
- 1c++ 全局数组_c++ 怎么使数组全局化
- 2比较稳妥的荣品 rk3399刷机,顺便解决无法进入刷入系统问题以及短接针脚刷机麻烦的问题
- 3python转换八进制用取余数方法_python 二、八、十六进制之间的快速转换
- 4多少并发量算高并发_高并发解决方案之秒杀
- 5Django实现接口自动化平台(十四)测试用例模块Testcases序列化器及视图【持续更新中】_python django自动化测试平台源码
- 6斯坦福 Stats60:21 世纪的统计学:第十五章到第十八章
- 7VMware虚拟机和主机之间无法复制粘贴,移动文件,重新安装vmware-tools变灰,VMware Tools继续运行脚本未能在虚拟机中成功运行。_vmware无法复制到主机
- 8基于GPT-4的 IDEA 神仙插件,亲测可用!
- 9【debug】error: subprocess-exited-with-error
- 10MyBatis-Plus QueryWapper 满足多个条件Or另一个条件_querywrapper 多个条件or匹配
quality focal loss & distribute focal loss 详解(paper, 代码)_distribution focal loss
赞
踩
参见generalized focal loss paper
其中包含有Quality Focal Loss 和 Distribution Focal Loss。
背景
dense detectors逐渐引领了目标检测领域的潮流。
目标框的表达方法,localization quality估计方法的改进引起了目标检测的逐渐进步。
其中,目标框表达(坐标或(l,r,t,b))目前被建模为一个简单的Dirac delta分布,也就是说数值是固定的,没有一个可变的范围。
localization quality可以是IOU score 或是 centerness score(FCOS),
在FCOS中 localization quality 和 分类score 进行了结合(相乘),得到最终的score, 然后在NMS中降序排列。
尽管已经有localization quality和分类score结合的先例,作者发现还存在2个问题:
- 训练和推理中 localization quality估计 和 分类score 的用处是不同的(对应QFL):
(1) 在最近的dense detectors中,localization quality的估计(IOU score等)和分类score是分开独立训练的,然而推理的时候却结合在一起(相乘),是不是训练的时候没有考虑它们的结合相关性?
(2) 一般只对正样本进行localization quality估计的监督,这不一定是可靠的,因为负样本可能拿到更高的估计。
通过一个图来看,下面的Figure 2中(a)列举了2个localization quality (IOU score) 较高的负样本(虽然分类score比较低)。
(b)中的蓝色点显示了分类score和IOU score的弱相关性,其中红色圈里面的(包含了图(a)中的A,B样本)就是有较高IOU score的负样本。而绿色点是作者提出的联合表示法,让它们有相关性(相等)。

- 目标框的表达不够灵活
广泛使用的目标框表达用了Dirac delta分布(一个脉冲),也就是说,坐标是固定的,要跟ground truth一样,不存在灵活变动的目标框。
但是看下图,有些物体本身边界就是不明确的,如左图,因为浪花的存在,左边界是不清晰的,所以这时候ground truth不一定是可靠的(用脉冲分布来判断也是不可靠的)。
而作者提出的分布对于不明确的边界有一个分布区间,可以在区间范围的数值灵活取值;而对明确的边界区间范围就比较尖锐。(图片中白框为gt, 绿框为作者方法的预测)
虽然近来有一些work提出了用高斯分布,但是高斯分布太simple, 谁又能保证真实的数值分布就是这样的对称?

