
- 1[架构之路-221]:鸿蒙系统和安卓系统的比较:微内核VS宏内核, 分布式VS单体式_鸿蒙微内核
- 2uniapp 安卓如何获取通话权限,监听通话情况_uniapp telephony_service
- 3关于罗德里格斯公式(Rodrigues‘sFormula)的详细推导过程
- 4风控安全产品系统设计的一些思考_风控系统设计
- 5【动态规划】【map】【C++算法】1289. 下降路径最小和 II
- 6物体检测技术的简单介绍
- 7Java 算法篇-深入了解单链表的反转(实现:用 5 种方式来具体实现)
- 8使用Golang语言walk框架开发一个简单的windowsGUI_golang walk
- 9关于在使用scrapy-redis分布式踩过的那些坑:
- 10Wireshark基本使用_wireshark使用
Python+Selenium爬取新浪微博数据_python怎么爬取微博实时数据
赞
踩
爬虫流程
1. 模拟登陆新浪微博
上一个博客有详细说明
https://blog.csdn.net/zczczcc/article/details/112198483 link.
2.爬取指定微博评论内容
我选择了“中国新闻网”发的一条微博https://m.weibo.cn/detail/4589546907894547进行分析
(选取评论数较少的微博即可)
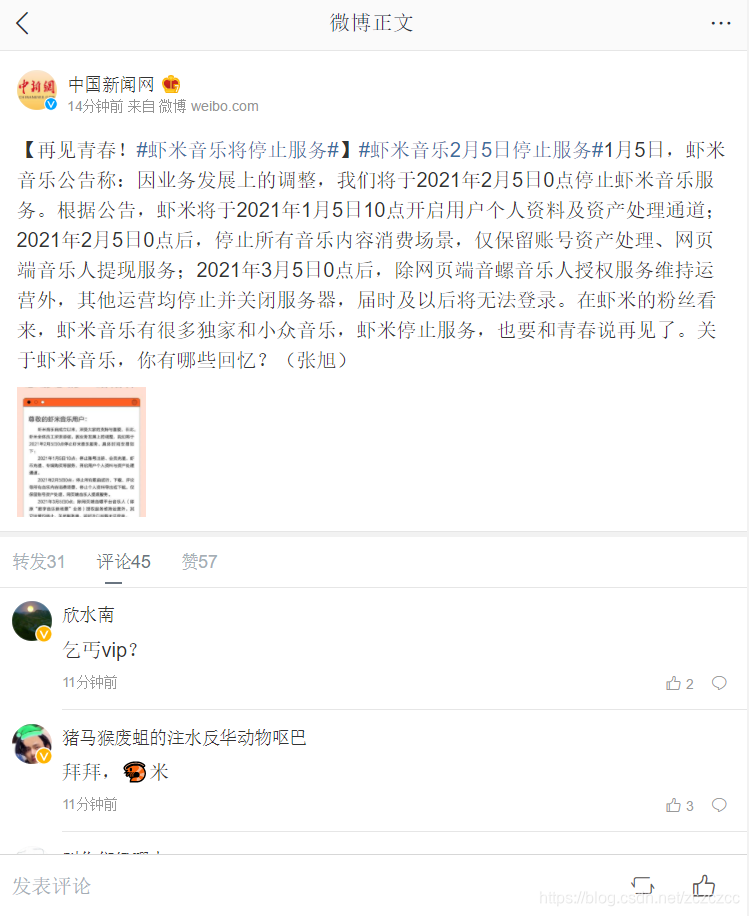
2.1分析网页
把鼠标挪到网页任意地方,单击鼠标右键,选择检查,进去Elements界面,点击检查框左上角的箭头,移动鼠标直接点击文字进行定位;
在文章中只有20个 div , 并且每个 div 中装载一条评论,每个页面原始就只能显示20条评论。
当我们把鼠标不断向下滑动的过程中,网页元素中的 div 也不断随评论的增加而增加,当活动到底部时,所有评论都加载出来了。可以初步判断该网页属于ajax加载类型,所以先就不要考虑用requests请求服务器了。
2.2获取数据
2.2.1 方法一:抓包
浏览器的中的每一条信息的加载都离不开 Network ,这就意味着我们可以通过它来查看网页加载出来的内容。
抓包的步骤:
1.鼠标右击,打开检查功能
2.选择Network
3.刷新网页
4.查看加载的数据
如何更好的查看加载的内容是什么?
