
- 1分布式爬虫scrapy-redis所踩过的坑_scrapy_redis的坑
- 2Flask项目实战01_flask项目实例
- 3K8s学习(8)---Pod详解(Pod生命周期)_k8s pod invalid
- 4云计算时代操作系统K8s 之pod 生命周期综述_k8s pod的生命周期
- 5Java8 时间字符串校验是否为对应的日期格式_java判断日期字符串格式
- 6【Docker Desktop】Windows11家庭版安装docker desktop和WSl2(Ubuntu22.04)并完成迁移,配置国内镜像_docker win11配置和使用
- 7Android P 屏保和休眠相关知识
- 8啥是Python之禅
- 9网络游戏防沉迷实名认证系统常见错误_sys req partner auth error
- 1032单片机实现呼吸灯_32呼吸灯
深度学习算法优化系列十九 | 如何使用tensorRT C++ API搭建网络_c++训练搭建网络模型
赞
踩
1. 前言
在深度学习算法优化系列十八 | TensorRT Mnist数字识别使用示例 中主要是用TensorRT提供的NvCaffeParser来将Caffe中的model转换成TensorRT中特有的模型结构。其中NvCaffeParser是TensorRT封装好的一个用以解析Caffe模型的工具 (高层的API),同样的还有NvUffPaser用于解析TensorFlow的pb模型,NvONNXParse用于解析Onnx模型。除了这几个工具之外,TensorRT还提供了C++ API(底层的API)直接在TensorRT中创建模型。这时候TensorRT相当于是一个独立的深度学习框架,不过这个框架只负责前向推理(Inference)。
2. 使用C++ API函数部署流程
使用C++ API函数部署网络主要分成4个步骤,即:
- 创建网络。
- 给网络添加输入。
- 添加各种各样的层。
- 设定网络输出。
其中,第1,2,4步在上节讲TensorRT运行Caffe模型的时候已经讲过了,只有第三步是这里独有的,因为对于NvCaffeParser工具来说,它只是把第三步封装好了。这里的第三步在上一节的代码中对应的是constructNetwork函数,一起来看下:
//! //! 简介: 使用caffe解析器创建MNIST网络并标记输出层 //! //! 参数: 指向将用MNIST网络填充的网络指针 //! //! 参数: 指向引擎生成器的生成器指针 //! void SampleMNIST::constructNetwork(SampleUniquePtr<nvcaffeparser1::ICaffeParser>& parser, SampleUniquePtr<nvinfer1::INetworkDefinition>& network) { const nvcaffeparser1::IBlobNameToTensor* blobNameToTensor = parser->parse( mParams.prototxtFileName.c_str(), mParams.weightsFileName.c_str(), *network, nvinfer1::DataType::kFLOAT); //输出Tensor标记 for (auto& s : mParams.outputTensorNames) { network->markOutput(*blobNameToTensor->find(s.c_str())); } // 在网络开头添加减均值操作 nvinfer1::Dims inputDims = network->getInput(0)->getDimensions(); // 读取均值文件的数据 mMeanBlob = SampleUniquePtr<nvcaffeparser1::IBinaryProtoBlob>(parser->parseBinaryProto(mParams.meanFileName.c_str())); nvinfer1::Weights meanWeights{nvinfer1::DataType::kFLOAT, mMeanBlob->getData(), inputDims.d[1] * inputDims.d[2]}; // 数据的原始分布是[0,256] // 减去均值之后是[-127,127] // The preferred method is use scales computed based on a representative data set // and apply each one individually based on the tensor. The range here is large enough for the // network, but is chosen for example purposes only. float maxMean = samplesCommon::getMaxValue(static_cast<const float*>(meanWeights.values), samplesCommon::volume(inputDims)); auto mean = network->addConstant(nvinfer1::Dims3(1, inputDims.d[1], inputDims.d[2]), meanWeights); mean->getOutput(0)->setDynamicRange(-maxMean, maxMean); network->getInput(0)->setDynamicRange(-maxMean, maxMean); // 执行减均值操作 auto meanSub = network->addElementWise(*network->getInput(0), *mean->getOutput(0), ElementWiseOperation::kSUB); meanSub->getOutput(0)->setDynamicRange(-maxMean, maxMean); network->getLayer(0)->setInput(0, *meanSub->getOutput(0)); // 执行缩放操作 samplesCommon::setAllTensorScales(network.get(), 127.0f, 127.0f); // 最后的网络的输入就是[-1, 1] }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
可以看到解析Caffe模型用的NvCaffeParser工具中的parse函数,这个函数接受网络模型文件(deploy.prototxt),权重文件(net.caffemodel)路径参数,然后解析这两个文件对应生成TensorRT模型结构。对于NvCaffeParser工具来说,需要三个文件,即:*.prototxt,*.caffemodel,标签文件(这个主要是将模型产生的数字标号分类,与真实的名称对应起来)。
