
- 1Unity打包WebGL的全过程及在打包和使用过程中会遇到的问题(本地测试)
- 2Unity异步编程【6】——Unity中的UniTask如何取消指定的任务或所有的任务
- 3Shader学习笔记:BRDF简单概述
- 4【Unity URP渲染管线下设置灯光数量上限_灯光不显示问题案例分享】_unity点光源数量
- 530分钟了解所有引擎组件,132个Unity 游戏引擎组件速通!【收藏 == 学会】
- 6Unity 制作登录功能02-创建和链接数据库(SQlite)_sqlite unity
- 7LitJson在Unity中的使用_unity litjson
- 8Unity模型正反面_unity 面片
- 9unity3d 物体高速运动下穿模的解决方案_unity加了碰撞体依然穿模
- 10【Unity3D】常用快捷键_unity快捷键
【Unity】万人同屏高级篇, 自定义BRG&dots合批渲染,海量物体目标搜索_unity 万人同屏
赞
踩
博文介绍了最基本的实现原理,有些老板懒得折腾,所以特意熬了几个秃头的夜把RVO、BRG、GPU动画、海量物体目标搜索等高度封装成了开箱即用的插件。 划重点!!此方案是绕开Entities(ECS),不用写一行ECS代码,现有MonoBehavior开发工作流享受Entities渲染的性能。已有项目也能使用此方案开挂,无需代码重构!。Wechat: SunSparkStudio
性能压力测试包自取:
PC 10万动画人同屏对抗:https://pan.baidu.com/s/1CgpTV0TuFagobtAf7k38OA?pwd=xwsf
安卓 1万动画人同屏避障: https://pan.baidu.com/s/1RkXyVXt_he5uCgizTSA42A?pwd=k0ji
插件使用视频教程:
Unity低成本性能开挂 gpu动画+dots graphics万人同屏渲染 jobs rvo2 弹幕游戏海量单位索敌
Unity万人同屏海量物体合批渲染
Unity万人同屏海量物体目标搜索
海量单位高性能索敌攻击方案压测
移动端测试AOT和HybridCLR热更性能对比
博文开发测试环境:
- Unity:Unity 2022.3.10f1,URP 14.0.8,Burst 1.8.8,Jobs 0.70.0-preview.7,热更HybridCLR 4.0.6
- PC:Win11,CPU i7-13700KF,GPU 3070 8G,RAM 32G;
- 移动端:Android,骁龙8 gen2,RAM 12G;
上篇博文通过最基本的自定义BRG(Batch Renderer Group) + RVO避障实现了10万人同屏动态避障:【Unity】十万人同屏寻路? 基于Dots技术的多线程RVO2避障_TopGames的博客-CSDN博客
上篇博文的BRG功能并不完善,不支持多种Mesh和Material渲染,没有拆分渲染批次(Batch),没有裁剪(Culling)处理(即不会剔除相机视口外的物体)。并且没有根据渲染数量拆分多个Draw Command。
BRG代码写起来并不容易,此博文基于Unity中国DOTS技术主管开源的一个BRG示例工程修改,这里仅描述主要的实现原理:
参考文章:Unity Open Day 北京站-技术专场:深入理解 Entities Gr - 技术专栏 - Unity官方开发者社区
BRG示例工程:
https://github.com/vinsli/batch-renderer![]() https://github.com/vinsli/batch-renderer
https://github.com/vinsli/batch-renderer
另外也可以看看Unity官方BRG测试案例,官方案例是把当前已经创建的MeshRenderer禁用然后用BRG接管渲染:
实现目标:
为了方便使用BRG功能,需要封装一个BatchRenderComponent脚本。不使用ECS,仅使用传统创建GameObject的方式与BRG无缝衔接,也就是对于海量物体不使用Unity Renderer组件,用封装后的BRG无感知接管物体的渲染,最大程度上不改变传统工作流的同时大幅提升性能;
其中GameObject是只有Transform组件的空物体,渲染由BatchRenderComponent接管,进行合批渲染。由于Transform只能在主线程使用,当数量级庞大时每帧修改Transform位置/旋转会导致掉帧,所以仅当这个GameObject挂载子节点(如,子节点包含特效,需要跟随人物移动)时才需要开启每帧同步Transform位置,这样可以大幅节省开销。
通过此方法可以完美绕开Entities(ECS),同时也绕开了Entities(ECS)对开发成本和效率影响,以及ECS当前不支持从文件名加载资源、不支持热更的痛点。
最终效果:
PC端5W人, AOT模式(不使用HybridCLR),开启阴影:

Android端5K人,AOT模式(不使用HybridCLR),开启阴影:
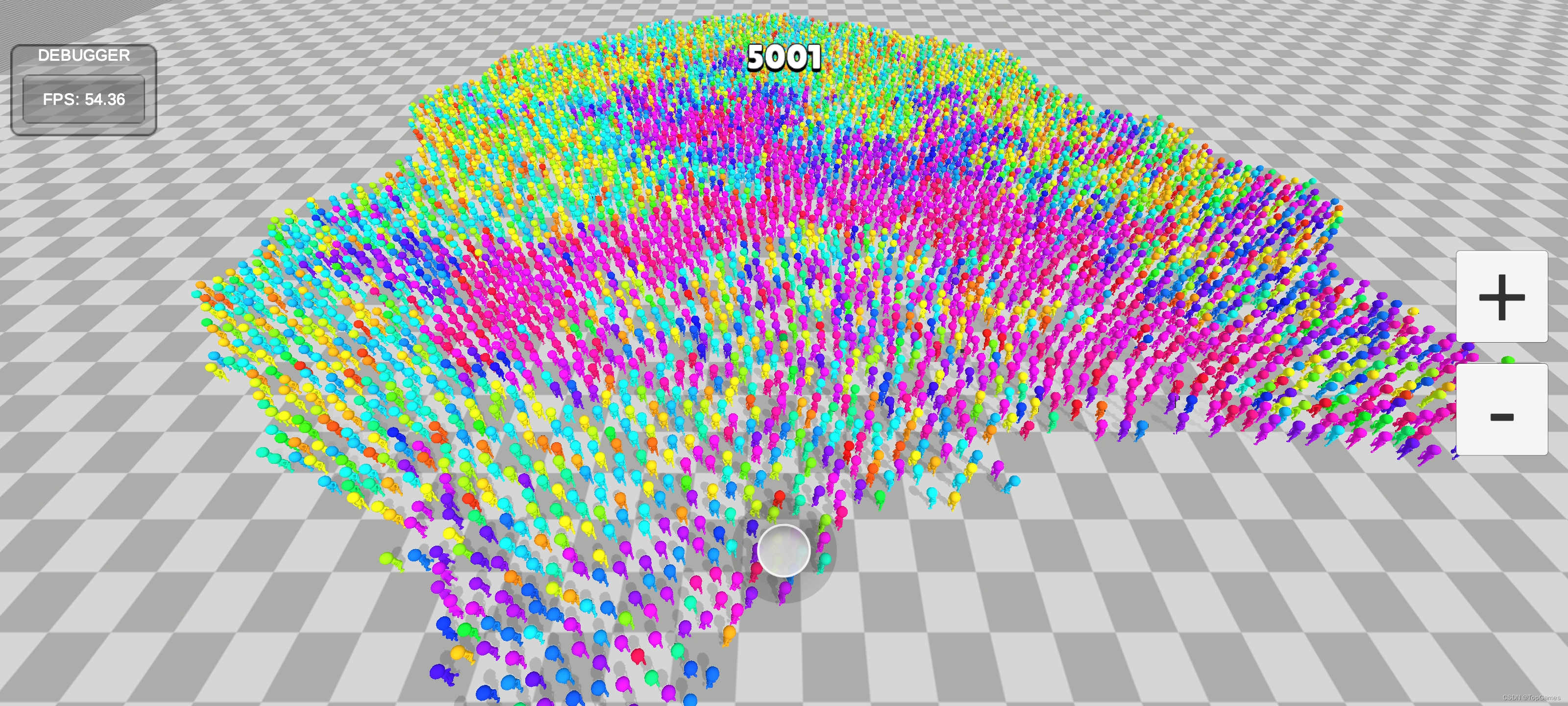
Android端5K人, HybridCLR热更模式,开启阴影:

测试中一帧创建1000个物体时会有明显卡顿,这是Unity实体化GameObject本身的性能问题,实际项目中海量物体的创建并不要求实时性,可以通过队列分散到多帧创建以解决卡顿。
一,支持多Mesh/多Material
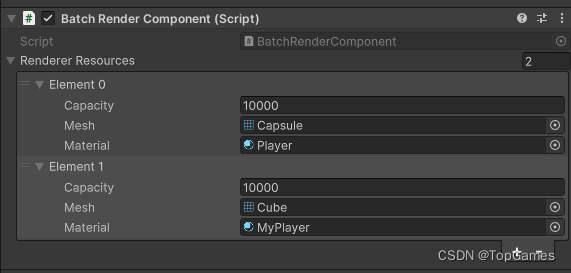
使用BRG必须开启SRP Batcher, SRP支持相同Material合批。因此支持多Material就需要根据不同Material拆分Batch,针对不同Material使用多个Batch渲染。
每个物体需要向GPU上传以下数据:
- 两个3x4矩阵,决定物体渲染的位置/旋转/缩放;
- _BaseColor,物体混合颜色;
- _ClipId, GPU动画id, 用于切换动画;
- int objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
- int worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
- int colorID = Shader.PropertyToID("_BaseColor");
- int gpuAnimClipId = Shader.PropertyToID("_ClipId");
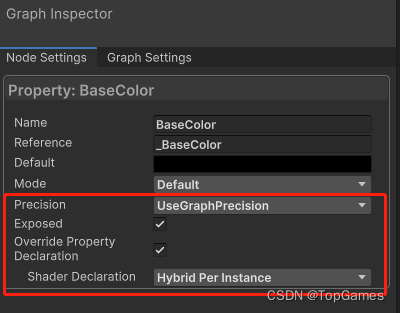
如果Shader还需要动态修改其它参数需要自行扩展,根据参数所占内存还需要重新组织内存分配;
注意,必须在Shader Graph中把参数类型设置为Hybrid Per Installed,否则无法正常将数据传递给shader:
将每个物体依赖的数据组织成一个struct便于管理RendererNode,由于要在Jobs中使用所以必须为struct类型:
- using Unity.Mathematics;
- using static Unity.Mathematics.math;
- using Unity.Burst;
-
- [BurstCompile]
- public struct RendererNode
- {
- public RendererNodeId Id { get; private set; }
- public bool Enable
- {
- get
- {
- return active && visible;
- }
- }
- /// <summary>
- /// 是否启用
- /// </summary>
- public bool active;
- /// <summary>
- /// 是否在视口内
- /// </summary>
- public bool visible;
- /// <summary>
- /// 位置
- /// </summary>
- public float3 position;
- /// <summary>
- /// 旋转
- /// </summary>
- public quaternion rotation;
- /// <summary>
- /// 缩放
- /// </summary>
- public float3 localScale;
- /// <summary>
- /// 顶点颜色
- /// </summary>
- public float4 color;
-
- /// <summary>
- /// 动画id
- /// </summary>
- public float4 animClipId;
- /// <summary>
- /// Mesh的原始AABB(无缩放)
- /// </summary>
- public AABB unscaleAABB;
-
- /// <summary>
- /// 受缩放影响的AABB
- /// </summary>
- public AABB aabb
- {
- get
- {
- //var result = unscaleAABB;
- //result.Extents *= localScale;
- return unscaleAABB;
- }
- }
- public bool IsEmpty
- {
- get
- {
- return unscaleAABB.Size.Equals(Unity.Mathematics.float3.zero);
- }
- }
- public static readonly RendererNode Empty = new RendererNode();
- public RendererNode(RendererNodeId id, float3 position, quaternion rotation, float3 localScale, AABB meshAABB)
- {
- this.Id = id;
- this.position = position;
- this.rotation = rotation;
- this.localScale = localScale;
- this.unscaleAABB = meshAABB;
- this.color = float4(1);
- this.active = false;
- this.visible = true;
- this.animClipId = 0;
- }
- /// <summary>
- /// 构建矩阵
- /// </summary>
- /// <returns></returns>
- [BurstCompile]
- public float4x4 BuildMatrix()
- {
- return Unity.Mathematics.float4x4.TRS(position, rotation, localScale);
- }
- }
初始化渲染数据Buffer列表:
为了维护数据简单,并避免物体数量变化后频繁重新创建列表,所以根据RendererResource的Capacity大小,维护一个固定长度的列表。并且根据不同的RendererResource拆分多个渲染批次:
- private void CreateRendererDataCaches()
- {
- m_BatchesVisibleCount.Clear();
- int index = 0;
- foreach (var rendererRes in m_RendererResources)
- {
- var drawKey = rendererRes.Key;
- m_BatchesVisibleCount.Add(drawKey, 0);
- NativeList<int> perBatchNodes;
- if (!m_DrawBatchesNodeIndexes.ContainsKey(drawKey))
- {
- perBatchNodes = new NativeList<int>(2048, Allocator.Persistent);
- m_DrawBatchesNodeIndexes.Add(drawKey, perBatchNodes);
-
- NativeQueue<BatchDrawCommand> batchDrawCommands = new NativeQueue<BatchDrawCommand>(Allocator.Persistent);
- m_BatchDrawCommandsPerDrawKey.Add(drawKey, batchDrawCommands);
- }
- else
- {
- perBatchNodes = m_DrawBatchesNodeIndexes[drawKey];
- }
- for (int i = 0; i < rendererRes.capacity; i++)
- {
-
- var color = SpawnUtilities.ComputeColor(i, rendererRes.capacity);
- var aabb = rendererRes.mesh.bounds.ToAABB();
- var node = new RendererNode(new RendererNodeId(drawKey, index), Unity.Mathematics.float3.zero, Unity.Mathematics.quaternion.identity, float3(1), aabb);