1.我们的目的只是找到自己需要的内容,没有必要全部都查看一遍,只需要知道一些关键的数据进行查看就好了。
最重要的是注意 Network 中的Type(加载的文件类型) 和 size(加载的文件大小) 这两个要素,如我们要查看的目标是文字文件,带有图片类型的文件都可以不用查看了,其二就是它的大小,上面的很多文件都没有显示大小,我们几乎可以把它忽略了。
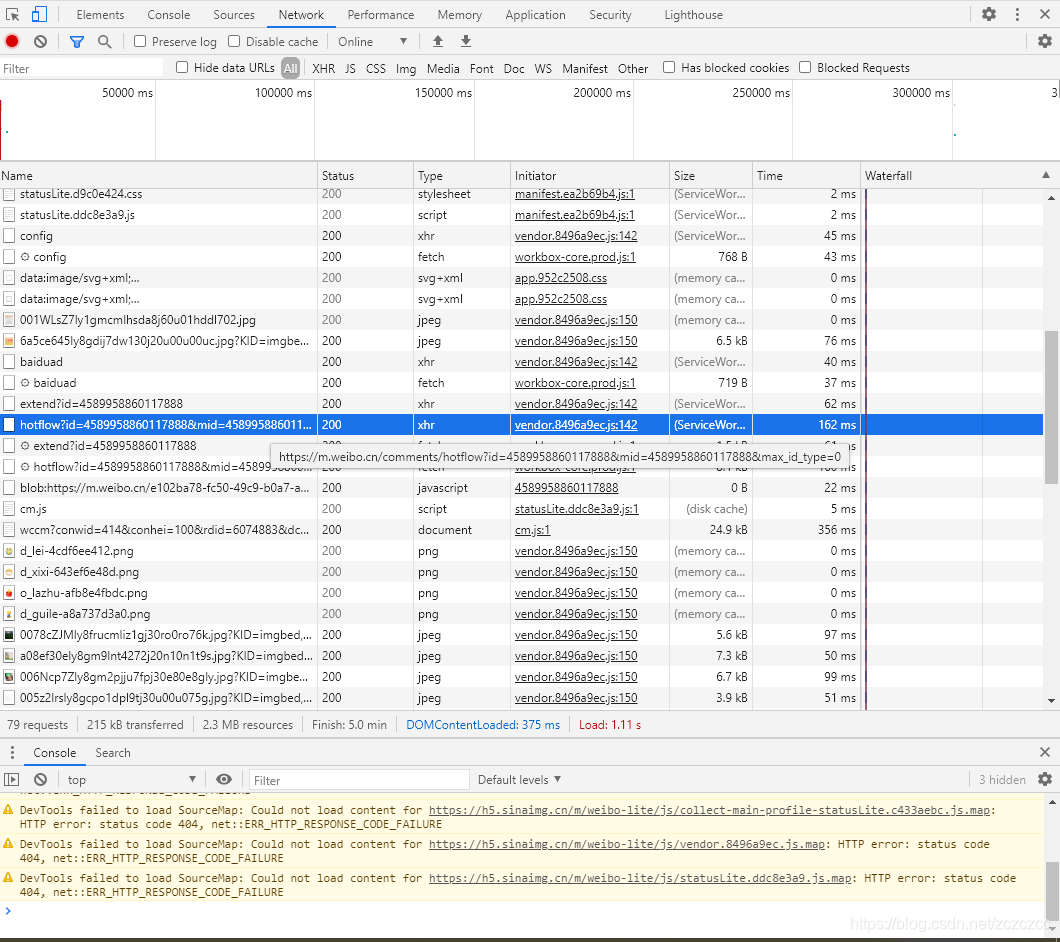
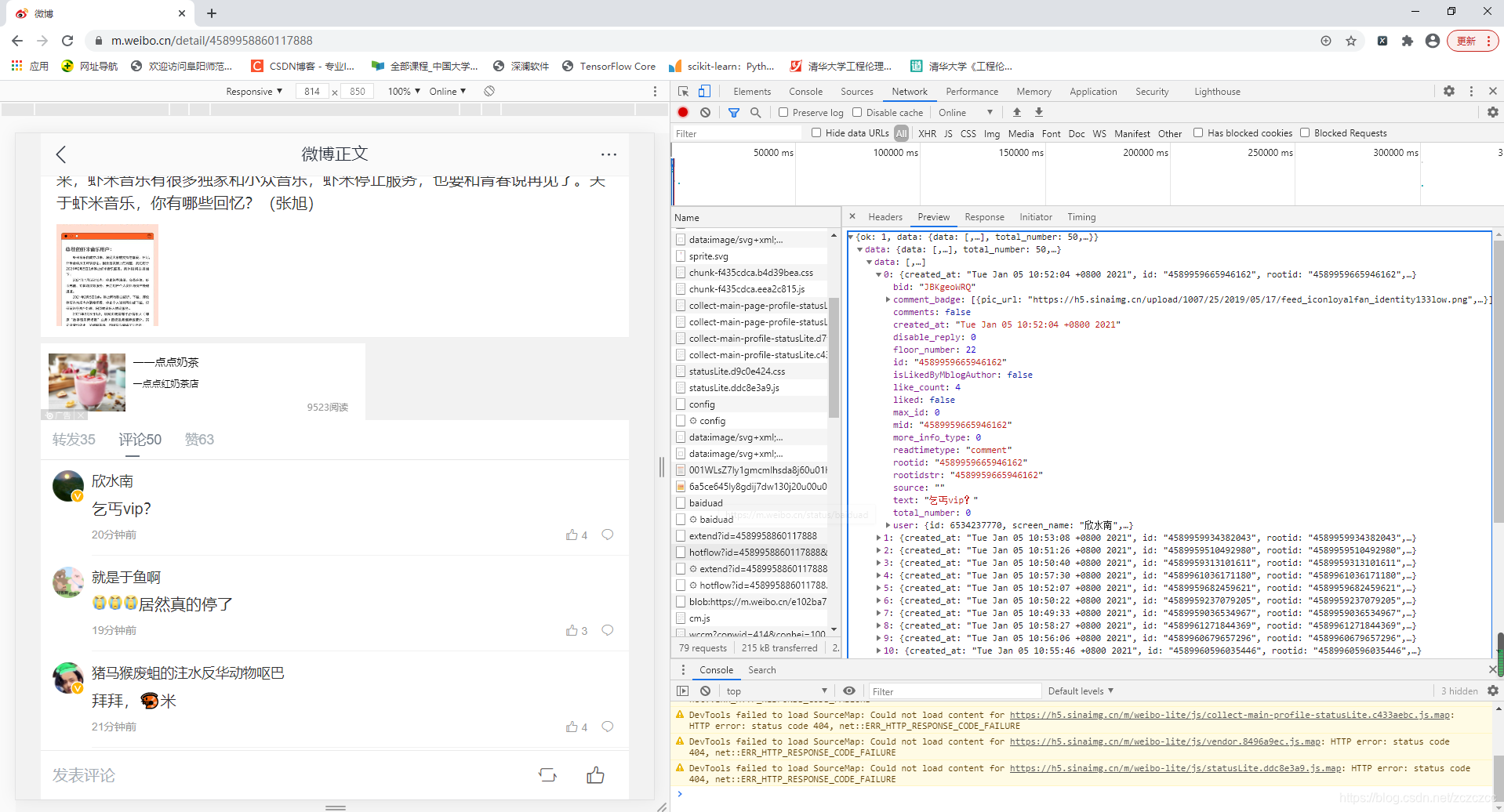
(本例的text内容是可以看出来的,如上图右侧所示。但是大多情况下文字内容显示不出来,则需要做下面2的处理)
2.双击
但是text的内容并不认识(因为其是json格式文件)
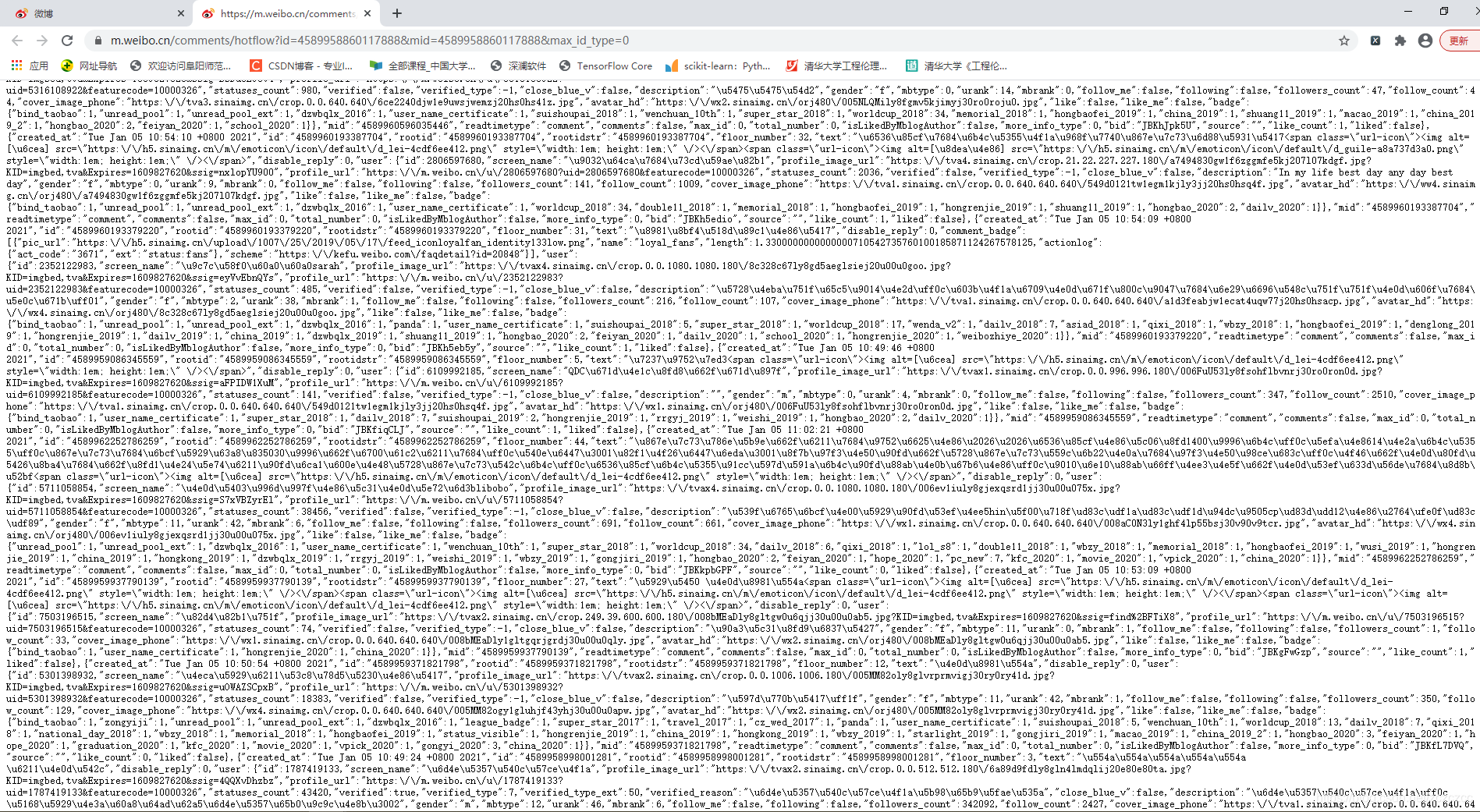
先把这个内容复制,再找个json解析器在线解析一下。
如用这个解析器: https://www.json.cn/ ,把刚才的内容粘贴进来再看看结果:
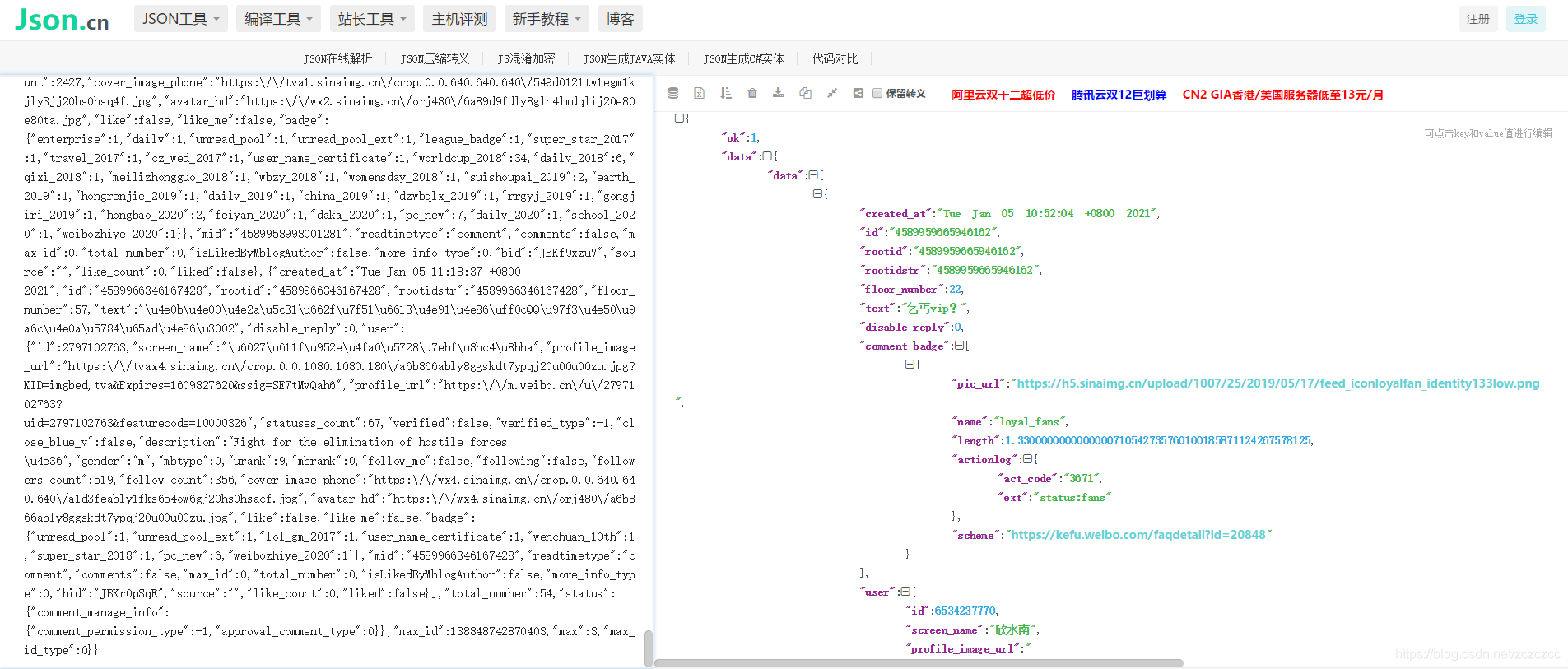
复制这个路径,python请求看看:
路径的获得方法:
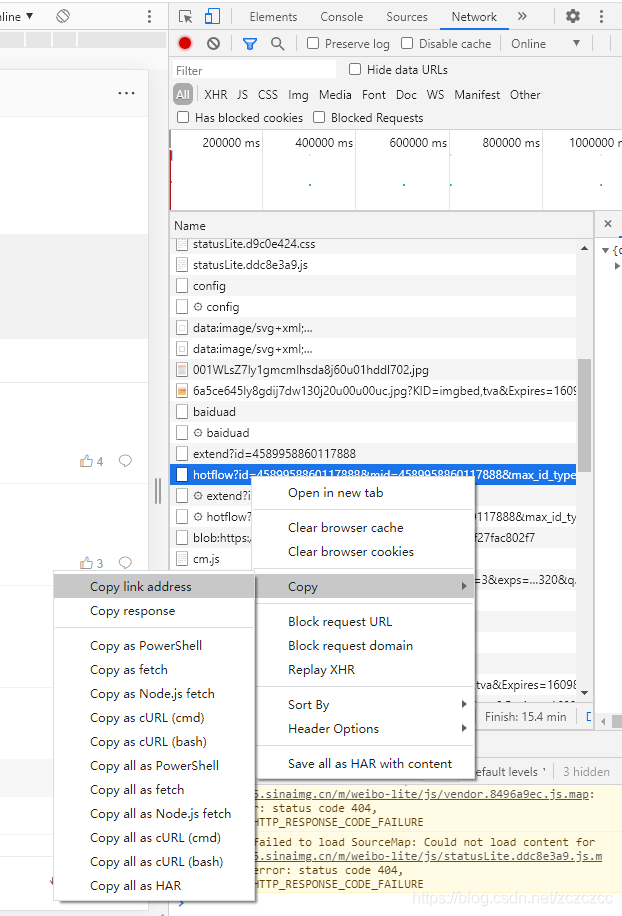
即运行以下代码

3.完美拿到我们需要的数据,接下来就是再去抓其他的数据了,分析一下它们的URL

我们可以看到,它们的不同之处都在 ==max_id ==上,只要找出它们的关系,就可以拿到它的数据啦。如果它的关系不好找的话,那就换其他的方法爬取吧。但是,通过Ajax拿到数据才是最快最全的,所以必须想办法拿到它的 max_id , 下面有关于它的讲解
2.2.2 方法二: selenium库
1.控制浏览器
from selenium import webdriver
driver = webdriver.Chrome() #需要调用对应的chromedriver.exe
- 1
- 2
2.等待网页加载
driver.implicitly_wait(5) #最长等待5秒,记载完成后自动跳过
- 1
3.打开网页
driver.get(url) # 需要打开的网页
