
- 1【ChatGPT实战】7.使用ChatGPT自动化操作Excel_chat gpt怎么自动填写表格
- 2【深度学习】AlexNet CIFAR-10从70%到86%:CNN调参经验总结_cifar10 cnn loss下降慢
- 3【动态规划】【字符串】【行程码】1531. 压缩字符串
- 4【验证码逆向专栏】某验全家桶细节避坑总结_空间推理验证码识别
- 5python-scipy 生成巴特沃斯带通滤波器_butterbandpassfilter(low1,high1,isamplerate,order=
- 6Avalonia学习实践(二)--跨平台支持及发布_avalonia 安卓
- 7AI项目八:yolo5+Deepsort实现目标检测与跟踪(CPU版)_yolov5 目标检测cpu
- 8java中stream流_java stream流
- 9【融云分析】选择IM云服务,需要看哪些核心技术指标?
- 10地摊经济火了!手把手教程序员摆地摊如何月入9万_一边写程序一边摆地摊
LeetCode专题:栈和队列(持续更新,已更17题)_栈和队列大学生程序设计比赛题库
赞
踩
目录
LeetCode150.逆波兰表达式求值:
问题描述:
根据 逆波兰表示法,求表达式的值。
有效的算符包括
+、-、*、/。每个运算对象可以是整数,也可以是另一个逆波兰表达式。注意 两个整数之间的除法只保留整数部分。
可以保证给定的逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。(逆波兰表示法不用熟记)
输入:tokens = ["2","1","+","3","*"] 输出:9 解释:该算式转化为常见的中缀算术表达式为:((2 + 1) * 3) = 9
代码分析:
了解stoi()函数。
Java中自带栈结构:
- Deque<Integer> stack = new LinkedList<Integer>();
- push() pop()
Stack作为java语言的栈,是被诟病的地方,作为栈数据结构,却继承了vector,对外暴露了get(index)这样的方法,不是一种合理的实现方式,所以后来java开发提倡使用ArrayDeque。
- A more complete and consistent set of LIFO stack operations is
- provided by the {@link Deque} interface and its implementations, which
- should be used in preference to this class. For example:
-
- Deque<Integer> stack = new ArrayDeque<Integer>();
C++版:
- class Solution {
- public:
- int evalRPN(vector<string>& tokens) {
- //自带栈
- stack<long> sta;
- for (string& str: tokens) {
- if (str.size() >= 2 || str[0] >= '0') //是数字的判断条件
- //判断条件可改为"不等于+-*/"
- //stoi()将字符串转换为数字
- sta.emplace((long)stoi(str));
- else {
- long b = sta.top(); sta.pop();
- long a = sta.top(); sta.pop();
- switch (str[0]) {
- case '+': sta.emplace(a+b); break;
- case '-': sta.emplace(a-b); break;
- case '*': sta.emplace(a*b); break;
- case '/': sta.emplace(a/b); break;
- }
- }
- }
- return sta.top();
- }
- };

Java版:
- class Solution {
- public int evalRPN(String[] tokens) {
- //Java中string数组是可变长度的
- Deque<Integer> stack = new LinkedList<Integer>();
- int n = tokens.length;
- for (int i = 0; i < n; i++) {
- String token = tokens[i];
- if (isNumber(token)) {
- //string转为Integer
- stack.push(Integer.parseInt(token));
- } else {
- int num2 = stack.pop();
- int num1 = stack.pop();
- switch (token) {
- case "+":
- stack.push(num1 + num2);
- break;
- case "-":
- stack.push(num1 - num2);
- break;
- case "*":
- stack.push(num1 * num2);
- break;
- case "/":
- stack.push(num1 / num2);
- break;
- default:
- }
- }
- }
- return stack.pop();
- }
-
- public boolean isNumber(String token) {
- return !("+".equals(token) || "-".equals(token) || "*".equals(token) || "/".equals(token));
- }
- }
LeetCode225.用队列实现栈:
问题描述:
请你仅使用两个队列实现一个后入先出(LIFO)的栈,并支持普通栈的全部四种操作(
push、top、pop和empty)。实现
MyStack类:
void push(int x)将元素 x 压入栈顶。int pop()移除并返回栈顶元素。int top()返回栈顶元素。boolean empty()如果栈是空的,返回true;否则,返回false。注意:
- 你只能使用队列的基本操作 —— 也就是
push to back、peek/pop from front、size和is empty这些操作。- 你所使用的语言也许不支持队列。 你可以使用 list (列表)或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。
进阶:你能否仅用一个队列来实现栈。
代码分析:
方法一:两个队列
为了满足栈的特性,即最后入栈的元素最先出栈,在使用队列实现栈时,应满足队列前端的元素是最后入栈的元素。可以使用两个队列实现栈的操作,其中 queue1 用于存储栈内的元素,queue2 作为入栈操作的辅助队列。(本题意在一个队列为辅另一个为主,通过辅助队列使得主队列能完成栈的操作即主队列出队顺序为栈顶到栈底)
入栈操作时,首先将元素入队到 queue2,然后将 queue1 的全部元素(此时已经是先进后出的顺序)依次出队并入队到 queue2,此时 queue2 的前端的元素即为新入栈的元素,再将 queue1 和 queue2 互换,则 queue1 的元素即为栈内的元素,queue1 的前端和后端分别对应栈顶和栈底。
由于每次入栈操作都确保 queue1 的前端元素为栈顶元素,因此出栈操作和获得栈顶元素操作都可以简单实现。出栈操作只需要移除 queue1 的前端元素并返回即可,获得栈顶元素操作只需要获得 queue1 的前端元素并返回即可(不移除元素)。
由于 queue1 用于存储栈内的元素,判断栈是否为空时,只需要判断 queue1 是否为空即可。
——by力扣官方题解
C++版:
- class MyStack {
- public:
- queue<int> queue1;
- queue<int> queue2;
-
- MyStack() {
- //Java中需要初始化队列数据结构
- }
-
- void push(int x) {
- queue2.push(x);
- while (!queue1.empty()) {
- queue2.push(queue1.front());
- queue1.pop();
- }
- //swap两参数可以任意传两相同类型
- swap(queue1,queue2);
- }
-
- int pop() {
- int r = queue1.front();
- queue1.pop();
- return r;
- }
-
- int top() {
- int r = queue1.front();
- return r;
- }
-
- bool empty() {
- return queue1.empty();
- }
- };
Java版:
- class MyStack {
- Queue<Integer> queue1;
- Queue<Integer> queue2;
-
- /** Initialize your data structure here. */
- public MyStack() {
- queue1 = new LinkedList<Integer>();
- queue2 = new LinkedList<Integer>();
- }
-
- /** Push element x onto stack. */
- public void push(int x) {
- queue2.offer(x);
- while (!queue1.isEmpty()) {
- queue2.offer(queue1.poll());
- }
- Queue<Integer> temp = queue1;
- queue1 = queue2;
- queue2 = temp;
- }
-
- /** Removes the element on top of the stack and returns that element. */
- public int pop() {
- return queue1.poll();
- }
-
- /** Get the top element. */
- public int top() {
- return queue1.peek();
- }
-
- /** Returns whether the stack is empty. */
- public boolean empty() {
- return queue1.isEmpty();
- }
- }
方法二:一个队列
辅助队列的存在多余了,主队列插入新的元素后,将之前的元素依次出队并入队到队尾即可
代码类似省略
LeetCode232.用栈实现队列:
问题描述:
请你仅使用两个栈实现先入先出队列。队列应当支持一般队列支持的所有操作(
push、pop、peek、empty):实现
MyQueue类:
void push(int x)将元素 x 推到队列的末尾int pop()从队列的开头移除并返回元素int peek()返回队列开头的元素boolean empty()如果队列为空,返回true;否则,返回false说明:
- 你 只能 使用标准的栈操作 —— 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。- 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。
提示:
1 <= x <= 9- 最多调用
100次push、pop、peek和empty- 假设所有操作都是有效的 (例如,一个空的队列不会调用
pop或者peek操作)进阶:
- 你能否实现每个操作均摊时间复杂度为
O(1)的队列?换句话说,执行n个操作的总时间复杂度为O(n),即使其中一个操作可能花费较长时间。
代码分析:
无论「用栈实现队列」还是「用队列实现栈」,思路都是类似的。
都可以通过使用两个栈/队列来解决。
我们创建两个栈,分别为 out 和 in,用作处理「输出」和「输入」操作。
其实就是两个栈来回「倒腾」。
而对于「何时倒腾」决定了是 O(n) 解法 还是 均摊 O(1) 解法。
——by宫水三叶
O(n) 解法:
我们创建两个栈,分别为 out 和 in:
in 用作处理输入操作 push(),使用 in 时需确保 out 为空
out 用作处理输出操作 pop() 和 peek(),使用 out 时需确保 in 为空
Java版:
- class MyQueue {
- Deque<Integer> out, in;
- public MyQueue() {
- /*注意使用的是ArrayDeque而非LinkedList,两者都可以作为栈使用*/
- in = new ArrayDeque<>();
- out = new ArrayDeque<>();
- }
-
- public void push(int x) {
- while (!out.isEmpty()) in.addLast(out.pollLast());
- in.addLast(x);
- }
-
- public int pop() {
- while (!in.isEmpty()) out.addLast(in.pollLast());
- return out.pollLast();
- }
-
- public int peek() {
- while (!in.isEmpty()) out.addLast(in.pollLast());
- return out.peekLast();
- }
-
- public boolean empty() {
- return out.isEmpty() && in.isEmpty();
- }
- }
均摊 O(1) 解法:
事实上,我们不需要在每次的「入栈」和「出栈」操作中都进行「倒腾」。
我们只需要保证,输入的元素总是跟在前面的输入元素的后面,而输出元素总是最早输入的那个元素即可。
可以通过调整「倒腾」的时机来确保满足上述要求,但又不需要发生在每一次操作中:
只有在「输出栈」为空的时候,才发生一次性的「倒腾」
——by宫水三叶
Java版:
- class MyQueue {
- Deque<Integer> out, in;
- public MyQueue() {
- in = new ArrayDeque<>();
- out = new ArrayDeque<>();
- }
-
- public void push(int x) {
- in.addLast(x);
- }
-
- public int pop() {
- if (out.isEmpty()) {
- while (!in.isEmpty()) out.addLast(in.pollLast());
- }
- return out.pollLast();
- }
-
- public int peek() {
- if (out.isEmpty()) {
- while (!in.isEmpty()) out.addLast(in.pollLast());
- }
- return out.peekLast();
- }
-
- public boolean empty() {
- return out.isEmpty() && in.isEmpty();
- }
- }
C++版:
- class MyQueue {
- private:
- stack<int> inStack, outStack;
-
- void in2out() {
- while (!inStack.empty()) {
- outStack.push(inStack.top());
- inStack.pop();
- }
- }
-
- public:
- MyQueue() {}
-
- void push(int x) {
- inStack.push(x);
- }
-
- int pop() {
- if (outStack.empty()) {
- in2out();
- }
- int x = outStack.top();
- outStack.pop();
- return x;
- }
-
- int peek() {
- if (outStack.empty()) {
- in2out();
- }
- return outStack.top();
- }
-
- bool empty() {
- return inStack.empty() && outStack.empty();
- }
- };
关于「均摊复杂度」的说明:
我们先用另外一个例子来理解「均摊复杂度」,大家都知道「哈希表」底层是通过数组实现的。
正常情况下,计算元素在哈希桶的位置,然后放入哈希桶,复杂度为 O(1),假定是通过简单的“拉链法”搭配「头插法」方式来解决哈希冲突。
但当某次元素插入后,「哈希表」达到扩容阈值,则需要对底层所使用的数组进行扩容,这个复杂度是 O(n)。
显然「扩容」操作不会发生在每一次的元素插入中,因此扩容的 O(n) 都会伴随着 n 次的 O(1),也就是 O(n) 的复杂度会被均摊到每一次插入当中,因此哈希表插入仍然是 O(1) 的。
同理,我们的「倒腾」不是发生在每一次的「输出操作」中,而是集中发生在一次「输出栈为空」的时候,因此 pop 和 peek 都是均摊复杂度为 O(1) 的操作。
——by宫水三叶
剑指Offer30.包含min函数的栈:
问题描述:
定义栈的数据结构,请在该类型中实现一个能够得到栈的最小元素的 min 函数在该栈中,调用 min、push 及 pop 的时间复杂度都是 O(1)。
代码分析:
模拟栈的设计问题,关键就是得到最小的元素。参考标答我们发现getMin()功能可以用辅助栈来做,也就是维护一个可以告知我们最小值的栈。按照标答的思路,我们只需要设计一个数据结构,使得每个刚入栈的栈顶元素与其相应的最小值时刻保持一一对应。因此我们可以使用一个辅助栈,与元素栈同步插入与删除,用于存储与每个元素对应的最小值。
当一个元素要入栈时,我们取当前辅助栈的栈顶存储的最小值,与当前元素比较得出最小值,将这个最小值插入辅助栈中;
注:同步插入与删除很关键,做题时可能当前元素大于辅助栈顶值时就不插入,小于时才插入。
- class MinStack {
- private:
- stack<int> a, b; //a主b辅
- public:
- /** initialize your data structure here. */
- MinStack() {
- b.push(INT_MAX);
- }
-
- void push(int x) {
- a.push(x);
- b.push(::min(b.top(),x));
- }
-
- void pop() {
- a.pop();
- b.pop();
- }
-
- int top() {
- return a.top();
- }
-
- int min() {
- return b.top();
- }
- };
-
- /**
- * Your MinStack object will be instantiated and called as such:
- * MinStack* obj = new MinStack();
- * obj->push(x);
- * obj->pop();
- * int param_3 = obj->top();
- * int param_4 = obj->min();
- */
插一嘴,这里 ::min的意思是全局作用域符号,当全局变量(库函数min)在局部函数(自定义min)中与其中某个变量重名,那么就可以用 ::来区分。
LeetCode1249.移除无效的括号:
问题描述:
给你一个由
'('、')'和小写字母组成的字符串s。你需要从字符串中删除最少数目的
'('或者')'(可以删除任意位置的括号),使得剩下的「括号字符串」有效。请返回任意一个合法字符串。
有效「括号字符串」应当符合以下 任意一条 要求:
- 空字符串或只包含小写字母的字符串
- 可以被写作
AB(A连接B)的字符串,其中A和B都是有效「括号字符串」- 可以被写作
(A)的字符串,其中A是一个有效的「括号字符串」
示例 1:
输入:s = "lee(t(c)o)de)" 输出:"lee(t(c)o)de" 解释:"lee(t(co)de)" , "lee(t(c)ode)" 也是一个可行答案。
示例 2:
输入:s = "))(("
输出:""
解释:空字符串也是有效的
代码分析:
题干说了一堆其实就是初级典型括号匹配问题,只不过本题在检测括号匹配的基础上还要对不匹配的部分进行删减。稍加思索我们想到维护两个栈同时分别存放'('和其对应在string容器中的下标。【这里若用pair打包,一个栈即可。也可以联想为键值对。】用STL提供的字符串操作函数erase(下标,擦除数量)对不匹配的')'和遍历结束时栈中还存在的多余的'('进行擦除。基本可以得到如下:
- class Solution {
- public:
- string minRemoveToMakeValid(string s) {
- //if(s == ")))))") return "";
- stack<int> st1, st2;
- for(int i = 0;i <= s.size()-1 ; ++i) {
- if(s[i] == '(') {st1.push(s[i]);st2.push(i);}
- if(s[i] == ')') {
- if(st1.empty()) {s.erase(i,1);--i;}
- else {st1.pop();st2.pop();}
- }
- }
- while(!st2.empty()) {
- s.erase(st2.top(),1);
- st2.pop();
- }
- return s;
- }
- };
当然肯定有情况没有考虑周全,程序在测试样例")))))"处报错,你一惊,发现样例才过了9/60个。当然,也可能只是这一个样例较为特殊,于是你自作聪明地在代码前面加上了if(s == ")))))") return "";然后,竟然ac了......