- node.color = color;
- perBatchNodes.Add(index);
- m_AllRendererNodes[index++] = node;
- }
- }
- }
组织拆分后每个Batch的数据:
由于不同硬件性能不同,单个Draw Command数量是有上限的,所以还需要根据渲染数量拆分至多个BatchDrawCommand。这里主要是对内存的直接操作,需要正确计算内存偏移,否则会导致程序崩溃。
- private void GenerateBatches()
- {
- #if UNITY_ANDROID || UNITY_IOS
- int kBRGBufferMaxWindowSize = 16 * 256 * 256;
- #else
- int kBRGBufferMaxWindowSize = 16 * 1024 * 1024;
- #endif
- const int kItemSize = (2 * 3 + 2); //每个物体2个3*4矩阵,1个颜色值,1个动画id,内存大小共8个float4
- m_MaxItemPerBatch = ((kBRGBufferMaxWindowSize / kSizeOfFloat4) - 4) / kItemSize; // -4 "float4" for 64 first 0 bytes ( BRG contrainst )
- // if (_maxItemPerBatch > instanceCount)
- // _maxItemPerBatch = instanceCount;
-
- foreach (var drawKey in m_DrawBatchesNodeIndexes.GetKeyArray(Allocator.Temp))
- {
- if (!m_BatchesPerDrawKey.ContainsKey(drawKey))
- {
- m_BatchesPerDrawKey.Add(drawKey, new NativeList<int>(128, Allocator.Persistent));
- }
-
- var instanceCountPerDrawKey = m_DrawBatchesNodeIndexes[drawKey].Length;
- m_WorldToObjectPerDrawKey.Add(drawKey, new NativeArray<float4>(instanceCountPerDrawKey * 3, Allocator.Persistent));
- m_ObjectToWorldPerDrawKey.Add(drawKey, new NativeArray<float4>(instanceCountPerDrawKey * 3, Allocator.Persistent));
-
- var maxItemPerDrawKeyBatch = m_MaxItemPerBatch > instanceCountPerDrawKey ? instanceCountPerDrawKey : m_MaxItemPerBatch;
- //gather batch count per drawkey
- int batchAlignedSizeInFloat4 = BufferSizeForInstances(kBytesPerInstance, maxItemPerDrawKeyBatch, kSizeOfFloat4, 4 * kSizeOfFloat4) / kSizeOfFloat4;
- var batchCountPerDrawKey = (instanceCountPerDrawKey + maxItemPerDrawKeyBatch - 1) / maxItemPerDrawKeyBatch;
-
- //create instance data buffer
- var instanceDataCountInFloat4 = batchCountPerDrawKey * batchAlignedSizeInFloat4;
- var instanceData = new GraphicsBuffer(GraphicsBuffer.Target.Raw, GraphicsBuffer.UsageFlags.LockBufferForWrite, instanceDataCountInFloat4, kSizeOfFloat4);
- m_InstanceDataPerDrawKey.Add(drawKey, instanceData);
-
- //generate srp batches
- int left = instanceCountPerDrawKey;
- for (int i = 0; i < batchCountPerDrawKey; i++)
- {
- int instanceOffset = i * maxItemPerDrawKeyBatch;
- int gpuOffsetInFloat4 = i * batchAlignedSizeInFloat4;
-
- var batchInstanceCount = left > maxItemPerDrawKeyBatch ? maxItemPerDrawKeyBatch : left;
- var drawBatch = new SrpBatch
- {
- DrawKey = drawKey,
- GraphicsBufferOffsetInFloat4 = gpuOffsetInFloat4,
- InstanceOffset = instanceOffset,
- InstanceCount = batchInstanceCount
- };
-
- m_BatchesPerDrawKey[drawKey].Add(m_DrawBatches.Length);
- m_DrawBatches.Add(drawBatch);
- left -= batchInstanceCount;
- }
- }
-
- int objectToWorldID = Shader.PropertyToID("unity_ObjectToWorld");
- int worldToObjectID = Shader.PropertyToID("unity_WorldToObject");
- int colorID = Shader.PropertyToID("_BaseColor");
- var batchMetadata = new NativeArray<MetadataValue>(4, Allocator.Temp, NativeArrayOptions.UninitializedMemory);