下面我们来说一下 使用C++ API函数的部署流程。
2.1 创建网络
//! //! 简介: 创建网络、配置生成器并创建网络引擎 //! //! 细节: 此函数通过解析caffe模型创建MNIST网络,并构建用于运行MNIST(mEngine)的引擎 //! //! 返回值: 如果引擎被创建成功,直接返回True //! bool SampleMNISTAPI::build() { //加载权重,*.wts文件 mWeightMap = loadWeights(locateFile(mParams.weightsFile, mParams.dataDirs)); // 1. Create builder //创建一个 IBuilder,传进gLogger参数是为了方便打印信息。 //builder 这个地方感觉像是使用了建造者模式。 auto builder = SampleUniquePtr<nvinfer1::IBuilder>(nvinfer1::createInferBuilder(gLogger.getTRTLogger())); if (!builder) { return false; } //创建一个 network对象,但是这个network对象只是一个空架子,里面的属性还没有具体的数值。 auto network = SampleUniquePtr<nvinfer1::INetworkDefinition>(builder->createNetwork()); if (!network) { return false; } //创建一个配置文件解析对象 auto config = SampleUniquePtr<nvinfer1::IBuilderConfig>(builder->createBuilderConfig()); if (!config) { return false; } //利用C++ API创建网络 auto constructed = constructNetwork(builder, network, config); if (!constructed) { return false; } assert(network->getNbInputs() == 1); auto inputDims = network->getInput(0)->getDimensions(); assert(inputDims.nbDims == 3); assert(network->getNbOutputs() == 1); auto outputDims = network->getOutput(0)->getDimensions(); assert(outputDims.nbDims == 3); return true; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
2.2 为网络添加输入
在创建网络的时候,也即是调用上面代码段中的constructNetwork函数时,首先需要明确网络的输入blob,代码如下:
// 为网络添加输入
ITensor* data = network->addInput(
mParams.inputTensorNames[0].c_str(), DataType::kFLOAT, Dims3{1, mParams.inputH, mParams.inputW});
- 1
- 2
- 3
其中,mParams.inputTensorNames[0].c_str()是输入blob的名字,DataType::kFLOAT指的是数据类型,与其相关的还有在NvInferRuntimeCommon.h中定义的几种数据类型:
enum class DataType : int
{
kFLOAT = 0, //!< FP32 format.
kHALF = 1, //!< FP16 format.
kINT8 = 2, //!< quantized INT8 format.
kINT32 = 3 //!< INT32 format.
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
后面的Dims3{1, mParams.inputH, mParams.inputW}指的是,batch_size为1(已经省略),channel为1,输入height和width分别为 INPUT_H, INPUT_W的blob。
2.3 添加各种层
- 添加一个Scale Layer。
添加一个Scale Layer的代码如下,
// Create scale layer with default power/shift and specified scale parameter.
const float scaleParam = 0.0125f;
const Weights power{DataType::kFLOAT, nullptr, 0};
const Weights shift{DataType::kFLOAT, nullptr, 0};
const Weights scale{DataType::kFLOAT, &scaleParam, 1};
IScaleLayer* scale_1 = network->addScale(*data, ScaleMode::kUNIFORM, shift, scale, power);
assert(scale_1);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
可以看到主要调用了一个addScale()函数,后面接受的参数是这一层需要设置的参数,Scale层的作用是为每个输入数据执行幂运算,公式为:
f ( x ) = ( s h i f t + s c a l e ∗ x ) p o w e r f(x)=(shift+scale*x)^{power} f(x)=(shift+scale∗x)power。
层的类型为Power。
可选参数为:
power: 默认为1。
scale: 默认为1。
shift: 默认为0。
- 1
- 2
- 3
其中Weights类的定义如下(在NvInferRuntime.h中):
class Weights
{
public:
DataType type; //!< The type of the weights.
const void* values; //!< The weight values, in a contiguous array.
int64_t count; //!< The number of weights in the array.
};
- 1
- 2
- 3
- 4
- 5
- 6
- 7
Scale层是没有训练参数的,ReLU层,Pooling层都没有训练参数。而有训练参数的如卷积层,全连接层,在构造的时候则需要先加载权重文件。
- 添加一个20个通道的 5 × 5 5\times 5 5×5卷积层的。
// Add convolution layer with 20 outputs and a 5x5 filter.
