
- 1HarmonyOS应用开发-闪屏启动页
- 2揭密字节跳动薪资职级,资深测试居然能拿......_字节跳动2-2是什么级别
- 3【云原生】kubectl命令的详解_kubectl命令详解
- 4Linux最狠命令sudo rm -rf /* 详细解释_删库代码rm-rf
- 5web3: 智能合约
- 6Android 系统启动过程纪要(基于Android 10)
- 7华为云云耀云服务器L实例评测|Python Selenium加Chrome Driver构建UI自动化测试实践
- 8HDFS Java API操作(IDEA版)
- 9基于产生式系统的小型专家系统--动物识别_产生式系统动物识别
- 10Android Studio下载及安装和Gradle的配置(非常详细)从零基础入门到精通,看完这一篇就够了
Python爬虫实战+数据分析+数据可视化(猫眼电影)_y5dcc
赞
踩
一、爬虫部分
爬虫说明:
1、本爬虫是以面向对象的方式进行代码架构的
2、本爬虫爬取的数据存入到MongoDB数据库中
3、爬虫代码中有详细注释
代码展示
import re import time from pymongo import MongoClient import requests from lxml import html from urllib import parse class CatMovie(): def __init__(self): self.start_url = 'https://maoyan.com/films?showType=3&offset=0' self.url_temp = 'https://maoyan.com/films?showType=3&offset={}' self.detail_url = 'https://maoyan.com/films/{}' # 构造响应头 self.headers = { "Cookie": "__mta=143397386.1607405956154.1608533524873.1608533569928.76; _lxsdk_cuid=174f6b873b49b-005ed8da7476a-3d634f03-144000-174f6b873b5c8; uuid_n_v=v1; __utma=17099173.1780976830.1607406113.1607406113.1607406113.1; __utmz=17099173.1607406113.1.1.utmcsr=(direct)|utmccn=(direct)|utmcmd=(none); recentCis=52%3D73%3D1; _lxsdk=92DE8D903FA311EB97145540D12763BA74A99EC69EF74E288E03A6373ED78378; _lx_utm=utm_source%3Dmeituanweb; Hm_lvt_703e94591e87be68cc8da0da7cbd0be2=1608533269,1608533300,1608533544,1608533623; Hm_lpvt_703e94591e87be68cc8da0da7cbd0be2=1608533623; _lxsdk_s=176840dd994-603-17f-1df%7C%7C34; __mta=143397386.1607405956154.1608533569928.1608533622616.77; uuid=70554980435911EB91B6516866DCC34951FCE88748C84B79A0630808E1889048; _csrf=be6825573a1247a5dcf2ed5a6100bacaacccd21643c45ee79a3a7a28c1bb32e9; lt=3dN05zd6hwM_WEa3scYBnu5qcEoAAAAARgwAAMUreBNzDKR9eCuGuYWtOPWt5ULO65alj1dffuIQJisgN0lrWp0kJkyABp6Ly8cJ2A; lt.sig=y5Xz3WT9ooI2TpIM7pzKU9CROfo", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.88 Safari/537.36" } # 猫眼电影的自定义字体映射 self.font_dict = {'unif4ef': '6', 'unif848': '3', 'unif88a': '7', 'unie7a1': '9', 'unie343':'1','unie137':'8','unif489':'0','unie5e2':'4','unif19b':'2','unie8cd':'5'} self.client = MongoClient() self.collection = self.client['test']['cat_movie'] # 构造请求详情页url def get_url_list(self): total_num = 2000 page = total_num//30+1 return [self.url_temp.format(i*30) for i in range(0,page+1)] # 解析请求并解析url地址 def parse_url(self,url): rest = requests.get(url,headers=self.headers) return rest.content.decode() # 解析并获取列表页数据 def get_content_list(self,html_str): movie_ids = re.findall(r'href="/films/(.*?)" target',html_str) item_list = [] for i in movie_ids[::3]: item = {} detail_url = self.detail_url.format(i) # 获取到每一个详情数据的唯一标志在通过urljoin构造详情页url item['detail_url'] = parse.urljoin(self.start_url,detail_url) item = self.parse_detail(item['detail_url'],item) print(item) item_list.append(item) return item_list # 解析并获取详情页数据 def parse_detail(self,url,item): time.sleep(0.1) rest = requests.get(url,headers=self.headers) # 先替换掉页面中加密字体的&#x 通过用**包裹方便后续锁定 html_str = re.sub(r'&#x(\w+)?;',r'*uni\1*',rest.content.decode()) html_str = html.etree.HTML(html_str) # 获取信息多采用三目运算符的方式 防止因获取的内容不存在而报异常 # 通过三目运算符进行多重判断可以增加程序的稳定性 movie_name = html_str.xpath('//div[@class="movie-brief-container"]/h1/text()') item['movie_name'] = movie_name[0] if len(movie_name)>0 else None movie_type = html_str.xpath('//div[@class="movie-brief-container"]/ul/li[1]/a/text()') movie_type = movie_type if len(movie_type)>0 else None if movie_type is not None: item['movie_type'] = '·'.join([i.strip() for i in movie_type]) else: item['movie_type'] = '类型未知' area_time = html_str.xpath('//div[@class="movie-brief-container"]/ul/li[2]/text()') area_time = area_time[0] if len(area_time)>0 else None if area_time is not None: area_time = area_time.split('/') item['movie_area'] = area_time[0].strip() if len(area_time)>0 else '上映国家未知' item['movie_duration'] = area_time[1].strip() if len(area_time)>1 else '电影时长未知' else: item['movie_area'] = '上映国家未知' item['movie_duration'] = '电影时长未知' movie_publish = html_str.xpath('//div[@class="movie-brief-container"]/ul/li[3]/text()') movie_publish = movie_publish[0] if len(movie_publish)>0 else None if movie_publish is not None: item['movie_publish'] = re.findall(r'(\d+-\d+-\d+)',movie_publish) item['movie_publish'] = item['movie_publish'][0] if len(item['movie_publish'])>0 else movie_publish else: item['movie_publish'] = '上映时间未知' movie_score = html_str.xpath('//div[@class="movie-index-content score normal-score"]/span/span/text()') movie_score = movie_score[0] if len(movie_score)>0 else None if movie_score is not None: item['movie_score'] = re.sub(r'(\*[a-z0-9]+?\*)',lambda x:self.font_dict[x.group(1).strip('*')],movie_score) else: item['movie_score'] = '电影评分未知' movie_comments = html_str.xpath('//span[@class="score-num"]/span/text()') movie_comments = movie_comments[0] if len(movie_comments)>0 else None if movie_comments is not None: item['movie_comments'] = re.sub(r'(\*[a-z0-9]+?\*)',lambda x:self.font_dict[x.group(1).strip('*')],movie_comments) else: item['movie_comments'] = '评论人数未知' movie_booking = html_str.xpath('//div[@class="movie-index-content box"]/span[1]/text()') movie_booking = movie_booking[0] if len(movie_booking)>0 else None if movie_booking is not None: unit = html_str.xpath('//div[@class="movie-index-content box"]/span[2]/text()') unit = unit[0] if len(unit) > 0 else '' item['movie_booking'] = re.sub(r'(\*[a-z0-9]+?\*)', lambda x: self.font_dict[x.group(1).strip('*')],movie_booking) + unit else: item['movie_booking'] = '电影票房未知' movie_director = html_str.xpath('//div[@class="celebrity-container"]//div[1]//div[@class="info"]//a/text()') movie_director = movie_director[0] if len(movie_director)>0 else None if movie_director is not None: item['movie_director'] = movie_director.strip() else: item['movie_director'] = '导演未知' return item # 保存数据 def save(self,content_list): for i in content_list: self.collection.insert(i) # 程序主方法 def run(self): url_list = self.get_url_list() for i in url_list: time.sleep(0.5) html_str = self.parse_url(i) item_list = self.get_content_list(html_str) # self.save(item_list) if __name__ == '__main__': movie = CatMovie() movie.run()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
二、数据分析和数据可视化部分
数据分析和数据可视化说明:
1、本博客通过Flask框架来进行数据分析和数据可视化
2、项目的架构图为

代码展示
- 数据分析代码展示(analysis.py)
import re from pymongo import MongoClient import pandas as pd import numpy as np import pymysql # 不同年份上映的电影数量 def movie_date_publish_count(df): grouped = df.groupby('movie_publish_year')['movie_type'].count().reset_index() data = grouped.to_dict(orient='records') # 将数据转换成数组嵌套数组的格式 data = [[str(i['movie_publish_year']),i['movie_type']] for i in data] return data # 不同地区的电影上映数量最多的前十个地区 def movie_country_publish_top10(df): # 原数据中可能每个电影上映在多个地区 且不同地区之间使用逗号分隔 因此将movie_area列数据以逗号进行分隔变成列表 series_country = df['movie_area'].str.split(',').tolist() # 利用set函数的特性 当数据出现重复时 只保留一个数据 list_country = set([j for i in series_country for j in i]) # 创建0矩阵统计不同地区电影上映的数量 zero_list = pd.DataFrame(np.zeros((len(series_country),len(list_country))),columns=list_country) for