
- 1UNet 系列:做医学图像分割的任何人,都必须要会使用 nnU-Net_nnunet和unet区别
- 2Unity-ROS与激光雷达小车搭建(五)_gazebo-unity
- 3confluence 编辑器这次没有加载_【PyCharm】 配置Python环境 加载Pandas包
- 4ST发布M33内核新品STM32U5,首款40nm工艺超低功耗系列,160MHz全速运行19uA/MHz_stm32u5发售日期
- 5HTML5作品展示摄影网站网页模板源码下载_图片展示页面源代码
- 6Index_js setproperty
- 72023年美赛获奖结果分析(附中英文版赛题)_2023美赛
- 8HTML常用标签之标题、段落、换行和水平线标签_写出 标题标记、段落标记
- 9支付宝原生小程序封装组件_支付宝小程序封装公共的js
- 10pyqt写个元旦快乐代码
pytorch配置双显卡,使用双显卡跑代码_pytorch-gpu 双卡测试代码
赞
踩
项目场景:
Linux系统,pytorch环境
问题描述:
使用的服务器有两张显卡,感觉一张显卡跑代码比较慢,想配置两张显卡同时跑代码,只需要在你的代码中添加几行,就可以使用双显卡,亲测有效。
解决方案:
提示:这里填写该问题的具体解决方案:
先看以下官方示例代码,插入添加的地方是需要我们添加在代码中的代码行
- import torch
- import torch.nn as nn
- from torch.utils.data import Dataset, DataLoader
- import os
- #######添加
- os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 这里输入你的GPU_id
-
- # Parameters and DataLoaders
- input_size = 5
- output_size = 2
-
- batch_size = 30
- data_size = 100
- #######添加
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
-
- # Dummy DataSet
- class RandomDataset(Dataset):
-
- def __init__(self, size, length):
- self.len = length
- self.data = torch.randn(length, size)
-
- def __getitem__(self, index):
- return self.data[index]
-
- def __len__(self):
- return self.len
-
- rand_loader = DataLoader(dataset=RandomDataset(input_size, data_size),
- batch_size=batch_size, shuffle=True)
-
- # Simple Model
- class Model(nn.Module):
- # Our model
-
- def __init__(self, input_size, output_size):
- super(Model, self).__init__()
- self.fc = nn.Linear(input_size, output_size)
-
- def forward(self, input):
- output = self.fc(input)
- print("\tIn Model: input size", input.size(),
- "output size", output.size())
-
- return output
- ################添加
- # Create Model and DataParallel
- model = Model(input_size, output_size)
- if torch.cuda.device_count() > 1:
- print("Let's use", torch.cuda.device_count(), "GPUs!")
- model = nn.DataParallel(model)
- model.to(device)
-
-
- #Run the Model
- for data in rand_loader:
- input = data.to(device)
- output = model(input)
- print("Outside: input size", input.size(),
- "output_size", output.size())
其中我将model = nn.DataParallel(model)修改为model = nn.DataParallel(model.cuda()),这一步直接参照网上修改的,因此这一步没有报错。
比如我自己在我代码中添加如下:
- from model.hash_model import DCMHT as DCMHT
- import os
- from tqdm import tqdm
- import torch
- import torch.nn as nn
- from torch.utils.data import DataLoader
- import scipy.io as scio
-
-
- from .base import TrainBase
- from model.optimization import BertAdam
- from utils import get_args, calc_neighbor, cosine_similarity, euclidean_similarity
- from utils.calc_utils import calc_map_k_matrix as calc_map_k
- from dataset.dataloader import dataloader
- ###############添加
- os.environ['CUDA_VISIBLE_DEVICES'] = '0,1' # 这里输入你的GPU_id
- device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
-
- class Trainer(TrainBase):
-
- def __init__(self,
- rank=0):
- args = get_args()
- super(Trainer, self).__init__(args, rank)
- self.logger.info("dataset len: {}".format(len(self.train_loader.dataset)))
- self.run()
-
- def _init_model(self):
- self.logger.info("init model.")
- linear = False
- if self.args.hash_layer == "linear":
- linear = True
-
- self.logger.info("ViT+GPT!")
- HashModel = DCMHT
- self.model = HashModel(outputDim=self.args.output_dim, clipPath=self.args.clip_path,
- writer=self.writer, logger=self.logger, is_train=self.args.is_train, linear=linear).to(self.rank)
- ####################################添加
- self.model= nn.DataParallel(self.model.cuda())
- if torch.cuda.device_count() >1:
- print("Lets use",torch.cuda.device_count(),"GPUs!")
