
- 1按照模板生成文件,Word 或者 Excel
- 224届双非日常实习测开面经-腾讯、字节、英伟达、OPPO、深信服、Red Hat面经大合集_英伟达 面经
- 3java 获取本机cpu占用_java如何获取系统CPU、内存占用
- 42023末最新的 从零开始的Midjourney高效使用技巧总结(二)
- 5pycharm的常用设置_pycharm设置
- 6Android ADB原理及常用命令_adb keyevent
- 7java技能等级证_JAVA技能等级考试(1)
- 8docker build: COPY/ADD报错:not a directory_docker cp not a directory
- 9stable_diffusion_webui docker环境配置
- 10基于支持向量回归和LSTM的短时交通流预测_lstm车流量预测python
Druid连接池-数据源配置|使用|销毁_druiddatasource
赞
踩
Druid连接池-数据源配置|使用|销毁
Druid连接池参数配置
通过使用数据库连接池可以极大提升数据库CURD操作的效率,尝试参考Druid的github官网配置了一些参数。
DruidDataSource参数配置
DruidDataSource-德鲁伊数据源可以理解为它就是正在使用的某个数据库,最普遍的操作就是直接用于获取维护在连接池中的Connection连接对象,而不用自己再重新new对象了,为我们省去了创建、释放Connection对象的时间。
以下是基本的Druid数据的一些参数配置,像:JDBC基本连接参数、连接池初始化/最大容量等参数的配置。官网的配置是整合了Spring框架,通过XML文档配置的,然后通过IOC机制便捷的获取DruidDataSource的对象,可以省去自己编写代码创建数据源对象的繁琐步骤,这也是使用框架开发的好处了吧。
另外值得一提的是,官网的配置直接指定好了初始化时调用的方法init()和销毁时调用的方法close(),在start和shutdown-Spring项目时会自动调用。当然如果通过Servlet技术开发的话,也是可以基于ServletContext监听器(或者说Application域对象的监听器)javax.servlet.ServletContextListener的contextInitialized()和contextDestroyed()方法模拟Spring的IOC机制实现数据源的创建和销毁。
driverClassName=com.mysql.cj.jdbc.Driver #开启预编译机制|开启批处理机制 url=jdbc:mysql://localhost:3306/数据库名称?useSSL=false&useUnicode=true&characterEncoding=utf8&serverTimezone=GMT&useServerPrepStmts=true&cachePrepStmts=true&rewriteBatchedStatements=true username=root password=root initialSize=5 minIdle=5 maxActive=30 maxWait=60000 poolPreparedStatements=true #是否使用预编译机制 maxPoolPreparedStatementPerConnectionSize=20 filters=log4j,wall,stat #-------------连接泄漏回收参数-------------------------------- #当未使用的时间超过removeAbandonedTimeout时,是否视该连接为泄露连接并删除 #默认为false removeAbandoned=false #泄露的连接可以被删除的超时值, 单位毫秒-默认为300*1000 removeAbandonedTimeoutMillis=300*1000 #标记当Statement或连接被泄露时是否打印程序的stack traces日志。 #默认为false logAbandoned=true #连接最大存活时间 #默认-1 #phyTimeoutMillis=-1

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
Druid内置监控页面配置
Servlet(最常用的用于收发请求和响应的类),Druid内置提供了一个StatViewServlet用于展示Druid的统计信息。其的用途包括:
①提供监控信息展示的html页面
②提供监控信息的JSON API内置监控页面是一个Servlet。
只需要在web.xml中按照Servlet的配置方法配置就行了。官网给出的例子如下,