上面是大背景,现在来回顾一下Focal Loss
Focal Loss
Focal Loss在这篇文章里有写过。
它主要是解决class imbalance,同时降低容易分类的weight,使训练更集中到难分类的上面
我们从cross entropy入手:
cross entropy的公式如下:
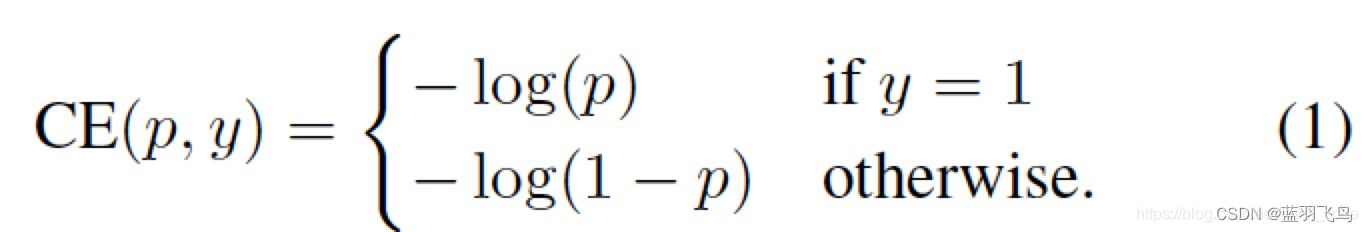
把其中的y=1时为p, y=0时1-p 写成一个
p
t
p_{t}
pt
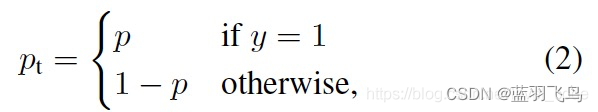
那么,cross entropy可以简化为:
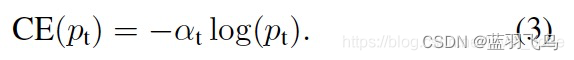
降低容易分类的weight, 比如
p
t
=
0.9
p_{t}=0.9
pt=0.9时,很容易分类,降低它的weight, 同时结合
α
t
\alpha_{t}
αt解决class imbalance的问题。
这个就是Focal Loss的公式。
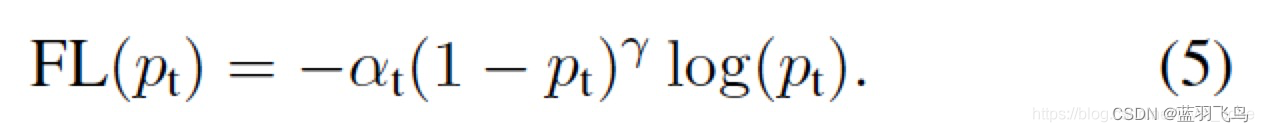
Quality Focal Loss
Quality Focal Loss是针对作者提出的问题1。
要把IOU score 和 分类score 结合起来,防止出现 训练时它们互不相关,推理时又结合在一起用 的问题。
要把分类score和IOU score结合,就是把one-hot label给soft化,具体就是把label的1 乘以 IOU score,
这里的IOU score是指预测出的bounding box和与之匹配的ground truth box的IOU。范围在0~1之间。
理论上来说一个预测box会匹配一个gt_box, 当匹配多个时,取cost最小的那个。
至于如何匹配,就是计算一张图片中有效的(自己定义)预测box和这张图片所有的ground truth box的IOU,
再取IOU>阈值的box作为最终预测的box。
每个box还会有一个class score.
class score经过sigmoid运算后就是公式中的
σ
\sigma
σ
公式中的
y
y
y是label乘以对应的IOU score,那就是分类score和IOU score的结合产物。
现在它们已经结合起来,而又和Focal loss有什么关系?
为了解决class imbalance的问题,这个结合产物还需要和Focal Loss结合,
但是Focal Loss的label是0,1,而这里的soft label是小数,
所以把Focal Loss中的两项做一下扩展:

因此得到最后的QFL公式:

具体看下面的代码:
def quality_focal_loss(pred, target, beta=2.0): r"""Quality Focal Loss (QFL) is from `Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection <https://arxiv.org/abs/2006.04388>`_. Args: pred (torch.Tensor): Predicted joint representation of classification and quality (IoU) estimation with shape (N, C), C is the number of classes. target (tuple([torch.Tensor])): Target category label with shape (N,) and target quality label with shape (N,). beta (float): The beta parameter for calculating the modulating factor. Defaults to 2.0. Returns: torch.Tensor: Loss tensor with shape (N,). """ assert ( len(target) == 2 ), """target for QFL must be a tuple of two elements, including category label and quality label, respectively""" # label denotes the category id, score denotes the quality score label, score = target #label:gt label,score:gt score(IOU), # negatives are supervised by 0 quality score #pred:预测的class score pred_sigmoid = pred.sigmoid() #sigmoid:1/(1+e^-x) scale_factor = pred_sigmoid zerolabel = scale_factor.new_zeros(pred.shape) #全0 #label全为0时的qfl loss,即先把背景的loss填上 loss = F.binary_cross_entropy_with_logits( #等价于sigmoid+binary entropy, 更稳定 pred, zerolabel, reduction="none" ) * scale_factor.pow(beta) # FG cat_id: [0, num_classes -1], BG cat_id: num_classes bg_class_ind = pred.size(1) #背景的下标 #label是前景的下标,注意这是gt label pos = torch.nonzero((label >= 0) & (label < bg_class_ind), as_tuple=False).squeeze( 1 ) pos_label = label[pos].long() #取出下标对应的前景gt label # positives are supervised by bbox quality (IoU) score scale_factor = score[pos] - pred_sigmoid[pos, pos_label] #公式中的(y-sigma) #在有前景的对应位置填上gfl的前景loss loss[pos, pos_label] = F.binary_cross_entropy_with_logits( pred[pos, pos_label], score[pos], reduction="none" ) * scale_factor.abs().pow(beta) #公式中的QFL(sigma)不要负号 loss = loss.sum(dim=1, keepdim=False) return loss

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
Distribute Focal Loss
Distribution focal loss针对的是作者提出的问题2.
也就是目标框坐标不够灵活的问题,尤其在边界不够清晰明确的情况下(如遮挡等)。
看一个图理解一下

现有的方法在分类时label是one-hot, 而GFL(包含QFL和DFL)的QFL中把分类score和IOU score结合起来,形成了soft one-hot label.
再看目标框,现在是用(l, t, r, b)的形式估计box(参考FCOS).
既有的方法把目标框的(l, t, r, b) 定为脉冲分布,就是这个数值,没得商量。
而DFL中目标框的坐标有一个分布,有一个灵活变动的范围。
下面来看看如何灵活变动。
一般来说,预测值x 和真实标签y 之间,是假设的Dirac delta分布(一个脉冲),即

这表示预测值x 总有一个标签y与之对应。
那么将它与x相乘就能复原标签y.

现在不用脉冲分布,也不用高斯分布或是其他什么分布,直接用一个P(x)表示一个广义的分布。
假设label y的范围在[y0, yn], 就可以根据模型估计

为了和CNN一致,把连续积分变离散表达,
这时需要从[y0, yn]这个区间取出一系列的值{y0, y1, … yn}(作者是每间隔1取一次值)。
同时还要保证离散概率之和为1的性质:

于是(4)式就变为:

那这里的P(x)分布到底是什么呢?
作者把它简化为一个有n+1个units的Softmax layer,那么
P
(
y
i
)
P(y_{i})
P(yi)就对应了
S
i
S_{i}
Si
但是y不是可以直接用任何一个loss函数从网络end-to-end训练出来么,
注意到这个训练过程中,P(x)可以是任意值,使得积分结果为y,如下图,能得到y的不同组合很多。
需要选出一个接近target的分布提高学习效率。
直觉上来说,分布(3)在target附近更集中,更容易预测出准确结果。

因此要优化P(x)的形状,使它在target y附近有更高的概率。而且这个location处不要偏离label太多。
综合以上考虑,作者提出了DFL,使网络尽快把值集中到label y, 增大
y
i
y_{i}
yi和
y
i
+
1
y_{i+1}
yi+1的概率。
其中
y
i
<
=
y
<
=
y
i
+
1
y_{i} <= y <= y_{i+1}
yi<=y<=yi+1,也就是最接近y的两个label.
而且因为只有正样本才有目标框,不存在class imbalance的情况。
所以只需要用QFL中的cross entropy部分。
总结一下,DFL就是要让预测的label y 尽可能地靠近
y
i
y_{i}
yi和
y
i
+
1
y_{i+1}
yi+1.
这个label可以是box坐标,(l, t, r, b)中的每个数值等。

