
- 1mysql8.0.17 win7免安装版_win10 mysql8 error
- 2git基本使用_vscode undo commit
- 3[pytorch] 定义自己的dataloader
- 4python pythonw_pythonw.exe还是python.exe?
- 5vagrant + docker + pycharm 建立一套完整的Python开发环境_pycharm2019 docker
- 62021年Android面试题知识点_2021年andorid面试题
- 7芯片封装技术基础_封装实现的5个功能
- 8IDEA 一直不停的scanning files to index解决办法
- 9vue、react中虚拟的dom_vue react 虚拟dom
- 10Flink基础系列21-Sink之Kafka_flink sink kafka
P27-32:完整的训练模型(Pytorch小土堆学习笔记)_maxpool2d(2)
赞
踩
先亮代码,分成了两个文件一个是model1,用于存放模型,另一个文件是train,用于数据训练以及展示等功能,这样更符合实际应用场景。
model1:
- import torch
- from torch import nn
- from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
- class qiqi(nn.Module):
- def __init__(self):
- super(qiqi, self).__init__()
- self.model1 = Sequential(
- Conv2d(3, 32, 5, padding=2), #注意有逗号
- MaxPool2d(2),
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),
- Linear(1024, 64),
- Linear(64, 10)
- )
- def forward(self,x):
- x=self.model1(x)
- return x
-
- #测试一下模型
- if __name__ == '__main__':
- qq=qiqi()
- input = torch.ones((64,3,32,32))
- output = qq(input)
- print(output.shape)

train:
- import torch
- import torchvision
- from torch import nn
- from torch import optim
- from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
- from model1 import * #直接调用
-
- #准备数据集
- train_data = torchvision.datasets.CIFAR10(root="./dataset2", train=True, transform=torchvision.transforms.ToTensor(),
- download=True)
- test_data = torchvision.datasets.CIFAR10(root = "./dataset2",train=False, transform=torchvision.transforms.ToTensor(),
- download=True)
- #length长度
- train_data_size = len(train_data)
- test_data_size = len(test_data)
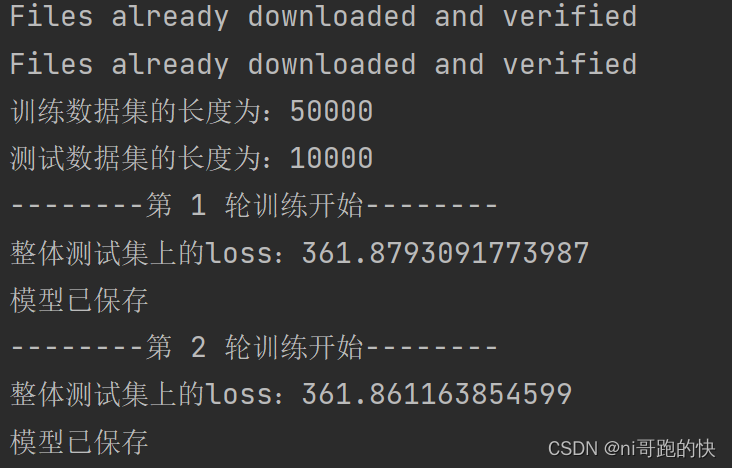
- print("训练数据集的长度为:{}".format(train_data_size))
