
- 1queryWrapper手册及示例_querywrapper 包含
- 255 | 云计算、容器革命与服务端的未来
- 3Android保存图片到相册,兼容Android10及以上版本_android 保存图片到相册
- 4C#编程练习_c#编程训练
- 5Arduino超声波智能循迹避障小车简易教程_arduino小车超声波
- 6免费idea插件Boit (ChatGPT)_idea chatgpt插件
- 7【MySQL用法】Mysql数据库连接池 [ druid ] 的所有配置介绍_mysql数据库连接池配置文件
- 8C++类_声明、定义、实现_c++ 类 声明
- 9检测头篇 | 原创自研 | YOLOv8 更换 SEResNeXtBottleneck 头 | 附详细结构图
- 104399小游戏童年的乐趣,python爬取4399全站小游戏_4399&fenlei=256&oq=4%26lt%3b99&rsv_pq=c6368b950161
[NLP]LLM 训练时GPU显存耗用量估计_llama2 70b需要多大显存
赞
踩
一 只进行推理
全精度llama2 7B最低显存要求:28GB
全精度llama2 13B最低显存要求:52GB
全精度llama2 70B最低显存要求:280GB
16精度llama2 7B预测最低显存要求:14GB
16精度llama2 13B预测最低显存要求:26GB
16精度llama2 70B预测最低显存要求:140GB
8精度llama2 7B预测最低显存要求:7GB
8精度llama2 13B预测最低显存要求:13GB
8精度llama2 70B预测最低显存要求:70GB
4精度llama2 7B预测最低显存要求:3.5GB
4精度llama2 13B预测最低显存要求:6.5GB
4精度llama2 70B预测最低显存要求:35GB
目前模型的参数绝大多数都是float32类型, 占用4个字节。所以一个粗略的计算方法就是,每10亿个参数,占用4G显存(实际应该是10^9*4/1024/1024/1024=3.725G,为了方便可以记为4G)。
比如LLaMA的参数量为7000559616,7B(70亿), 那么全精度加载这个模型参数需要的显存为:
7000559616 * 4 /1024/1024/1024 = 26.08G | 4G * 7 = 28G

如果用用半精度的FP16/BF16来加载,这样每个参数只占2个字节,所需显存就降为一半,只需要13.04G。
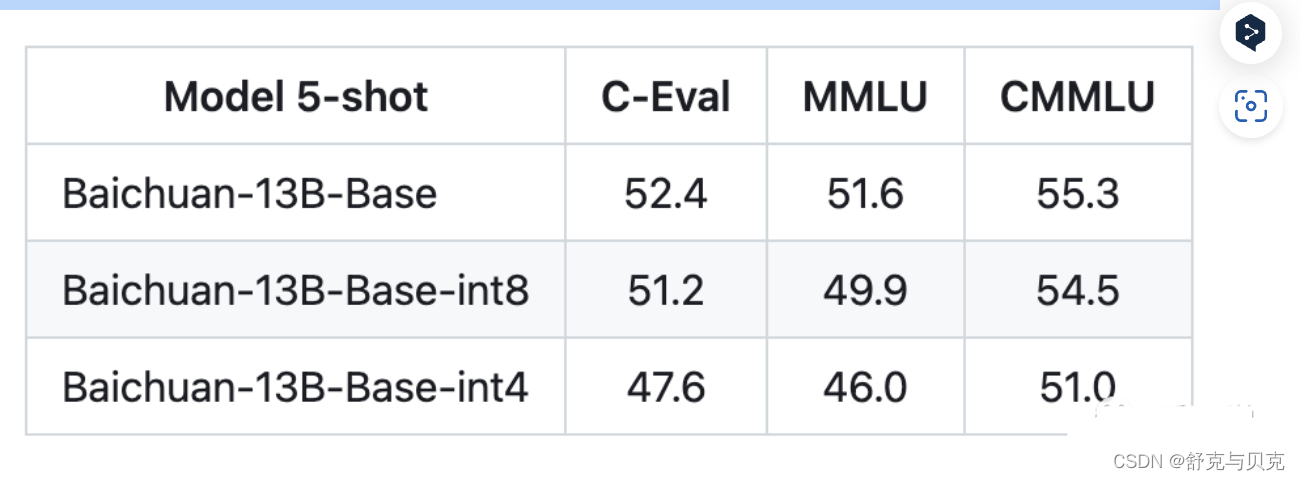
目前int4就是最低精度了,再往下效果就很难保证了。比如百川给的量化结果对比如下:
注意上面只是加载模型到显存,模型运算时的一些临时变量也需要申请空间,比如你beam search的时候。所以真正做推理的时候记得留一些Buffer,不然就容易OOM。
如果显存还不够,就只能采用Memery Offload的技术,把部分显存的内容给挪到内存,但是这样会显著降低推理速度。
| dtype | 每10亿参数需要占用内存 |
|---|---|
| float32 | 4G |
| fp16/bf16 | 2G |
| int8 | 1G |
| int4 | 0.5G |
二 进行模型训练
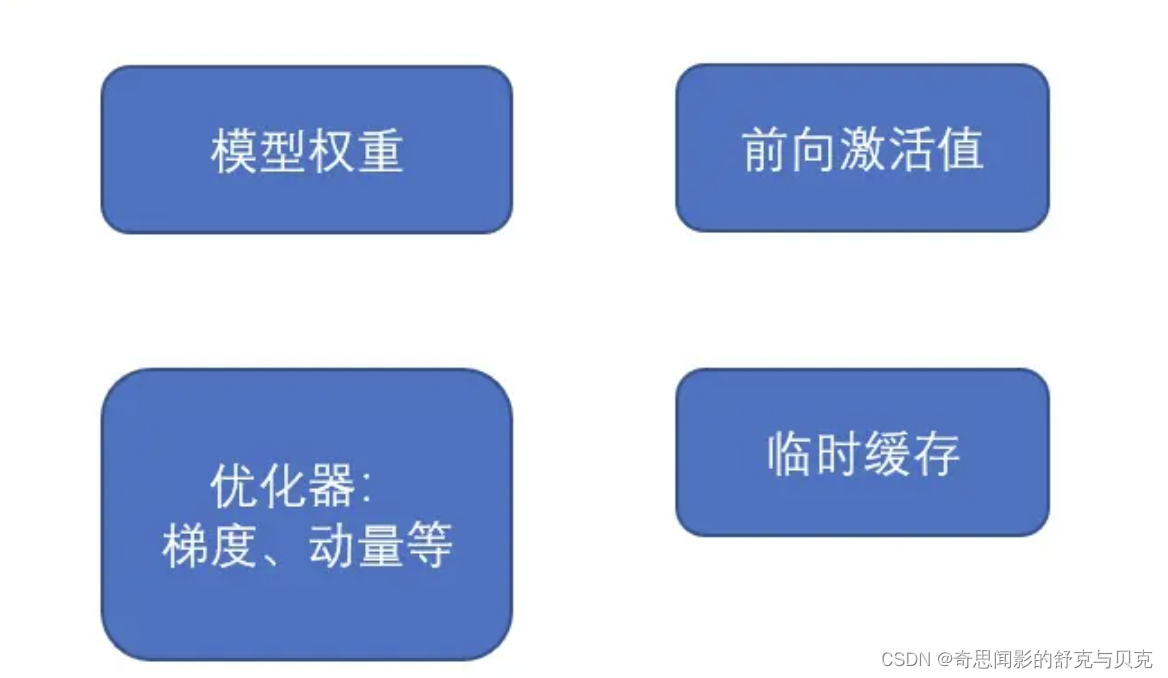
以LLM中最常见的Adam + fp16混合精度训练为例,分析其显存占用有以下四个部分:

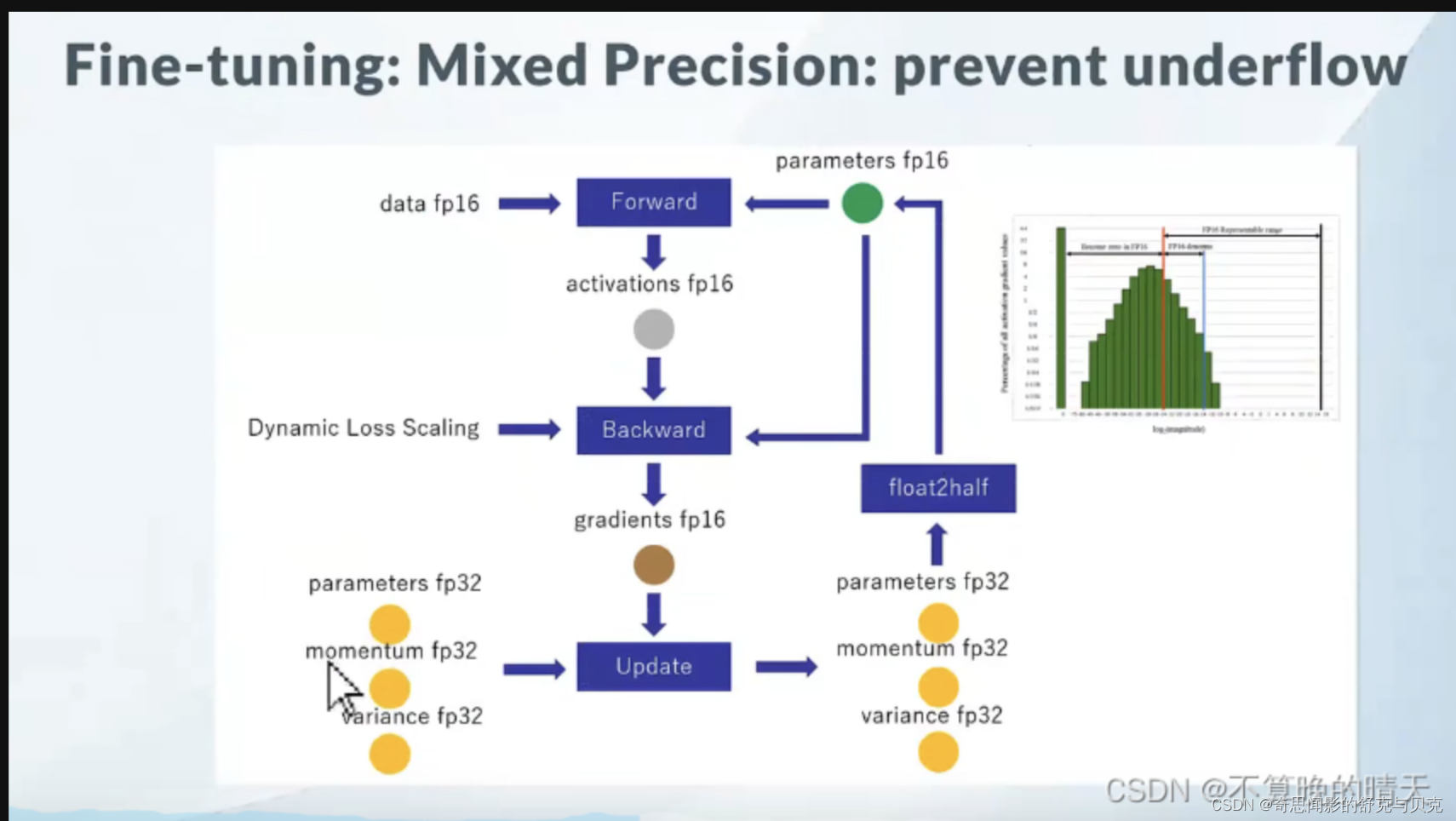
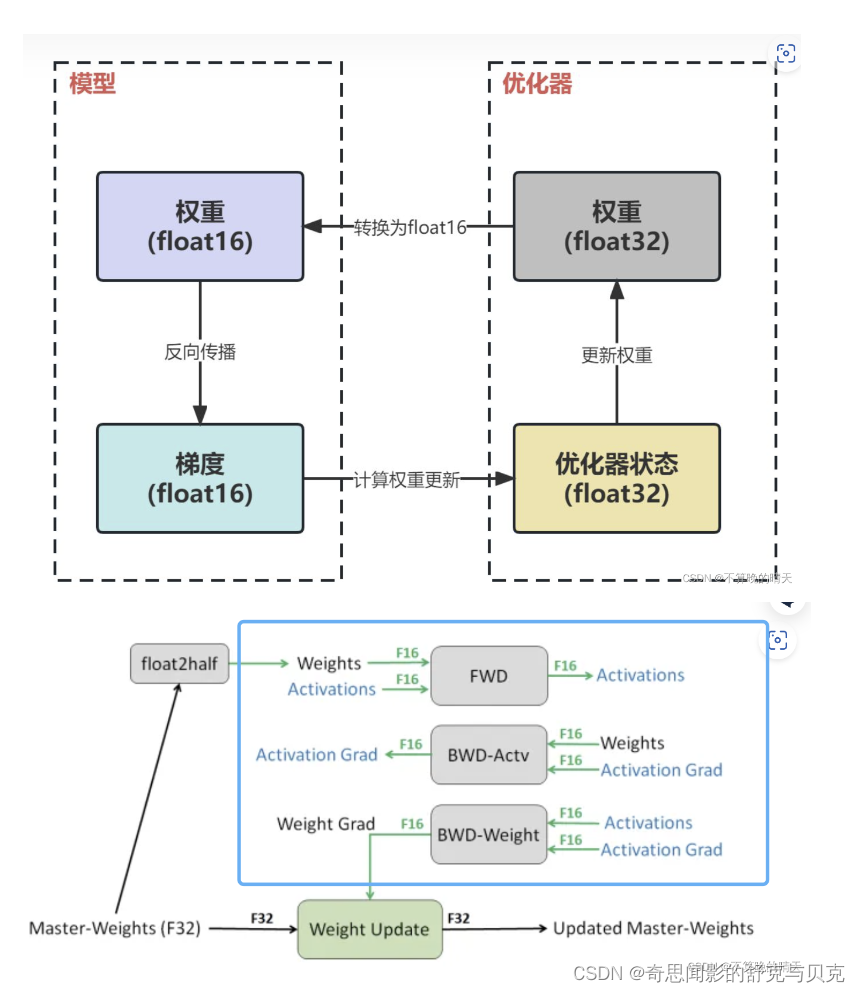

GPT-2含有1.5B个参数,如果用fp16格式,只需要1.5G*2Byte=3GB显存, 但是模型状态实际上需要耗费1.5B*16=24GB.
llama2 7B最低显存要求:如果用fp16格式,只需要7G*2Byte=14GB显存, 但是模型状态实际上需要耗费7B*16=112GB.
比如说有一个模型参数量是1M,在一般的深度学习框架中(比如说PyTorch),一般是32位存储。32位存储的意思就是1个参数用32个bit来存储。那么这个拥有1M参数量的模型所需要的存储空间的大小即为:1M * 32 bit = 32Mb = 1M * 4Byte = 4MB。因为1 Byte = 8 bit。现在的quantization技术就是减少参数量所占的位数:比如用16位存储,那么:所需要的存储空间的大小即为:1M * 16 bit = 16Mb = 2MB。

显存计算
全参数微调LLaMA-2-7B:
1. 开启zero3且不offload时,全参数微调最少需要显存可以估计为n_params(in Billion)16个GB。所以7*16=112GB,大约是1120/80=1.4张80G的A100显卡,大概是1台机器的2张卡。这里估计的只是把模型、梯度和优化器放下需要的显存,前向计算还需要额外的显存。
全参数微调LLaMA-2-70B:
1. 开启zero3且不offload时,全参数微调最少需要显存可以估计为n_params(in Billion)16个GB。所以70*16=1120GB,大约是1120/80=14张80G的显卡,大概是两台机器。这里估计的只是把模型、梯度和优化器放下需要的显存,前向计算还需要额外的显存。
| 测试1 | 测试2 | |
|---|---|---|
| setting | huggingface trainer 数据长度吃满 | 同 |
| nnodes | 4 | 4 |
| ngpus_per_node | 8 | 8 |
| batch_size_per_device | 1 | 3 |
| gradient_accumulate_steps | 16 | 3 |
| global_batch_size (前面4个的乘积) | 512 | 288 |
| 每步需要的时间,秒 (稳定训练若干步后) | 249.56 | 105.30 |
| nvidia-smi看到的显存占用,MB | 71000 | 75000 |
| 训练120k个样本需要的时间 | 14h50m | 11h57m |
可以看出,要想训练快,还是要把batch_size_per_device尽量开大一些。
checkpoint大小计算
保存checkpoint的时候只需要模型参数(fp16)和优化器状态(fp32)就行了。
对于70B的模型,使用AdamW训练时优化器的参数量是模型本身的两倍,所以最后算起来每个checkpoint需要70 * 2 + 70 * 2 * 4 = 700GB ,还是非常大的。建议设置一下hf trainer的--save_total_limit number ,把太早的checkpoint删掉,避免集群的磁盘满了。
结论如下:
- 不考虑Activation,3090的模型容量上限是 24/16=1.5B,A100的模型容量上限是 80/16=5B
- 假设训练的过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得我们的理论计算值
16Φ更接近真实的显存占用,那么24G的3090的模型容量上限是1.5B(差不多是GPT-2的水平),80G的A100的模型容量上限是5B