当然这样含糊过去肯定良心不安,分析")))))"在程序中的运行,发现s.size()也需要随i动态变化,于是在前面定义一个全局变量length=s.size()-1;别忘了--length即可。
官解的Java版书写方式可以参考学习。
- /*我采用两栈,此处采用一栈一集合,思路相同*/
- class Solution {
- public String minRemoveToMakeValid(String s) {
- Set<Integer> indexesToRemove = new HashSet<>();
- Stack<Integer> stack = new Stack<>();
- for (int i = 0; i < s.length(); i++) {
- if (s.charAt(i) == '(') {
- stack.push(i);
- } if (s.charAt(i) == ')') {
- if (stack.isEmpty()) {
- indexesToRemove.add(i);
- } else {
- stack.pop();
- }
- }
- }
- // Put any indexes remaining on stack into the set.
- while (!stack.isEmpty()) indexesToRemove.add(stack.pop());
- StringBuilder sb = new StringBuilder();
- for (int i = 0; i < s.length(); i++) {
- if (!indexesToRemove.contains(i)) {
- sb.append(s.charAt(i));
- }
- }
- return sb.toString();
- }
- }
- /*从之前分析可知,根据栈中是否有可匹配的 "(",可以立即知道当前每个 ")" 是否有效。但是无法立即知道每个 "(" 是否有效,必须要等到字符串扫描结束,根据栈中是否有剩余的 "(" 确定。所以正反分别扫一遍,"("、")"均清楚
- */
- class Solution {
- //open、close的设置方便反过来时也按照相同的模式来处理
- private StringBuilder removeInvalidClosing(CharSequence string, char open, char close) {
- StringBuilder sb = new StringBuilder();
- int balance = 0;
- for (int i = 0; i < string.length(); i++) {
- char c = string.charAt(i);
- if (c == open) {
- balance++;
- } if (c == close) {
- if (balance == 0) continue;
- balance--;
- }
- sb.append(c);
- }
- return sb;
- }
- //记得StringBuilder.toString()=string
- public String minRemoveToMakeValid(String s) {
- StringBuilder result = removeInvalidClosing(s, '(', ')');
- result = removeInvalidClosing(result.reverse(), ')', '(');
- return result.reverse().toString();
- }
- }
LeetCode1823.找出游戏的获胜者:
问题描述:
共有
n名小伙伴一起做游戏。小伙伴们围成一圈,按 顺时针顺序 从1到n编号。确切地说,从第i名小伙伴顺时针移动一位会到达第(i+1)名小伙伴的位置,其中1 <= i < n,从第n名小伙伴顺时针移动一位会回到第1名小伙伴的位置。游戏遵循如下规则:
- 从第
1名小伙伴所在位置 开始 。- 沿着顺时针方向数
k名小伙伴,计数时需要 包含 起始时的那位小伙伴。逐个绕圈进行计数,一些小伙伴可能会被数过不止一次。- 你数到的最后一名小伙伴需要离开圈子,并视作输掉游戏。
- 如果圈子中仍然有不止一名小伙伴,从刚刚输掉的小伙伴的 顺时针下一位 小伙伴 开始,回到步骤
2继续执行。- 否则,圈子中最后一名小伙伴赢得游戏。
给你参与游戏的小伙伴总数
n,和一个整数k,返回游戏的获胜者。
典型约瑟夫环模板题,可惜LeetCode上有关的题解不全面,不能有效启发思维,特此借鉴洛谷等OJ上的佬来解答
代码分析:
方法一:数组模拟循环链表(若真使用链表,这题的代码实现复杂程度无疑大大上升了)
- class Solution {
- public:
- int findTheWinner(int n, int k) {
- //a[i]存放第i+1个人位置的指向
- int a[n+1];
- for(int i = 1; i <= n-1; ++i){
- a[i] = i+1;
- }
- //成环
- a[n] = 1;
- int sum = 0, count = 1, step = n, result = 0;
- //大循环直到n个人全部出队为止
- while(sum < n){ //sum为出队的总人数,count为计数器,step表示当前指向
- //小循环结束后step为计数第k-1个人,即出队人的前驱
- while(count<k){
- step = a[step];
- ++count;
- }
- //最后一个人
- if(sum == n-1) result = a[step];
- sum++;
- //其前驱的后继指向其自身后继
- a[step]=a[a[step]];
- count = 1;
- }
- return result;
- }
- };
方法二:队列(参考前面用队列模拟栈问题,出队的元素可以继续入队到队尾!)非常简洁和优美
- /*
- 首先我们需要模拟一个队列,将所有的元素压进队列
- 在进行循环(直到队列为空为止) 首先你要知道:
- 队列只可以在head删除,那么这就要求我们只要这个人经过判断并且不会被剔除,那么就必须把他排在队尾
- 重复该操作k−1次,则在k−1次操作之后,队首元素即为这一轮中数到的第k人的编号,将队首元素取出,即为数到的第k人离开圈子。直到队列中只剩下1个元素。
- */
- class Solution {
- public:
- int findTheWinner(int n, int k) {
- queue<int> qu;
- for (int i = 1; i <= n; i++) {
- qu.emplace(i);
- }
- while (qu.size() > 1) {
- for (int i = 1; i < k; i++) {
- qu.emplace(qu.front());
- qu.pop();
- }
- qu.pop();
- }
- return qu.front();
- }
- };
方法三:数学+递归&迭代,公式推导见官解
- //递归
- class Solution {
- public:
- int findTheWinner(int n, int k) {
- if (n == 1) {
- return 1;
- }
- return (k + findTheWinner(n - 1, k) - 1) % n + 1;
- }
- };
-
- //迭代
- class Solution {
- public:
- int findTheWinner(int n, int k) {
- int winner = 1;
- for (int i = 2; i <= n; i++) {
- winner = (k + winner - 1) % i + 1;
- }
- return winner;
- }
- };
方法四:数组模拟链表的另一种思路,来自洛谷
- 从1-N a[i] = i+1;
- int p = 0;
- n次循环{
- //核心公式,下一个出队的人
- p = (p+k%n-1+n)%n;
- 输出a[p]即可得到依次出队的人编号;
- //将出队人后面的所有人向前移动来覆盖
- copy(a+p+1;a+n;a+p);
- }
LeetCode42.接雨水:
问题描述:
给定
n个非负整数表示每个宽度为1的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
示例 1:

输入:height = [0,1,0,2,1,0,1,3,2,1,2,1] 输出:6 解释:上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。
代码分析:
注意蓝色雨水区域的形成条件:左右由高度相同的柱子围堵而成,不要误把y轴当作柱子。
解法一:按行求,下沉法
最开始想到的解法,感觉很巧妙很好想,但是提交后发现最后几个测试案例都大的离谱,TLE了。本题由于放在“栈”专题,于是硬生生地在程序中套了一个栈。
- class Solution {
- public:
- int trap(vector<int>& height)
- {
- stack<int> stk; //逐行分析时,存放每一层有柱子区域的编号
- int max=-1; //统计数组中的柱子的最大高度
- int sum=0; //累计有水的区域数量
- int sign; //逐行分析时,每一行第一个有柱子区域的编号
-
- 找出最高的柱子高度,按行计数即为逐次将整体向下平移一格
-
- for(int i=0;i<=height.size()-1;i++)
- {
- if(height.at(i)>max)
- max=height.at(i);
- }
-
- x轴上第一格位置处不会有水
-
- if(height.size()<=2) return 0;
-
- for(int j=1;j<=max;j++) //需要整体向下平移max次一格高度
- {
- for(int k=0;k<=height.size()-1;k++) //逐格分析
- {
- if(height.at(k)>=1)
- {
- if(stk.empty())
- {
- sign=k;
- stk.push(k);
- }
- else
- stk.push(k);
- }
- }
-
- 核心计算公式,(每一层有水的格子区域数量)=(x轴上始末位置的柱子之间的格子数)-(始末之间有柱子的格子数)
-
- sum+=((stk.top()-sign-1)-(stk.size()-2));
-
- 开始整体下沉,若高度为0则不动
-
- for(int k=0;k<=height.size()-1;k++)
- {
- if(height.at(k)>=1)
- height.at(k)--;
- else continue;
- }
-
- 一行计数完毕后,记得清空栈
-
- for(int k=stk.size()-1;k>=0;k--)
- {
- stk.pop();
- }
- }
- return sum;
- }
- };
解法二:按列求
求每一列的水,我们只需要关注当前列,以及左边最高的柱子,右边最高的柱子就够了(至于为什么其余的柱子是无关紧要的,可以自己脑补一下)。
装水的多少,当然根据木桶效应,我们只需要看左边最高的柱子和右边最高的柱子中较矮的一个就够了。
而根据较矮的那个柱子和当前列的柱子的高度可以分为三种情况。
- 较矮的柱子的高度大于当前列的柱子的高度,当前列的水量即为高度差
- 较矮的柱子的高度小于当前列的柱子的高度,当前列不会有水
- 较矮的柱子的高度等于当前列的柱子的高度,当前列不会有水
明白了这三种情况,程序就很好写了,遍历每一列,然后分别求出这一列两边最高的柱子。找出较矮的一端,和当前列的高度比较,结果就是上边的三种情况。
——by windliang
- public int trap(int[] height) {
- int sum = 0;
- //最两端的列不用考虑,因为一定不会有水。所以下标从 1 到 length - 2
- for (int i = 1; i < height.length - 1; i++) {
- int max_left = 0;
- //找出左边最高
- for (int j = i - 1; j >= 0; j--) {
- if (height[j] > max_left) {
- max_left = height[j];
- }
- }
- int max_right = 0;
- //找出右边最高
- for (int j = i + 1; j < height.length; j++) {
- if (height[j] > max_right) {
- max_right = height[j];
- }
- }
- //找出两端较小的
- int min = Math.min(max_left, max_right);
- //只有较小的一段大于当前列的高度才会有水,其他情况不会有水
- if (min > height[i]) {
- sum = sum + (min - height[i]);
- }
- }
- return sum;
- }
- 作者:windliang
解法三:动态规划
解法二的时间复杂度较高(O(n^2),遍历每一列需要 n,找出左边最高和右边最高的柱子加起来刚好又是一个 n)是因为需要对每个下标位置都向两边扫描。如果已经知道每个位置两边的最大高度,则可以在 O(n) 的时间内得到能接的雨水总量。使用动态规划的方法,可以在 O(n) 的时间内预处理得到每个位置两边的最大高度。
首先用两个数组,max_left [i] 代表第 i 列左边最高的柱子的高度,max_right[i] 代表第 i 列右边最高的柱子的高度。(一定要注意下,第 i 列左(右)边最高的柱子,是不包括自身的,和 leetcode 上边的讲的有些不同,因此i的取值范围为【1,height.length-2】。)
max_left [i] = Max(max_left [i-1],height[i-1]);
max_right[i] = Max(max_right[i+1],height[i+1]);
还要记得初始化max_left[0]=height[0];max_right[n−1]=height[n−1];
套用解法二的大体算法,将O(n^2)简化为O(n)
- public int trap(int[] height) {
- int sum = 0;
- int[] max_left = new int[height.length];
- int[] max_right = new int[height.length];
- max_left[0]=height[0]; max_right[n−1]=height[n−1];
-
- for (int i = 1; i < height.length - 1; i++) {
- max_left[i] = Math.max(max_left[i - 1], height[i - 1]);
- }
- for (int i = height.length - 2; i >= 0; i--) {
- max_right[i] = Math.max(max_right[i + 1], height[i + 1]);
- }
- for (int i = 1; i < height.length - 1; i++) {
- int min = Math.min(max_left[i], max_right[i]);
- if (min > height[i]) {
- sum = sum + (min - height[i]);
- }
- }
- return sum;
- }
- 作者:windliang
解法四:单调栈
看了官解,解释得很专业很官方,像咱这种菜鸡是看不懂的(笑)。于是搬运了作者windliang的通俗易懂的解释。
“说到栈,肯定会想到括号匹配了。我们仔细观察蓝色的部分,可以和括号匹配类比下。每次匹配出一对括号(找到对应的一堵墙),就计算这两堵墙中的水。
我们用栈保存每堵墙。
当遍历墙的高度的时候,如果当前高度小于栈顶的墙高度,说明这里会有积水,我们将墙的高度的下标入栈。
如果当前高度大于栈顶的墙的高度,说明之前的积水到这里停下,我们可以计算下有多少积水了。计算完,就把当前的墙继续入栈,作为新的积水的墙。
总体的原则就是,
- 当前高度小于等于栈顶高度,入栈,指针后移。
当前高度大于栈顶高度,栈顶出栈,计算出当前墙和栈顶的墙之间水的多少,然后计算当前的高度和新栈的高度的关系,重复此步骤。直到当前墙的高度不大于栈顶高度或者栈空,然后把当前墙入栈,指针后移。”
看到这应该没有啥具体直观的感受,详见windliang / 力扣官方题解的动图演示,这里不放出了。总之单调栈做法值得推敲,作者的总结功力十分深厚。
补一句,虽然
while循环里套了一个while循环,但是考虑到每个元素最多访问两次,入栈一次和出栈一次,所以时间复杂度是 O(n)。
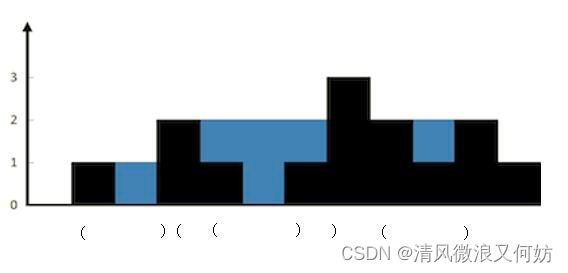
- class Solution {
- public int trap(int[] height) {
- int sum = 0;
- Stack<Integer> stack = new Stack<>();
- int current = 0;
- //从头到尾遍历
- while(current < height.length) {
- //如果栈不空并且当前指向的高度大于栈顶高度就一直循环
- //相当于一直在寻找current指向的")"所对应的"("
- while(!stack.empty() && height[current] > height[stack.peek()]) {
- int h = height[stack.peek()]; //栈顶出栈
- stack.pop();
- //注意此时要立刻再次检查一下栈空
- if(stack.empty()) {
- break;
- }
- //开始相关计算
- int distance = current-stack.peek()-1;
- int min = Math.min(height[stack.peek()],height[current]);
- sum += distance*(min-h);
- }
- //若因栈空至此,表明此current指向的")"前已无匹配的"(",不需要进行计算,应把它当成新的"("放入栈中;若因<=至此,表明当前")"已经匹配完成,当成新的"("放入栈中进行下一轮遍历
- stack.push(current);
- current++;
- }
- return sum;
- }
- }
解法五:双指针
动态规划中,我们常常可以对空间复杂度进行进一步的优化。
可以看到,max_left [ i ] 和 max_right [ i ] 数组中的元素我们其实只用一次,然后就再也不会用到了。所以我们可以不用数组,只用一个变量就行了。我们先尝试着用老办法改造下
max_left。
- public int trap(int[] height) {
- int sum = 0;
- int max_left = 0;
- int[] max_right = new int[height.length]; //先不动修改max_right
- for (int i = height.length - 2; i >= 0; i--) {
- max_right[i] = Math.max(max_right[i + 1], height[i + 1]);
- }
- //相同的修改逻辑不能运用在max_right的修改上
- for (int i = 1; i < height.length - 1; i++) {
- max_left = Math.max(max_left, height[i - 1]);
- int min = Math.min(max_left, max_right[i]);
- if (min > height[i]) {
- sum = sum + (min - height[i]);
- }
- }
- return sum;
- }
- 作者:windliang
但是会发现我们不能用相同的逻辑把 max_right 的数组去掉,因为最后的 for 循环是从左到右遍历的,而 max_right 的更新是从右向左的。
所以这里要用到两个指针,left 和 right,从两个方向去遍历。left++就是从左向右更,right++就是从右向左更。
那么什么时候从左到右,什么时候从右到左呢?
