
- 1K8s 入门指南(一):单节点集群环境搭建
- 22023年最热门的网络安全行业岗位分析_网络安全的职业分析
- 3【知识图谱】图数据库Neo4jDesktop的安装图文详解(小白适用)_neo4j桌面版
- 4IntelliJ IDEA无公网远程连接Windows本地Mysql数据库提高开发效率
- 5人工智能 - 目标检测:发展历史、技术全解与实战
- 6最最普通程序员,如何利用工资攒够彩礼,成为人生赢家
- 7【Docker】Docker Compose,yml 配置指令参考的详细讲解
- 8无需部署服务器,如何结合内网穿透实现公网访问导航页工具Dashy
- 9AI 绘画Stable Diffusion 研究(八)sd采样方法详解
- 10南京邮电大学数学实验最新版
Zookeeper分布式命名服务实战
赞
踩
目录
分布式命名服务
命名服务是为系统中的资源提供标识能力。ZooKeeper的命名服务主要是利用ZooKeeper节点的树形分层结构和子节点的顺序维护能力,来为分布式系统中的资源命名。需要用到分布式命名服务的应用场景典型的有:分布式API目录、分布式节点命名、分布式ID生成器。
分布式API目录
为分布式系统中各种API接口服务的名称、链接地址,提供类似JNDI(Java命名和目录接口)中的文件系统的功能。借助于ZooKeeper的树形分层结构就能提供分布式的API调用功能。著名的Dubbo分布式框架就是应用了ZooKeeper的分布式的JNDI功能。在Dubbo中,使用ZooKeeper维护的全局服务接口API的地址列表。大致的思路为:
服务提供者(Service Provider)
在启动的时候,向ZooKeeper上的指定节点/dubbo/${serviceName}/providers写入自己的API地址,这个操作就相当于服务的公开。
服务消费者(Consumer)
启动的时候,订阅节点/dubbo/{serviceName}/providers下的服务提供者的URL地址,获得所有服务提供者的API。
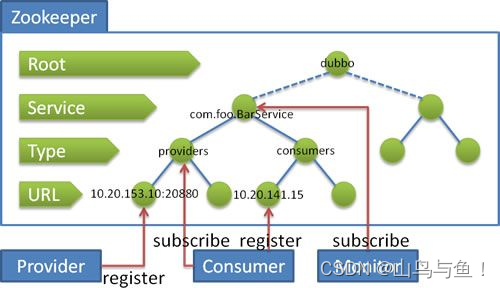
分布式节点的命名
一个分布式系统通常会由很多的节点组成,节点的数量不是固定的,而是不断动态变化的。比如说, 当业务不断膨胀和流量洪峰到来时,大量的节点可能会动态加入到集群中。而一旦流量洪峰过去了, 就需要下线大量的节点。这就需要用到分布式节点的命名服务。
可用于生成集群节点的编号的方案:
1. 使用数据库的自增ID特性,用数据表存储机器的MAC地址或者IP来维护。
2. 使用ZooKeeper持久顺序节点的顺序特性来维护节点的NodeId编号。
在第2种方案中,集群节点命名服务的基本流程是:
启动节点服务,连接ZooKeeper,检查命名服务根节点是否存在,如果不存在,就创建系统的根节点。 在根节点下创建一个临时顺序ZNode节点,取回ZNode的编号把它作为分布式系统中节点的NODEID。 如果临时节点太多,可以根据需要删除临时顺序ZNode节点。
分布式的ID生成器
分布式系统中,分布式ID生成器的使用场景非常多,比如大量的数据记录、大量的系统消息 、大量的请求日志、分布式节点的命名服务等
传统的数据库自增主键已经不能满足需求。在分布式系统环境中,需要一种全新的唯一ID系统, 这种系统需要满足以下需求:
全局唯一:不能出现重复ID。
高可用:ID生成系统是基础系统,被许多关键系统调用,一旦宕机,就会造成严重影响。
分布式的ID生成器方案:
1. Java的UUID。
2. 分布式缓存Redis生成ID:利用Redis的原子操作INCR和INCRBY,生成全局唯一的ID。
3. Twitter的SnowFlake算法。
4. ZooKeeper生成ID:利用ZooKeeper的顺序节点,生成全局唯一的ID。
5. MongoDB的ObjectId:MongoDB是一个分布式的非结构化NoSQL数据库,每插入一条记录会自动生成全局唯 一的一个“_id”字段值,它是一个12字节的字符串,可以作为分布式系统中全局唯一的ID。
基于Zookeeper实现分布式ID生成器