// 添加卷积层
IConvolutionLayer* conv1 = network->addConvolution(*scale_1->getOutput(0), 20, DimsHW{5, 5}, mWeightMap["conv1filter"], mWeightMap["conv1bias"]);
assert(conv1);
//设置步长
conv1->setStride(DimsHW{1, 1});
- 1
- 2
- 3
- 4
- 5
- 6
注意这里的mWeightMap在bool SampleMNISTAPI::build()函数里面已经加载了,权重只用加载一次。在第一行添加卷积层的函数里面,*scale_1->getOutput(0) 用来获取上一层Scale层的输出,20表示卷积核的个数,DimsHW{5, 5}表示卷积核的大小,weightMap["conv1filter"]和weightMap["conv1bias"]表示权值系数矩阵。
2.4 解析mnistapi.wts文件
上面提到在添加各种层之前,已经在build()函数里面加载了ministapi.wts权重文件,这个权重文件在F:\TensorRT-6.0.1.5\data\mnist这个路径下,是用来存放网络中各个层间的权值系数的。这里可以用Notepad++打开查看一下,截图如下:
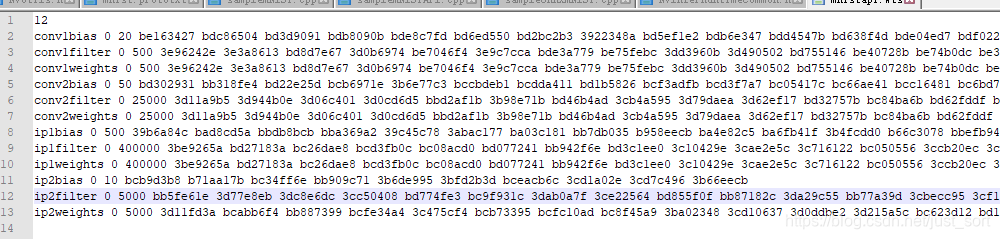
容易发现每一行都是一层的一些参数,比如conv1bias就是第一个卷积层的偏置系数,后面的0指的是 kFLOAT 类型,也就是float 32;后面的20是系数的个数,因为输出是20,所以偏置是20个;下面一行是卷积核的系数,因为是20个5 x 5的卷积核,所以有20 x 5 x 5=500个参数。其它层依次类推。这个wts文件是怎么来的呢?个人认为无论什么模型,你用相应工具解析解析模型将层名和权值参数键值对存到这个文件中就可以了,由于我暂时不会使用到它,这里就不深挖了。
2.5 设定网络输出
我们必须设定网络的输出blob,mnist例子中即在网络的最后添加一个softmax,这部分的代码如下:
// Add softmax layer to determine the probability.
ISoftMaxLayer* prob = network->addSoftMax(*ip2->getOutput(0));
assert(prob);
prob->getOutput(0)->setName(mParams.outputTensorNames[0].c_str());
network->markOutput(*prob->getOutput(0)
- 1
- 2
- 3
- 4
- 5
2.6 为什么要使用底层C++/Python API?
对于RNN和不对称Padding来说,NvCaffeParser是不支持的,只有 C++ API 和 Python API,才是支持的。除此之外,如果你想使用Darknet训练出来的检测模型(*.weights),不想模型转换,那么你可以直接使用底层的 C++ API,和Python API,因为它需要的就只是一个层名和权值参数对应的map文件,这使得TensorRT的使用更加灵活。
3. 官方例程
官方例程位于F:\TensorRT-6.0.1.5\samples\sampleMNISTAPI\sampleMNISTAPI.cpp,和上节讲的例子的区别已经在上面的第二节讲清楚了,可以对应着深度学习算法优化系列十八 | TensorRT Mnist数字识别使用示例 代码解析去理解一下。
4. 后记
这篇推文主要讲解了在TensorRT中除了使用Caffe/TensorFlow/ONNX之外,还可以使用底层C++/PYTHON API自己定义网络结构来部署,看完这个相信对TRT的demo就了解得比较全面了,后面的推文我将从优化方面(低精度推理)来继续讲解TensorRT。
5. 参考
- https://arleyzhang.github.io/articles/fda11be6/
- https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/c_api/index.html
- https://docs.nvidia.com/deeplearning/sdk/tensorrt-api/python_api/index.html
- https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html
6. 同期文章
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:


