
- 1AtCoder Beginner Contest 293——A-E题讲解
- 2网络安全体系与网络安全模型_安全等级保护 环境模型
- 3使用Navicat将表设计导出数据库设计文档_数据库的设计表怎么导出
- 4Vue基础知识总结 13:从零开始搭建Vue项目_vue从零开始
- 5Docker基础配置_docker配置
- 6【ES6】- class继承_class extends c { constructor(...args: any[]) { su
- 7自定义el-dialog头部实现最大化和最小化_el-dialog自定义头部
- 8保姆级教程:js前端接入科大讯飞语音评测,实现朗读打分,vue对接科大讯飞语音评测,还可以实现句子逐词分析对错以及打分,将demo接入vue项目中_科大讯飞语音识别vue
- 9中华传统文化题材网页设计主题:基于HTML+CSS设计放飞青春梦想网页【学生网页设计作业源码】_传智之歌学工部,无悔的青春网页设计
- 10UE 光照可移动与静态在虚拟制片中的差别_ue5固定光
Keras调用单个或者多个GPU训练的方法_keras调用gpu
赞
踩
前期准备:
- 下载和安装自己 nvidia 驱动
- 按照nvidia 驱动的版本号安装 cuda 和 cudnn
- 安装 anaconda
- 添加 anaconda 的环境变量
- 创建 conda 的虚拟环境
1. 安装 keras-gpu
(因为 conda 会将一系列的附带包全部安装适配版本,例如 cudatoolkit,tensorflow-gpu,所以直接用 conda 安装 keras-gpu 即可)
进行这一步,默认读者已经安装了 anaconda 并且创建了自己的虚拟环境;
conda install keras-gpu
- 1
2. 调用单个 gpu 设备:
-
查看你都 gpu 设备编号:
nvidia-smi
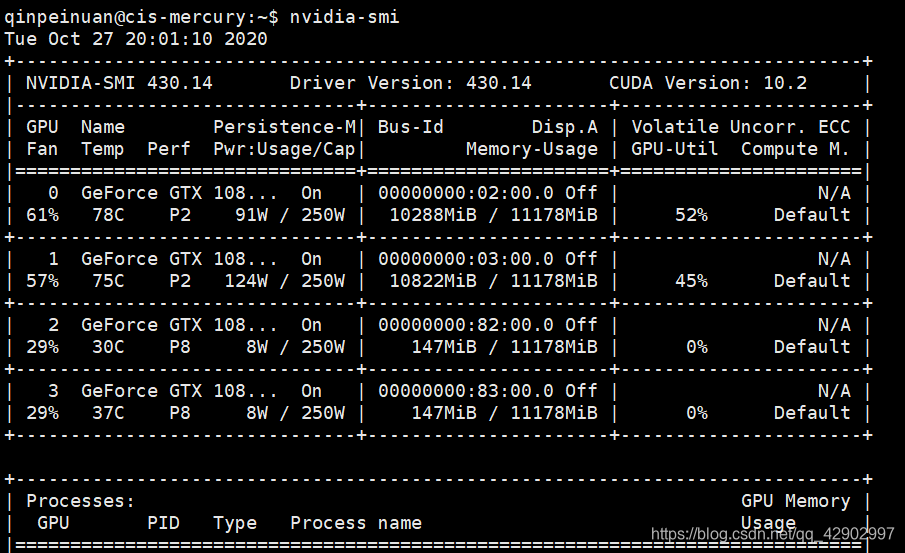
根据上面显示,有 0 1 2 3 一共四个 gpu -
在代码第一行添加下面一句话:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" //使用的gpu的编号,使用第 0 个
model = .... //创建、定义自己使用的模型
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
3. 调用多个 gpu 设备
3.1 数据并行计算
什么叫数据并行呢?
数据集一共 10000 个数据,他们太多了,没办法一同放到内存里面,所以要进行 batch_size的拆分,如果 batch_size = 64, 那么我们把 64 个数据叫做一个 batch,这个batch 是我们根据经验人为设定的;而多个 gpu 的数据并行计算会把一个 batch 的数据拆分成几个部分放在并行的 gpu 设备上,这样可以节省时间提高效率。
具体操作:
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "1,2,3"
model = .... //创建、定义自己使用的模型
model = keras.utils.multi_gpu_model(model, gpus=3) //在 compile 之前加这句话,gpus=3指的是 gpu 的数量用 3 个
model.compile(loss='categorical_crossentropy',
optimizer=opt,
metrics=['accuracy'])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
3.2 设备并行计算
什么叫设备并行呢?
设备并行性包括在不同设备上运行同一模型的不同部分。对于具有并行体系结构的模型,例如有两个分支的模型,这种方式很合适。这种并行可以通过使用 tf.device来实现。一个简单的例子:
## 模型中共享的 LSTM 用于并行编码两个不同的序列 input_a = keras.Input(shape=(140, 256)) input_b = keras.Input(shape=(140, 256)) shared_lstm = keras.layers.LSTM(64) ## 在一个 GPU 上处理第一个序列 with tf.device('/device:GPU:0'): encoded_a = shared_lstm(input_a) # 在另一个 GPU上 处理下一个序列 with tf.device('/device:GPU:1'): encoded_b = shared_lstm(input_b) # 在 CPU 上连接结果 with tf.device('/cpu:0'): merged_vector = keras.layers.concatenate([encoded_a, encoded_b], axis=-1) # 整个全连接层 fc1 = keras.layers.Dense(50, activation='softmax')(merged_vector) # 新建模型 model = keras.Model(inputs=[input_a, input_b], outputs=fc1) # 其他代码 ...

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 一.引言:之前提到过自定义Loss与metrics,下面盘点下常用的损失函数供今后自定义损失函数使用。二.常见损失函数1.MAE平均绝对误差(mean-absoluteerror)pre为预测值,y为真实值,MAE为预测值与真实值差的绝对值... [详细]
赞
踩
- 定义余弦相似度层,并在batch内进行负采样NEG,batch_size=20,128classNegativeCosineLayer():"""自定义batch内负采样并做cosine相似度的层"""def__call__(self,in... [详细]
赞
踩
- 一.引言DSSM(LearningDeepStructuredSemanticModelsforWebSearchusingClickthroughData)一文利用点击数据挖掘词语的深层语义模型,其思路是构建一个Query塔和一个Titl... [详细]
赞
踩
- pythonkerasCNN训练文字的一位特征向量怎么构造为什么幸福总是擦肩而过,偶尔想你的时候,就让回忆来陪小编。keras/imdb_cnn.pyatmaster·fchollet/keras·GitHub'''Thisexampled... [详细]
赞
踩
- 详解Keras的Embedding层_可训练embedding层可训练embedding层Embedding层keras.layers.embeddings.Embedding(input_dim,output_dim,embeddings... [详细]
赞
踩
- Bert简介与Keras-Bert常用Demo展示。_keras-bertkeras-bert目录一.引言二.Bert简介1.EmbeddingLayer2.Encoderlayer3.Pre-training与Fine-Tuning三.K... [详细]
赞
踩
- Keras:基于Python的深度学习库(这份学习资料是学习的老师上课的ppt,感谢张老师)一、Keras关键词中文官网:https://keras.io/zh/纯Python 符号式编程 Tensorflow或Theano为后端(back... [详细]
赞
踩
- 参考:http://keras-cn.readthedocs.io/en/latest/一、Keras简介Keras是一个高层神经网络API,Keras由纯Python编写而成并基Tensorflow、Theano以及CNTK后端。Kera... [详细]
赞
踩
- 在本教程中,我们介绍了如何使用Keras构建和训练一个简单的卷积神经网络进行手写数字识别。Keras提供了许多其他层和功能,可以用于构建更复杂的神经网络模型。我们鼓励初学者在这个基础上继续探索Keras的更多功能,并尝试解决不同类型的深度学... [详细]
赞
踩
- 本文内容参考以下文章并做知识汇总:http://www.cnblogs.com/lc1217/p/7132364.htmlhttps://keras-cn.readthedocs.io/en/latest/1.关于Keras1)简介Kera... [详细]
赞
踩
- 小白也能学会的简单神经网络的搭建,全面了解Keras高层接口_tensorflow.kerastensorflow.keras目录 1.网络层类2.网络容器3.模型装配4.模型训练5.模型测试6.模型保存(1)张量方式(2)网络方... [详细]
赞
踩
- 深度学习框架-keras_.keras.keras1.4tf.keras介绍tf.keras是TensorFlow2.0的高阶API接口,为TensorFlow的代码提供了新的风格和设计模式,大大提升了TF代码的简洁性和复用性,官方也推荐使... [详细]
赞
踩
- Keras:Python深度学习库简介Keras是一个高级神经网络API,用Python编写,能够在TensorFlow,CNTK或Theano之上运行。它的开发重点是实现快速开发。能够以最小的时间成本从理论到结果,这也进行快速研究验证的关... [详细]
赞
踩
- 全栈工程师开发手册(作者:栾鹏)python教程全解一、网络层keras的层主要包括:常用层(Core)、卷积层(Convolutional)、池化层(Pooling)、局部连接层、递归层(Recurrent)、嵌入层(Embedding)... [详细]
赞
踩
- 在本文中,了解了如何在Keras中创建用于照片中对象识别的深度学习模型。关于CIFAR-10数据集以及如何将其加载到Keras中并绘制数据集中的临时示例如何在问题上训练和评估一个简单的卷积神经网络如何将简单的卷积神经网络扩展为深度卷积神经网... [详细]
赞
踩
- 深度学习是一种新兴的技术,已经在许多领域中得到广泛的应用,如计算机视觉、自然语言处理、语音识别等。Keras是深度学习的一种重要框架,它具有许多优点,如简单易用、模块化、多后端支持等。Keras核心是Keras的主要库,它提供了一些高级AP... [详细]
赞
踩
- catalogue1.引言2.一些基本概念3.Sequential模型4.泛型模型5.常用层6.卷积层7.池化层8.递归层Recurrent9.嵌入层Embedding1.引言Keras是一个高层神经网络库,Keras由纯Python编写而... [详细]
赞
踩
- Keras是一个Python深度学习框架,可以方便地定义和训练几乎所有类型的深度学习模型。Keras最开始是为研究人员开发的,其目的在于快速实验。本文简单介绍了Keras的原理和用法。_pythonkeraspythonkerasKeras... [详细]
赞
踩
- IntroductionKeras是一个高级的神经网络API,用Python实现,并可以基于TensorFlow,CNTK与Theano等计算框架运行。Keras的核心是神经网络,它的意义主要在于使得神经网络的实现更加方便快捷,因此它本质上... [详细]
赞
踩
- 目录1.典型深度学习框架概述可视化解读十种CNN框架2.深度迁移学习攻略应对过拟合数据增强十种卷积神经网络框架1.典型深度学习框架概述论文发表时间:-Keras可以使用的6种模型现在已经不止6种:KerasDocumentation“[m]... [详细]
赞
踩