- 1
4.点击网页节点
driver.find_element_by_xpath('这里放网页xpath路径').click()
- 1
5.输入内容
driver.find_element_by_xpath('这里放网页输入框的xpath路径').send_keys('输入词')
- 1
在HTML源码上鼠标右击——> copy ——> Copy Xpath
6.获取文本
driver.find_element_by_xpath('网页中文本xpath路径').text #直接获取某个具体文本
- 1
7.网页下拉
js="var q=document.documentElement.scrollTop=10000000" #滚动条,数值为每次下拉的长度,不叠加,以浏览器底部为最大值
driver.execute_script(js)#调用js
- 1
- 2
8.获取HTML源码
driver.page_source
- 1
爬取实战思路:
1.控制浏览器打开网页
2.获取评论数量:
如果评论量大于20,就需要进行下拉加载,小于20不需要下拉,下拉次数 = 评论数 ÷ 20
但是这里需要下拉时需要登录才能继续加载
3.获取源码
4.使用解析库提取信息
3、微博首页具体动态链接获取
3.1、寻找Ajax加载的数据
对于这样的网页,如何获取它文章的链接也是一个难题,它的这些数据都是通过Ajax动态加载的。
从微博的官网,点击到“科技”,发现它的URL并没有变化,如果通过 selenium 点击转到“科技”获取网页HTML,找遍怎么网页都没有链接,这是就不是 selenium 获取HTML能搞定的了,还是只能通过抓包。
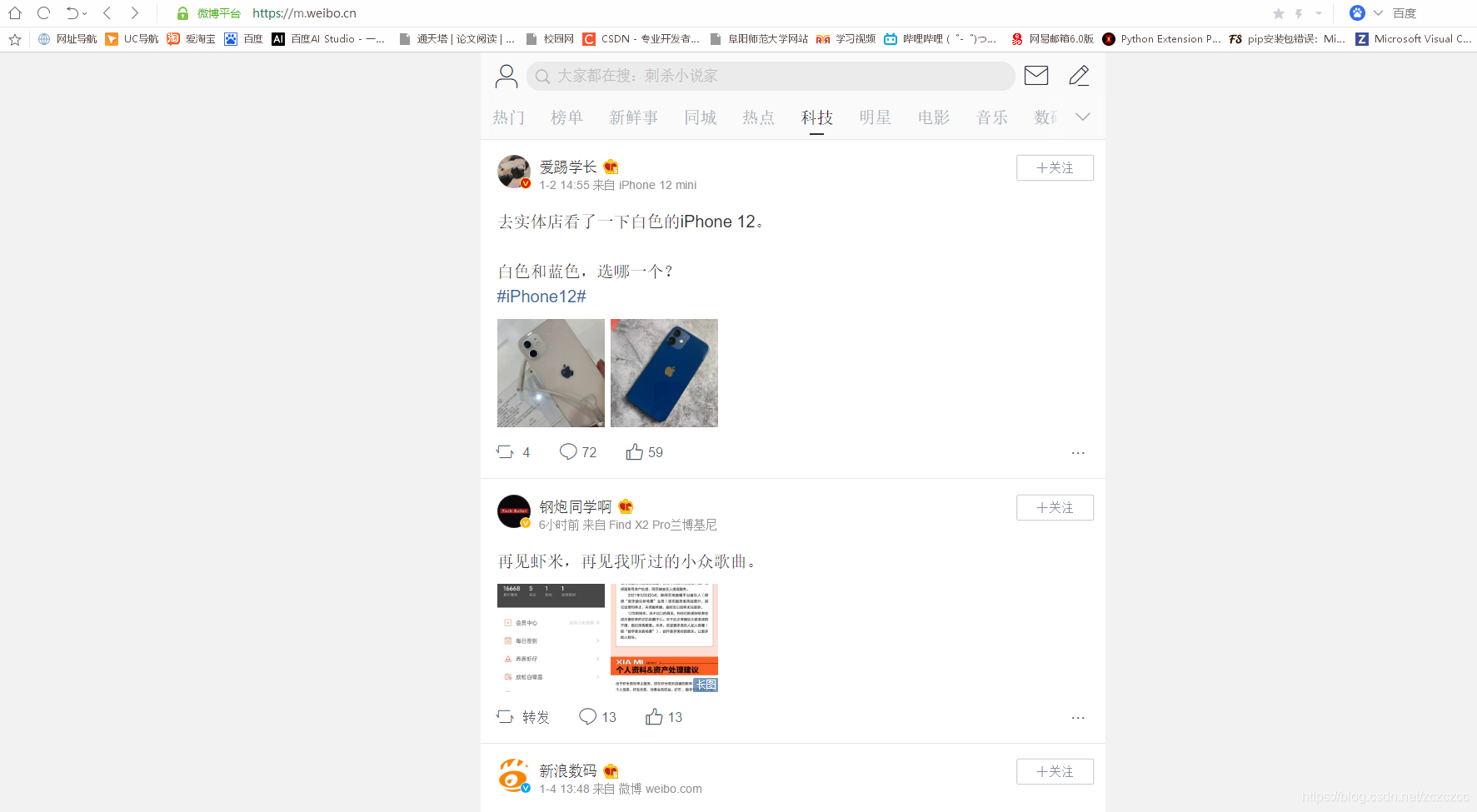
具体浏览几篇文章后发现,它的的部分 URL 都是统一的,
微博文章链接 ‘https://m.weibo.cn/detail/’+ 发布时的id
接下来就是获取它下一个加载数据的通道了,照样是通过抓包的方式获取,不断的下拉网页,加载出其他的Ajax数据传输通道,再进行对比
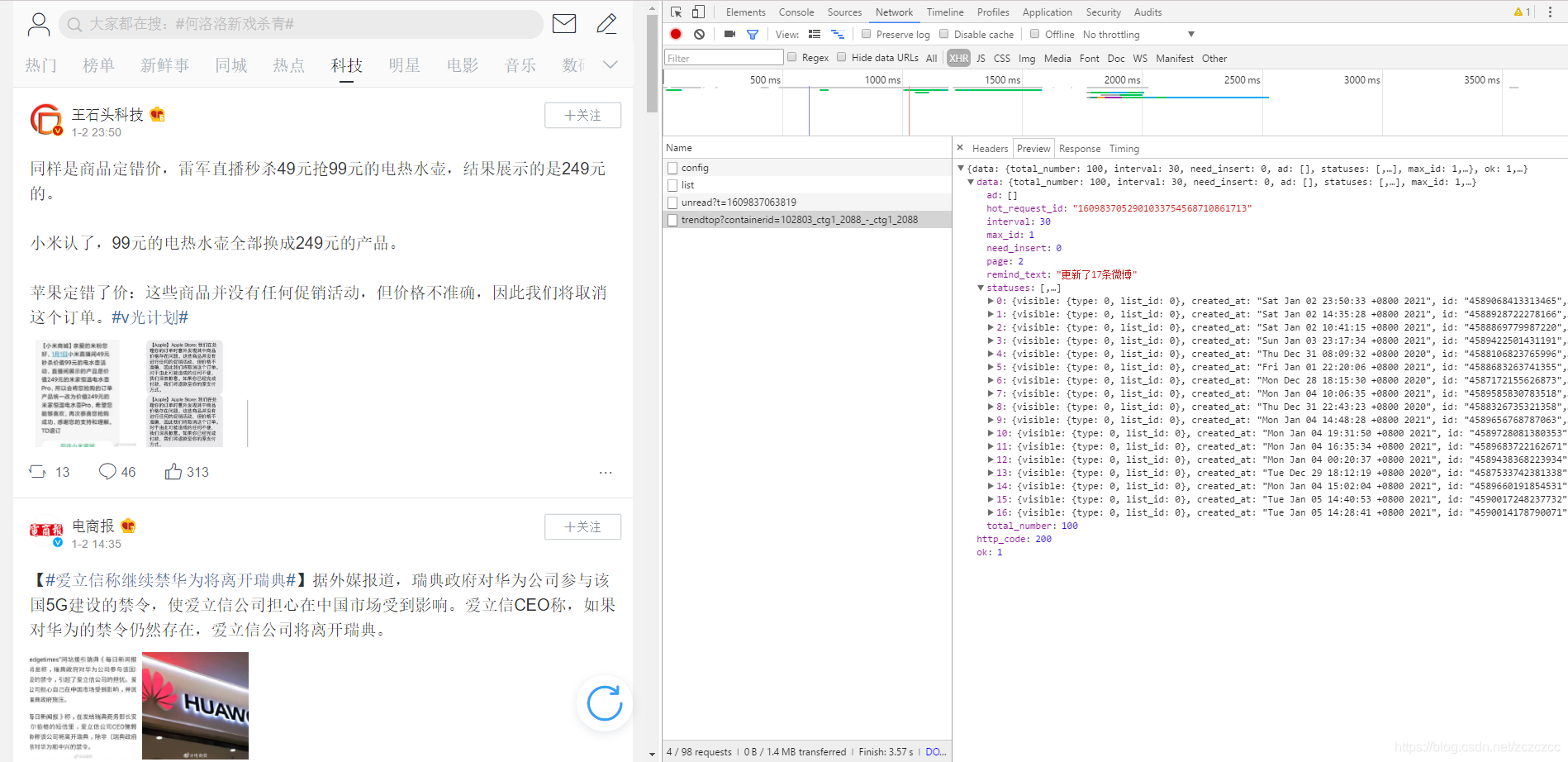
