
- 1从三份白皮书看汽车网络安全模型_idprr
- 2【笔记】1、初学python3网络爬虫——环境配置_cmd加入python 爬虫
- 3vue封装一个卡片组件_vue card
- 4java基础(类,对象)_attributeerror: module 'scrapy' has no attribute '
- 5最常见DDOS攻击工具有哪些?怎么防御DDOS攻击?
- 6[ 云计算 | Azure 实践 ] 在 Azure 门户中创建 VM 虚拟机并进行验证
- 7面试必备:分库分表经典15连问_分库分表面试题
- 8【愚公系列】2023年11月 Java教学课程 203-RabbitMQ(SpringAMQP)
- 9网络安全(黑客)——2024自学
- 10ROS的卸载与安装【血泪总结!亲测有效】_卸载ros
Python学习笔记哈哈哈_某公司,账户余额有1w元,给20名员工发工资
赞
踩
目录
第二章
字面量
1.字面量的含义
代码中,被写在代码中的固定的值,称之为字面量
2.常见的字面量类型
整数、浮点数、字符串
3.如何基于print语句完成各类字面量的输出
print(10),输出整数10
print(13.14),输出浮点数13.14
print(“黑马程序员”),输出字符串:黑马程序员
注释
1.单行注释
通过 # 号定义
2.多行注释
通过一对三个引号来定义("""注释内容""")
变量
1.格式
变量 = 值
print(“输出的值是:”,变量)
2.快捷键
ctrl + d ,复制单行语句
数据类型
1.查看数据的类型
type():括号内可以是变量也可以是字面量
应用:name = “潘森”
type(name)
type(45)
type("数据类型")
2.变量有没有数据类型
没有类型
数据类型转换
字符串、整数、浮点数、类型转换的语句是什么?
int(x) 将x转换为一个整数
float(x) 将x转换为一个浮点数
str(x) 将x转换为字符串
注:浮点数转整数会丢失精度即小数部分
标识符
1.标识符的概念
用户编写代码时,对变量、类、方法等编写的名字,叫做标识符
2.标识符的命名规则
内容限定:
中文、英文、数字、下划线
大小写敏感
不可使用关键字
3.变量的命名规范
见名知意
下划线命名法
英文字母全小写
运算符
1.算术运算符
+,-,*,/,//,%,**
2.赋值运算符
=
字符的三种定义方式
1.字符串的三种定义方式
单引号
双引号
三引号
2.引号的嵌套
可以使用:转义字符 \ 来进行转义
字符串的拼接
1.如何拼接
使用“+”号连接字符串变量或字符串字面量
2.注意事项
无法和非字符串类型进行拼接
字符串格式化
1.字符串格式
"%占位符" % 变量
2.常用占位符
%s %d %f
3.实例
- name = "潘森"
- setup_year = 2004
- stock_price = 45.89
- message = "%s,成立于:%d,我今天的股价是:%.3f" % (name, setup_year, stock_price)
- print(message)
格式化的精度控制
1.精度控制的语法
m.n的形式控制
m和.n均可省略
2.如果m比数字本身宽度大
m不生效
3..n会对小数做精度限制
对小数部分做四舍五入
字符串格式化方式2
1.格式
f "{变量}{变量}" 的方式
2.特点
不会理会类型
不做精度控制
适合对精度没有要求的时候快速使用
3.实例
- name = "萨拉芬尼"
- set_year = 2008
- stock_price = 19.89
- print(f"我是{name},我成立于{set_year},我今天的股票价格是{stock_price}")
表达式的格式化
实例
- name = "数码"
- stock_price = 13.98
- stock_code = 4
- stock_price_daily_growth_factor = 1.3
- growth_days = 8
- finally_stock_price = stock_price_daily_growth_factor ** growth_days * stock_price
- print(f"公司:{name},股价代码:{stock_code},当前股价:{stock_price}")
- print("每日增长系数是%.2f,经过%d天的增长后,股价达到了%.2f" % (stock_price_daily_growth_factor, growth_days, finally_stock_price))
数据输入(input())
1.获取键盘数据
name = input();
2.拓展
name = input("请输入你的名字:");
第三章
布尔类型
1.表示真假的关键字
True和False
if语句的基本格式
1.基本格式
if 要判断的条件:
条件成立时,要做的事情
2.if语句的注意事项
判断条件的结果一定要是布尔类型
不要忘记判断条件后的:冒号
归属于if语句的代码块,需在前方填充4个空格缩进
if else语句
1.if else语句中
if和其代码块,条件满足时执行
else搭配if的判断条件,当不满足的时候执行
2.if else语句的注意事项
else 不需要判断条件,当if的条件不满足时,else执行
else的代码块,同一样要4个空格作为缩进
代码实例:
- age = int(input("请输入你的年龄:"))
- if age >= 18:
- print(f"您已成年,游玩需要补票10元")
- else:
- print("您未成年,可以免费游玩。")
-
- print("祝您游玩愉快!")
if elif else语句
1.if elif else语句的作用
可以完成多个条件的判断
2.使用if elif else的注意点
elif可以写多个
判断是互斥且有序的,上一个满足后面的就不会判断了
可以在条件判断中,直接写input语句,节省代码量
实例:
- num2 = 10
- if int(input("请输入你猜想的数字:")) == num2:
- print("你猜对了!")
- elif int(input("不对,再猜一次:")) == num2:
- print("你猜对了!")
- elif int(input("不对,再猜最后一次:")) == num2:
- print("你猜对了!")
