
- 1ONLYOFFICE是一站式协作免费开源办公神器
- 2【vue】实现超过两行或多行显示展开收起 (单个展开收起和数组多个展开收起)_vue 展开收起
- 3uniapp使用Vant ui_uniapp vant
- 4人工神经网络进化简史_axon制导
- 5vue安装node-sass问题解决_path d:\vue_service\ysm\pushmall-foreground\node_m
- 6CentOS7光驱安装本地源_安装centos系统一直读取不到光驱
- 7Sublime Text 3使用SublimeLinter配置JS,CSS,HTML语法检查_sublimetext配置js
- 8大材小用之罗伯茨梯度锐化_edge(i,'roberts',0.1)什么意思
- 9Flask 入门5 :过滤器
- 10Python中的图像处理(第十一章)Python图像锐化及边缘检测(2)_numpy工具包定义prewitt算子,并用该算子对灰度图像“lena.jpg”进行图像锐化提取
PaddleDetection研究报告——百度目标检测PP-YOLOE论文解读+实践应用_pp-yoloe-r paddleocr
赞
踩
- 最新发布
- PP-YOLOE+,最高精度提升2.4% mAP,达到54.9% mAP,模型训练收敛速度提升3.75倍,端到端预测速度最高提升2.3倍;多个下游任务泛化性提升。
- PicoDet-NPU模型,支持模型全量化部署;新增PicoDet版面分析模型。超轻量目标检测算法。
- PP-TinyPose增强版,在健身、舞蹈等场景精度提升9.1% AP,支持侧身、卧躺、跳跃、高抬腿等非常规动作。超轻量关键点检测算法。
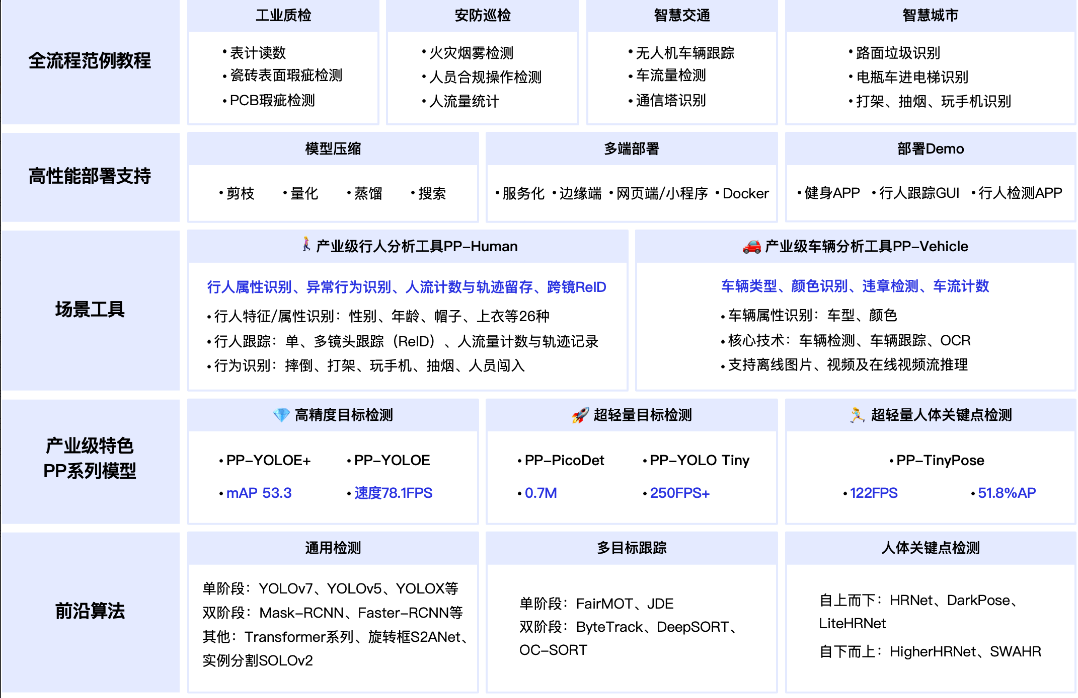
- 新增能力
- 发布行人分析工具PP-Humanv2,新增打架、打电话、抽烟、闯入四大行为识别,底层算法性能升级,覆盖行人检测、跟踪、属性三类核心算法能力,提供全流程开发及模型优化策略,支持在线视频流输入。
- 首次发布PP-Vehicle,提供车牌识别、车辆属性分析(颜色、车型)、车流量统计以及违章检测四大功能,兼容图片、在线视频流、视频输入,提供完善的二次开发文档教程。
- 应用场景
- 智能健身
智能化的对健身动作进行识别、矫正、计数
2. 打架识别
3. 来客分析
通过对来店客人的属性识别、行为预警、时长和轨迹记录等数据进行统计分析, 可以应用于 相关场所的客流通统计、用户画像、客户留存分析等功能, 进而提升 相关场所的经营和服务水平
4. 车辆结构化识别
车牌识别、车辆属性分析、违章检测、车流量计数
- 论文介绍
4.1 PP-YOLOE
论文地址:PP-YOLOE+

主要创新点:
- Anchor free无锚盒机制
- 可扩展的backbone和neck,由CSPRepResStage(CSPNet+RMNet)构成
- 使用Varifocal Loss(VFL)和Distribution focal loss(DFL)的头部机制ET-head
- 动态标签分配算法Task Alignment Learning(TAL)
| YOLOV5 | YOLOX | PPYOLOE | YOLOV6 | |
| 数据增广 | mosaic、mixup等 | mosaic、mixup等 | 只有最基本的 | 同yolov5 |
| backbone | cspdarknet | cspdarknet | CSPRepResNet | EfficientRep |
| neck | PAN | PAN | PAN | Rep-PAN |
| Head | 耦合 | 解耦 | ET-Head | 解耦+加速 |
| label assignment | max-iou-assign | simOTA | TAL | simOTA |
