
- 1基于 STM32 的语音识别智能家居控制系统的设计(LD3320语音识别芯片+ESP8266 WIFI模块+DHT11温湿度采集+MQ系列 烟雾及可燃气体+蜂鸣器+步进电机模拟窗帘+OLED液晶显示+_基于语音识别的智能家居控制
- 2【SpringBoot+MP】阿里云短信测试服务操作流程、用户手机验证码登录实现_阿里云短信服务学生测试资质信息怎么写
- 3数据库系统概论第五版(王珊) 课后习题答案_数据库系统概论第五版课后答案
- 4数据库课程设计——学生选课管理系统_数据库学生选课管理系统
- 5Go语言(Golang)的Web框架比较:gin VS echo_echo gin
- 6蓝桥杯单片机零基础到国二经验分享_xmf393.com
- 7ST7789-TFT屏幕驱动(整理有stm32/51单片机/arduino等驱动代码)
- 8微信小程序canvas手写签字
- 9【Spring Boot 3】【JPA】枚举类型持久化
- 10【好书推荐-第二期】《实战AI大模型 》:带你走进大模型GPTs、AIGC的世界(李开复、周鸿祎、颜水成倾力推荐)
聊一聊AIGC
赞
踩
“UGC不存在了”——借鉴自《三体》
ChatGPT 的横空出世将一个全新的概念推上风口——AIGC( AI Generated Content)。
GC即创作内容(Generated Content),和传统的UGC、PGC,OGC不同的是,AIGC的创作主体由人变成了人工智能。
xGC
PGC:Professionally Generated Content,专业生产内容
UGC:User Generated Content,用户生产内容
OGC:Occupationally Generated Content,品牌生产内容。
AI 可以 Generate 哪些 Content?
作为淘宝内容线的开发,我们每天都在和内容打交道,那么AI到底能生成什么内容?
围绕着不同形式的内容生产,AIGC大致分为以下几个领域:

文本生成
基于NLP的文本内容生成根据使用场景可分为非交互式文本生成与交互式文本生成。
非交互式文本生成包括摘要/标题生成、文本风格迁移、文章生成、图像生成文本等。
交互式文本生成主要包括聊天机器人、文本交互游戏等。
【代表性产品或模型】:JasperAI、copy.AI、ChatGPT、Bard、AI dungeon等。

图像生成
图像生成根据使用场可分为图像编辑修改与图像自主生成。
图像编辑修改可应用于图像超分、图像修复、人脸替换、图像去水印、图像背景去除等。
图像自主生成包括端到端的生成,如真实图像生成卡通图像、参照图像生成绘画图像、真实图像生成素描图像、文本生成图像等。
【代表性产品或模型】:EditGAN,Deepfake,DALL-E、MidJourney、Stable Diffusion,文心一格等。

音频生成
音频生成技术较为成熟,在C端产品中也较为常见,如语音克隆,将人声1替换为人声2。还可应用于文本生成特定场景语音,如数字人播报、语音客服等。此外,可基于文本描述、图片内容理解生成场景化音频、乐曲等。
【代表性产品或模型】:DeepMusic、WaveNet、Deep Voice、MusicAutoBot等。

视频生成
视频生成与图像生成在原理上相似,主要分为视频编辑与视频自主生成。
视频编辑可应用于视频超分(视频画质增强)、视频修复(老电影上色、画质修复)、视频画面剪辑(识别画面内容,自动场景剪辑)。
视频自主生成可应用于图像生成视频(给定参照图像,生成一段运动视频)、文本生成视频(给定一段描述性文字,生成内容相符视频)。
【代表性产品或模型】:Deepfake,videoGPT,Gliacloud、Make-A-Video、Imagen video等。
多模态生成
以上四种模态可以进行组合搭配,进行模态间转换生成。如文本生成图像(AI绘画、根据prompt提示语生成特定风格图像)、文本生成音频(AI作曲、根据prompt提示语生成特定场景音频)、文本生成视频(AI视频制作、根据一段描述性文本生成语义内容相符视频片段)、图像生成文本(根据图像生成标题、根据图像生成故事)、图像生成视频。
【代表性产品或模型】:DALL-E、MidJourney、Stable Diffusion等。
本文接下来将会着重讲述文本类AIGC和图像类AIGC。
文本类AIGC
RNN → Transformer → GPT(ChatGPT)
最近势头正猛的ChatGPT就是文本类AIGC的代表。
ChatGPT(Chat Generative Pre-trained Transformer),即聊天生成型预训练变换模型,Transformer指的是一种非常重要的算法模型,稍后将会介绍。
其实现在的用户对于聊天机器人已经很熟悉了,比如天猫精灵、小爱同学或是Siri等语音助手。那为什么ChatGPT一出现,这些语音助手就显得相形见绌呢?