- else:
- print("Sorry,全部猜错啦,我想的是:10")
判断语句的嵌套
案例需求:
定义一个数字(1~10,随机产生),通过判断来猜出数字
案例要求:
1.数字随机产生,范围1~10
2.有三次机会猜测数字,通过3层嵌套判断实现
3.每次猜不中,会提示大了或小了
- import random
- num = random.randint(1, 10)
- guess_num = int(input("请输入你要猜测的数字:"))
- if guess_num == num:
- print("恭喜,第一次就猜中了")
- else:
- if guess_num > num:
- print("你猜测的数字大了")
- else:
- print("你猜测的数字小了")
-
- guess_num = int(input("再次输入你要猜测的数字:"))
-
- if guess_num == num:
- print("恭喜,第二次猜中了")
- else:
- if guess_num > num:
- print("你猜测的数字大了")
- else:
- print("你猜测的数字小了")

第四章
while循环的基础应用
1.while循环的语法格式
while 条件:
条件满足时,做的事情1
条件满足时,做的事情2
条件满足时,做的事情3
条件满足时,做的事情n
2.while循环的注意事项
条件需要提供布尔类型结果,True继续,False停止
空格缩进不能忘
规划好循环终止条件,否则将无限循环
- num = 1
- sum = 0
- while num <= 100:
- sum = sum +num
- num = num + 1
-
- print(sum)
while循环基础案例
实例:
- import random
- num = random.randint(1, 100)
- count = 0
- flag = True
- while flag:
- guess_num = int(input("请输入你猜测的数字:"))
- count += 1
- if guess_num == num:
- print("猜中了")
- flag = False
- else:
- if guess_num > num:
- print("你猜的大了")
- else:
- print("你猜的太小了")
-
- print(f"你总共猜了{count}次")
while循环
实例1:
- i = 1
- while i <= 100:
- print(f"今天是第{i}天,准备表白......")
- j = 1
- while j <= 10:
- print(f"送给小妹的第{j}只玫瑰花")