根据老办法的更新规则,我们可以知道
max_left = Math.max(max_left, height[i - 1]);
height [ left - 1] 是可能成为 max_left 的, 同理,height [ right + 1 ] 也是可能成为 max_right 的。只要保证 height [ left - 1]
<height [ right + 1 ] ,那么 max_left 就一定小于 max_right!!!现在不难得出以下:
- public int trap(int[] height) {
- int sum = 0;
- int max_left = 0;
- int max_right = 0;
- int left = 1;
- int right = height.length - 2; // 加右指针进去
- //虽然i连续性从头扫到尾,但left和right间断性交替性地更新着
- for (int i = 1; i < height.length - 1; i++) {
- //从左到右更
- if (height[left - 1] < height[right + 1]) {
- max_left = Math.max(max_left, height[left - 1]);
- int min = max_left;
- if (min > height[left]) {
- sum = sum + (min - height[left]);
- }
- left++;
- //从右到左更
- } else {
- max_right = Math.max(max_right, height[right + 1]);
- int min = max_right;
- if (min > height[right]) {
- sum = sum + (min - height[right]);
- }
- right--;
- }
- }
- return sum;
- }
- 作者:windliang
本题非常有代表性,也是LeetCode热门前50题之一。本题的多重解法值得隔日反复推敲。
接下来我们多来几道单调栈的困难题来趁热打铁。
LeetCode84.柱状图中的最大矩形:
问题描述:
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
求在该柱状图中,能够勾勒出来的矩形的最大面积。
示例 1:
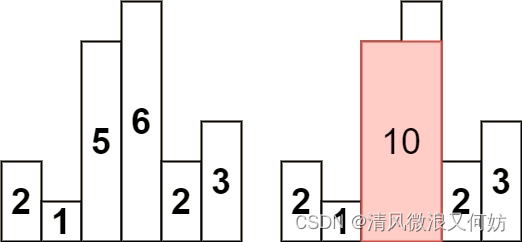
输入:heights = [2,1,5,6,2,3] 输出:10 解释:最大的矩形为图中红色区域,面积为 10
代码分析:
在没使用算法数据结构之前,咱小白写这题肯定是在线or暴力or模拟,时间复杂度为O(n^2)。万一逻辑稍稍全面一点,测试用例稍稍放宽一点,AC是没问题的,但是没能从中学到什么东西。我相信很多题目,只要你给一个小白足够的思考时间,他是能把解决方案写的大差不差的。第一次写这题是在2022/3,理清当时解法也需要一阵子。代码如下报了TLE,原来是最后一个测试案例卡住了......不管那么多了,来提升提升“格调”。说实话,看过上一题,这一题就有用单调栈的冲动,非常相似。
都能想到,我们需要在柱状图中找出最大的矩形,因此我们可以考虑枚举矩形的宽和高,其中「宽」表示矩形贴着柱状图底边的宽度,「高」表示矩形在柱状图上的高度。
如果我们枚举「宽」,我们可以使用两重循环枚举矩形的左右边界以固定宽度 w,此时矩形的高度 h,就是所有包含在内的柱子的「最小高度」,对应的面积为 w×h。下面给出了这种方法的 C++ 代码。
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights) {
- int n = heights.size();
- int ans = 0;
-
- 不能直接枚举宽度,需要通过定下左边界i(有n种可能位置)时移动右边界j(有n-i种可能位置)来
- 确定的
- 而高度是根据右边界j所对应的height[j]在下标范围[i+1,n-1]之间的最小值来确定的
-
- for (int left = 0; left < n; ++left) {
- int minHeight = INT_MAX;
- // 枚举右边界
- for (int right = left; right < n; ++right) {
- // 确定高度
- minHeight = min(minHeight, heights[right]);
- // 计算面积
- ans = max(ans, (right - left + 1) * minHeight);
- }
- }
- return ans;
- }
- };
- 作者:力扣官解
如果我们枚举「高」,我们可以使用一重循环枚举某一根柱子,将其固定为矩形的高度 h。随后我们从这跟柱子开始向两侧延伸,直到遇到高度小于 h 的柱子,就确定了矩形的左右边界。如果左右边界之间的宽度为 w,那么对应的面积为 w×h。下面给出了这种方法的 C++ 代码。
- /*差不多快一年前的自解,比较丑陋,不能普适于各种情况于是采用了开头的特判*/
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights)
- {
- if(heights.size()==1)
- return heights.at(0);
- int maxx=0;
- for(int i=0;i<=heights.size()-1;i++)
- {
- int j=1;
- int now=i;
- while(i>=1)
- {
- if(heights.at(i-1)>heights.at(now))
- {
- j++;
- i--;
- continue;
- }
- else
- break;
- }
- i=now;
- while(i<=heights.size()-2)
- {
- if(heights.at(i+1)>=heights.at(now))
- {
- j++;
- i++;
- continue;
- }
- else
- break;
- }
- if(maxx<max(heights.at(now),heights.at(now)*j))
- maxx=max(heights.at(now),heights.at(now)*j);
- i=now;
- }
- return maxx;
- }
- };
- /*还得是官解呀*/
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights) {
- int n = heights.size();
- int ans = 0;
- for (int mid = 0; mid < n; ++mid) {
- // 枚举高
- int height = heights[mid];
- int left = mid, right = mid;
- // 确定左右边界
- while (left - 1 >= 0 && heights[left - 1] >= height) {
- --left;
- }
- while (right + 1 < n && heights[right + 1] >= height) {
- ++right;
- }
- // 计算面积
- ans = max(ans, (right - left + 1) * height);
- }
- return ans;
- }
- };
- 作者:力扣官解
考虑到枚举「宽」的方法使用了两重循环,本身就已经需要 O(N^2) 的时间复杂度,不容易优化,因此我们可以考虑优化只使用了一重循环的枚举「高」的方法。
方法一:单调栈
上题只是初步见识了一下单调栈,可能咱对其工作原理等(比方说,上题为何也要将当前的current在最后入栈?单调栈的精髓在于“遮挡作用”?)没有清醒的认识,这里我把力扣官解给的长篇大论咀嚼并节选摘抄一下,像极了严谨数学公式的推导(bushi)。但友情提示,想快速弄清本题和42.题之间共性和差异的、巩固加深单调栈快速解题的,只看官解并不是很好的选择,力扣评论区多看几个大咖的直观通俗解答会更清楚。还是要耐下心去理解,浮躁追求速度是不可取的。不必捧一踩一,吸取百家之长总是没有坏处的。
- 首先我们枚举某一根柱子 i 作为高 h=heights[i];
随后我们需要进行向左右两边扩展,使得扩展到的柱子的高度均不小于 h。换句话说,我们需要找到左右两侧最近的高度小于 h 的柱子,这样这两根柱子之间(不包括其本身)的所有柱子高度均不小于 h,并且就是 i 能够扩展到的最远范围。(讲解语言组织得真的很官方笑)
那么如何寻找拓展呢,除了前面的暴力遍历方式。先来看以下结论:
对于两根柱子 j0 以及 j1,如果 j0<j1 并且 heights[j0]≥heights[j1],那么对于任意的在它们之后出现的柱子 i(j1<i),j0 一定不会是 i 左侧且最近的小于其高度的柱子。换句话说,如果有两根柱子 j0 和 j1,其中 j0 在 j1 的左侧,并且 j0 的高度大于等于 j1,那么在后面的柱子 i 向左找小于其高度的柱子时,j1 会「挡住」j0,j0 就不会作为答案了。(遮挡作用)
这样一来,我们可以对数组从左向右进行遍历,同时维护一个「可能作为答案」的数据结构,其中按照从小到大的顺序存放了一些 j 值。根据上面的结论,如果我们存放了 j0,j1,⋯,js,那么一定有 height[j0]<height[j1]<⋯<height[js],因为如果有两个相邻的 j 值对应的高度不满足 < 关系,那么后者会「挡住」前者,前者就不可能作为答案了。
当我们枚举到第 i 根柱子时,我们的数据结构中存放了 j0,j1,⋯ ,js,如果第 i 根柱子左侧且最近的小于其高度的柱子为 ji,那么必然有
height[j0]<height[j1]<⋯<height[ji]<height[i]≤height[ji+1]<⋯<height[js];(这个公式不代表数据结构中的元素顺序,只代表height[i]理应排在结论中的位置,i大于所有的j!!!)具体解释看下图,jo,j1,...,ji,ji+1,...,js代表图中下标3、4、5、6,i代表7
如何在该数据结构中找到i所对应的ji呢?