- 假设训练的过程中batchsize恒定为1,也即尽最大可能减少Activation在显存中的占用比例,使得我们的理论计算值
- 考虑Activation,3090的模型容量上限是 0.75B,A100的容量上限是 2.5B
- batchsize为1的训练效率非常低,batchsize大于1才能充分发挥GPU的效率,此时Activation变得不可忽略。经验之谈,一般需要给Activation预留一半的显存空间(比如3090预留12G,A100预留40G),此时3090的模型容量上限是0.75B,A100的容量上限是2.5B,我们实际测试结果接近这个值
- 激活在训练中会消耗大量的显存。一个具体的例子,模型为1.5B的GPT-2,序列长度为1K,batch size为32,则消耗显存为60GB。
- [1B, 5B] 是目前市面上大多数GPU卡的分水岭区间
- [0, 1B) 市面上绝大多数卡都可以直接硬train一发
- [1B, 5B] 大多数卡在这个区间的某个值上触发模型容量上限,具体触发值和显存大小有关
- (5B, ~) 目前没有卡能裸训
- VUE可视化编辑器(vue-uieditor)基于VUE2.x在线可视化VUE开发,所见即所得支持es2015JS语法开发结果不用二次编译,马上可以使用减轻开发成本,提升项目维护效率可实现低代码开发相关资源安装与使用安装yarnaddvue... [详细]
赞
踩
- 一、Lambda表达式1.jdk8接口的新特性多继承和默认方法。interfaceA{}interfaceB{}publicinterfaceInte1extendsA,B{Stringadd();defaultinttest(inta,i... [详细]
赞
踩
- 如何使用vscode上传服务器上代码到GitHub【可视化操作】新建本地仓库上传项目管理更新代码新建本地仓库点击左边SourceControl栏,出现如下两个按钮,表示该文件夹还没有建立git仓库,选择上面的按钮InitializeRepo... [详细]
赞
踩
- Java中的Lambda表达式是JDK8中的一种新特性,它允许我们将一段代码(这段代码可以理解为一个接口的实现)当成参数传递给某个方法,然后进行业务处理,这种方式更像是一种函数式编程风格,可以让代码结构更简洁,开发效率更高。比较让人容易迷乱... [详细]
