
- 1在安卓手机搭建kali环境,手机变成便携式渗透神器_kali linux手机版
- 2Golang:sync.Map_golang sync.map
- 3S5P6818裸机开发(1)-启动过程分析_s5p6818直接在sd卡运行
- 4Python 深度学习框架之keras库详解
- 5【Python数据结构与算法】—— 搜索算法 | 期末复习不挂科系列
- 6使用Vue-PDF实现预览、翻页、放大缩小、侧边栏预览
- 7挑战Open AI!!!马斯克宣布成立xAI._智能船舶发展白皮书——远洋船舶篇
- 8linux基于mosquitto搭建MQTT服务器集群_mosquitto 集群
- 9微信小程序详细登录流程(图解+代码流程)_小程序登录
- 10Unity3D Update和FixedUpdate的区别及深入探讨_unity update fixedupdate
普通查询、排序与分页查询、分组查询、子查询(内查询)、连接之 LEFT JOIN、RIGHT JION、INNER JOIN_oracle left join(子查询)
赞
踩
普通查询
查询所有信息
- SELECT 列名1, 列名2, … FROM 表名(执行速度比较快,尽量用这个)
- SELECT * FROM 表名
过滤查询
- 使用WHERE子句,将不满足条件的行过滤掉
- 在增加、删除、查找、修改数据之前可以先使用WHERE子句进行过滤记录
- 例如:INSERT INTO emp(id, name, sal, hire_date) SELECT employee_id, last_name, salary, hire_date FROM employees WHERE 子句;
空值参与运算
- 所有运算符(除 || 外)或列值遇到null值,运算的结果都为null。
- 在 Oracle/Mysql 里面, 空值NULL不等于空字符串。一个空字符串的长度是 0,而一个空值的长度是空。

- 空值是占用空间的。
- 当为null的字段在一条记录的最后,就是说他后边没有非null的字段值时,是不占空间的
- 当为null的字段在一条记录的中间,就是说他后边还有非null的字段值时,他占一个字节
列的别名
- SELECT 列名1 (AS) “列别名1” FROM 表名
- AS 可以省略
- 别名可以使用双引号,以便在别名中包含空格或特殊的字符并区分大小写。
连接符 ||
- 连接符||:使||两边进行拼接,两边可以为任意的数据类型的数据。比如说:
- 列与列之间的合并:如 SELECT empno||ename FROM emp;则会出现类似7369SMI的结果
- 列与字符[串]的合并:如SELECT ‘id:’ || empno || ’,name is’ || ename FROM emp
去掉重复行 DISTINCT
- 只能放在第一列的前面,如 SELECT DISTINCT ename, job FROM emp,但是SELECT ename, DISTINCT job FROM emp 会报错
- DISTINCT 其实是对后面所有列名的组合进行去重
算术运算符
- 尽量用12 * sal,把常量写在前面,效率较高。Sal * 12效率会较低。
- 时间数据也可以进行加减
逻辑运算符
AND、OR、NOT、BETWEEN AND、IN、LIKE、IS NULL
IN(写成IN[5,20]在此区间范围内)
LIKE:%:任意个数的任意字符 :表示一个字符
IS NULL
9.逻辑运算符
AND、OR、NOT、BETWEEN AND、IN、LIKE、、IS NULL
IN(写成IN[5,20]在此区间范围内)
LIKE:%:任意个数的任意字符
_:表示一个字符
IS NULL
case when then else end
https://blog.csdn.net/konglongaa/article/details/80250253
case具有两种格式:简单case函数、case搜索函数。
简单case函数:
case sex
when '1' then '男'
when '2' then '女'
else '其他' end
- 1
- 2
- 3
- 4
case搜索函数:
case when sex = '1' then '男'
when sex = '2' then '女'
else '其他' end
- 1
- 2
- 3
这两种方式,可以实现相同的功能。简单case函数的写法相对比较简洁,但是和case搜索函数相比,功能方面会有些限制,比如写判定式。
还有一个需要注重的问题,case函数只返回第一个符合条件的值,剩下的case部分将会被自动忽略。比如说,下面这段sql,你永远无法得到“第二类”这个结果
case when col_1 in ('a', 'b') then '第一类' //比如这个判定就是简单case函数不能实现的
when col_1 in ('a') then '第二类'
else '其他' end
- 1
- 2
- 3
排序与分页查询
排序
- SELECT 列名1, 列名2 FROM 表名 ORDER BY 排序列名1 [ASC/DESC],排序列名2 [ASC/DESC]。
- ORDER BY 子句在 SELECT 语句的结尾。默认是升序 ASC
- 可以使用不在 SELECT 列表中的列排序
- 在对多列进行排序的时候,首先排序的第一列必须有相同的列值,才会对第二列进行排序。如果第一列数据中所有值都是唯一的,将不再对第二列进行排序。
分页查询
什么是分页
为了便于在网页显示数据,常常要将数据量大的数据进行分页显示。分页就是根据给出的区间查询不同区间的数据,让数据呈现出一页一页的形式。
Oracle 实现分页
Oracle中通过ROWNUM实现分页,ROWNUM是一个伪列,在普通的查询中是不可见的,需要取出数据后ROWNUM才会有值。
https://blog.csdn.net/weixin_43525116/article/details/85006795?spm=1001.2101.3001.6661.1&utm_medium=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-85006795-blog-91410802.topnsimilarv1&depth_1-utm_source=distribute.pc_relevant_t0.none-task-blog-2%7Edefault%7ECTRLIST%7ERate-1-85006795-blog-91410802.topnsimilarv1&utm_relevant_index=1

SELECT rownum, employee_id, last_name,salary
FROM(
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC
)
WHERE rownum <= 10
- 1
- 2
- 3
- 4
- 5
- 6
- 7
因为不能使用 > 所以只能再查询一次把rownum变成一个真实的列
SELECT rn, employee_id, last_name,salary
FROM(
SELECT rownum rn, employee_id, last_name,salary
FROM(
SELECT employee_id,last_name,salary
FROM employees
ORDER BY salary DESC
)
)
WHERE rn > 40 and rn <= 50
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
一个数据库的分页查询:对Oracle数据库中记录进行分页,每页显示10条记录, 查询第5页的数据
select employee_id, last_name, salary
from (
select rownum rn, employee_id, last_name, salary
from employees
) e
where e.rn <= 50 and e.rn > 40
- 1
- 2
- 3
- 4
- 5
- 6
这是一个通用的格式, 对Oracle分页必须使用ROWNUM伪列
select employee_id, last_name, salary
from (
select rownum rn, employee_id, last_name, salary
from employees
) e
where e.rn <= pageNo * pageSize and e.rn > (pageNo - 1) * pageSize
- 1
- 2
- 3
- 4
- 5
- 6
分组查询
分组:GROUP BY子句
- 可以使用GROUP BY子句将表中的数据分成若干组
- 在带有GROUP BY子句的查询语句中,在SELECT列表中指定的列要么是GROUP BY子句中指定的列,要么包含聚合函数。而在MYSQL中则没有强制性要要求,没有强调SELECT指定的字段必须属于GROUP BY后的条件。
- 如果你想进行多个分组就在GROUP BY后面添加想要分组的组名就可以了
单个分组:

多个分组:
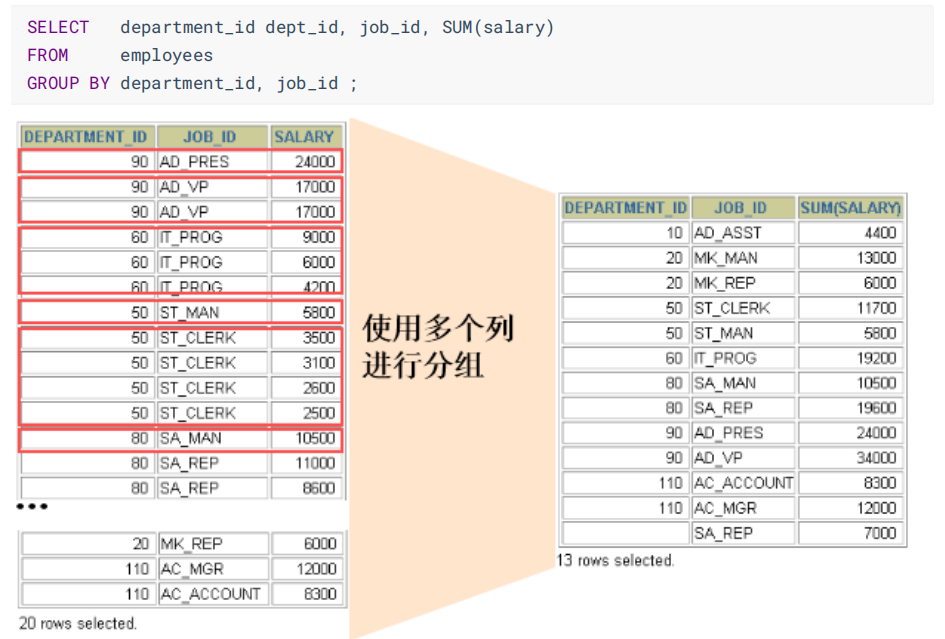
过滤分组:HAVING子句
- HAVING 不能单独使用,必须要跟 GROUP BY 一起使用
- 不能在WHERE子句中使用聚合函数,但是可以在having子句中使用聚合函数
- HAVING 可以把分组计算的函数和分组字段作为筛选条件
//求出各部门中平均工资大于6000的部门,以及其平均工资
SELECT department_id, AVG(salary)
FROM employees
GROUP BY department_id
HAVING AVG(salary) > 6000
- 1
- 2
- 3
- 4
- 5
WHERE和HAVING的对比
- 区别1:
- WHERE 可以直接使用表中的字段作为筛选条件,但不能使用分组中的计算函数作为筛选条件;
- HAVING 必须要与 GROUP BY 配合使用,可以把分组计算的函数和分组字段作为筛选条件。
- 区别2:
- 如果需要通过连接从关联表中获取需要的数据,WHERE 是先筛选后连接,而 HAVING 是先连接后筛选。
子查询(内查询)
子查询指一个查询语句嵌套在另一个查询语句内部的查询。SQL 中子查询的使用大大增强了SELECT 查询的能力,因为很多时候查询需要从结果集中获取数据,或者需要从同一个表中先计算得出一个数据结果,然后与这个数据结果(可能是某个标量,也可能是某个集合)进行比较。
子查询的基本使用
- 非关联子查询在主查询(外查询)之前一次执行完成,子查询要包含在括号内,通常在右侧(非强制)
- 子查询中不需要ORDER BY 子句(非强制)
- 子查询的结果被主查询(外查询)使用。
- 单行操作符对应单行子查询,多行操作符对应多行子查询,单行和多行子查询的时候要注意空值的问题
- 如果子查询未返回任何行,则主查询也不会返回任何结果(空值)
子查询的分类
- 按子查询的结果返回一条还是多条记录,将子查询分为单行子查询 、 多行子查询
- 按子查询返回单列记录还是多列记录,将子查询分为单列子查询、多列子查询
- 按内查询是否被执行多次,将子查询划分为关联子查询、非关联子查询。
- 最大的区别在于,是否在内查询中用到了外查询的表、字段等。
单行子查询
子查询结果只有一个,主要和<> = <= >= !=等运算符组合使用
题目:返回公司工资最少的员工的last_name,job_id和salary
SELECT last_name, job_id, salary
FROM employees
WHERE salary =
(SELECT MIN(salary)
FROM employees);
- 1
- 2
- 3
- 4
- 5
题目:查询最低工资大于50号部门最低工资的部门id和其最低工资
SELECT department_id, MIN(salary)
FROM employees
GROUP BY department_id
HAVING MIN(salary) >
(SELECT MIN(salary)
FROM employees
WHERE department_id = 50);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
多行子查询
- 子查询结果是多行。IN;ANY、ALL和关系运算符>、>=、=、<、<=来组合使用
- IN 等于列表中的任意一个
- ANY 和子查询返回的某一个值比较(< ANY 小于最大,> ANY 大于最小,…)
- ALL 和子查询返回的所有值比较(< ALL 小于最小,> ALL 大于最大,…)
题目:返回其他部门中比 job_id 为 ’IT_PROG’ 部门任一工资低的员工的员工号、姓名、job_id、salary
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE job_id <> 'IT_PROG'
AND salary < ANY (SELECT salary
FROM employees
WHERE job_id ='IT_PROG')
- 1
- 2
- 3
- 4
- 5
- 6
题目:返回其他部门中比job_id为’IT_PROG’部门所有工资低的员工的员工号姓名、job_id、salary
SELECT employee_id, last_name, job_id, salary
FROM employees
WHERE job_id <> 'IT_PROG'
and salary < ALL(SELECT salary
FROM employees
WHERE job_id ='IT_PROG')
- 1
- 2
- 3
- 4
- 5
- 6
单列子查询和多列子查询
主查询与子查询返回的多个列进行比较
题目:查询与141号或174号员工的 manager_id 和 department_id 相同的其他员工的employee_id, manager_id,department_id
//单列子查询
SELECT employee_id, manager_id, department_id
FROM employees
WHERE manager_id IN
(SELECT manager_id
FROM employees
WHERE employee_id IN (174,141))
AND department_id IN
(SELECT department_id
FROM employees
WHERE employee_id IN (174,141))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
//多列子查询(列与列要一一对应,并且两边要有括号)
SELECT employee_id, manager_id, department_id
FROM employees
WHERE (manager_id, department_id) IN
(SELECT manager_id, department_id
FROM employees
WHERE employee_id IN (141,174))
AND employee_id NOT IN (141,174);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
题目:显式员工的employee_id,last_name和location。其中,若员工 department_id 与 location_id 为1800 的 department_id 相同,则 location 为 ’Canada’,其余则为 ’USA’。
//单列子查询
//简单case语句,其实就是等于条件的case搜索语句,所以WHEN后必须为单行子查询
SELECT employee_id, last_name,
(CASE department_id
WHEN (SELECT department_id
FROM departments
WHERE location_id = 1800)
THEN 'Canada' ELSE 'USA' END) location
FROM employees;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
//多列子查询
//case搜索语句,WHEN后可以自定义判断条件,所以WHEN后可以单行子查询,也可以为多行子查询
SELECT employee_id, last_name,
(CASE
WHEN (department_id, last_name) in
(SELECT department_id, last_name
FROM departments
WHERE location_id = 1800)
THEN 'Canada' ELSE 'USA' END) location
FROM employees;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
关联子查询
更多更详细见:https://blog.csdn.net/tanx17/article/details/107921091
如果子查询的执行依赖于外部查询,通常情况下都是因为子查询中的表用到了外部的表,并进行了条件关联,因此每执行一次外部查询,子查询都要重新计算一次,这样的子查询就称之为关联子查询。相关子查询按照一行接一行的顺序执行,主查询的每一行都执行一次子查询。
题目:返回比本部门平均工资高的员工的last_name,department_id,salary及平均工资
//方法1:相关子查询
SELECT last_name, department_id, salary,
(SELECT AVG(salary) FROM employees e3
WHERE e1.department_id = e3.department_id
GROUP BY department_id) avg_salary
FROM employees e1
WHERE salary >
(SELECT AVG(salary)
FROM employees e2
WHERE e1.department_id = e2.department_id
)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
//方法2:在FROM后使用普通子查询
SELECT a.last_name, a.salary, a.department_id, b.salavg
FROM employees a, (SELECT department_id,
AVG(salary) salarg
FROM employees
GROUP BY department_id) b
WHERE a.department_id = b.department_id
