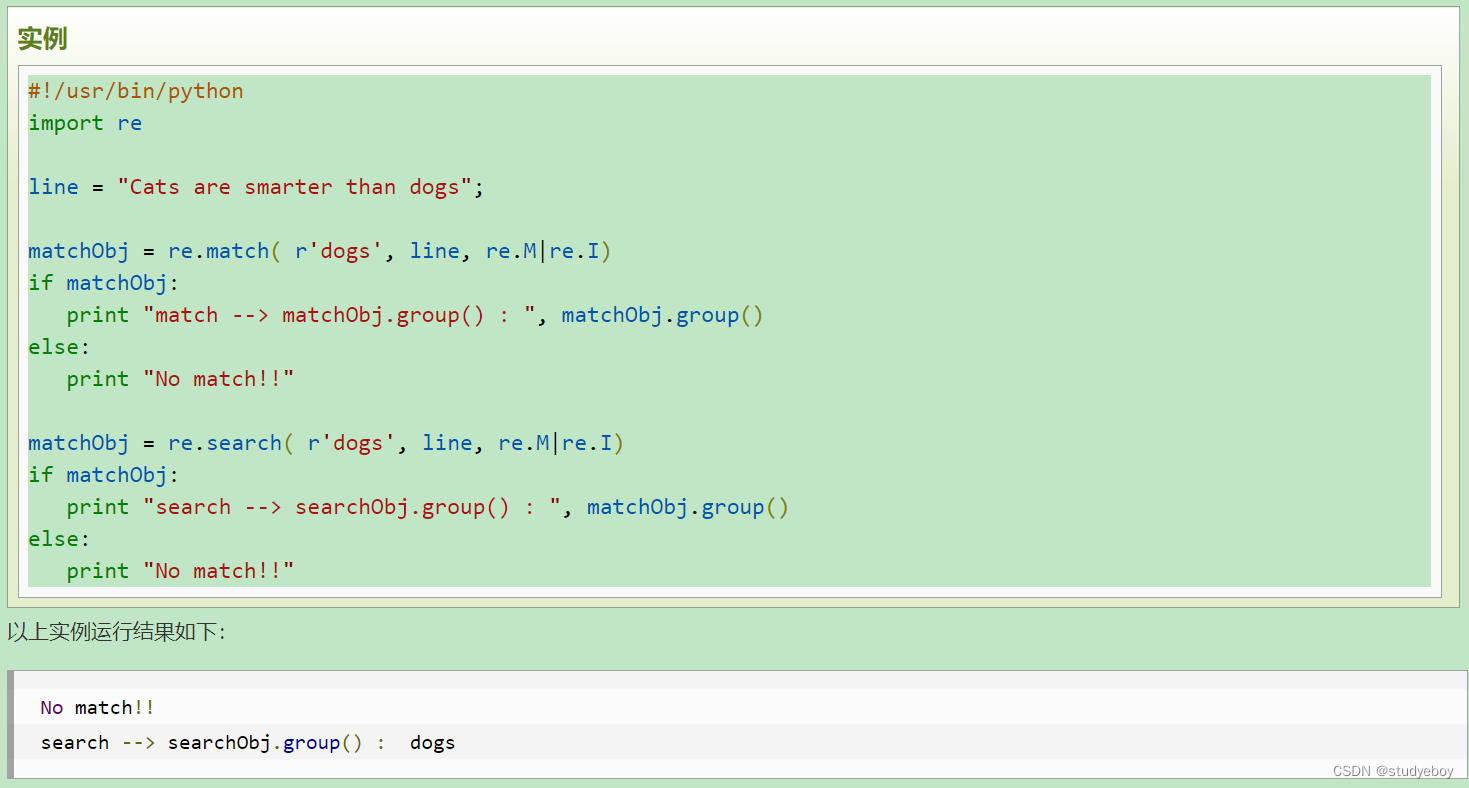
re.match函数
re.match函数尝试从字符串的起始位置匹配一个模式,如果不是起始位置匹配成功的话,match()就返回none。


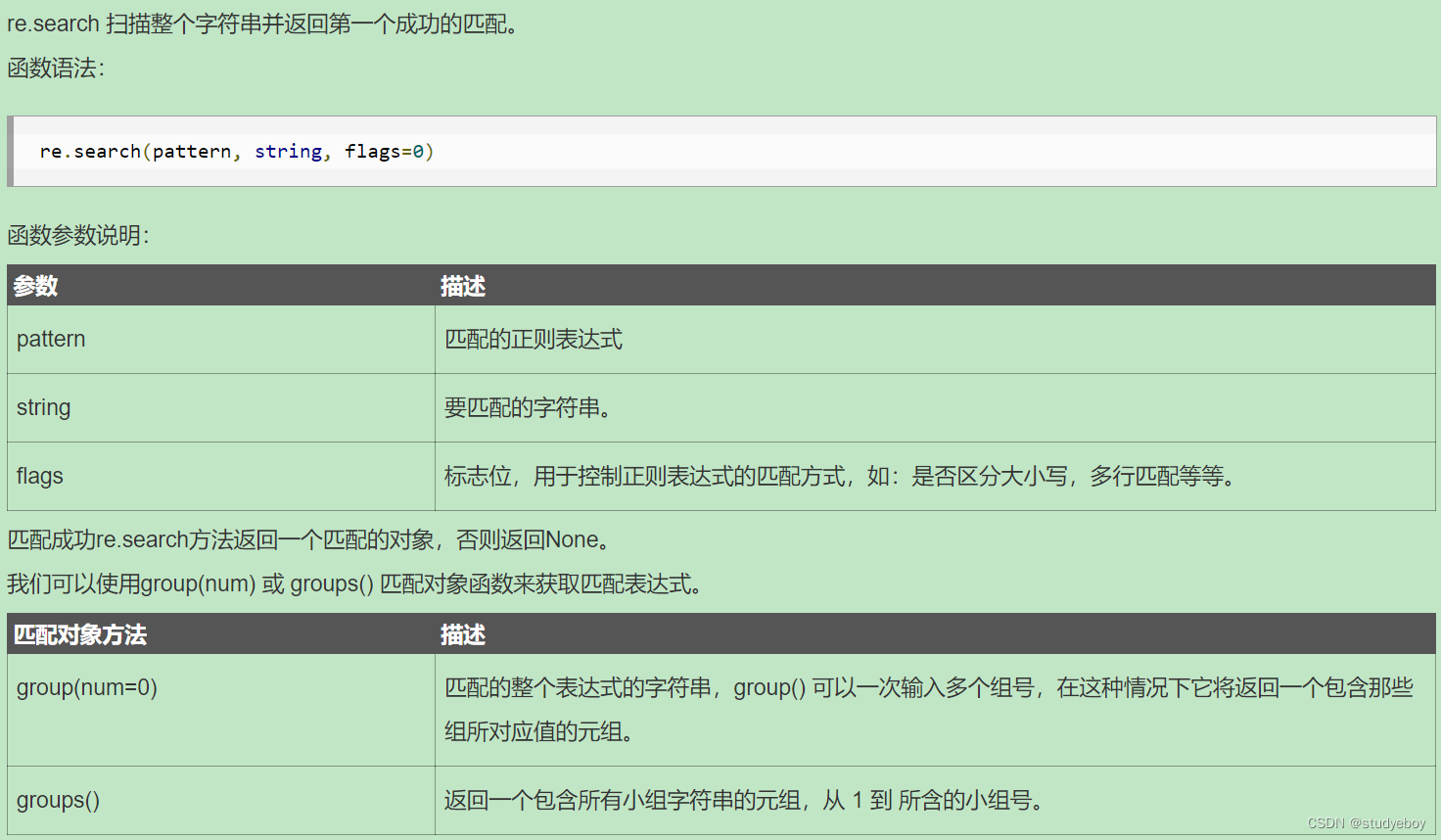
re.search方法
re.search扫描整个字符串并返回第一个成功的匹配。
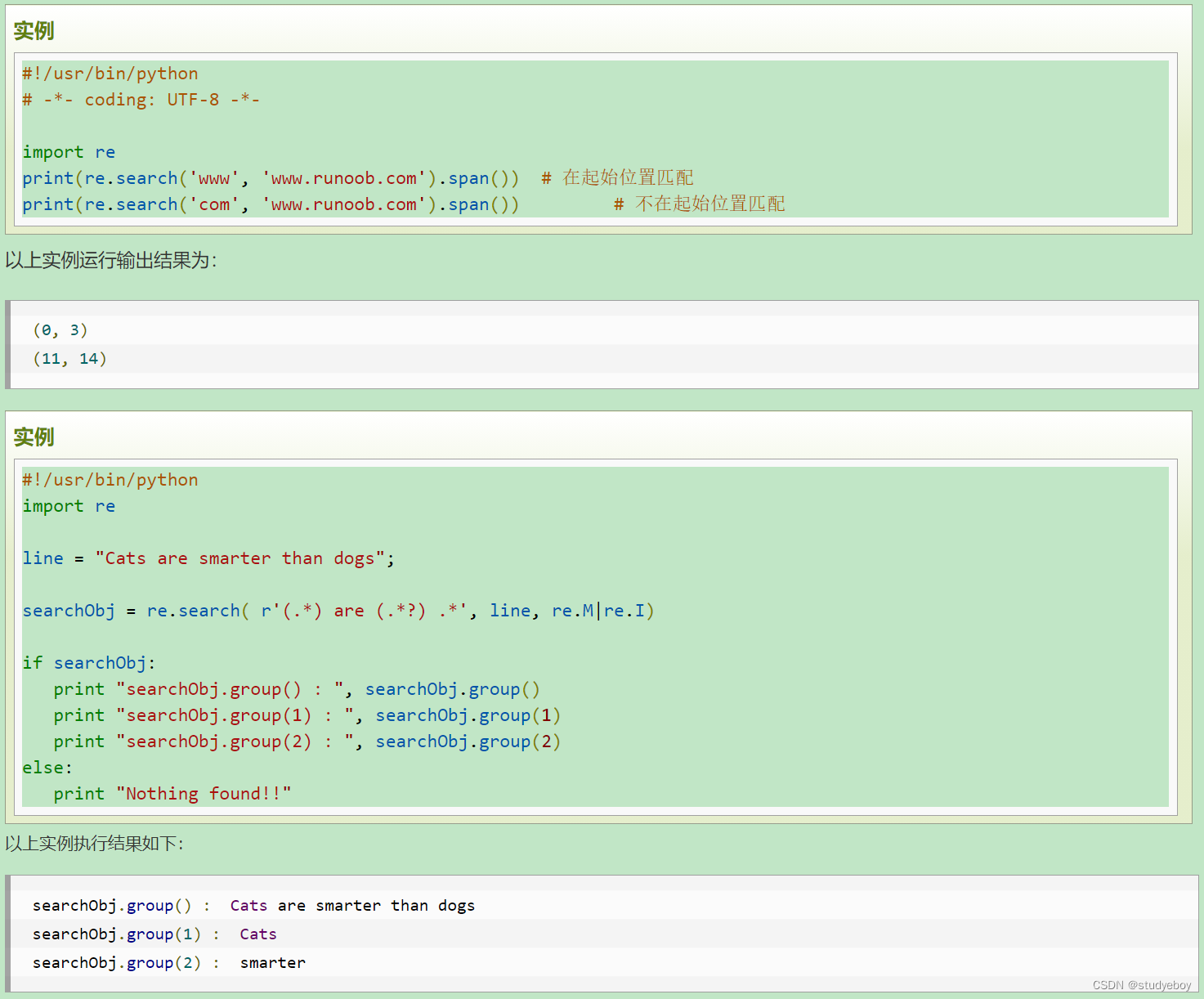
re.match和re.search的区别
re.match只匹配字符串的开始,如果字符串开始不符合正则表达式,则匹配失败,函数返回None;而re.search匹配整个字符串,直到找到一个匹配。
