
- 1Android AudioManager
- 2在IXDP425上安装ecos3 redboot
- 3Ubuntu本地安装MySQL8.0以及常见问题设置方法_ubuntu安装mysql8.0
- 4TensorRT加速方法介绍(python pytorch模型)_detected invalid timing cache, setup a local cache
- 5操作系统笔记、面试八股(三)—— 系统调用与内存管理_计算机 系统调用
- 6计算24点问题_四十二点左边议题的
- 7基于A*算法的路径规划实践(MATLAB语言)_栅格法环境建模
- 8DevChat:VSCode中基于大模型的AI智能编程助手_vscode chat插件
- 9vue+elementUi+el-upload实现上传、获取本机服务器路径、URL、document、createObjectURL、getElementsByClassName_vue获取本地文件路径
- 10学习笔记Spark(二)—— Spark集群的安装配置_spark_worker_memory
【数图大作业】基于模板匹配的文字识别(二)(文字行列分割)_模板分割和识别
赞
踩
【数图大作业】基于模板匹配的文字识别(一)
上一篇简要介绍了题目要求,并给出了实现要点和预处理部分实现方案。
下面进行行列分割部分的介绍。之所以需要进行行列分割,是因为我们的测试图像是包含多个汉字(或许还有空格和标点符号)的图片,如果直接进行模板匹配,无法确定待匹配对象。所以为了截取 ROI ,我们在对测试图像进行预处理之后,要对文字进行行列分割。
行分割
任务:
确定每行文字的开始行和结束行的位置。
步骤:
先将源图像进行二值化反色得到黑底白字的反色图,从反色图像第一行开始,判断反色图像中每行是否出现了白点,即原图中该行是否存在黑点,如果存在则表明该行存在汉字。
再次扫描,从第一行开始到倒数第二行,判断此行与下一行反色后白点总数是否满足一定条件。如果此行没有白点而下一行白点总数不为0,则下一行是汉字的上边界;如果此行白点总数不为0而下一行没有白点,则此行是汉字的下边界。
流程图:

代码:
int CVICALLBACK rowSplit (int panel, int control, int event, void *callbackData, int eventData1, int eventData2) { Point point; PixelValue grayLevel; // 每行文字上界和下界的数目 int topm=0, botm=0; // 获取输入图像的宽高 imaqGetImageSize (srcImage, &width, &height); // 每行(反色后)白点的数目 int *pt = calloc(height, sizeof(int)); switch (event) { case EVENT_COMMIT: // 出现(反色后)白色像素则确定边界 for(int h = 0; h < height; h++) { for(int w = 0; w < width; w++) { point.x = w; point.y = h; imaqGetPixel(binImage, point, &grayLevel); if(grayLevel.grayscale == 255.0) *(pt + h) = *(pt + h) + 1; } } // 记录每行文字上界和下界 for(int h = 0; h < height - 1; h++) { if(*(pt + h) == 0 & *(pt + h + 1) > 0) { topRow[topm++] = h; num_row = num_row + 1; } if(*(pt + h) > 0 & *(pt + h + 1) == 0) bottomRow[botm++] = h; } // 记录行分割后每行文字的高度 for(int topm = 0; topm < num_row; topm++) _height[topm] = bottomRow[topm] - topRow[topm]; break; } return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
列分割
任务:
确定每个文字的开始列和结束列的位置。
步骤:
在行分割的基础上,先进行行扫描,然后进行列扫描,判断一行汉字里的每一列是否出现了白点,即原图中该列是否存在黑点,如果存在则表明该列存在汉字。
再次扫描,从每一行的第一列开始扫描到倒数第二列,判断此列与下一列反色后白点总数是否满足一定条件。如果此列没有白点而下一列白点总数不为0,则下一列是字的左边界;如果此列白点总数不为0而下一列没有白点,则此列是字的右边界。
代码:
for(h = 0; h < num_row; h++) { i = 0, j = 0; // 出现(反色后)白色像素则确定边界 for(int x = 0; x < width; x++) { for(int y = topRow[h]; y <= bottonRow[h]; y++) { point.x = x; point.y = y; imaqGetPixel(binImage, point, &grayLevel); if(grayLevel.grayscale == 255.0) *(pt + h * width + x) = *(pt + h * width + x) + 1; } } // 记录每行文字左界和右界 for(int x = 0; x < width - 1; x++) { if(*(pt + h * width + x) == 0 & *(pt + h * width + x + 1) > 0) leftMargin[h][i++] = x; if(*(pt + h * width + x) > 0 & *(pt + h * width + x + 1) == 0) { rightMargin[h][j++] = x; num_col[h] = num_col[h] + 1; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
列分割的原理和行分割基本一致,但是有可能出现误分割的情况(字中间存在空隙,即某行文字中某列反色后白色像素点数目为0)。
左右结构字体防误切割
任务:
识别出类似于“八”和“川”这种可能会被误分割成两部分或三部分的字。
步骤:
1.对于“八”型的字:
如果列分割的时候被分成第h行的第i个和第i+1个字,则根据第i个和第i+1个字的左右边界坐标值是否满足一定条件,来判断是否需要合并。
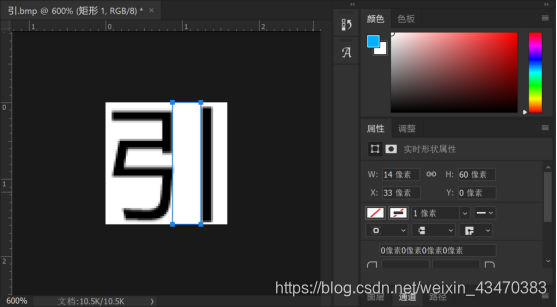
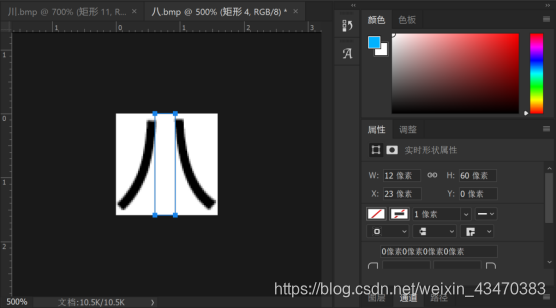
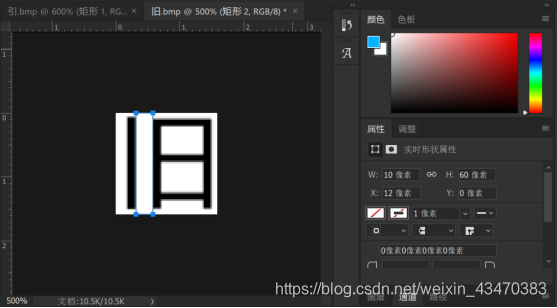
通过分析字形,确定判断条件:
(1) 第i+1个字的左边界与第i个字的右边界相距小于文字高度的三分之一;
(2) 第i+1个字的右边界与第i个字的左边界相距小于文字高度;
(3) 第i+2个字的右边界与第i个字的左边界相距大于文字高度。
以上三个条件都满足,则为“八”型的字。
对于“八”型的字,将初次列分割得到第i个和第i+1个字的左右边界合并,并将该行字的个数减去1。
2.对于“川”型的字:
如果列分割的时候被分成第h行的第i个、第i+1个字和第i+2个字,则根据第i个、第i+1个字和第i+2个字的左右边界坐标值是否满足一定条件,来判断是否需要合并。
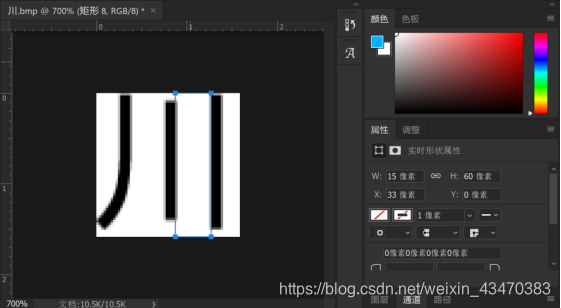
通过分析字形,确定判断条件:
(1) 第i+2个字的左边界与第i+1个字的右边界相距小于文字高度的三分之一;
(2) 第i+1个字的左边界与第i个字的右边界相距小于文字高度的三分之一;
(3) 第i+2个字的右边界与第i个字的左边界相距小于文字高度;
(4) 第i+3个字的右边界与第i个字的左边界相距大于文字高度。
以上条件(1)和(2)满足任意一条,同时满足条件(3)和(4),则为“川”型的字。
对于“川”型的字,将初次列分割得到第i个、第i+1个和第i+2个字的左右边界合并,并将该行字的个数减去2。
流程图:

代码:
for(i = 0; i < num_col[h]; i++) { // 判断是否为“八”字这类容易被误分割成两部分的字,并对此进行合并 if((leftMargin[h][i+1] - rightMargin[h][i] <= _height[h]/3) && (rightMargin[h][i+1] - leftMargin[h][i] <= _height[h]) && (rightMargin[h][i+2] - leftMargin[h][i] >= _height[h])) { for(g = i; g < num_col[h]; g++) rightMargin[h][g] = rightMargin[h][g+1]; for(j = i + 1; j < num_col[h]; j++) leftMargin[h][j] = leftMargin[h][j+1]; num_col[h] = num_col[h] - 1; } // 判断是否为“川”字这类容易被误分割成三部分的字,并对此进行合并 if(((leftMargin[h][i+2] - rightMargin[h][i+1] <= _height[h]/3) || (leftMargin[h][i+1] - rightMargin[h][i] <= _height[h]/3)) && (rightMargin[h][i+2] - leftMargin[h][i] <= _height[h]) && (rightMargin[h][i+3] - leftMargin[h][i] >= _height[h])) { for(g = i;g < num_col[h]; g++) rightMargin[h][g] = rightMargin[h][g+2]; for(j = i + 1; j < num_col[h]; j++) leftMargin[h][j] = leftMargin[h][j+2]; num_col[h] = num_col[h] - 2; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
分割效果

- 来源:力扣(LeetCode)链接:https://leetcode-cn.com/problems/remove-duplicates-from-sorted-array著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。... [详细]
赞
踩
- 飞控(Pixhawk4Mini)与机载电脑(JetsonXavierNX)实现串口通信_pixhawk4telem1串口pixhawk4telem1串口一、飞控端配置首先对Pixhawk4Mini烧录固件参考KakuteH7刷写px4固件_... [详细]
赞
踩
- article
vmtools安装时候提示unable to find the tar installer database file /etc/vmware-tools/locations_unable to find the tar installer database file (/e
出现这个问题的主要原因是你之前安装失败或者强行终止导致的解决方案进入etc目录删除vmware-tools删除命令:rm-rfvmware-tools接下来进入到tmp目录,删除以小写vm开头的所有东西rm-rf/tmpvm*..._una... [详细]赞
踩
- 一、题目描述略二、思路两个游标i、j,一个辅助变量id。 j用来记录元素要复制到的位置:也就是0、1、2、3…… i用来记录哪个元素要进行复制操作,id辅助这一过程。 j很好说,步长为1,直接for循环j++就可以了。 关键是i,关键是哪个... [详细]
赞
踩
- ERROR1105(HY000):APRIMARYKEYmustincludeallcolumnsinthetable'spartitioningfunctionMySQL里面主键及唯一索引都需要包含分区键,否则均会报错CREATETABL... [详细]
赞
踩
- 用的stm32f407芯片,定义了一个float型变量,总是进入硬件中断,按照正点原子的移植方法,修改函数也不行,从网上参考了许多方法,说是UCOS-III不支持FPU,按照说明修改了函数都不行,不经不行,而且程序完全不能运行了。后来看到有... [详细]
赞
踩
- flask搭建及部署pip19.2.3python3.7.5Flask1.1.1Flask-SQLAlchemy2.4.1Pika1.1.0Redis3.3.11flask-wtf0.14.21、创建flask项目:创建完成后整个项目结构树... [详细]