在ZooKeeper节点的四种类型中,其中有以下两种类型具备自动编号的能力:
PERSISTENT_SEQUENTIAL持久化顺序节点。
EPHEMERAL_SEQUENTIAL临时顺序节点。
ZooKeeper的每一个节点都会为它的第一级子节点维护一份顺序编号,会记录每个子节点创建的先后 顺序,这个顺序编号是分布式同步的,也是全局唯一的。可以通过创建ZooKeeper的临时顺序节点的方法,生成全局唯一的ID
- @Slf4j
- public class IDMaker extends CuratorBaseOperations {
-
- private String createSeqNode(String pathPefix) throws Exception {
- CuratorFramework curatorFramework = getCuratorFramework();
- //创建一个临时顺序节点
- String destPath = curatorFramework.create()
- .creatingParentsIfNeeded()
- .withMode(CreateMode.EPHEMERAL_SEQUENTIAL)
- .forPath(pathPefix);
- return destPath;
- }
-
- public String makeId(String path) throws Exception {
- String str = createSeqNode(path);
- if(null != str){
- //获取末尾的序号
- int index = str.lastIndexOf(path);
- if(index>=0){
- index+=path.length();
- return index<=str.length() ? str.substring(index):"";
- }
- }
- return str;
- }
- }

- @Slf4j
- public class IDMakerTest {
-
- @Test
- public void testMarkId() throws Exception {
- IDMaker idMaker = new IDMaker();
- idMaker.init();
- String pathPrefix = "/idmarker/id-";
- //模拟5个线程创建id
- for(int i=0;i<5;i++){
- new Thread(()->{
- for (int j=0;j<10;j++){
- String id = null;
- try {
- id = idMaker.makeId(pathPrefix);
- log.info("线程{}第{}次创建id为{}",Thread.currentThread().getName(),
- j,id);
- } catch (Exception e) {
- e.printStackTrace();
- }
- }
- },"thread"+i).start();
- }
- }
- }
执行结果如下 :
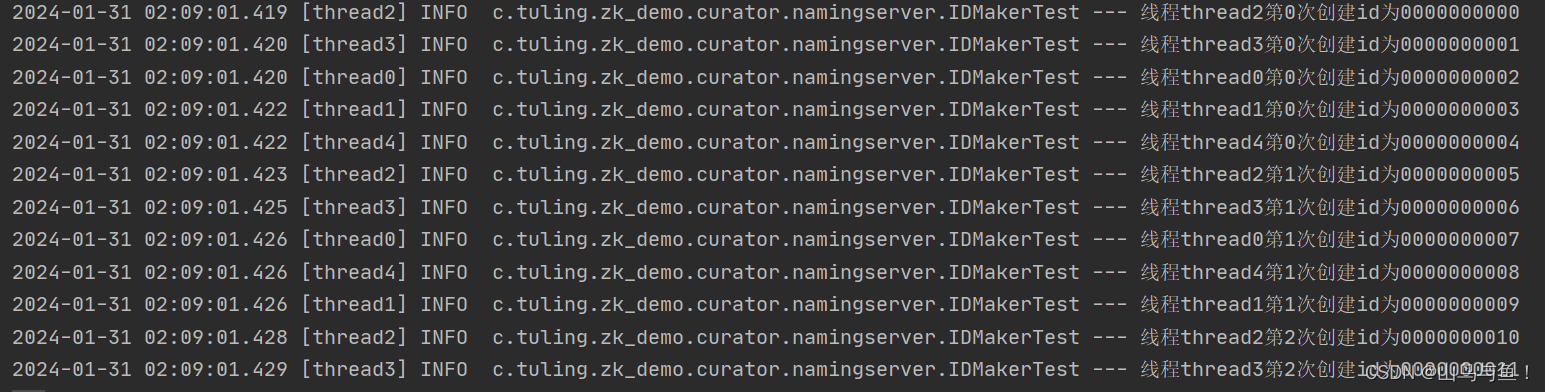
如果是每秒钟要几万、几十万的id,这种方案是不行的,受限于zookeeper的顺序节点写操作。
基于Zookeeper实现SnowFlakeID算法
Twitter(推特)的SnowFlake算法是一种著名的分布式服务器用户ID生成算法。SnowFlake算法所生成的ID是一个64bit的长整型数字。这个64bit被划分成四个部分,其中后面三个部分分别表示时间戳、工作机器ID、序列号。
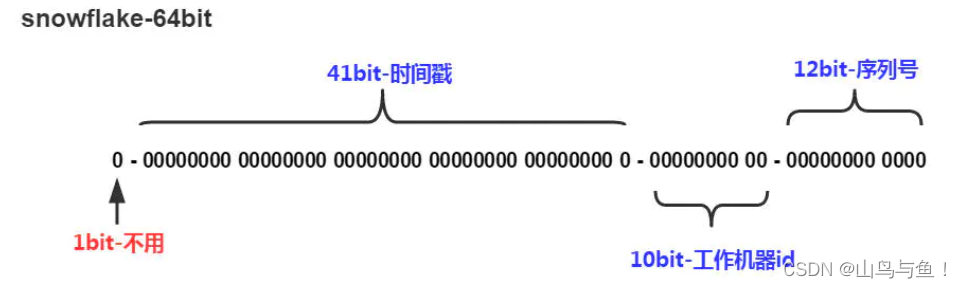
SnowFlakeID的四个部分,具体介绍如下:
1. 第一位 占用1 bit,其值始终是0,没有实际作用。
2. 时间戳 占用41 bit,精确到毫秒,总共可以容纳约69年的时间。
3. 工作机器id占用10 bit,最多可以容纳1024个节点。
