
- 1HarmonyOS系统中内核实现烟雾检测的方法_smoke 内核编译
- 2【毕业季|进击的技术er】作为一名职场人,精心总结的嵌入式学习路线图
- 3【PaLM2】PaLM2 大语言模型与 Bard 使用体验
- 4TCP的三个窗口:发送窗口swnd、接收窗口rwnd、拥塞窗口cwnd_tcp发送窗口
- 5国内手机安装 Google Play 服务 (GMS/Google Mobile Services)_国内安卓如何安装google play csdn
- 6用Python编写的小游戏:探索游戏世界的乐趣_python制作小游戏
- 7C++ find函数详解_c++ find
- 8【就业必备知识】大学毕业如何处理档案和户口,小心变成死档和黑户_毕业户口没转出会变成黑户吗
- 9【愚公系列】2023年12月 HarmonyOS应用开发者高级认证(完美答案)_【愚公系列】2023年12月 harmonyos应用开发者高级认证(完美答案
- 10[MySQL] SQL优化之性能分析
【Scrapy学习心得】爬虫实战五(Scrapy-Redis分布式爬虫)_scrapy爬虫框架心得
赞
踩
【Scrapy学习心得】爬虫实战五(Scrapy-Redis分布式爬虫)
声明:仅供技术交流,请勿用于非法用途,如有其它非法用途造成损失,和本博客无关
前言
- 分布式爬虫:即多台机器同时爬取一个或多个网站,每台机器的爬虫代码基本相同,换句话说就是在一台机器上开发爬虫代码,开发完成后将其上传到其他的机器上,它们所请求的url队列是共享的,它们共同完成这一整个url队列的爬取,从而实现分布式。
- Scrapy框架本身并不支持分布式,它是单机的,而实现分布式其实就是将一台机上所需要请求的url全部共享出来,让多台机器共同去完成爬取。这个我们也可以不用自己来实现,可以通过现有的别人已经写好的框架来实现分布式,它就是本文的主角:Scrapy-Redis
- Redis是完全开源免费的,遵守BSD协议的,一个高性能的key-value数据库。它在这里的作用主要是用来存储共享url队列,还可以用于url去重以及存储数据。
废话不多说,直接开始吧~
本次爬取的网站是:点击跳转
一、基本配置
- 一台master机,一台slave机,本文使用的master是云服务器(Ubuntu),而slave是我的笔记本电脑(Windows)
- 两台机都需要安装Python3.7、Scrapy框架、Scrapy-Redis框架
- 在master机上安装Redis数据库,并配置好能够远程连接等等
二、分析页面
我们随便筛选几个条件搜索一下,发现了这个列表页的url是存在一定规律的:
例如:筛选的条件为广东的18岁以上的mm:
http://www.youyuan.com/find/guangdong/mm18-0/advance-0-0-0-0-0-0-0/p1/
- 1
例如:筛选的条件为广东的18岁至25岁的mm:
http://www.youyuan.com/find/guangdong/mm18-25/advance-0-0-0-0-0-0-0/p1/
- 1
其次,按F12打开开发者工具,然后可以看到这一列表页上的所有信息都在<ul class="mian search_list">下的<li>当中,并且可以发现详情页的url就在a标签里面。
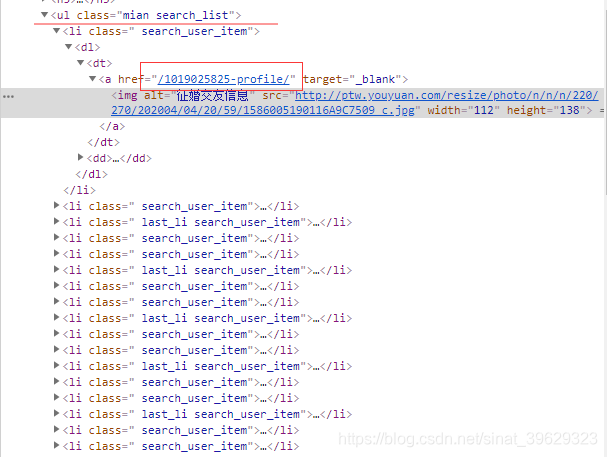
拿到了详情页的url后,接下来就是翻页的url,以及什么时候停止翻页了,我们将页面滚动到最低端,找到>这个翻页的按钮,可以发现其href属性就是翻页的url。并且还发现了,当不能进行翻页时,这个herf属性的值变成了###。

接下来,进入详情页里面获取我们需要的信息了。发现html的结构还是很有规则的,很容易就能获取到所需要的信息。(这里就不多讲了,详情请看代码以及注释即可)

三、获取的信息
全国所有城市中18岁以上的mm,这个页面里包含了所有城市对应的部分url链接,用于拼接搜索条件的具体的url链接即可。
- 昵称、年龄、收入、相册等
- 内心独白
- 详细资料
- 征友条件
四、开始敲代码
首先创建Scrapy爬虫项目:scrapy startproject youyuan
然后再创建爬虫文件:cd youyuan && scrapy genspider yy youyuan.com
最后开始敲代码
(一)原始Scrapy框架下的爬虫代码(非分布式)
items.py 代码如下:
from scrapy import Item, Field
class YouyuanItem(Item):
name=Field() #姓名
address = Field() #地址
age = Field() #年龄
height = Field() #身高
salary = Field() #收入
house = Field() #房子
hobby = Field() #爱好
image = Field() #照骗
motto = Field() #内心独白
detail = Field() #详细资料
boy_condition = Field() #男友标准
url=Field() #个人主页
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
pipelines.py 代码如下:(开发阶段只先输出一下,没有特别的地方)
# -*- coding: utf-8 -*-
# Define your item pipelines here
class YouyuanPipeline(object):
def process_item(self, item, spider):