- for (int i = 0; i < m_DrawBatches.Length; i++)
- {
- var drawBatch = m_DrawBatches[i];
- var instanceData = m_InstanceDataPerDrawKey[drawBatch.DrawKey];
-
- var baseOffset = drawBatch.GraphicsBufferOffsetInFloat4 * kSizeOfFloat4;
- int gpuAddressOffset = baseOffset + 64;
- batchMetadata[0] = CreateMetadataValue(objectToWorldID, gpuAddressOffset, true); // matrices
- gpuAddressOffset += kSizeOfPackedMatrix * drawBatch.InstanceCount;
- batchMetadata[1] = CreateMetadataValue(worldToObjectID, gpuAddressOffset, true); // inverse matrices
- gpuAddressOffset += kSizeOfPackedMatrix * drawBatch.InstanceCount;
- batchMetadata[2] = CreateMetadataValue(colorID, gpuAddressOffset, true); // colors
-
-
- if (BatchRendererGroup.BufferTarget == BatchBufferTarget.ConstantBuffer)
- {
- drawBatch.BatchID = m_BRG.AddBatch(batchMetadata, instanceData.bufferHandle, (uint)BatchRendererGroup.GetConstantBufferOffsetAlignment(), (uint)BatchRendererGroup.GetConstantBufferMaxWindowSize());
- }
- else
- {
- drawBatch.BatchID = m_BRG.AddBatch(batchMetadata, instanceData.bufferHandle);
- }
- m_DrawBatches[i] = drawBatch;
- }
- }
二,Culling剔除视口外物体渲染
使用Jobs判定物体AABB包围盒是否在相机视口内,把视口外RendererNode的visible标记为false
- [BurstCompile]
- private unsafe struct CullingJob : IJobParallelFor
- {
- [ReadOnly]
- public NativeArray<Plane> CullingPlanes;
- [DeallocateOnJobCompletion]
- [ReadOnly]
- public NativeArray<SrpBatch> Batches;
- [ReadOnly]
- public NativeArray<RendererNode> Nodes;
- [ReadOnly]
- public NativeList<int> NodesIndexes;
- [ReadOnly]
- [NativeDisableContainerSafetyRestriction]
- public NativeArray<float4> ObjectToWorldMatrices;
- [ReadOnly]
- public int DrawKeyOffset;
-
- [WriteOnly]
- [NativeDisableUnsafePtrRestriction]
- public int* VisibleInstances;
- [WriteOnly]
- public NativeQueue<BatchDrawCommand>.ParallelWriter DrawCommands;
-
- public void Execute(int index)
- {
- var batchesPtr = (SrpBatch*)Batches.GetUnsafeReadOnlyPtr();
- var objectToWorldMatricesPtr = (float4*)ObjectToWorldMatrices.GetUnsafeReadOnlyPtr();
- ref var srpBatch = ref batchesPtr[index];
- int visibleCount = 0;
- int batchOffset = DrawKeyOffset + srpBatch.InstanceOffset;
- int idx = 0;
- for (int instanceIdx = 0; instanceIdx < srpBatch.InstanceCount; instanceIdx++)
- {
- idx = srpBatch.InstanceOffset + instanceIdx;
-
- int nodeIndex = NodesIndexes[idx];
- var node = Nodes[nodeIndex];
- if (!node.active) continue;
- //Assume only have 1 culling split and have 6 culling planes
- var matrixIdx = idx * 3;
- var worldAABB = Transform(ref objectToWorldMatricesPtr[matrixIdx], ref objectToWorldMatricesPtr[matrixIdx + 1], ref objectToWorldMatricesPtr[matrixIdx + 2], node.aabb);
- if (!(node.visible = (Intersect(CullingPlanes, ref worldAABB) != FrustumPlanes.IntersectResult.Out)))
- continue;
-
- VisibleInstances[batchOffset + visibleCount] = instanceIdx;
- visibleCount++;
- }
-
- if (visibleCount > 0)
- {
- var drawKey = srpBatch.DrawKey;
- DrawCommands.Enqueue(new BatchDrawCommand
- {