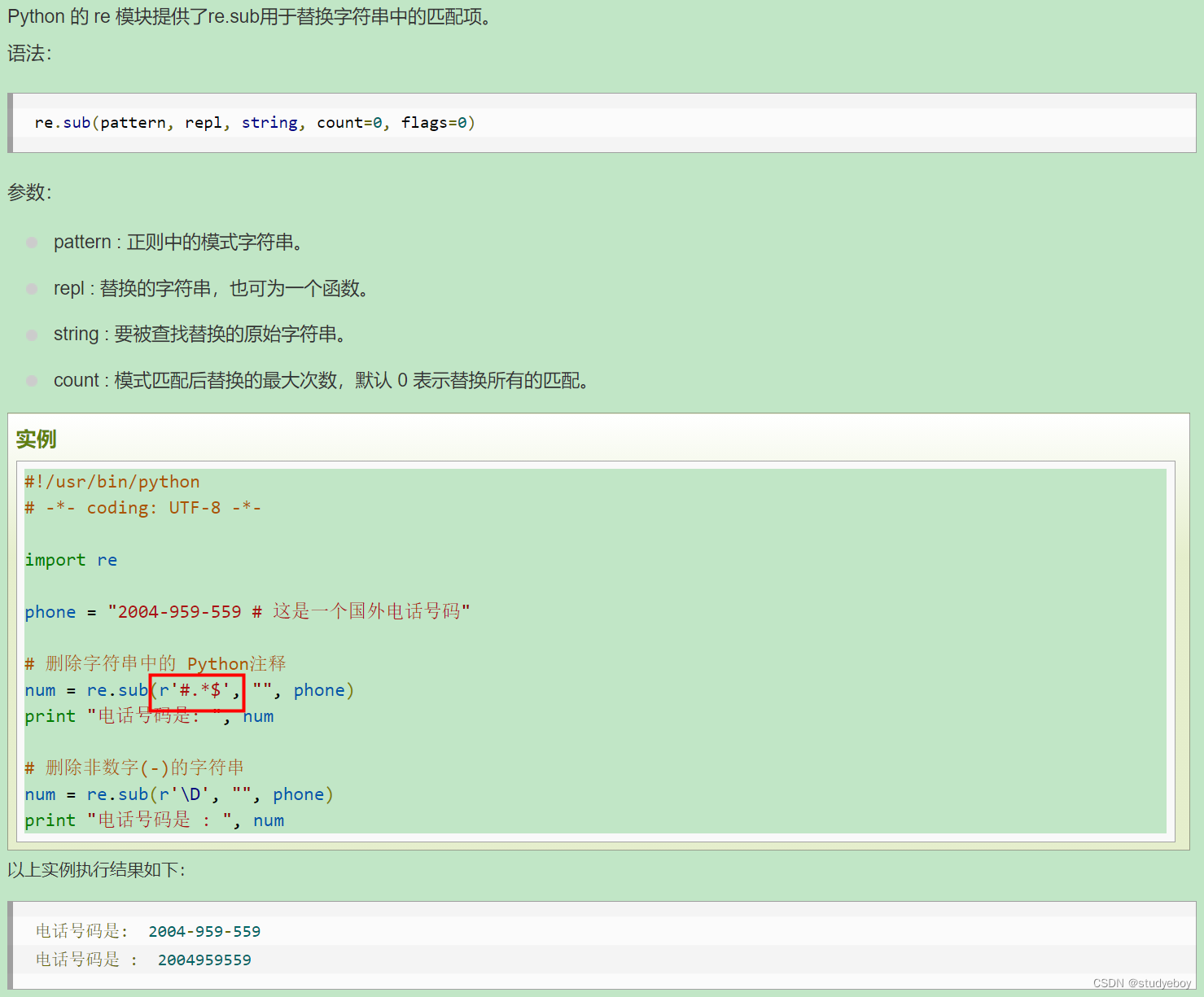
re.sub函数(检索和替换)
Python的re模块提供了re.sub用于替换字符串中的匹配项。
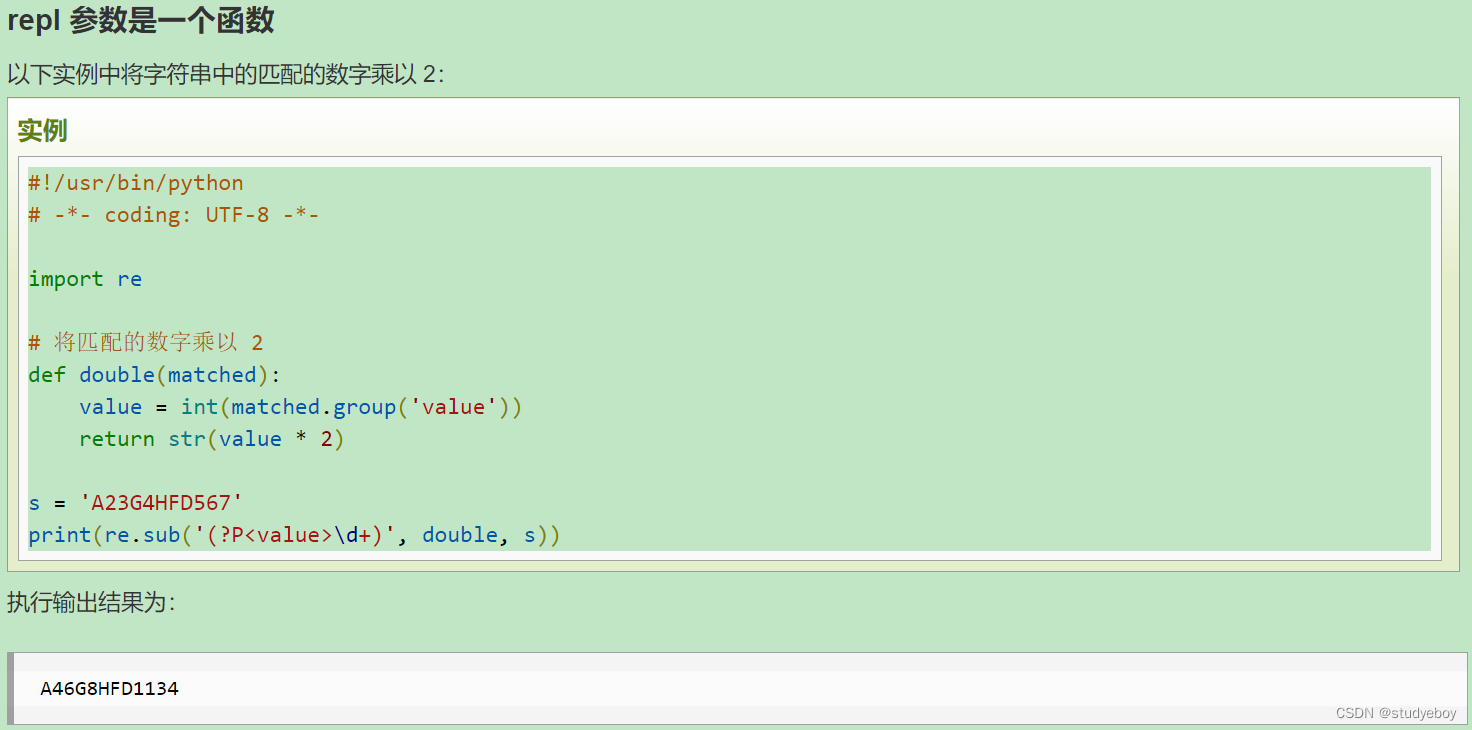
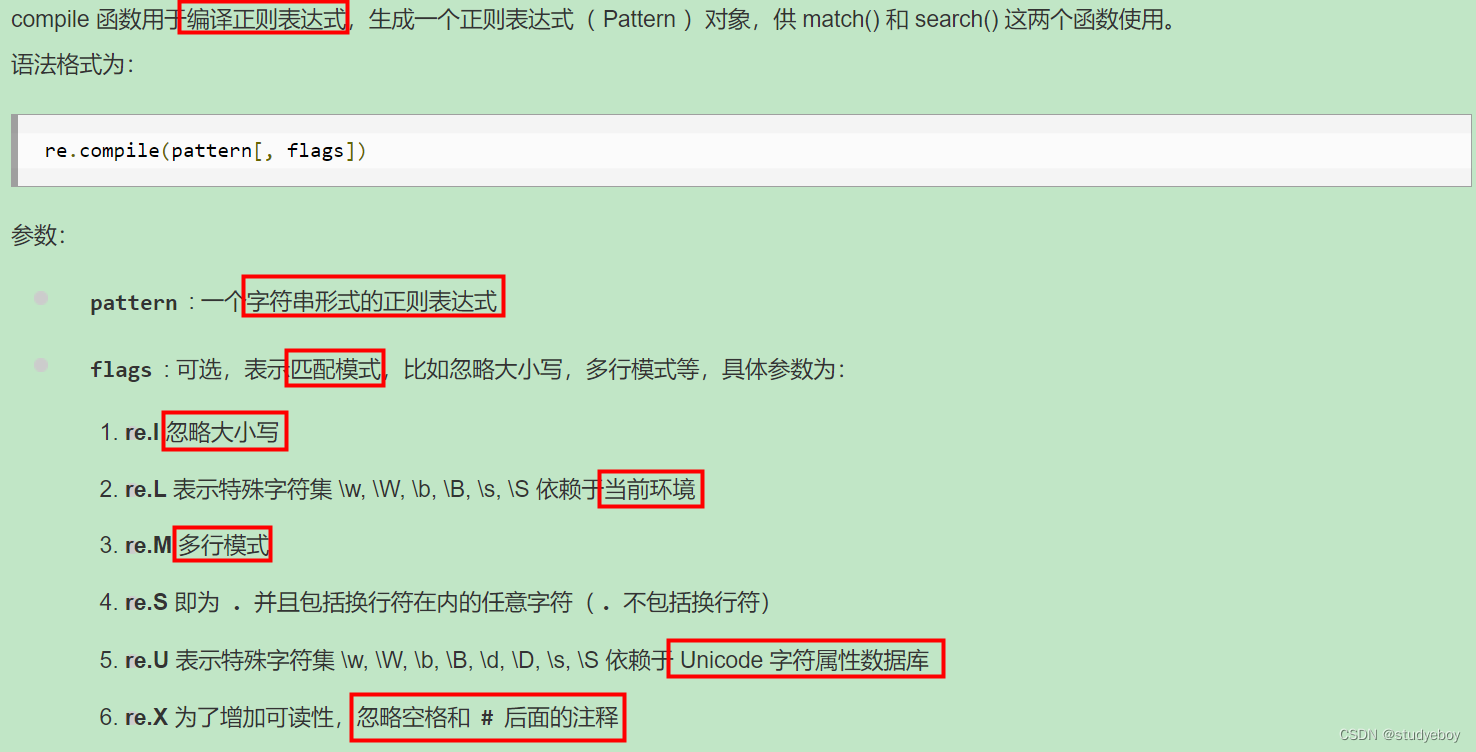
re.compile函数
compile函数用于编译正则表达式,生成一个正则表达式(Pattern)对象,供match()和research()这个函数使用。
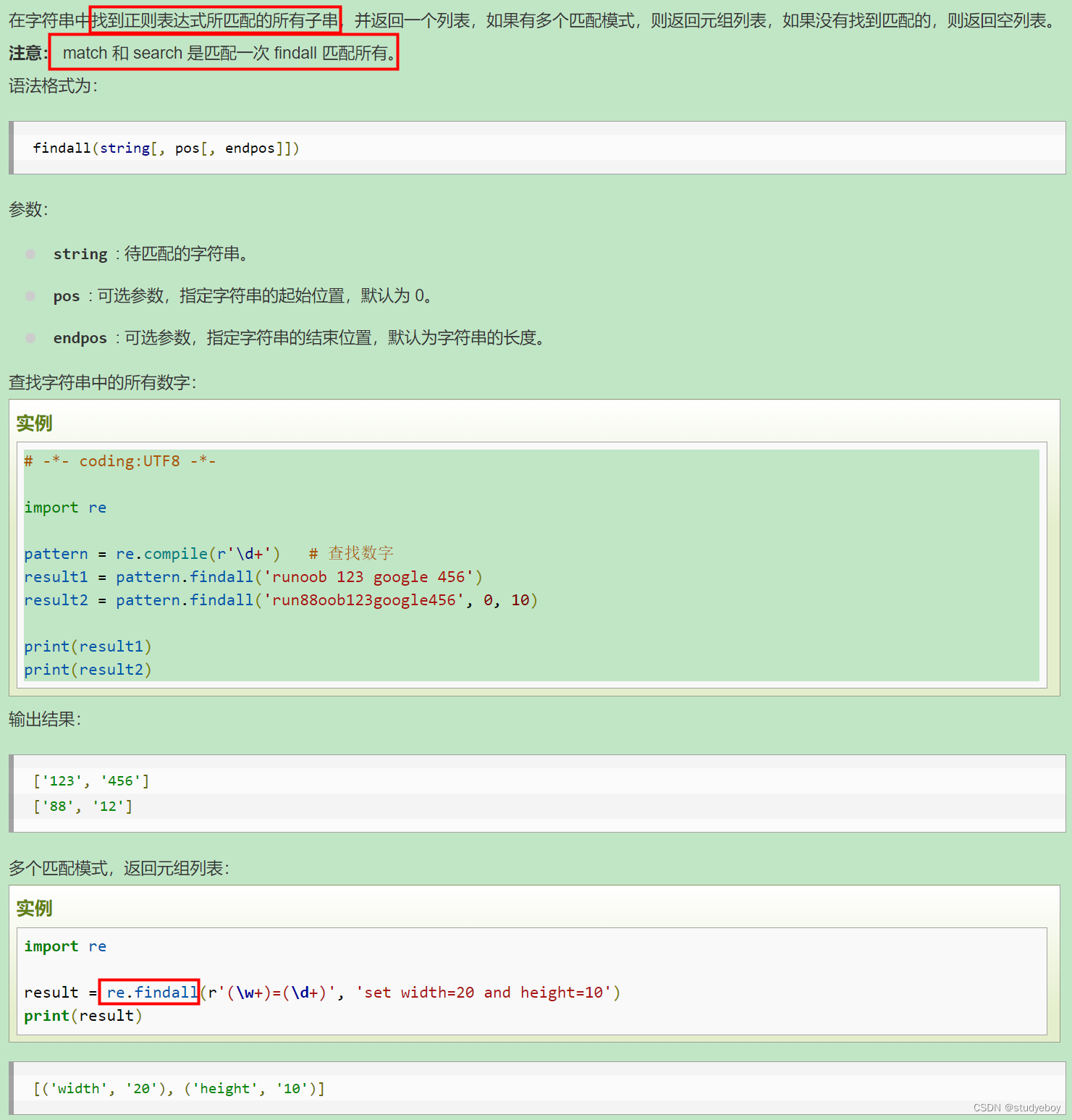