- self.model.to(device)
-
- if self.args.pretrained != "" and os.path.exists(self.args.pretrained):
- self.logger.info("load pretrained model.")
- self.model.load_state_dict(torch.load(self.args.pretrained, map_location=f"cuda:{self.rank}"))
-
- self.model.float()
- self.optimizer = BertAdam([
- {'params': self.model.clip.parameters(), 'lr': self.args.clip_lr},
- {'params': self.model.image_hash.parameters(), 'lr': self.args.lr},
- {'params': self.model.text_hash.parameters(), 'lr': self.args.lr}
- ], lr=self.args.lr, warmup=self.args.warmup_proportion, schedule='warmup_cosine',
- b1=0.9, b2=0.98, e=1e-6, t_total=len(self.train_loader) * self.args.epochs,
- weight_decay=self.args.weight_decay, max_grad_norm=1.0)
-
- print(self.model)
添加以上代码后一般还会报如下错误:
“AttributeError: ‘DataParallel’ object has no attribute ‘xxx’”,解决办法为先在dataparallel后的model调用module模块,然后再调用xxx。
比如在上述我自己的代码中会报错“AttributeError: ‘DataParallel’ object has no attribute ‘clip’”,
解决办法是将model,修改为model.module.,后续报错大致相同,将你的代码中涉及到model.的地方修改为model.module.即可。
self.optimizer = BertAdam([
{'params': self.model.module.clip.parameters(), 'lr': self.args.clip_lr},
{'params': self.model.module.image_hash.parameters(), 'lr': self.args.lr},
{'params': self.model.module.text_hash.parameters(), 'lr': self.args.lr}
], lr=self.args.lr, warmup=self.args.warmup_proportion,
检查显卡使用情况
打开终端,在终端输入nvidia-smi命令可查看显卡使用情况
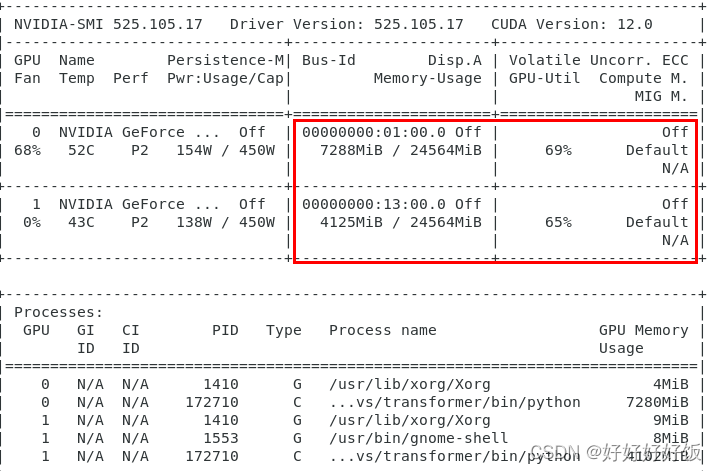
成功使用双显卡跑代码!