- visibleOffset = (uint)batchOffset,
- visibleCount = (uint)visibleCount,
- batchID = srpBatch.BatchID,
- materialID = drawKey.MaterialID,
- meshID = drawKey.MeshID,
- submeshIndex = (ushort)drawKey.SubmeshIndex,
- splitVisibilityMask = 0xff,
- flags = BatchDrawCommandFlags.None,
- sortingPosition = 0
- });
- }
- }
- }
三,添加/移除渲染物体:
添加Renderer,实际上就是从RendererNode列表中找出空闲的RendererNode用来存放数据。从上万长度的数组中找出空闲索引也是比较消耗性能的,所以这里使用Jobs查找,每次查找出N个空闲索引,存入队列待使用,直到用完后再进行下次查找。
移除Renderer,就是把RendererNode的active设置为false置为空闲状态
- public RendererNodeId AddRenderer(int resourceIdx, float3 pos, quaternion rot, float3 scale)
- {
- if (resourceIdx < 0 || resourceIdx >= m_RendererResources.Count)
- {
- return RendererNodeId.Null;
- }
- var rendererRes = m_RendererResources[resourceIdx];
- var inactiveList = m_InactiveRendererNodes[rendererRes.Key];
- if (inactiveList.Count < 1)
- {
- var nodesIndexes = m_DrawBatchesNodeIndexes[rendererRes.Key];
- var jobs = new GetInactiveRendererNodeJob
- {
- Nodes = m_AllRendererNodes.AsReadOnly(),
- NodesIndexes = nodesIndexes,
- RequireCount = 2048,
- Outputs = inactiveList
- };
- jobs.Schedule().Complete();
- }
- if (!inactiveList.TryDequeue(out int inactiveNodeIndex))
- {
- Log.Warning("添加Renderer失败, Inactive renderer node is null");
- return RendererNodeId.Null;
- }
- var renderer = m_AllRendererNodes[inactiveNodeIndex];
- renderer.position = pos;
- renderer.rotation = rot;
- renderer.localScale = scale;
- renderer.active = true;
- //renderer.color = float4(1);
- renderer.visible = true;
- renderer.animClipId = 0;
- m_AllRendererNodes[inactiveNodeIndex] = renderer;
- m_BatchesVisibleCount[rendererRes.Key]++;
- m_TotalVisibleCount++;
- return renderer.Id;
- }
四,同步RVO位置数据到RendererNode:
由于已经把所有RendererNode组织到了一个NativeArray里,所以可以非常容易得使用Jobs批量同步渲染位置、旋转等信息;
- /// <summary>
- /// 通过JobSystem更新渲染数据
- /// </summary>
- /// <param name="agents"></param>
- internal void SetRendererData(NativeArray<AgentData> agentsData)
- {
- var job = new SyncRendererNodeTransformJob
- {
- AgentDataArr = agentsData,
- Nodes = m_AllRendererNodes
- };
- job.Schedule(agentsData.Length, 64).Complete();
- }
-
-
- [BurstCompile]
- private struct SyncRendererNodeTransformJob : IJobParallelFor
- {
- [ReadOnly] public NativeArray<AgentData> AgentDataArr;
- [NativeDisableParallelForRestriction]
- public NativeArray<RendererNode> Nodes;
-
- public void Execute(int index)
- {
- var agentDt = AgentDataArr[index];
- var node = Nodes[agentDt.rendererIndex];
- node.position = agentDt.worldPosition;
- node.rotation = agentDt.worldQuaternion;
- node.animClipId = agentDt.animationIndex;
- Nodes[agentDt.rendererIndex] = node;
- }
- }
五,创建空物体并绑定RVO Agent和RendererNode:
上述BRG封装完成后就可以非常简单得创建空物体,在空物体脚本中绑定RVO Agent和RendererNode,其中RVO Agent用于自动寻路,RendererNode相当于是空物体的渲染组件;
空物体挂载脚本如下:
- using UnityEngine;
- using UnityGameFramework.Runtime;
-
- public class RvoBRGEntity : EntityBase
- {
- float m_MoveSpeed = 5f;
-
- Transform m_FollowTarget;
