
- 1【微信小程序开发】学习小程序的模块化开发(自定义组件和分包加载)
- 2深度解析用户画像标签体系构建方法
- 3android studio 连接安卓手机/鸿蒙手机教程_android studio 鸿蒙
- 45月22日比特币披萨日,今天你吃披萨了吗?
- 5HarmonyOS播放视频及音乐
- 6k8s中如何使用gpu、gpu资源讲解、nvidia gpu驱动安装
- 7ISFP型人格的优势和劣势分析(mbti性格测试)_mbti职业性格测试isfp计算机
- 8动态规划高频问题
- 9AI 时代,程序员无需焦虑 | 《服务端开发:技术、方法与实用解决方案》(文末送书福利4.0)
- 10mysql食堂系统E R图_食堂管理系统E-R图.doc
pytorch小土堆_小土堆pytorch
赞
踩
深度学习代码
一、数据集部分
Dataset、DataLoader、transforms、SummaryWriter
二、建模部分
torch.nn包:Linear()、Conv2d()、MaxPool2d() 、Sigmoid()、ReLU()、BatchNorm2d()、Flatten()、Sequential()
三、前向传播、反向传播部分
损失器、优化器
训练:前向、反向、训练
- from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
- Sequential(
- Conv2d(3, 32, 5, padding=2),#输入通道、输出通道、卷积核、padding
- MaxPool2d(2),#池化
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),#展平
- Linear(1024, 64),#输入特征、输出特征
- Linear(64, 10)
- )
数据集
一、dir()与help()
dir()函数与help()函数
dir() 查看包里有什么
help() 查看怎么使用 help(Dataset)
Dataset?? 查看怎么使用
ctrl按住类查看
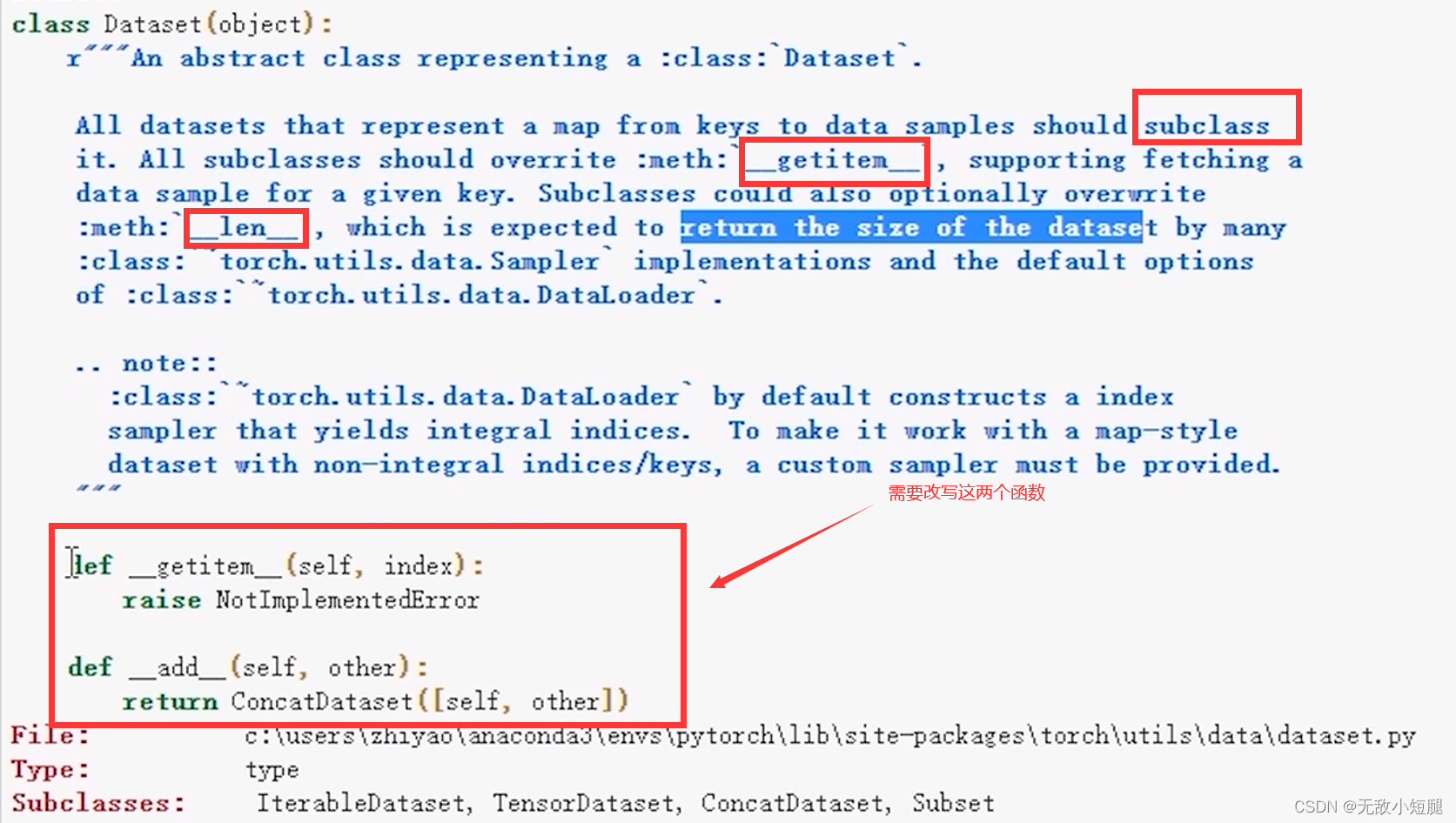
二、python文件、控制台、jupyter区别
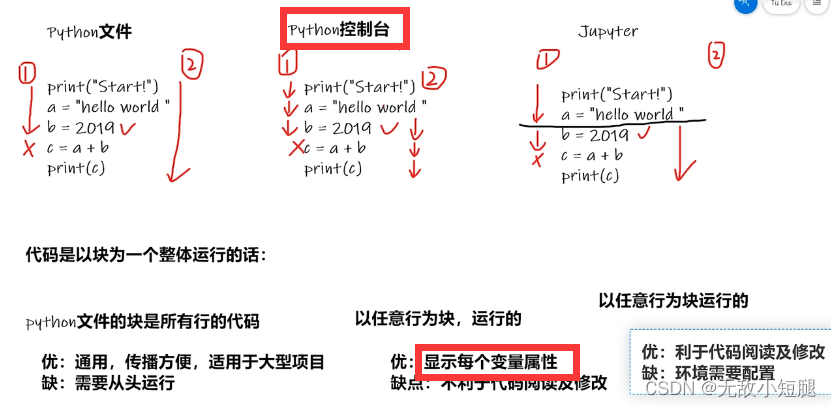
三、Dataset与DataLoader类
Dataset
1.创建一个myData类,继承Dataset类
2.重要函数
(1)初始化函数__init__():得到所有样本以及标签
(2)获取样本对函数__getitem__():获取样本对,模型直接通过这一函数获得一对样本对{x:y}
(3)返回数据集长度__len__()
3.路径函数
(1)os.path.join()将多个路径拼接
(2)os.listdir()将路径下的所有文件名组成一个列表
```
4.Dataset对象相加,即可使得多个数据集拼接;Dataset对象中可以使用root_dir和label_dir找到同标签的所有数据集
DataLoader
test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)#writer.add_images可以一幅图输出多张图片
- import torchvision
-
- # 准备的测试数据集
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
-
- test_data = torchvision.datasets.CIFAR10("./dataset", train=False, transform=torchvision.transforms.ToTensor())
-
- test_loader = DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=True)
-
- # 测试数据集中第一张图片及target
- img, target = test_data[0]
- print(img.shape)
- print(target)
-
- writer = SummaryWriter("dataloader")
- for epoch in range(2):
- step = 0
- for data in test_loader:
- imgs, targets = data
- # print(imgs.shape)
- # print(targets)
- writer.add_images("Epoch: {}".format(epoch), imgs, step)
- step = step + 1
-
- writer.close()
-
-

四、tensorboard
1.SummaryWriter类
能够绘制train_loss的图像,保存在logs文件夹里
(1)代码:
- #coding=utf-8
- '''
- 1.SummaryWriter类
- writer=SummaryWriter("logs") #logs指的是文件夹
- writer.add_scalar("y=2x", 2*i, i) #图像名,描点连直线画图