本质上是NLP模型之间的差异。
在自然语义理解领域(NLP)中,RNN和Transformer是最常见的两类模型。
循环神经网络(recurrent neural network)
RNN,即循环神经网络(recurrent neural network)源自于1982年由Saratha Sathasivam 提出的霍普菲尔德网络。下图所示是一个RNN网络的简易展示图,左侧是一个简单的循环神经网络,它由输入层、隐藏层和输出层组成。
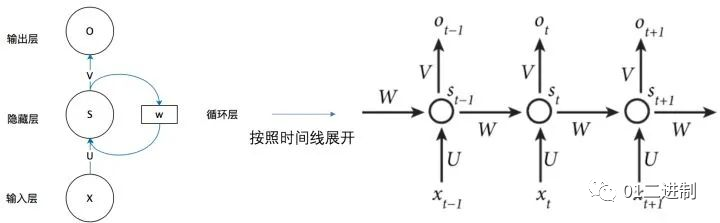
RNN 的主要特点在于 w 带蓝色箭头的部分。输入层为 x,隐藏层为 s,输出层为 o。U 是输入层到隐藏层的权重,V 是隐藏层到输出层的权重。隐藏层的值 s 不仅取决于当前时刻的输入 x,还取决于上一时刻的输入。权重矩阵 w 就是隐藏层上一次的值作为这一次的输入的权重。由此可见,这种网络的特点是,每一个时刻的输入依赖于上一个时刻的输出,难以并行化计算。
从人类视角理解RNN 人类可以根据语境或者上下文,推断语义信息。就比如,一个人说了:我喜欢旅游,其中最喜欢的地方是三亚,以后有机会一定要去___,很显然这里应该填”三亚”。 但是机器要做到这一步就比较困难。RNN的本质是像人一样拥有记忆的能力,因此,它的输出就依赖于当前的输入和记忆。
Transformer
而Transformer模型诞生于2017年,起源自《Attention Is All You Need》。这是一种基于Attention机制来加速深度学习算法的模型,可以进行并行化计算,而且每个单词在处理过程中注意到了其他单词的影响,效果非常好。
!](https://cdn.ytools.xyz/uPic/202303211936538.png)
Attention机制:又称为注意力机制,顾名思义,是一种能让模型对重要信息重点关注并充分学习吸收的技术。通俗的讲就是把注意力集中放在重要的点上,而忽略其他不重要的因素。 其中重要程度的判断取决于应用场景,根据应用场景的不同,Attention分为空间注意力和时间注意力,前者用于图像处理,后者用于自然语言处理。
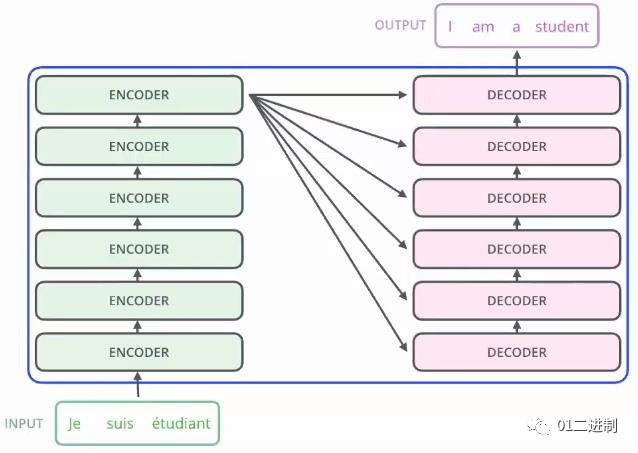
Transformer是完全基于自注意力机制的一个深度学习模型,有关该模型的介绍,详情可参考下面这篇文章
- baichuan-7B是由百川智能开发的一个开源的大规模预训练模型。基于Transformer结构,在大约1.2万亿tokens上训练的70亿参数模型,支持中英双语,上下文窗口长度为4096。在标准的中文和英文权威benchmark(C-E... [详细]
赞
踩
- AGI时代步步紧逼,还不跟紧步伐吗?AIGC|AGI究竟是什么?为什么大家都在争先入场?一、AI大语言模型进入爆发阶段2022年12月ChatGPT突然爆火,原因是其表现出来的智能化已经远远突破了我们的常规认知。虽然其呈现在使用者面前仅仅只... [详细]
赞
踩
- 2023年是人工智能大语言模型大爆发的一年,一些概念和英文缩写也在这一年里集中出现,很容易混淆,甚至把人搞懵。LLM:LargeLanguageModel,即大语言模型,旨在理解和生成人类语言。LLM的特点是规模庞大,包含成百、上千亿的参数... [详细]
赞
踩
- 变分自编码器(VAE)是一种强大的生成模型,可用于生成图像、文本和音频等各种数据类型。本文介绍了VAE的原理,并提供了一个使用PyTorch的示例来生成手写数字图像。_vae手写数据集vae手写数据集1变分自编码器介绍变分自编码器(Vari... [详细]
赞
踩