赞
踩
- 题意:给你一个有n(2思路:不难发现,最后一定要正好去掉k-1条边才能使他们互不连通,对于这k-1条边我们希望他们的权值之和最小,更进一步,我们希望选取的每条边都尽量小。正常来想,应该是边权递增排序,每次去掉一条边,看是否不连通的数目加... [详细]
赞
踩
- jdk1.8新特性知识点:Lambda表达式 函数式接口 *方法引用和构造器调用 StreamAPI 接口中的默认方法和静态方法 新时间日期API _jdk1.8的新特性jdk1.8的新特性jdk1.8新特性知识点:Lambda表... [详细]
赞
踩
- Python支持向量机1声明本文的数据来自网络,部分代码也有所参照,这里做了注释和延伸,旨在技术交流,如有冒犯之处请联系博主及时处理。2支持向量机简介相关概念见下:支持向量机通过寻找训练数据里最大化类之间距离的超平面来来对数据进行分类。间隔... [详细]
赞
踩
- Git什么是Git?Git是一款源代码管理工具(版本控制工具)我们写的代码需要使用Git进行管理。源代码有必要管理起吗?1.02.0//svn,vss,vcs….git有必要,因为人工的去处理不同的版本,做相应备份会很麻烦。Git是linu... [详细]
赞
踩
- 个人博客个人博客:https://www.crystalblog.xyz/备用地址:https://wang-qz.gitee.io/crystal-blog/1.简介JDK8是官方发布的一个大版本,提供了很多新特性功能给开发者使用,包含语... [详细]
赞
踩
- 介绍目前的多目标优化算法有很多,KalyanmoyDeb的带精英策略的快速非支配排序遗传算法(nondominatedsortinggeneticalgorithmIl,NSGA-I)无疑是其中应用最为广泛也是最为成功的一种。clc;cle... [详细]
赞
踩
- 编辑|明明1月19日,在极客公园创新者大会IF2018的现场,GoogleBrain首席工程师陈智峰发表题为:《找答案从定义问题开始——TensorFlow可以用来做什么?》的演讲,分享了GoogleBrain最近一年到两年时间里面的研究方... [详细]
赞
踩
- Checkers:负责真实服务器的健康检查healthchecking,是keepalived最主要的功能。上图是Keepalived的功能体系结构,大致分两层:用户空间(userspace)和内核空间(kernelspace)。主要包括I... [详细]