可以很明显的看出,它的当前链接就只是带上了&page=当前数字 的标签,并且每次加载出18篇动态文章

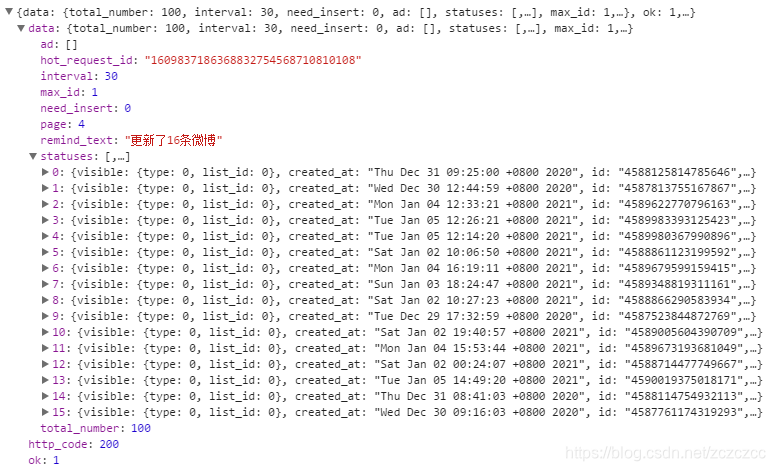
3.2、解析提取json数据
在线解析后的结果,简单的给它打上标签,每一个等级为一块,一级包括二级和三级,二级包括三级… 然后通过前面的标签进行迭代输出,索引出来
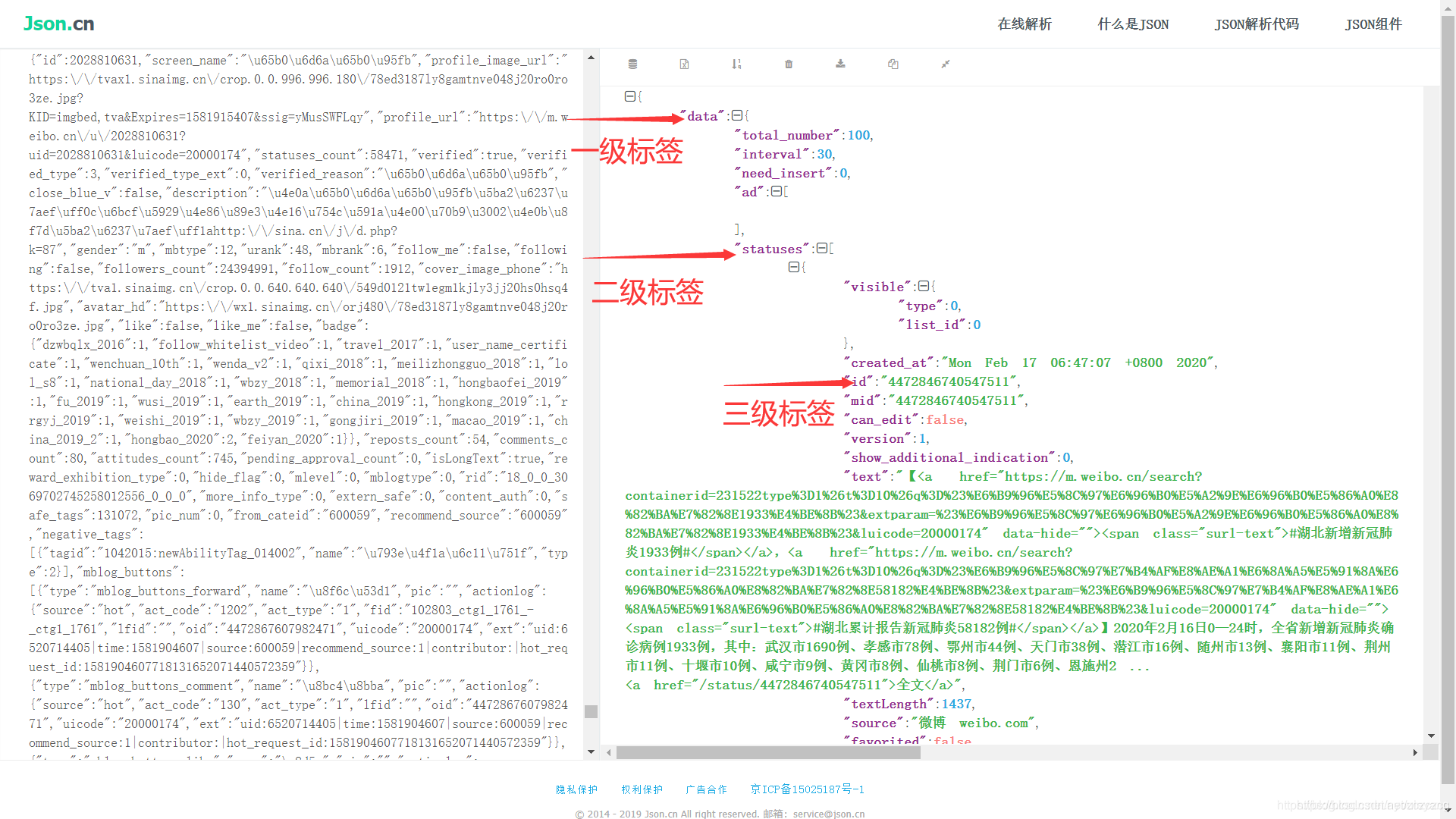
3.3、提取所有页面链接代码
方法实现:
import requests
api_url = ' https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_2088_-_ctg1_2088'
reponse = requests.get(api_url)
for json in reponse.json()['data']['statuses']:
comment_ID = json['id']
print (comment_ID)
- 1
- 2
- 3
- 4
- 5
- 6