<!-- 配置 Druid 监控信息显示页面 --> <servlet> <servlet-name>DruidStatView</servlet-name> <servlet-class>com.alibaba.druid.support.http.StatViewServlet</servlet-class> <init-param> <!-- 允许清空统计数据 --> <param-name>resetEnable</param-name> <param-value>true</param-value> </init-param> <init-param> <!-- 用户名 --> <param-name>loginUsername</param-name> <param-value>druid</param-value> </init-param> <init-param> <!-- 密码 --> <param-name>loginPassword</param-name> <param-value>druid</param-value> </init-param> </servlet> <servlet-mapping> <servlet-name>DruidStatView</servlet-name> <url-pattern>/druid/*</url-pattern> </servlet-mapping>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
Druid配置采集web-jdbc关联监控的数据
监听器(Listener)WebStatFilter用于采集web-jdbc关联监控的数据,其实就是让自己指定想要统计、不想要统计哪些数据。
关于这些init-param参数名称这样写,肯定是因为Druid内部已经预先做好了规范,只要了解参数的作用,并进行配置就可以生效了。
<!--filter配置--> <filter> <filter-name>DruidWebStatFilter</filter-name> <filter-class>com.alibaba.druid.support.http.WebStatFilter</filter-class> <!--排除一些不必要的url数据统计-就是把不想统计的请求过滤掉--> <init-param> <param-name>exclusions</param-name> <param-value>*.js,*.gif,*.jpg,*.png,*.css,*.ico,/druid/*</param-value> </init-param> <init-param> <param-name>profileEnable</param-name> <param-value>true</param-value> </init-param> <init-param> <param-name>resetEnable</param-name> <param-value>true</param-value> </init-param> <!-- 用户名 --> <init-param> <param-name>loginUsername</param-name> <param-value>druid</param-value> </init-param> <init-param> <!-- 密码 --> <param-name>loginPassword</param-name> <param-value>druid</param-value> </init-param> <init-param> <param-name>principalCookieName</param-name> <param-value>USER_COOKIE</param-value> </init-param> <init-param> <param-name>principalSessionName</param-name> <param-value>USER_SESSION</param-value> </init-param> </filter> <filter-mapping> <filter-name>DruidWebStatFilter</filter-name> <url-pattern>/*</url-pattern> </filter-mapping>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
Druid连接池数据源创建
通过手写DruidUtil类实现DruidDataSource创建,并提供获取Connection对象的获取方法,向外部提供数据库连接对象,然后配合DButils.jar提供的QueryRunner实现数据库CURD操作。
