
- 1玩转k8s:yaml介绍
- 2Hadoop_HDFS(二):Shell操作之文件的管理(上传下载删除等)_hdfs 删除文件夹
- 3MySQL基础~排序查询、聚合函数查询、Group by分组查询、limit分页_mysql如何让聚合函数在limit分页前进行
- 4使用Python Flask搭建Web问答应用程序并发布到公网远程访问_flask 发布
- 5《软件工程》学生信息管理系统概要设计说明书_学生信息管理系统j结构化软件说明书
- 6运维笔记之centos7安装mysql数据库
- 7PyQt5新手教程(五万字)_学习pyqt5需要掌握哪些python只是知识
- 82023-11-19-2023一带一路暨金砖国家技能发展与技术创新大赛之网络安全在企业信息管理中的应用 pwn WriteUps 决赛初赛
- 9【云原生】Docker如何构建镜像
- 10SpringCloud Aliba-Nacos集群配置-从入门到学废【3】
DRF--模型序列化器,字段修改_序列化器自定义fields名称
赞
踩
模型序列化器:
有时候我们根据模型类的字段一个个去定义序列化器类中的字段,可能模型类有百个字段,这样一个个定义就显得非常繁琐,所以我们可以使用drf中自带的模型序列化器,即serializers.ModelSerializer:
1.serializers.ModelSerializer为我们根据模型类自动生成序列化器类
2.serializers.ModelSerializer为我们自动提供了create()方法和update()方法.
1.定义模型序列化器
# projects/serializers.py
- class PorjectModelSerializer(serializers.ModelSerializer):
- """
- 1。模型序列化器,不继承serializers.Serializer,继承serializers.ModelSerializer,
- 2。必须定义内部类Meta
- Meta内部指定model属性,表示需要模型序列化器需要序列化的具体模型类
- fields:指定需要序列化的模型类中的具体字段
- fields="__all__":代表模型中的所有字段都序列化对应生成
- fields=(字段1,字段2,字段3,):自定义需要指定的字段生成
- exclude:指定模型类中不需要序列化的字段
- exclude=(字段1,字段2,字段3,):这些字段不需要自动生成
- """
- class Meta:
- model = Projects
- fields = "__all__"
2.指定模型序列化器需要操作的模型类
# projects/models.py
- class Projects(BaseModel):
- """
- max_length:必传参数
- verbose_name:在渲染表单的时候,下面会有一个中文的描述信息:项目名称;
- 在后台管理站点也会把当前字段加上一个描述
- help_text:在api接口文档中会作为中文描述信息
- unique=True: 代表给一个字段设置唯一约束,默认为False
- default:指定默认值
- TextField():支持长文本
- blank=True:允许传空字符串,DRF进行反序列化输入时才有效
- null = Tru:允许为null,DRF进行反序列化输入时才有效
- DateTimeField指定auto_now_add=True,在创建一条记录时会自动创建时间作为该字段的值,后续更新不会改变该值
- DateTimeField指定auto_now=True,在更新一条记录时,会自动将更新记录的时间作为该字段的值
- """
- full_name = models.CharField(max_length=50,
- verbose_name='项目名称',
- help_text='项目名称',
- unique=False)
- leader = models.CharField(max_length=10,
- verbose_name='项目负责人',
- help_text='项目负责人')
- # default=xxx指定默认值
- is_execute = models.BooleanField(verbose_name='是否启动项目',
- help_text='是否启动项目',
- default=False)
- # TextField()支持长文本
- # blank=True,允许传空字符串
- # null = True,允许为null
- desc = models.TextField(verbose_name='项目描述信息',
- help_text='项目描述信息',
- blank=True, default='')
-
- # 修改模型类元信息
- class Meta:
- # # 是否被管理
- # managed = True
- # db_table:指定表名
- db_table = 'tb_projects'
-
- def __str__(self):
- # print打印对象时可以默认返回的东西
- return f'Projects({self.full_name})'
3.terminal中执行命令
3.1 python manage.py shell
3.2 from projects.serializers import PorjectModelSerializer
3.3 PorjectModelSerializer()
4.效果:

5.定义模型序列化器类总结:
5.1 继承serializers.ModelSerializer类或其子类
5.2 需要在Meta内部类中指定model,fields类属性参数
5.2.1 model指定模型类(需要生成序列化器的模型类)
5.2.2 fields指定模型类中哪些字段需要被生成序列化器字段
5.3 会给id主键,有指定auto_now_add或者auto_now参数的DateTimeField字段,自动添加
read_only=True
5.4 有设置unique=True的模型字段,会自动在validators列表中添加唯一约束校验
(UniqueValidator)
5.5 有设置default=True的模型字段,会自动添加required=False
5.6 有设置null=True的模型字段,会自动添加allow_null=True
5.7 有设置blank=True的模型字段,会自动添加allow_blank=True
6.字段修改
有时候,我们通过模型序列化器生成的序列化器中的字段并不能完全满足我们对序列化与反序列化操作的要求,我们可以自己修改不满足要求的字段.
