
- 1SublimeText调试JS操作方法_sublime text 调试 javascript
- 2AtCoder 注册、如何参加Atcoder的比赛_atcoder注册
- 3C++ 蓝桥杯之 龟兔赛跑预测_c++龟兔赛跑预测
- 4数据结构和算法之排序总结_排序算法的技术要点和设计要求
- 52022年蓝桥杯Python程序设计B组思路和代码分享
- 6uniapp h5发行_uniapp 发布h5
- 7【Godot】学习状态机和行为树的 Godot 网址_godot教程网站
- 8讯飞星火认知大模型 Nodejs SDK & Web使用_讯飞 spark nodejs 部署
- 9华为OD机试真题- 最小的调整次数【2023Q1】【JAVA、Python、C++】_最小调整次数华为od
- 10Python 之 Pandas DataFrame 数据类型的简介、创建的列操作_python pandas dataframe
分类预测 | MATLAB实现BO-CNN-GRU贝叶斯优化卷积门控循环单元多输入分类预测_cnn gru 超参数 优化
赞
踩
分类预测 | MATLAB实现BO-CNN-GRU贝叶斯优化卷积门控循环单元多输入分类预测
效果一览








基本介绍
基于贝叶斯(bayes)优化卷积神经网络-门控循环单元(CNN-GRU)分类预测,BO-CNN-GRU/Bayes-CNN-GRU多输入分类模型。
1.优化参数为:学习率,隐含层节点,正则化参数。
2.可视化展示分类准确率,输入多个特征,输出四个类别。
3.运行环境matlab2020b及以上。
模型描述
-
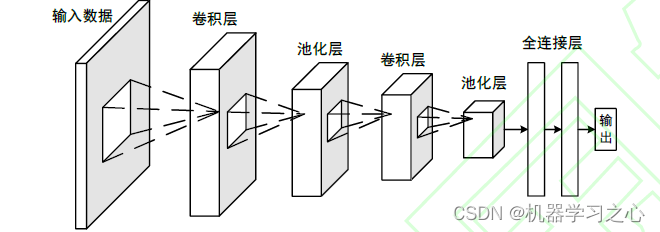
CNN 是通过模仿生物视觉感知机制构建而成,能够进行有监督学习和无监督学习。隐含层的卷积核参数共享以及层间连接的稀疏性使得CNN 能够以较小的计算量从高维数据中提取深层次局部特征,并通过卷积层和池化层获得有效的表示。CNN 网络的结构包含两个卷积层和一个展平操作,每个卷积层包含一个卷积操作和一个池化操作。第二次池化操作后,再利用全连接层将高维数据展平为一维数据,从而更加方便的对数据进行处理。
-
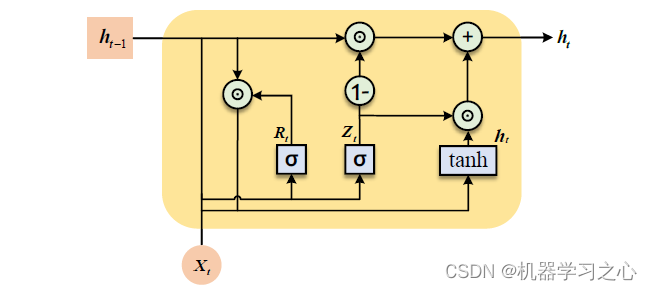
当时间步数较大时,RNN 的历史梯度信息无法一直维持在一个合理的范围内,因此梯度衰减或爆炸几乎是不可避免的,从而导致RNN 将很难从长距离序列中捕捉到有效信息。LSTM 作为一种特殊的RNN,它的提出很好的解决了RNN 中梯度消失的问题。而GRU 则是在LSTM 的基础上提出的,其结构更简单,参数更少,训练时间短,训练速度也比LSTM更快。
-
为使模型具有自动提取特征的功能,一般采用深度学习的方法来进行构建。其中,CNN 在提取特征这方面能力较强,它通常依靠卷积核来对特征进行提取。但是,卷积核的存在又限制了CNN 在处理时间序列数据时的长期依赖性问题。
-
在这项研究中,GRU 的引入可以有效地解决这个问题,并且我们可以捕获时间序列前后的依赖关系。另一方面, GRU 模块的目的是捕获长期依赖关系,它可以通过存储单元长时间学习历史数据中的有用信息,无用的信息将被遗忘门遗忘。另外,直接用原始特征进行处理,会极大的占用模型的算力,从而降低模型的预测精度,CNN-GRU模型结合了CNN和GRU的优点。
-
通常,在模型训练过程中需要对超参数进行优化,为模型选择一组最优的超参数,以提高预测的性能和有效性。 凭经验设置超参数会使最终确定的模型超参数组合不一定是最优的,这会影响模型网络的拟合程度及其对测试数据的泛化能力。
-
伪代码

-
通过调整优化算法调整模型参数,学习重复率和贝叶斯优化超参数来调整模型参数。
程序设计
- 完整程序和数据获取方式1:私信博主,;
- 完整程序和数据下载方式2:同等价值程序兑换。
%% 优化算法参数设置 %参数取值上界(学习率,隐藏层节点,正则化系数) %% 贝叶斯优化参数范围 optimVars = [ optimizableVariable('NumOfUnits', [10, 50], 'Type', 'integer') optimizableVariable('InitialLearnRate', [1e-3, 1], 'Transform', 'log') optimizableVariable('L2Regularization', [1e-10, 1e-2], 'Transform', 'log')]; %% 从主函数中获取训练数据 num_dim = evalin('base', 'num_dim'); num_class = evalin('base', 'num_class'); Lp_train = evalin('base', 'Lp_train'); t_train = evalin('base', 't_train'); T_train = evalin('base', 'T_train'); FiltZise= evalin('base', 'FiltZise'); %% 创建混合CNN-GRU网络架构 % 创建"CNN-GRU"模型 layers = [... % 输入特征 sequenceInputLayer([num_dim 1 1],'Name','input') sequenceFoldingLayer('Name','fold') % CNN特征提取 convolution2dLayer([FiltZise 1],32,'Padding','same','WeightsInitializer','he','Name','conv','DilationFactor',1); batchNormalizationLayer('Name','bn') eluLayer('Name','elu') averagePooling2dLayer(1,'Stride',FiltZise,'Name','pool1') % 