
- 1探秘亚马逊云科技海外服务器 | 解析跨境云计算的前沿技术与应用
- 2Leetcode Solutions - Part 2_let x1, x2 are solutions to (at a + 碌ii)x = 鈭扐t r,
- 3dubbo源码分析第十六篇一dubbo集群容错策略-BroadcastCluster广播_dubbo broadcast cluster
- 4简单易懂深入PyTorch中RNN、LSTM和GRU使用和理解
- 5《成为一名优秀的架构师:从基础到实践》_现代c++软件架构:方法与实践 pdf
- 6(附源码)基于Java SpringBoot的电影院管理系统设计与实现 毕业设计 011633_电影管理系统java源码
- 7黑马程序员——Objective-C——定义类、方法、创建对象
- 8HTML小游戏13 —— 仿《神庙逃亡》3D风格跑酷游戏《墓地逃亡》(附完整源码)_html神庙逃亡制作代码
- 9chatgpt赋能python:Python量化交易:为什么Python是最好的选择_pyalgotrade optimizer cuda
- 10二战华为成功上岸,准备了小半年,要个27k应该也算不上很高吧~
cnn卷积神经网络(计算过程详析)_cnn layer 计数
赞
踩
参考网址
https://www.cnblogs.com/skyfsm/p/6790245.html
一般的神经网络结构如下
CNN卷积神经网络可以被分为许多层,其层级结构一般为
• 数据输入层/ Input layer
• 卷积计算层/ CONV layer
• ReLU激励层 / ReLU layer
• 池化层 / Pooling layer
• 全连接层 / FC layer
1.数据输入层
该层要做的处理主要是对原始图像数据进行预处理,其中包括:
• 去均值:把输入数据各个维度都中心化为0,如下图所示,其目的就是把样本的中心拉回到坐标系原点上。
• 归一化:幅度归一化到同样的范围,如下所示,即减少各维度数据取值范围的差异而带来的干扰,比如,我们有两个维度的特征A和B,A范围是0到10,而B范围是0到10000,如果直接使用这两个特征是有问题的,好的做法就是归一化,即A和B的数据都变为0到1的范围。
• PCA/白化:用PCA降维;白化是对数据各个特征轴上的幅度归一化,去均值与归一化效果图:
2.卷积计算层
这一层就是卷积神经网络最重要的一个层次,也是“卷积神经网络”的名字来源。
在这个卷积层,有两个关键操作:
• 局部关联。每个神经元看做一个滤波器(filter)
• 窗口(receptive field)滑动,窗口在有些地方也称为感受野, filter对局部数据计算
先介绍卷积层遇到的几个名词:
• 卷积核(或称为卷积过滤器),其通道数与它进行卷积的输入的通道数必须是相同的.
例如: 若输入图像为32*32*3,则卷积核的通道数也必须是3,如可以为5*5*3
• 深度/depth: 就是有几个卷积核(或称为有多少个神经元),深度depth就是多少,下图中就是有5个卷积核,即卷积核的深度是5
• 步长/stride (窗口一次滑动的长度)
• 填充值/zero-padding
我们在处理一个卷积层时,希望用到多种卷积核,因为每一个卷积核都可以从输入中得到一种特殊的模式或概念(比如一个3*3的卷积核可以起到sobel算子的作用,提取到图像的边缘).所以我们会有一组卷积核,即卷积核与卷积核中的参数是不同的. 在上图中,32*32*3的图像经过5(kernel_size)*5(kernel_size)*3(input_channel)*5(kernel_chanel)的卷积核运算后(strid=1),得到的特征图的尺寸为32*32*5,即原始的3通道的图像,经过卷积运算后,得到了5通道的特征图,形象理解就是卷积核的第一通道可以提取图像边缘特征,第二通道用来提取色彩特征,第三通道用来提取纹理特征....
填充值是什么呢?