if spider.name == 'yy':
print(item)
return item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
yy.py 代码如下:
# -*- coding: utf-8 -*- import scrapy from youyuan.items import YouyuanItem import re # 这个函数是用于处理详细资料和征友条件的,返回一个字典 def process_data(data): key = data[::2] value = [re.sub(' ','',i) for i in data[1::2]] return dict(zip(key, value)) class YySpider(scrapy.Spider): name = 'yy' allowed_domains = ['youyuan.com'] start_urls = ['http://www.youyuan.com/city/'] def parse(self, response): # 构造每个城市中的18岁以上的mm请求url base_url = 'http://www.youyuan.com/find{0}mm18-0/advance-0-0-0-0-0-0-0/p1/' a_list=response.xpath('//div[@class="yy_city_info"]/ul/li/font/a') for a in a_list: yield scrapy.Request( base_url.format(a.xpath('./@href').get()), callback=self.parse_all, priority=3 ) def parse_all(self, response): # 拿到列表页中所有mm的详情页url li_list = response.xpath('//ul[@class="mian search_list"]/li') for li in li_list: detail_url = response.urljoin(li.xpath('./dl/dt/a/@href').get()) yield scrapy.Request( detail_url, callback=self.parse_item, priority=1 ) # 若有下一页,则继续发起请求 temp = response.xpath('//a[@class="pe_right"]/@href').get() if temp != '###': next_page = response.urljoin(temp) yield scrapy.Request( next_page, callback=self.parse_all, priority=2 ) def parse_item(self, response): # 详情页里爬取mm的所有想要的信息 # 判断是否已经进入了详情页,有一些页面会重定向到首页,从而会报错的 flag=response.xpath('//p[@class="top_tit"]') if flag: item=YouyuanItem() item['name'] = response.xpath('//div[@class="main"]/strong/text()').get() # 姓名 temp=response.xpath('//p[@class="local"]/text()').get().split() item['address'] = temp[0] # 地址 item['age'] = temp[1] # 年龄 item['height'] = temp[2] # 年龄 item['salary'] = temp[3] # 收入 item['house'] = temp[4] # 房子 item['hobby'] = [i.strip() for i in response.xpath('//ol[@class="hoby"]/li//text()').getall()] # 爱好 item['image'] = response.xpath('//li[@class="smallPhoto"]/@data_url_full').getall() # 照骗 item['motto'] = response.xpath('//ul[@class="requre"]/li[1]/p/text()').get().strip() # 内心独白 item['detail'] = process_data(response.xpath('//div[@class="message"]')[0].xpath('./ol/li//text()').getall()) # 详细资料 item['boy_condition'] = process_data(response.xpath('//div[@class="message"]')[1].xpath('./ol/li//text()').getall()) # 男友标准 item['url'] = response.url # 个人主页 return item

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
settings.py 代码如下:
# -*- coding: utf-8 -*- # Scrapy settings for youyuan project BOT_NAME = 'youyuan' SPIDER_MODULES = ['youyuan.spiders'] NEWSPIDER_MODULE = 'youyuan.spiders' # 日志级别 LOG_LEVEL='DEBUG' # 用户代理 USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36' # Obey robots.txt rules ROBOTSTXT_OBEY = False # 下载延迟 DOWNLOAD_DELAY = 0.5 # pipeline管道 ITEM_PIPELINES = { 'youyuan.pipelines.YouyuanPipeline': 300, }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
(二)Scrapy-Redis(分布式爬虫)
其实应用Scrapy-Redis框架来写分布式爬虫,只需要在原始Scrapy框架下的爬虫代码里修改一部分代码即可。
- yy.py 代码修改或增加如下:(引入RedisSpider;并修改继承的类;去掉start_urls;增加redis_key),其他代码不变
from scrapy_redis.spiders import RedisSpider
# class YySpider(scrapy.Spider):
class YySpider(RedisSpider):
name = 'yy'
allowed_domains = ['youyuan.com']
# start_urls = ['http://www.youyuan.com/city/']
redis_key = 'yy:start_urls'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- settings.py 代码修改如下:(增加与redis相关的配置)
# 去重 DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter" # 调度器 SCHEDULER = "scrapy_redis.scheduler.Scheduler" # 优先级队列(以下3个随便选一个) # SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderPriorityQueue" SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderQueue" #SCHEDULER_QUEUE_CLASS = "scrapy_redis.queue.SpiderStack" # 允许暂停 SCHEDULER_PERSIST = True # Redis连接 REDIS_HOST = 'master机的ip地址' REDIS_PORT = 6379 REDIS_PARAMS = {'password':'redis设置的密码'} # 没有配置密码的话可以去掉 # 并发请求数量(默认是16,若不更改小一点的话,会出现有一台机一直处于等待状态) CONCURRENT_REQUESTS = 2 # pipeline管道(开启redis的管道) ITEM_PIPELINES = { 'youyuan.pipelines.YouyuanPipeline': 300, 'scrapy_redis.pipelines.RedisPipeline': 400, }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
五、运行分布式爬虫项目
首先,在master机上开启redis服务端,即在控制台运行命令:redis-server,或者以指定配置文件的方式来启动:redis-server /etc/redis/redis.conf
然后,在master机上的另一个终端上进入redis客户端,即在控制台运行命令:redis-cli,之后如果你的redis设置了密码,那么再输入:auth 你的密码,然后才能继续操作redis数据库
再者,分别运行两台机的爬虫项目(不分先后,随意即可),运行的命令是:scrapy crawl yy(在有scrapy.cfg文件的目录下进入cmd命令),此时两台机都是处于监听的状态中
最后,在master机的redis客户端中,输入:lpush yy:start_urls http://www.youyuan.com/city/,之后,会看到两台机都开始跑起来了!ohhhhhhhhhhh~
六、将数据转存至MySQL
即使爬取到的数据会自动存到Redis数据库中(开启Redis的pipeline之后),可是我的云服务器内存还是比较小,不想占用太多的内存,所以,可以将Redis数据库中的数据转存到本地MySQL数据库中。
Python中操作Redis数据库的包是:redis,可以直接用pip来安装;而操作MySQL数据库的包是:pymysql,同样可以用pip来安装。
将数据转存到MySQL的代码如下:
import json import redis import pymysql import time # 连接redis数据库 rediscli = redis.StrictRedis(host='', port = 6379, db = 0, password='') # 连接mysql数据库 mysqlcli = pymysql.connect(host='',user='',password='',database='',charset='utf8') while True: if rediscli.exists("yy:items") == 0: sj = time.perf_counter() # 计时 # 超过1分钟,退出循环 if sj >= 60: mysqlcli.close() break else: # 将Redis数据库中的数据pop出来 source, data = rediscli.blpop(["yy:items"]) item = json.loads(data) cursor = mysqlcli.cursor() sql = '''insert into youyuan(name,address,age,height,salary,house,hobby,image,motto, detail,boy_condition,url) values (%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s,%s)''' cursor.execute(sql,[item['name'],item['address'],item['age'],item['height'],item['salary'],item['house'], json.dumps(item['hobby'],ensure_ascii=False), json.dumps(item['image'],ensure_ascii=False), item['motto'],json.dumps(item['detail'],ensure_ascii=False), json.dumps(item['boy_condition'],ensure_ascii=False),item['url']]) mysqlcli.commit() cursor.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
七、一些tips、一些坑
- 在本机上先敲好代码,然后打包项目,直接上传至云服务器即可。比如打包时的命令:
tar -cvf youyuan.tar youyuan(在youyuan项目的最上层文件目录下进入cmd命令,再运行即可);然后在云服务器上的解包命令:tar -xvf youyuan.tar即可;其中,将打包后项目上传到云服务器上可以在xshell里面操作。 - Redis数据库的安装以及配置,可以看这里的教程点击跳转,还有,可能在redis运行的日志文件中会发现有个警告:
WARNING overcommit_memory is set to 0! Background save may fail under low memory condition. To fix this issue add 'vm.overcommit_memory = 1' to /etc/sysctl.conf and then reboot or run the command 'sysctl vm.overcommit_memory=1' for this to take effect.这时,只需按照它的提示在这个/etc/sysctl.conf配置文件中加入vm.overcommit_memory = 1,并且在控制台中运行命令:sysctl vm.overcommit_memory=1即可。 - 这个有缘网站应该是有限制可查看数量的,因为一开始我只是想爬取全国18岁~25岁的mm的,但是跑完之后才1000左右条数据,而且我发现直接跳到几百页后,会有重复的数据出现,所以说那些页数都是假的?!所以我才一怒之下将25岁的上限给去掉了(捂脸)。不过也有可能是我没有注册,可能登陆之后会看到更多的信息??这个后面再说吧哈哈。
ps:扫描下方二维码,关注公众号【Python王者之路】,回复20200626即可获取本文项目源代码

参考链接
https://www.bilibili.com/video/BV1H441127tZ
写在最后
其实一开始我是用RedisCrawlSpider来爬的,可是呢,如果只是一台机运行的话,master和salve都可以跑,没问题的,但是,一旦两台机一起跑,就会有其中一台机跑不了,报错的信息是builtins.ValueError:Method '_callback' not found,不是callback找不到就是其他的函数,总之总有一台机跑不了(百度了很久,也没有解决。),本来我都想放弃了,然后突然有个想法就是不用RedisCrawlSpider来爬,换成RedisSpider,之后竟然奇迹般地成功了!!哈哈哈哈~
这个是补全之前的Scrapy框架的学习心得,其实在那个时候就知道分布式爬虫的一些原理了,只是没有去实践。所以,现在有时间了,就补上了之前学习Scrapy框架未完成的事。还是会学到很多东西的哈哈~
 文章浏览阅读5.3k次,点赞63次,收藏56次。key的类型对应着value的类型,同样也有五种(string、list、hash、set、zset)Rediskey的类型以及命令系列文章目录第一章Java线程池技术应用第二章CountDo... [详细]
文章浏览阅读5.3k次,点赞63次,收藏56次。key的类型对应着value的类型,同样也有五种(string、list、hash、set、zset)Rediskey的类型以及命令系列文章目录第一章Java线程池技术应用第二章CountDo... [详细]赞
踩
- 如何实现附近商户的搜索?RedisGEO一键搞定!微服务SpringBoot整合RedisGEO实现附近商户功能文章目录⛄引言♨️广播站一、RedisGEO数据结构用法⛅GEO基本语法、指令⚡使用GEO存储经纬度、查询距离二、SpringB... [详细]
赞
踩
- Docker是一个开源的应用容器引擎,可以自动化部署、扩展应用程序。它可以帮助开发人员将应用程序及其依赖项打包到一个可移植的容器中,然后在任何环境中运行。Redis是一个开源的内存数据结构存储系统,它可以用作数据库、缓存和消息代理。它支持多... [详细]