package com.xwd.utils; import com.alibaba.druid.pool.DruidDataSource; import com.alibaba.druid.pool.DruidDataSourceFactory; import javax.sql.DataSource; import java.sql.Connection; import java.sql.ResultSet; import java.sql.SQLException; import java.sql.Statement; /** * @ClassName DruidUtils * @Description: com.xwd.utils * @Auther: xiwd * @Date: 2022/2/17 - 02 - 17 - 2:33 * @version: 1.0 */ public class DruidUtil { //properties private static PropertyUtil propertyUtil =null; private static DruidDataSource dataSource;//数据源对象 // private static Logger logger;//日志打印对象 //setter //getter //static block static { //实例化Logger对象 // logger = Logger.getLogger(DruidUtil.class); //加载配置文件 propertyUtil=new PropertyUtil("/druid.properties"); try { //实例化数据源对象 dataSource = (DruidDataSource) DruidDataSourceFactory.createDataSource(propertyUtil.getProperties()); // logger.fatal("Druid DataSource has been initialized SUCCESSFULLY!"); } catch (Exception e) { e.printStackTrace(); // logger.fatal("Druid DataSource initialized FAILED!"); } } //constructors //methods /** * 获取数据源DataSource对象 * @return */ public static DruidDataSource getDruidDataSource(){ return dataSource; } /** * 获取数据库连接Connection对象 * @return Connection对象 */ public static Connection getConnection(){ Connection connection = null; try { connection = dataSource.getConnection(); } catch (SQLException e) { e.printStackTrace(); return connection; } return connection; } /** * 将数据库连接对象归还到数据库连接池中 * @param connection Connection-数据库连接对象 */ public static void returnResources( Connection connection){ returnResources(null,null,connection); } /** * 将数据库连接对象归还到数据库连接池中 * @param statement Statement-SQL语句执行器 * @param connection Connection-数据库连接对象 */ public static void returnResources( Statement statement,Connection connection){ returnResources(null,statement,connection); } /** * 将数据库连接对象归还到数据库连接池中 * @param resultSet ResultSet-结果集 * @param statement Statement-SQL语句执行器 * @param connection Connection-数据库连接对象 */ public static void returnResources(ResultSet resultSet, Statement statement,Connection connection){ if (null!=resultSet) { try { resultSet.close(); } catch (SQLException e) { e.printStackTrace(); } } if (null!=statement) { try { statement.close(); } catch (SQLException e) { e.printStackTrace(); } } if (null!=connection) { try { connection.close(); } catch (SQLException e) { e.printStackTrace(); } } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