- j += 1
- print("小妹,我喜欢你")
- i += 1
-
- print(f"坚持到第{i - 1}天,表白成功")
实例2:
- i = 1
- j = 1
- while i <= 9:
- j = 1
- while j <= i:
- print(f"{j} * {i}={j * i}", end=" ")
- j += 1
- print("")
- i += 1
for循环的基础语法
1.for循环的语法格式
for 临时变量in 待处理数据集(序列):
循环满足条件时执行的代码
2.for循环的注意点
无法定义循环条件,只能被动取出数据处理
要注意,循环内的语句,需要有空格缩进
实例:
- name = "huangluya"
- count = 0
- for x in name:
- if x == "a":
- count += 1
- print(count)
range语句
- num = 100
- count = 0
- for x in range(1, num):
- if x % 2 == 0:
- count += 1
- print(f"1到{num}范围内,有{count}个偶数")
for循环临时变量和作用域
1.for循环中的临时变量,其作用域限定
循环内
2.这种限定
是编程规范的限定,而非强制限定
不遵守也能正常运行,但是不建议这样做
如需访问临时变量,可以预先在循环外定义它
for循环的应用
实例:
- for i in range(1, 101):
- print(f"今天是向小妹表白的第{i}天,加油坚持")
- for j in range(1, 11):
- print(f"给小妹送的第{j}朵玫瑰花")
- print("小妹我喜欢你")
for循环九九乘法表
- for i in range(1, 10):
- for j in range(1, i + 1):
- print(f"{j}*{i}={j * i}", end=" ")
- print()
continue和break
continue
中断所在循环的档次执行,直接进入下一次循环
break
直接结束所在的循环
注意事项
countinue和break,在for和while循环中作用一致
在嵌套循环中,只能作用在所在的循环上,无法对上层循环起作用
循环综合案例
某公司,账户余额有1W元,给20名员工发工资。
员工编号从1到20,从编号1开始,依次领取工资,每人可领取1000元
领工资时,财务判断员工的绩效分(1-10)(随机生成),如果低于5,不发工资,换下一位
如果工资发完了,结束发工资。
- import random
- yue = 10000
- for i in range(1, 21):