- AIGC,AI做图,洗图的技巧,星火大模型,通义千问大模型,文心一言的做图能力,读图能力的对比,测试大模型。_aigc洗稿aigc洗稿目录一、洗稿,洗图,洗视频二、如何洗图2.1先看看效果2.2如何做的2.3提示词示例三、试试星火和通义2.... [详细]
赞
踩
- 尽管只有五天的时间,但遵循这个计划,您一定能在北京度过一个舒适而愉快的假期。:使用清晰、准确的语言,避免使用模糊的术语或行话,除非您确定这些术语对于理解问题是必要的。:虽然详细很重要,但也请尝试保持您的问题尽可能简洁,避免不必要的信息,以免... [详细]
赞
踩
- aigc局部动画aigc局部动画ComfyUI+AnimateDiff+ControlNet的Inpainting生成局部重绘动画_哔哩哔哩_bilibili动图:【StableDiffusion】SD生成超稳定丝滑卡通动画(附安装包),一... [详细]
赞
踩
- controlnet可以让stablediffusion的生图变得可控。冻结了stablediffusion的预训练模型并重用它的预训练编码层神经网络结构与零初始化卷积层连接,从零开始逐渐增加参数,并确保微调过程中不会有噪声影响Contro... [详细]
赞
踩
- IPAdapter能够通过图像给StableDiffusion模型以内容提示,让其生成参考该图像画风,可以免去Lora的训练,达到参考画风人物的生成效果。通过文本提示词生成的图像,往往需要设置复杂的提示词,通常设计提示词变得很复杂。文本提示... [详细]
赞
踩
- 说句题外话,其实很多B2B行业在逐渐B2C化,也就是说它主打的不是企业,而是企业里的某个人,采用B2C的营销方法,产生大量的内容去影响这个人的心智,典型例子如ABM,亦或很多B2B企业通过抖音等典型的B2C场景做营销,所以在行业发展上会越来... [详细]
赞
踩
- 本文提出VITS2,一种单阶段的文本到语音模型,可以有效地合成更自然的语音。通过在时长预测器中引入对抗学习,提高了训练推理效率和自然度。将transformer块添加到规范化流中,以捕获在转换分布时的长期依赖关系。通过在对齐搜索中引入高斯噪... [详细]
赞
踩
 万兴科技借力阿里云容器服务ACK和镜像服务企业版ACREE,进一步提升用户体验。Kubernetes是企业云上管理资源的最佳选择,具有很强的应用编排能力,可靠性及弹性。阿里云容器服务助力万兴科技AIGC应用加速作者:子白(顾静)2023年堪... [详细]
万兴科技借力阿里云容器服务ACK和镜像服务企业版ACREE,进一步提升用户体验。Kubernetes是企业云上管理资源的最佳选择,具有很强的应用编排能力,可靠性及弹性。阿里云容器服务助力万兴科技AIGC应用加速作者:子白(顾静)2023年堪... [详细]赞
踩
- Kafka是一种开源的分布式流处理平台,由Apache软件基金会开发和维护。它最初是由LinkedIn开发的,并在2011年成为开源项目。Kafka提供了高吞吐量、可持久化的数据流处理能力,可以处理大规模的实时数据流。它的设计目标是提供一个... [详细]
赞
踩
- AIGC继承了专业生成内容(PGC)的高质量特点,再结合用户生成内容(UGC)的分布式、互动的特点,打造了全新的数字内容生成与交互形态。AIGC的实现主要基于人工智能中的各种模型,比如说基于神经网络模型的图像生成,或者基于深度学习模型的文本... [详细]
赞
踩
- 人工智能生成内容(ArtificialIntelligenceGeneratedContent,简称AIGC)是指利用人工智能技术和算法来自动生成各种形式的内容,例如文章、新闻、广告、代码等。AIGC的发展可以追溯到机器学习和自然语言处理等... [详细]
赞
踩
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