赞
踩
- linux下执行.sh文件的方法.sh文件就是文本文件,如果要执行,需要使用chmoda+xxxx.sh来给可执行权限。是bash脚本么可以用touchtest.sh#创建test.sh文件vitest.sh#编辑test.sh文件加入内容... [详细]
赞
踩
- 机器人技术是未来科技的高峰,等待着热爱机器人技术的小伙伴去征服。_jetsonnanob01jetsonnanob01文章目录一、Jetsonnano简介二、系统环境配置1、系统镜像烧录2、CUDA环境配置三、ROS安装和环境配置总结一、J... [详细]
赞
踩
- 模板中的大概内容以用户在网站中注册新账户的过程为例。用户在表单中输入电子邮件地址和密码,点击提交。于是,服务器接收到包含用户输入数据的请求,然后Flask把请求给处理注册请求的视图函数。这个视图再访问数据库,添加新用户,生成响应回送浏览器,... [详细]
赞
踩
- 什么是TTL电平,什么是CMOS电平,他们的区别(一)TTL高电平3.6~5V,低电平0V~2.4VCMOS电平Vcc可达到12VCMOS电路输出高电平约为0.9Vcc,而输出低电平约为0.1Vcc。CMOS电路不使用的输入端不能悬空,会造... [详细]
赞
踩
- 代码卡死是因为在执行RCC初始化时,由于时间太短没有延时就开始检测标志位HAL_OK是否被置位。但是这里面啥都没有还有个死循环故当标志位检测不到时卡进死循环。本文记录了使用STM32CubeMX生成配置模板,在MDK环境下撰写完逻辑代码进行... [详细]
赞
踩
- 面试的时候,总会遇到这么一个场景。1.场景分析面试官:你们的服务的QPS是多少?我:我们的服务高峰期访问量还挺大的,大约是3万吧。面试官:这么大的访问量,你们的服务器能撑住吗?有加缓存吗?我:有的,我们使用了Redis做缓存,接口优先查询缓... [详细]
赞
踩
- 我们进行套接字编程时往往只关注数据通信,而忽略了套接字具有的不同特性。但是,理解这些特性并根据实际需要进行更改也十分重要。从上表可以看出,套接字可选项是分层的。IPPROTOIP层可选项是IP协议相关事项,IPPROTO_TCP层可选项是T... [详细]
赞
踩
- article
多操作系统引导管理工具System Commander 2000 全面兼容Windows 9x/NT/2000、Linux、OS/2 Warp、 NetWare、Solaris_system command下载
多操作系统引导管理工具SystemCommander20002000-06-229:00 在多操作系统引导管理工具方面,目前比较好的工具是PowerQuest公司的BootMagic和VCommunications,Inc的SystemC... [详细]赞
踩
- 打开服务器的终端可以在pycharm中直接进行远程服务器的命令行操作。在pycharm中打开服务器的终端,不需要Git。pycharm已经连接上Linux服务器。运行run.sh文件。_pycharm在远程服务器上调试.sh文件pychar... [详细]
赞
踩
- 原文外网链接IEEE754.PDF(berkeley.edu)http://people.eecs.berkeley.edu/~wkahan/ieee754status/IEEE754.PDF百度网盘分享链接链接:https://pan.b... [详细]
赞
踩
- 给定一个二叉树的根节点root,返回它的中序遍历。示例1:输入:root=[1,null,2,3]输出:[1,3,2]示例2:输入:root=[]输出:[]示例3:输入:root=[1]输出:[1]示例4:输入:root=[1,2]输出:[... [详细]
赞
踩
- IPv4地址转地址如:输入14.197.150.014,输出河北省·石家庄市。C#IPv4转地址·地名高德需求:IPv4地址转地址如:输入14.197.150.014,输出河北省·石家庄市SDK:目前使用SDK为高德地图WebAPI高德地图... [详细]
赞
踩
- 主要讲述修复“由于i/o设备错误,无法运行此项请求”错误提示的方法,以及格式化移动硬盘的方法。_diskpart遇到错误:由于i/o设备错误,无法运行此项请求。有关详细信息,请参阅diskpart遇到错误:由于i/o设备错误,无法运行此项请... [详细]
赞
踩