re.findall函数
在字符串中找到正则表达式所匹配的所有子串,并返回一个列表,如果有多个匹配模式,则返回元组列表,如果没有找到匹配的,则返回空列表。
注意:match和search是匹配一次findall是匹配所有。
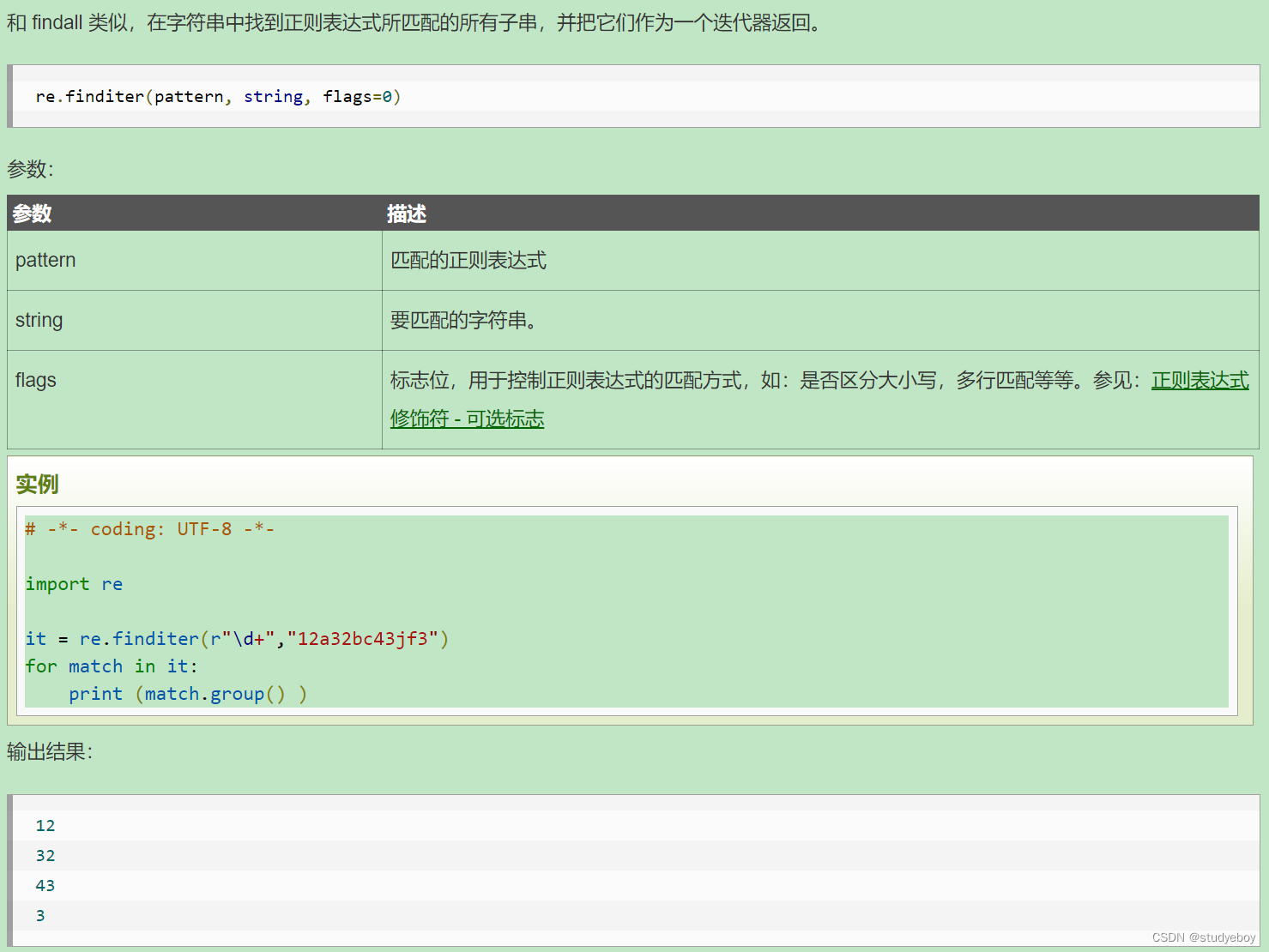
re.finditer函数
和findall类似,在字符串中找到正则表达式所匹配的所有子串,并把它们作为一个迭代器返回。
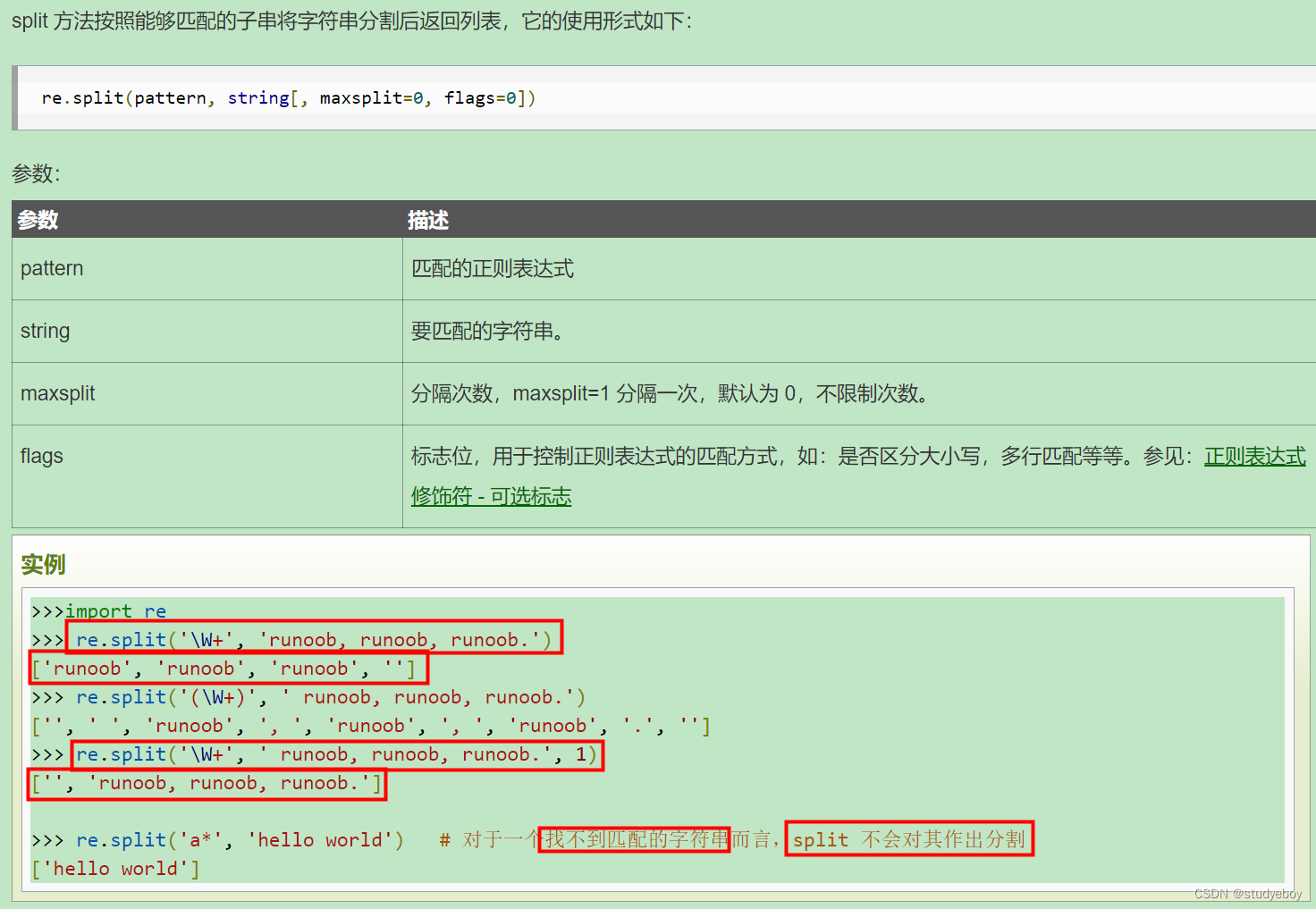
re.split函数
split方法按照能够匹配的子串将字符串分割后返回列表。
正则表达式对象