i in range(len(zero_list)): zero_list.loc[i][series_country[i]] = 1 # 使用聚合函数对不同地区的电影进行统计 country_movie_counts = zero_list.sum().astype(np.int) country_movie_counts = country_movie_counts.reset_index() country_movie_counts.columns = ['movie_area','count'] # 对数据进行排序并取出数量最多的前十个地区 country_movie_counts = country_movie_counts.sort_values(by='count',ascending=False)[:10] data = [[i['movie_area'],i['count']] for i in country_movie_counts.to_dict(orient='records')] return data # 统计票房前十的电影 def movie_booking_top10(df): # 按照票房数量进行排序并取出前十的数据 df = df.sort_values(by = 'movie_booking',ascending=False) movie_name_to_booking = df[['movie_name','movie_booking']][:10] data = [[i['movie_name'],i['movie_booking']] for i in movie_name_to_booking.to_dict(orient='records')] print(data) return data # 统计评论前十的电影 def movie_comment_top10(df): # 按照评论数量进行排序并取出前十的数据 df = df.sort_values(by = 'movie_comments',ascending=False) movie_name_to_booking = df[['movie_name','movie_comments']][:10] data = [[i['movie_name'],i['movie_comments']] for i in movie_name_to_booking.to_dict(orient='records')] print(data) return data # 统计不同评分区间的电影数量 def movie_score_count(df): # 根据不同区间划分电影评分数据 区间分别为 <7.0 7.0-8.0 >8.0 三个区间 grouped1 = df[df['movie_score']<7.0]['movie_score'] grouped2 = df[(df['movie_score']>=7.0) & (df['movie_score']<=8.0)]['movie_score'] grouped3 = df[df['movie_score']>8]['movie_score'] movie_score_to_count = [{'movie_score':'<7.0','count':len(grouped1)},{'movie_score':'7.0-8.0','count':len(grouped2)},{'movie_score':'>8.0','count':len(grouped3)}] data = [[i['movie_score'],i['count']] for i in movie_score_to_count] return data # 统计不同类型的电影数量最多的前十个类型 def movie_type_count(df): # 原数据中可能每个电影有多个电影类型 且不同电影类型之间使用点号分隔 因此将movie_type列数据以点号进行分隔变成列表 series_movie_type = df['movie_type'].str.split('·').tolist() movie_type_list = [j for i in series_movie_type for j in i] # 利用set函数的特性 当数据出现重复时 只保留一个数据 movie_type = set(movie_type_list) # 创建0矩阵统计不同电影类型的数量 zero_list = pd.DataFrame(np.zeros((len(df),len(movie_type))),columns=movie_type) for i in range(len(df)): zero_list.loc[i][series_movie_type[i]] = 1 # 使用聚合函数对不同类型的电影进行统计 movie_type_counts = zero_list.sum().astype(np.int) movie_type_counts = movie_type_counts.reset_index() movie_type_counts.columns = ['movie_type','count'] # 对数据进行排序并取出数量最多的前十个类型 movie_type_counts = movie_type_counts.sort_values(by='count',ascending=False)[:10] data = [[i['movie_type'],i['count']] for i in movie_type_counts.to_dict(orient='records')] return data if __name__ == '__main__': # 初始化MondoDB数据库 client = MongoClient() collection = client['test']['cat_movie'] # 获取数据 movies = collection.find({},{'_id':0}) df = pd.DataFrame(movies) # 打印基础信息 print(df.info()) print(df.head()) # 保留有用字段 df = df[['movie_name','movie_type','movie_area','movie_duration','movie_publish','movie_score','movie_comments','movie_booking']] # 过滤数据 # 过滤movie_type列数据 df = df[df['movie_type'].str.contains('类型未知')==False] # 过滤movie_area列数据 df = df[df['movie_area'].str.contains('上映国家未知')==False] # 过滤movie_duration列数据 df = df[df['movie_duration'].str.contains('电影时长未知') == False] # 过滤movie_publish列数据 df = df[df['movie_publish'].str.contains('上映时间未知') == False] # 过滤movie_score列数据 df = df[df['movie_score'].str.contains('电影评分未知') == False] # 过滤movie_comments列数据 df = df[df['movie_comments'].str.contains('评论人数未知') == False] # 过滤movie_booking列数据 df = df[df['movie_booking'].str.contains('暂无') == False] # 处理数据转换数据类型 # 去掉movie_duration列数据中的分钟并将数据转换成int数据类型 df['movie_duration'] = df['movie_duration'].apply(lambda x:int(re.findall(r'(\d+)分钟',x)[0])) # 将movie_score列数据转换成float类型 df['movie_score'] = df['movie_score'].apply(lambda x:float(x)) # 将movie_comments列数据统一单位 df['movie_comments'] = df['movie_comments'].apply(lambda x:int(float(re.findall(r'(.