-
- RVOAgent mAgent;
- RendererNodeId m_RenderId;
- protected override void OnShow(object userData)
- {
- base.OnShow(userData);
- m_FollowTarget = Params.Get<VarTransform>("FollowTarget");
-
- mAgent = GF.RVO.AddAgent(this);//为空GameObject添加 RVO Agent
- mAgent.maxSpeed = m_MoveSpeed;
- m_RenderId = GF.BatchRender.AddRenderer(0, mAgent.pos, mAgent.rotation, CachedTransform.localScale); //为空GameObject添加一个BRG渲染节点
- mAgent.rendererIndex = m_RenderId.Index;
- mAgent.SyncTransform = false; //默认不同步当前Transform
- }
-
- protected override void OnUpdate(float elapseSeconds, float realElapseSeconds)
- {
- base.OnUpdate(elapseSeconds, realElapseSeconds);
- mAgent.targetPosition = m_FollowTarget.position; //更新RVO Agent目标点
- mAgent.animationIndex = mAgent.IsMoving ? 1 : 0;
- }
-
- protected override void OnHide(bool isShutdown, object userData)
- {
- if (!isShutdown)
- {
- GF.RVO.RemoveAgent(mAgent);
- GF.BatchRender.RemoveRenderer(m_RenderId);
- }
- base.OnHide(isShutdown, userData);
- }
- }
六,海量物体目标搜索:
海量物体就会面临如何获取范围内的敌人或获取最近的攻击目标,在数万数量级面前即使是遍历所有目标进行距离判定还是非常耗时的操作,大部分情况下需要每帧进行目标搜索。
推荐几个高性能jobs开源库:
1. Neighbor Search Grid, 可用于高性能最近目标搜索、范围内目标搜索:GitHub - nezix/NeighborSearchGridBurst: Neighbor search using a grid based approach + C# job system + Burst
2. KDTree Jobs版,可用于高性能最近目标搜索、范围内目标搜索:GitHub - ArthurBrussee/KNN: Fast K-Nearest Neighbour Library for Unity DOTS
3. QuadTree,可用于做高性能碰撞检测:GitHub - marijnz/NativeQuadtree: A Quadtree Native Collection for Unity DOTS
强烈推荐Neighbor Search Grid,其原理是将海量单位划分到格子区域,从查询点最近的格子进行目标搜索,同样支持单次查询多个点。
使用方法:
1. 查询最近目标:
以查询最近的RVO Agent为例:
- /// <summary>
- /// 给定多个point,一次查询各个点最近的Agent
- /// </summary>
- /// <param name="points"></param>
- /// <param name="nearestAgents"></param>
- /// <returns></returns>
- public int GetNearestAgents(Vector3[] points, RVOAgent[] nearestAgents)
- {
- if (points.Length != nearestAgents.Length || !m_orca.TryGetFirst(-1, out IAgentProvider agentProvider, true))
- {
- return 0;
- }
-
- m_orca.currentHandle.Complete();//确保RVO Jobs已经完成
- int arrayLength = agentProvider.outputAgents.Length;
- if (arrayLength < 1 || arrayLength != m_agents.Count) return 0;
-
- NativeArray<AgentData> tempAgentDatas = new NativeArray<AgentData>(agentProvider.outputAgents, Allocator.TempJob);
- var tempPositions = new NativeArray<float3>(arrayLength, Allocator.TempJob, NativeArrayOptions.UninitializedMemory);
- var job = new GetAgentsPositionArrayJob
- {
- Input = tempAgentDatas,
- Output = tempPositions
- };
- job.Schedule(arrayLength, 64).Complete();
- if (m_GirdInitialized)
- {
- if (m_GridSearch.PositionsLength != job.Output.Length)
- {
- m_GridSearch.clean();
- m_GridSearch.initGrid(job.Output);
- }
- else
- {
- m_GridSearch.updatePositions(job.Output);
- }
- }
- else
- {
- m_GridSearch.initGrid(job.Output);
- m_GirdInitialized = true;
- }
- var indexes = m_GridSearch.searchClosestPoint(points);
- int resultCount = 0;
- for (int i = 0; i < indexes.Length; i++)
- {
