
- 1Xcode9解决exportArchive: requires a provisioning profile
- 2【开发工具】从eclipse到idea的过度
- 3flutter极光推送配置厂商通道(华为)笔记--进行中
- 4Python使用re库处理正则详解_re_extract_question
- 5Vue~~_[eslint] d:\web\vue-houtai\src\app.vue 22:8 error
- 6Unity入门小游戏 变色跑酷_unity+kinect跑酷游戏
- 7Docker仓库
- 8golang 转换时指定多个别名_go json 别名
- 9pip安装软件包报错: error subprocess-exited-with-error问题记录_error: subprocess-exited-with-error 脳 pip subproce
- 10小程序 获取微信、手机设备、账号等信息api_微信小程序api获取设备号
【Linux】基础IO -- 磁盘文件系统_linux 磁盘 文件
赞
踩
前言
上篇Linux文章,我们学习了打开文件,读写文件等的操作。这些都是针对被打开的文件。
而文件还有没有打开的状态,也就是磁盘文件。本篇博客就将会针对磁盘文件,学习其相关知识。

一. 磁盘文件
我们先思考:
- 磁盘文件如何合理存储?
- 如何定位一个文件?
- 如何对磁盘文件进行读取和写入?
1. 磁盘的物理结构
磁盘是计算机上唯一的一个
机械设备,同时也是外设
我们先了解磁盘的物理结构,这样,在后续的抽象中我们才能有更好的理解

- 盘片
盘片是多个摞在一起的,形成一层一层的盘面
盘片是类似光碟一样的东西,我们可以抽象理解为,磁盘表面有一个又一个的小磁铁,当我们向磁盘写入数据时:磁性N -> S;删除磁盘数据:磁性S -> N- 磁头
磁头为了读取数据,同样也是多个一起的,一面对应一个磁头,一个磁头负责一面的读取
因为磁头也是一层一层分布的,并固定在一起,所以磁头的摆动是共进退的- 盘片和磁头是
