
热门标签
热门文章
- 1读写配置文件(.congfig)步骤,web.config_congfig.bin文件查看
- 2Spring Security 学习笔记(六)--OAuth2.0_spring-security-oauth2-autoconfigure
- 3C语言生成随机数的方法_c语言随机数
- 42020年美国大学生数学建模竞赛E题淹没在塑料里解题全过程文档及程序_2020美赛e题用的模型
- 5Unity编辑器扩展: GUILayout、EditorGUILayout 控件整理_editorguilayout.popup
- 6Python使用ChatGPT的主要方法_python调用chatgpt
- 7Python 程序的输出 | 第一套_python程序输出结果
- 8Scala学习笔记(12)—集合(三)—列表List_scala 创建list
- 9用Python让蔡徐坤在我的命令行里打篮球~技术流追星!
- 10模态弹窗与非模态弹窗_模态弹窗和非模态弹窗
当前位置: article > 正文
爬虫工作量由小到大的思维转变---<第三十四章 Scrapy 的部署scrapyd+Gerapy>_gerapy如何登录
作者:程序诗人 | 2024-01-29 13:29:49
赞
踩
gerapy如何登录
前言:
scrapy-redis没被部署,感觉讲起来很无力;因为实在编不出一个能让scrapy-redis发挥用武之地的案子;所以,索性直接先把分布式爬虫的部署问题给讲清楚!! 然后,曲线救国式地再在部署的服务器上,讲scrapy redis我感觉这样才好!
正文:
现在还有不少人在用scrapy web进行爬虫管理,但我个人感觉是那玩意儿BUG挺多的;且不灵光!
而Gerapy和scrapy web都是基于scrapyd的,所以 我直接省去了去讲scrapy web的知识点,推荐这个Gerapy;当然了,还有其他的, 例如:"crawlab",也是用于爬虫管理的,你就忽悠忽悠老板,措辞我都给你想好了:' 这玩意儿老好了,真的,先进单位都在用~嘎嘎香;谁用谁知道,贼牛逼!! '-----让他给你买!
比较:Gerapy 和 Scrapy Web
都是用于构建和管理 Scrapy 爬虫项目的工具,但它们有一些区别:
- 1. 功能和用途:Gerapy 是一个全面的 Scrapy 爬虫项目管理平台,提供了完整的爬虫项目管理、任务调度、监控和部署等功能。它不仅提供了界面化的项目管理工具,还支持多用户、权限管理和插件扩展等特性。而 Scrapy Web 是一个基于 Scrapy 的 Web 组件,可为 Scrapy 提供一个可视化界面,用于监控和管理爬虫的运行状态。
- 2. 界面和可视化:Gerapy 提供了强大的 Web 界面,以图形化和交互式的方式来管理爬虫项目。它提供了项目、爬虫、调度、日志等各个方面的可视化管理界面。而 Scrapy Web 则主要关注在爬虫任务的监控和管理方面,提供了简化的可视化界面来查看爬虫的运行状态、调度任务以及查看日志等。
- 3. 插件扩展:Gerapy 支持插件扩展,你可以为 Gerapy 添加自定义的功能和工具。它提供了开放的插件接口,允许你开发和集成自己的插件。而 Scrapy Web 没有插件扩展的功能,主要关注于提供爬虫任务的可视化管理和监控功能。
- 总结来说,Gerapy 是一个功能强大、全面的 Scrapy 爬虫项目管理平台,提供了项目管理、任务调度、监控和部署等多个方面的功能,并支持插件扩展。Scrapy Web 则更专注于提供可视化界面来监控和管理爬虫的运行状态和调度任务.
废话不多说,讲我们的:
安装:
1.创建项目文件(这我就不废话了,mkdir一个文件夹)
2.配置虚拟环境(这我也不废话了,搞个环境依赖包)
3.安装依赖包(python随便升,没问题;我目前py==3.11.X)
- pip install scrapy==2.9.0
-
- pip install scrapyd
-
- #可自定义要不要按scrapy-redis,上面两个就是环境必须给他装的! 我推荐scrapy装2.9.0,
- #别升高了!!原因我前文讲过
-
- pip install gerapy
-
- #pip install gerapy_auto_extractor
-
前文链接:爬虫工作量由小到大的思维转变---<第三十三章 Scrapy Redis 23年8月5日后会遇到的bug)>-CSDN博客
-
关于:gerapy_auto_extractor(要不要安,随便你们,这个无所谓的)
- gerapy_auto_extractors 是一个用于实现自动提取器(Auto Extractors)功能的 Python 包。它是基于 Gerapy 平台(一个用于构建和管理 Scrapy 爬虫项目的框架)开发的一个插件。
- 自动提取器是一种用于从网页中自动提取数据的功能。通过配置自动提取器规则,可以指定数据应该如何从 HTML 或其他文档中提取出来,而无需手动编写解析规则。gerapy_auto_extractors 提供了一套规则配置和数据提取的功能,以方便开发人员通过简单的配置来直接提取数据。
- 使用 gerapy_auto_extractors,你可以轻松地配置自动提取器规则,而无需手动编写 XPath 或其他解析规则。该包还支持在 Gerapy Web 界面中进行规则配置和管理。
- ps:为了使用 gerapy_auto_extractors,你需要首先安装 Gerapy 平台,并将 gerapy_auto_extractors 作为其插件进行安装和启用。
4.初始化gerapy
进入到项目文件夹内,控制台:
- cd <你的项目文件夹内>
- gerapy init
初始化完成,出现: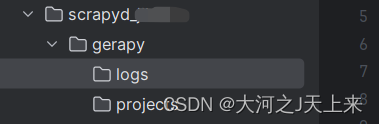
5.创建`数据库迁移文件`
在文件内部:
gerapy migrate 出现对应的: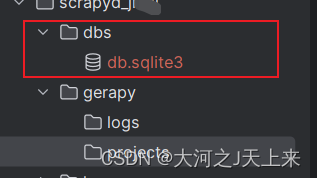 表示成功!