正则表达式修饰符-可选标志

正则表达式模式
模式字符串使用特殊字符的语法来表示一个正则表达式:
- 字母和数字表示它们自身。一个正则表达式模式中的字母和数字匹配同样的字符串。
- 多数字母和数字前加一个反斜杠时会拥有不同的含义。
- 标点符号只有被转义时才匹配自身,否则它们表示特殊的含义。
- 反斜杠本身需要使用反斜杠转义。
- 由于正则表达式通常包含反斜杠,所以最好使用原始字符串来表示,模式元素(如r’\t’,等价于’\t’)匹配相应的字符串。
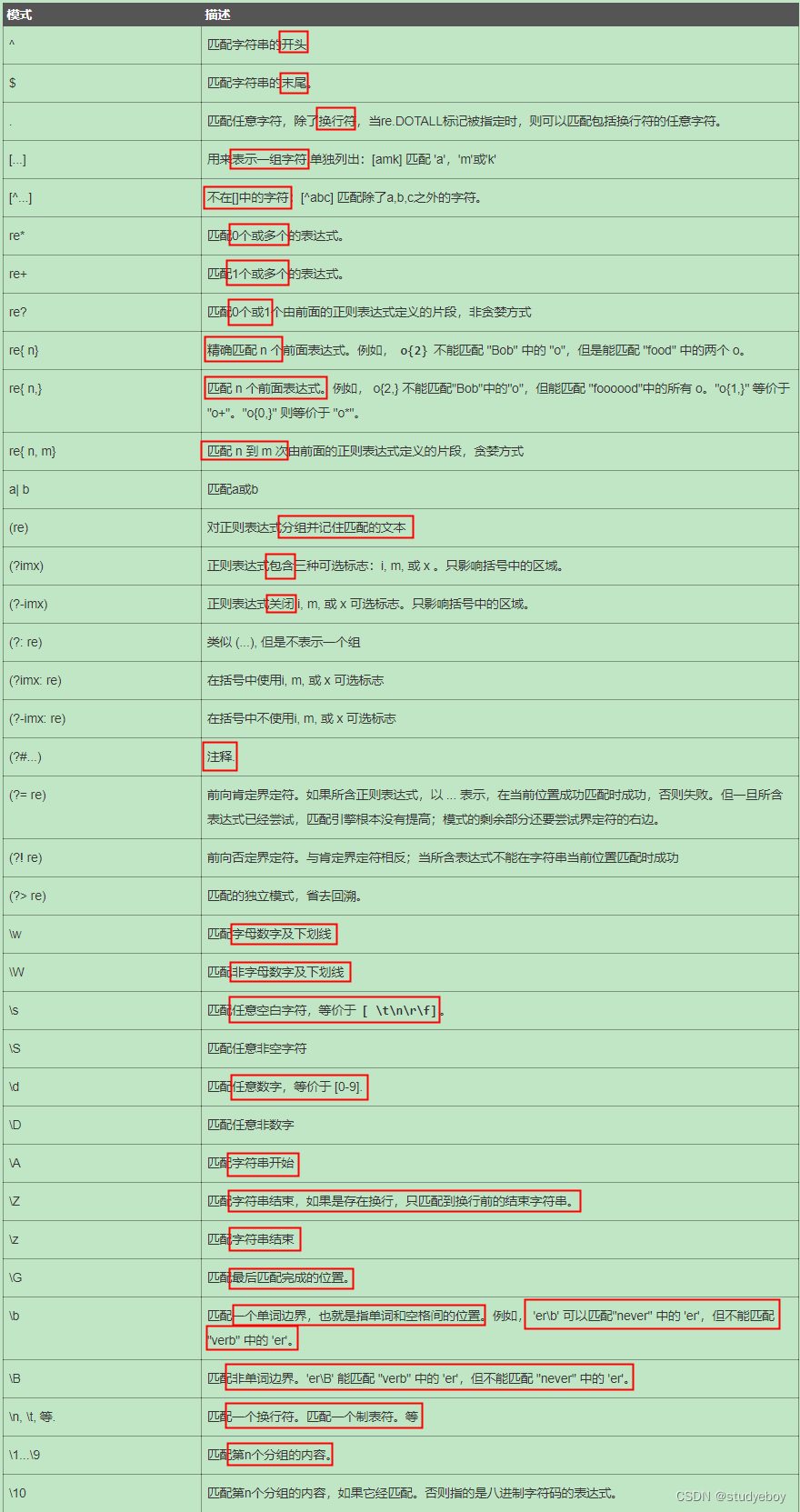
正则表达式-语法