没有挨着的。如果挨着,那么在两者的高速转动时,就可能产热过多,导致盘片表面的磁性因高温而被破坏,进而数据丢失。但二者的距离依然很近
2. 物理层面的读写
接下来,我们尝试在物理层面了解数据在磁盘上的读和写
首先,我们先了解盘片的结构
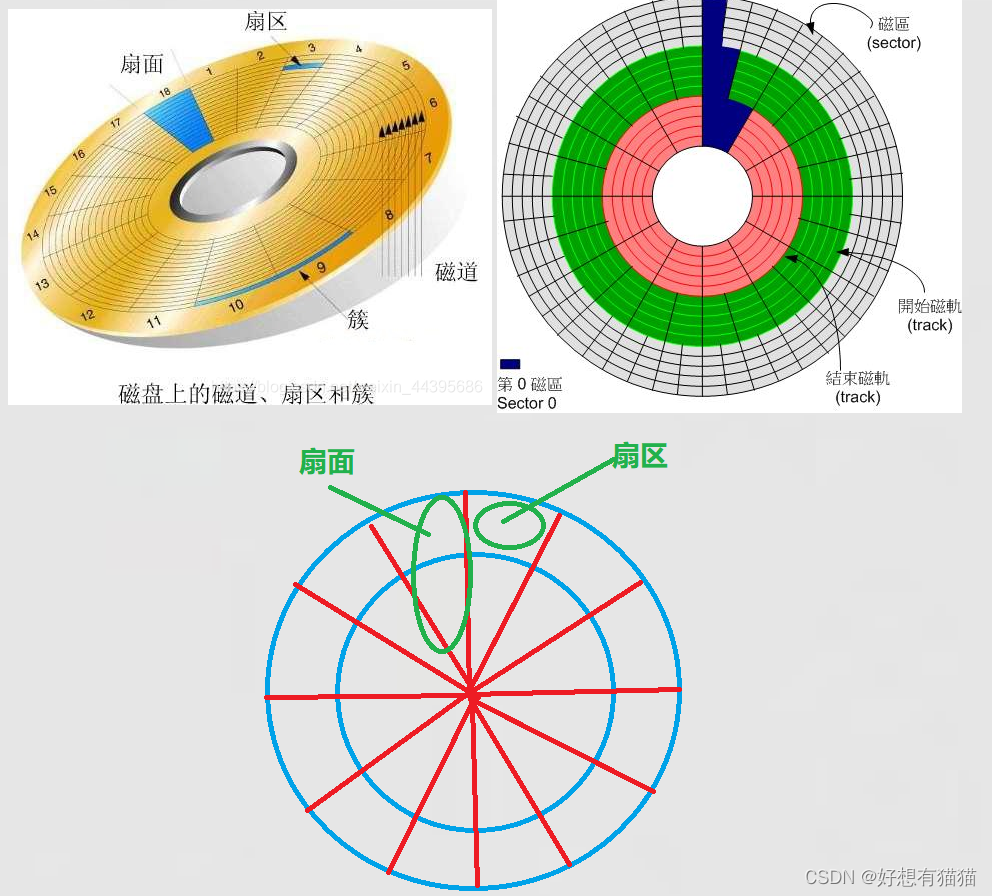
- 扇面:
盘片是一个圆形结构,通过角度可以将盘片均匀分割,而每一块就是一块扇面- 扇区
再通过从外到内,不同半径又可以分成不同区块,这些区块就是扇区。
扇区是磁盘存储的基本单元。一个扇区有512个字节,或者4kb数据。一般磁盘,所有扇区都是512字节。- 磁道
同一个半径都一圈区域是磁道,一个磁道上有半径相同的扇区
接下来,我们了解物理结构上数据的读写

数据的读写依靠的都是
磁头,马达带动传动轴,传动手臂,利用磁头在盘片上读写。
每一面盘面,每一个磁道,每一个扇区都有其相应的编号。我们可以通过这些编号,驱动磁头读取数据。
首先,我们要先确定数据在哪个盘面,也就是确定哪个磁头读取 —>磁头的编号;盘面的编号
其次,我们再定位在哪个磁道-->半径
最后,我们确定在该磁道的哪一个扇区-->扇区的编号
我们称这样的物理读取数据的方法是CHS定位法
磁头:head ;磁道(柱面):cylinder;扇区:sector取各个单词的首字母
3. 磁盘的逻辑抽象
在物理存储中,我们可以根据
CHS定位法确定所需数据所在的扇区,但是磁盘毕竟是外设,而操作系统作为内设,是否也是根据CHS定位法读取数据呢?
答案是否定的。如果操作系统,也就是软件,同样依靠CHS定位法的话,那是不是意味着这是二者沟通的唯一途径呢?但是我们上述也提及到,一般的磁盘,扇区大小是512字节,但也有4kb的,这意味着不同磁盘存储数据其实不同,那CHS定位法就不能统一,磁盘可以不同,但是操作系统对待所有磁盘应该都是相同的,所以操作系统并不直接通过CHS定位法读取数据,而是使用自己的一套逻辑
在操作系统处理现实结构时,都是采用先描述,再组织的方式抽象数据类型,在磁盘这里同样使用了这一方式