表示成功!
讲解:
gerapy migrate 命令的主要用途是将数据库结构与 Gerapy 项目的模型定义同步。它提供了以下几个重要的用途和好处:
- 数据库迁移管理:gerapy migrate 命令使得数据库迁移变得简单和可控。通过捕捉模型定义的变化,并生成对应的迁移文件,可以轻松地管理数据库表结构的变更和演进。
- 模型变更应用:当你在 Gerapy 项目中创建、修改或删除模型(Model)定义时,gerapy migrate 命令可以自动应用这些变更到数据库中。它负责生成并执行相应的迁移操作,确保表结构与模型定义保持一致。
- 数据库版本控制:通过 gerapy migrate 命令生成的迁移文件,可以方便地进行数据库版本控制。你可以使用 Git 或其他版本控制系统来管理这些迁移文件,以便记录和追踪数据库结构的变化。
- 多环境部署:针对不同的环境(例如开发环境、测试环境、生产环境),你可以使用 gerapy migrate 命令为每个环境执行相应的数据库迁移操作。这样可以确保不同环境的数据库表结构与模型定义保持一致,避免了手动维护多个数据库的麻烦。
6.初始化Gerapy 平台的管理员账户
gerapy initadmin
他会自动生成一个临时的管理员账户,如图:
7.启动 Web 服务器
- gerapy runserver 0.0.0.0:8000 #接受全部的ip,端口自定义
- #或者
-
- gerapy runserver 127.0.0.1:8080 #在本地地址绑定到端口 8080 上
图例:
8.登录gerapy
网络页面(没服务器部署前,用本地127.0.0.1登录):
在浏览器输入: 127.0.0.1:8000
弹出页面:
(第一次登录)输入用户名:admin 密码:admin
登录成功!

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/43104
推荐阅读
- 使用scrapy对接selenium完成对动态网站的爬取_scrapyseleniumscrapyselenium最近学习了scrapy爬虫框架,想要找个目标练练手。由于现在很多网页都是动态的,因此还需要配合selenium爬取。本文旨在记... [详细]
赞
踩
- 如果您需要手动启动传输,或者需要在某个特定时间点执行代码,则可能需要使用close_spider方法。数据保存到redis后,在爬虫结束方法退出driver,否则下次再跑就会报502超时链接不到dockerselenium的driver,因... [详细]
赞
踩
- 在spiders文件中写如下:custom_settings={‘DOWNLOAD_DELAY’:0.2,‘CONCURRENT_REQUESTS_PER_IP’:4,‘DOWNLOADER_MIDDLEWARES’:{},}_scrapy... [详细]
赞
踩
- 是用来导入Scrapy框架内置的中间件类。这个中间件类用于处理请求的重试逻辑,当请求失败或遇到特定的异常时,可以根据配置的参数进行自动重试。在Scrapy-Redis中,你可以根据需要使用增加请求重试次数:通过修改设置项来增加请求的最大重试... [详细]
赞
踩
- 详细介绍scrapy核心组件spider,middlewareitempipeline的使用,代码复用度高,示例可拓展开发。scrapy框架核心知识Spider,Middleware,ItemPipeline,scrapy项目创建与启动,S... [详细]
赞
踩
- 终于找到机会,开始把scrapy-redis细致地给大伙通一通了!为什么非要细致讲scrapy-redis呢?1.市面上关于scrapy-redis的教程,都比较笼统;demo级别好写,但是一旦上了项目,就问题百出!2.scrapy-red... [详细]
赞
踩
- 重点在读connection.py的源码,这个组件主要是用来连接的;因为连接都无法做到,后面想更改点自定义就白扯了;该函数从Scrapy的设置对象中获取Redis客户端实例。它使用get_client来实例化客户端,并使用默认参数值defa... [详细]
赞
踩
相关标签