正则表达式(regular expression)描述了一种字符串匹配的模式(pattern),可以用来检查一个串是否含有某种子串、将匹配的子串替换或者从某个串中取出符合某个条件的子串等。

构造正则表达式用多种元字符与运算符将小的表达式结合在一起来创建更大的表达式。正则表达式的组件可以是单个字符、字符集合、字符范围、字符间的选择或者所有这些组件的任意组合。
正则表达式是由普通字符(例如a到z)以及特殊字符(称为“元字符”)组成的文字模式。模式描述在搜索文本时要匹配的一个或多个字符串。正则表达式作为一个模板,将某个字符模式与所搜索的字符串进行匹配。
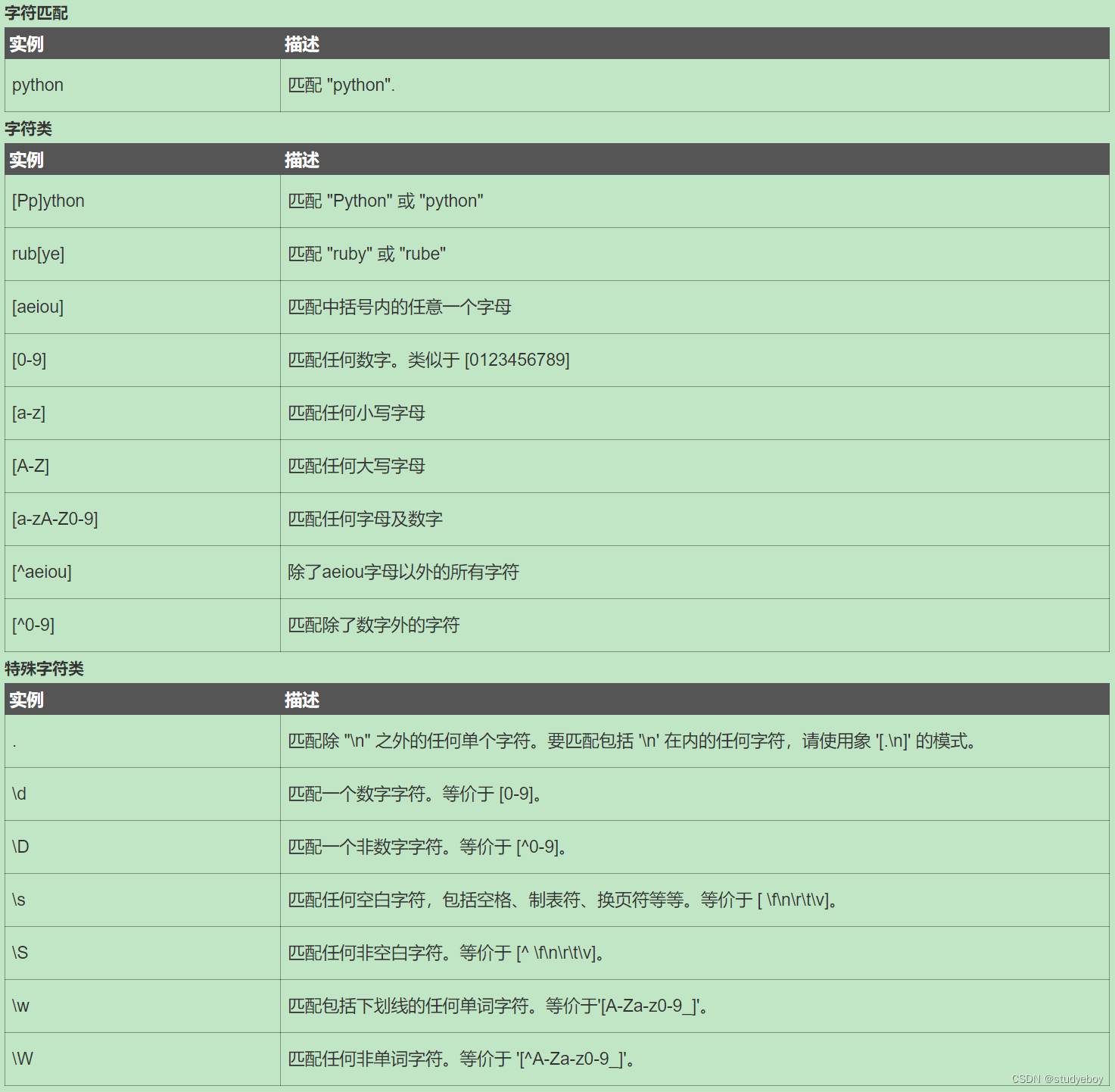
普通字符
普通字符包括没有显示指定为元字符的所有可打印和不可打印字符。包括大写和小写的字母、所有数字、所有标点符合和一些其它符号。