- writer.add_image("train", img_array, 1, dataformats='HWC') #train是图像名;img_array必须是numpy或者tensor型;1指的是step,把step改成2再次运行后,train图像可以左右拖动
- '''
- from torch.utils.tensorboard import SummaryWriter
- import numpy as np
- from PIL import Image
-
- writer = SummaryWriter("logs")
- image_path = "../hymenoptera_data/train/bees/205835650_e6f2614bee.jpg"
- image_path1 = "../hymenoptera_data/train/ants/0013035.jpg"
- img_PIL = Image.open(image_path)
- img_array = np.array(img_PIL)
- print(type(img_array))
- print(img_array.shape)#可以看出是(H,W,C)型
- img_PIL1 = Image.open(image_path1)
- img_array1 = np.array(img_PIL1)
- #
- #logs文件夹中保存训练的数据集
- writer.add_image("train", img_array, 1, dataformats='HWC')
- writer.add_image("train", img_array1, 2, dataformats='HWC')
-
- #logs文件中保存画图信息
- # y = 2x
- for i in range(100):
- writer.add_scalar("y=2x", 2*i, i)#"y=2x"对应一副图像,再来一次不改变""里图像名的话会在原图像上画,线会叠加
-
- writer.close()
(2)同路径的终端下输入(其中port是指定服务器,默认是6006,若冲突则更换):
tensorboard --logdir=logs --port=6007

点击后显示:

2.__call__函数可以使得对象当函数用

注意

五、tranforms
1.transforms用法
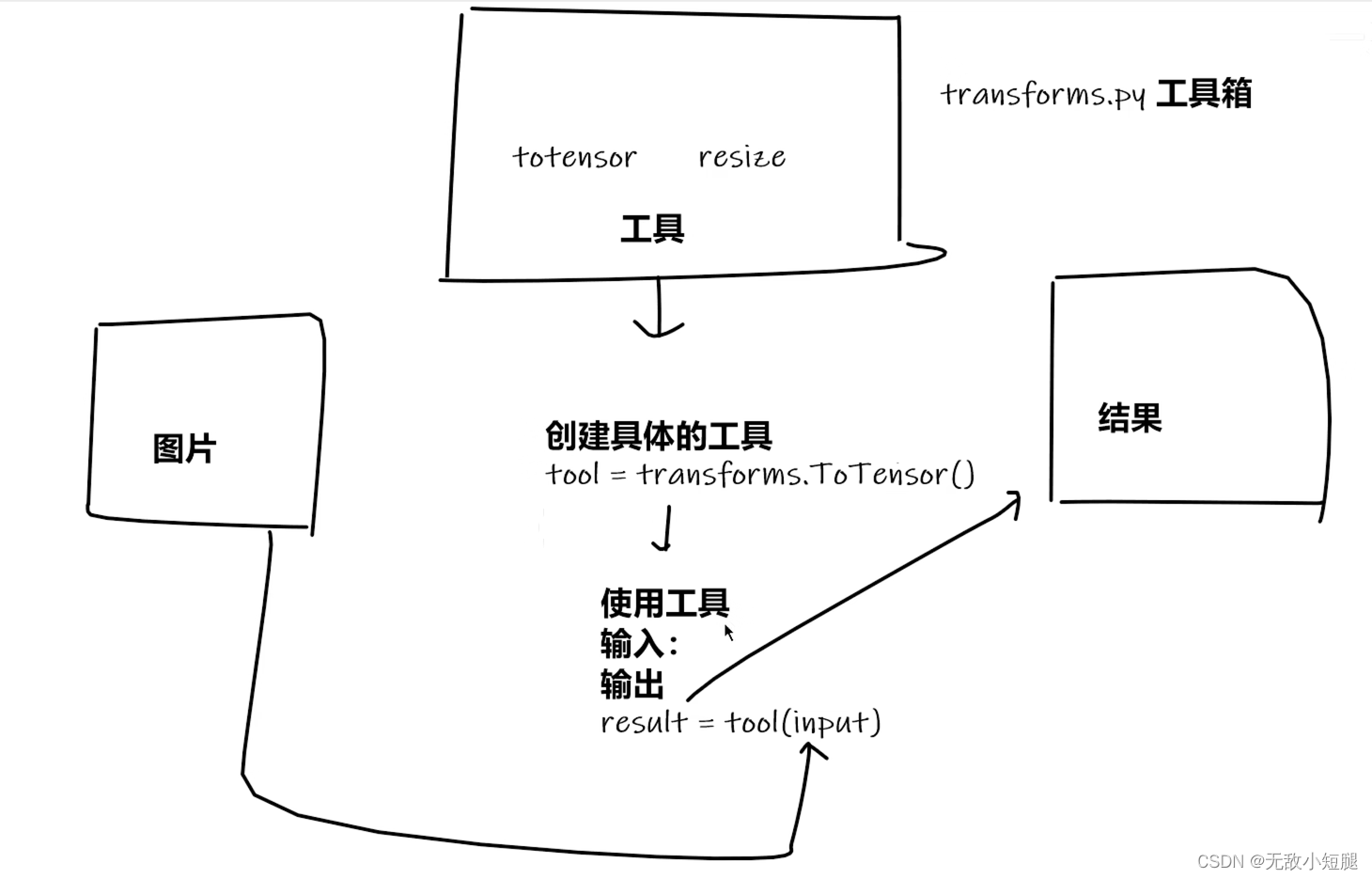
2.ToTensor()使用
- T=transforms.ToTensor() #创建一个对象
-
- input_tensor=T(input)#将numpy转化为tensor对象,将hwc转为chw
3.Normalize()使用
标准化,将像素值映射到-1到1之间
4.Resize()使用
改变图像大小,输入的是PIL或者tensor,输入与输出格式对应
5.Compose()使用
将多个操作组合在一起,注意前面对象的输出一定要对应后面对象的输入
transform = transforms.Compose([transforms.Resize(400), transforms.ToTensor()])建模
一、torch.nn包

二、torch.nn.Module类
1.任何模型需要继承Module类,并且实现__init__()以及forward()
2.调试代码

三、torch.nn.Cov2d()函数
1.卷积:对于3通道图像,卷积核通道数必须等于图像通道数
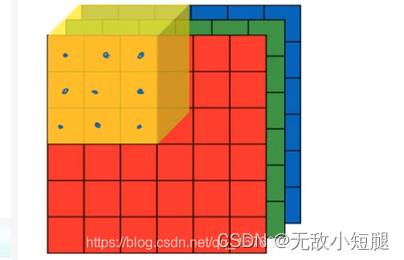
最原始的图像数据类型应该是BCHW类型的数据,卷积操作不改变B
input=torch.reshape(input,(1,1,2,2))#将input转化为BCHW类型,作为输入层所以计算CWH变化时,先对一个样本进行计算
conv1 = torch.nn.Conv2d(in_channels=3, out_channels=6, kernel_size=3, stride=1, padding=0)四、torch.nn.MaxPool2d()函数——下采样,即池化
最大池化的目的是保留原始数据特征情况下,减小数据量
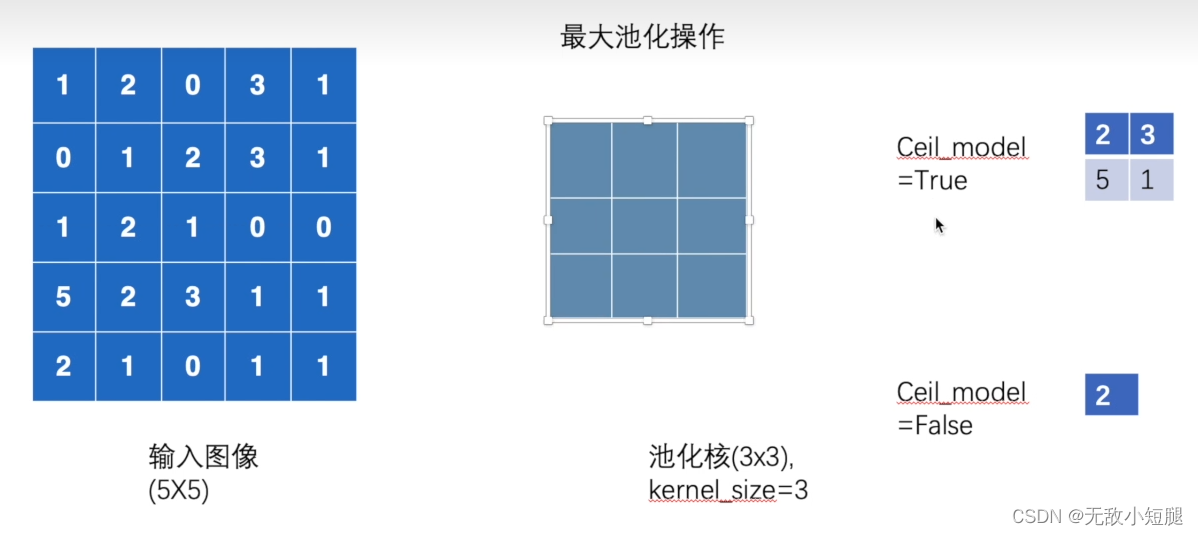
maxpool1 = torch.nn.MaxPool2d(kernel_size=3, ceil_mode=False)五、非线性激活函数
- 1.torch.nn.Sigmoid()
-
- 2.torch.nn.ReLU()
六、正则化层——可以加快网络训练速度
- m=torch.nn.BatchNorm2d(100,affine=False)#正则化对象
- input=torch.randn(20,100,35,45)#BCHW类型数据
- output=m(input)#将input正则化
七、线性层
- torch.nn.Flatten(img)#将张量展平为一维的
- linear1=torch.nn.Linear(in_features,out_features)#线性层改变特征数量
八、Sequential函数
1.简单的网络结构