4. 序列号占用12 bit。这个值在同一毫秒同一节点上从0开始不断累加,最多可以累加到4095。 在工作节点达到1024顶配的场景下,SnowFlake算法在同一毫秒最多可以生成的ID数量为: 1024 * 4096 =4194304,在绝大多数并发场景下都是够用的。
SnowFlake算法的优点:
1. 生成ID时不依赖于数据库,完全在内存生成,高性能和高可用性。
2. 容量大,每秒可生成几百万个ID。
3. ID呈趋势递增,后续插入数据库的索引树时,性能较高。
SnowFlake算法的缺点:
1. 依赖于系统时钟的一致性,如果某台机器的系统时钟回拨了,有可能造成ID冲突,或者ID乱序。 2. 在启动之前,如果这台机器的系统时间回拨过,那么有可能出现ID重复的危险。
基于zookeeper实现雪花算法:
- public class SnowflakeIdGenerator {
-
- /**
- * 单例
- */
- public static SnowflakeIdGenerator instance =
- new SnowflakeIdGenerator();
-
- /**
- * 初始化单例
- *
- * @param workerId 节点Id,最大8091
- * @return the 单例
- */
- public synchronized void init(long workerId) {
- if (workerId > MAX_WORKER_ID) {
- // zk分配的workerId过大
- throw new IllegalArgumentException("woker Id wrong: " + workerId);
- }
- instance.workerId = workerId;
- }
-
- private SnowflakeIdGenerator() {
-
- }
-
- /**
- * 开始使用该算法的时间为: 2017-01-01 00:00:00
- */
- private static final long START_TIME = 1483200000000L;
-
- /**
- * worker id 的bit数,最多支持8192个节点
- */
- private static final int WORKER_ID_BITS = 13;
-
- /**
- * 序列号,支持单节点最高每毫秒的最大ID数1024
- */
- private final static int SEQUENCE_BITS = 10;
-
- /**
- * 最大的 worker id ,8091
- * -1 的补码(二进制全1)右移13位, 然后取反
- */
- private final static long MAX_WORKER_ID = ~(-1L << WORKER_ID_BITS);
-
- /**
- * 最大的序列号,1023
- * -1 的补码(二进制全1)右移10位, 然后取反
- */
- private final static long MAX_SEQUENCE = ~(-1L << SEQUENCE_BITS);
-
- /**
- * worker 节点编号的移位
- */
- private final static long WORKER_ID_SHIFT = SEQUENCE_BITS;
-
- /**
- * 时间戳的移位
- */
- private final static long TIMESTAMP_LEFT_SHIFT = WORKER_ID_BITS + SEQUENCE_BITS;
-
- /**
- * 该项目的worker 节点 id
- */
- private long workerId;
-
- /**
- * 上次生成ID的时间戳
- */
- private long lastTimestamp = -1L;
-
- /**
- * 当前毫秒生成的序列
- */
- private long sequence = 0L;
-
- /**
- * Next id long.