import requests,time comment_urls = [] def get_title_id(): '''爬取首页的每个主题的ID''' for page in range(1,3):# 这是控制ajax通道的量 head = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 UBrowser/6.2.4098.3 Safari/537.36'} time.sleep(2) # 该链接通过抓包获得 api_url = 'https://m.weibo.cn/api/feed/trendtop?containerid=102803_ctg1_2088_-_ctg1_2088&page=' + str(page) print (api_url) rep = requests.get(url=api_url, headers=head) for json in rep.json()['data']['statuses']: comment_url = 'https://m.weibo.cn/detail/' + json['id'] print (comment_url) comment_urls.append(comment_url) get_title_id()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
然后把拿到的id加在https://m.weibo.cn/detail/ 的后面就可以访问具体的文章了
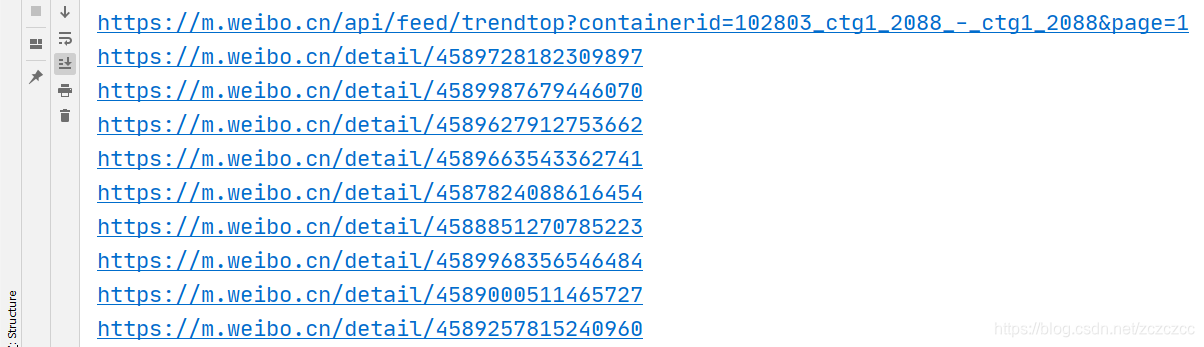
现在成功的拿到了每个文章的链接,接下来可以使用 selenium 控制浏览器 进行爬虫了
4、selenium爬取评论
爬取流程:
1.自定义浏览器
2.登录微博,让浏览器记录cookie值
3.通过ajax获取文章链接
4.分别访问每篇文章
5.通过评论数判断下拉次数,进行下拉加载数据
6.下拉完成后就获取源码
7.解析网页提取信息
8.保存数据
参考博客—https://blog.csdn.net/ayouleyang/article/details/104306270 link.