以下图为例子,比如有这么一个5*5的图片(一个格子一个像素),我们滑动窗口(卷积核)取2*2,步长取2,那么我们发现还剩下1个像素没法滑完,那怎么办呢?
那我们在原先的矩阵边上加了一层填充值,使其变成6*6的矩阵,那么窗口就可以刚好把所有像素遍历完。这就是填充值的作用。
卷积的计算
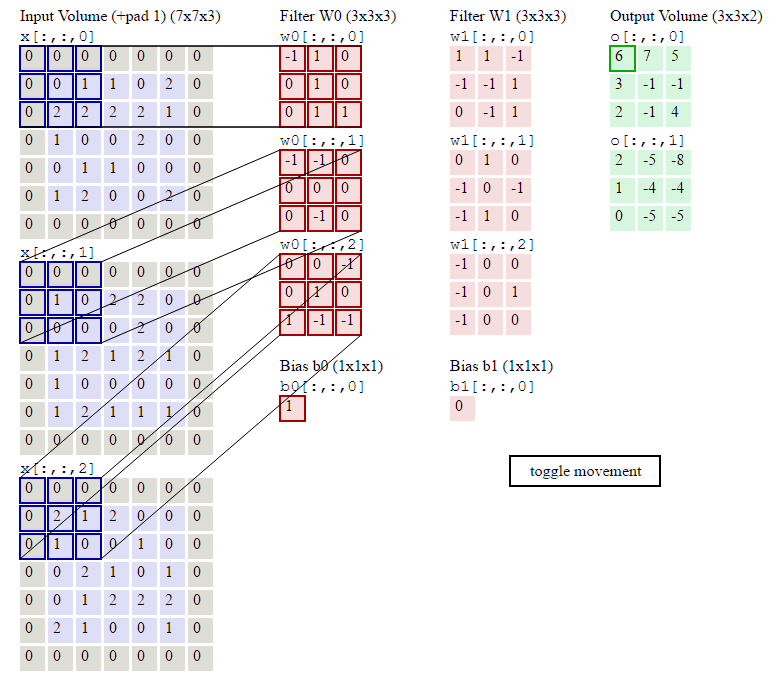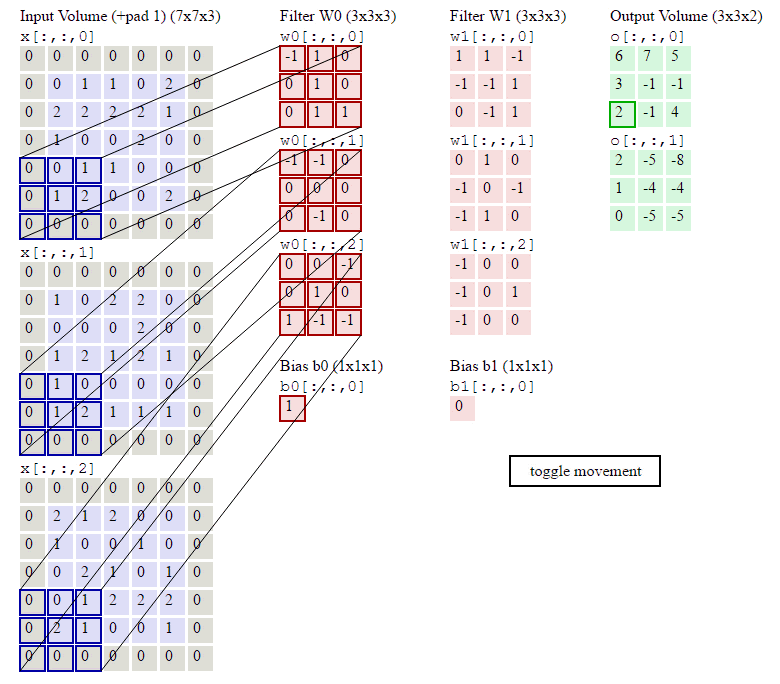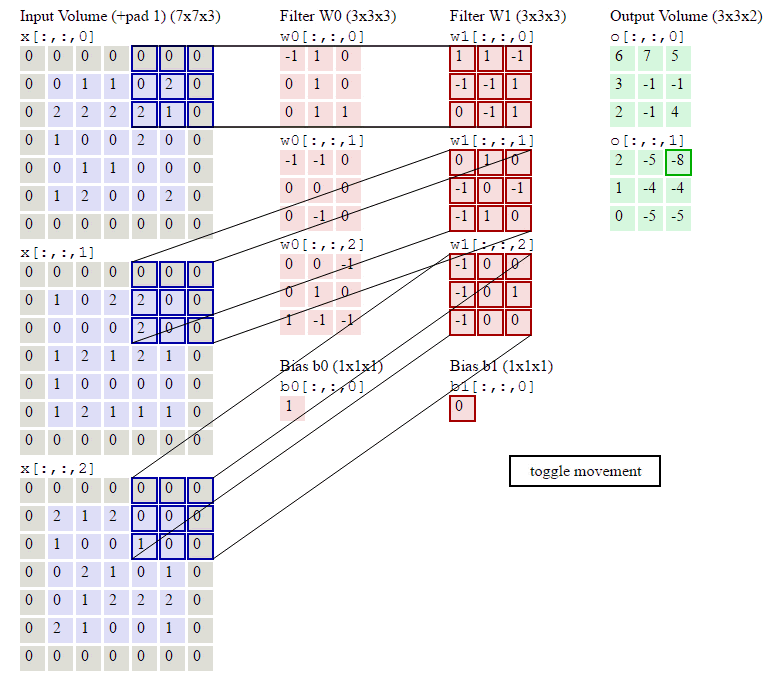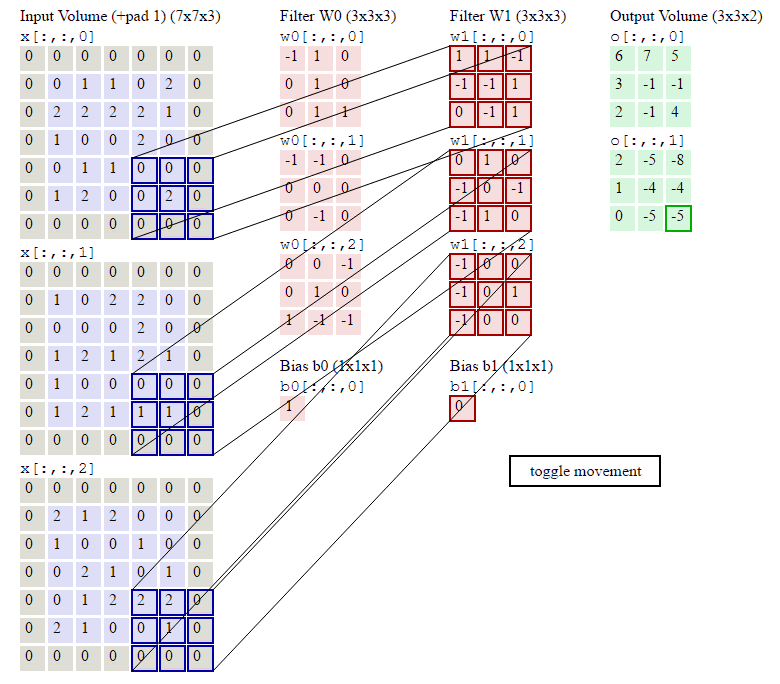
这里的第一列蓝紫色矩阵代表输入的图像,第二列粉色矩阵就是卷积层的神经元,这里表示有两个神经元(w0,w1),第三列绿色矩阵就是经过卷积运算后的输出矩阵,这里的步长设置为2。
蓝色的矩阵(输入图像)与粉色的矩阵(filter)进行矩阵内积计算(就是矩阵对应元素先相乘再相加),具体过程为
并将三个内积运算的结果与偏置值b相加,计算后的值就是绿框矩阵的一个元素。计算过程如下:
第一步:输入图像通道1中元素与filter w0的通道1做内积运算
step1.2 输入图像通道2中元素与filter w0的通道2做内积运算
step1.3 输入图像通道3中元素与filter w0的通道3做内积运算
step1.4 将filter w0与输入各通道的值叠加, 然后加上偏置得到卷积结果
4+0+1+1=6
tensorflow程序实现
- import tensorflow as tf
- import numpy as np
- #输入图片,[batch_size,height,width,channels]
- input = np.array([[[[0., 1.,1,0,2],
- [ 2. , 2.,2,2,1],
- [ 1,0,0,2,0],
- [0,1,1,0,0],
- [1,2,0,0,2]],
-
- [[ 1,0,2,2,0],
- [0,0,0,2,0.],
- [ 1,2,1,2,1],
- [1,0,0,0,0.],
- [1,2,1,1,1.],],
-
- [[2,1,2,0,0.],
- [1,0,0,1,0.],
- [0,2,1,0,1.],
- [0,1,2,2,2.],
- [2,1,0,0,1.]]]])