非打印字符
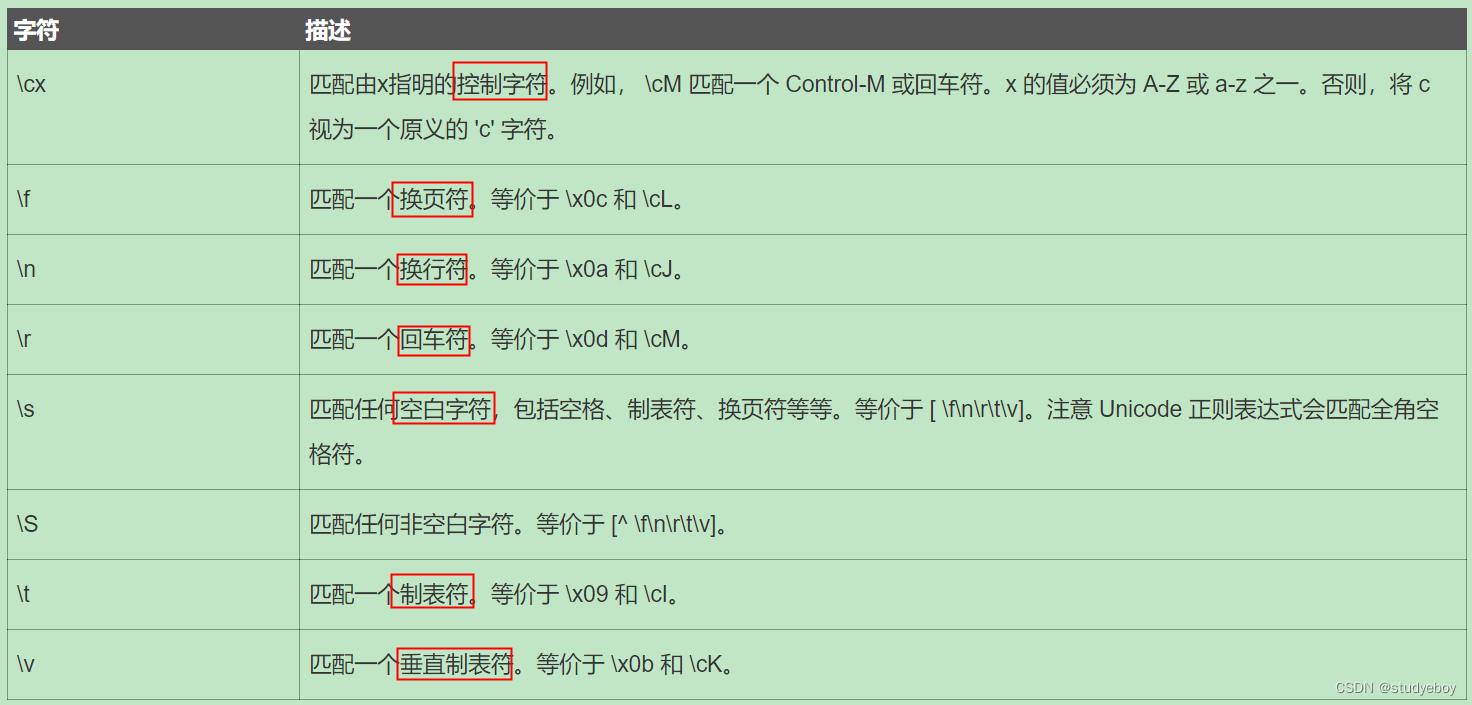
特殊字符
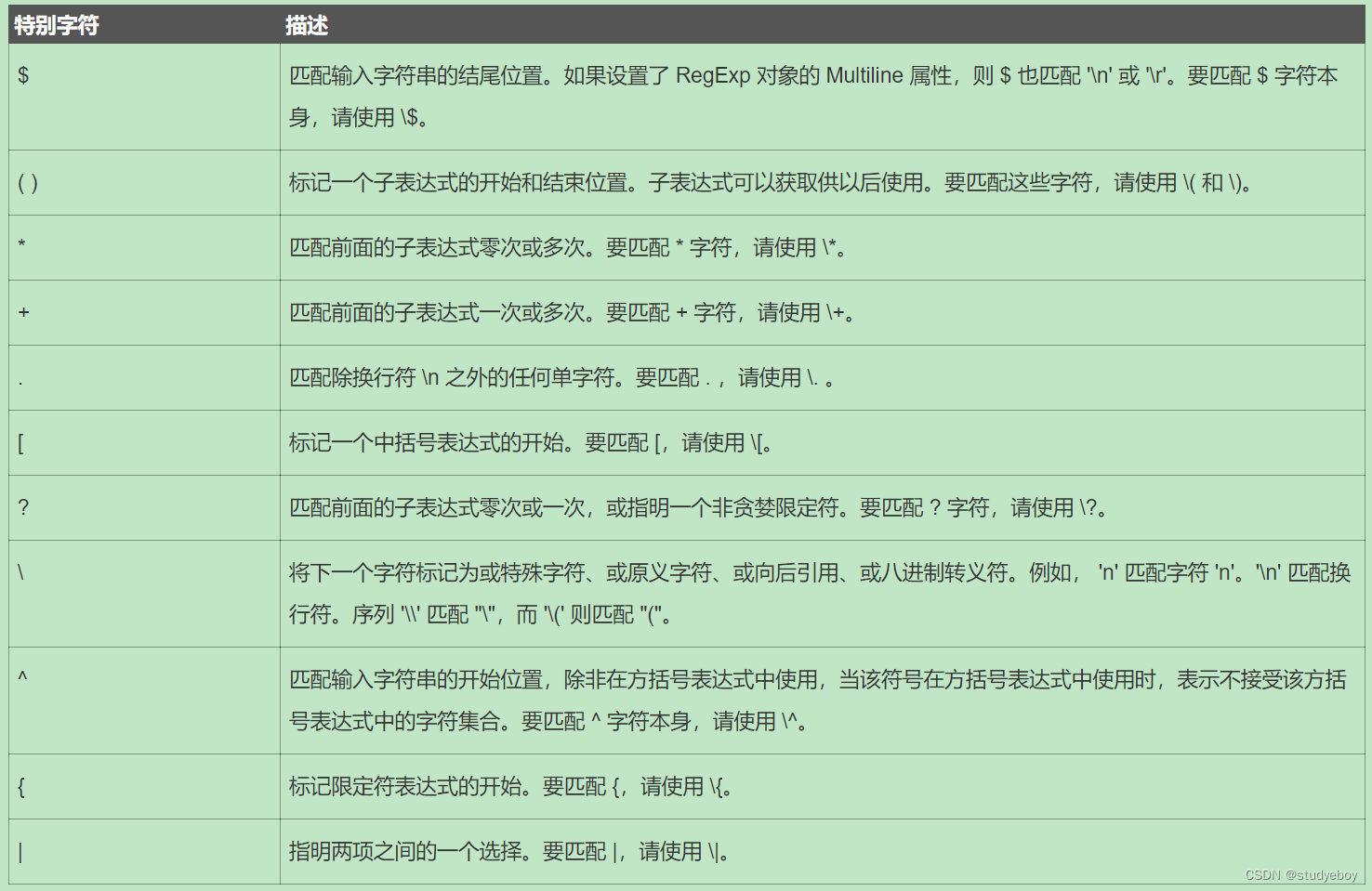
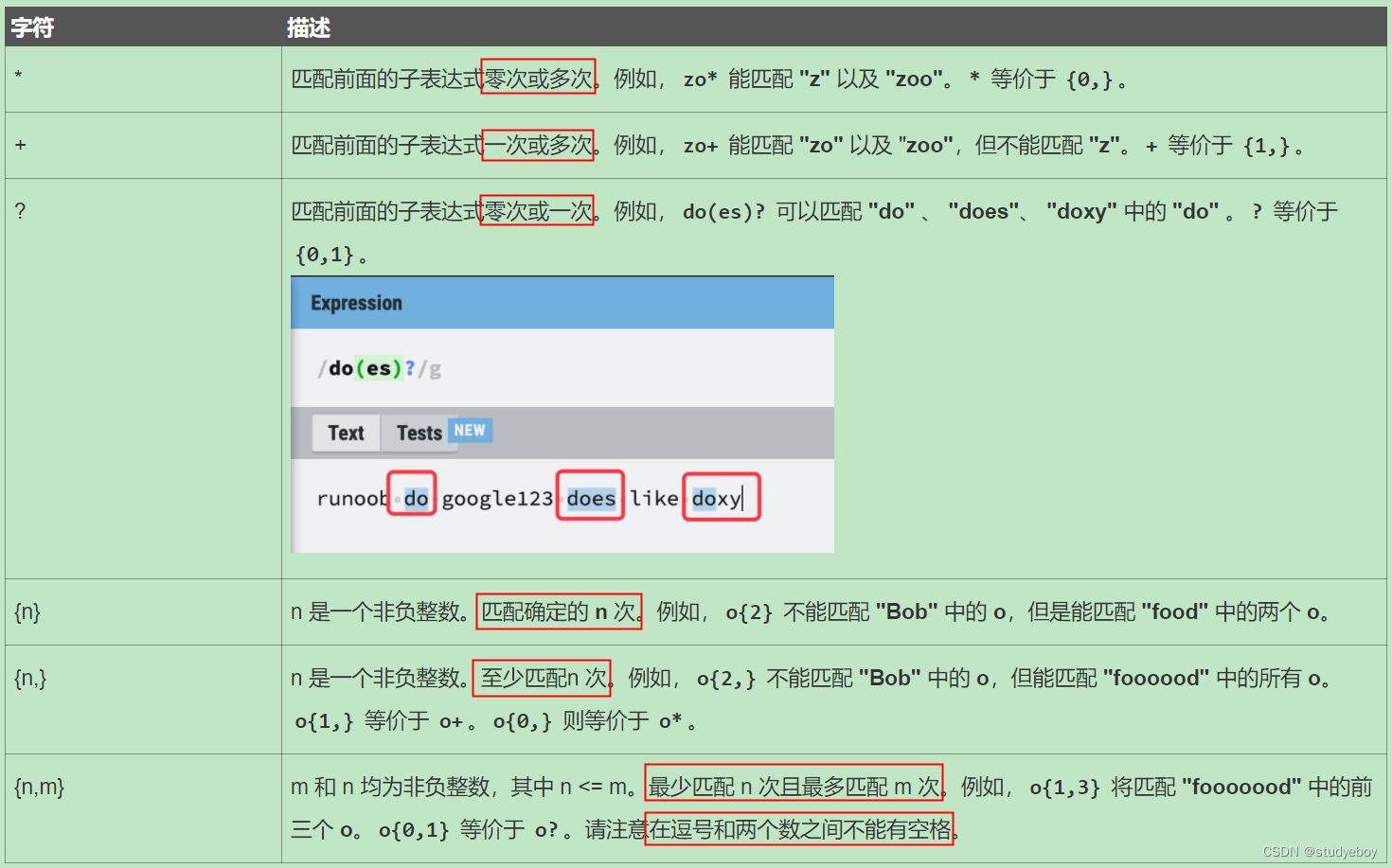
限定符
限定符用来指定正则表达式的一个给定组件必须要出现多次才能满足匹配。有*或+或?或{n}或{n,}或{n,m}共6种。
定位符
定位符能够将正则表达式固定到行首或行尾。这些正则表达式出现在一个单词内、在一个单词的开头或者一个单词的结尾。

选择