AND a.salary > b.salavg;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
题目:若employees表中employee_id与job_history表中employee_id相同的数目不小于2,输出这些相同id的员工的employee_id,last_name和其job_id。
SELECT e.employee_id, last_name,e.job_id
FROM employees e
WHERE 2 <= (SELECT COUNT(*)
FROM job_history
WHERE employee_id = e.employee_id);
- 1
- 2
- 3
- 4
- 5
在 ORDER BY 后使用子查询(必须是单行子查询,即返回一个结果)
题目:查询员工的employee_id,last_name,要求按照员工的department_name排序
//在ORDER BY后关联子查询
SELECT employee_id, last_name
FROM employees e
ORDER BY
(SELECT department_name
FROM departments d
WHERE e.department_id = d.department_id);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
EXISTS 与 NOT EXISTS 关键字
关联子查询通常也会和 EXISTS、NOT EXISTS操作符一起来使用,用来检查在子查询中是否存在满足条件的行。EXISTS关键字表示如果存在某种条件,则返回TRUE,否则返回FALSE。
题目:查询公司管理者的employee_id,last_name,job_id,department_id信息
//方式一:EXISTS + 子查询
SELECT employee_id, last_name, job_id, department_id
FROM employees e1
WHERE EXISTS (SELECT *
FROM employees e2
WHERE e2.manager_id =
e1.employee_id);
- 1
- 2
- 3
- 4
- 5
- 6
- 7
//方式二:自连接
SELECT DISTINCT e1.employee_id, e1.last_name, e1.job_id, e1.department_id
FROM employees e1 JOIN employees e2
WHERE e1.employee_id = e2.manager_id;
- 1
- 2
- 3
- 4
//方式三:
SELECT employee_id, last_name, job_id, department_id
FROM employees e1
WHERE employee_id IN (
SELECT DISTINCT manager_id
FROM employees);
- 1
- 2
- 3
- 4
- 5
- 6
关联更新
使用关联子查询依据一个表中的数据更新另一个表的数据。
UPDATE table1 alias1
SET column = (SELECT expression
FROM table2 alias2
WHERE alias1.column = alias2.column);
- 1
- 2
- 3
- 4
关联删除
使用关联子查询依据一个表中的数据删除另一个表的数据。
DELETE FROM table1 alias1
WHERE column operator (SELECT expression
FROM table2 alias2
WHERE alias1.column = alias2.column);
- 1
- 2
- 3
- 4
自连接和子查询谁效率高
自连接:指两张表结构和数据内容完全一样的表,在做数据处理的时候,我们通常会给它们分别重命名来加以区分,然后进行关联。
题目中可以使用子查询,也可以使用自连接。一般情况建议你使用自连接,因为在许多 DBMS 的处理过程中,对于自连接的处理速度要比子查询快得多。
可以这样理解:子查询实际上是通过未知表进行查询后的条件判断,而自连接是通过已知的自身数据表进行条件判断,因此在大部分 DBMS 中都对自连接处理进行了优化。
Sql 连接之 LEFT JOIN、RIGHT JION、INNER JOIN
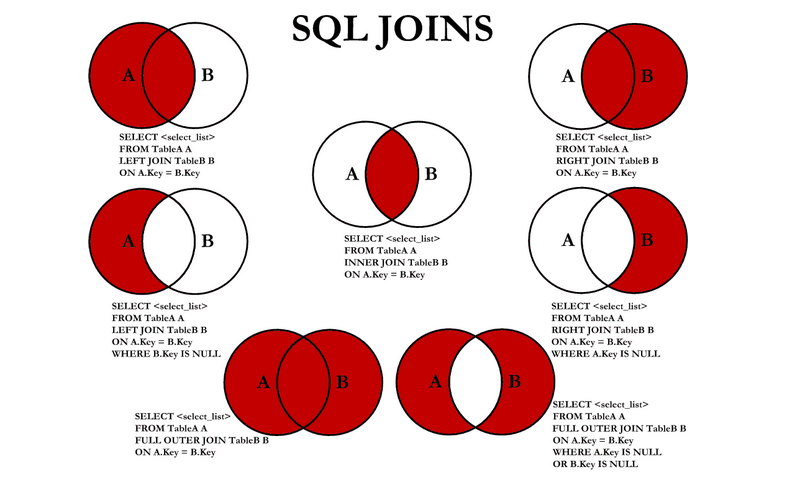
left join(左连接) 返回包括左表中的所有记录和右表中联结字段相等的记录
right join(右连接) 返回包括右表中的所有记录和左表中联结字段相等的记录