- sc = random.randint(1, 10)
- if sc >= 5 and yue > 0:
- yue -= 1000
- print(f"向员工{i},发放工资1000元,账户余额还剩余{yue}元")
- elif yue <= 0:
- print("工资发完了,下个月领取吧。")
- break
- else:
- print(f"员工{i},绩效分{sc},低于5,不发工资,下一位")
第五章
函数定义
1.函数的定义
def 函数名(传入参数):
函数体
return 返回值
2.函数使用步骤
先定义函数
后调用函数
3.注意事项
参数不需要,可以省略
返回值不需要,可以省略
函数返回值
1.返回值语法
def 函数(参数...):
函数体
return 返回值
变量 = 函数(参数)
2.注意
函数体在遇到return后就结束了,所以写在return后的代码不会执行。
函数返回值——None类型
1.定义
None 是类型'NoneType'的字面量,用于表示:空的、无意义的
2.函数如何返回None
不适用return语句即返回None
主动return None
3.使用场景
函数返回值
if判断
变量定义
函数的说明文档
1.定义语法
def func(x, y):
"""
:param x:形参x的说明
:param y:形参y的说明
:return:返回值的说明
"""
函数体
return 返回值
:param 用于解释参数
:return 用于解释返回值
2.实例:
- def add(x, y):
- """
- :param x:形参x表示相加的其中一个数字
- :param y:形参y表示相加的另一个数字
- :return:返回值是2数相加的结果
- """
- result = x + y
- print(f"2数相加的结果是:{result}")
- return result
-
-
- print(add(2, 3))
变量的作用域
1.全局变量
- num = 200
-
-
- def test_a():
- print(f"test_a:{num}")
-
-
- def test_b():
- print(f"test_b:{num}")
-
-
- test_a()
- test_b()
- print(num)
2.global关键字
使用global关键字将函数内定义的变量声明为全局变量
- num = 100
-
-
- def testA():
- print(num)
-
-
- def testB():
- global num
- num = 200
- print(num)
-
-
- testA()
- testB()
综合案例
1.代码实例:
- yue = 20000
-
-
- def menu():