看下它的代码
def distribution_focal_loss(pred, label): r"""Distribution Focal Loss (DFL) is from `Generalized Focal Loss: Learning Qualified and Distributed Bounding Boxes for Dense Object Detection <https://arxiv.org/abs/2006.04388>`_. Args: pred (torch.Tensor): Predicted general distribution of bounding boxes (before softmax) with shape (N, n+1), n is the max value of the integral set `{0, ..., n}` in paper. label (torch.Tensor): Target distance label for bounding boxes with shape (N,). Returns: torch.Tensor: Loss tensor with shape (N,). """ #label为y, pred为y^(y的估计值) #因为y_i <= y <= y_i+1(paper) #取dis_left = y_i, dis_right = y_i+1 dis_left = label.long() dis_right = dis_left + 1 weight_left = dis_right.float() - label #y_i+1-y weight_right = label - dis_left.float() #y-y_i #paper中的log(S)这里用CE loss = ( F.cross_entropy(pred, dis_left, reduction="none") * weight_left + F.cross_entropy(pred, dis_right, reduction="none") * weight_right ) return loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 文章浏览阅读6.9k次,点赞26次,收藏138次。LSTM(LongShort-TermMemory)是一种常用的循环神经网络(RNN)模型,用于处理序列数据,具有记忆长短期的能力。在时间序列预测中,LSTM既可以多元预测机制又可以作为单元... [详细]
赞
踩
- 计算机视觉是一门研究如何使机器“看”的科学,更进一步的说,就是是指用摄影机和电脑代替人眼对目标进行识别、跟踪和测量等机器视觉,并进一步做图形处理,使电脑处理成为更适合人眼观察或传送给仪器检测的图像。作为一个科学学科,计算机视觉研究相关的理论... [详细]
赞
踩
- 本文全面回顾了目标检测技术的演进历程,从早期的滑动窗口和特征提取方法到深度学习的兴起,再到YOLO系列和Transformer的创新应用。通过对各阶段技术的深入分析,展现了计算机视觉领域的发展趋势和未来潜力。人工智能-目标检测:发展历史、技... [详细]
赞
踩
- OpenCV+OCR识别图像验证码中指定颜色文字!【OpenCV+OCR】计算机视觉:识别图像验证码中指定颜色文字文章目录1.写在前面2.读取验证码图像3.生成颜色掩码4.生成黑白结果图5.OCR文字识别6.测试结果【作者主页】:吴秋霖【作... [详细]
赞
踩
- 本文全面探讨了人脸识别技术的发展历程、关键方法及其应用任务目标,深入分析了从几何特征到深度学习的技术演进。_人脸识别技术的发展历程人脸识别技术的发展历程目录一、人脸识别技术的发展历程早期探索:20世纪60至80年代技术价值点:自动化与算法化... [详细]
赞
踩
- 材料设计和发现:通过机器学习和深度学习算法,预测材料的性质和特性,在材料研究和开发中起到重要的作用。例如,使用AI算法可以快速分析材料的光学、电学和磁学性能,预测材料的力学性能和耐久性能等。材料制备和加工:AI可以帮助优化材料制备和加工工艺... [详细]
赞
踩
- 讲述BP神经网络原理,并通过Python语言,分别导入numpy、sklearn和pytorch库完成编程。_bp神经网络bp神经网络一、人工神经网络1.1人工神经网络理论人工神经网络(ArtificialNeuralNetwork,ANN... [详细]
赞
踩