- print("测试数据集的长度为:{}".format(test_data_size))
-
- #利用DataLoader来加载数据集
- train_dataloader = DataLoader(train_data,batch_size=64)
- test_dataloader = DataLoader(test_data,batch_size=64)
-
-
- #创建网络模型
- qq=qiqi()
-
- #损失函数
- loss_fn = nn.CrossEntropyLoss()
-
- #优化器
- learning_rate = 1e-2
- optimizer = torch.optim.SGD(qq.parameters(),lr=learning_rate)
-
- #设置训练网络的一些参数
- #记录训练的次数
- total_train_step = 0
- #记录测试的次数
- total_test_step = 0
- #训练的轮数
- epoch = 10
-
- writer = SummaryWriter("total_process")
- for i in range(epoch):
- print("--------第 {} 轮训练开始--------".format(i+1))
- #训练步骤开始
- qq.train() #这行代码在这里作用不大,因为模型中是一些常见的函数
- for data in train_dataloader:
- imgs,targets=data
- outputs = qq(imgs)
- loss = loss_fn(outputs,targets)
-
- #优化器优化模型
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- total_train_step = total_train_step+1
- if total_train_step % 100 == 0:
- print("本轮用时:{}".format(end_time-start_time) )
- print("训练次数:{}, loss: {}".format(total_train_step,loss.item)) #这里item也可以 不用
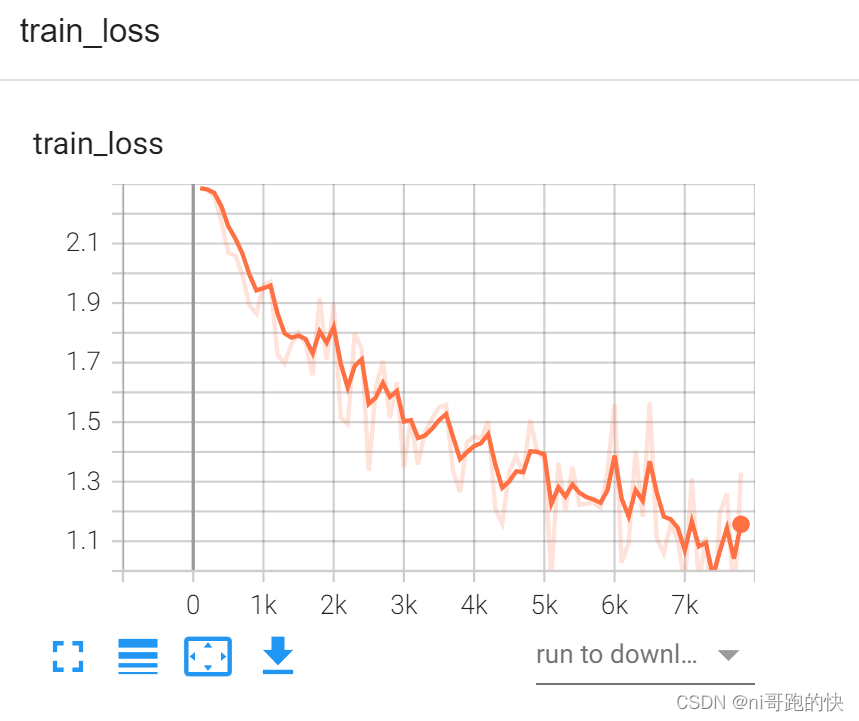
- writer.add_scalar("train_loss",loss.item(),total_train_step)
-
-
- #测试步骤开始
- qq.eval() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
- total_test_loss = 0
- total_accurancy = 0
- with torch.no_grad():
- for data in test_dataloader:
- imgs, targets = data
- outputs = qq(imgs)
- loss = loss_fn(outputs, targets)
- total_test_loss = total_test_loss + loss.item()
- accurancy = (outputs.argmax(1) == targets).sum()
- total_accurancy = total_accurancy + accurancy
-
- print("整体测试集上的loss:{}".format(total_test_loss))
- print("整体测试集上的正确率:{}".format(total_accurancy/test_data_size))
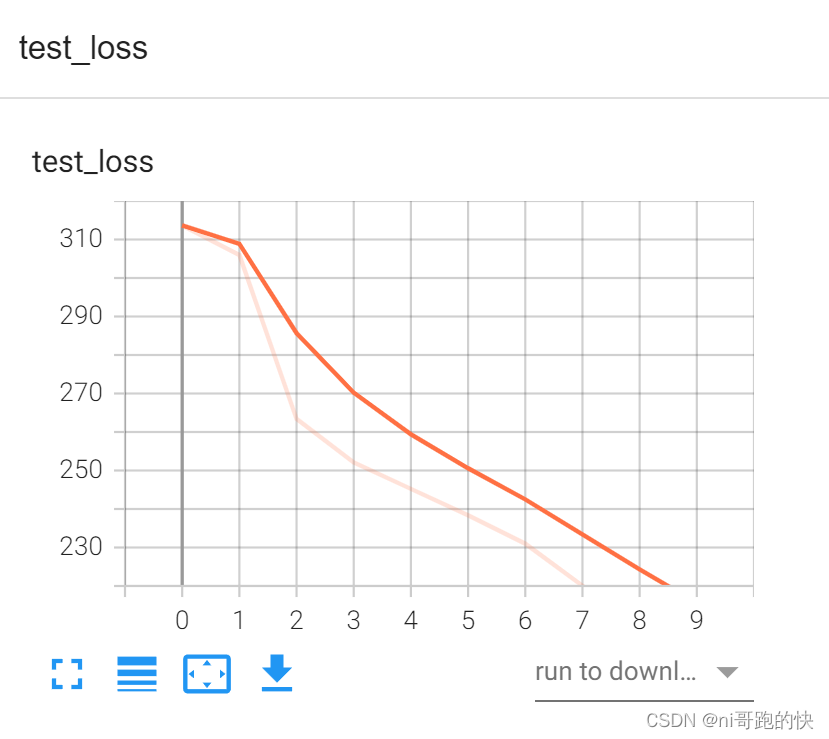
- writer.add_scalar("test_loss",total_test_loss,total_test_step)