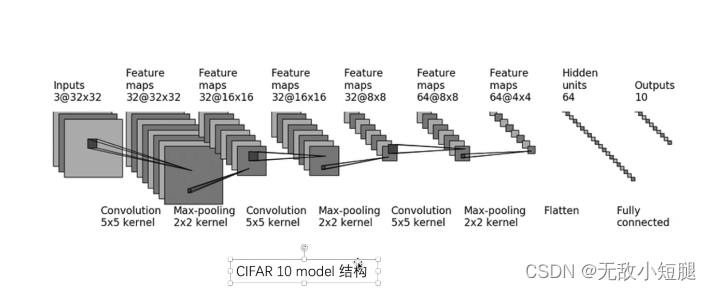
- import torch
- from torch import nn
- from torch.nn import Conv2d, MaxPool2d, Flatten, Linear, Sequential
- from torch.utils.tensorboard import SummaryWriter
-
- class Tudui(nn.Module):
- def __init__(self):
- super(Tudui, self).__init__()
- self.model1 = Sequential(
- Conv2d(3, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),
- Linear(1024, 64),
- Linear(64, 10)
- )
-
- def forward(self, x):
- x = self.model1(x)
- return x
-
- tudui = Tudui()#生成一个模型对象
- input = torch.ones((64, 3, 32, 32))#输入数据,必须是(B,C,H,W)类型
- output = tudui(input)
- print(output.shape)
-
- #可视化构造图
- writer = SummaryWriter("../logs_seq")
- writer.add_graph(tudui, input)
- writer.close()
-
模型可视化结果:

前向传播与反向传播
一、前向传播求得y_hat以及loss
-
- #损失器对象
- loss = L1Loss(reduction='sum')
- loss_mse = nn.MSELoss()
- loss_cross = nn.CrossEntropyLoss()#交叉熵
-
- #计算损失
- l=loss(y,y_hat)
二、反向传播
loss.backward()#求解计算图内所有的梯度三、优化器——梯度置0,梯度更新
四、训练
- import torch
- import torchvision
- from torch import nn
- from torch.nn import Sequential, Conv2d, MaxPool2d, Flatten, Linear
- from torch.optim.lr_scheduler import StepLR
- from torch.utils.data import DataLoader
-
- dataset = torchvision.datasets.CIFAR10("../data", train=False, transform=torchvision.transforms.ToTensor(),
- download=True)
-
- dataloader = DataLoader(dataset, batch_size=1)
-
- class Tudui(nn.Module):
- def __init__(self):
- super(Tudui, self).__init__()
- self.model1 = Sequential(
- Conv2d(3, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),
- Linear(1024, 64),
- Linear(64, 10)
- )
-
- def forward(self, x):
- x = self.model1(x)
- return x
-
-
- loss = nn.CrossEntropyLoss()
- tudui = Tudui()
- optim = torch.optim.SGD(tudui.parameters(), lr=0.01)
- for epoch in range(20):
- running_loss = 0.0
- for data in dataloader:
- imgs, targets = data
- outputs = tudui(imgs)
- result_loss = loss(outputs, targets)
- optim.zero_grad()
- result_loss.backward()
- optim.step()
- running_loss = running_loss + result_loss
- print(running_loss)
现有模型的使用、修改、保存、加载
一、添加与修改
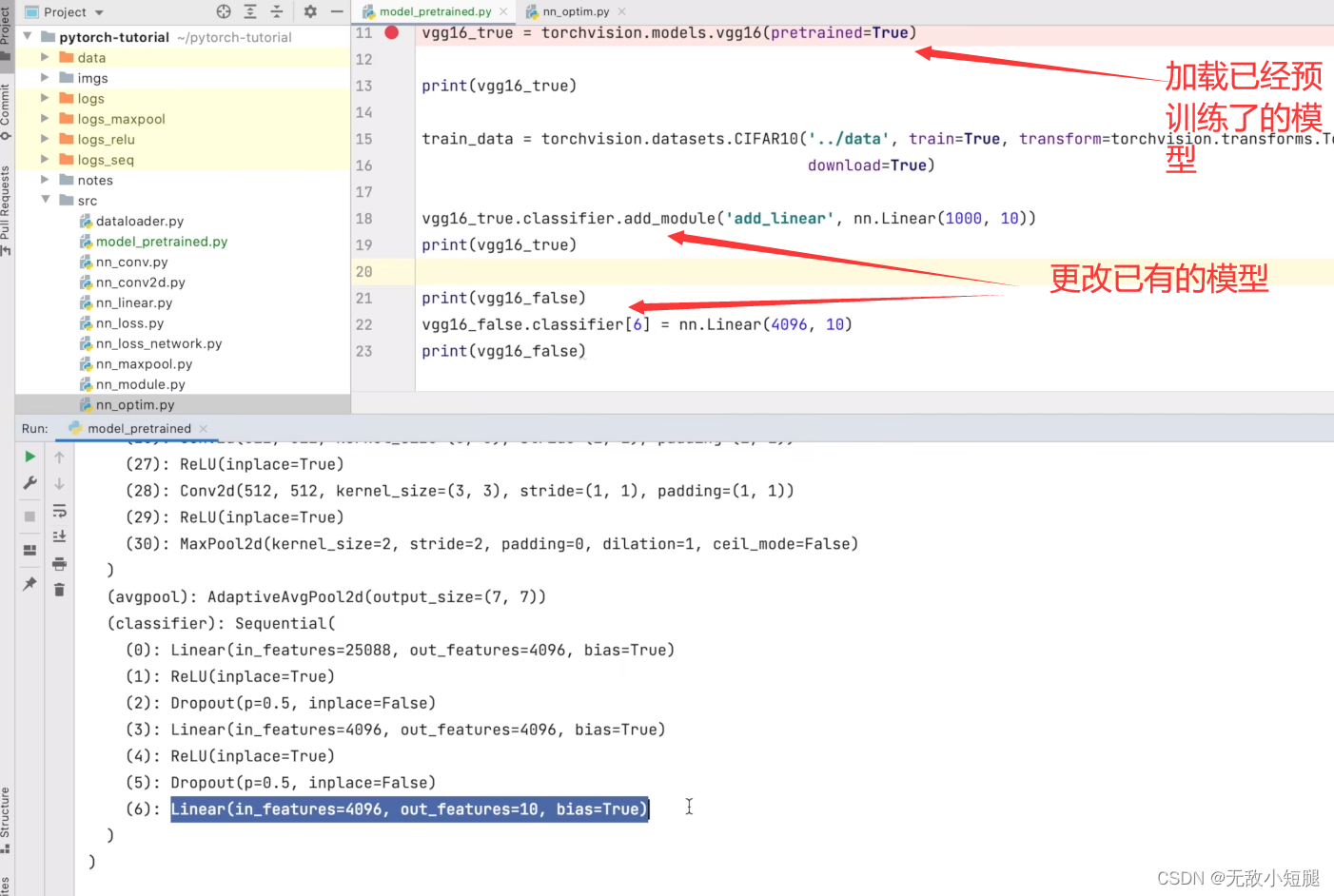
二、保存
- vgg16 = torchvision.models.vgg16(pretrained=False)
- # 保存方式1,模型结构+模型参数
- torch.save(vgg16, "vgg16_method1.pth")
-
- # 保存方式2,模型参数(官方推荐)
- torch.save(vgg16.state_dict(), "vgg16_method2.pth")
三、加载