展开层 sequenceUnfoldingLayer('Name','unfold') % 平滑层 flattenLayer('Name','flatten') % GRU特征学习 gruLayer(optVars.NumOfUnits,'Name','gru1','RecurrentWeightsInitializer','He','InputWeightsInitializer','He') % GRU输出 gruLayer(32,'OutputMode',"last",'Name','gru2','RecurrentWeightsInitializer','He','InputWeightsInitializer','He') dropoutLayer(0.25,'Name','drop1') % 全连接层 fullyConnectedLayer(num_class,'Name','fc') softmaxLayer('Name','sf') classificationLayer('Name','cf')]; layers = layerGraph(layers); layers = connectLayers(layers,'fold/miniBatchSize','unfold/miniBatchSize'); %% CNNGRU训练选项 % 批处理样本 MiniBatchSize =128; % 最大迭代次数 MaxEpochs = 500; options = trainingOptions( 'adam', ... 'MaxEpochs',500, ... 'GradientThreshold',1, ... 'InitialLearnRate',optVars.InitialLearnRate, ... 'LearnRateSchedule','piecewise', ... 'LearnRateDropPeriod',400, ... 'LearnRateDropFactor',0.2, ... 'L2Regularization',optVars.L2Regularization,... 'Verbose',false, ... 'Plots','none');

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
参考资料
[1] https://blog.csdn.net/kjm13182345320/article/details/129036772?spm=1001.2014.3001.5502
[2] https://blog.csdn.net/kjm13182345320/article/details/128690229
- 我们使用百度的在线图片识别网站做弹窗上传test,该网站也可以通过对input对象使用send_keys来进行图片上传。首先,打开弹窗,并输入图片的路径,通过回车键找到图片。输入图片名称后点击打开按钮即可完成图片的上传。_pywinauto... [详细]
赞
踩
- 1.音频标签和视频标签使用方式基本一致2.浏览器支持情况不同3.谷歌浏览器把音频和视频自动播放禁止了4.可以把视频标签添加muted属性来静音播放视频,音频不可以(可以通过JavaScript解决)5.视频标签是重点,经常设置自动播放,不使... [详细]
赞
踩
- 仪器设备是高等学校从事教学、科研的重要条件和基本手段,也是学校综合实力的体现。最早期的大型仪器设备管理是用账本形式,将大型设备仪器以书面的形式记录在册。随着学校建设速度加快,建筑楼宇增多,仪器设备大量增加,学校原有的设备数据库管理系统已不适... [详细]
赞
踩
- 学过面对对象的同学都知道虚函数是面向对象编程中的一个重要概念,它允许在基类和派生类之间实现多态性(polymorphism)。我们可以在基类去定义一个成员函数,然后再派生类再去覆盖写它,这样在不同派生类使用相同函数名就可以实现不同的功能。下... [详细]
赞
踩
- vue+vuex+vue-cli+vue-router+element-ui+swiper等技术开发仿微信pc端界面聊天应用,实现了发送消息+表情(动图gif)、图片/视频预览、右键长按菜单、红包/朋友圈、截图发送等功能。技术栈vue版本:... [详细]
赞
踩
- 最近,也做了一段时间的互联网开发,感觉转型,不仅仅是技术上的,同时也是工作方式的,工作节奏的改变。我把对公司的一些理解整理在这边网上,我看到很好的文章里,当然文章是以测试人员的视角,来写的,但大致把互联网开发和传统软件开发的不同概括的很好了... [详细]
赞
踩
- 本篇文章主要为学习其模型思想。_基于残差网络和gru的温度预测基于残差网络和gru的温度预测本篇文章主要为学习其模型思想。引言卷积神经网络(CNN)作为在图像处理、计算机视觉等领域被广泛应用的模型,其特殊的网络结构通过共享权重的特性可以很好... [详细]
赞
踩
- 关于virtual关键字的用法总结如下,有错误或者总结不到位的情况请能帮本人指出,非常感谢!Virtual是C++OO机制中很重要的一个关键字。只要是学过C++的人都知道在类Base中加了Virtual关键字的函数就是虚拟函数。基类的函数调... [详细]
赞
踩
- article
关于github报错:ssh: connect to host github.com port 22: Connection timed outfatal: Could not read from r...
