
- 1【大厂AI课学习笔记】1.4 算法的进步(4)关于李飞飞团队的ImageNet
- 2download.js实现下载的基本用法_downloadjs
- 3Win10系统安装打印机提示未安装打印机驱动程序,试图将驱动程序添加到存储区_未安装打印机驱动程序,试图将驱动程序添加
- 4Python爬虫--爬取哔哩哔哩(B站)短视频平台视频_b站视频爬取
- 5鸿蒙应用开发学习|HarmonyOS是什么
- 6Flink实时数仓同步:流水表实战详解
- 7MVP与MVC的区别_mvp mvc 区别
- 8【EasyExcel-Alibaba】在Java中操作Excel 完成数据的导入导出_com.yeahka.easyexcel.util.easyexcelutil
- 9codeforces230 B. T-primes 【思维 + 打表】_input 3 4 5 6 output yes no no note the given test
- 10自然语言处理的巅峰:深度学习与大数据的奇迹
hadoop2.6.3学习第二节:安装和配置_ask your administrator to install one of them
赞
踩
本节主要是参考了别人的构建方案,然后自己配置的时候优化了一下。
安装过程主要有以下几个步骤:
一、建立hadoop运行帐号
分别运行下面命令
sudo groupadd hadoop 创建用户组
sudo useradd hadoop -g hadoop 创建用户
cd /home/ 切换用户目录
sudo mkdir hadoop/ 创建hadoop目录
sudo chown -R hadoop:hadoop hadoop/ 设置目录的所有者为hadoop用户
执行完上面,运行帐号的建立就完成了
二、安装虚拟机jdk
这里安装的版本是:jdk-8u72-linux-x64.gz
上传文件方式两种:FTP和rz/sz上传和下载工具
sudo apt-get install lrzsz 开启rz/sz上传下载功能,用rz选择文件上传至linux
sudo tar -zxvf jdk-8u72-linux-x64.gz -C /opt/ 命令将其解压到/opt目录下
sudo mv jdk1.8.0_72 java文件夹重命名为java
配置环境变量了,使用vi /etc/profile命令编辑添加如下内容:
export JAVA_HOME=/opt/java/
export PATH=$JAVA_HOME/bin:$PATH
配置好之后要用命令source /etc/profile使配置文件生效
使用命令sudo chown -R hadoop:hadoop java/将所有者设置为hadoop
这样jdk就安装完毕了,检查jdk环境变量是否配置正确,输入java -version,如下图,则安装配置成功

二、hadoop的安装
下载hadoop-2.6.3.tar.gz,点击下载
先解压到hadoop目录下,sudo tar -zxvf hadoop-2.6.3.tar.gz -C /home/hadoop/
然后设置所有者,sudo chown -R hadoop:hadoop hadoop-2.6.3/
再vi /etc/profile配置环境变量
新增:export HADOOP_HOME=/home/hadoop/hadoop-2.6.3
修改:export PATH=$JAVA_HOME/bin:$PATH:$HADOOP_HOME/bin
使用source /etc/profile使配置生效。安装方法和jdk类似。
三、配置hadoop-2.6.3
cd etc/hadoop/
配置 hadoop-env.sh文件-->修改JAVA_HOME
export JAVA_HOME=/home/java/
配置 yarn-env.sh 文件-->>修改JAVA_HOME
export JAVA_HOME=/home/java/
配置slaves文件-->>增加slave节点
slave1
slave2
配置 core-site.xml文件-->>增加hadoop核心配置(hdfs文件端口是9000、file:/home/spark/opt/hadoop-2.6.0/tmp、)
- <configuration>
- <property>
- <name>fs.defaultFS</name>
- <value>hdfs://master:9000</value>
- </property>
- <property>
- <name>io.file.buffer.size</name>
- <value>131072</value>
- </property>
- <property>
- <span style="white-space:pre"> </span><!--指定hadoop的工作目录 -->
- <name>hadoop.tmp.dir</name>
- <value>file:/home/hadoop/hadoop-2.6.3/tmp</value>
- <description>Abasefor other temporary directories.</description>
- </property>
- <property>
- <name>hadoop.proxyuser.spark.hosts</name>
- <value>*</value>
- </property>
- <property>
- <name>hadoop.proxyuser.spark.groups</name>
- <value>*</value>
- </property>
- </configuration>
配置 hdfs-site.xml 文件-->>增加hdfs配置信息(namenode、datanode端口和目录位置)
- <configuration>
- <pre name="code" class="html" style="font-size: 13.3333px;"><!--指定<span style="font-size: 13.3333px; font-family: Arial, Helvetica, sans-serif;">secondnamenode,建议和master不在一个机器保证数据安全</span> -->
- <property> <name>dfs.namenode.secondary.http-address</name> <value>slave1:9001</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/hadoop/hadoop-2.6.3/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/hadoop/hadoop-2.6.3/dfs/data</value> </property> <property>
- <pre name="code" class="html" style="font-size: 13.3333px;"><!--设置datanode的数量,除了master以外-->
- <name>dfs.replication</name> <value>2</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property></configuration>
配置 mapred-site.xml 文件-->>增加mapreduce配置(使用yarn框架、jobhistory使用地址以及web地址)
- <configuration>
- <property>
- <name>mapreduce.framework.name</name>
- <value>yarn</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.address</name>
- <value>master:10020</value>
- </property>
- <property>
- <name>mapreduce.jobhistory.webapp.address</name>
- <value>master:19888</value>
- </property>
- </configuration>
- <configuration>
- <property>
- <name>yarn.nodemanager.aux-services</name>
- <value>mapreduce_shuffle</value>
- </property>
- <property>
- <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
- <value>org.apache.hadoop.mapred.ShuffleHandler</value>
- </property>
- <property>
- <name>yarn.resourcemanager.address</name>
- <value>master:8032</value>
- </property>
- <property>
- <name>yarn.resourcemanager.scheduler.address</name>
- <value>master:8030</value>
- </property>
- <property>
- <name>yarn.resourcemanager.resource-tracker.address</name>
- <value>master:8035</value>
- </property>
- <property>
- <name>yarn.resourcemanager.admin.address</name>
- <value>master:8033</value>
- </property>
- <property>
- <name>yarn.resourcemanager.webapp.address</name>
- <value>master:8088</value>
- </property>
- </configuration>