把所有高度大于等于 height[i] 的 j 值全部移除,剩下的 j 值中高度最高的即为答案。在这之后,我们将 i 放入数据结构中,开始接下来的枚举。此时,我们需要使用的数据结构也就呼之欲出了,它就是栈。
- 栈中存放了 j 值。从栈底到栈顶,j 的值严格单调递增,同时对应的高度值也严格单调递增;
当我们枚举到第 i 根柱子时,我们从栈顶不断地移除 height[j]≥height[i] 的 j 值。在移除完毕后,栈顶的 j 值就一定满足 height[j]<height[i],此时 j 就是 i 左侧且最近的小于其高度的柱子。
这里会有一种特殊情况。如果我们移除了栈中所有的 j 值,那就说明 i 左侧所有柱子的高度都大于 height[i],那么我们可以认为 i 左侧且最近的小于其高度的柱子在位置 j=−1,它是一根「虚拟」的、高度无限低的柱子。这样的定义不会对我们的答案产生任何的影响,我们也称这根「虚拟」的柱子为「哨兵」。
- 我们再将 i 放入栈顶。栈中存放的元素具有单调性,这就是经典的数据结构「单调栈」了。
单调栈的时间复杂度是多少?直接计算十分困难,但是我们可以发现:
每一个位置只会入栈一次(在枚举到它时),并且最多出栈一次。
因此当我们从左向右/总右向左遍历数组时,对栈的操作的次数就为 O(N)。所以单调栈的总时间复杂度为 O(N)。
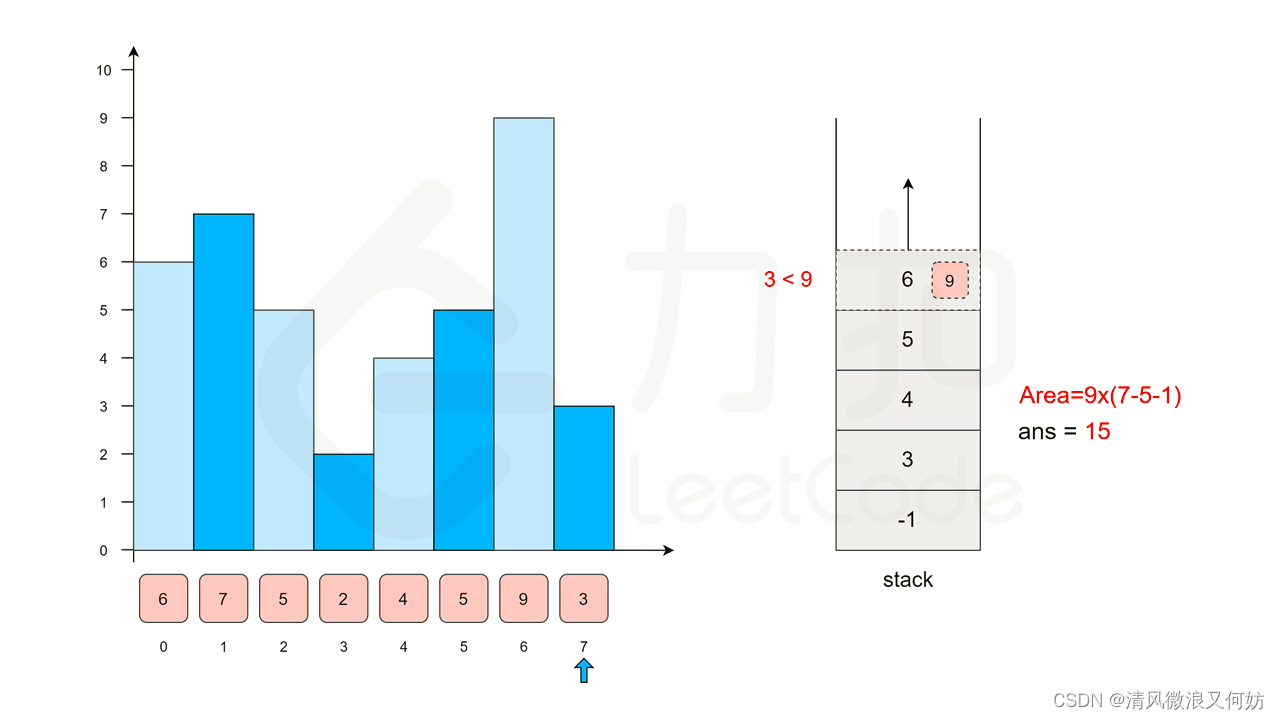
在贴官解之前,再画龙点睛一下。
本题单调栈的解法和接雨水的题目是遥相呼应的。
为什么这么说呢,42. 接雨水是找每个柱子左右两边第一个大于该柱子高度的柱子,而本题是找每个柱子左右两边第一个小于该柱子的柱子。
这里就涉及到了单调栈很重要的性质,就是单调栈里的顺序,是从小到大还是从大到小,首先弄清这点才行。
然后剧透一下,以上的单调栈官解看下来,你写出的应该是预处理版的单调栈!哈哈哈傻了吧,这地方要好好理解一下!上文接雨水单调栈解法、力扣热评代码随想录的解法,都是非预处理的优化版单调栈!而此处官解、力扣热评宫水三叶的解法,才是预处理版的单调栈。
- /*预处理版*/
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights) {
- int n = heights.size();
-
- 左右两边界都需要拓展且都采用相同单调栈逻辑
-
- vector<int> left(n), right(n);
-
- stack<int> mono_stack;
-
- 此时的单调栈从0->n-1单增
-
- for (int i = 0; i < n; ++i) {
- while (!mono_stack.empty() && heights[mono_stack.top()] >= heights[i]) {
- mono_stack.pop();
- }
- left[i] = (mono_stack.empty() ? -1 : mono_stack.top());
- mono_stack.push(i);
- }
-
- mono_stack = stack<int>();
-
- 此时的单调栈从n-1->0单增
-
- for (int i = n - 1; i >= 0; --i) {
- while (!mono_stack.empty() && heights[mono_stack.top()] >= heights[i]) {
- mono_stack.pop();
- }
- right[i] = (mono_stack.empty() ? n : mono_stack.top());
- mono_stack.push(i);
- }
-
- int ans = 0;
- for (int i = 0; i < n; ++i) {
- ans = max(ans, (right[i] - left[i] - 1) * heights[i]);
- }
- return ans;
- }
- };
- 作者:力扣官解
- /*预处理版*/
- class Solution {
- public int largestRectangleArea(int[] hs) {
- int n = hs.length;
-
- 你能找出上面的力扣官解的影子
-
- int[] l = new int[n], r = new int[n];
- Arrays.fill(l, -1); Arrays.fill(r, n);
-
- Deque<Integer> d = new ArrayDeque<>();
-
- for (int i = 0; i < n; i++) {
- while (!d.isEmpty() && hs[d.peekLast()] > hs[i]) r[d.pollLast()] = i;
- d.addLast(i);
- }
-
- d.clear();
-
- for (int i = n - 1; i >= 0; i--) {
- while (!d.isEmpty() && hs[d.peekLast()] > hs[i]) l[d.pollLast()] = i;
- d.addLast(i);
- }
- int ans = 0;
- for (int i = 0; i < n; i++) {
- int t = hs[i], a = l[i], b = r[i];
- ans = Math.max(ans, (b - a - 1) * t);
- }
- return ans;
- }
- }
- 作者:宫水三叶
重头戏来了,我们刚刚首先从左往右对数组进行遍历,借助单调栈求出了每根柱子的左边界,随后从右往左对数组进行遍历,借助单调栈求出了每根柱子的右边界。那么我们是否可以只遍历一次就求出答案呢?
在上面,我们在对位置 i 进行入栈操作时,确定了它的左边界。从直觉上来说,与之对应的我们在对位置 i 进行出栈操作时可以确定它的右边界!仔细想一想,这确实是对的。当位置 i 被弹出栈时,说明此时遍历到的位置 i0 的高度【小于等于】 height[i],并且在 i0 与 i 之间没有其他高度小于等于 height[i] 的柱子。这是因为,如果在 i 和 i0 之间还有其它位置的高度小于等于 height[i] 的,那么在遍历到那个位置的时候,i 应该已经被弹出栈了。所以位置 i0 就是位置 i 的右边界。
到这里有人又要发问了,等等,我们需要的是「一根柱子的左侧且最近的【小于】其高度的柱子」,但这里我们求的是【小于等于】,那么会造成什么影响呢?答案是:我们确实无法求出正确的右边界,但对最终的答案没有任何影响。这是因为在答案对应的矩形中,如果有若干个柱子的高度都等于矩形的高度,那么最右侧的那根柱子是可以求出正确的右边界的,而我们没有对求出左边界的算法进行任何改动,因此最终的答案还是可以从最右侧的与矩形高度相同的柱子求得的。读者可以仔细思考一下这一步(估计咱根本都不会有想到这里的机会笑)。
在遍历结束后,栈中仍然有一些位置,这些位置对应的右边界就是位置为 n 的「哨兵」。我们可以将它们依次出栈并更新右边界,也可以在初始化右边界数组时就将所有的元素的值置为 n。
- /*非预处理优化版*/
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights) {
- int n = heights.size();
-
- right数组需要全部初始化为n
- vector<int> left(n), right(n, n);
-
- stack<int> mono_stack;
- for (int i = 0; i < n; ++i) {
- while (!mono_stack.empty() && heights[mono_stack.top()] >= heights[i]) {
-
- 关键之处,right[i]的值在遍历到i之前的某个元素时便已经提前得出!!!
- 剩余的未被mono_stack.top()取到的位置的right数组值均在前面被初始化为n
-
- right[mono_stack.top()] = i;
- mono_stack.pop();
- }
- left[i] = (mono_stack.empty() ? -1 : mono_stack.top());
- mono_stack.push(i);
- }
-
- int ans = 0;
- for (int i = 0; i < n; ++i) {
- ans = max(ans, (right[i] - left[i] - 1) * heights[i]);
- }
- return ans;
- }
- };
- 作者:力扣官解
最后插一嘴哈,如果你仔细观察比较了接雨水那题的单调栈解法和本题解法,你会发现,差异和变数还是挺多的。本题无论如何都要拓展右边界(虽然既可以预处理又可以立刻得出),而42.题的current即右边界是固定的,只需要利用单调栈拓展左边界即可。
代码结构仿照42.题来写的本题题解,来自 代码随想录,可以参考一下他的这种思路来让本题和42.题联系更加紧密。
- /*仿照42.题代码结构*/
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights) {
- stack<int> st;
- //vector的insert()用法
- heights.insert(heights.begin(), 0); // 数组头部加入元素0
- heights.push_back(0); // 数组尾部加入元素0
- st.push(0);
- int result = 0;
- for (int i = 1; i < heights.size(); i++) {
- //实际上这里会持续不断地循环将大于height[i]的元素持续出栈并更新计算结果,而之前的做法只不过一次性地找到了数组左边界
- while (heights[i] < heights[st.top()]) {
- int mid = st.top();
- st.pop();
- int w = i - st.top() - 1;
- int h = heights[mid];
- result = max(result, w * h);
- }
- st.push(i);
- }
- return result;
- }
- };
- 作者:代码随想录
方法二:动态规划
本题动态规划的写法整体思路和42. 接雨水是一致的。需要记录每个柱子 左边第一个小于该柱子的下标,需要循环查找。在这不赘述。唯一值得注意的是为何需要循环t = minLeftIndex[t]?因为也许当前t符合a(a<i)柱子左边第一个,但height[t]>height[i]即不符合i柱子左边第一个。
- class Solution {
- public:
- int largestRectangleArea(vector<int>& heights) {
-
- //存放每个柱子 左边/右边第一个小于该柱子的下标
- vector<int> minLeftIndex(heights.size());
- vector<int> minRightIndex(heights.size());
-
- int size = heights.size();
-
- minLeftIndex[0] = -1; // 注意这里初始化为哨兵
- for (int i = 1; i < size; i++) {
- int t = i - 1;
- // 这里不是用if,而是不断向左寻找的过程
- while (t >= 0 && heights[t] >= heights[i]) t = minLeftIndex[t];
- minLeftIndex[i] = t;
- }
-
- minRightIndex[size - 1] = size; // 注意这里初始化为哨兵
- for (int i = size - 2; i >= 0; i--) {
- int t = i + 1;
- // 这里不是用if,而是不断向右寻找的过程
- while (t < size && heights[t] >= heights[i]) t = minRightIndex[t];
- minRightIndex[i] = t;
- }
- // 求和
- int result = 0;
- for (int i = 0; i < size; i++) {
- int sum = heights[i] * (minRightIndex[i] - minLeftIndex[i] - 1);
- result = max(sum, result);
- }
- return result;
- }
- };
- 作者:代码随想录
留给本题的时间真的挺多的,只能说这题值得这样做。期待二次、多次回刷。接下来再看本题的升级版85.
LeetCode85.最大矩形:
问题描述:
给定一个仅包含
0和1、大小为rows x cols的二维二进制矩阵,找出只包含1的最大矩形,并返回其面积。
示例 1:

输入:matrix = [["1","0","1","0","0"],["1","0","1","1","1"],["1","1","1","1","1"],["1","0","0","1","0"]] 输出:6 解释:最大矩形如上图所示。
代码分析:
还是先暴力再优化。关键在于把二维化一维,然后套用LeetCode84.的结论。
方法一: 使用柱状图的优化暴力方法
首先计算出矩阵的每个元素的左边连续 1 的数量,使用二维数组 left 记录,其中 left[i][j] 为矩阵第 i 行第 j 列元素的左边连续 1 的数量。由于left数组设置的特性,我们对于每一个点,向左和向上拓展,枚举以其为右下角的全1矩形。
具体而言,当考察以 matrix[i][j] 为右下角的矩形时,在当前固定矩形高度情况下,我们枚举满足 0≤k≤i 的所有可能的 k,此时矩阵的最大宽度就为 left[i][j],left[i−1][j],…,left[k][j] 的最小值。
对于上述语句不能理解,自行跳转力扣官解,下图也能直观说明这一点。
对每个点重复这一过程,就可以得到全局的最大矩形。
我们预计算最大宽度的方法事实上将输入转化成了一系列的柱状图,我们针对每个柱状图计算最大面积。于是,上述方法本质上是「84. 柱状图中最大的矩形」题中优化暴力算法的复用。
当然可能大家都看出来了,没必要对matrix中每个点进行上述枚举高度的计算,直接以matrix的底边为x轴基准线,对matrix的每一列应用单调栈即可,对了,这是第二种方法。

- class Solution {
- public:
- int maximalRectangle(vector<vector<char>>& matrix) {
- int m = matrix.size();
- //这种情况要特判
- if (m == 0) {
- return 0;
- }
- int n = matrix[0].size();
- //初始化二维数组全为0
- vector<vector<int>> left(m, vector<int>(n, 0));
-
- for (int i = 0; i < m; i++) {
- for (int j = 0; j < n; j++) {
- if (matrix[i][j] == '1') {
- left[i][j] = (j == 0 ? 0: left[i][j - 1]) + 1;
- }
- }
- }
-
- int ret = 0;
- for (int i = 0; i < m; i++) {
- for (int j = 0; j < n; j++) {
- if (matrix[i][j] == '0') {
- continue;
- }
- int width = left[i][j];
- int area = width;
- //遍历高度,注意matrix下标的起始点是在左上角!
- //即使该点所在列上有0,也不影响结果,width可能为0,但area取的是较大的那一个
- for (int k = i - 1; k >= 0; k--) {
- width = min(width, left[k][j]);
- area = max(area, (i - k + 1) * width);
- }
- ret = max(ret, area);
- }
- }
- return ret;
- }
- };
- 作者:力扣官解
时间复杂度:O(m^2*n),其中 m 和 n 分别是矩阵的行数和列数。计算 left 矩阵需要 O(mn) 的时间。随后对于矩阵的每个点,需要 O(m) 的时间枚举高度。故总的时间复杂度为 O(mn)+O(mn)⋅O(m)=O(m^2*n)。
方法二:单调栈
时间复杂度:O(mn),其中 m 和 n 分别是矩阵的行数和列数。计算 left 矩阵需要 O(mn) 的时间;对每一列应用柱状图算法需要 O(m) 的时间,一共需要 O(mn) 的时间。直接上代码。
- /*预处理版单调栈*/
- class Solution {
- public:
- int maximalRectangle(vector<vector<char>>& matrix) {
- int m = matrix.size();
- if (m == 0) {
- return 0;
- }
- int n = matrix[0].size();
- vector<vector<int>> left(m, vector<int>(n, 0));
-
- for (int i = 0; i < m; i++) {
- for (int j = 0; j < n; j++) {
- if (matrix[i][j] == '1') {
- left[i][j] = (j == 0 ? 0: left[i][j - 1]) + 1;
- }
- }
- }
-
- int ret = 0;
- for (int j = 0; j < n; j++) { // 对于每一列,使用基于柱状图的方法
-
- 此处若把柱状图横过来,up down相当于上一题的left right数组!!!