用圆括号()将所有选择项括起来,相邻的选择项之间用|分隔。()表示捕获分组,()会把每个分组里的匹配的值保存起来,多个匹配值可以通过数字n来查看(n使一个数字,表示第n个捕获组的内容)。但是圆括号会有一个副作用,使相关的匹配会被缓存,将?:放在第一个选项前面来消除这种副作用。
?=、?<=、 ?!、 ?<!的区别
-
exp1(?=exp2):查找exp2前面的exp1

-
(?<exp2)exp1:查找exp2后面的exp1

-
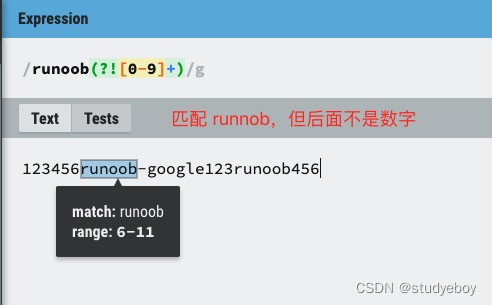
exp1(?!exp2):查找后面不是exp2的exp1
-
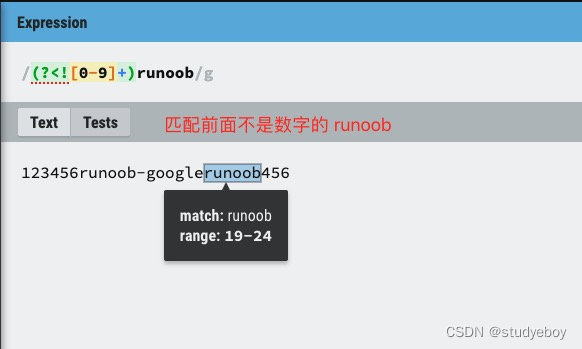