现实生活中,我们用过磁带,这也是将数据以磁性存储的设备,磁带在机子里是圆状的,但是我们将带子一点点拉出来,他就可以被我们展开成线性结构。
而在操作系统中,同样是将磁盘上的一个个磁道,抽象成一个个数组,内部存储扇区

简单的将磁盘数据存储抽象化,使用
数组下标模拟扇区的编号
但是一般一个扇区的大小是512字节,但是操作系统的读取是以4KB为单位进行IO的,所以换算过来,操作系统一次读取8个扇区。但是操作系统其实并不需要知道扇区的概念,他只把一次读取的4KB大小的数据,称为块。
计算机常规的访问方式:起始地址+偏移量
所以我们只需要知道数据块的起始地址(盘片的第一个扇区的下标地址)+4KB(块的类型),操作系统把块看作一种类型
所谓块的地址,本质就是数组的一个下标。
这种访问方式称为LAB --- logic adress block 逻辑块地址访问
操作系统通过读取块的方式,将要找的数据,传递给磁盘
OS -> N(数组下标) -> LAB -> 逻辑块地址
但是磁盘通过CHS定位法定位数据
所以LAB和CHS是需要互相转换的
二. 文件系统
之前我们所谈的文件系统并不完整,之前是针对打开的文件,而这次我们要学习的是文件系统对磁盘文件的管理。
我们使用的笔记本的存储可能会被分成2个盘,或者4个盘,我的就被分成了4个盘,分别是C,D,E,F。但这是Windows的图形化展示给我们看的,实际上我们的硬盘并没有被分成4块,其实还是完整的一块。只是通过规定界限,划分成了4个区域。

紧接着,我们知道操作系统的读取是4KB,而一个盘通常是100多GB,所以在此之下还有着划分
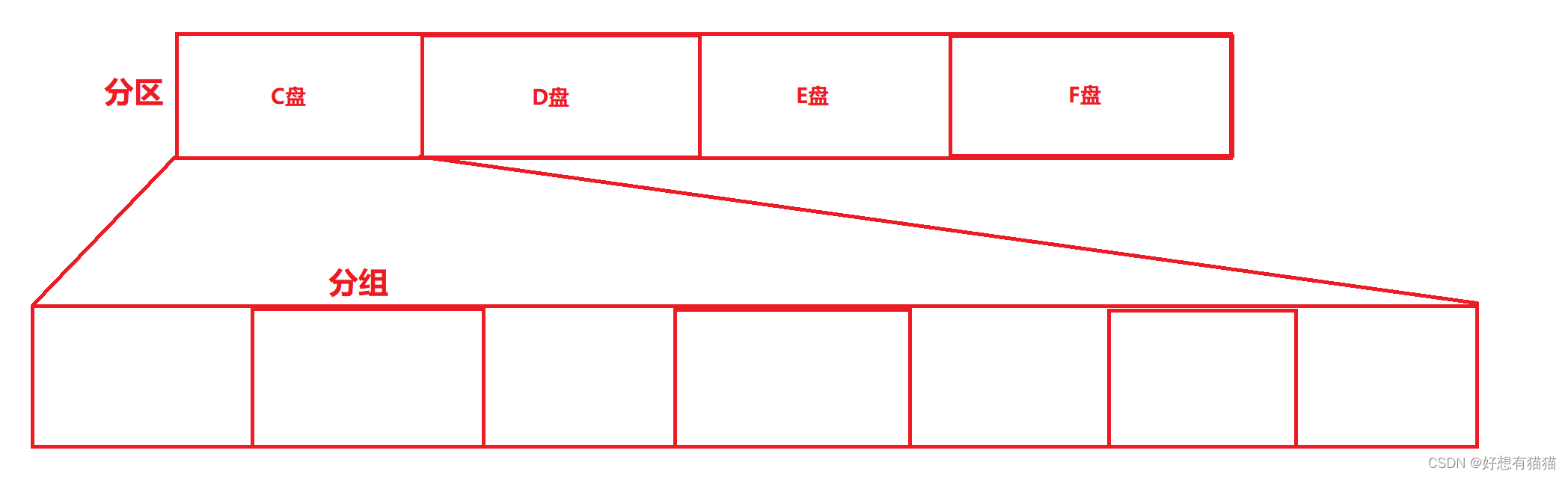
接下来,对于这个分组,我们就需要详细学习了
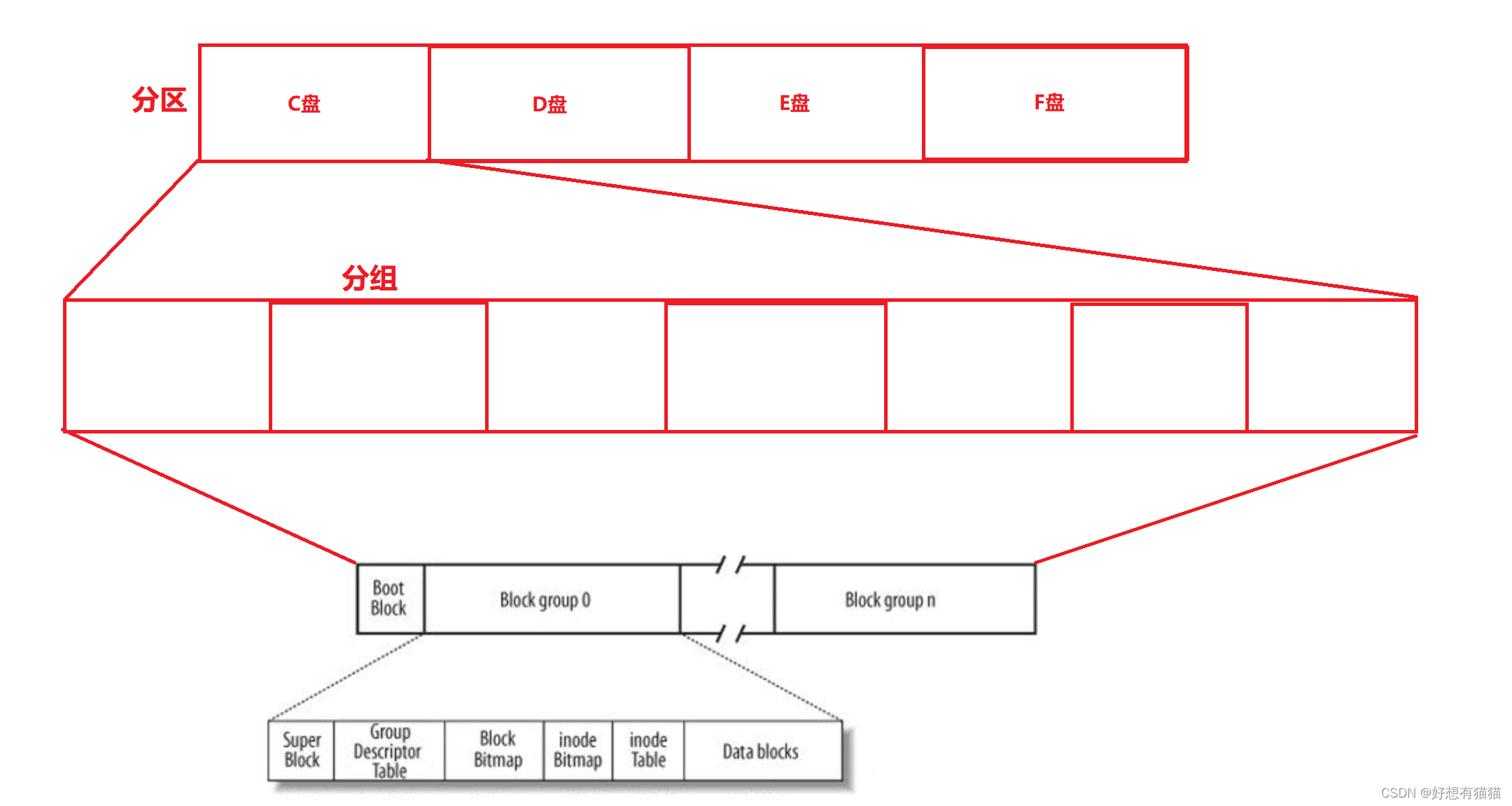
我们先看区的整体结构

Boot Block:启动块,大小为1kb,由pc标准规定的,用来存储磁盘分区信息和启动信息,任何文件系统都不能操作该块。