- print(input)
- input= tf.constant(input, shape=[1, 5, 5, 3],dtype=tf.float32)#输入图片,3x3,两通道#
- filter = np.array([[[[-1.,1,0],
- [0,1,0.],
- [0,1,1]],
-
- [[-1.,-1,0],
- [0,0,0.],
- [0,-1,0]],
-
- [[0.,0,-1],
- [0,1,0.],
- [1,-1,-1.]]],
-
- [[[1., 1, -1],
- [-1, -1, 1.],
- [0, -1, 1]],
-
- [[0., 1, 0],
- [-1, 0, -1.],
- [-1, 1, 0]],
-
- [[-1., 0, 0],
- [-1, 0, 1.],
- [-1, 0, 0.]]
- ]])#2通道卷即核
- print('filter',filter)
- #filter 卷积核,[height,width,in_channels,out_channels]
- filter= tf.constant(filter, shape=[3,2, 3, 3],dtype=tf.float32)#1*3*3*2的卷积核
- # filter= tf.constant(filter, dtype=tf.float32)#1*3*3*2的卷积核
-
- #strides,卷积时在图像每一维的步长,这是一个一维的向量,[1,strides,strides,1]第一位和最后一位固定必须是1
- #padding:string类型,值为SAME,valid,表示的是卷积的形式,是否考虑边界,SAME是考虑边界,不足的时候用0去填充周围,
- #valid则不考虑
- op2 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='SAME')# shape=(1, 3, 3, 2)
- # op3 = tf.nn.conv2d(input, filter, strides=[1, 2, 2, 1], padding='VALID')# shape=(1, 3, 3, 2)
- #对于filter,多个输入通道,变成一个输入通道,是对各个通道上的卷积值进行相加
- init = tf.global_variables_initializer()
- with tf.Session() as sess:
- sess.run(init)
- print("conv ", sess.run(op2))
- print('op2',op2)
- # print("convOP3 ", sess.run(op3))
- # print('op3', op3)

备注:在上述的实现中,还有两点问题为解决
1.输出感觉不是`[batch,channel,height,width]维度的
2.不知道如何把偏置加上去
pytorch代码实现
- import torch
- from torch.nn import functional as F
- import numpy as np
- """定义输入样本"""
- #1张3通道的5*5的图像
- #输入图片,[batch_size,channels,height,width]
- input = np.array([[[[0., 1.,1,0,2],
- [ 2. , 2.,2,2,1],
- [ 1,0,0,2,0],
- [0,1,1,0,0],
- [1,2,0,0,2]],
-
- [[ 1,0,2,2,0],
- [0,0,0,2,0.],
- [ 1,2,1,2,1],
- [1,0,0,0,0.],
- [1,2,1,1,1.],],
-
- [[2,1,2,0,0.],
- [1,0,0,1,0.],
- [0,2,1,0,1.],
- [0,1,2,2,2.],
- [2,1,0,0,1.]]]])