6.1 方式一:
6.1.1 可以重新定义模型类中同名的字段
6.1.2 自定义字段的优先级会更高
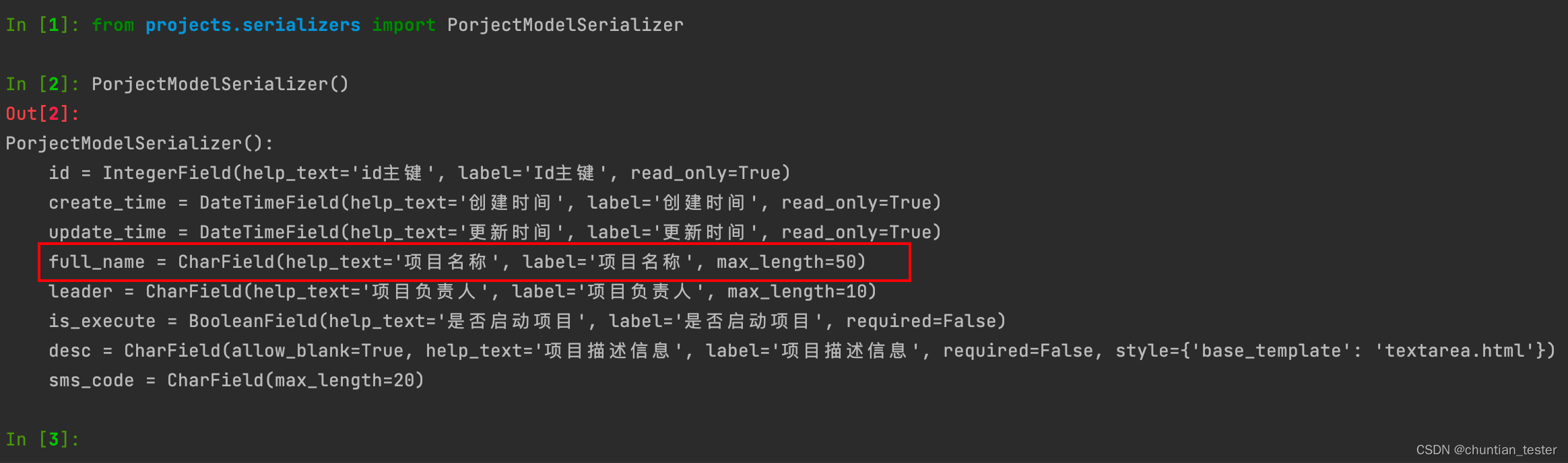
例如:给序列化器自动生成的full_name字段增加min_length=8
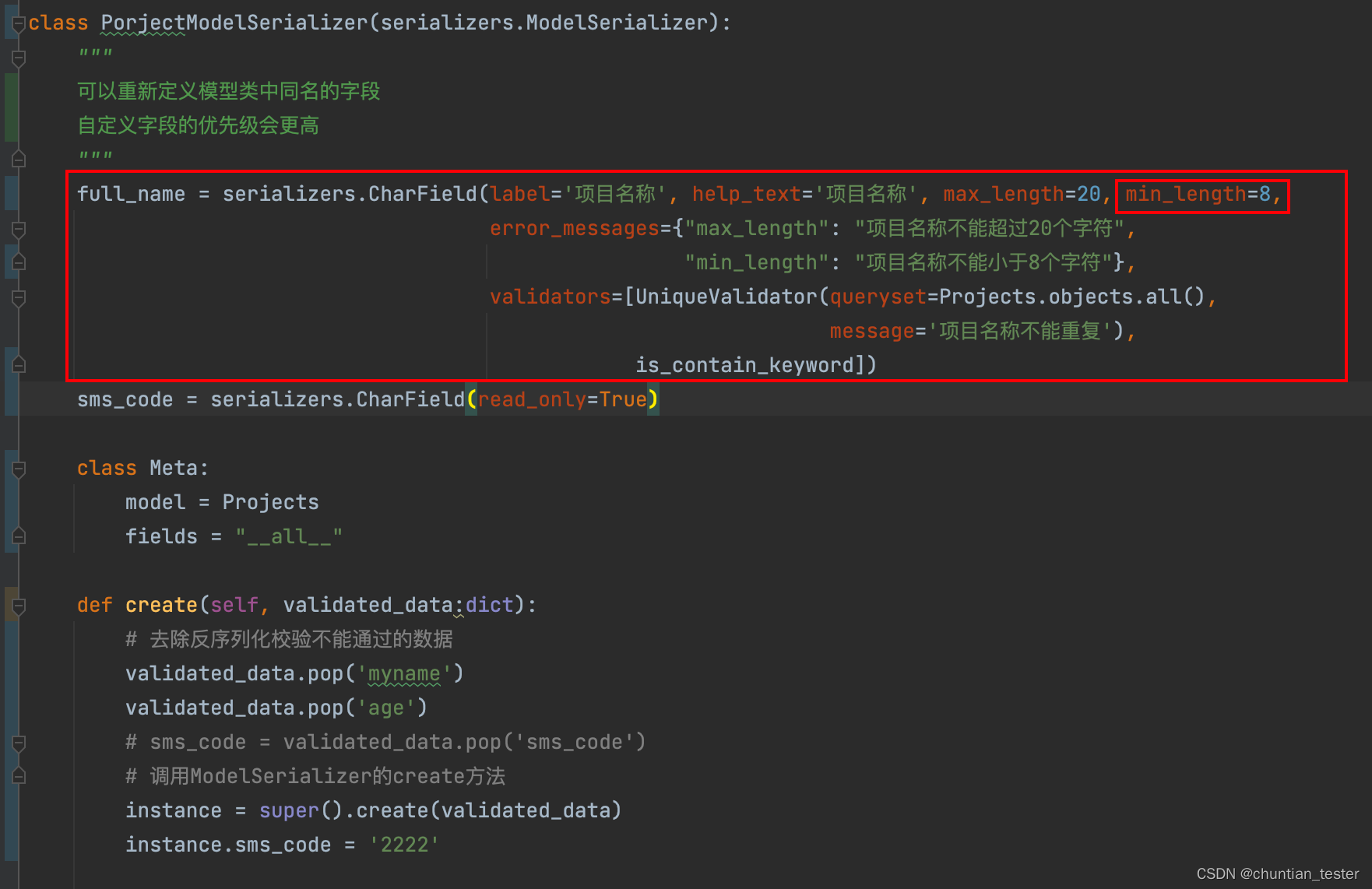
输出

6.2 方式二:
如果生成的序列化器中只有少量字段不满足需求,可以在Meta内部类中定义extra_kwargs字典进行微调,将需要调整的字段作为key,需要修改的内容作为value
6.2.1 在Meta内部类中定义extra_kwargs属性(字典)
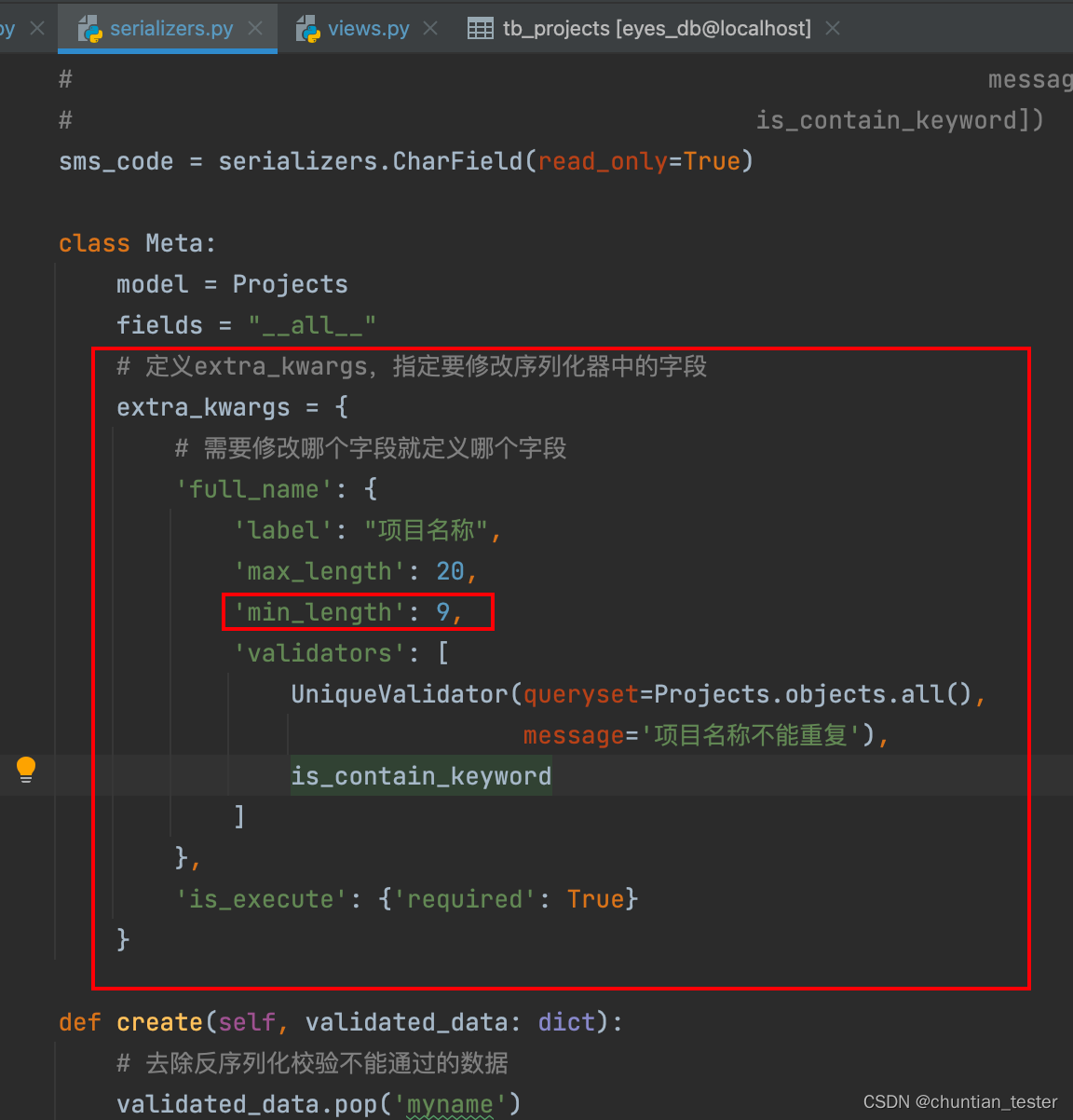
输出
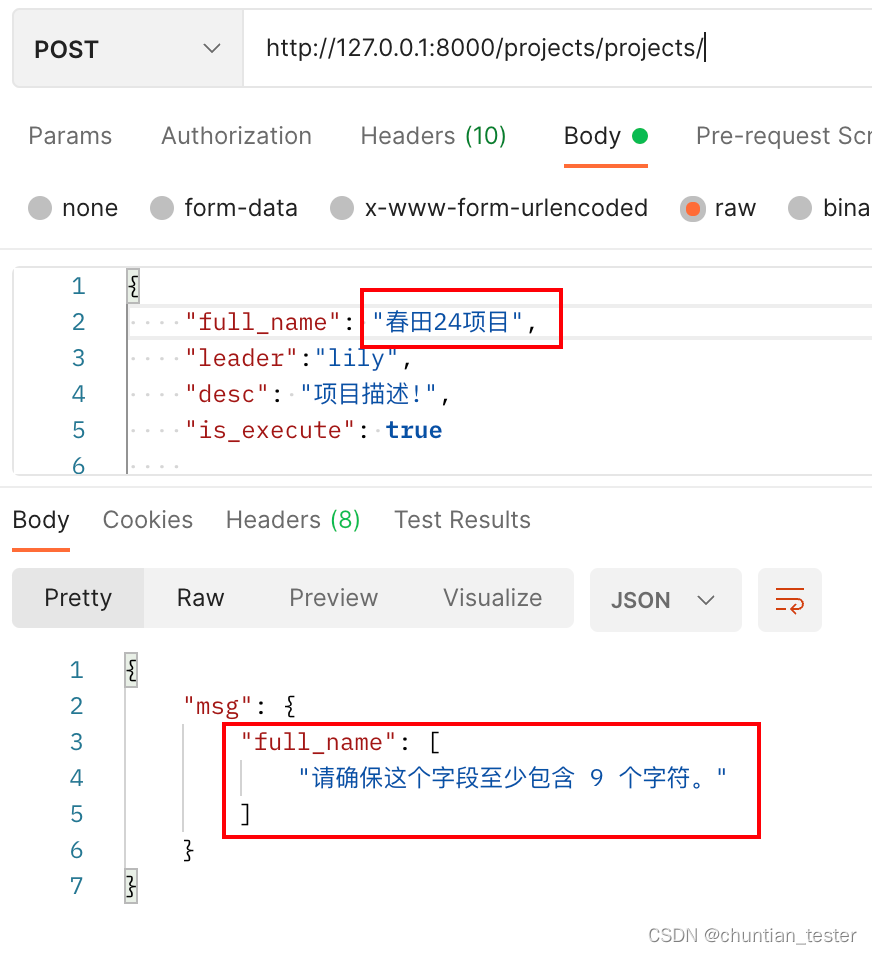
6.3 代码
- class PorjectModelSerializer(serializers.ModelSerializer):
- """
- 可以重新定义模型类中同名的字段
- 自定义字段的优先级会更高
- """
- # full_name = serializers.CharField(label='项目名称', help_text='项目名称', max_length=20, min_length=8,
- # error_messages={"max_length": "项目名称不能超过20个字符",
- # "min_length": "项目名称不能小于8个字符"},
- # validators=[UniqueValidator(queryset=Projects.objects.all(),
- # message='项目名称不能重复'),
- # is_contain_keyword])
- sms_code = serializers.CharField(read_only=True)
-
- class Meta:
- model = Projects
- fields = "__all__"