Block group:块组,详细如下
1. Block group
接下来,我们详细看块组的结构

文件=属性+内容
Linux是将属性和内容分开存储的,属性存储在inode Table,内容存储在Date blocks
一个文件的所有属性存放在inode节点中(128字节),一个文件,一个inode。属性包括但不限于,文件创建时间内,文件大小,文件类型,文件权限…
文件的内容是变化的,使用数据块存储文件内容,所以一个文件的内容可能由1个或多个块存储,一个块就是4KB,即使该文件内容只有1字节,仍然需要分配一个块 – 4KB存储。内容存储在Date blocks
SuperBlock:保存文件系统的所有属性信息,比如文件系统的类型(Linux是Ext),整个分组的情况(该分区有几个组,起始在哪,终止在哪,有多少被内存加载…)。SuperBlock是
统一更新的,每1个Block group中都有SuperBlock,group 0中为主,其他group为辅,主要是将SuperBlock进行备份,避免因为一点损害导致全局不可用。因为SuperBlock关乎与数据,所以需要备份。
Group Descriptor Table 组描述表:描述group内各个位置存储的信息,如Block Bitmap的起始位置和length等等。inode table:保存group内所有文件的inode节点,每一个inode都有自己的inode编号,这个编号也属于文件的属性。
inodeData blocks:存储当前group所有文件的内容。一个inode对应一个文件,而该文件inode属性和该文件对应的数据块,
有映射关系。inode内存储该文件内容所在数据块在Date blocks的下标(可多个)。
Block Bitmap位图&inode Bitmap位图:每一个bit表示是否空闲,描述哪些data block或inode block是空闲或者被占用的。
2. 文件名和inode编号
Linux系统只认识