- var index = indexes[i];
- if (index == -1) continue;
- var searchAgent = m_agents[tempAgentDatas[index].index];
- if (searchAgent == null) continue;
- nearestAgents[resultCount++] = searchAgent;
- }
- tempPositions.Dispose();
- tempAgentDatas.Dispose();
- return resultCount;
- }
2. 查询范围内多个目标:
- /// <summary>
- /// 获取给定点半径内的Agents
- /// </summary>
- /// <param name="point"></param>
- /// <param name="radius"></param>
- /// <param name="results"></param>
- /// <returns></returns>
- public int OverlapSphere(Vector3 point, float radius, RVOAgent[] results)
- {
- if (!m_orca.TryGetFirst(-1, out IAgentProvider agentProvider, true))
- {
- return 0;
- }
- m_orca.currentHandle.Complete();//确保RVO Jobs已经完成
- int arrayLength = agentProvider.outputAgents.Length;
- if (arrayLength < 1 || arrayLength != m_agents.Count) return 0;
-
- NativeArray<AgentData> tempAgentDatas = new NativeArray<AgentData>(agentProvider.outputAgents, Allocator.TempJob);
- var tempPositions = new NativeArray<float3>(arrayLength, Allocator.TempJob, NativeArrayOptions.UninitializedMemory);
- var job = new GetAgentsPositionArrayJob
- {
- Input = tempAgentDatas,
- Output = tempPositions
- };
- job.Schedule(arrayLength, 64).Complete();
- if (m_GirdInitialized)
- {
- if (m_GridSearch.PositionsLength != job.Output.Length)
- {
- m_GridSearch.clean();
- m_GridSearch.initGrid(job.Output);
- }
- else
- {
- m_GridSearch.updatePositions(job.Output);
- }
- }
- else
- {
- m_GridSearch.initGrid(job.Output);
- m_GirdInitialized = true;
- }
- m_QueryPoints[0] = point;
- var indexes = m_GridSearch.searchWithin(m_QueryPoints, radius, results.Length);
- int resultCount = 0;
- for (int i = 0; i < indexes.Length; i++)
- {
- if (indexes[i] == -1) continue;
- int index = indexes[i];
- int agentIndex = tempAgentDatas[index].index;
- if (agentIndex >= 0 && agentIndex < arrayLength)
- {
- results[resultCount++] = m_agents[agentIndex];
- }
- }
- tempPositions.Dispose();
- tempAgentDatas.Dispose();
- return resultCount;
- }
总结:
海量物体同屏大多数时间并非所有物体都在视口内,所以BRG增加剔除功能后性能会得到大幅提升。
通过对RVO和BRG的封装,可以非常简单得与传统开发方式无缝结合,比使用Entities更加简单并且同样能享受到dots技术优势。
不足的是还没有为BRG实现LOD, 海量物体渲染CPU和GPU是木桶效应,共同决定了帧数。Jobs&Burst解决了CPU瓶颈,但GPU瓶颈还需要从多个方向去解决,其中使用LOD对远处物体使用低顶点Mesh已降低GPU压力是效果显著的一种方式。
关于移动平台,事实上BRG对移动平台无明显增益,Jobs才是性能提升的关键,使用Jobs计算数据和上传给GPU,大大降低了GPU等待CPU的时间,可惜的是移动平台下Jobs工作线程谜之少,带来的增益非常有限。
由于HybridCLR不支持Burst加速,HybridCLR下Jobs代码以解释方式执行,所以相比AOT性能大打折扣。对于热更项目要想发挥Burst加成,就需要把Jobs代码放到AOT执行了。以demo为例,dots代码放到AOT后与纯AOT性能相差无几,5K人全部在视口内也能流畅运行,相对于移动平台,在实际项目中同时出现在视口内的物体基本不会超过3K,有了Culling功能后视口内外共1W物体也能流程运行。
- 文章浏览阅读1k次。区别在于,Asset是在编辑器中管理和引用的资源,而Resource是在运行时动态加载的资源。Unity采用的方案明显是第二种,它会对Assets文件夹下的所有文件生成一个名称相同,扩展名为meta的文件,包括文件夹也会... [详细]
赞
踩
 文章浏览阅读1.3k次,点赞30次,收藏31次。Post-Processing是一块内容很多知识,想要学习好这块简单大家还是多去网上查阅资料。因为博客嘛,整理简单的东西还可以,太复杂了就显得不够用了。我会整理我学习的步骤给大家,大家也去看看... [详细]
文章浏览阅读1.3k次,点赞30次,收藏31次。Post-Processing是一块内容很多知识,想要学习好这块简单大家还是多去网上查阅资料。因为博客嘛,整理简单的东西还可以,太复杂了就显得不够用了。我会整理我学习的步骤给大家,大家也去看看... [详细]赞
踩