-
- vector<int> up(m, 0), down(m, 0);
-
- stack<int> stk;
-
- 此时stk从0 -> m-1单增
-
- for (int i = 0; i < m; i++) {
- while (!stk.empty() && left[stk.top()][j] >= left[i][j]) {
- stk.pop();
- }
- up[i] = stk.empty() ? -1 : stk.top();
- stk.push(i);
- }
- stk = stack<int>();
-
- 此时stk从m-1 -> 0单增
-
- for (int i = m - 1; i >= 0; i--) {
- while (!stk.empty() && left[stk.top()][j] >= left[i][j]) {
- stk.pop();
- }
- down[i] = stk.empty() ? m : stk.top();
- stk.push(i);
- }
-
- 注意matrix的计数起点在左上角即可
-
- for (int i = 0; i < m; i++) {
- int height = down[i] - up[i] - 1;
- int area = height * left[i][j];
- ret = max(ret, area);
- }
- }
- return ret;
- }
- };
- 作者:力扣官解
再来看三叶姐的解法,相当于把力扣官解的图旋转了90度!matrix宽和高正好反过来了!来参考对比学习一下这另一角度的思路。
我们将
mat的每一行作为基准,以基准线为起点,往上连续 1 的个数为高度(换汤不换药)。将原矩阵进行这样的转换好处是 : 对于原矩中面积最大的矩形,其下边缘必然对应了某一条基准线,从而将问题转换为84题。
- class Solution {
- public int maximalRectangle(char[][] mat) {
- int n = mat.length, m = mat[0].length, ans = 0;
- int[][] sum = new int[n + 10][m + 10];
- for (int i = 1; i <= n; i++) {
- for (int j = 1; j <= m; j++) {
- sum[i][j] = mat[i - 1][j - 1] == '0' ? 0 : sum[i - 1][j] + 1;
- }
- }
- int[] l = new int[m + 10], r = new int[m + 10];
- for (int i = 1; i <= n; i++) {
- int[] cur = sum[i];
- Arrays.fill(l, 0); Arrays.fill(r, m + 1);
- Deque<Integer> d = new ArrayDeque<>();
- for (int j = 1; j <= m; j++) {
- while (!d.isEmpty() && cur[d.peekLast()] > cur[j]) r[d.pollLast()] = j;
- d.addLast(j);
- }
- d.clear();
- for (int j = m; j >= 1; j--) {
- while (!d.isEmpty() && cur[d.peekLast()] > cur[j]) l[d.pollLast()] = j;
- d.addLast(j);
- }
- for (int j = 1; j <= m; j++) ans = Math.max(ans, cur[j] * (r[j] - l[j] - 1));
- }
- return ans;
- }
- }
- 作者:宫水三叶
到这本题告一段落了。通过类似题型的比较学习,我们收获了很多。类似单调栈的题目还有LeetCode739、496、503等,之后都会拿出来讲。
LeetCode456.132模式:
问题描述:
给你一个整数数组
nums,数组中共有n个整数。132 模式的子序列 由三个整数nums[i]、nums[j]和nums[k]组成,并同时满足:i < j < k和nums[i] < nums[k] < nums[j]。如果
nums中存在 132 模式的子序列 ,返回true;否则,返回false。
示例 1:
输入:nums = [3,1,4,2] 输出:true 解释:序列中有 1 个 132 模式的子序列: [1, 4, 2] 。
示例 2:
输入:nums = [-1,3,2,0] 输出:true 解释:序列中有 3 个 132 模式的的子序列:[-1, 3, 2]、[-1, 3, 0] 和 [-1, 2, 0] 。
代码分析:
别想当然i,j,k连在一起,那样难度会小很多(希望你仔细分析了题目并看了示例2)不然你会写出如下单调栈代码:
- class Solution {
- public:
- bool find132pattern(vector<int>& nums) {
- stack<int> stk;
- int count = 0;
- bool flag = false;
- for(int i = 0; i <= nums.size()-1; ++i) {
- while(!stk.empty() && nums[i] < stk.top()) {
- stk.pop();
- ++count;
- }
- if(!stk.empty() && count==1) {
- flag = true;
- break;
- }
- stk.push(nums[i]);
- count = 0;
- }
- return flag;
- }
- };
以上代码有84 / 102 个通过的测试用例,也就是说,严谨的测试案例把你无意中偷的五分之一的懒给逮到了。
若你采取 箫骋 的做法,暴力一点通过101 / 102,单车变摩托。不过,这思路还是很清奇呢,没有采取对三个数枚举,优化了nums[i]的选取,但本题的数据规模仍不支持。。
- class Solution {
- public:
- bool find132pattern(vector<int>& nums) {
- int a = nums[0];
- for(int j=1; j <= nums.size()-1; j++){
- for(int k = nums.size()-1; k >= j+1; k--){
- if(a < nums[k] && nums[k] < nums[j])
- return true;
- }
- a = min(a,nums[j]);
- }
- return false;
- }
- };
由于本题中 n 的最大值可以到 2×10^5,因此对于一个满足 132 模式的三元组下标 (i,j,k),枚举其中的 2 个下标时间复杂度为 O(n^2),会超出时间限制。
因此我们可以考虑枚举其中的 1 个下标,并使用合适的数据结构维护另外的 2 个下标的可能值。在这里来细品 力扣官方题解 的题解。
方法一:枚举 3
力扣官解说枚举 3 是容易想到并且也是最容易实现的(这有待读者考量)。
从左到右枚举 3 的下标 j,那么:
由于 1 是模式中的最小值,因此我们在枚举 j 的同时,维护数组 a 中左侧元素 a[0..j−1] 的最小值,即为 1 对应的元素 a[i]。但前提是 a[i]<a[j];
由于 2 是模式中的次小值,因此我们可以使用一个有序集合(例如平衡树)维护数组 a 中右侧元素 a[j+1..n−1] 中的所有值。当我们确定了 a[i] 和 a[j] 之后,只需要在有序集合中查询严格比 a[i] 大的那个最小的元素,即为 a[k]。但前提是 a[k]<a[j]。
- class Solution {
- public:
- bool find132pattern(vector<int>& nums) {
- int n = nums.size();
- //注意考虑这种特判情况
- if (n < 3) {
- return false;
- }
-
- // j左侧最小值
- int left_min = nums[0];
- // j右侧所有元素
- multiset<int> right_all;
-
- for (int k = 2; k <= n - 1; ++k) { // 因为j初始为1
- right_all.insert(nums[k]);
- }
-
- i,j,k的移动和迭代更新都在这一层循环中被处理
-
- for (int j = 1; j <= n - 2; ++j) {
-
- 只要i,j的位置满足条件合适,就寻找合适的k的位置
-
- if (left_min < nums[j]) {
- auto it = right_all.upper_bound(left_min);
- //迭代器可以看成为地址,取其值要用*号
- if (it != right_all.end() && *it < nums[j]) {
- return true;
- }
- }
-
- 当前的i,j,k不符合132模式,注意nums[i]更新选取为nums[i]和nums[j]较小的那一个
-
- left_min = min(left_min, nums[j]);
- //别忘记k要让出j下一步即将移动到的位置
- right_all.erase(right_all.find(nums[j + 1]));
- }
-
- return false;
- }
- };
- 作者:力扣官解
来复习一下multiset吧,详见 链表:LeetCode2.两数相加。
multiset的insert()、lower_bound()、upper_bound()等函数返回值均为迭代器即typedef multiset<int>::iterator Iter;而lower_bound(begin, end, num)和upper_bound(begin, end, num)均是使用二分查找的方法分别返回第一个大于等于/大于num的值的地址即迭代器。不存在则返回end。

时间复杂度:O(nlogn)。在初始化时,我们需要 O(nlogn) 的时间将数组元素 a[2..n−1] 加入有序集合中。在枚举 j 时,维护左侧元素最小值的时间复杂度为 O(1),将 a[j+1] 从有序集合中删除的时间复杂度为 O(logn),总共需要枚举的次数为 O(n),因此总时间复杂度为 O(nlogn)。
方法二:枚举 1
如果我们从左到右枚举 1 的下标 i,那么 j,k 的下标范围都是减少的,这样就不利于对它们进行维护。因此我们可以考虑从右到左枚举 i。
那么我们应该如何维护 j,k 呢?在 132 模式中,如果 1<2 并且 2<3,那么根据传递性,1<3 也是成立的,那么我们可以使用下面的方法进行维护:
- 我们使用一种数据结构维护所有遍历过的元素,它们作为 2 的候选元素。每当我们遍历到一个新的元素时,就将其加入数据结构中;
遍历到一个新的元素的同时,我们可以考虑其是否可以作为 3。如果它作为 3,那么数据结构中所有严格小于它的元素都可以作为 2,我们将这些元素全部从数据结构中移除,并且使用一个变量维护(“记录”这个词我觉得更准确)所有被移除的元素的最大值。这些被移除的元素都是可以真正作为 2 的,并且元素的值越大,那么我们之后找到 1 的机会也就越大。
那么这个「数据结构」是什么样的数据结构呢?我们尝试提取出它进行的操作:
1.它需要支持添加一个元素;
2.它需要支持移除所有严格小于给定阈值的所有元素;
3.上面两步操作是「依次进行」的,即我们先用给定的阈值移除元素,再将该阈值加入数据结构中。
这就是「单调栈」。在单调栈中,从栈底到栈顶的元素是严格单调递减的。当给定阈值 x 时,我们只需要不断地弹出栈顶的元素,直到栈为空或者 x 严格小于栈顶元素。此时我们再将 x 入栈,这样就维护了栈的单调性。
我们用单调栈维护所有可以作为 2 的候选元素。初始时,单调栈中只有唯一的元素 a[n−1]。我们还需要使用一个变量 max_k 记录所有可以真正作为 2 的元素的最大值;
随后我们从 n−2 开始从右到左枚举元素 a[i]:
首先我们判断 a[i] 是否可以作为 1。如果 a[i]<max_k(因为在此步骤前已经维护好了max_k即a[k]<a[j]),那么它就可以作为 1,我们就找到了一组满足 132 模式的三元组;
随后我们判断 a[i] 是否可以作为 3,以此找出哪些可以真正作为 2 的元素。我们将 a[i] 不断地与单调栈栈顶的元素进行比较,如果 a[i]] 较大,那么栈顶元素可以真正作为 2,将其弹出并更新 max_k;
最后我们将 a[i] 作为 2 的候选元素放入单调栈中。这里可以进行一个优化,即如果 a[i]≤max_k,那么我们也没有必要将 a[i] 放入栈中,因为即使它在未来被弹出,也不会将 max_k 更新为更大的值。(这里解释一下a[i]为什么会不大于max_k,其实很好想,如果之前的元素都普遍较大,而当前的元素异常小,这种情况是有可能的。并且我们维护单调栈的真实目的只是为了更新max_k,a[i]≤max_k仅仅代表a[i]不适合成为3,但2仍然为max_k十分合适保持不变。)
在枚举完所有的元素后,如果仍未找到满足 132132132 模式的三元组,那就说明其不存在。
- class Solution {
- public:
- bool find132pattern(vector<int>& nums) {
- int n = nums.size();
- stack<int> candidate_k;
- candidate_k.push(nums[n - 1]);
- int max_k = INT_MIN;
-
- for (int i = n - 2; i >= 0; --i) {
-
- 如果上一轮的循环处理好了3和2之间的关系,那么本轮循环的开始可以检测当前元素能否作为1
-
- if (nums[i] < max_k) {
- return true;
- }
- while (!candidate_k.empty() && nums[i] > candidate_k.top()) {
- max_k = candidate_k.top();
- candidate_k.pop();
- }
- if (nums[i] > max_k) {
- candidate_k.push(nums[i]);
- }
- }
- return false;
- }
- };
- 作者:力扣官解
方法三:枚举 2 (难理解,截止本次更新时未明白)
从左到右进行枚举,在枚举的过程中,i,j 的下标范围都是增加的。
由于我们需要保证 1<2 并且 2<3,那么我们需要维护一系列尽可能小的元素作为 1 的候选元素,并且维护一系列尽可能大的元素作为 3 的候选元素。
我们可以分情况进行讨论,假设当前有一个小元素 xi 以及一个大元素 xj 表示一个二元组,而我们当前遍历到了一个新的元素 x=a[k],那么:
如果 x>xj,那么让 x 作为 3 显然是比 xj 作为 3 更优,因此我们可以用 x 替代 xj;
如果 x<xi,那么让 x 作为 1 显然是比 xi 作为 3 更优,然而我们必须要满足 132 模式中的顺序,即 1 出现在 3 之前,这里如果我们简单地用 x 替代 xi,那么 xi=x 作为 1 是出现在 xj 作为 3 之后的,这并不满足要求(简单点解释,就是说xj此时已经确定了,不能不和xj商量就私自串通xi和xk进行改变,私自改变后就没能考虑到xj的感受)。因此我们需要为 x 找一个新的元素作为 3。由于我们还没有遍历到后面的元素,因此可以简单地将 x 同时看作一个二元组的 xi 和 xj;
对于其它的情况,xi≤x≤xj,当前即为最优。
这样一来,与方法二类似,我们使用两个单调递减的单调栈维护一系列二元组 (xi,xj),表示一个可以选择的 1−3 区间,并且从栈底到栈顶 xi 和 xj 分别严格单调递减,因为根据上面的讨论,我们只有在 x<xi 时才会增加一个新的二元组。
如果我们想让 x 作为 2,那么我们并不知道到底应该选择单调栈中的哪个 1−3 区间,因此我们只能根据单调性进行二分查找:
对于单调栈中的 xi,我们需要找出第一个满足 xi<x 的位置 idxi,这样从该位置到栈顶的所有二元组都满足 xi<x;
对于单调栈中的 xj,我们需要找出最后一个满足 xj>x 的位置 idxj,这样从栈底到该位置的所有二元组都满足 xj>x;
如果 idxi 和 idxj 都存在,并且 idxi≤idxj,那么就存在至少一个二元组 (xi,xj) 满足 xi<x<xj,x 就可以作为 2,我们就找到了一组满足 132 模式的三元组。
在枚举完所有的元素后,如果仍未找到满足 132 模式的三元组,那就说明其不存在。
需要注意的是,我们是在单调递减的栈上进行二分查找,因此大部分语言都需要实现一个自定义比较函数,或者将栈中的元素取相反数后再使用默认的比较函数。
- class Solution {
- public:
- bool find132pattern(vector<int>& nums) {
-
- 方法三不好理解,这个二元组需要反复阅读题解才可明白其用途
-
- int n = nums.size();
- vector<int> candidate_i = {nums[0]};
- vector<int> candidate_j = {nums[0]};
-
- for (int k = 1; k <= n - 1; ++k) {
- auto it_i = upper_bound(candidate_i.begin(), candidate_i.end(), nums[k], greater<int>());
- auto it_j = lower_bound(candidate_j.begin(), candidate_j.end(), nums[k], greater<int>());
- if (it_i != candidate_i.end() && it_j != candidate_j.begin()) {
- int idx_i = it_i - candidate_i.begin();
- int idx_j = it_j - candidate_j.begin() - 1;
- if (idx_i <= idx_j) {
- return true;
- }
- }
-
- if (nums[k] < candidate_i.back()) {
- candidate_i.push_back(nums[k]);
- candidate_j.push_back(nums[k]);
- }
- else if (nums[k] > candidate_j.back()) {
- int last_i = candidate_i.back();
- while (!candidate_j.empty() && nums[k] > candidate_j.back()) {
- candidate_i.pop_back();
- candidate_j.pop_back();
- }
- candidate_i.push_back(last_i);
- candidate_j.push_back(nums[k]);
- }
- }
-
- return false;
- }
- };
- 作者:力扣官解
方法三完全可以做到 O(n),维护前缀最小值+单调栈即可。先从单调栈中找到左侧离 i 最近的比 nums[i] 大的元素,再查询这个值左侧的最小值,只要这个最小值小于 nums[i] 即可。
——by 白
多么令人叹为观止的解法三!无需使用二分查找。见下方代码
- class Solution {
- public:
- bool find132pattern(vector<int>& nums) {
- const int n = nums.size();
-
- 维护单减栈
-
- stack<int> st;
-
- 维护前缀最小值
-