inode编号,文件的inode属性中,并不存在文件名。
文件名是给用户看的
目录其实也是文件,拥有自己的inode,但其内容和普通文件有所不同
任何一个文件,一定在一个目录内部,目录的数据块里面保存的是,该目录下,文件名和文件inode编号的映射关系,而且在目录中,文件名和inode互为key值(可通过文件名找到inode,可通过inode找到文件名)。
3. 文件的读取
当我们访问一个文件的时候,我们是在特定目录下访问:cat log.txt
- 先要在当前目录下,通过文件名找到对应文件的inode编号
- 一个目录也是文件,一定隶属于一个分区,结合inode,在分区中找到分组,在分组中找到文件的inode。
- 再通过找到的inode,找到该文件的数据块Date blocks,并加载到OS,并完成显示器显示
4. 文件的删除
要删除文件,首先要
找到该文件,查找的过程就和文件的读取一样,之后,文件的删除其实并不是将Date blocks里的数据清空,而是将Block Bitmap和inode Bitmap中该文件的位图置为0,下一次在该位置创建文件,写新文件时,可以直接进行覆盖。
当我们误删文件的时候,Linux下,我们可以在日志中找到删除文件的inode编号,我们以此就可以找到原文件的inode,再找到其inode Bitmap和Block Bitmap,将其置为1,这样创建新文件的时候,就不会在这个位置进行覆盖了,文件也恢复了。
Windows下,可以在回收站中找到,回收站类似日志,但是文件进入回收站,其实只是Linux下的mv,剪切移到回收站,清空回收站,才对应Linux下的rm。
5. inode映射关系
inode其实是一个结构体,我们上面说过,一个inode是128字节,存储相应的Date blocks的地址使用数组,但是128字节也存储不了几个地址,那这不就意味着inode存储的对应文件的大小并不大,但是实际上,一个文件大到,几百MB,GB。所以inode和Date blocks的映射关系到底是什么呢?