配置方面到这里先结束。
三、克隆虚拟机
关闭"VMware Workstation上面的master虚拟机。
然后右键这个虚拟机-->管理-->克隆

一直下一步,到下图位置停下来,选择“创建完整克隆”

这里名称选择slave1,点击完成后,重新再重复一遍复制一个slave2

克隆好之后,分别进入机器,重命名机器名。因为是克隆的,默认的名字都会和原来的名字一样。
vim /etc/hostname 分别命名机器为slave1,slave2
使用ifconfig 查看3太机器的ip地址,然后分别在三台机器下配置hosts文件

hosts文件路径为;/etc/hosts,我的hosts文件配置如下,大家可以参考自己的IP地址以及相应的主机名完成配置

至此,3台服务器都准备好了。
四、格式化namenode
格式化namenode:进入master主机的hadoop-2.6.3目录下:./bin/hdfs namenode -format,出现如下界面基本完成

五、启动hadoop
这一步也在主结点master上进行操作:
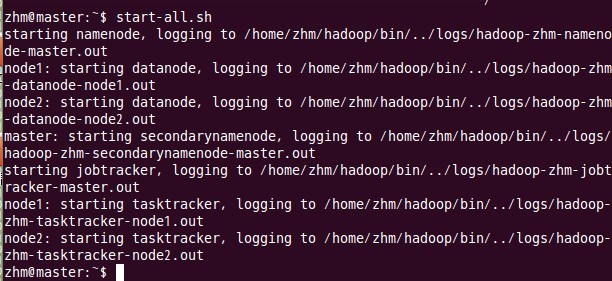
六、 用jps检验各后台进程是否成功启动
在主结点master上查看namenode,jobtracker,secondarynamenode进程是否启动。

如果出现以上进程则表示正确。
不出现则:ufw disable 关闭防火墙
如果jps指令输入后
七、 通过网站查看集群情况
在浏览器中输入:http://192.168.23.128:8088/,网址为master结点所对应的IP:

在浏览器中输入:http://192.168.1.100:50070,网址为master结点所对应的IP:

至此,hadoop2.6.3的完全分布式集群安装已经全部完成,
- article
【ERROR】chaincode install failed with status: 500 - failed to invoke backing implementation xxx
Error:chaincodeinstallfailedwithstatus:500-failedtoinvokebackingimplementationof'InstallChaincode':couldnotbuildchaincod... [详细]赞
踩
- xcodeiOS17.2notinstall,Simulator手动安装_ios17.2simulatorios17.2simulatorxcodeiOS17.2notinstall,Simulator手动安装参考文档xcode又又又升级了... [详细]
赞
踩
- 利用机器学习sklearn构建模型与实现,讲述了机器学习的概念和学习用例,sklearn的概念,安装和使用,这里举例了波士顿数据集的例子讲述sklearn转换器处理数据的方法以及构建并评价回归模型。_condainstallsklearnc... [详细]
赞
踩
- 在IntelCPU的Windows电脑下,启动模拟器失败,提示“UnabletoinstallHAXM.”,无法安装HAXM。打开控制面板>程序>程序与功能>启动或关闭Winodows功能,找到并取消勾选“Hyper-V”,点击确定并重启电... [详细]
赞
踩
- 在使用Maven对项目或模块进行编译(compile)、安装(install)、打包(package)等操作,单元测试没必要编译,设置跳过单元测试可以增加编译速度、也可以防止出现一些奇怪的异常现象。1、Idea可视化跳过。2、使用命令参数跳... [详细]
赞
踩
- 网络通讯Linux中最基本基本的功能之一,很多是时候我们需要获取Linux的网络信息。Linux中存在很多网络监控工具,本文就给大家介绍一下,Linux常见的网络监控工具。NetstatNetstat是Linux下全能的网络监控工具,可以监... [详细]
赞
踩
- 在Fedora23上安装Codelocks16.01的过程。1.安装gcc,需要c和c++两部分dnfinstallgccdnfinstallgcc-c++2.安装gtk2-devel,因为默认已经安装了正式产品需要的支持库,但是没有安装开... [详细]
赞
踩
- Pleaseaskyouradministratortoinstallthepackageunzip_askyouradministratoraskyouradministratorPleaseaskyouradministratortoi... [详细]
赞
踩
- 我在构建一个vue项目时,npminstall卡住不动,卡住的地方控制台信息是reify:rxjs:timingreifyNode:node_modules/listr/node_modules/rxjs原因:文件缓存问题或镜像仓库网络问题... [详细]
赞
踩
- reify:lodash:timingreifyNode:node_modules/@types/nodeCompletedin578ms_npminstallelectron卡住不动npminstallelectron卡住不动问题今天在使... [详细]
赞
踩
- article
2021-09-16 npm install @vuecli 卡在了 reifyrxjs timing reifyNode node_modules@vueclinode_modules_reify:rxjs: timing reifynode:node_modules/core-js
npminstall@vue/cli卡在了reify:rxjs:timingreifyNode:node_modules/@vue/cli/node_modules/....随后产生报错查了一堆东西,后来发现其主要原因在于npm镜像源的问题... [详细]赞
踩
- article
npm install 卡在了 reify:rxjs: timing reifyNode,出现 gyp ERR find Python、gyp ERR find VS_reify:fsevents: timing reifynode:node_modules/jest
前言最近跑一个vue的项目,第一步肯定是npminstall,结果就出现我标题上写的那些情况,经过一番搜索,网上一堆方法尝试了,有说叫你用管理员权限运行npminstall--global--productionwindows-build-... [详细]赞
踩
- nvm_nvminstall报错nvminstall报错前言如果只安装一个版本的node,可能会在运行一些vue项目时报错比如:node版本过低时:SyntaxError:Unexpectedtoken'.'语法错误->ES特性不支持... [详细]
赞
踩
- pipinstall报错:MicrosoftVisualC++14.0isrequired_pip需要visualstudiopip需要visualstudio目录问题现象 解决办法:1.下载文件包2.安装3.安装好之后问题现象p... [详细]
赞
踩
- pipinstallpygame报错解决方案_error:subprocess-exited-with-error脳pythonsetup.pyegg_infodidnotrunerror:subprocess-exited-with-er... [详细]
赞
踩
- article
【报错】Solved — pip install torch-scatter==2.0.5 及 pip install torch-sparse==0.6.8 报错_nvidia geforce rtx 4090 with cuda capability sm_89
【代码】【报错】Solved—pipinstalltorch-scatter==2.0.5及pipinstalltorch-sparse==0.6.8报错。_nvidiageforcertx4090withcudacapabilitysm_... [详细]赞
踩
- Python版本带来的系列问题_pipinstallsubprocesspipinstallsubprocess工作搞AirTest时遇到pip安装的系列问题。pipinstall安装公司源时,先遇到这个错:按照提示,更新了pip最新版D:... [详细]
赞
踩
- article
pip install celery-with-redis出错error in anyjson setup command: use_2to3 is invalid._python38 pip install celery报错
pipinstallcelery-with-redis出错errorinanyjsonsetupcommand:use_2to3isinvalid.它会先安装依赖包anyjson**主要原因是在setuptools58之后的版本已经废弃了u... [详细]赞
踩
- 本文主要介绍了pipinstallmysql出现error:subprocess-exited-with-error的解决方案,希望能对使用mysql的同学们有所帮助。文章目录1.问题描述2.解决方案_pipinstallmysql出现er... [详细]
赞
踩
- article
解决git clone或者pip install git+https://github.com/ruotianluo/meshed-memory-transformer.git出现的一系列问题_error: subprocess-exited-with-error 脳 git clone --
方法2:在https:后加入gitclone.com。方法1:将命令https改为git。将setuptools包删除。_error:subprocess-exited-with-error脳gitclone--filter=blob:no... [详细]赞
踩