- print("-------------主菜单-------------")
- print("周杰轮,您好,欢迎来到黑马银行ATM。请选择操作:")
- print("查询余额 [输入1]")
- print("存款 [输入2]")
- print("取款 [输入3]")
- print("退出 [输入4]")
- num = int(input("请输入1~4,选择您需要做的事:"))
- if num == 1:
- check_yue()
- elif num == 2:
- save_money()
- elif num == 3:
- get_money()
- elif num == 4:
- return "a"
-
-
- def check_yue():
- print("-------------查询余额-------------")
- print(f"周杰轮,您好,您的余额剩余:{yue}元")
- menu()
-
-
- def save_money():
- print("-------------存款-------------")
- money = int(input("打算存多少:"))
- global yue
- yue = yue + money
- print(f"周杰轮,您好,您存款{money}元成功")
- print(f"周杰轮,您好,您的余额剩余:{yue}")
- menu()
-
-
- def get_money():
- money = int(input("请输入取款金额:"))
- global yue
- if yue >= money:
- print(f"周杰轮,您好,您取款{money}元成功")
- yue = yue - money
- else:
- print(f"周杰轮,您好,您的取款数目大于您的余额,取款失败,请重新操作")
- menu()
-
-
- for i in range(1, 100):
- a = menu()
- if a == "a":
- break
代码演示:
1.运行阶段
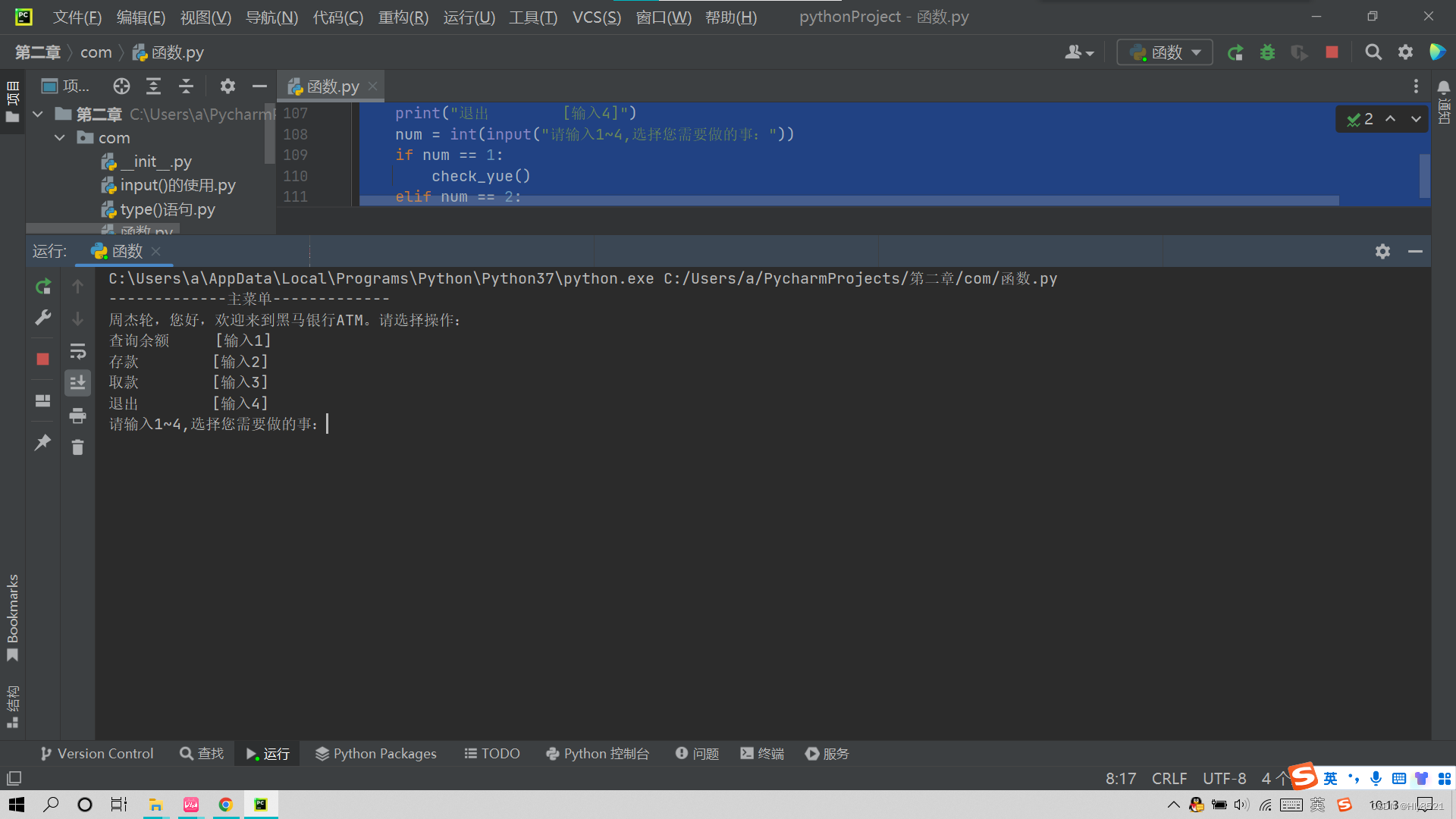
2.查询操作演示
3.存款操作演示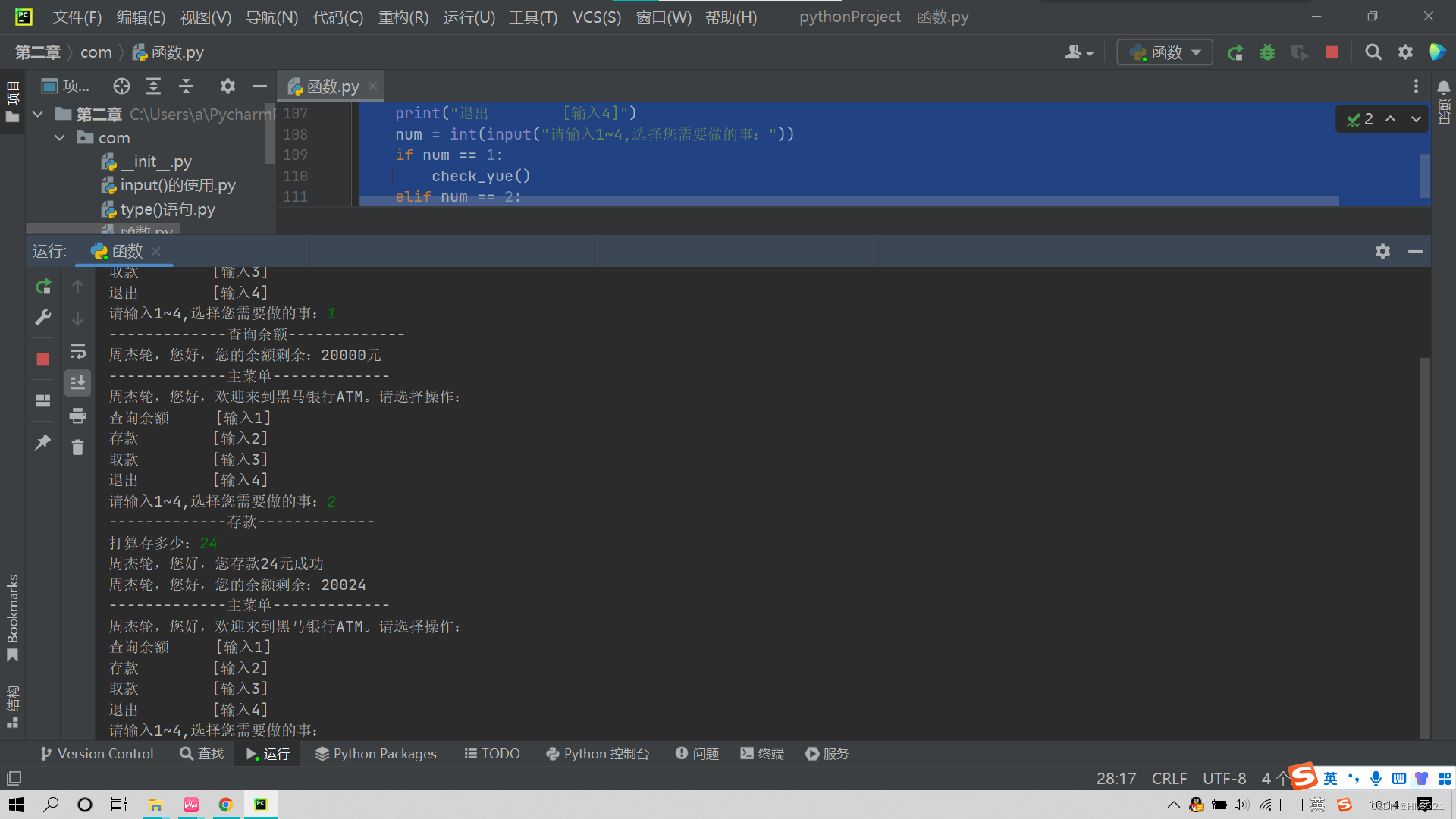
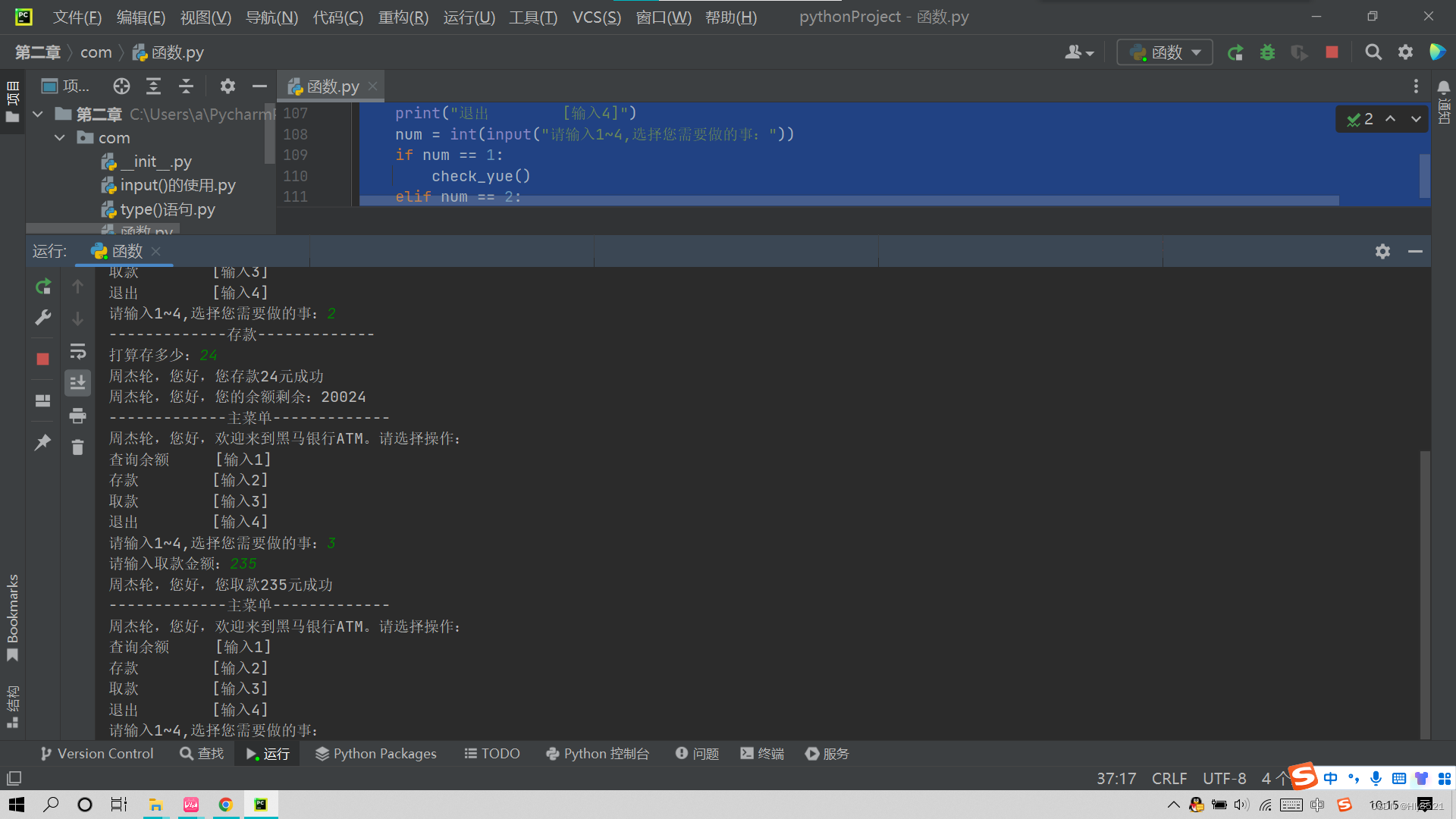
4.取款操作演示
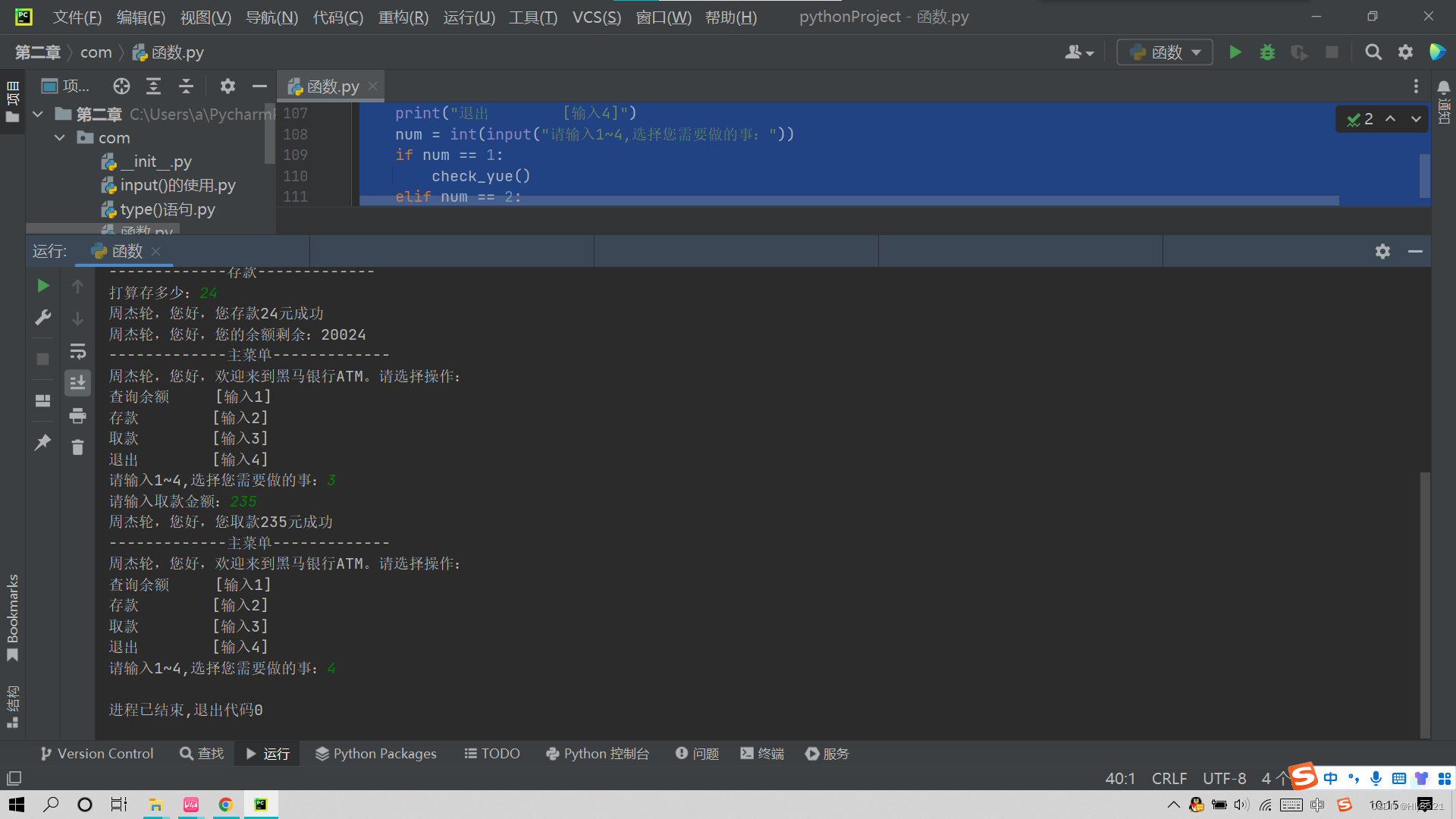
5.退出操作演示
list(列表)
1.列表的定义
基本语法:
# 字面量
[元素1,元素2,元素3,元素4,...]
# 定义变量
变量名称 = [元素1,元素2,元素3,元素4,...]