当执行git命令如:gitclone、gitpull等等出现报错:ssh:connecttohostgithub.comport22:Connectiontimedoutfatal:Couldnotreadfromremotereposit... [详细]赞
踩
- 本文基于Flink1.12版本,目前这个版本已经不需要再指定具体的kafka版本了。本文从Sql角度分析一下,创建一个kafka的table之后,flink是如何从kafka中读写数据的。入口依然是通过SPI机制找到kafka的factor... [详细]
赞
踩
- voliate的三个特点1.可见性:一个线程修改了voliate修饰的值后,对于其他线程可见;2.有序性:保证临界区代码执行有序性;3.受限原子性:不保证原子性。voliate如何实现线程安全实现变量可见性进制指令重排序voliate读写过... [详细]
赞
踩
- 闭包是自包含的函数代码块,可以在代码中被传递和使用。Swift中的闭包与C和Objective-C中的代码块(blocks)以及其他一些编程语言中的匿名函数(Lambdas)比较相似。闭包可以捕获和存储其所在上下文中任意常量和变量的引用。被... [详细]
赞
踩
- 多态是C++面向对象编程中重要的特性。相同的行为方式可能导致不同的行为结果,即产生了多种形态行为,即多态。就是不同的类可以共享一个函数,但是各自的实现不同为了实现多态,首先要有继承关系,在基类中声明一个虚函数,然后再派生类中进行不同的实现根... [详细]
赞
踩
- 尽管大多数访问Amazon.com的网民看到的只是一个漂亮的电子商务网站,但戴夫看到的却是一个数据宝藏和挣钱的路子。 戴夫二年前离开了企业软件厂商BEASystems,希望“站在可编程网站的肩膀上”建立一家新公司。他与哈里森合伙成立了Mp... [详细]
赞
踩
- 物联网作为现实与虚拟世界的连接基础,一直备受关注。不管是人工智能革命还是区块链技术,物联网都将作为底层架构,提供有价值、可使用的数字资源,但是截至到目前,物联网依然面临着太多亟待解决的问题。首先是碎片化问题。从物联网诞生的那一天起,它就是碎... [详细]
赞
踩
- 现有实现方式中最典型的代表就是工业控制计算机(简称工控机),生产厂商将各种接口进行模块(卡)化设计,将其与通用的计算机主机模块结合,就实现了通用计算机接入特定通信系统的目的,客户购买时根据需要选择接口模块(卡)和满足处理能力的通用计算机主机... [详细]
赞
踩
- Ruff低成本数采网关,针对一些数采及控制较为简单的中频采集、小数据量、采集点数从性价比到功能体验,Ruff智能数采网关更适用于工业和市政领域随着物联网等技术的迅猛发展以及各领域数字化转型的迫切要求,在工业以及市政等领域,面临着大量的底层设... [详细]
赞
踩
- 在IntelliJIDEA中,选择"File">"New">"Project..."。在"NewProject"窗口中,选择"Java"并选择"WebApplication"模板。在IntelliJIDEA中,选择"Run">"Run"(或... [详细]
赞
踩
- 即使一个经验丰富的工程师,对于设备的完整性、数据保护和设备管理,DIY安全也不会得到保证,近来物联网设备的应用让这一观点变得痛苦而清晰。2017年底,有超过50亿的蓝牙设备被发现容易受到BlueB..._区块链结合物联网可以避免哪些攻击cs... [详细]
赞
踩
- P5469[NOI2019]机器人洛谷黑题题解P5469[NOI2019]机器人洛谷黑题题解[NOI2019]机器人题目背景时限3秒,内存512MB题目描述小R喜欢研究机器人。最近,小R新研制出了两种机器人,分别是P型机器人和Q型机器人。现... [详细]
赞
踩