- # 定义extra_kwargs,指定要修改序列化器中的字段
- extra_kwargs = {
- # 需要修改哪个字段就定义哪个字段
- 'full_name': {
- 'label': "项目名称",
- 'max_length': 20,
- 'min_length': 9,
- 'validators': [
- UniqueValidator(queryset=Projects.objects.all(),
- message='项目名称不能重复'),
- is_contain_keyword
- ]
- },
- 'is_execute': {'required': True}
- }
-
- def create(self, validated_data: dict):
- # 去除反序列化校验不能通过的数据
- validated_data.pop('myname')
- validated_data.pop('age')
- # sms_code = validated_data.pop('sms_code')
- # 调用ModelSerializer的create方法
- instance = super().create(validated_data)
- instance.sms_code = '2222'
-
- return instance
-
- def update(self, instance, validated_data):
- instance = super().create(validated_data)
- return instance
- 2020年IOS逆向反编译注入修改游戏或APP的调用参数新手系列教程——用bfinject脱壳、注入自己的动态framework、cycript的使用开篇本篇文章是继上一篇文章:2020年IOS逆向反编译注入修改游戏或APP的调用参数新手系... [详细]
赞
踩
- 前言Flink提供了一个ApacheKafka连接器,我们可以很方便的实现从Kafka主题读取数据和向其写入数据。Flink附带了提供了多个Kafka连接器:universal通用版本,0.10,0.11官方文档解释说universal(通... [详细]