(?<!exp2)exp1:查找前面不是exp2的exp1
反向引用
正则表达式-修饰符(标记)
标记也称为修饰符,正则表达式的标记用于指定额外的匹配策略。标记不写在正则表达式里,标记位于表达式之外。

正则表达式-运算符优先级

正则表达式-匹配规则
基本模式匹配
字符簇
^表示字符串的开头,但它还有另外一个含义。当在一组方括号里使用 ^ 时,它表示"非"或"排除"的意思,常常用来剔除某个字符。
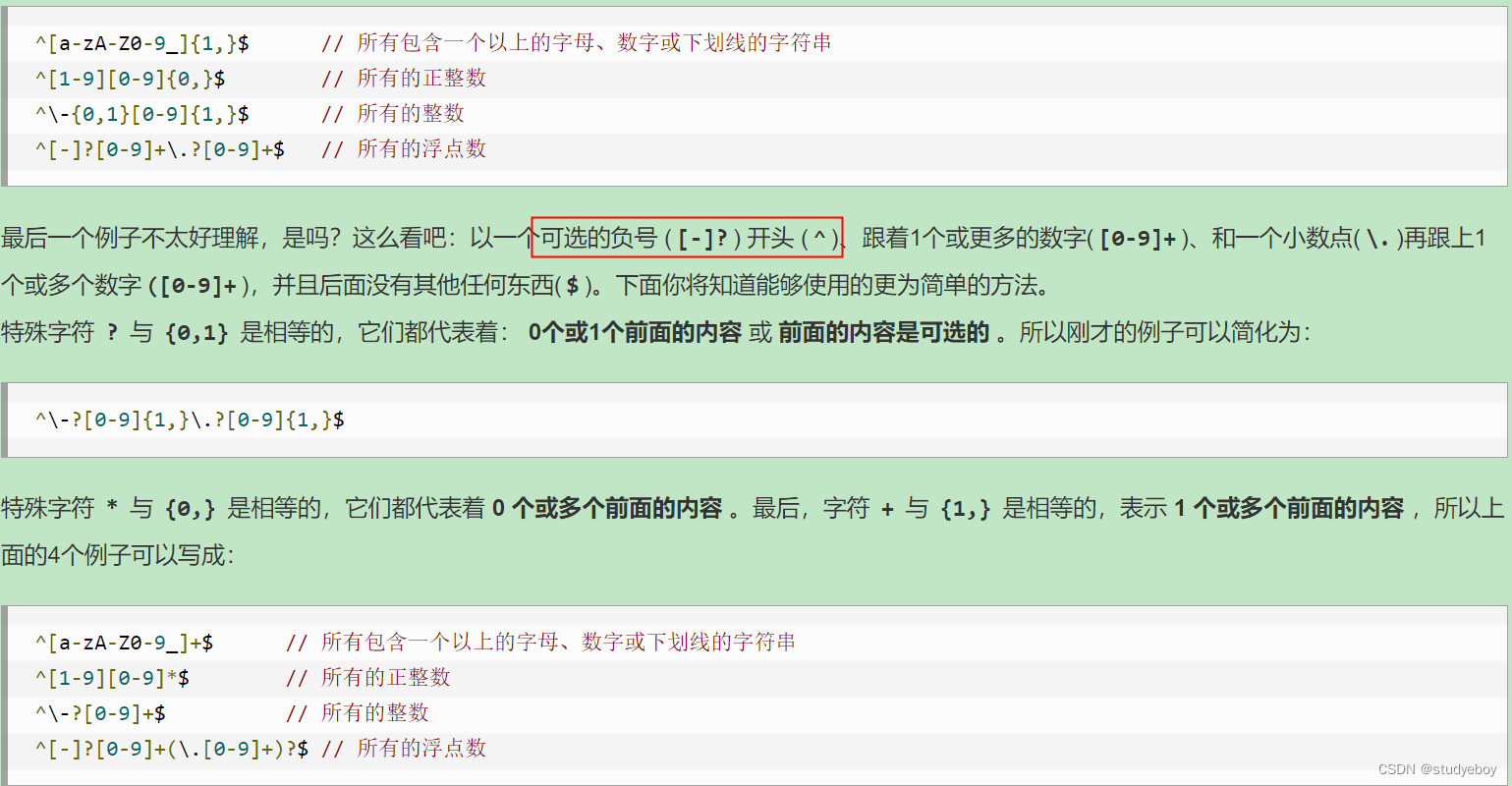
确定重复出现
参考资料
正则表达式 - 教程
Python 正则表达式
正则表达式的先行断言(lookahead)和后行断言(lookbehind)