赞
踩
- 方法2,清缓存前确保redis-server.exe进程已经启动,然后打开redis-cli.exe,跳出的CMD里面输入flushall,显示OK就可以了。2、执行./redis-cli或者./redis-cli-h127.0.0.1-p... [详细]
赞
踩
- 基于docker搭建redis_docker安装redisdocker安装redis一、Redis简介Redis,英文全称是RemoteDictionaryServer(远程字典服务),是一个开源(BSD许可),内存存储的数据结构服务器,可... [详细]
赞
踩
- Centos8使用docker安装软件教程:jdk、nginx、nacos、redis、SentinelDashboard_centos8jdkcentos8jdk目录一、安装软件(1)全部安装命令(2)安装:jdk(3)安装:nginx&... [详细]
赞
踩
- 使用scrapy对接selenium完成对动态网站的爬取_scrapyseleniumscrapyselenium最近学习了scrapy爬虫框架,想要找个目标练练手。由于现在很多网页都是动态的,因此还需要配合selenium爬取。本文旨在记... [详细]
赞
踩
- 如果您需要手动启动传输,或者需要在某个特定时间点执行代码,则可能需要使用close_spider方法。数据保存到redis后,在爬虫结束方法退出driver,否则下次再跑就会报502超时链接不到dockerselenium的driver,因... [详细]
赞
踩
- 在spiders文件中写如下:custom_settings={‘DOWNLOAD_DELAY’:0.2,‘CONCURRENT_REQUESTS_PER_IP’:4,‘DOWNLOADER_MIDDLEWARES’:{},}_scrapy... [详细]
赞
踩
- 是用来导入Scrapy框架内置的中间件类。这个中间件类用于处理请求的重试逻辑,当请求失败或遇到特定的异常时,可以根据配置的参数进行自动重试。在Scrapy-Redis中,你可以根据需要使用增加请求重试次数:通过修改设置项来增加请求的最大重试... [详细]
赞
踩
- 通供应商门户具备内外协同的能力,为外部供应商集中推送展示与其相关的所有采购业务信息(历史合作、考察整改,绩效评价等),支持供应商信息的自助维护,实时风险自动提。涉及技术:Eureka、Config、Zuul、OAuth2、Security、... [详细]
赞
踩
- Redis常见用途包括被用作分布式环境中的消息队列服务,本文介绍开发SpringBoot应用时借助SpringDataRedis实现消息的发布及订阅。:定时发布消息。:订阅消息。虽然使用Redis可是实现分布式环境下的消息发布及订阅功能,但... [详细]
赞
踩
- Redisson区别与Lettuce和Jedis之处在于,Redisson不再是一个纯粹的Redis客户端,还提供了很多高级的分布式服务,本文介绍开发SpringBoot应用集成Redisson实现消息的发布及订阅。:定义消息主题(Topi... [详细]
赞
踩
- SpringDataRedis整合了Lettuce和Jedis两个流行的Redis客户端,本文介绍Lettuce客户端在SpringBoot应用开发中的使用。SpringBoot应用中引入自动生成Bean实例,用于创建对象;自动生成Bean... [详细]
赞
踩
 redis数据类型Set详细介绍redis—Set集合目录前言1.常见命令2.使用场景前言集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中1)元素之间是无序的2)元素不允许重复,如图2-24所示。一个集合中最多可以存储2... [详细]
redis数据类型Set详细介绍redis—Set集合目录前言1.常见命令2.使用场景前言集合类型也是保存多个字符串类型的元素的,但和列表类型不同的是,集合中1)元素之间是无序的2)元素不允许重复,如图2-24所示。一个集合中最多可以存储2... [详细]赞
踩
- 一个基于SSM+SpringBoot+Redis的个人博客系统项目,在实现基本的编写、发布、查看、修改、删除博客以及个人信息显示等功能外,还对用户密码进行加盐加密处理,在主页实现分页功能,此外还将用户的Session进行持久化处理并存储到R... [详细]
赞
踩
- ZooKeeper是一个开源的分布式协调服务,旨在帮助构建可靠的分布式系统。它通过提供高可用、高性能的分布式协调机制来解决分布式应用中的一致性和协作问题。首先,我们来看ZooKeeper的起源、特点和应用场景。ZooKeeper最初由雅虎研... [详细]
赞
踩
- Spring对Jedis和lettuce进行了封装,spring-data-redis提供统一的API进行操作。Redis学习笔记2:Java客户端Redis学习笔记2:Java客户端常见的RedisJava客户端有三种:Jedis,优点是... [详细]
赞
踩
- 在Linux上安装Redis的详细步骤可以阅读。Redis学习笔记1:基础Redis学习笔记1:基础安装在Linux上安装Redis的详细步骤可以阅读这里。命令行客户端与服务端一同安装的还有命令行客户端redis-cli,可以通过以下方式用... [详细]
赞
踩
- 在这个方案中,他确实可以使用对应路径的拦截,同时刷新登录token令牌的存活时间,但是现在这个拦截器他只是拦截需要被拦截的路径,假设当前用户访问了一些不需要拦截的路径,那么这个拦截器就不会生效,所以此时令牌刷新的动作实际上就不会执行,所以这... [详细]
赞
踩