inode中存储Date block的地址确实是使用数组,但数组映射的Date block中可能并不是存储的文件的内容。
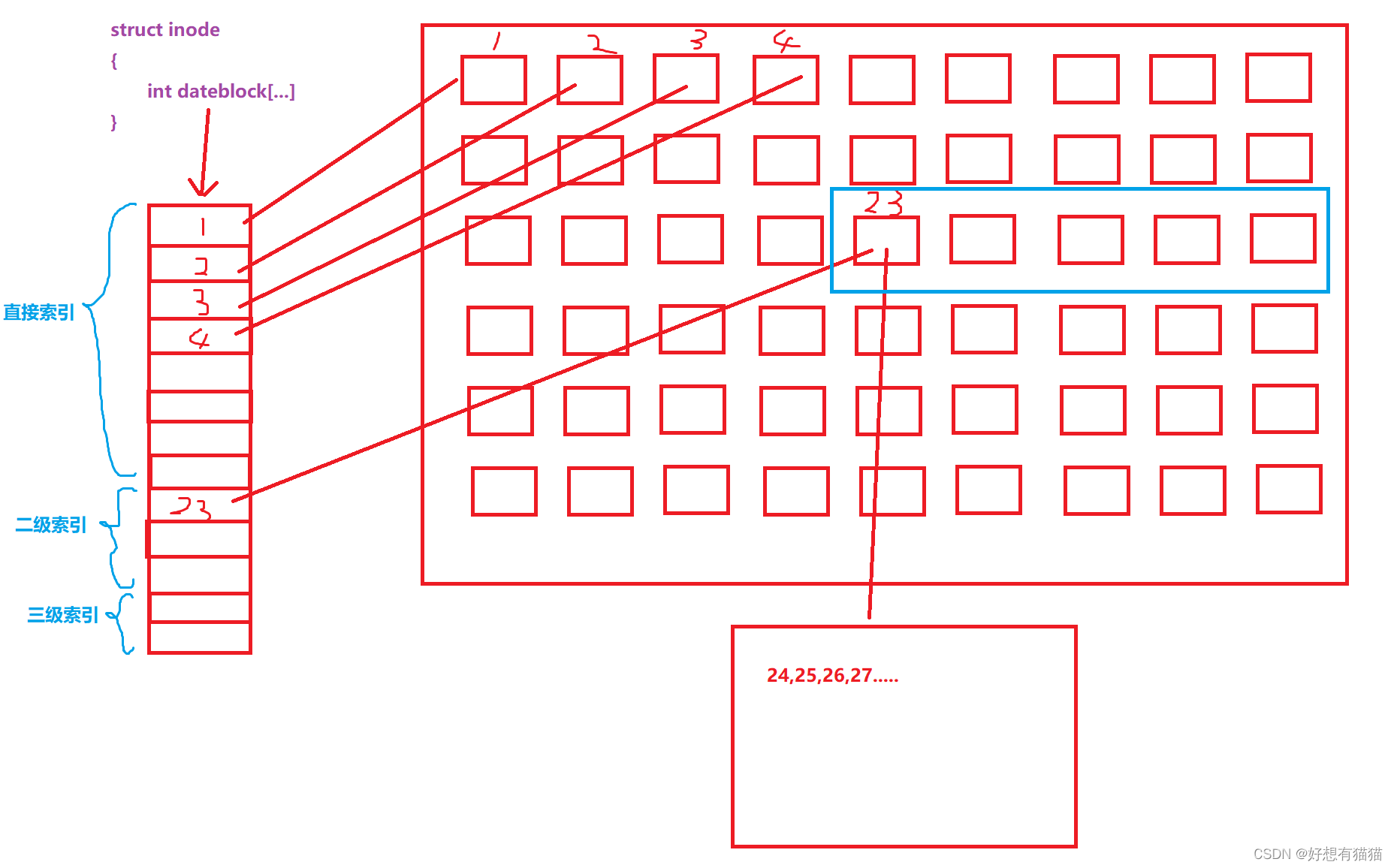
直接索引
存储的直接就是相应的内容的Date block,如图的1,2,3,4其内部直接是文件的内容二级索引
inode中存储的地址对应的Date block内部不是文件的内容,而是其他Date block的下标,代表该文件由多个Date block存储内容
。这样文件的大小不就可以存储更多了吗三级索引
同二级索引一样,但是inode对应的Date block存储的是二级索引的Date block,内部继续存储Date block的下标
6. 补充知识
- inode编号,
可以直接确定该inode在本区内的位置,不能跨分区。- 分区,分组,Block group的内部结构,都是
操作系统帮我们划分,管理的。在安装操作系统的时候,这些内容其实就已经在执行了。格式化,其实就是操作系统向分区写入文件系统的管理属性存在数据块存满,inode没用完或者inode用完了,但是数据块没用完。
如果一直创建空文件,inode就可以被用完,但是数据块显然没用完
如果只创建少数文件,但一直往这几个文件内写内容,也存在数据块满了,但是inode没用完的情况。目录也是文件,我们上面讲到,文件名并不是文件的属性,没有存储在inode结构体中,而是存储在目录中,但目录也是文件,那文件名和inode的映射关系到底在哪呢?
答案是,在操作系统眼中,目录和普通文件都是文件,目录的属性等也是存储在其inode结构体中,但目录的数据/内容,就是该目录下各文件名和inode的映射关系。详细我们在下篇博客 – 软硬链接,还会学习到
结束语
磁盘文件系统的学习大致就到这,读者可以结合博主前面的【Linux】文件操作和【Linux】重定向,这样就是一个完整的文件系统,包括操作系统如何打开/关闭,如何对文件做读写,重定向在文件操作角度是如何实现的。
如果觉得本篇文章对你有所帮助的话,不妨点个赞支持一下博主,拜托啦,这对我真的很重要。

- DataEase是开源的数据可视化分析工具,帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。是开源的数据可视化分析工具,帮助用户快速分析数据并洞察业务趋势,从而实现业务的改进与优化。在本地搭建后,借助cpolar内网穿透实现远... [详细]
赞
踩
- 介绍socket编程,简单实现一个UDP服务器✨✨【Linux】套接字编程目录套接字IP+PORTTCP和UDP的介绍TCPUDP网络字节序转换接口UDP服务器的编写服务器的初始化 socketbindsockaddr结构服务器的... [详细]
赞
踩
- 本文是对Linux中文件和目录权限的总结。以上就是我对于Linux中文件和目录权限的总结。!!Linux:权限个人主页:个人主页个人专栏:《数据结构》《C语言》《C++》《Linux》文章目录前言一、Linux权限的管理文件访问者的分类(身... [详细]
赞
踩
- 看了这篇文章你将学到软硬链接的使用,以及制作自己的动静态库,并使用他们✨✨_动态库的软连接动态库的软连接系列文章收录于【Linux】文件系统 专栏关于文件描述符与文件重定向的相关内容可以移步 文件描述符与重定向操作。可以... [详细]
赞
踩
- 讲述Linux的基本指令:man、cp、mv、cat、more、less、head、tail等指令。【走进Linux的世界】Linux---基本指令(2)个人主页:平行线也会相交欢迎点赞... [详细]
赞
踩
- 上一篇文章中我们讲到了很多的网络名词以及相关知识,下面我们就直接进入udp服务器的实现。一、udp服务器的实现cc=g++.PHONY:allclean:我们通过all就可以创建多个可执行程序了,对于cc这个变量我们设置为g++,以后如果想... [详细]
赞
踩
- Linux防火墙服务和区的不同配置操作,放行端口或服务等_linux防火墙配置linux防火墙配置目录防火墙介绍zones预定义服务firewalld启动与停止查看firewalld当前状态和设置使⽤CLI查看firewalld设置fire... [详细]
赞
踩
 MeterSphere是一站式开源持续测试平台,涵盖测试跟踪、接口测试、UI测试和性能测试等功能,全面兼容JMeter、Selenium等主流开源标准,有效助力开发和测试团队充分利用云弹性进行高度可扩展的自动化测试,加速高质量的软件交付,推... [详细]
MeterSphere是一站式开源持续测试平台,涵盖测试跟踪、接口测试、UI测试和性能测试等功能,全面兼容JMeter、Selenium等主流开源标准,有效助力开发和测试团队充分利用云弹性进行高度可扩展的自动化测试,加速高质量的软件交付,推... [详细]赞
踩
- KaliLinux是一款基于Debian的发行版,这意味着它拥有强大的社区支持和丰富的软件资源。它被设计为具有快速、轻量级的特性,特别适合在虚拟机和闪存驱动器上运行。KaliLinux的目标是成为网络和安全专业人士的首选工具,它提供了广泛的... [详细]
赞
踩