- #方式1加载模型
- model = torch.load('tudui_method1.pth')
- print(model)
-
- #方式2
- vgg16 = torchvision.models.vgg16(pretrained=False)
- vgg16.load_state_dict(torch.load("vgg16_method2.pth"))
- print(vgg16)
完整的模型训练、测试
- # -*- coding: utf-8 -*-
-
- import torchvision
- from torch.utils.tensorboard import SummaryWriter
-
- from model import *
- # 准备数据集
- from torch import nn
- from torch.utils.data import DataLoader
-
- train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
- download=True)
- test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
- download=True)
-
- # length 长度
- train_data_size = len(train_data)
- test_data_size = len(test_data)
- # 如果train_data_size=10, 训练数据集的长度为:10
- print("训练数据集的长度为:{}".format(train_data_size))
- print("测试数据集的长度为:{}".format(test_data_size))
-
-
- # 利用 DataLoader 来加载数据集
- train_dataloader = DataLoader(train_data, batch_size=64)
- test_dataloader = DataLoader(test_data, batch_size=64)
-
- # 创建网络模型
- tudui = Tudui()
-
- # 损失函数
- loss_fn = nn.CrossEntropyLoss()
-
- # 优化器
- # learning_rate = 0.01
- # 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
- learning_rate = 1e-2
- optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
-
- # 设置训练网络的一些参数
- # 记录训练的次数
- total_train_step = 0
- # 记录测试的次数
- total_test_step = 0
- # 训练的轮数
- epoch = 10
-
- # 添加tensorboard
- writer = SummaryWriter("../logs_train")
-
- for i in range(epoch):
- print("-------第 {} 轮训练开始-------".format(i+1))
-
- # 训练步骤开始
- tudui.train()
- for data in train_dataloader:
- imgs, targets = data
- outputs = tudui(imgs)
- loss = loss_fn(outputs, targets)
-
- # 优化器优化模型
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- total_train_step = total_train_step + 1
- if total_train_step % 100 == 0:
- print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
- writer.add_scalar("train_loss", loss.item(), total_train_step)
-
- # 测试步骤开始
- tudui.eval()
- total_test_loss = 0
- total_accuracy = 0
- with torch.no_grad():
- for data in test_dataloader:
- imgs, targets = data
- outputs = tudui(imgs)
- loss = loss_fn(outputs, targets)
- total_test_loss = total_test_loss + loss.item()
- accuracy = (outputs.argmax(1) == targets).sum()
- total_accuracy = total_accuracy + accuracy
-
- print("整体测试集上的Loss: {}".format(total_test_loss))
- print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
- writer.add_scalar("test_loss", total_test_loss, total_test_step)
- writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
- total_test_step = total_test_step + 1
-
- torch.save(tudui, "tudui_{}.pth".format(i))
- print("模型已保存")
-
- writer.close()
使用GPU训练
1.
2.方式1
-
- import torch
- import torchvision
- from torch.utils.tensorboard import SummaryWriter
-
- # from model import *
- # 准备数据集
- from torch import nn
- from torch.utils.data import DataLoader
-
- train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
- download=True)
- test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
- download=True)
-
- # length 长度
- train_data_size = len(train_data)
- test_data_size = len(test_data)
- # 如果train_data_size=10, 训练数据集的长度为:10
- print("训练数据集的长度为:{}".format(train_data_size))
- print("测试数据集的长度为:{}".format(test_data_size))
-
-
- # 利用 DataLoader 来加载数据集
- train_dataloader = DataLoader(train_data, batch_size=64)
- test_dataloader = DataLoader(test_data, batch_size=64)
-
- # 创建网络模型
- class Tudui(nn.Module):
- def __init__(self):
- super(Tudui, self).__init__()
- self.model = nn.Sequential(
- nn.Conv2d(3, 32, 5, 1, 2),
- nn.MaxPool2d(2),
- nn.Conv2d(32, 32, 5, 1, 2),
- nn.MaxPool2d(2),
- nn.Conv2d(32, 64, 5, 1, 2),
- nn.MaxPool2d(2),
- nn.Flatten(),
- nn.Linear(64*4*4, 64),
- nn.Linear(64, 10)
- )
-
- def forward(self, x):
- x = self.model(x)
- return x
- tudui = Tudui()
- if torch.cuda.is_available(): #####模型cuda
- tudui = tudui.cuda()
-
- # 损失函数
- loss_fn = nn.CrossEntropyLoss()
- if torch.cuda.is_available(): #####损失函数cuda
- loss_fn = loss_fn.cuda()
- # 优化器
- # learning_rate = 0.01
- # 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
- learning_rate = 1e-2
- optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
-
- # 设置训练网络的一些参数
- # 记录训练的次数
- total_train_step = 0
- # 记录测试的次数
- total_test_step = 0
- # 训练的轮数
- epoch = 10
-
- # 添加tensorboard
- writer = SummaryWriter("../logs_train")
-
- for i in range(epoch):
- print("-------第 {} 轮训练开始-------".format(i+1))
-
- # 训练步骤开始
- tudui.train()
- for data in train_dataloader:
- imgs, targets = data
- if torch.cuda.is_available(): #####数据集cuda
- imgs = imgs.cuda()
- targets = targets.cuda()
- outputs = tudui(imgs)
- loss = loss_fn(outputs, targets)
-
- # 优化器优化模型
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- total_train_step = total_train_step + 1
- if total_train_step % 100 == 0:
- print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
- writer.add_scalar("train_loss", loss.item(), total_train_step)
-
- # 测试步骤开始
- tudui.eval()
- total_test_loss = 0
- total_accuracy = 0
- with torch.no_grad():
- for data in test_dataloader:
- imgs, targets = data
- if torch.cuda.is_available(): #####数据集cuda
- imgs = imgs.cuda()
- targets = targets.cuda()
- outputs = tudui(imgs)
- loss = loss_fn(outputs, targets)
- total_test_loss = total_test_loss + loss.item()
- accuracy = (outputs.argmax(1) == targets).sum()
- total_accuracy = total_accuracy + accuracy
-
- print("整体测试集上的Loss: {}".format(total_test_loss))
- print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
- writer.add_scalar("test_loss", total_test_loss, total_test_step)
- writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
- total_test_step = total_test_step + 1
-
- torch.save(tudui, "tudui_{}.pth".format(i))
- print("模型已保存")
-
- writer.close()
3.方式2
- import torch
- import torchvision
- from torch.utils.tensorboard import SummaryWriter
-
- # from model import *
- # 准备数据集
- from torch import nn
- from torch.utils.data import DataLoader
-
- # 定义训练的设备
- device = torch.device("cuda")
-
- train_data = torchvision.datasets.CIFAR10(root="../data", train=True, transform=torchvision.transforms.ToTensor(),
- download=True)
- test_data = torchvision.datasets.CIFAR10(root="../data", train=False, transform=torchvision.transforms.ToTensor(),
- download=True)
-
- # length 长度
- train_data_size = len(train_data)
- test_data_size = len(test_data)
- # 如果train_data_size=10, 训练数据集的长度为:10
- print("训练数据集的长度为:{}".format(train_data_size))
- print("测试数据集的长度为:{}".format(test_data_size))
-
-
- # 利用 DataLoader 来加载数据集
- train_dataloader = DataLoader(train_data, batch_size=64)
- test_dataloader = DataLoader(test_data, batch_size=64)
-
- # 创建网络模型
- class Tudui(nn.Module):
- def __init__(self):
- super(Tudui, self).__init__()
- self.model = nn.Sequential(
- nn.Conv2d(3, 32, 5, 1, 2),
- nn.MaxPool2d(2),
- nn.Conv2d(32, 32, 5, 1, 2),
- nn.MaxPool2d(2),
- nn.Conv2d(32, 64, 5, 1, 2),
- nn.MaxPool2d(2),
- nn.Flatten(),
- nn.Linear(64*4*4, 64),
- nn.Linear(64, 10)
- )
-
- def forward(self, x):
- x = self.model(x)
- return x
- tudui = Tudui()
- tudui = tudui.to(device)
-
- # 损失函数
- loss_fn = nn.CrossEntropyLoss()
- loss_fn = loss_fn.to(device)
- # 优化器
- # learning_rate = 0.01
- # 1e-2=1 x (10)^(-2) = 1 /100 = 0.01
- learning_rate = 1e-2
- optimizer = torch.optim.SGD(tudui.parameters(), lr=learning_rate)
-
- # 设置训练网络的一些参数
- # 记录训练的次数
- total_train_step = 0
- # 记录测试的次数
- total_test_step = 0
- # 训练的轮数
- epoch = 10
-
- # 添加tensorboard
- writer = SummaryWriter("../logs_train")
-
- for i in range(epoch):
- print("-------第 {} 轮训练开始-------".format(i+1))
-
- # 训练步骤开始
- tudui.train()
- for data in train_dataloader:
- imgs, targets = data
- imgs = imgs.to(device)
- targets = targets.to(device)
- outputs = tudui(imgs)
- loss = loss_fn(outputs, targets)
-
- # 优化器优化模型
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- total_train_step = total_train_step + 1
- if total_train_step % 100 == 0:
- print("训练次数:{}, Loss: {}".format(total_train_step, loss.item()))
- writer.add_scalar("train_loss", loss.item(), total_train_step)
-
- # 测试步骤开始
- tudui.eval()
- total_test_loss = 0
- total_accuracy = 0
- with torch.no_grad():
- for data in test_dataloader:
- imgs, targets = data
- imgs = imgs.to(device)
- targets = targets.to(device)
- outputs = tudui(imgs)
- loss = loss_fn(outputs, targets)
- total_test_loss = total_test_loss + loss.item()
- accuracy = (outputs.argmax(1) == targets).sum()
- total_accuracy = total_accuracy + accuracy
-
- print("整体测试集上的Loss: {}".format(total_test_loss))
- print("整体测试集上的正确率: {}".format(total_accuracy/test_data_size))
- writer.add_scalar("test_loss", total_test_loss, total_test_step)
- writer.add_scalar("test_accuracy", total_accuracy/test_data_size, total_test_step)
- total_test_step = total_test_step + 1
-
- torch.save(tudui, "tudui_{}.pth".format(i))
- print("模型已保存")
-
- writer.close()

4.gpu训练保存的模型在cpu上跑![]()
- 这篇博客手把手教你搭建Pytoch-Gpu环境!可谓是良心制作!一步一步,自己感觉很详细,质量也很高,算是对配置Pytorch深度学习环境的一个总结!大部分人想学编程都被配置环境劝退,这个过程难免会遇到各种各样的坑,但也正是这些坑让我们不断... [详细]
赞
踩
- ResNet代码复现(PyTorch),每一行都有超详细注释,新手小白都能看懂,亲测可运行_resnet实验复现resnet实验复现关于ResNet的原理和具体细节,可参见上篇解读:经典神经网络论文超详细解读(五)——ResNet(残差网络... [详细]
赞
踩
- 大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型13-pytorch搭建RBM(受限玻尔兹曼机)模型,调通模型的训练与测试。RBM(受限玻尔兹曼机)可以在没有人工标注的情况下对数据进行学习。其原理类似于我们人类学习... [详细]