关于注释掉Log4j初始化的代码说明
由于Druid内置提供了四种LogFilter(Log4jFilter、Log4j2Filter、CommonsLogFilter、Slf4jLogFilter),用于输出JDBC执行的日志。这些Filter都是Filter-Chain扩展机制中的Filter,在一开始已经配置了参数,指定使用log4j打印日志。
filters=log4j,wall,stat
- 1
但是在使用时,还需要引入log4j.jar包或者pom坐标,并准备好log4j.properties配置文件。
#默认error及其以上级别日志都会被记录下来
log4j.rootLogger=debug,stdout,logfile
#
#打印日志到控制台上
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.err
log4j.appender.stdout.layout=org.apache.log4j.SimpleLayout
#
#通过文件记录日志
log4j.appender.logfile=org.apache.log4j.FileAppender
#日志文件路径
log4j.appender.logfile.File=d:/sys.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d{yyyy-MM-dd HH:mm:ss} %l %F %p %m%n
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
DruidDataSource销毁
上面提到Druid官网数据源初始化参数的例子显然是整合了spring框架的,很容易配置DruidDataSource数据源的销毁方法close(),但是在使用Servlet开发时,可能很容易忽略此项。然后,就可能导致Tomcat服务shutDown时,爆出如下内容:
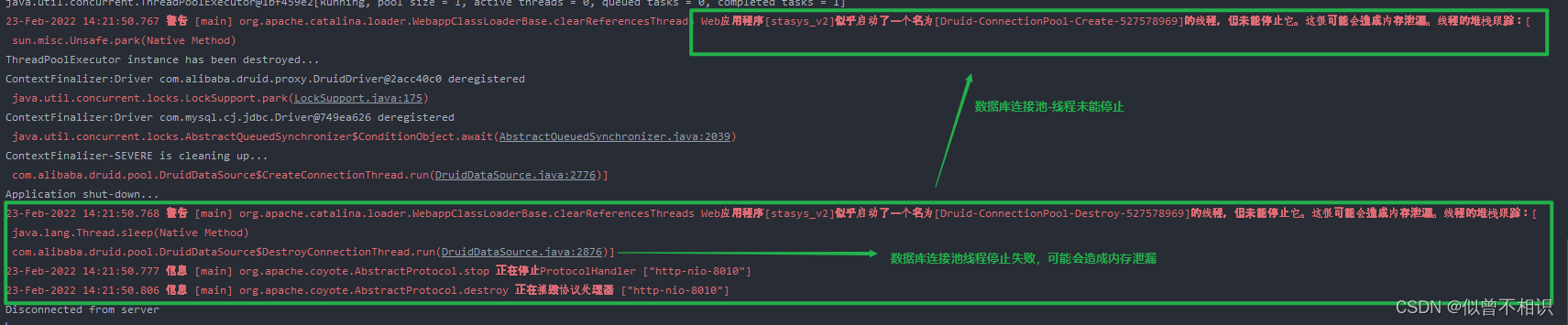
如何解决?结合已有配置参数,猜想可能是因为没有做DruidDataSource数据源销毁的操作。既然官方配置文档提示了要使用close()方法,那么就可以在ServletContext监听器实现类中的contextDestroyed()方法中,进行数据源的关闭操作。
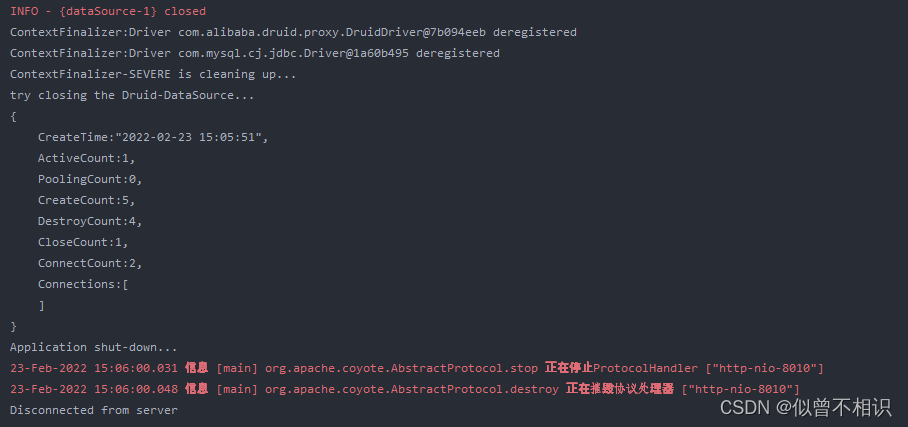
@Override public void contextDestroyed(ServletContextEvent sce) { //ServletContext销毁方法 //销毁自定义的线程池对象 // destroyThreadPoolExector(sce); //释放驱动 //releaseDriverResources(); //释放Druid数据库连接池资源 releaseDruidSources(); //提示关闭服务器应用 System.out.println("Application shut-down..."); } /** * 释放数据库连接池资源 */ private void releaseDruidSources() { System.out.println("try closing the Druid-DataSource..."); AbandonedConnectionCleanupThread.checkedShutdown(); DruidDataSource druidDataSource = DruidUtil.getDruidDataSource(); druidDataSource.close(); System.out.println(druidDataSource); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 自动化测试,顾名思义,自动完成测试工作。通过一些自动化测试工具或自己造轮子,实现模拟之前人工写的工作并验证其结果完成整个测试过程,这样的测试过程,便是自动化测试。把人对软件的测试行为转化为由机器执行测试行为的一种实践,对于最常见的自动化测试... [详细]
赞
踩
- 1.要实现舵机摇头就是依次从0°摇到90°,然后再摇到180°,反复循环,因为舵机是用PWM控制的,在垃圾桶项目中已经使用过舵机,可以直接拿代码过来用,最好进行代码的封装,在工程中引入该舵机的源文件。在测距避障过程中,如果使用的是普通转弯函... [详细]
赞
踩
- 一OKHttp简介OKHttp是一个处理网络请求的开源项目,Android当前最火热网络框架,由移动支付Square公司贡献,用于替代HttpUrlConnection和ApacheHttpClient(androidAPI236.0里已移... [详细]
赞
踩
- android--学习笔记_安卓okhttp3依赖安卓okhttp3依赖说明OKHttp3主要是一个网络请求网络请求方式一般为PUT,DELETE,POST,GET等。常用的是get、post文件的上传下载加载图片(内部会图片大小自动压缩)... [详细]