| Anchor-free | anchor-based | Anchor-free | Anchor-free | Anchor-free |
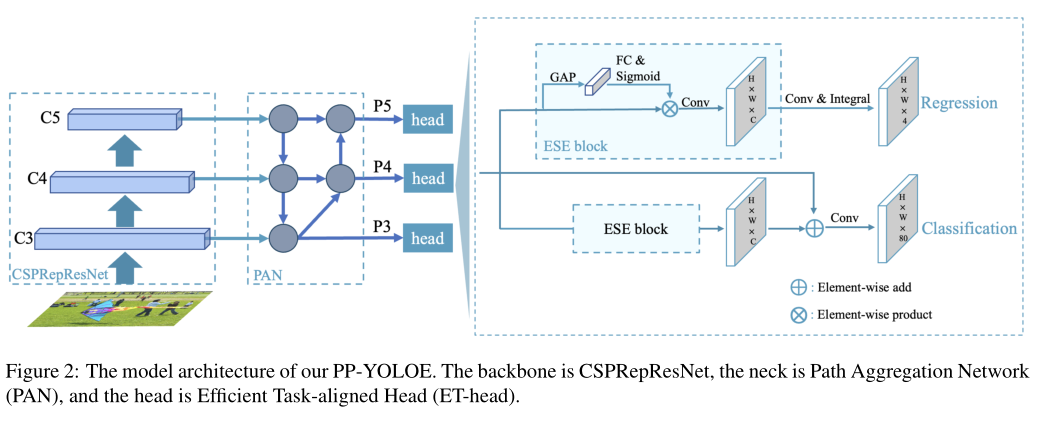
网络结构:
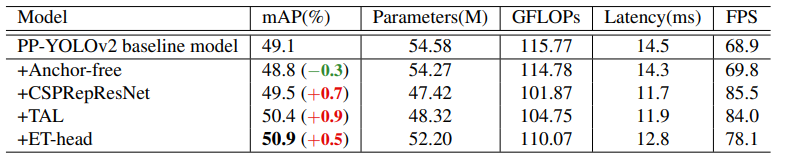
消融实验各改进部分效果
- Anchor free无锚盒机制
Anchor引入的缺点:
(1) 检测器的性能一般和anchor(框)的比例和尺寸有关。
(2) 一般anchor的尺寸和大小固定,很难处理形状变化大的目标,当进行迁移学习时,可能需要重新设计anchor。
(3) anchor的引入使得训练任务非常繁琐。
(4) 为了得到较高的召回率,通常需要在图片中生成非常密集的anchor,而大部分anchor为负样本,导致正负样本极度不均匀,负样本对检测器没有任何作用。
Anchor-free的引入:
针对预测点,直接预测这个点相对于目标的左侧、上侧、右侧、下侧的距离(l、t、r、b)

xmin = Cx-l*s ymin = Cy-t*s
xmax = Cx+r*s ymax = Cy+b*s
其中,l、t、r、b为回归任务预测得到的,且在特征图尺度上的,需乘s映射到原图。s为预测的特征特相对于原图的步距,(xmin,ymin),(xmax,ymin),(xmax,ymax),(xmin,ymax)分别为顶点坐标。
- 可扩展的backbone和neck,由CSPRepResStage(CSPNet+RMNet)构成

在backbone部分集成了残差结构和密集连接结构,且推理过程较训练过程少了1x1的残差连接,最后以ESE(注意力模块)连接。
PAN(Path Aggregation Network)结构其实就是在FPN(从顶到底信息融合)的基础上加上了从底到顶的信息融合。
- 使用Varifocal Loss(VFL)和Distribution focal loss(DFL)的头部机制ET-head
结构:

- 在精度无损的条件下,将通道注意力模块简化成了更加高效的 ESE block,ESE block相比于SE block少用一个全连接层,避免通道信息的丢失。
- 将分类任务对齐模块简化成了 shortcut,进一步提升了速度。
损失函数:
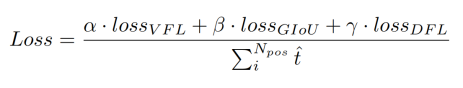
- 采用 VFL(varifocal loss)作为分类损失(交叉熵),它对于正负样本的权重分配不同,这种实现使得具有高IoU的阳性样本对损失的贡献相对较大。这也使得模型在训练时更关注高质量的样本,而不是那些低质量的样本。
- 在之前,目标检测任务中做回归一般是直接预测某个回归值,或者预测相较于anchor的比例,为了解决边界框表示不灵活的问题,DFL提出利用一般分布来预测bounding box,将回归看作是一个分布预测任务。
- GIOU损失来表示检测框的质量评估。
- 两者都使用IoU感知分类得分(IACS)作为预测目标。这可以有效地学习分类分数和定位质量估计的联合表示,这使得训练和推断之间具有高度一致性。
详细参考:
- 动态标签分配算法Task Alignment Learning(TAL)
TAL是由论文TOOD提出,目的是把两个任务的最优anchor拉近,通过设计一个样本分配策略和一个任务对齐的损失来执行。样本分配通过计算每个anchors的任务对齐程度来收集训练样本(即正样本或负样本),而任务对齐损失可以逐步将分类和定位最佳的anchor统一起来,以在训练期间预测分类和定位。因此,在推理时,可以保留具有最高分类分数并共同具有最精确定位的边界框。
anchor对齐度量
通过分类得分和预测框和gt的IoU的高阶组合来表示这个度量:

其中 s 和 u 分别表示分类 Score 和 IoU 值。 α 和 β 用于控制2个任务在anchor对齐度量中的影响。 值得注意的是,t 在2个任务的联合优化中起着关键作用,以实现任务对齐的目标。 它鼓励网络从联合优化的角度动态关注高质量(即任务对齐)Anchor。
训练样本分配
对于每个gt,选择m个具有最大t值的anchor作为正样本点,其余的为负样本。
任务对齐损失
为了显式的增加对齐的anchor的得分,减少不对齐的anchor的得分,用t来代替正样本anchor的标签。

同时,借鉴了focal loss的思想,最后的损失函数如下
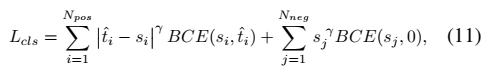
其中 j 表示 Nneg 个负anchors中的第 j 个anchors,γ 是focus参数。
定位损失函数和分类类似,使用归一化的t来对GIoU loss进行了加权:
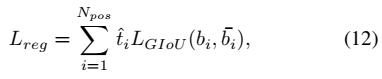
总的loss就是把这两个损失加起来。
- 实践应用
5.1 行为分析 声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/52045
- 为了避免学习后短时间内遗忘,让自己随时可以查阅前方自己学过的知识,特意注册csdn博客,方便自己学习时做笔记,也方便随时回顾。也希望自己的学习过程能给同样初学python爬虫的你带来一点指引!由于自己是新手,只有一点点的python基础,所... [详细]
赞
踩
- 【代码】Python之pdf内容读取。_python读取pdf内容python读取pdf内容importpandasaspdimportpdfplumberwithpdfplumber.open(r'C:\Users\2023\02\开发.... [详细]
赞
踩
- 注意在具体的应用中,需要根据文件名的编码和需要的展示方式,选择合适的字符编码进行处理,以确保文件名的正确性和兼容性。视图函数是处理用户请求的函数,它接收并处理用户发送的请求,并返回相应的响应结果。获取表单数据时,要确保请求的方法为POST,... [详细]
赞
踩
- 文章目录创建LVM的基本步骤LVM常用命令创建使用LVM逻辑卷1)创建PVa.我们已经添加了一个sdb磁盘b.接下来我们创建4个分区:c.查看分好的分区:d.设定分区号代码e.创建pvf.查看物理卷信息g.创建vg卷组h.创建LV格式化与挂... [详细]
赞
踩
- PaddleDetection是百度Paddle家族的一个目标检测开发套件。个人感觉Paddle的优点是模型比较丰富,支持的部署方式较多(python、C++、移动端等),缺点是坑比较多,百度的老毛病了,什么都弄一点,但都不精通。本文研究了... [详细]
赞
踩
- 初识Flask1.1搭建开发环境1.1.1Pipenv工作流1.1.2安装Flask1.1.3集成开发环境1.2Hello,Flask!1.2.1创建程序实例1.2.2注册路由1.3启动开发服务器1.3.1RunFlask1.3.2更多的启... [详细]
赞
踩
- 目录一、spring-configuration-metadata.json内置tomcat优化1、常用配置说明2、springboot中的配置文件二、keepalive链接设置一、spring-configuration-metadata... [详细]
赞
踩
- 在最近的OpenAI开发日之后,使用量再度激增,随后OpenAI宣布暂停新用户使用其付费服务。这背后体现了大模型提供规模化服务时运维的重要性。EvanMorikawa是Ope...ChatGPT规模化服务的经验与教训2022年11月30日,... [详细]
赞
踩