*)万',x)[0])*10000) if len(re.findall(r'万',x))>0 else int(x)) # 将movie_booking列数据统一单位 df['movie_booking'] = df['movie_booking'].apply(lambda x: float(re.findall(r'(.*)亿', x)[0]) if len(re.findall('亿', x)) > 0 else round(float(x.split('万')[0])/10000,2)) # 将movie_publish转换成pandas时间类型并将数据转换成具体的年添加到pd中 df['movie_publish'] = df['movie_publish'].apply(lambda x:re.findall(r'(.*)中国大陆上映',x)[0] if len(re.findall(r'中国大陆上映',x))>0 else x) df['movie_publish'] = pd.to_datetime(df['movie_publish']) date = pd.DatetimeIndex(df['movie_publish']) df['movie_publish_year'] = date.year # 不同年份上映的电影数量 # data = movie_date_publish_count(df) # 不同地区的电影上映数量最多的前十个地区 # data = movie_country_publish_top10(df) # 统计票房前十的电影 # data = movie_booking_top10(df) # 统计评论前十的电影 # data = movie_comment_top10(df) # 统计不同评分区间的电影数量 # data = movie_score_count(df) # 统计不同类型的电影数量最多的前十个类型 data = movie_type_count(df) # 创建数据库连接 conn = pymysql.connect(host='localhost',user='root',password='123456',port=3306,database='cateye',charset='utf8') # 获取游标对象 with conn.cursor() as cursor: # 不同年份上映的电影数量 # sql = 'insert into db_year_movie_count(year,count) values(%s,%s)' # 不同地区的电影上映数量最多的前十个地区 # sql = 'insert into db_area_movie_count(area,count) values(%s,%s)' # 统计票房前十的电影 # sql = 'insert into db_booking_movie_count(name,booking) values(%s,%s)' # 统计评论前十的电影 # sql = 'insert into db_comment_movie_count(name,comment) values(%s,%s)' # 统计不同评分区间的电影数量 # sql = 'insert into db_score_movie_count(score,count) values(%s,%s)' # 统计不同类型的电影数量最多的前十个类型 sql = 'insert into db_type_movie_count(type,count) values(%s,%s)' try: result = cursor.executemany(sql,data) if result: print('数据库插入数据成功') conn.commit() except pymysql.MySQLError as error: print(error) conn.rollback() finally: conn.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127
- 128
- 129
- 130
- 131
- 132
- 133
- 134
- 135
- 136
- 137
- 138
- 139
- 140
- 141
- 142
- 143
- 144
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- 156
- 157
- 158
- 159
- 160
- 161
- 162
- 163
- 164
- 165
- 166
- 167
- 168
- 169
- 170
- 171
- 172
- 173
- 174
- 175
- 176
- 177
- 178
- 179
- 180
- 数据库模型文件展示(models.py)
from . import db # 年份与上映电影数量模型 class YearMovieCount(db.Model): __tablename__ = 'db_year_movie_count' id = db.Column(db.Integer,primary_key=True,autoincrement=True) year = db.Column(db.String(64),nullable=False) count = db.Column(db.Integer,nullable=False) # 地区与上映电影数量前十模型 class AreaMovieCount(db.Model): __tablename__ = 'db_area_movie_count' id = db.Column(db.Integer,primary_key=True,autoincrement=True) area = db.Column(db.String(64),nullable=False) count = db.Column(db.Integer,nullable=False) # 票房前十电影模型 class BookingMovieCount(db.Model): __tablename__ = 'db_booking_movie_count' id = db.Column(db.Integer,primary_key=True,autoincrement=True) name = db.Column(db.String(64), nullable=False) booking = db.Column(db.Float, nullable=False) # 评论前十电影模型 class CommentMovieCount(db.Model): __tablename__ = 'db_comment_movie_count' id = db.Column(db.Integer,primary_key=True,autoincrement=True) name = db.Column(db.String(64),nullable=False) comment = db.Column(db.BigInteger,nullable=False) # 票房前十电影模型 class ScoreMovieCount(db.Model): __tablename__ = 'db_score_movie_count' id = db.Column(db.Integer,primary_key=True,autoincrement=True) score = db.Column(db.String(64),nullable=False) count = db.Column(db.Integer,nullable=False) # 类型与上映电影数量前十模型 class TypeMovieCount(db.Model): __tablename__ = 'db_type_movie_count' id = db.Column(db.Integer,primary_key=True,autoincrement=True) type = db.Column(db.String(64),nullable=False) count = db.Column(db.Integer,nullable=False)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 配置文件代码展示(config.py)