- *
- * @return the nextId
- */
- public Long nextId() {
- return generateId();
- }
-
- /**
- * 生成唯一id的具体实现
- */
- private synchronized long generateId() {
- long current = System.currentTimeMillis();
-
- if (current < lastTimestamp) {
- // 如果当前时间小于上一次ID生成的时间戳,说明系统时钟回退过,出现问题返回-1
- return -1;
- }
-
- if (current == lastTimestamp) {
- // 如果当前生成id的时间还是上次的时间,那么对sequence序列号进行+1
- sequence = (sequence + 1) & MAX_SEQUENCE;
-
- if (sequence == MAX_SEQUENCE) {
- // 当前毫秒生成的序列数已经大于最大值,那么阻塞到下一个毫秒再获取新的时间戳
- current = this.nextMs(lastTimestamp);
- }
- } else {
- // 当前的时间戳已经是下一个毫秒
- sequence = 0L;
- }
-
- // 更新上次生成id的时间戳
- lastTimestamp = current;
-
- // 进行移位操作生成int64的唯一ID
-
- //时间戳右移动23位
- long time = (current - START_TIME) << TIMESTAMP_LEFT_SHIFT;
-
- //workerId 右移动10位
- long workerId = this.workerId << WORKER_ID_SHIFT;
-
- return time | workerId | sequence;
- }
-
- /**
- * 阻塞到下一个毫秒
- */
- private long nextMs(long timeStamp) {
- long current = System.currentTimeMillis();
- while (current <= timeStamp) {
- current = System.currentTimeMillis();
- }
- return current;
- }
-
- }
- article
Zookeeper 实战 | Zookeeper 和Spring Cloud相结合解决分布式锁、服务注册与发现、配置管理_spring-cloud2.0 zookeeper配置用户名密码
Zookeeper是一个开源的分布式协调服务,它起源于Google的Chubby项目,并成为Hadoop分布式系统的基础组件。Zookeeper提供了一组简单的原语集,分布式应用程序可以基于这些原语实现同步服务、配置维护和命名服务等。Zoo... [详细]赞
踩
- Quorum是集群模式下特有的对象,是Zookeeper服务器实例(ZooKeeperServer)的托管者,QuorumPeer代表了集群中的一台机器,在运行期间,QuorumPeer会不断检测当前服务器实例的运行状态,同时根据情况发起L... [详细]
赞
踩
- Dubbo和ZooKeeper是如何协同工作的?文章目录Dubbo和ZooKeeper是如何协同工作的?Dubbo1.服务提供者-配置2.服务消费者-配置负载均衡1.随机+权重(random)2.轮询+权重(roundrobin)3.最少连... [详细]
赞
踩
- ZooKeeper是一个开源的分布式协调服务,旨在帮助构建可靠的分布式系统。它通过提供高可用、高性能的分布式协调机制来解决分布式应用中的一致性和协作问题。首先,我们来看ZooKeeper的起源、特点和应用场景。ZooKeeper最初由雅虎研... [详细]
赞
踩
- springboot整合zookeeper_springbootzookeeperspringbootzookeeper文章目录springboot整合zookeepercurator简介curator整合依赖配置类yml配置注册监听机制w... [详细]
赞
踩
- article
3.Spring Boot使用Apache Curator实现leader选举「第四章 ZooKeeper Curator应用场景实战」「架构之路ZooKeeper理论和实战」_spring boot zk选主