赞
踩
- 网络安全行业14年开始兴起,现在国家也非常重视和支持,虽然现在人才越来越多,但还是处于上升阶段,因为人才在增多的同时,网络安全人才的需求量也在增大。而我国的网络安全产业增速较快,发展机遇较多,发展空间巨大。没学过的同学也不要慌,可以去B站搜... [详细]
赞
踩
- article
TEMU平台跟亚马逊衣物收纳柜16 CFR 1261报告 ASTM F2057-19测试办理_亚马逊要求的家具油漆检测16 cfr part 1261 or astm f2057-23 (saf
此政策适用于独立式衣物收纳商品,包括但不限于高度为27英寸(69厘米或686毫米)或更高(从地面到商品顶部测量)的箱子、抽屉柜、斗柜、衣柜、衣橱柜、衣橱、门橱和梳妆台。经过16CFR1261测试和ASTMF2057-19测试,衣物收纳柜的倾... [详细]赞
踩
- 音频基本概念_音频通道与声音的关系音频通道与声音的关系音频相关的基本概念1.声音的本质声音的本质是波在介质中的传播现象,声波的本质是一种波,是一种物理量。两者不一样,声音是一种抽象的,是声波的传播现象,声波是物理量。2.声音的三要素响度(l... [详细]
赞
踩
- 之前直接将抖音的复制链接复制到PC端浏览器中打开就能获取到无水印视频,但是这个方法最近被抖音禁了,看到的视频带水印了。废话不多说,今天就来介绍如何通过charles来抓取抖音APP请求获取无水印视频。工欲善其事必先利其器:charles如何... [详细]
赞
踩
- 搞定pywinauto微信自动发送消息后,看到是使用的UIA,然后看到FlaUI。好吧,C#也能做,然后就开干了。具体代码如下:classProgram{[STAThread]staticvoidMain(string[]args){Pro... [详细]
赞
踩
- 本文介绍开发SpringBoot应用时使用JPA如何处理日期时间类型的持久化。和虽然是JDK8开始引入的新的日期时间类型,但本文重点不在于分析这几种日期时间类型的应用场景差异,仅说明SpringBootDataJPA如何处理这几种日期时间类... [详细]