- input= torch.from_numpy(input)
- print(input.shape)#torch.Size([1, 3, 5, 5])
- """手动定义卷积核(weight),[2, 3, 3, 3] [out_channels,in_channels,height,width]"""
- filter = np.array([[[[-1.,1,0],
- [0,1,0.],
- [0,1,1]],
-
- [[-1.,-1,0],
- [0,0,0.],
- [0,-1,0]],
-
- [[0.,0,-1],
- [0,1,0.],
- [1,-1,-1.]]],
-
- [[[1., 1, -1],
- [-1, -1, 1.],
- [0, -1, 1]],
-
- [[0., 1, 0],
- [-1, 0, -1.],
- [-1, 1, 0]],
-
- [[-1., 0, 0],
- [-1, 0, 1.],
- [-1, 0, 0.]]
- ]])#2通道卷即核
- filter= torch.from_numpy(filter)
- print('filter.shape',filter.shape)#torch.Size([2, 3, 3, 3])
- """偏置bias,2个卷积核,2个偏置,每个卷积核的各个通道共用一个偏置"""
- b=np.array([1.,0.])
- b=torch.from_numpy(b)
- """2D卷积得到输出"""
- out = F.conv2d(input, filter, b, stride=2, padding=1) # 步长为2,外加2圈padding
- print('out.shape',out.shape)#torch.Size([1, 2, 3, 3])输出特征图的尺寸[batch_Size,channels,height,width]
- print(out)
- # tensor([[[[ 6., 7., 5.],
- # [ 3., -1., -1.],
- # [ 2., -1., 4.]],
- #
- # [[ 2., -5., -8.],
- # [ 1., -4., -4.],
- # [ 0., -5., -5.]]]], dtype=torch.float64)
卷积后的特征图的维度计算公式:
总结:从上述计算过程可以看出:
若输入图片的维度为(W1,H1,D1)(W1为行数,H1为列数,D1为图片通道数一般为3),filter个数为K(比如上图K=2),filter大小F(上图F=3,3x3的filter),步长S(上图s=2),边界填充P(上图p=1)
(1)各个滤波器,比如filter 0,其维度为W2*H2*D2(W2为行数,H2为列数,D2为维度),则需要满足D1=D2;
(2)若输入图像为5x5x3,filter0维度为3x3x3,在zero pad为1,则加上zero pad后的输入图像为7x7x3(原图像的四周各加上1列像素),则卷积后的特征图大小为5x5x1,与输入图像的宽高一样。
(3)关于特征图(w3,h3,d3)的大小计算方法具体如下:
w3=(w1+2P-F)/S+1
h3=(h1+2p-F)/s+1
D3=K
参数共享机制
• 在卷积层中每个神经元连接数据窗的权重是固定的,每个神经元只关注一个特性。神经元就是图像处理中的滤波器,比如边缘检测专用的Sobel滤波器,即卷积层的每个滤波器都会有自己所关注一个图像特征,比如垂直边缘,水平边缘,颜色,纹理等等,这些所有神经元加起来就好比就是整张图像的特征提取器集合。
比如输入图片为一只猫,那么不同的filter就会提取不同的特征,比如



3.激励层
把卷积层输出结果做非线性映射。
CNN采用的激励函数一般为ReLU(The Rectified Linear Unit/修正线性单元),它的特点是收敛快,求梯度简单,但较脆弱,图像如下。激励层的实践经验:
①不要用sigmoid!不要用sigmoid!不要用sigmoid!
② 首先试RELU,因为快,但要小心点
③ 如果2失效,请用Leaky ReLU或者Maxout
④ 某些情况下tanh倒是有不错的结果,但是很少
4.池化层
池化层夹在连续的卷积层中间, 用于压缩数据和参数的量,减小过拟合。
简而言之,如果输入是图像的话,那么池化层的最主要作用就是压缩图像。