- 1.远程SSH登录上Centos服务器,并进行如下操作注意:挂载操作会清空数据,请确认挂载盘无数据或者未使用1.列出所有磁盘命令:ll/dev/disk/by-path(注意:ll是字母LL的小写,不是数字11)2.格式化硬盘/dev/sd... [详细]
赞
踩
- (2)如果PILImage属于(L,LA,P,I,F,RGB,YCbCr,RGBA,CMYK,1)中的一种图像类型,或者numpy.ndarray格式数据类型是np.uint8,则将[0,255]的数据转为[0.0,1.0],也就是说将所有... [详细]
赞
踩
- RabbitMQ基础_rabbitmq基础组件rabbitmq基础组件1、前言学习一门技术,首先要知道它能帮我们解决哪些问题,带着这个疑问去探索可以事半功倍。痛点1:业务复杂,需要同步调用多个系统的接口,总耗时较长,用户体验差。痛点2:比如... [详细]
赞
踩
- C++中的域运算符::有两种作用:引用全局变量和表示类成员和命名空间。它可用于引用同名全局变量和访问类成员。c++作用域运算符的作用域运算符的作用1.引用全局变量2.用于表示类成员,命名空间c++中有::符号,叫做域运算符,这个符号有多种作... [详细]
赞
踩
- 【杂谈】SpringBoot默认支持的并发量SpringBoot应用支持的最大并发量是多少?SpringBoot能支持的最大并发量主要看其对Tomcat的设置,可以在配置文件中对其进行更改。当在配置文件中敲出max后提示值就是它的默认值。我... [详细]
赞
踩
- 'p'格式字符编码一个“Pascal字符串”,意思是一个简短的可变长度字符串,存储在固定数量的字节中,由count给出。字符串的字节在后面。请注意,对于unpack(),'p'格式字符会消耗计数字节,但返回的字符串不能包含超过255个字符。... [详细]
赞
踩
- 本文章简要枚举了常见的日期和时间的校验正则表达式,并针对日期校验表达式的组装过程进行了步骤描述。_校验日期格式校验日期格式日期校验/时间校验正则表达式解析0结论以下为常用的日期格式校验表达式0.1日期格式校验以下日期校验可满足“四年一闰,百... [详细]
赞
踩
- ????这是一个或许对你有用的社群????一对一交流/面试小册/简历优化/求职解惑,欢迎加入「芋道快速开发平台」知识星球。下面是星球提供的部分资料:《项目实战(视频)》:从书中学,往事中“练”《互联网高频面试题》:面朝简历学习,春暖花开《架... [详细]
赞
踩
- 最近在rk3399pro开发板上编写python程序(opencv获取rtsp流–vpu硬件解码—多进程读取/处理),但是由于远程网络摄像头rtsp流会发生丢包、网络卡顿的现象,导致程序意外退出,现通过设置shell脚本自动启动意外中断的程... [详细]
赞
踩
- 网络安全人才的薪酬也会随着岗位的不同,有所差别。从用人单位的所属行业来看,对网络安全人才需求量最大的行业是IT信息技术,其发布的网络安全人才招聘数量占所有网络安全人才招聘总人数的42.4%,其次为互联网,占13.7%。总体而言,用人单位提供... [详细]
赞
踩
- SpringBoot提供了AbstractRoutingDataSource根据用户定义的规则选择使用的数据源,这样我们可以在每次数据库操作前设置使用的数据源,实现可动态路由的数据源,从而实现读写分离的功能。_springboot多数据源配... [详细]
赞
踩
- Linux系统重装时保留重要分区对于熟悉Windows操作系统的人,一般都知道在重安装系统时只格式化C分区,而不动其它分区,以便尽可能保留已有的数据,极大地减少数据恢复工作。对于Linux操作系统,完全可实现类似的操作。与使用Windows... [详细]
赞
踩
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