- 文章浏览阅读4.1k次,点赞83次,收藏87次。本文将使用ShaderGraph制作一个根据坐标控制溶解的位置,物体靠近局部溶解的效果,可以直接拿到项目中使用。下面就开始看一下具体的制作流程,然后自己动手制作一个吧!【UnityShader... [详细]
赞
踩
- 文章浏览阅读601次。[游戏开发][Unity]Xlua生成wrap文件报错、打AB包Wrap报错[游戏开发][Unity]Xlua生成wrap文件报错、打AB包Wrap报错 Xlua生成wrap文件,自带添加了ref字段报错例如... [详细]
赞
踩
- 文章浏览阅读972次,点赞44次,收藏50次。Unity的多语言本地化是一个很实用的功能,它可以帮助游戏支持多种语言,让不同语言的玩家都能够更好地体验游戏。而实现本地化的方案也有很多种,各个方案之间也各有优劣,后面也会对多个方案进行介绍学习... [详细]
赞
踩
- 文章浏览阅读2.6k次,点赞4次,收藏14次。UnityMetaQuest混合现实MR透视Passthrough开发环境配置_unityvrunityvr文章目录... [详细]
赞
踩
- 文章浏览阅读4.1k次,点赞36次,收藏96次。ShaderGraph是Unity中的一个可视化工具,用于创建和编辑图形着色器。其意义在于简化编写复杂着色器的过程,减少对具体编程语言的依赖,使艺术家和设计师可以更方便地创建各种美术效果。使用... [详细]
赞
踩
- 文章浏览阅读1.1w次,点赞17次,收藏77次。unity新手向:通过实例化实现简单的射击功能。_unity3d发射子弹unity3d发射子弹前言:对于射击类游戏,相信大家并不陌生。那么想要实现这一功能,我们通常会使用两种方法:1.射线追踪... [详细]
赞
踩
 文章浏览阅读2k次,点赞4次,收藏6次。ThreadPool中有若干数量的线程,如果有任务需要处理时,会从线程池中获取一个空闲的线程来执行任务,任务执行完毕后线程不会销毁,而是被线程池回收以供后续任务使用。当线程池中所有的线程都在忙碌时,又... [详细]
文章浏览阅读2k次,点赞4次,收藏6次。ThreadPool中有若干数量的线程,如果有任务需要处理时,会从线程池中获取一个空闲的线程来执行任务,任务执行完毕后线程不会销毁,而是被线程池回收以供后续任务使用。当线程池中所有的线程都在忙碌时,又... [详细]赞
踩
- 文章浏览阅读1.2k次,点赞3次,收藏4次。如何通过环信IMSDK实现用户管理、好友系统(联系人管理)及聊天消息管理功能。_环信im环信im文章目录... [详细]
赞
踩
- 文章浏览阅读4.2k次,点赞36次,收藏96次。ShaderGraph是Unity中的一个可视化工具,用于创建和编辑图形着色器。其意义在于简化编写复杂着色器的过程,减少对具体编程语言的依赖,使艺术家和设计师可以更方便地创建各种美术效果。使用... [详细]
赞
踩
- 文章浏览阅读1.4k次。在Unity中,UI缩放模式定义了UI元素在屏幕上的缩放方式。Unity提供了三种UI缩放模式:ConstantPixelSize(固定像素大小)、ScaleWithScreenSize(按屏幕大小缩放)和Const... [详细]
赞
踩
 文章浏览阅读5k次,点赞11次,收藏42次。上面设置的值表示,当粒子效果数量达到100以后,它就会为了保护计算机,当前面一波的粒子效果消失之后,才会去进行下一波的粒子效果的显示,这是一种保护性能、设置上限的方法,也是一种保护性能‘设置上限的... [详细]
文章浏览阅读5k次,点赞11次,收藏42次。上面设置的值表示,当粒子效果数量达到100以后,它就会为了保护计算机,当前面一波的粒子效果消失之后,才会去进行下一波的粒子效果的显示,这是一种保护性能、设置上限的方法,也是一种保护性能‘设置上限的... [详细]赞
踩
 众所周知,工欲善其事必先利其器,有一个好的工具可以让我们事半功倍,有一个好用的网站更是如此!但是好用的网站真的太多了,收藏夹都满满的(但是几乎没打开用过unity学习网站Unity相关网站整理大全众所周知,工欲善其事必先利其器,有一个好的工... [详细]
众所周知,工欲善其事必先利其器,有一个好的工具可以让我们事半功倍,有一个好用的网站更是如此!但是好用的网站真的太多了,收藏夹都满满的(但是几乎没打开用过unity学习网站Unity相关网站整理大全众所周知,工欲善其事必先利其器,有一个好的工... [详细]赞
踩
 (1)熟悉Unity中UI界面的设计与编写;(2)熟悉UI界面中场景转换,UI与场景内容相互关联的方式。(3)熟悉Unity中MySQL数据库的操作新建一个Unity场景,在此场景中实现如下功能:(1)自行设计一个登录、注册UI界面;(2)... [详细]
(1)熟悉Unity中UI界面的设计与编写;(2)熟悉UI界面中场景转换,UI与场景内容相互关联的方式。(3)熟悉Unity中MySQL数据库的操作新建一个Unity场景,在此场景中实现如下功能:(1)自行设计一个登录、注册UI界面;(2)... [详细]赞
踩
 unity如何生成exe文件_unity导出exeunity导出exe场景:unity如何生成exe文件方法在Unity中,可以通过以下步骤生成exe文件:在Unity界面中,点击菜单栏的“File”,选择“BuildSettings”。在... [详细]
unity如何生成exe文件_unity导出exeunity导出exe场景:unity如何生成exe文件方法在Unity中,可以通过以下步骤生成exe文件:在Unity界面中,点击菜单栏的“File”,选择“BuildSettings”。在... [详细]赞
踩
- 本人是在学习完c,c++,数据结构算法,操作系统网络这些基础的课程之后,打算学习自己喜欢的游戏开发方向的东西,然后在B站上自学了几天unity,用到unity的触发器,碰撞,刚体,以及一个简单的ui界面,但是本人目前没有c#的学习经验,但是... [详细]
赞
踩
- Unity——在C#中调用C++动态链接库(DLL)。打开VS,新建一个C++空项目,自命名项目名称与位置。如果Unity已经在运行并且Dll已经存在,那么新的Dll写入生成会失败,此时需要关掉Unity再重新生成。_unity调用c++动... [详细]
赞
踩
- 最近有个Holoens2识别灭火器实体交互的项目,大概有2-3年没有搞MR的项目了,重新看一下,以前没有记录的习惯,现在慢慢培养一下。小Dome链接:link好记性不如烂笔头!unity使用Vuforia扫描实体物体交互文章目录前言一、Vu... [详细]
赞
踩
- 记录风格化水的实现过程_unity水体shaderunity水体shader写在前面长文警告!!!!!很久没更新博客了,,这次是要做一个风格化水效果,是基于Plane着色实现水面效果。项目:Unity2017.4.40f1Build-in,... [详细]
赞
踩