赞
踩
- 简单记录一下C++中常用的四种类型转换。提示以下是本篇文章正文内容,下面案例可供参考RTTI(RunTimeTypeldentification)即通过运行时类型识别,程序能够使用基类的指针或引用来检查着这些指针或引|用所指的对象的实际派生... [详细]
赞
踩
- OkHttp的特点,如何使用get,post方法_okhttp3okhttp3深入解析OkHttp31.特点2.基本使用2.1OkHttp的基本使用,get请求2.2OkHttp的基本使用,post请求原文转载:深入解析OkHttp3.1.... [详细]
赞
踩
- 与传统的回归方法不同,SVR关注的是在一定的容忍度下找到一个边界,使得预测值与真实值之间的误差尽可能小,并且使得尽可能多的数据点落在该边界内。这个边界由支持向量确定,而支持向量是训练数据中距离边界最近的点。与传统的回归方法不同,SVR关注的... [详细]
赞
踩
- 抖音短视频数据抓取实战系列(十二)——抓取实战BUG总集1、模拟器自带的Xposed框架无法安装。2、Fiddler无法监测雷电模拟器上的数据。3、模拟器抖音用户详情页为空(未解决)。4、pip版本更新。5、mitmdump报killedb... [详细]
赞
踩
- 区间预测|MATLAB实现基于CNN-GRU-Multihead-Attention-KDE多头注意力卷积门控循环单元多变量时间序列区间预测区间预测|MATLAB实现基于CNN-GRU-Multihead-Attention-KDE多头注意... [详细]
赞
踩
- 数字图像处理(实践篇)三十二OpenCV-Python比较两张图片的差异数字图像处理(实践篇)三十二OpenCV-Python比较两张图片的差异目录一方案二实践通过计算两张图像像素值的均方误差(MSE)来比较两张图像。差异大的两张图片具有... [详细]
赞
踩