class Config(object): SECRET_KEY = 'ma5211314' SQLALCHEMY_DATABASE_URI = 'mysql://root:123456@localhost:3306/cateye' SQLALCHEMY_TRACK_MODIFICATIONS = True class DevelopmentConfig(Config): DEBUG = True class ProjectConfig(Config): pass # 采用映射方式方便后续调用配置类 config_map = { 'develop':DevelopmentConfig, 'project':ProjectConfig }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 主工程目录代码展示(api_1_0/_init_.py)
from flask import Flask import pymysql from flask_sqlalchemy import SQLAlchemy # python3的pymysql取代了mysqldb库 为了防止出现 ImportError: No module named ‘MySQLdb’的错误 pymysql.install_as_MySQLdb() from config import config_map db = SQLAlchemy() # 采用工厂模式创建app实例 def create_app(mode = 'develop'): app = Flask(__name__) config = config_map[mode] # 加载配置类 app.config.from_object(config) db.init_app(app) # 导入蓝图 from . import views app.register_blueprint(views.blue,url_prefix='/show') return app
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 主程序文件代码展示(manager.py)
from api_1_0 import create_app,db from flask_script import Manager from flask_migrate import Migrate,MigrateCommand from flask import render_template app = create_app() manager = Manager(app) Migrate(app,db) manager.add_command('db',MigrateCommand) # 首页视图函数 @app.route('/') def index(): return render_template('index.html') if __name__ == '__main__': manager.run()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 视图文件代码展示(api_1_0/views/_init_.py,show.py)
_init_.py
from flask import Blueprint
# 为了在主程序运行时能够加载到模型类
from api_1_0 import model
blue = Blueprint('show',__name__)
# 导入定义的视图函数
from . import show
- 1
- 2
- 3
- 4
- 5
- 6
- 7
show.py
from api_1_0.views import blue from api_1_0.model import db,AreaMovieCount,BookingMovieCount,CommentMovieCount,ScoreMovieCount,TypeMovieCount,YearMovieCount from flask import render_template ''' 将数据转换成列表的形式或者是列表嵌套字典的形式 locals()方法能够以字典的形式返回函数内所有声明的变量 ''' # 年份与上映电影数量折线图 @blue.route('/drawLine') def drawLine(): year_count = YearMovieCount.query.all() year = [i.year for i in year_count] count = [i.count for i in year_count] return render_template('drawLine.html',**locals()) # 票房前十电影柱状图和评论前十电影模型柱状图 @blue.route('/drawBar') def drawBar(): movie_booking = BookingMovieCount.query.all() booking_name = [i.name for i in movie_booking] new_booking_name = [] for i in booking_name: i = list(i) if len(i)>6: i.insert(len(i)//2,'\n') new_booking_name.append(''.join(i)) booking = [i.booking for i in movie_booking] movie_comment = CommentMovieCount.query.all() comment_name = [i.name for i in movie_comment] new_comment_name = [] for i in comment_name: i = list(i) if len(i) > 6: i.insert(len(i) // 2, '\n') new_comment_name.append(''.join(i)) comment = [i.comment//10000 for i in movie_comment] return render_template('drawBar.html',**locals()) # 地区与上映电影数量前十模型占比图和类型与上映电影数量前十模型占比图 @blue.route('/drawPie') def drawPie(): area_movie_count = AreaMovieCount.query.all() area_count = [{'name':i.area,'value':i.count} for i in area_movie_count] type_movie_count = TypeMovieCount.query.all() type_count = [{'name':i.type,'value':i.count} for i in type_movie_count] return render_template('drawPie.html',**locals()) # 不同评分区间电影数量占比图 @blue.route('/drawSignalPie') def drawSignalPie(): score_movie_count = ScoreMovieCount.query.all() score_count = [{'name':i.score,'value':i.count} for i in score_movie_count] return render_template('drawSignalPie.html',**locals())