- vector<int> pmin{INT_MAX};
- for (int i = 0;i < n;++i) {
-
- 先从单调栈中找到左侧离 i 最近的比 nums[i] 大的元素
-
- while (!st.empty() && nums[st.top()] <= nums[i])
- st.pop();
-
- 再查询这个值左侧的最小值,只要这个最小值小于 nums[i] 即可。
-
- if (!st.empty() && pmin[st.top()] < nums[i])
- return true;
- st.push(i);
- pmin.push_back(min(pmin.back(), nums[i]));
- }
- return false;
- }
- };
- 作者:白
LeetCode496.下一个更大元素 I
问题描述:
nums1中数字x的 下一个更大元素 是指x在nums2中对应位置 右侧 的 第一个 比x大的元素。给你两个 没有重复元素 的数组
nums1和nums2,下标从 0 开始计数,其中nums1是nums2的子集。对于每个
0 <= i < nums1.length,找出满足nums1[i] == nums2[j]的下标j,并且在nums2确定nums2[j]的 下一个更大元素 。如果不存在下一个更大元素,那么本次查询的答案是-1。返回一个长度为
nums1.length的数组ans作为答案,满足ans[i]是如上所述的 下一个更大元素 。
示例 1:
输入:nums1 = [4,1,2], nums2 = [1,3,4,2]. 输出:[-1,3,-1] 解释:nums1 中每个值的下一个更大元素如下所述: - 4 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。 - 1 ,用加粗斜体标识,nums2 = [1,3,4,2]。下一个更大元素是 3 。 - 2 ,用加粗斜体标识,nums2 = [1,3,4,2]。不存在下一个更大元素,所以答案是 -1 。
代码分析:
当题目出现「找到最近一个比其大的元素」的字眼时,自然会想到「单调栈」。单调栈问题不能光看不练,前面就当是例题讲解过了,这题可以自己独立解决的。直接上代码了。当然,更优秀的方式是将用来过渡答案的right数组改为unordered_map<int,int> hashmap,因为find()为O(n),哈希表查找为O(1),空间复杂度相同。关于STL主要函数的复杂度汇总详见 http://t.csdn.cn/emYn0。
维护单调栈,每个元素最多入栈出栈一次,复杂度为 O(n);构造答案复杂度为 O(m)。整体复杂度为 O(n+m)。
- class Solution {
- public:
- vector<int> nextGreaterElement(vector<int>& nums1, vector<int>& nums2) {
-
- 由于是找当前元素右边第一个大于它的元素,从后向前维护一个单减栈
-
- stack<int> stk;
- int m = nums1.size();
- int n = nums2.size();
- vector<int> right(n);
- vector<int> ans(m);
- for(int i = n - 1; i >= 0; --i) {
- while(!stk.empty() && nums2[stk.top()] < nums2[i]) {
- stk.pop();
- }
- right[i] = (stk.empty() ? -1 : nums2[stk.top()]);
- stk.push(i);
- }
- for(int i = 0; i <= m - 1; ++i) {
- //auto为新语法,有的编译器可能不支持,可以改用vector<int>::iterator
- auto temp = find(nums2.begin(), nums2.end(), nums1[i]);
- int j = temp - nums2.begin();
- ans[i] = right[j];
- }
- return ans;
- }
- };
接下来看本题的升级题:
LeetCode503.下一个更大元素 II
问题描述:
给定一个循环数组
nums(nums[nums.length - 1]的下一个元素是nums[0]),返回nums中每个元素的 下一个更大元素 。数字
x的 下一个更大的元素 是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出-1。
示例 1:
输入: nums = [1,2,1] 输出: [2,-1,2] 解释: 第一个 1 的下一个更大的数是 2; 数字 2 找不到下一个更大的数; 第二个 1 的下一个最大的数需要循环搜索,结果也是 2。
代码分析:
还是需要维护单调栈(用静态数组模拟栈在时间上会更快速一些),观察示例1,写出其按上一题得出的right数组值为[2,-1,-1]。我们发现nums为循环数组时,最多只需遍历到下标2*n-1处就能求出本题的right数组,相当于给数组[1,2,1,1,2,1]求right数组后取right[0-2]的值即可。按照以上思路写出代码:
- class Solution {
- public:
- vector<int> nextGreaterElements(vector<int>& nums) {
- int n = nums.size();
-
- numss为翻倍后的新数组
-
- vector<int> numss;
- vector<int> ans(n);
- vector<int> right(2*n, 0);
- stack<int> stk;
- for(int i = 0; i <= n - 1; ++i) {
- numss.push_back(nums[i]);
- }
- for(int i = 0; i <= n - 1; ++i) {
- numss.push_back(nums[i]);
- }
- for(int i = 2*n - 1; i >= 0; --i) {
-
- 因为加倍后有重复元素,此处为<=
-
- while(!stk.empty() && numss[stk.top()] <= numss[i]) {
- stk.pop();
- }
- right[i] = (stk.empty() ? -1: numss[stk.top()]);
- stk.push(i);
- }
- for(int i = 0; i <= n - 1; ++i) {
- ans[i] = right[i];
- }
- return ans;
- }
- };
接下来我们通过 宫水三叶 的解释再来加深一下对单调栈的理解
我们先回想一下「朴素解法」是如何解决这个问题的。
对于每个数而言,我们需要遍历其右边的数,直到找到比自身大的数,这是一个 O(n^2) 的做法。之所以是 O(n^2),是因为每次找下一个最大值,我们是通过「主动」遍历来实现的。
而如果使用的是单调栈的话,可以做到 O(n) 的复杂度,我们将当前还没得到答案的下标暂存于栈内,从而实现「被动」更新答案。也就是说,栈内存放的永远是还没更新答案的下标。
LeetCode739.每日温度:
问题描述:
给定一个整数数组
temperatures,表示每天的温度,返回一个数组answer,其中answer[i]是指对于第i天,下一个更高温度出现在几天后。如果气温在这之后都不会升高,请在该位置用0来代替。
示例 1:
输入:temperatures = [73,74,75,71,69,72,76,73]输出: [1,1,4,2,1,1,0,0]
代码分析:
- class Solution {
- public:
- vector<int> dailyTemperatures(vector<int>& temperatures) {
- int n = temperatures.size();
- stack<int> stk;
- vector<int> right(n);
- for(int i = n - 1; i >= 0; --i) {
- while(!stk.empty() && temperatures[stk.top()] <= temperatures[i]) {
- stk.pop();
- }
- right[i] = (stk.empty() ? 0: stk.top() - i);
- stk.push(i);
- }
- return right;
- }
- };
LeetCode795.区间子数组个数:
问题描述:
给你一个整数数组
nums和两个整数:left及right。找出nums中连续、非空且其中最大元素在范围[left, right]内的子数组,并返回满足条件的子数组的个数。生成的测试用例保证结果符合 32-bit 整数范围。
示例 1:
输入:nums = [2,1,4,3], left = 2, right = 3 输出:3 解释:满足条件的三个子数组:[2], [2, 1], [3]
代码分析:
方法一:一次遍历(经典枚举连续子数组个数写法)
一个子数组的最大值范围在 [left,right] 表示子数组中不能含有大于 right 的元素,且至少含有一个处于 [left,right] 区间的元素。
我们可以将数组中的元素分为三类,并分别用 0, 1, 2 来表示:
小于 left,用 0 表示;
大于等于 left 且小于等于 right,用 1 表示;
大于 right,用 2 表示。
那么本题可以转换为求解不包含 2,且至少包含一个 1 的子数组数目。我们遍历 i,并将右端点固定在 i,求解有多少合法的子区间。过程中需要维护两个变量:
- last1,表示上一次 1 出现的位置,如果不存在则为 −1;
- last2,表示上一次 2 出现的位置,如果不存在则为 −1。
如果 last1≠−1,那么子数组若以 i 为右端点,合法的左端点可以落在 (last2,last1] 之间。这样的左端点共有 last1−last2 个。
综上,我们遍历 i:
- 如果 left≤nums[i]≤right,令 last1=i;
- 否则如果 nums[i]>right,令 last2=i,last1=−1。
然后将 last1−last2 累加到答案中即可。最后的总和即为题目所求。
看代码便可理解。
此方法要学习掌握。
- class Solution {
- public:
- int numSubarrayBoundedMax(vector<int>& nums, int left, int right) {
-
- 一定要将last2初始化为-1
-
- int res = 0, last2 = -1, last1 = -1;
-
- 遍历i作为固定的右边界
-
- for (int i = 0; i < nums.size(); i++) {
- if (nums[i] >= left && nums[i] <= right) { //找到了1
- last1 = i;
- } else if (nums[i] > right) {
-
- 找到了2,但last1应为2之后的第一个1,因此需要进入下一轮循环,
- 而continue下去的标志是把last1重新置位-1
-
- last2 = i;
- last1 = -1;
- }
- if (last1 != -1) {
- res += last1 - last2;
- }
- }
- return res;
- }
- };
- 作者:力扣官解
方法二:容斥原理
方法一提到,我们要计算的合法子区间不包含 2 且至少包含一个 1。所以,我们可以先求出只包含 0 或 1 的子区间数目,再减去只包括 0 的子区间数目。
设函数 count(nums,lower) 可以求出数组 nums 中所有元素小于等于 lower 的子数组数目,那么题目所求就是 count(nums,right)−count(nums,left)。
关于 count(nums,lower) 的实现,我们用 i 遍历 nums[i],cur 表示 i 左侧有多少个连续的元素小于等于 lower:
如果 nums[i]≤lower,令 cur=cur+1;
否则,令 cur=0。
每次将 curcurcur 加到答案中,最终的和即为 count 函数返回值。
异常巧妙,十分牛波一。
- class Solution {
- public:
- int numSubarrayBoundedMax(vector<int>& nums, int left, int right) {
-
- 注意所需范围是[left, right]
-
- return count(nums, right) - count(nums, left - 1);
- }
-
- int count(vector<int>& nums, int lower) {
- int res = 0, cur = 0;
- for (auto x : nums) {
- cur = x <= lower ? cur + 1 : 0;
- res += cur;
- }
- return res;
- }
- };
- 作者:力扣官解
方法三:单调栈
统计所有最大值范围在 [left,right] 之间的子数组个数,可等价为统计每一个范围落在 [left,right] 之间的 nums[i] 作为最大值时子数组的个数。
由此可以进一步将问题转换为:求解每个 nums[i] 作为子数组最大值时,最远的合法左右端点的位置。也就是求解每一个 nums[i] 左右最近一个比其“大”的位置,这就转换成了前面我们熟悉的一般性做法。
统计所有 nums[i] 对答案的贡献即是最终答案。但我们忽略了「当 nums 存在重复元素,且该元素作为子数组最大值时,最远左右端点的边界越过重复元素时,导致重复统计子数组」的问题。
三叶姐还特地贴了图如下:
为了消除这种重复统计,我们可以将「最远左右边界」的一端,从「严格小于」调整为「小于等于」,从而实现半开半闭的效果。
具体来看代码:(注意区别题目传递的形参left、right与left、right数组的名称区别!!!此处将形参left、right替换为a、b)

- class Solution {
- public int numSubarrayBoundedMax(int[] nums, int a, int b) {
- int n = nums.length, ans = 0;
- int[] left = new int[n + 10], right = new int[n + 10];
-
- 注意各版本单调栈书写之间的共性和差异!
-
- Arrays.fill(left, -1); Arrays.fill(right, n);
- Deque<Integer> stk = new ArrayDeque<>();
-
- 不可以使用非预处理优化版,因为两个方向的遍历中对单调栈采取的策略不同!
- '<' '<='使得(left, right]区间半开半闭,预防了重复问题
-
- for(int i = 0; i <= n - 1; ++i) { //从左向右,但更新的是right数组,是三叶版的新写法
- while(!stk.isEmpty() && nums[stk.peekLast()] < nums[i]) right[stk.pollLast()] = i;
- stk.addLast(i);
- }
- stk.clear();
- for(int i = n - 1; i >= 0; --i) { //从右向左,但更新的是left数组
- while(!stk.isEmpty() && nums[stk.peekLast()] <= nums[i]) left[stk.pollLast()] = i;
- stk.addLast(i);
- }
- for(int i = 0; i <= n - 1; ++i) {
- if(nums[i] < a || nums[i] > b) continue;
- ans += (i - left[i])*(right[i] - i);
- }
- return ans;
- }
- }
我们马不停蹄看下一题。
LeetCode907. 子数组的最小值之和:
问题描述:
给定一个整数数组
arr,找到min(b)的总和,其中b的范围为arr的每个(连续)子数组。由于答案可能很大,因此 返回答案模
10^9 + 7。
示例 1:
输入:arr = [3,1,2,4] 输出:17 解释: 子数组为 [3],[1],[2],[4],[3,1],[1,2],[2,4],[3,1,2],[1,2,4],[3,1,2,4]。 最小值为 3,1,2,4,1,1,2,1,1,1,和为 17。
代码分析:
本题是上一题的子题,学会上一题求子数组个数,这题只需解决数学部分即可,当然也可以用动态规划来做。我们来细品 力扣官方题解 & 宫水三叶 的解法。
方法一:单调栈
先提示一下求解最小值之和的思路:
考虑所有满足以数组 arr 中的某个元素 arr[i] 为最右且最小的元素的子序列个数 C[i],那么题目要求连续子数组的最小值之和即为
,其中数组 arr 的长度为 n。我们必须假设当前元素为最右边且最小的元素,这样才可以构造互不相交的子序列,否则会出现多次计算,因为一个数组的最小值可能不唯一。
经过以上思考,我们只需要找到每个元素 arr[i] 以该元素为最右且最小的子序列的数目 left[i],以及以该元素为最左且最小的子序列的数目 right[i],则以 arr[i] 为最小元素的子序列的数目合计为 left[i]×right[i]。十分类似上一题,注意防止重复计算。
- class Solution {
- public:
- int sumSubarrayMins(vector<int>& arr) {
- int n = arr.size();
- vector<int> monoStack;
- vector<int> left(n), right(n);
- for (int i = 0; i < n; i++) {
- while (!monoStack.empty() && arr[i] <= arr[monoStack.back()]) {
- monoStack.pop_back();
- }
- left[i] = i - (monoStack.empty() ? -1 : monoStack.back());
- monoStack.emplace_back(i);
- }
- monoStack.clear();
- for (int i = n - 1; i >= 0; i--) {
- while (!monoStack.empty() && arr[i] < arr[monoStack.back()]) {
- monoStack.pop_back();
- }
- right[i] = (monoStack.empty() ? n : monoStack.back()) - i;
- monoStack.emplace_back(i);
- }
- long long ans = 0;
- long long mod = 1e9 + 7;
- for (int i = 0; i < n; i++) {
- ans = (ans + (long long)left[i] * right[i] * arr[i]) % mod;
- }
- return ans;
- }
- };
- 作者:力扣官解
方法二:动态规划
设 s[j][i] 表示子数组 [arr[j],arr[j+1],⋯ ,arr[i]] 的最小值,则可以推出所有连续子数组的最小值之和为
。我们只需要求出以每个元素 arr[i] 为最右的子数组最小值之和,即可求出所有的子数组的最小值之和。每当我们减少 j 时,子序列的最小值可能会有关联,事实上我们可以观察到 s[j−1][i]=min(s[j][i],arr[j−1])。那么s[j][i]与arr[j-1]如何比较大小呢?