赞
踩
- 详细的讲解了SpringBoot自动配置的原理以及其中使用到的主要注解和类SpringBoot中的自动配置(autoconfigure)文中部分图片来源为动力节点-王鹤老师的SpringBoot3.0视频讲解中。SpringBoot中的自动... [详细]
赞
踩
- ALBERT前言当前的趋势是预训练模型越大,效果越好,但是受限算力,需要对模型进行瘦身。这里的ALBERT字如其名(AliteBERT),就是为了给BERT瘦身,减少模型参数,降低内存占用和训练时间(待思考)。论文来源:Lan,Z.,Che... [详细]
赞
踩
- 1模型结构论文信息:2018年10月,谷歌,NAACL论文地址https://arxiv.org/pdf/1810.04805.pdf模型和代码地址https://github.com/google-research/bertBERT自18... [详细]
赞
踩
- 安装在执行报错别慌,再运行一次命令。多试几次就好了。_error:subprocess-exited-with-error脳gitclone--filter=blob:none--quieterror:subprocess-exited-w... [详细]
赞
踩
- docker17.03.2-ce使用GPU_dockernvidiadockernvidiadocker17.03.2-ce使用GPUdocker官方是19.0.2开始支持英伟达GPU在此之前版本可以通过英伟达魔改docker的工具实现此需... [详细]
赞
踩
- 在springboot项目中,使用aop增强,不仅可以很优雅地扩展功能,还可以让一写多用,避免写重复代码,例如:记录接口耗时,记录接口日志,接口权限,等等。然而,当我们在一个接口中使用多个aop,时,就需要注意他们的执行顺序了。如果不把这个... [详细]
赞
踩
- 来源:谈数据,作者:石秀峰全文共3825个字,建议阅读8分钟数据作为数字经济时代新型生产要素,是企业的重要资产,也是赋能企业数字化转型的基石。在向着数字化快速迈进的同时,当前企业数据治理都面临着各种挑战和不足。企业越大,需要和产生的数据也就... [详细]
赞
踩
- windows系统下,Pycharm与Docker的核心配置方法,与GPU无法使用的解决方案。_windowspycharmnvidia-dockerwindowspycharmnvidia-dockerWindows+Pycharm+Do... [详细]
赞
踩
- Camera2框架的相机模型被设计成一个管道,使用相机时需要先和相机设备建立一个会话,通过该会话向相机发送请求,相机将图像数据保存到配置好的Surface,Surface就是存放图像数据的缓冲区。请求分为单次请求、重复请求和多次请求三种。_... [详细]
赞
踩
- vue3中v-model无法获取this.$emit('input')的值文章目录前情提要实战解析最后前情提要vue3的v-model已经有了变化,假如你还不知道其中细节,看完这篇文章你就完全明白了,我以踩坑的场景来进行解析。起因是在我的项... [详细]
赞
踩
- 2.1超声波传感器引脚和参数介绍(PA0–>TrigPA1–>Echo)2.2超声波测距实现原理首先看原理图:如图所示,超声波工作的过程实际就是不断循环主控(STM32)发送Trig信号、超声波模块发送驱动信号以及主控接收Echo信号并测距... [详细]
赞
踩
- gitcommit命令将暂存区内容添加到本地仓库中。gitcommit-m[message]:提交暂存区到本地仓库中,[message]可以是一些备注信息。 _gitcommit-agitcommit-agitcommit命令将暂存区内容添... [详细]
赞
踩
- 学完stm32,总是想做点东西“大显身手”一下,智能小车就成了首选项目,其核心只是就是PWM输出,I/O口引脚电平判断。制作智能小车的硬件名单:制作智能小车的硬件列表: (1)STM32C8T6核心板 一块 (2)L298N电机驱动 ... [详细]
赞
踩
- 字符串的基本操作简单易懂版_java字符串操作java字符串操作目录 1.字符串连接(两种) 2.字符串比较 3.字符串截取 4.字符串查找 5.字符串替换 6.字符串与字符数组1、字符串连接第一种就是我们常用的 + 连接publiccla... [详细]
赞
踩
- CV之DL之YOLOv8:YOLOv8的简介、安装和使用方法、案例应用之详细攻略目录YOLOv8的简介YOLOv8的安装和使用方法YOLOv8的案例应用YOLOv8的简介2023年1月11日,Ultralytics重磅发布YOLOv8。U... [详细]
赞
踩
- AndroidStudio是专为Android应用程序开发而设计的官方集成开发环境(IDE)。它提供了丰富的工具和功能,帮助开发者更高效地构建出色的应用程序。本文将为您提供AndroidStudio的安装文档基础指南,帮助您顺利安装并开始使... [详细]
赞
踩