赞
踩
- 本文在原论文的基础上进行了代码补充,并提供了整个流程的代码运行方法以完成图像超分辨率工作。_超分辨率图像重建超分辨率图像重建本文代码 ... [详细]
赞
踩
- 本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。_... [详细]
赞
踩
- article
成功解决RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c
成功解决RuntimeError:[enforcefailatC:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.c... [详细]赞
踩
- roberta文本分类 ... [详细]
赞
踩
- 本文使用PyTorch构建一个简单而有效的泰坦尼克号生存预测模型。通过这个项目,你会学到如何使用PyTorch框架创建神经网络、进行数据预处理和训练模型。我们将探讨如何处理泰坦尼克号数据集,设计并训练一个神经网络,以预测乘客是否在灾难中幸存... [详细]
赞
踩
- 人/B们/E常/S说/S生/B活/E是/S一/S部/S教/B科/M书/E”图中是双向的三层RNNs,堆叠多层的RNN网络,可以增加模型的参数,提高模型的拟合。理网格化数据(例如图像数据)的神经网络,RNN是专门用来处理序列数据的神经网络。双... [详细]
赞
踩
- 本文深入探索了PyTorch框架中的torch.nn模块,这是构建和实现高效深度学习模型的核心组件。我们详细介绍了torch.nn的关键类别和功能,包括ParameterModuleSequentialModuleListModuleDic... [详细]
赞
踩
- 本篇博客深入探讨了PyTorch的torch.nn子模块中与Transformer相关的核心组件。我们详细介绍了及其构成部分——编码器()和解码器(),以及它们的基础层——和。每个部分的功能、作用、参数配置和实际应用示例都被全面解析。这些组... [详细]
赞
踩
- PyTorch是由Facebook的AI研究团队开发的一个开源机器学习库,最初发布于2016年。它的前身是Torch,这是一个使用Lua语言编写的科学计算框架。PyTorch的出现标志着Torch的核心功能被转移到了Python这一更加流行... [详细]
赞
踩
- 本文详细介绍了PyTorch框架中的多个填充类,用于在深度学习模型中处理不同维度的数据。这些填充方法对于保持卷积神经网络中数据的空间维度至关重要,尤其在图像处理、音频信号处理等领域中有广泛应用。每种填充方法都有其特定的应用场景和注意事项,如... [详细]
赞
踩
- article
PyTorch 简单易懂的实现 CosineSimilarity 和 PairwiseDistance - 距离度量的操作_nn.cosinesimilarity(dim=1)返回的一定是标量吗
和。模块专注于计算两个高维数据集之间的余弦相似度,适用于评估文档、用户偏好等在特征空间中的相似性。而模块提供了一种计算两组数据点之间成对欧几里得距离的有效方式,这在聚类、近邻搜索或预测与实际值之间距离度量的场景中非常有用。这两个模块共同构成... [详细]赞
踩
- torch.cosine_similarity可以对两个向量或者张量计算相似度>>>input1=torch.randn(100,128)>>>input2=torch.randn(100,128)>>>output=torch.cosin... [详细]
赞
踩
- 本文提供几个pytorch中常用的向量相似度评估方法,并给出其源码实现,供大家参考。分别为以下六个。(其中第一个pytoch自带有库函数)_l2正则化和余弦相似度计算pytorxhl2正则化和余弦相似度计算pytorxh原文链接:https... [详细]
赞
踩
- 余弦相似度\color{red}{余弦相似度}余弦相似度在NLP的任务里,会对生成两个词向量进行相似度的计算,常常采用余弦相似度公式计算。余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接... [详细]
赞
踩
- 两个张量之间的欧氏距离即m*e和n*e张量之间的欧式距离理论分析算法实现importtorchdefeuclidean_dist(x,y):"""Args:x:pytorchVariable,withshape[m,d]y:pytorchV... [详细]
赞
踩
- importtorch.nn.functionalasFF.cosin_similarity(a,b,dim=1)沿着dim维度对a,b两个tensor计算余弦相似度。由于dim属性的存在,使得a,b两个tensor可以为任意维。_pyto... [详细]
赞
踩
- importtorchfromtorchimportTensordefcos_similar(p:Tensor,q:Tensor):sim_matrix=p.matmul(q.transpose(-2,-1))a=torch.norm(p,... [详细]
赞
踩