- writer.add_scalar("test_accuracy",total_accurancy/test_data_size,total_test_step)
- total_test_step = total_test_step + 1
-
- torch.save(qq,"qq_{}.pth".format(i))
- print("模型已保存")
-
- writer.close()
补充一下正确率那一块代码的理解:
拿一个简单的二分类举例:
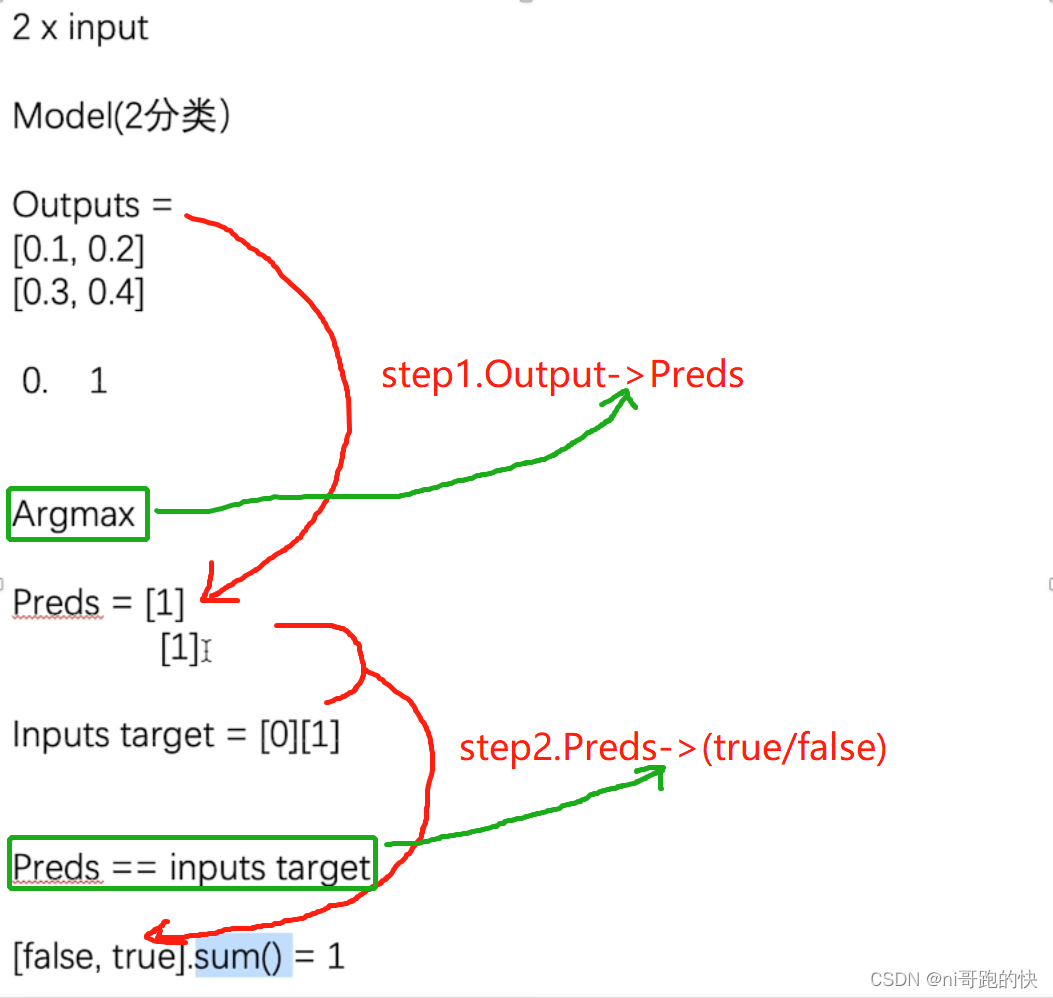
输出只能输出概率,第一步要在Argmax的帮助下找到最大值并归为其中一类(argmax(1)表示横着判断,argmax(0)表示竖着判断),如图所示,第一行判定分类为1,第二行判断分类为1,所以第一步处理后的结果为:[1][1];第二步,与targets进行比较分类一致为true,分类不一致为false,为true的是分类正确的,最终求和得到分类正确的数目
上面在训练和测试的过程中用train和eval是因为bn层和dropout层在训练和测试是不一样的

运行结果 :
tensorboard展示的结果:
接下来对代码进行一些升级(为了方便,将代码放在一个文件中)
使用GPU进行训练:(两种方法)
两种方法的核心理念是一致的,都是将网络模型、数据、损失函数调用cuda()

第一个方法:
- #
- if torch.cuda.is_available():
- qq=qq.cuda()
- #
- if torch.cuda.is_available():
- loss_fn = loss_fn.cuda()
- #训练集和测试集中都要加入
- if torch.cuda.is_available():
- imgs = imgs.cuda()
- targets = targets.cuda()
第二个方法:

- #在一开始输入
- device = torch.device("cuda:0")
- #之后在数据(测试+训练)、模型、损失函数中分别输入
- qq = qq.to(device)
-
- loss_fn = loss_fn.to(device)
-
- imgs = imgs.to(device)
- targets = targets.to(device)
方法二的完整代码:
- import torch
- import torchvision
- from torch import nn
- from torch import optim
- from torch.nn import Conv2d,MaxPool2d,Flatten,Linear,Sequential
- from torch.utils.data import DataLoader
- from torch.utils.tensorboard import SummaryWriter
- import time
-
- #定义训练的设备
- device = torch.device("cuda")
- #准备数据集
- train_data = torchvision.datasets.CIFAR10(root="./dataset2", train=True, transform=torchvision.transforms.ToTensor(),
- download=True)
- test_data = torchvision.datasets.CIFAR10(root = "./dataset2",train=False, transform=torchvision.transforms.ToTensor(),
- download=True)
- #length长度
- train_data_size = len(train_data)
- test_data_size = len(test_data)
- print("训练数据集的长度为:{}".format(train_data_size))
- print("测试数据集的长度为:{}".format(test_data_size))
-
- #利用DataLoader来加载数据集
- train_dataloader = DataLoader(train_data,batch_size=64)
- test_dataloader = DataLoader(test_data,batch_size=64)
-
- #准备训练模型
- class qiqi(nn.Module):
- def __init__(self):
- super(qiqi, self).__init__()
- self.model1 = Sequential(
- Conv2d(3, 32, 5, padding=2), #注意有逗号
- MaxPool2d(2),
- Conv2d(32, 32, 5, padding=2),
- MaxPool2d(2),
- Conv2d(32, 64, 5, padding=2),
- MaxPool2d(2),
- Flatten(),
- Linear(1024, 64),
- Linear(64, 10)
- )
- def forward(self,x):
- x=self.model1(x)
- return x
- #创建网络模型
- qq=qiqi()
- qq = qq.to(device)
-
- #损失函数
- loss_fn = nn.CrossEntropyLoss()
- loss_fn = loss_fn.to(device)
-
- #优化器
- learning_rate = 1e-2
- optimizer = torch.optim.SGD(qq.parameters(),lr=learning_rate)
-
- #设置训练网络的一些参数
- #记录训练的次数
- total_train_step = 0
- #记录测试的次数
- total_test_step = 0
- #训练的轮数
- epoch = 10
- #记录时间
- start_time = time.time()
- writer = SummaryWriter("train_gpu2")
- for i in range(epoch):
- print("--------第 {} 轮训练开始--------".format(i+1))
- #训练步骤开始
- qq.train() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
- for data in train_dataloader:
- imgs,targets = data
- imgs = imgs.to(device)
- targets = targets.to(device)
- outputs = qq(imgs)
- loss = loss_fn(outputs,targets)
-
- #优化器优化模型
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- total_train_step = total_train_step+1
- if total_train_step % 100 == 0:
- end_time = time.time()
- print("本轮用时:{}".format(end_time-start_time) )
- print("训练次数:{}, loss: {}".format(total_train_step,loss.item())) #这里item也可以不用
- writer.add_scalar("train_loss",loss.item(),total_train_step)
-
- #测试步骤开始
- qq.eval() #对现在的网络层没影响,在含有bn层和dropout层的模型中有影响,因为这两个层在训练和测试是不一样的
- total_test_loss = 0
- total_accurancy = 0
- with torch.no_grad():
- for data in test_dataloader:
- imgs, targets = data
- imgs = imgs.to(device)
- targets = targets.to(device)
- outputs = qq(imgs)
- loss = loss_fn(outputs, targets)
- total_test_loss = total_test_loss + loss.item()
- accurancy = (outputs.argmax(1) == targets).sum()
- total_accurancy = total_accurancy + accurancy
-
- print("整体测试集上的loss:{}".format(total_test_loss))
- print("整体测试集上的正确率:{}".format(total_accurancy/test_data_size))
- writer.add_scalar("test_loss",total_test_loss,total_test_step)
- writer.add_scalar("test_accuracy",total_accurancy/test_data_size,total_test_step)
- total_test_step = total_test_step + 1
-
- torch.save(qq,"qq_{}.pth".format(i))
- print("模型已保存")
-
- writer.close()
- 这篇博客手把手教你搭建Pytoch-Gpu环境!可谓是良心制作!一步一步,自己感觉很详细,质量也很高,算是对配置Pytorch深度学习环境的一个总结!大部分人想学编程都被配置环境劝退,这个过程难免会遇到各种各样的坑,但也正是这些坑让我们不断... [详细]
赞
踩
- ResNet代码复现(PyTorch),每一行都有超详细注释,新手小白都能看懂,亲测可运行_resnet实验复现resnet实验复现关于ResNet的原理和具体细节,可参见上篇解读:经典神经网络论文超详细解读(五)——ResNet(残差网络... [详细]
赞
踩
- 大家好,我是微学AI,今天给大家介绍一下人工智能(pytorch)搭建模型13-pytorch搭建RBM(受限玻尔兹曼机)模型,调通模型的训练与测试。RBM(受限玻尔兹曼机)可以在没有人工标注的情况下对数据进行学习。其原理类似于我们人类学习... [详细]
赞
踩
- 本文在原论文的基础上进行了代码补充,并提供了整个流程的代码运行方法以完成图像超分辨率工作。_超分辨率图像重建超分辨率图像重建本文代码 ... [详细]
赞
踩
- 本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。_... [详细]
赞
踩
- article
成功解决RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c
成功解决RuntimeError:[enforcefailatC:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.c... [详细]赞
踩
- roberta文本分类 ... [详细]
赞
踩
- 本文使用PyTorch构建一个简单而有效的泰坦尼克号生存预测模型。通过这个项目,你会学到如何使用PyTorch框架创建神经网络、进行数据预处理和训练模型。我们将探讨如何处理泰坦尼克号数据集,设计并训练一个神经网络,以预测乘客是否在灾难中幸存... [详细]
赞
踩
- 人/B们/E常/S说/S生/B活/E是/S一/S部/S教/B科/M书/E”图中是双向的三层RNNs,堆叠多层的RNN网络,可以增加模型的参数,提高模型的拟合。理网格化数据(例如图像数据)的神经网络,RNN是专门用来处理序列数据的神经网络。双... [详细]
赞
踩
- 本文深入探索了PyTorch框架中的torch.nn模块,这是构建和实现高效深度学习模型的核心组件。我们详细介绍了torch.nn的关键类别和功能,包括ParameterModuleSequentialModuleListModuleDic... [详细]
赞
踩
- 本篇博客深入探讨了PyTorch的torch.nn子模块中与Transformer相关的核心组件。我们详细介绍了及其构成部分——编码器()和解码器(),以及它们的基础层——和。每个部分的功能、作用、参数配置和实际应用示例都被全面解析。这些组... [详细]
赞
踩
- PyTorch是由Facebook的AI研究团队开发的一个开源机器学习库,最初发布于2016年。它的前身是Torch,这是一个使用Lua语言编写的科学计算框架。PyTorch的出现标志着Torch的核心功能被转移到了Python这一更加流行... [详细]
赞
踩
- 本文详细介绍了PyTorch框架中的多个填充类,用于在深度学习模型中处理不同维度的数据。这些填充方法对于保持卷积神经网络中数据的空间维度至关重要,尤其在图像处理、音频信号处理等领域中有广泛应用。每种填充方法都有其特定的应用场景和注意事项,如... [详细]
赞
踩
- article
PyTorch 简单易懂的实现 CosineSimilarity 和 PairwiseDistance - 距离度量的操作_nn.cosinesimilarity(dim=1)返回的一定是标量吗
和。模块专注于计算两个高维数据集之间的余弦相似度,适用于评估文档、用户偏好等在特征空间中的相似性。而模块提供了一种计算两组数据点之间成对欧几里得距离的有效方式,这在聚类、近邻搜索或预测与实际值之间距离度量的场景中非常有用。这两个模块共同构成... [详细]赞
踩
- torch.cosine_similarity可以对两个向量或者张量计算相似度>>>input1=torch.randn(100,128)>>>input2=torch.randn(100,128)>>>output=torch.cosin... [详细]
赞
踩
- 本文提供几个pytorch中常用的向量相似度评估方法,并给出其源码实现,供大家参考。分别为以下六个。(其中第一个pytoch自带有库函数)_l2正则化和余弦相似度计算pytorxhl2正则化和余弦相似度计算pytorxh原文链接:https... [详细]
赞
踩
- 余弦相似度\color{red}{余弦相似度}余弦相似度在NLP的任务里,会对生成两个词向量进行相似度的计算,常常采用余弦相似度公式计算。余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接... [详细]
赞
踩
- 两个张量之间的欧氏距离即m*e和n*e张量之间的欧式距离理论分析算法实现importtorchdefeuclidean_dist(x,y):"""Args:x:pytorchVariable,withshape[m,d]y:pytorchV... [详细]
赞
踩
- importtorch.nn.functionalasFF.cosin_similarity(a,b,dim=1)沿着dim维度对a,b两个tensor计算余弦相似度。由于dim属性的存在,使得a,b两个tensor可以为任意维。_pyto... [详细]
赞
踩
- importtorchfromtorchimportTensordefcos_similar(p:Tensor,q:Tensor):sim_matrix=p.matmul(q.transpose(-2,-1))a=torch.norm(p,... [详细]
赞
踩