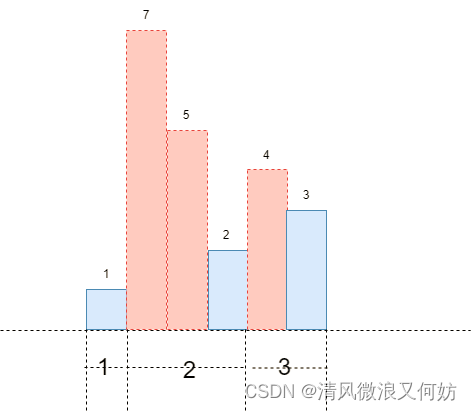
假设当前数组为: arr=[1,7,5,2,4,3,9],当 i=5 时,所有以索引 j 为起点且以 i 结尾的连续子序列为:
j=5, [3]
j=4, [4,3]
j=3, [2,4,3] 左侧序列的最小值分别为 [3,3,2,2,2,1],
j=2, [5,2,4,3] 可以发现重要点是 j=5,j=3,j=0
j=1, [7,5,2,4,3] 分别是 j 从 i 开始向左移动遇到的最小值的位置
j=0, [1,7,5,2,4,3] 如下图所示:
肯定用单调栈了
设以 arr[i] 为最右且最小的最长子序列长度为 k:
当 j>=i−k+1 时:连续子序列 [arr[j],arr[j+1],⋯,arr[i]] 的最小值为 arr[i],即 s[j][i]=arr[i]。
当 j<i−k+1 时:连续子序列 [arr[j],arr[j+1],⋯,arr[i]] 的最小值一定比 arr[i] 更小,通过分析可以知道它的最小值 s[j][i]=min(s[j][i−k],arr[i])=s[j][i−k]。
则可以知道递推公式如下:
令
,则上式转换为:
。
维护一个单调栈,很容易求出元素 x 的左边第一个比它小的元素,即求出以 x 为最右且最小的子序列的最大长度,推出dp数组,子数组的最小值之和即为
。
以上文字内容比较纷繁,需耐下心来体会。
- class Solution {
- public:
- int sumSubarrayMins(vector<int>& arr) {
- int n = arr.size();
- long long ans = 0;
- long long mod = 1e9 + 7;
- stack<int> monoStack;
- vector<int> dp(n);
- for (int i = 0; i < n; i++) {
- while (!monoStack.empty() && arr[monoStack.top()] > arr[i]) {
- monoStack.pop();
- }
-
- 以当前值为最右且最小的子序列的长度k
-
- int k = monoStack.empty() ? (i + 1) : (i - monoStack.top());
-
- 可以认为dp[-1] = 0
-
- dp[i] = k * arr[i] + (monoStack.empty() ? 0 : dp[i - k]);
-
- 逐层累加dp[i]时就需取余
-
- ans = (ans + dp[i]) % mod;
- monoStack.emplace(i);
- }
- return ans;
- }
- };
- 作者:力扣官解
看下一道类似题。
LeetCode2104.子数组范围和
问题描述:
给你一个整数数组
nums。nums中,子数组的 范围 是子数组中最大元素和最小元素的差值。返回
nums中 所有 子数组范围的 和 。子数组是数组中一个连续 非空 的元素序列。
示例 1:
输入:nums = [1,2,3] 输出:4 解释:nums 的 6 个子数组如下所示: [1],范围 = 最大 - 最小 = 1 - 1 = 0 [2],范围 = 2 - 2 = 0 [3],范围 = 3 - 3 = 0 [1,2],范围 = 2 - 1 = 1 [2,3],范围 = 3 - 2 = 1 [1,2,3],范围 = 3 - 1 = 2 所有范围的和是 0 + 0 + 0 + 1 + 1 + 2 = 4
代码分析:
作为三叶姐关于单调栈题单 单调栈 · SharingSource/LogicStack-LeetCode Wiki · GitHub 的最后一题(目前),再一次带大家详细品读 力扣官方题解 & 宫水三叶 的解法。还是从区间DP和单调栈角度着手,加深诸如此类问题的代码书写熟练度。至此,单调栈问题告一段落,一座小高峰已经初步被我们攻克。
方法一:单调栈
此时理应想到与官解大体一致的框架。
首先注意子数组的最小值或最大值不唯一的情况(此点可能容易遗漏)。
为了使子数组的最小值或最大值唯一,我们定义如果 nums[i]=nums[j],那么 nums[i] 与 nums[j] 的逻辑大小由下标 i 与下标 j 的逻辑大小决定,即如果 i<j,那么 nums[i] 逻辑上小于 nums[j]。
根据范围和的定义,可以推出范围和 sum 等于所有子数组的最大值之和 sumMax 减去所有子数组的最小值之和 sumMin。
以求解sumMin为例,sumMax同理:
假设 nums[i] 左侧最近的比它小的数为 nums[j]【minLeft(i)】,右侧最近的比它小的数为 nums[k]【minRight(i)】,那么所有以 nums[i] 为最小值的子数组数目为 (k−i)×(i−j)。
- class Solution {
- public:
- long long subArrayRanges(vector<int>& nums) {
- int n = nums.size();
- vector<int> minLeft(n), minRight(n), maxLeft(n), maxRight(n);
- stack<int> minStack, maxStack;
-
- 从左向右遍历已经决定了在值相同时,当前遍历到的nums[i]是较大的
-
- for (int i = 0; i < n; i++) {
- while (!minStack.empty() && nums[minStack.top()] > nums[i]) {
- minStack.pop();
- }
- minLeft[i] = minStack.empty() ? -1 : minStack.top();
- minStack.push(i);
-
- // 如果 nums[maxStack.top()] == nums[i], 那么根据定义,
- // nums[maxStack.top()] 逻辑上小于 nums[i],因为 maxStack.top() < i
- while (!maxStack.empty() && nums[maxStack.top()] <= nums[i]) {
- maxStack.pop();
- }
- maxLeft[i] = maxStack.empty() ? -1 : maxStack.top();
- maxStack.push(i);
- }
- minStack = stack<int>();
- maxStack = stack<int>();
-
- 从右向左遍历已经决定了在值相同时,当前遍历到的nums[i]是较小的
-
- for (int i = n - 1; i >= 0; i--) {
- // 如果 nums[minStack.top()] == nums[i], 那么根据定义,
- // nums[minStack.top()] 逻辑上大于 nums[i],因为 minStack.top() > i
- while (!minStack.empty() && nums[minStack.top()] >= nums[i]) {
- minStack.pop();
- }
- minRight[i] = minStack.empty() ? n : minStack.top();
- minStack.push(i);
-
- while (!maxStack.empty() && nums[maxStack.top()] < nums[i]) {
- maxStack.pop();
- }
- maxRight[i] = maxStack.empty() ? n : maxStack.top();
- maxStack.push(i);
- }
-
- long long sumMax = 0, sumMin = 0;
- for (int i = 0; i < n; i++) {
- sumMax += static_cast<long long>(maxRight[i] - i) * (i - maxLeft[i]) * nums[i];
- sumMin += static_cast<long long>(minRight[i] - i) * (i - minLeft[i]) * nums[i];
- }
- return sumMax - sumMin;
- }
- };
- 作者:力扣官解
时间复杂度:O(n),其中 n 为数组的大小。使用单调栈预处理出四个数组需要 O(n),计算最大值之和与最小值之和需要 O(n)。
方法二:区间 DP(预处理)
定义 f[l][r][k] 为区间 [l,r] 范围内的最值情况,其中 k 非 0 即 1:f[l][r][0] 代表区间 [l,r] 内的最小值,f[l][r][1] 代表区间 [l,r] 内的最大值。
不失一般性考虑 f[l][r][0] 和 f[l][r][1] 该如何计算:[l,r] 区间的最值可由 [l,r−1] 与 nums[r] 更新而来:
;
。
再枚举区间统计答案。
- class Solution {
- public long subArrayRanges(int[] nums) {
- int n = nums.length;
- int[][][] f = new int[n][n][2];
- for (int i = 0; i < n; i++) f[i][i][0] = f[i][i][1] = nums[i];
-
- for (int len = 2; len <= n; len++) { // len为[l,r]区间长度
- for (int l = 0; l + len - 1 < n; l++) { //好处是将三重循环变为两重,枚举l,r也因len的固定跟着确定了
- int r = l + len - 1;
- f[l][r][0] = Math.min(nums[r], f[l][r - 1][0]);
- f[l][r][1] = Math.max(nums[r], f[l][r - 1][1]);
- }
- }
- long ans = 0;
- for (int i = 0; i < n; i++) {
- for (int j = i + 1; j < n; j++) {
- ans += f[i][j][1] - f[i][j][0];
- }
- }
- return ans;
- }
- }
- 作者:宫水三叶
时间复杂度:复杂度为 O(n^2);统计范围和的复杂度为 O(n^2)。整体复杂度为 O(n^2)
空间复杂度:O(n^2)
更进一步,我们发现在转移计算 [l,r] 的最值情况时,仅依赖于 [l,r−1](小区间),因此我们可以使用两变量代替动规数组,边遍历边维护并统计答案。优化为如下:
- class Solution {
- public long subArrayRanges(int[] nums) {
-
- 短小精悍
-
- int n = nums.length;
- long ans = 0;
- for (int i = 0; i < n; i++) {
- int min = nums[i], max = nums[i];
- for (int j = i + 1; j < n; j++) {
- min = Math.min(min, nums[j]);
- max = Math.max(max, nums[j]);
- ans += max - min;
- }
- }
- return ans;
- }
- }
- 作者:宫水三叶
LeetCode2444.统计定界子数组的数目
问题描述:
给你一个整数数组
nums和两个整数minK以及maxK。
nums的定界子数组是满足下述条件的一个子数组:
- 子数组中的 最小值 等于
minK。- 子数组中的 最大值 等于
maxK。返回定界子数组的数目。
子数组是数组中的一个连续部分。
示例 1:
输入:nums = [1,3,5,2,7,5], minK = 1, maxK = 5 输出:2 解释:定界子数组是 [1,3,5] 和 [1,3,5,2] 。
代码分析:
方法一:分析性质 + 一次遍历
定界子数组满足性质:
- 子数组不能包含越界的数字(nums[i]>maxK 或 nums[i]<minK);
- 子数组必须同时包含 maxK 和 minK。
根据上述条件,我们从左到右遍历数组,统计以 i 为右端点的定界子数组数量:
维护左侧第一个越界数字的位置 l,表示左端点不能等于或越过 l;
- 同时,分别维护 maxK 和 minK 在左侧第一次出现的位置 r1 和 r2,表示左端点必须在 min(r1,r2) 及其左侧,否则子数组中会缺少 maxK 或 minK;
- 因此,以 i 为右边界的子数组数量(如果存在)= min(r1,r2)−l。
类似795.区间子数组个数的解法一
—— by newhar
- class Solution {
-
- public:
-
- long long countSubarrays(vector<int>& nums, int minK, int maxK) {
-
- 这个角度的思路非常简洁优美
-
- int n = nums.size();
- long long ret = 0L;
- for(int i = 0, l = -1, r1 = -1, r2 = -1; i < n; ++i) {
- if(nums[i] > maxK || nums[i] < minK) l = i;
- if(nums[i] == maxK) r1 = i;
- if(nums[i] == minK) r2 = i;
- ret += max(0, min(r1, r2) - l);
- }
- return ret;
- }
- };
- 作者:newhar
方法二:容斥原理
假设get(y,x)表示满足区间中所有数大于等于y且小于等于x的子区间的个数。(不一定要保证区间中一定出现y或者x)
那么get(y+1,x) 表示在满足get(y,x)的所有子区间中不包含y子区间的个数,
同理get(y,x-1)表示在满足get(y,x)的所有子区间中不包含x的子区间的个数,
get(y+1,x-1) 表示在满足get(y,x)的所有子区间中既不包含y,又不包含x的子区间的个数。
我们要求的是必须同时包含y和x的子区间的数目,根据容斥原理:
答案 = 所有区间数 - 不包含X的区间数 - 不包含Y的区间数 + 既不包含X又不包含Y的区间数 即为 get(y,x) - get(y+1,x) - get(y,x-1) + get(y+1,x-1)。
那么如何求get(y,x) 呢:我们知道get(y,x) 统计的所有区间都是不包含小于y的数和大于x的数的,所以我们可以在原序列A中用小于y的数或者大于x的数将序列分成若干段,每一段都是符合条件的区间,我们只需要在分割的每个子区间内求区间数量之和即可。
用以下样例举例:
将序列 {1 3 2 4 1} 进行划分:
这样可以划分成三个子区间, 每个子区间都满足所有数都在y和x之间(包括x和y)
那么问题就转换成了求给定一个区间求有多少个子区间,这里有个公式,假设区间长度为n, 则子区间个数 = n*(n+1)/2。
公式证明:
枚举左端点,对于每个固定的左端点找到右端点的个数,比如 以第一个点为左端点的子区间的个数为:n,以第二个点为左端点的子区间个数为n-1,
... 以第n个点为左端点的区间个数为1。将以上的所有情况相加:n + (n-1) + (n-2) + ... + 1 = n * (n+1) / 2 (等差数列求和)。最后根据前面的容斥原理得出答案。
——by junlin623 博客园

- /*参考书写规范,非力扣平台*/
- #include <bits/stdc++.h>
- using namespace std;
- #define rep(i,a,b) for(int i = a;i < b;i++)
- #define per(i,a,b) for(int i = b - 1;i >= a;i--)
- #define all(x) (x).begin(),(x).end()
- #define fi first
- #define se second
- typedef long long ll;
- typedef pair<int,int> PII;
- typedef vector<int> VI;
-
- const int N = 200010;
- int a[N], n, x, y;
-
- ll get(int l,int r) {
- ll res = 0, cnt = 0;
- rep(i,0,n) {
- if(a[i] < l || a[i] > r) res += 1ll * cnt * (cnt + 1) / 2, cnt = 0;
- else cnt++;
- }
-
- 注意a[n]也是个分界线,所以循环结束后要再次处理
-
- if(cnt) res += 1ll * cnt * (cnt + 1) / 2;
- return res;
- }
-
- int main() {
- scanf("%d%d%d", &n, &x, &y);
- rep(i,0,n) scanf("%d", &a[i]);
- printf("%lld\n", get(y,x) - get(y+1,x) - get(y,x-1) + get(y+1,x-1));
- return 0;
- }
- 作者:junlin623
方法三:双指针
和上一个方法一样,也是将区间进行划分,不同的是,我们是直接求每个子区间中满足条件的区间数量(不再统计全部)
这样对于每个子区间的统计就可以用双指针来做,具体看代码。
—— by junlin623 博客园
- /*注意代码书写规范,非力扣平台*/
- #include <bits/stdc++.h>
- using namespace std;
- #define rep(i,a,b) for(int i = a;i < b;i++)