- 是基于.NET的OpenCV包装器,源代码是采用C和C++写的,目前对于C++和Python开发者相对来说比较友好,对于Python开发者而言官方提供了使用。首选我们使用VisualStudio2022创建一个.Net控制台程序,然后安装安... [详细]
赞
踩
- 为了帮助用户高效率、低成本应对企业级复杂场景,函数计算团队正式推出StableDiffusionAPIServerless版解决方案,通过使用该方案,用户可以充分利用StableDiffusion+Serverless技术优势快速开发上线A... [详细]
赞
踩
- 本项目可实现录音软件的录音、存储、播放等功能web前端项目-实现录音功能【附源码】录音功能运行效果:本项目可实现录音软件的录音、存储、播放等功能HTML源码:(1)index.html:<!DOCTYPEhtml><htm... [详细]
赞
踩
- article
2021-09-16 npm install @vuecli 卡在了 reifyrxjs timing reifyNode node_modules@vueclinode_modules_reify:rxjs: timing reifynode:node_modules/core-js
npminstall@vue/cli卡在了reify:rxjs:timingreifyNode:node_modules/@vue/cli/node_modules/....随后产生报错查了一堆东西,后来发现其主要原因在于npm镜像源的问题... [详细]赞
踩
- HopperDisassembler4激活版是mac上一款非常强大的二进制反编译工具,支持反汇编器,反编译和调试。它不仅拥有帮助您有效拆开任何二进制软件的强大功能,还可以提供给您所有的软件编码内容,如导入符号或控制流程的实用化信息,在允许您... [详细]
赞
踩
- volatile变量对所有线程是立即可见的包含两个意思:对一个volatile变量的读总是能看到任意线程对这个变量最后的写,即每次读取volatile变量的时候,会使线程工作内存中的变量副本无效,从而必须从主内存中更新变量值。 对一个vol... [详细]
赞
踩