- 注意事项:下载openssh9.3p2的安装包:或者是使用我提供的离线包:openssh7.4p1升级到openssh9.3p2所需的离线包网盘下载:链接:https://pan.baidu.com/s/1W426VDGwchE9ndKGV... [详细]
赞
踩
- mkdir命令是Linux系统中的一个用于创建目录的命令。它的作用是在指定的路径下创建一个新的目录。使用mkdir命令可以方便地创建一个空的目录,该目录可以用于存储文件或其他目录。通过指定路径参数,可以在当前工作目录或其他指定目录下创建新的... [详细]
赞
踩
- 上篇文章我们说学习系统我们要翻越三座大山:进程周边、文件周边以及线程周边。那今天我们就对第一座大山:进程周边开启攀登之旅【Linux】进程周边001之进程概念... [详细]
赞
踩
- >对于企业网络安全建设工作的质量保障,业界普遍遵循PDCA(计划(Plan)、实施(Do)、检查(Check)、处理(Act))的方法论。近年来,网络安全攻防对抗演练发挥了越来越重要的作用。企业的安全管理者通过组织内部或外部攻击队,站在恶意... [详细]
赞
踩
 上篇文章我们最后提到了进程的并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。那么Linux是如何完成进程切换的呢?本篇文章博主会与大家共同领略Linux系统进程调度算法之美。【Linux】进... [详细]
上篇文章我们最后提到了进程的并发:多个进程在一个CPU下采用进程切换的方式,在一段时间之内,让多个进程都得以推进,称之为并发。那么Linux是如何完成进程切换的呢?本篇文章博主会与大家共同领略Linux系统进程调度算法之美。【Linux】进... [详细]赞
踩
- 【代码】【Linux】项目自动化构建工具-make/Makefile。【Linux】项目自动化构建工具-make/Makefile背景会不会写makefile,从侧面说明了一个人是否具备完成大型工程的能力。一个工程中的源文件不计数,其按类型... [详细]
赞
踩
- 1.申请锁和释放锁本身就被设计成了原子性操作2.当线程访问临界区的过程,对于其他线程是原子的(对于其他线程来讲,一个线程要么没有锁,要么释放锁)。3.在临界区中,线程可以被切换,(在线程被切出去的时候,是持有锁被切走的,我不在期间,你们没有... [详细]
赞
踩
- 本文是对Linux中vim使用的总结以上就是我对于Linux中vim使用的总结。!!Linux:vim的简单使用个人主页:个人主页个人专栏:《数据结构》《C语言》《C++》《Linux》文章目录前言一、vim的基本概念二、vim的基本操作三... [详细]
赞
踩
- umount命令用于卸载(取消挂载)已经挂载的文件系统,使其从文件系统树中移除。它用于断开文件系统与指定挂载点之间的连接,以便安全地卸载文件系统。_取消挂载取消挂载目录标题描述语法格式参数说明错误情况注意事项底层实现示例示例一示例二示例三示... [详细]
赞
踩
- 【Linux】探索Linux进程优先级|环境变量|本地变量|内建命令【Linux】探索Linux进程优先级|环境变量|本地变量|内建命令最近,我发现了一个超级强大的人工智能学习网站。它以通俗易懂的方式呈现复杂的概念,而且内容风趣幽默。我觉得... [详细]
赞
踩
- t:显示TCP连接-u:显示UDP连接-l:仅显示监听状态的连接-n:以数字形式显示端口号,而不是以服务名称显示通过管道符号|将netstat的输出结果传递给grep命令,用于过滤出包含指定端口号的行。执行命令后,终端将显示与该端口号相关的... [详细]
赞
踩