相关历史文章(阅读本文前,您可能需要先看下之前的系列????)国内最全的SpringBoot系列之四享元模式:共享女友-第355篇什么是ZooKeeper-第347篇ZooKeeper安装-第348篇ZooKeeper数据结构和实操-第34... [详细]赞
踩
- /***演示ApacheCuratorAPI*1、增删查改*2、ACL访问权限控制*3、注册watch事件的三个接口*/@RestControllerpublicclassCuratorClientApiText{privateLogger... [详细]
赞
踩
- 通过springboot快速开发web应用,并读取单机部署的zookeeper上的数据。_springbootzookeeperspringbootzookeeper本文讲解了如果通过springboot快速开发web服务,并读取zooke... [详细]
赞
踩
- Dubbo是阿里出品的分布式开源服务框架,阿里已交予Apache开源组织基金会ApacheDubbo是一款高性能、轻量级的开源RPC服务框架Dubbo官网RPC【RemoteProcedureCall】是指远程过程调用,是一种进程间通信方式... [详细]
赞
踩
- 注意我这里用的是官方最稳定的版本3.7.1,版本之间有个别命令是有差距的!本篇文章的示例SpringBoot和Zookeeper客户端以及zookeeper都是最新版本!Curator是Netflix公司开源的⼀套zookeeper客户端框... [详细]
赞
踩
- 同样的这篇文章很大程度上参考了下面这篇文章:Springboot整合Dubbo/ZooKeeper详解SOA案例所以我也是当做转载了。1、首先是安装与部署zookeeper下载、解压、修改zoo.cfg、启动。本demo采用单点模式。详细内... [详细]
赞
踩
- springbootzookeeperdubbospringboot2.3.4zookeeper3.5.9dubbo2.7.2_springboot+zookeeper+dubbo集成demospringboot+zookeeper+dub... [详细]
赞
踩
- 1.必备软件及作用链接:https://pan.baidu.com/s/1wk7jgCjtUSLMJnnLfltZFw提取码:67k3JDK:ZooKeeper和Tomcat是用Java编写创建,它运行在JVM。所以需要使用JDK6或更高版... [详细]
赞
踩
- 吐槽一下,搞这个花了4个多小时,心态有点崩。开始了,怎么配interface目录结构如下:单纯的建了一个接口内容如下packagecom.yichen.demo;publicinterfaceIUserService{publicStrin... [详细]
赞
踩
- 分布式锁是分布式系统中常用的一个同步工具,它可以在多个进程之间协调访问共享资源,避免数据不一致或重复处理。在分布式环境中,由于网络通信的延迟和节点故障等原因,传统的锁机制无法满足需求。因此,分布式锁成为了实现分布式同步的常用方案之一。Zoo... [详细]
赞
踩
- Zookeeper&Springboot使用介绍基础环境说明:SpringBoot:2.3.4.RELEASEcurator:5.1.0具体功能内容:锁选举Barrier缓存持久化节点队列一、Zookeeper基本介绍二、基本操作creat... [详细]
赞
踩
- 在SpringBoot项目中,通过整合ZooKeeper,我们可以实现分布式锁、配置管理等功能,帮助构建高可用、可靠的分布式应用。通过以上步骤,你已经成功在SpringBoot项目中整合了ZooKeeper,实现了与ZooKeeper的连接... [详细]
赞
踩
- springboot中zookeeper使用文章目录springboot中zookeeper使用一、简介二、示例2.1添加maven依赖2.2添加配置文件application.yaml2.3定义zookeeper客户端2.4定义zooke... [详细]
赞
踩
- Dubbo官网ApacheDubbo是一款高性能、轻量级的开源JavaRPC框架它提供了三大核心能力面向接口的远程方法调用智能容错和负载均衡以及服务自动注册和发现。Dubbo基本工作流程服务提供者(Provider):暴露服务的服务提供方,... [详细]
赞
踩
- zookeeper+Springboot实现服务器动态上下线监听用于监听节点数据产生的变化,在zk中可以配置集群的通用配置,当配置数据发生了变化之后通知所有订阅该节点的Watcher,该节点发生事件类型用于监听节点状态的变化,比如创建一个节... [详细]
赞
踩