赞
踩
- Java11版本中主要的新特性_javaltsjavalts今天来总结一下Java11版本中主要的新特性。供大家学习参考。目录1.HTTPClientAPI同步用法异步用法:需要用到SendSync方法2.直接运行单个Java... [详细]
赞
踩
- JDK各个版本新功能总览_jdk版本jdk版本目录JDK版本总览 1、JDK1.1(1997) &n... [详细]
赞
踩
- 集合——有时称为容器——是一个对象,它将多个元素组合成一个单元。集合用于存储、检索、操作和通信聚合数据。集合框架表示和操作集合的统一体系结构。组成接口表示集合的抽象数据类型。接口允许对集合进行独立于其表示细节的操作。在面向对象语言中,接口通... [详细]
赞
踩
- 目录一、接口的默认方法二、Lambda表达式三、函数式接口四、方法与构造函数引用五、Lambda作用域六、访问局部变量七、访问对象字段与静态变量八、访问接口的默认方法九、DateAPI十、Annotation注解一、接口的默认方法Java8... [详细]
赞
踩
- 效果代码实现importrandom#导入标准模块中的randomif__name__=='__main__':checkcode=""#保存验证码的变量foriinrange(4):#循环四次index=random.randrange(... [详细]
赞
踩
- 玄学之门题目:分析:代码:题目:传送门分析:类似kruskalkruskalkruskal算法的过程,对于一条边,如果它们的两个点属于两个不同的集合,那么这些集合间都要连边,为保证最小生成树还是数据给出的树,我们就让它们都连上v+1v+1v... [详细]
赞
踩
- git_git显示着未进行版本管理的文件提交不了git显示着未进行版本管理的文件提交不了文章目录gitpush失败,提示![rejected]master->master(fetchfirst)error:failedtopushsomer... [详细]
赞
踩
- 谢谢你能看我一本正经的胡说八道。0)缘由为什么要写这么一篇博文呢?我在很多次面试中,都被问到SVM算法。惭愧的是,我近两年一直关注深度学习算法,对SVM的理论本来就掌握得不熟,加上时间一久,被问到的时候结果可想而知。所以,思来想去,痛定思痛... [详细]
赞
踩