# 定义空列表
变量名称 = [ ]
变量名称 = list()
2.列表的下标索引
列表的每一个元素,都有编号称之为下标索引
需要注意下标索引的取值范围,超出范围无法取出元素,并且会报错
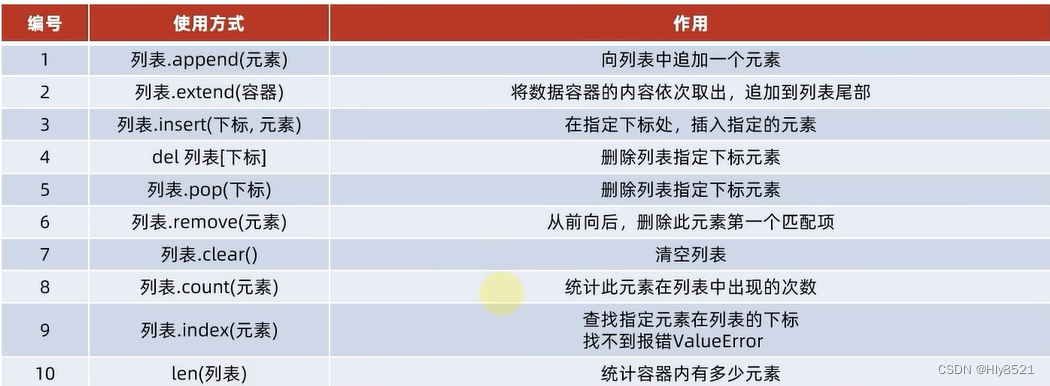
3.列表的常用操作
查询功能:
列表.idex(元素)
修改功能:
列表[下标] = 值
插入功能:
列表.insert(位置,所要插入的数值)
追加元素:
列表.append(元素),将指定元素,追加到列表的尾部
追加一批元素:
列表.extend(列表变量)
删除元素:
del 列表[下标]
列表.pop(下标)作用:将对应下标元素取出然后返回出去
删除某元素在列表中的第一个匹配项:
列表.remove(元素)
清空列表:
列表.clear()
统计列表内某元素的数量:
列表.count(元素)
统计全部元素:
len(列表)
总结:
列表的特点:
可以容纳多个元素
可以容纳不同类型的元素(混装)
数据是有序存储的(有下标序号)
允许重复数据存在
可以修改(增加或删除元素等)
综合案例:
- list1 = [21, 25, 21, 23, 22, 20]
- list1.append(31)
- list1.extend([29, 33, 30])
- del1 = list1.pop(0)
- print(f"取出的元素是{del1}")
- del2 = list1.pop(-1)
- print(f"取出的元素是{del2}")
- find1 = list1.index(31)
- print(f"元素31在列表中的下标位置是{find1}")
- print(list1)
列表的遍历
1.定义
将容器内的元素依次取出,并处理,称之为遍历操作
2.while和for循环遍历
实例:
- def list_while_func():
- list1 = [21, 25, 21, 23, 22, 20]
- index = 0
- while index < len(list1):
- osx = list1[index]
- print(osx)
- index +=1
-
-
- def list_for_func():
- list1 = [21, 25, 21, 23, 22, 20]
- index = 0
- for i in list1:
- print(i)
-
- list_while_func()
- print("-----------------------------------")
- list_for_func()
3.while和for循环对比
for循环更简单,while循环更灵活
for用于从容器内依次取出元素并处理,while用以任何需要循环的场景
小练习:
- def list_while_func():
- list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- new_list = []
- i = 0
- while i < len(list1):
- if list1[i] % 2 == 0:
- new_list.append(list1[i])
- i += 1
- print(f"通过while循环,从列表[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]取出偶数,组成新列表:{new_list}")
-
-
- def list_for_func():
- list1 = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
- new_list = []
- for i in list1:
- if i % 2 == 0:
- new_list.append(i)
- print(f"通过for循环,从列表[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]取出偶数,组成新列表:{new_list}")
-
-
- list_while_func()
- list_for_func()
元组的定义和操作
1.元组定义
# 定义元组字面量
(元素,元素,元素,.............,元素)
# 定义元组变量
变量名称 = (元素,元素,元素,.............,元素)
# 定义空元组
变量名称 = ()
变量名称 = tuple()
注:定一单个元素,元素后面要加“,”号
2.元组的操作
查找:元组.index(元素)
统计某个数据出现次数:元组.count(元素)
统计元组内的元素个数:len(元组)
3.元组的遍历
实例演示:
- t = (2, 3, 4, 5, 1, 7)
- index = 0
- while index < len(t):
- print(t[index])
- index += 1
-
-
- for i in t:
- print(i)
4.注意事项
元组不能被修改
元组内嵌套的列表可以修改
实例:
- t1 = (1, 2, ['java', 'c++'])
- t1[2][1] = "python"
- print(t1)
字符串
1.常用操作
字符串的替换:
字符串.replace(字符串1,字符串2)功能:将字符串内的全部:字符串1替换为字符串2
字符串的分割:
字符串.split(分割符字符串)功能:将字符串划分为多个字符,并存入列表对象中
字符串的规整操作(去前后空格):
字符串.strip()//去除前后空格
字符串.strip(指定字符串) //去除前后指定字符串
字符串的遍历实例:
- my_str = "品牌电脑"
- index = 0
- while index < len(my_str):
- print(my_str[index])
- index += 1
-
- for i in my_str:
- print(i)
2.字符串的特点
只可以存储字符串
长度任意(取决于内存大小)
支持下标索引
允许重复字符串存在
不可以修改(增加或删除元素等)
支持for、while循环
序列
列表、元组、字符串,均可视为序列。
1.序列的操作
切片:
序列[起始:结束:步长]
实例:
- str1 = "为什么最迷人的最危险"
- str2 = str1[:: -1][3: 8]
- print(str2)
集合
1.集合的定义
集合不允许重复元素
# 定义集合字面量
{元素, 元素, ..........,元素}
# 定义集合变量
变量名称 = {元素, 元素, ..........,元素}
# 定义空集合
变量名称 = set()
2.集合的常用操作
修改:
集合是无序的,所以不支持下标索引访问
但是集合和列表一样,是允许修改的
添加新元素:
集合.add(新元素)
移除元素:
集合.remove(旧元素)
随机取出元素:
集合.pop()
清空集合:
集合.clear()
取两个集合的差集:
集合1.difference(集合2),功能:取出集合1和集合2的差集, 有返回值
集合1.difference(集合2),功能:删除集合2中的元素,无返回值
集合合并:
集合1.union(集合2)
3.集合的遍历
只可以用for循环遍历
- for i in set1:
- print(i)
字典
1.定义格式
字典也不能使用下标索引
# 定义字典字面量
{key:value,key:value,.........,key:value}
# 定义字典变量
my_dict = {key:value,key:value,.........,key:value}
# 定义空字典
my_dict = {}
my_dict = dict()
2.字典数据的获取
字典[Key],可以取到对应的Value
3.字典的嵌套
字典可以是任意数据类型(Key不可为字典)
Key不允许重复
- my_dict = {"王力鸿": {"语文": 77, "数学": 66, "英语": 33},
- "周杰轮": {"语文": 88, "数学": 86, "英语": 55},
- "林俊节": {"语文": 99, "数学": 96, "英语": 66}}
- print(my_dict["林俊节"]["语文"])
4.字典的常用操作
新增元素:
字典[Key] = Value
更新元素:
字典[Key] = Value 注意:对已经存在的Key执行以上操作,就是更新Value值
删除元素:
字典.pop(Key)
清空元素:
字典.clear()
获取全部的key:
字典.keys(),结果:得到字典中的全部的Key
遍历字典:
- 方法一:
- my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77}
- keys = my_dict.keys()
- for i in keys:
- print(f"字典的key是:{i}")
- print(f"字典的value是:{my_dict[i]}")
- 方法二:
- my_dict = {"周杰轮": 99, "林俊节": 88, "张学油": 77}
- for key in my_dict:
- print(f"字典的key是:{key}")
- print(f"字典的value是:{my_dict[key]}")
统计字典中多少元素:
变量 = len(字典)
数据容器特点对比
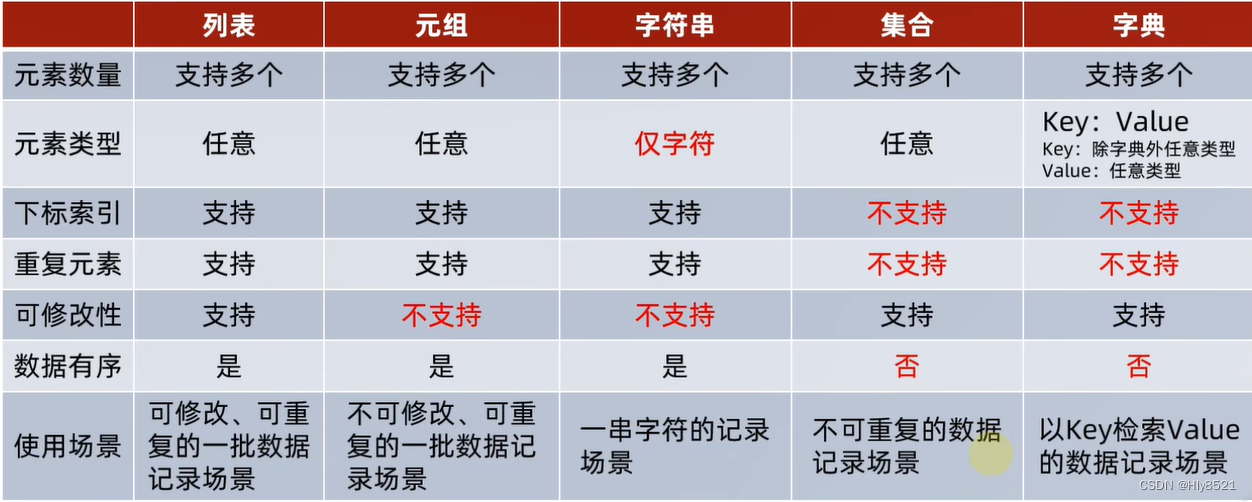
数据容器的通用操作
1.遍历
2.max,min
max(序列或非序列)
min(序列或非序列)
3.容器的转换功能
list(容器) str(容器) tuple(容器) set(容器)
4.排序功能
sorted(容器,[reverse = True])为给定容器进行排序,True倒序,False正序
字符串大小比较方式
1.字符串比较
从头到尾,一位位进行比较,其中一位大,后面就无需比较
2.单个字符比较
通过ASCII码表,确定字符对应的码值来确定大小
第七章——函数进阶
函数的多返回值
1.多个返回值
实例演示:
- def test_return():
- return 1, 2
-
-
- x, y = test_return()
- print(x)
- print(y)
函数的多种传参方式
1.函数参数种类
位置参数:
- def user_info(name, age, gender):
- print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
-
-
- user_info('TOM', 20, '男')
关键字参数:
- def user_info(name, age, gender):
- print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
-
-
- user_info(name='TOM', age=20, gender='男')
缺省参数:
- def user_info(name, age, gender='男'):
- print(f'您的名字是{name}, 年龄是{age}, 性别是{gender}')
-
-
- user_info(name='TOM', age=20)
- user_info('Rose', 18, '女')
不定长参数:
用于不确定调用的时候会传递多少个参数(不传参也可以)的场景。
作用:当调用函数时不确定参数个数时,可以使用不定长参数
不定长参数的类型:
1.位置传递
以元组的形式接收参数,形式参数一般命名为args
- def user_info(*args):
- print(args)
-
-
- user_info('TOM')
- user_info('TOM', 18)
2.关键字传递
以字典的形式接收参数,形式参数一般命名为kwargs
- def user_info(**kwargs):
- print(kwargs)
-
-
- user_info(name='TOM', age=18, id=10)
匿名函数
1.函数作为参数传递
- def test_func(compute):
- result =compute(1, 2)
- print(f"compute参数类型:{type(compute)}")
- print(f"计算结果:{result}")
-
-
- def compute(x, y):
- return x + y
-
-
- test_func(compute)
2.函数传参注意
将函数传入的作用在于:传入计算逻辑,而非传入数据
3.lambda匿名函数
lambda关键字,可以定义匿名函数(无名称)
无名称的匿名函数,只能临时使用一次
匿名函数语法:
lambda 传入参数:函数体(一行代码)
- def test_func(compute):
- result = compute(1, 2)
- print(f"结果是:{result}")
-
-
- test_func(lambda x, y: x + y)
第八章文件操作
文件的读取
1.open()打开函数
open(name, mode, encoding)
name:要打开的目标文件名
mode:设置打开文件的模式:只读、写入、追加等
encoding:编码格式(建议使用UTF-8)
示例代码:f = open('python.txt', 'r' , 'encoding'
2.读操作相关方法
read()方法:
文件对象.read(num)num表示要从文件中读取的数据长度(单位是字节)如果没有传入num,那么就读取全部数据
readlines()方法:
文件对象.readlines()返回的是一个列表,其中每一行为一个元素
fro循环读取文件行:
- f = open("D:/test.txt", "r", encoding="UTF-8")
- for line in f:
- print(line)
关闭文件:
文件对象.close()