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 主页展示(index.html)
主页简单创建了四个超链接指向对应的图表
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>首页说明</title> <style> .container{ width: 100%; height: 600px; padding: 40px; line-height: 60px; } ul{ margin: auto; width: 60%; } </style> </head> <body> <div class="container"> <ul> <li><a href="http://127.0.0.1:5000/show/drawLine" target="_blank"><h3>年份与上映电影数量折线图</h3></a></li> <li><a href="http://127.0.0.1:5000/show/drawPie" target="_blank"><h3>地区与上映电影数量前十模型占比图和类型与上映电影数量前十模型占比图</h3></a></li> <li><a href="http://127.0.0.1:5000/show/drawBar" target="_blank"><h3>票房前十电影柱状图和评论前十电影模型柱状图</h3></a></li> <li><a href="http://127.0.0.1:5000/show/drawSignalPie" target="_blank"><h3>不同评分区间电影数量占比图</h3></a></li> </ul> </div> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29

- 模板文件代码展示(drawBar.html,drawLine.html,drawSignalPie.html,drawPie.html)
drawBar.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>地区与上映电影数量前十模型占比图和类型与上映电影数量前十模型占比图</title> <script src="../static/js/echarts.min.js"></script> <script src="../static/theme/vintage.js"></script> <style> .cart-group{ display: flex; width: 100%; height: 600px; justify-content: space-between; } </style> </head> <body> <div class="cart-group"> <div class="cart1" style="width: 700px;height: 400px"></div> <div class="cart2" style="width: 700px;height: 400px"></div> </div> <script> var myCharts1 = echarts.init(document.querySelector('.cart1'),'vintage') var myCharts2 = echarts.init(document.querySelector('.cart2'),'vintage') var booking_name = {{ new_booking_name|tojson }} var booking = {{ booking|tojson }} var comment_name = {{ new_comment_name|tojson }} var comment = {{ comment|tojson }} function getOptions(category,data,title_text,desc,unit){ var option = { title:{ text:title_text, textStyle:{ fontFamily:'楷体', fontSize:21 } }, legend:{ name:[desc] }, xAxis:{ type:'category', data:category, axisLabel:{ interval:0, rotate:30, margin:16 } }, yAxis:{ type:'value', scale:true }, tooltip:{ trigger:'item', triggerOn:'mousemove', formatter:function(arg){ return '电影名称:'+arg.name+"<br>"+arg.seriesName+":"+arg.value+unit } }, series:[ { name:desc, type:'bar', data:data, label:{ show:true, position:'top', rotate:30, distance:10 } } ] } return option } var option1 = getOptions(booking_name,booking,'票房前十电影柱状图','电影票房','亿') var option2 = getOptions(comment_name,comment,'评论前十电影柱状图','电影评论','万') myCharts1.setOption(option1) myCharts2.setOption(option2) </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
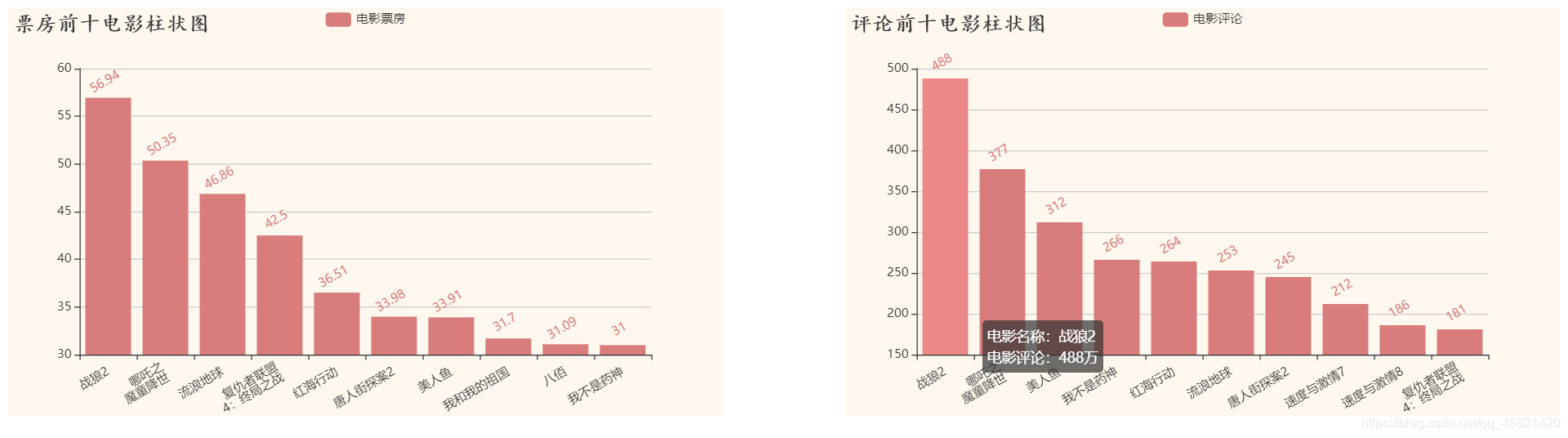
结论:
战狼2无论是票房还是评论数都稳居第一,电影票房一般和电影评论成正比,电影票房的高低在一定程度上反映电影评论的多少。
drawLine.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>年份与上映电影数量折线图</title> <script src="../static/js/echarts.min.js"></script> <script src="../static/theme/vintage.js"></script> </head> <body> <div class="cart" style="width: 1000px;height: 600px;margin: auto"></div> <script> var myCharts = echarts.init(document.querySelector('.cart'),'vintage') var year = {{ year|tojson }} var count = {{ count|tojson }} var option = { title:{ text:'年份与上映电影数量折线图', textStyle:{ fontFamily:'楷体', fontSize:21 } }, legend:{ name:['电影年份数量变化'] }, xAxis: { type: 'category', data: year, axisLabel: { interval: 0, rotate: 40, margin: 10 } }, yAxis:{ type:'value', scale:true }, tooltip:{ trigger:'axis', triggerOn:'mousemove', formatter:function(arg) { return '上映年份:'+arg[0].name+"<br>"+'电影数量:'+arg[0].value } }, series:[ { name:'电影年份数量变化', type:'line', data:count, label:{ show:true, rotate: 40 }, smooth:true, markLine:{ data:[ { name:'平均值', type:'average', label: { formatter:function(arg) { return arg.name+':\n'+Math.ceil(arg.value) } } } ] }, markPoint:{ data:[ { name:'最大值', type:'max', label:{ show: true, formatter:function (arg) { return arg.name } }, symbolSize:[40,40],//容器大小 symbolOffset:[0,-20] }, { name:'最小值', type:'min', label:{ show: true, formatter:function (arg) { return arg.name } }, symbolSize:[40,40],//容器大小 symbolOffset:[0,-20] } ] } } ] } myCharts.setOption(option) </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
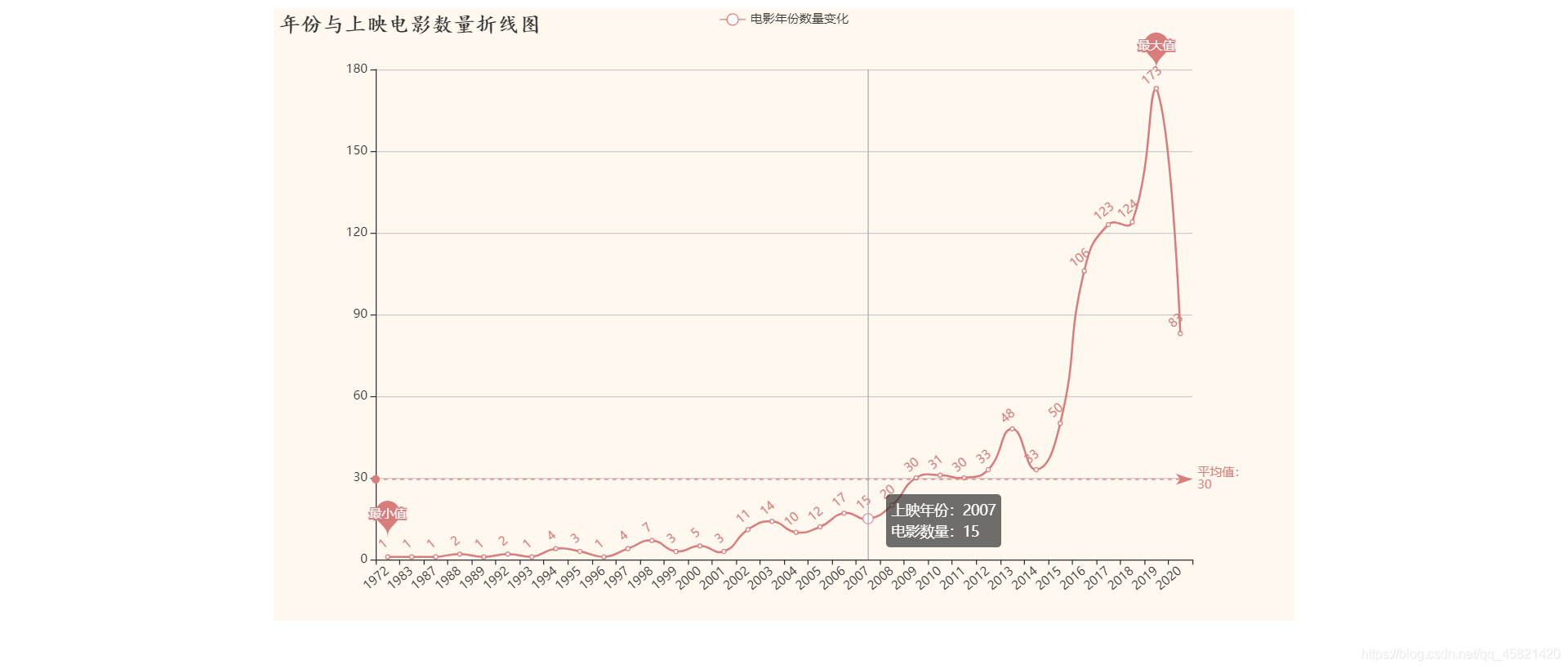
结论:
年份与电影上映数量成正比,电影上映数量随时间的增长而增加,而2020年由于疫情原因,使得电影上映数量同比上一年较低。
drawPie.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>工作经验与薪资关系图&学历与薪资关系图</title> <script src="../static/js/echarts.min.js"></script> <script src="../static/theme/dark.js"></script> <script src="../static/theme/my_theme.js"></script> <script src="../static/theme/vintage.js"></script> <style> .chart-group{ width: 100%; height: 1000px; padding: 50px; display: flex; justify-content: space-evenly; margin: auto; } .chart1{ width: 600px; height: 400px; } .chart2{ width: 600px; height: 400px; } </style> </head> <body> <div class="chart-group"> <div class="chart1"></div> <div class="chart2"></div> </div> <script> // 初始化echarts var myCharts1 = echarts.init(document.querySelector('.chart1'),'vintage') var myCharts2 = echarts.init(document.querySelector('.chart2'),'vintage') // 获取视图函数传入数据并转换成json格式 var wel_count = {{ wel_count|tojson }} var edu_count = {{ edu_count|tojson }} var value = [] function getOption(data,desc){ var option = { title:{ text : desc, textStyle:{ fontFamily:'楷体', fontSize:21 }, }, tooltip:{ trigger:'item', triggerOn:'mousemove', formatter:function(rst){ if(desc=="工作经验的人数分布图"){ return '福利类型:'+rst.name+'<br>'+'企业数量:'+rst.value+'个'+'<br>'+'占比:'+rst.percent+"%" }else{ return '学历:'+rst.name+'<br>'+'所需岗位:'+rst.value+'人'+'<br>'+'占比:'+rst.percent+"%" } } }, legend:{ name:['人数占比'], orient: 'vertical', bottom:10, right:10, }, series:[ { name:'人数占比', type:'pie', data:data, label:{ show:true }, roseType:'radius', selectedMode:'multiple', selectedOffset: 10 } ] } return option } var option1 = getOption(wel_count,'福利类型数量前十占比') var option2 = getOption(edu_count,'学历人数占比图') myCharts1.setOption(option1) myCharts2.setOption(option2) </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
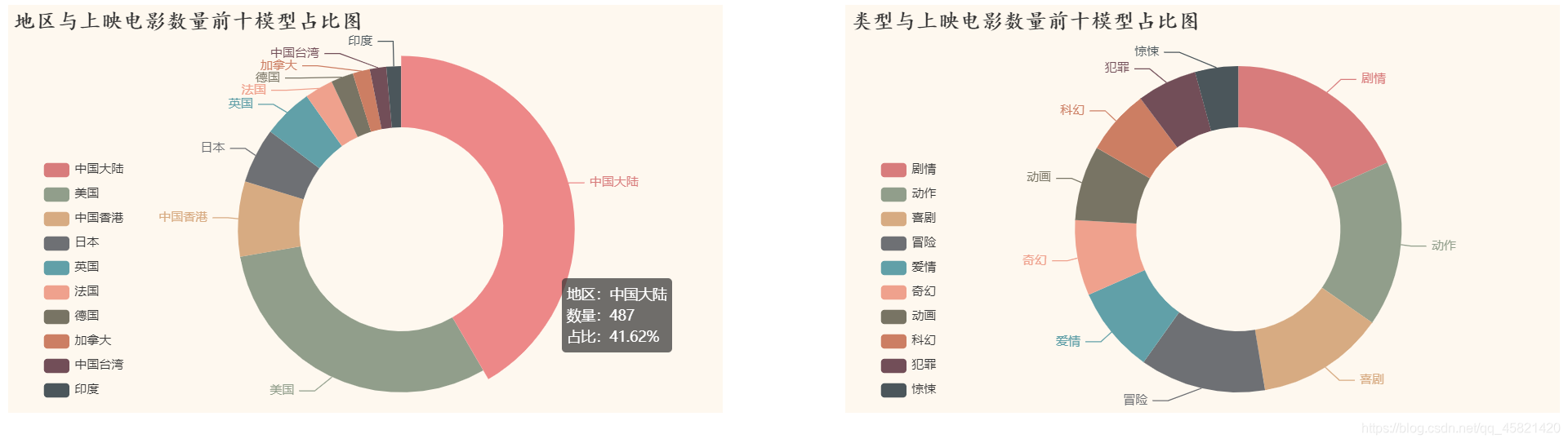
结论:
中国大陆电影上映数量占40%左右,中国电影上映数量占全国电影数量的一半左右;电影类型主要以剧情、喜剧、动作为主,占总电影类型的一半左右。
drawSignalPie.html
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>不同评分区间电影数量占比图</title> <script src="../static/js/echarts.min.js"></script> <script src="../static/theme/vintage.js"></script> </head> <body> <div class="cart" style="width: 1000px;height: 600px;margin: auto"></div> <script> var myCharts = echarts.init(document.querySelector('.cart'),'vintage') data = {{ score_count|tojson }} var option = { title:{ text:'不同评分区间电影数量占比图', textStyle:{ fontFamily:'楷体', fontSize:21 } }, tooltip:{ trigger:'item', triggerOn:'mousemove', formatter:function (arg) { return '评分:'+arg.name+'<br>'+'数量:'+arg.value+'<br>'+'占比:'+arg.percent+'%' } }, series:[ { name:'电影评分', type:'pie', data:data, label:{ show:true, formatter:function (arg) { return arg.seriesName+':'+arg.name } }, roseType:'radius', selectedMode:'multiple', selectedOffset:20 } ] } myCharts.setOption(option) </script> </body> </html>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