- #define per(i,a,b) for(int i = b - 1;i >= a;i--)
- #define all(x) (x).begin(),(x).end()
- #define fi first
- #define se second
- typedef long long ll;
- typedef pair<int,int> PII;
- typedef vector<int> VI;
-
- const int N = 200010;
- int n, x, y, idx;
-
- 数组里的每一个元素都是vector<int>
-
- VI v[N];
-
-
- int main() {
- scanf("%d%d%d", &n, &x, &y);
- //最大值是x,最小值是y
- //将每一段子区间都放到一个vector中
- rep(i,0,n) {
- int xx;
- scanf("%d", &xx);
- if(xx < y || xx > x) {
- if(v[idx].size() != 0)
- idx++;
- }
- else v[idx].push_back(xx);
- }
-
- ll res = 0;
-
- rep(i,0,idx+1) {
- unordered_map<int,int> hs; //开哈希表用来统计是否出现x和y
- for(int j = 0, k = 0;j < (int)v[i].size();j++) {
- while((hs[x] == 0 || hs[y] == 0) && k < (int)v[i].size()) {
- hs[v[i][k]]++;
- k++;
- }
- if(hs[x] != 0 && hs[y] != 0) res += (int)v[i].size() - k + 1; //此时以k和这个区间末尾之间的所有位置都可以作为以j位置为左端点区间的右端点
- hs[v[i][j]]--; //j右移一位,将这个位置的数值从哈希表中移除
- }
- }
-
- printf("%lld\n", res);
- return 0;
- }
方法四:滑动窗口(RMQ)(截止本次更新时未弄清)
这题要用的主要性质是集合的最小(最大)值的单调性,即
若 A ⊆ B,则 minA ≥ minB, maxA ≤ maxB
如果固定子数组的一端,则子数组的最小(最大)值关于另一端点具有单调性,因此可以使用二分查找、滑动窗口来求出使得最小(最大值)值落在某一范围内的区间。
使用二分查找的话,需要大量计算快速计算区间最小(最大)值,这是经典的 RMQ 问题,使用 ST 表解决,初始化复杂度 O(nlogn),单次查询复杂度 O(1),二分需要查询区间最值 O(nlogn) 次,总复杂度为 O(nlogn)。
使用滑动窗口的话,维护滑动窗口的最小(最大)值也是经典问题(239. 滑动窗口最大值),方法很多,如懒惰删除的堆、前面提到的 ST 表,最好的方法是使用单调队列,插入、删除、查询的均摊复杂度为 O(1),总复杂度为 O(n)。
本题既需要维护最大值,又需要维护最小值,同时需要维护的是最小(最大)值等于某个值的区间,因此需要 4 次二分查找(4 个单调队列)。
- /*ST表模板*/
-
- template<typename T, typename Op>
-
- class SparseTable {
-
- public:
-
- using value_type = T;
-
- using size_type = unsigned;
-
- private:
-
- Op op;
-
- size_type n;
-
- std::unique_ptr<value_type[]> data;
-
- static constexpr size_type log2(size_type n) {
-
- return 31 - __builtin_clz(n);
-
- }
-
- static constexpr size_type log(size_type n) {
-
- return n > 1 ? log2(n - 1) + 1 : n;
-
- }
-
- void build() {
-
- const auto ptr = data.get();
-
- for (size_type i = 1;(1 << i) < n;++i) {
-
- const auto pre = ptr + n * (i - 1);
-
- const auto cur = ptr + n * i;
-
- const size_type d = 1 << (i - 1);
-
- const size_type m = n - (1 << i);
-
- for (size_type j = 0;j <= m;++j)
-
- cur[j] = op(pre[j], pre[j + d]);
-
- }
-
- }
-
- public:
-
- template<typename It>
-
- SparseTable(It s, size_type n, const Op& op = Op{})
-
- : op(op), n(n), data(std::make_unique<value_type[]>(n * log(n))) {
-
- const auto ptr = data.get();
-
- std::copy_n(s, n, ptr);
-
- build();
-
- }
-
- template<typename S>
-
- SparseTable(const S& s, const Op& op = Op{})
-
- : SparseTable(std::data(s), std::size(s), op) {}
-
- value_type query(size_type l, size_type r, const value_type& unitary = value_type{}) const {
-
- if (r <= l) return unitary;
-
- const size_type h = log(r - l) - 1;
-
- const auto row = data.get() + n * h;
-
- return op(row[l], row[r - (1 << h)]);
-
- }
-
- };
-
- template<typename It, typename Op>
-
- SparseTable(It, std::size_t, const Op&)
-
- -> SparseTable<typename std::iterator_traits<It>::value_type, Op>;
-
- template<typename S, typename Op>
-
- SparseTable(const S& s, const Op& op)
-
- -> SparseTable<typename std::iterator_traits<decltype(std::begin(s))>::value_type, Op>;
-
-
- /*main部分*/
- class Solution {
-
- public:
-
- long long countSubarrays(const vector<int>& nums, int minK, int maxK) {
-
- const int n = nums.size();
-
- SparseTable st1(nums.data(), n, [] (int x, int y) {
- return min(x, y);
- });
-
- SparseTable st2(nums.data(), n, [] (int x, int y) {
- return max(x, y);
- });
-
- /*二分查找*/
- const auto search = [&] (int l, int r, auto&& p) {
-
- while (l < r) {
-
- const int mid = (l + r) / 2;
-
- if (p(mid))
-
- l = mid + 1;
-
- else
-
- r = mid;
-
- }
-
- return l;
-
- };
-
- long long ans = 0;
-
- for (int i = 1;i <= n;++i) {
-
- const int l1 = search(0, i, [&] (int p) { return st1.query(p, i, INT_MAX) < minK; });
-
- const int r1 = search(0, i, [&] (int p) { return st1.query(p, i, INT_MAX) <= minK; });
-
- const int l2 = search(0, i, [&] (int p) { return st2.query(p, i, INT_MIN) > maxK; });
-
- const int r2 = search(0, i, [&] (int p) { return st2.query(p, i, INT_MIN) >= maxK; });
-
- ans += max(min(r1, r2) - max(l1, l2), 0);
-
- }
-
- return ans;
-
- }
-
- };
- 作者:白
- /*单调队列解法*/
- class Solution {
-
- public:
-
- long long countSubarrays(const vector<int>& nums, int minK, int maxK) {
-
- const int n = nums.size();
-
- long long ans = 0;
-
- int q1[n], l1 = 0, r1 = 0;
-
- int q2[n], l2 = 0, r2 = 0;
-
- int q3[n], l3 = 0, r3 = 0;
-
- int q4[n], l4 = 0, r4 = 0;
-
- int p1 = -1, p2 = -1, p3 = -1, p4 = -1;
-
- for (int i = 0;i < n;++i) {
-
- while (l1 < r1 && nums[q1[r1 - 1]] > nums[i])
-
- --r1;
-
- q1[r1++] = i;
-
- while (l1 < r1 && nums[q1[l1]] < minK)
-
- p1 = q1[l1++];
-
- while (l2 < r2 && nums[q2[r2 - 1]] > nums[i])
-
- --r2;
-
- q2[r2++] = i;
-
- while (l2 < r2 && nums[q2[l2]] <= minK)
-
- p2 = q2[l2++];
-
- while (l3 < r3 && nums[q3[r3 - 1]] < nums[i])
-
- --r3;
-
- q3[r3++] = i;
-
- while (l3 < r3 && nums[q3[l3]] > maxK)
-
- p3 = q3[l3++];
-
- while (l4 < r4 && nums[q4[r4 - 1]] < nums[i])
-
- --r4;
-
- q4[r4++] = i;
-
- while (l4 < r4 && nums[q4[l4]] >= maxK)
-
- p4 = q4[l4++];
-
- ans += max(min(p2, p4) - max(p1, p3), 0);
-
- }
-
- return ans;
-
- }
-
- };
- 作者:白
持续更新......(51200字)
- 本文属于「征服LeetCode」系列文章之一,这一系列正式开始于2021/08/12。由于LeetCode上部分题目有锁,本系列将至少持续到刷完所有无锁题之日为止;由于LeetCode还在不断地创建新题,本系列的终止日期可能是永远。在这一系... [详细]
赞
踩
 给你一个下标从0开始的mxn整数矩阵grid。你一开始的位置在左上角格子(0,0)。当你在格子(i,j)的时候,你可以移动到以下格子之一:满足j
给你一个下标从0开始的mxn整数矩阵grid。你一开始的位置在左上角格子(0,0)。当你在格子(i,j)的时候,你可以移动到以下格子之一:满足j赞
踩
- 【代码】LeetCode//C-1071.GreatestCommonDivisorofStrings。LeetCode//C-1071.GreatestCommonDivisorofStrings1071.GreatestCommonDi... [详细]
赞
踩
- 从二分+堆的角度带你打开矩阵中战斗力最弱的K行【每日挠头算法题】LeetCode1337.矩阵中战斗力最弱的K行——二分+排序/堆... [详细]
赞
踩
- 在LeetCode刷题的字符串和数组篇章,探索算法和数据结构的精华。通过挑战不同难度的问题,程序员能够培养对字符串和数组处理的深刻理解。这一篇章的问题范围广泛,包括搜索、排序、滑动窗口、动态规划等。通过解决这些问题,学习者将提高对字符串和数... [详细]
赞
踩
- 【代码】LeetCode//C-2130.MaximumTwinSumofaLinkedList。LeetCode//C-2130.MaximumTwinSumofaLinkedList2130.MaximumTwinSumofaLinke... [详细]
赞
踩
- 程序设计(上机)题库。C/C++程序设计(上机)题库(12题)[2023-12-05]C/C++程序设计(上机)题库(12题)[2023-12-05]程序设计(上机)题库1.ATM模拟器难度等级☆☆课题描述ATM的管理系统是银行流程业务中,... [详细]
赞
踩
- 在LeetCode上刷题时的学习笔记。_项目lessonlearn项目lessonlearn首先先赞一下LeetCode,这道题暴力解法(会超时)原本的Java版参考答案中有一处错误,反馈后仅仅5分钟就解决了,算上读题理解代码的时间,意味着... [详细]
赞
踩
- 【LeetCode:135.分发糖果+贪心】n个孩子站成一排。给你一个整数数组ratings表示每个孩子的评分。你需要按照以下要求,给这些孩子分发糖果:每个孩子至少分配到1个糖果。相邻两个孩子评分更高的孩子会获得更多的糖果。请你给每个孩子分... [详细]
赞
踩
- 【代码】LEETCODE164破解闯关密码。LEETCODE164破解闯关密码classSolution{public:stringcrackPassword(vector<int>&password){//在比较两个字... [详细]
赞
踩
- LeetCode206反转链表Leetcode206反转链表反转链表准备工作1)ListNode基本结构2)初始化ListNode集合解法一:遍历创建新节点解法二:两组List,面向对象操作解法三:递归调用解法四:直接移动解法五:解法二的面... [详细]
赞
踩
- 可以发现展开的顺序其实就是二叉树的先序遍历。算法和94题中序遍历的Morris算法有些神似,我们需要两步完成这道题。Leetcode—114.二叉树展开为链表【中等】2023每日刷题(九十八)Leetcode—114.二叉树展开为链表Mor... [详细]
赞
踩
- 232.用栈实现队列-力扣(LeetCode)题解:https://leetcode.cn/problems/implement-queue-using-stacks/solutions/2614065/s2kong-shi-cai-ba-... [详细]
赞
踩
- 如果会一点数论就不用深搜啦初等数论,LeetCode365.水壶问题一、题目1、题目描述有两个水壶,容量分别为 jug1Capacity 和 jug2Capacity 升。水的供应是无限的。确定是否有... [详细]
赞
踩
- 给定一个区间的集合intervals,其中intervals[i]=[starti,endi]。返回需要移除区间的最小数量,使剩余区间互不重叠。将数组按照左边界或者右边界从小到大排序,目的是为了将容易重叠的区间放在一块,本题解采用左边界排序... [详细]
赞
踩
- 每日一题leetcode-2859.计算K置位下标对应元素的和题目描述:https://leetcode.cn/problems/sum-of-values-at-indices-with-k-set-bits/description/思路... [详细]
赞
踩
- LeetCode2859.计算K置位下标对应元素的和:遍历(附Python一行代码版)给你一个下标从0开始的整数数组nums和一个整数k。请你用整数形式返回nums中的特定元素之和,这些特定元素满足:其对应下标的二进制表示中恰存在k个置位。... [详细]
赞
踩
- 使用Nodejs抓取的LeetCode简单算法题一步一步来,先攻破所有简单的题目,有些题目不适合使用JS解决,请自行斟酌Letcode简单题汇总104.MaximumDepthofBinaryTree||Givenabinarytree,f... [详细]
赞
踩
- 无重叠区间给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。注意:可以认为区间的终点总是大于它的起点。区间[1,2]和[2,3]的边界相互“接触”,但没有相互重叠。示例1:输入:[[1,2],[2,3],[3,4],[1,... [详细]
赞
踩
- 首先将每个数组元素按照左端点从小到大排序(可以用Java排序器实现),创建一个merged数组用来存放最终结果,然后依次遍历每一个数组元素取出左端点L和右端点R,如果merged数组中无内容或当前遍历数组的左端点比merged最后一个元素右... [详细]
赞
踩