- 本文从BERT的基本概念和架构开始,详细讲解了其预训练和微调机制,并通过Python和PyTorch代码示例展示了如何在实际应用中使用这一模型。我们探讨了BERT的核心特点,包括其强大的注意力机制和与其他Transformer架构的差异。_... [详细]
赞
踩
- article
成功解决RuntimeError: [enforce fail at C:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c
成功解决RuntimeError:[enforcefailatC:\actions-runner\_work\pytorch\pytorch\builder\windows\pytorch\c10\core\impl\alloc_cpu.c... [详细]赞
踩
- roberta文本分类 ... [详细]
赞
踩
- 本文使用PyTorch构建一个简单而有效的泰坦尼克号生存预测模型。通过这个项目,你会学到如何使用PyTorch框架创建神经网络、进行数据预处理和训练模型。我们将探讨如何处理泰坦尼克号数据集,设计并训练一个神经网络,以预测乘客是否在灾难中幸存... [详细]
赞
踩
- 人/B们/E常/S说/S生/B活/E是/S一/S部/S教/B科/M书/E”图中是双向的三层RNNs,堆叠多层的RNN网络,可以增加模型的参数,提高模型的拟合。理网格化数据(例如图像数据)的神经网络,RNN是专门用来处理序列数据的神经网络。双... [详细]
赞
踩
- 本文深入探索了PyTorch框架中的torch.nn模块,这是构建和实现高效深度学习模型的核心组件。我们详细介绍了torch.nn的关键类别和功能,包括ParameterModuleSequentialModuleListModuleDic... [详细]
赞
踩
- 本篇博客深入探讨了PyTorch的torch.nn子模块中与Transformer相关的核心组件。我们详细介绍了及其构成部分——编码器()和解码器(),以及它们的基础层——和。每个部分的功能、作用、参数配置和实际应用示例都被全面解析。这些组... [详细]
赞
踩
- PyTorch是由Facebook的AI研究团队开发的一个开源机器学习库,最初发布于2016年。它的前身是Torch,这是一个使用Lua语言编写的科学计算框架。PyTorch的出现标志着Torch的核心功能被转移到了Python这一更加流行... [详细]
赞
踩
- 本文详细介绍了PyTorch框架中的多个填充类,用于在深度学习模型中处理不同维度的数据。这些填充方法对于保持卷积神经网络中数据的空间维度至关重要,尤其在图像处理、音频信号处理等领域中有广泛应用。每种填充方法都有其特定的应用场景和注意事项,如... [详细]
赞
踩
- article
PyTorch 简单易懂的实现 CosineSimilarity 和 PairwiseDistance - 距离度量的操作_nn.cosinesimilarity(dim=1)返回的一定是标量吗
和。模块专注于计算两个高维数据集之间的余弦相似度,适用于评估文档、用户偏好等在特征空间中的相似性。而模块提供了一种计算两组数据点之间成对欧几里得距离的有效方式,这在聚类、近邻搜索或预测与实际值之间距离度量的场景中非常有用。这两个模块共同构成... [详细]赞
踩
- torch.cosine_similarity可以对两个向量或者张量计算相似度>>>input1=torch.randn(100,128)>>>input2=torch.randn(100,128)>>>output=torch.cosin... [详细]
赞
踩
- 本文提供几个pytorch中常用的向量相似度评估方法,并给出其源码实现,供大家参考。分别为以下六个。(其中第一个pytoch自带有库函数)_l2正则化和余弦相似度计算pytorxhl2正则化和余弦相似度计算pytorxh原文链接:https... [详细]
赞
踩
- 余弦相似度\color{red}{余弦相似度}余弦相似度在NLP的任务里,会对生成两个词向量进行相似度的计算,常常采用余弦相似度公式计算。余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小。余弦值越接近1,就表明夹角越接... [详细]
赞
踩
- 两个张量之间的欧氏距离即m*e和n*e张量之间的欧式距离理论分析算法实现importtorchdefeuclidean_dist(x,y):"""Args:x:pytorchVariable,withshape[m,d]y:pytorchV... [详细]
赞
踩
- importtorch.nn.functionalasFF.cosin_similarity(a,b,dim=1)沿着dim维度对a,b两个tensor计算余弦相似度。由于dim属性的存在,使得a,b两个tensor可以为任意维。_pyto... [详细]
赞
踩
- importtorchfromtorchimportTensordefcos_similar(p:Tensor,q:Tensor):sim_matrix=p.matmul(q.transpose(-2,-1))a=torch.norm(p,... [详细]
赞
踩
- 由于采用/usr/local/bin/gcc编译,先设置LD_LIBRARY_PATH,再启动python3。importtorch成功,测试cuda是否可用。importtorch报错。_编译pytorcharm库编译pytorcharm... [详细]
赞
踩
- CNN卷积神经网络的简单示例是使用PyTorch库实现的。示例涵盖了导入所需的Python库和模块、将数据转换为图像格式、将数据格式从numpy转换为tensor并打包成batch、定义CNN网络、定义损失函数、训练网络并显示学习曲线、进行... [详细]
赞
踩
- 日萌社人工智能AI:KerasPyTorchMXNetTensorFlowPaddlePaddle深度学习实战(不定时更新)Embedding版本.py"""pipinstalltorchtext"""#导入torchtext.datase... [详细]
赞
踩
- 本文介绍了如何在WindowsSubsystemforLinux2(WSL2)环境中使用NVIDIADocker进行全栈开发和深度学习。WSL2提供了一个强大的Linux环境,而NVIDIADocker则允许在该环境中利用NVIDIAGPU... [详细]
赞
踩