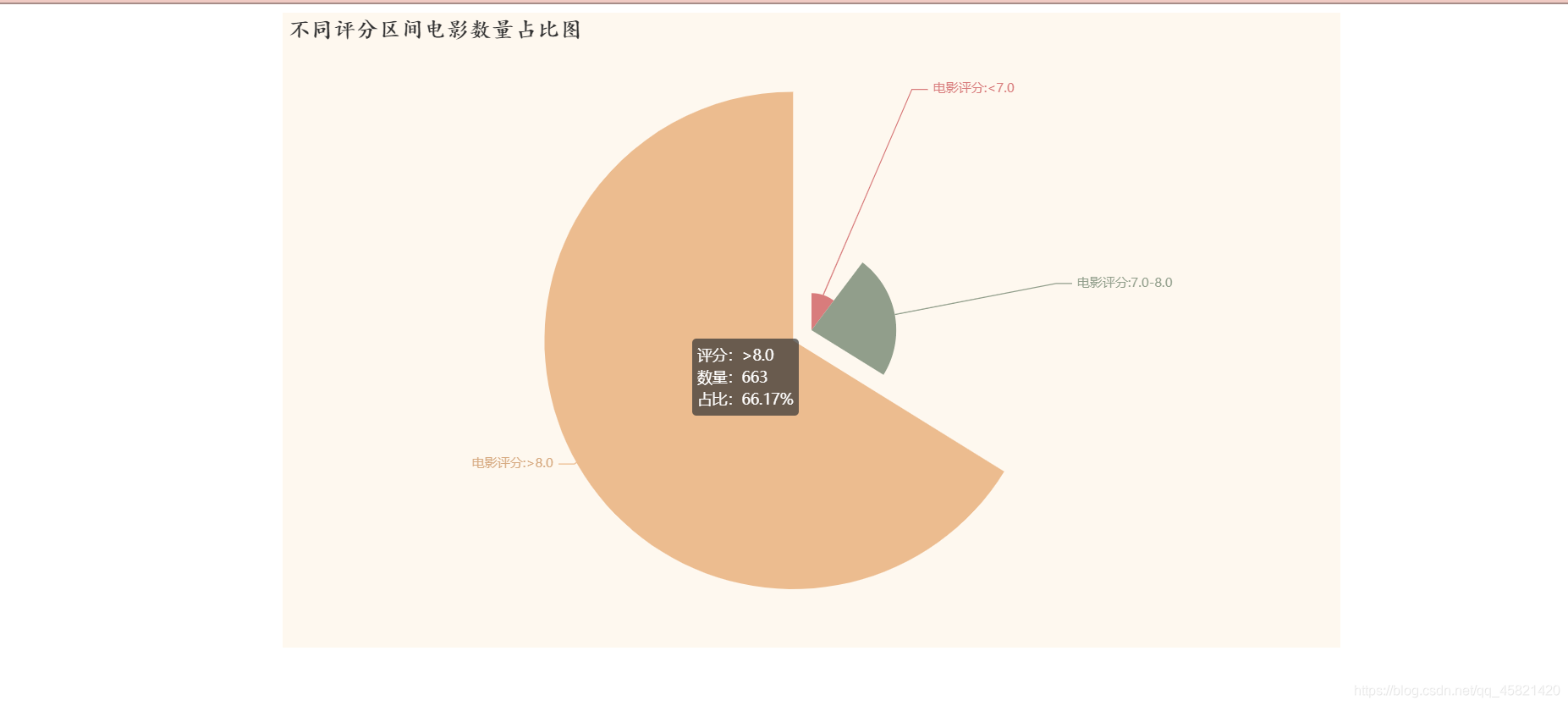
结论:
电影评分主要在8.0分以上,占总上映电影的六成以上,上映的电影水平普遍很高
以下是项目源码,希望能够帮助你们,如有疑问,下方评论
flask项目代码链接
 文章浏览阅读1.5w次,点赞124次,收藏198次。Pygame是一个基于Python的游戏开发库,它提供了一系列的工具和接口,使开发人员能够轻松地创建各种类型的游戏,包括2D游戏和简单的3D游戏。Python“贪吃蛇”游戏,在不断改进中学... [详细]
文章浏览阅读1.5w次,点赞124次,收藏198次。Pygame是一个基于Python的游戏开发库,它提供了一系列的工具和接口,使开发人员能够轻松地创建各种类型的游戏,包括2D游戏和简单的3D游戏。Python“贪吃蛇”游戏,在不断改进中学... [详细]赞
踩
- 文章浏览阅读6.5k次,点赞46次,收藏39次。FastAPI库(Python的Web框架)基本使用指南(二)FastAPI库(Python的Web框架)基本使用指南(二)核心功能定义路由FastAPI中定义路由的方式主要有两种,一种是使用... [详细]
赞
踩
- 文章浏览阅读3k次,点赞4次,收藏16次。Python是一种高级编程语言,它具有简单、易学、高效等特点。而Pythonget()函数是其中一个重要的函数。该函数用于返回指定键的值,如果键不存在,则返回默认值None。下面将从各个方面对Pyt... [详细]
赞
踩
- 文章浏览阅读1.1w次,点赞55次,收藏66次。本文仅分享Githack工具基本安装及使用相关知识不承担任何法律责任。Git是一个非常流行的开源分布式版本控制系统,它被广泛用于协同开发和代码管理。许多网站和应用程序都使用Git作为其代码管理... [详细]
赞
踩
- 文章浏览阅读6.9k次,点赞46次,收藏122次。get()是获取网页最常用的方式,在调用requests.get()函数后,返回的网页内容会保存为一个Response对象,其中,get()函数的参数url必须采用HTTP或HTTPS方式访... [详细]
赞
踩
- 文章浏览阅读1.5k次,点赞44次,收藏46次。6.2.4修改字典中的值要修改字典中的值,可依次指定字典名、用方括号括起的键以及与该键相关联的新值。我们首先定义了一个表示外星人alien_0的字典,其中只包含这个外星人的颜色。接下来,我们将... [详细]
赞
踩
- 文章浏览阅读3.8k次。本文介绍了Django框架中文件上传和处理的基本原理和实现方法,以及阿里云oss的对接方法。Django提供了一些内置的功能和工具,使文件上传变得简单和安全。它提供了一个处理文件上传的高级API,可以验证上传的文件... [详细]
赞
踩
- 文章浏览阅读1k次,点赞80次,收藏72次。本文主要介绍了集合和字典相关的知识,其中集合最大的特点就是无序和无重复,有三个特殊的操作,取出差集,消除差集,集合合并;字典最大的特点就是每个数据都是KeyValue键值对,且Key不可重复【Py... [详细]
赞
踩
- 文章浏览阅读4.4k次,点赞41次,收藏263次。深入探索Python的Pandas库:从核心数据结构到高级特性,本指南为你提供了全面的Pandas知识概览。无论你是数据初学者还是专家,都可在此找到宝贵的insights和技巧,助力你的数据... [详细]
赞
踩
- 文章浏览阅读2k次,点赞104次,收藏87次。OpenCV(OpenSourceComputerVisionLibrary)是一个开源的计算机视觉库,提供了丰富的图像处理和计算机视觉算法。它由一组用C++编写的函数和工具组成,同时也支持多种... [详细]
赞
踩
- 文章浏览阅读1.1w次,点赞43次,收藏270次。python-爬虫(可直接使用)python-爬虫(可直接使用)爬虫(WebScraping)是指通过编程自动化地获取互联网上的信息的过程。爬虫的目的通常是从网页中抓取数据,进行数据分析、处... [详细]
赞
踩
- 文章浏览阅读1.5k次,点赞8次,收藏12次。MAE的误差大概在0.11,以下数据均是预测未知数据。Holt-Winters模型,也称为三重指数平滑模型,是一种经典的时间序列预测模型,用于处理具有趋势和季节性的时间序列数据。Holt-Win... [详细]
赞
踩
- article
Unable to create process using ‘D:\Anaconda3\python.exe D:\Anaconda3\Scripts\conda-script.py shell.c
文章浏览阅读1w次,点赞20次,收藏17次。记录一下和Anacondaprompt斗智斗勇的一天,早上打开电脑,准备用prompt打开jupyter写点东西,结果人傻啦,报错无法启动进程。。。注意是先报错,后进入起始位置可以输入cmd指令,... [详细]赞
踩
 文章浏览阅读5.6k次,点赞2次,收藏12次。在“installcsvba”这个文件夹中新建一个名为“template”的文件夹,其中存放着所有csv文件的二进制文件,比如:接下来,我们以“installcsvba”这个工程为例,来介绍一下... [详细]
文章浏览阅读5.6k次,点赞2次,收藏12次。在“installcsvba”这个文件夹中新建一个名为“template”的文件夹,其中存放着所有csv文件的二进制文件,比如:接下来,我们以“installcsvba”这个工程为例,来介绍一下... [详细]赞
踩
- 文章浏览阅读4.1k次,点赞95次,收藏100次。维诺图的应用涵盖了多个领域,包括计算机图形学、地理信息系统、计算机视觉等。本文介绍维诺图在运动规划中的概念,并结合C++/Python/Matlab三种实现加深理解,为后续基于维诺图的路径规... [详细]
赞
踩
- 文章浏览阅读5.5k次,点赞123次,收藏181次。上述代码完成了一个简单的情感分析任务。根据具体需求和数据集,您可能需要调整预处理步骤、特征提取方法和支持向量机参数。此外,还可以尝试使用其他机器学习算法,如神经网络、决策树、随机森林等,以... [详细]
赞
踩
- 文章浏览阅读6.9k次,点赞26次,收藏138次。LSTM(LongShort-TermMemory)是一种常用的循环神经网络(RNN)模型,用于处理序列数据,具有记忆长短期的能力。在时间序列预测中,LSTM既可以多元预测机制又可以作为单元... [详细]
赞
踩
- 文章浏览阅读1.1k次。SegmentAnything可以实现对任意物体的识别和分割提供了简单易用的接口,用户只需要通过提示,即可进行物体识别和分割操作,今天给大家分享一下SAM的源码。【Python&语义分割】SegmentAnythin... [详细]
赞
踩
- 文章浏览阅读4.3w次,点赞291次,收藏1.3k次。本文一步一步地教你如何用Pyinstaller模块将Python程序打包成exe文件!这篇教程绝对是全网最全面、最详细的教程!包含五种打包的方法,从简单到复杂依次是:一般打包方法、虚拟环... [详细]
赞
踩
- 文章浏览阅读2.4w次,点赞62次,收藏642次。PythonCNN卷积神经网络实例讲解,CNN实战,CNN代码实例,套用简单_pythoncnnpythoncnn一、CNN简介1.神经网络基础输入层(Inputlayer),众多神经元(N... [详细]
赞
踩