 关于人类大脑建模的数学公式主要涉及到神经元网络、激活函数、学习算法等方面。这里是一些常见的数学公式(使用Markdown和LaTeX语法)。【人工智能】关于人类大脑模型的一些数学公式关于人类大脑模型的一些数学公式文章目录关于人类大脑模型的一... [详细]
关于人类大脑建模的数学公式主要涉及到神经元网络、激活函数、学习算法等方面。这里是一些常见的数学公式(使用Markdown和LaTeX语法)。【人工智能】关于人类大脑模型的一些数学公式关于人类大脑模型的一些数学公式文章目录关于人类大脑模型的一... [详细]赞
踩
- 大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型13-pytorch搭建RBM(受限玻尔兹曼机)模型,调通模型的训练与测试。RBM(受限玻尔兹曼机)可以在没有人工标注的情况下对数据进行学习。其原理类似于我们人类学习... [详细]
赞
踩
- 【深度学习】详解MAE-MaskedAutoencodersAreScalableVisionLearners_maemae目录摘要一、引言二、相关工作三、方法四、ImageNet实验4.1主要属性4.2与先前结果的对比4.3部分微调五、迁... [详细]
赞
踩
- 本系列旨在普及那些深度学习路上必经的核心概念,文章内容都是博主用心学习收集所写,欢迎大家三联支持!本系列会一直更新,核心概念系列会一直更新!欢迎大家订阅。【人工智能|知识表示】问题规约法&谓词/符号逻辑,良好的知识表示是解题的关键!(笔记总... [详细]
赞
踩
- 深度学习笔记——CNN卷积神经网络理论篇。主要包括CNN的概念、基本原理、类型综述。算是比较完善的一篇文章了。_打卤面cnn(卷积神经网络)csdn打卤面cnn(卷积神经网络)csdn学习时间:2022.04.10~2022.04.12文章... [详细]
赞
踩
- 身处人工智能爆发式增长时代的机器学习从业者无疑是幸运的,人工智能如何更好地融入人类生活的方方面面是这个时代要解决的重要问题。滴滴国际化资深算法工程师王聪颖老师发现,很多新人在入行伊始,往往把高大上的模型理论背得滚瓜烂熟,而在真正应用时却摸不... [详细]
赞
踩
- 作者:王斌谢春宇冷大炜引言目标检测是计算机视觉中的一个非常重要的基础任务,与常见的的图像分类/识别任务不同,目标检测需要模型在给出目标的类别之上,进一步给出目标的位置和大小信息,在CV三大任务(识别、检测、分割)中处于承上启下的关键地位。当... [详细]
赞
踩
- 人工智能的数学基础第一章人工智能与数学基础1.1人工智能简介1.2数学在人工智能中的作用1.3本书内容概述第二章线性代数基础2.1向量与矩阵2.2行列式与矩阵计算2.3线性方程组2.4矩阵分解与特征值分析第三章微积分基础3.1导数与微分3.... [详细]
赞
踩
 深度学习(DeepLearning,DL)是贯穿所有生成模型(GenerativeModel)的共同特征,几乎所有复杂的生成模型都以深度神经网络为核心,深度神经网络能够学习数据结构中的复杂关系,而不需要预先提取数据特征。在本节中,我们将介绍... [详细]
深度学习(DeepLearning,DL)是贯穿所有生成模型(GenerativeModel)的共同特征,几乎所有复杂的生成模型都以深度神经网络为核心,深度神经网络能够学习数据结构中的复杂关系,而不需要预先提取数据特征。在本节中,我们将介绍... [详细]赞
踩
- 1.Copilot的环境安装与使用都非常简单,可以把它当作一个在IDE中使用的ChatGPT。2.一些明确的代码逻辑,可以交给它完成。3.Copilot并非所有的输出都是正确的,在使用的过程中,需要适当进行纠错。人工智能|结对编程助手Git... [详细]
赞
踩
- 目标追踪技术对于民生、社会的发展以及国家军事能力的壮大都具有重要的意义。它不仅仅可以应用到体育赛事当中目标的捕捉,还可以应用到交通上,比如实时监测车辆是否超速等!对于国家的军事也具有一定的意义,比如说导弹识别目标等方向。所以说实时目标追踪技... [详细]
赞
踩
- 上一章介绍了目标检测上篇,主要为两阶段检测的R-CNN系列。这一章来学习一下目标检测下篇。R-CNN系列算法面临的一个问题,不是端到端的模型,几个构件拼凑在一起组成整个检测系统,操作起来比较复杂。而今天介绍的YOLO算法,操作简便且速度快,... [详细]
赞
踩
- 计算机视觉中的目标检测,梳理了这方面的知识点,主要讲了R-CNN、FastR-CNN、FasterR-CNN三种架构以及一些细节与改进方法【计算机视觉】24-ObjectDetection文章目录24-ObjectDetection1.In... [详细]
赞
踩