inner join(等值连接) 只返回两个表中联结字段相等的行
![[Oracle] instant client 21 和 PLSQL Developer 14 安装与详细配置_plsqldeveloper安装配置教程](https://img-blog.csdnimg.cn/3ff9cfd24e374d35ae37c8f31b170cad.png?x-oss-process=image/resize,m_fixed,h_300,image/format,png) PLSQLDeveloper14官方自带中文,这里笔者使用的客户机是win10系统,oracle数据库服务器操作系统是winserver2003,oracle数据库是10.0.2版本。_plsqldeveloper安装配置教程plsqlde... [详细]
PLSQLDeveloper14官方自带中文,这里笔者使用的客户机是win10系统,oracle数据库服务器操作系统是winserver2003,oracle数据库是10.0.2版本。_plsqldeveloper安装配置教程plsqlde... [详细]赞
踩
- 一.介绍使用kubeadm部署k8s集群的步骤:第一步:是在机器上部署容器运行时(docker,containerd等);第二步:然后部署kubeadm,kubelet,kubectl这三个服务;第三步:使用kubeadminit部署mas... [详细]
赞
踩
- 【声明】文章仅供学习交流,观点代表个人,与任何公司无关。编辑|SQL和数据库技术(ID:SQLplusDB)【Oracle】如何给物化视图分区文章目录【Oracle】如何给物化视图分区给物化视图进行分区的例【声明】文章仅供学习交流,观点代表... [详细]
赞
踩
 Oracle表连接、内连接、外连接(左连接、右连接、全连接)、隐式连接、表并集、表交集、表补集_oracleinnerjoinoracleinnerjoinOracle表连接、内连接、外连接(左连接、右连接、全连接)、隐式连接、表并集、表交... [详细]
Oracle表连接、内连接、外连接(左连接、右连接、全连接)、隐式连接、表并集、表交集、表补集_oracleinnerjoinoracleinnerjoinOracle表连接、内连接、外连接(左连接、右连接、全连接)、隐式连接、表并集、表交... [详细]赞
踩
- article
pyinstaller打包Mediapipe遇到的Failed to execute script_binary_graph_path=os.path.join(root_path, binary_g
背景IDE使用Pycharm,Anaconda3安装的Python版本是3.8,在此基础上通过Pycharm安装了Opencv4.5.2.32和Mediapipe0.8.4.2.在Pycharm的环境运行python是正常的,但是使用pyi... [详细]赞
踩
- NameExpandedNameShortDescriptionLongDescriptionExternalPropertiesABMRAutoBMRBackgroundProcessCoordinatesexecutionoftasks... [详细]
赞
踩
 【ORACLE】查看正在运行的的SQL【全】_oracle查询正在执行的sqloracle查询正在执行的sql文章目录前言1、查看Oracle正在执行的sql语句1.1、杀死进程1.2、若利用步骤2命令kill一个进程后,进程状态被置为"k... [详细]
【ORACLE】查看正在运行的的SQL【全】_oracle查询正在执行的sqloracle查询正在执行的sql文章目录前言1、查看Oracle正在执行的sql语句1.1、杀死进程1.2、若利用步骤2命令kill一个进程后,进程状态被置为"k... [详细]赞
踩
- 修改system文件编辑/etc/system文件,添加下行setnoexec_user_stack=13.2创建project检查用户配置文件#id-poracleuid=101(oracle)gid=103(oinstall)proji... [详细]
赞
踩
- JBSQLX工作日加班:3双休日加班:2节日加班:1现在想查询出结果时直接能看到是什么假期SELECT SPONSOR_NAMEAS姓名,CASE JBSQLX WHEN3THEN '工作日加班' WHEN2THEN '双休日加班... [详细]
赞
踩
- 现在有两张表,部门表,和用户表现在需要查询出各个部门里面女性的数量下面两种写法对比下就知道了SELECT a.NAME, count(b.xb)AS女性人数FROM orga LEFTJOINuser_bbONa.`name`=b.bm A... [详细]
赞
踩