with open():
- with open("D:/test.txt", "r", encoding="UTF-8")as f:
- for line in f:
- print(line)
3.文件的写入
案例演示:
# 1.打开文件
f = open('python.txt', 'w')
# 2.文件写入
f.write('hello world')
#3.文件刷新
f.flush()
注意:
直接调用write,内容并问真正写入文件
当调用flush的时候,内容会真正写入文件
实例:
- f = open('D:/test.txt', 'w')
- f.write("hello world")
- f.flush()
- f.close()
4.文件的追加
# 1.打开文件,通过a模式打开即可
f = open('python.txt', 'a')
# 2.文件写入
f.write('hello world')
#3.文件刷新
f.flush()
实例:
- f = open('D:/test.txt', 'a')
- f.write("hello world")
- f.flush()
- f.close()
第九章
异常
1.了解异常
异常是指程序出现错误
2.捕获异常
基本语法:
try:
可能发生错误的代码
except:
如果出现异常执行的代码
实例:
- try:
- f = open("D:/testt.txt", 'r')
- except:
- print("出现异常了,因为文件不存在,我们将open的模式改为w模式去打开")
- f = open("D:/testt.txt", "w")
- f.close()
3.捕获指定异常
实例:
- try:
- print(name)
- except NameError as e:
- print("出现了变量未定义的异常")
- print(e)
4.捕获多个异常
实例:
- try:
- print(1/0)
- except (NameError, ZeroDivisionError):
- print("ZeroDivision错误...")
5.捕获所有异常
实例:
- try:
- print(1/0)
- except Exception as e:
- print(e)
6.异常else(没有异常才会执行)
实例:
- try:
- print(1/1)
- except Exception as e:
- print(e)
- else:
- print("此程序没有异常")
7.异常finally(不管是否有异常,都会执行)
实例:
- try:
- f = open('D:/test.txt', 'r')
- except Exception as e:
- f = open('test.txt', 'w')
- else:
- print("没有异常,很开心")
- finally:
- f.close()
8.异常的传递(特点)
实例:
- def func01():
- print("这是func01开始")
- num = 1 / 0
- print("这是func01结束")
-
-
- def func02():
- print("这是func02开始")
- func01()
- print("这是func02结束")
-
-
- def main():
- try:
- func02()
- except Exception as e:
- print(e)
-
-
- main()
模块
1.了解模块
Python模块,是一个Python文件,以.py结尾,模块能定义函数,类和变量
2.模块导入方式
import 模块名
from 模块名 import 功能名
包
1.包定义
从物理上看,包就是一个文件夹,在该文件夹下包含了一个_init_.py文件,该文件可用于包含多个模块文件,从逻辑上看,包的本质依然是模块
2.包的应用
实例:
from my_package.my_module1 import * from my_package.my_module2 import * info_print1() info_print2()
模块:my_module1
def info_print1():
print("我是模块1的功能函数代码")
my_module2
def info_print2():
print("我是模块2的功能函数代码")
3.第三方包
第三方包安装:
通过官方网址安装
pip install 包名称
通过国内镜像安装
pip install -i http://pypi.tuna.tsinghua.edu.cn/simple 包名称
第十章
JSON数据格式的转换
1.功能定义
json就是一种在各个编程语言中流通的数据格式,负责不同编程语言中的数据传递和交互。类似于:国际通用语言---英语 还有中国---普通话
2.json数据的格式
{“name”:“admin”,“age”:18}
也可以是
[{“name”:“admin”,“age”:18},{“name”:“root”,“age”:16},{“name”:“localhost”,“age”:20}]
3.Python数据和Json数据的相互转化
# 导入json模块
import json
# 准备符合格式json格式要求的python数据
data = [{“name”:“admin”,“age”:18}]
# data = json.dumps(data)//如果有中文数据,data后面要加“,ensure_ascii=False”
实例:
- import json
-
- data = [{"name": "张大山", "age": 11}, {"name": "林俊节", "age": 11}, {"name": "周杰轮", "age": 11}]
- json_str = json.dumps(data, ensure_ascii=False)
- print(type(json_str))
- print(json_str)
# 通过json.loads(data)方法把json数据转化为python数据
实例:
- import json
- s = '[{"name": "张大山", "age": 11}, {"name": "林俊节", "age": 11}, {"name": "周杰轮", "age": 11}]'
- l = json.loads(s)
- print(type(l))
- print(l)
pyecharts模块
1.pyecharts功能
用来做数据可视化效果图
- from pyecharts.charts import Line
- # 生成对象
- line = Line()
- # 定义x,y轴的数据
- line.add_xaxis(["中国", "英国", "美国"])
- line.add_yaxis("GDP", [30, 20, 10])
- # 生成图像
- line.render()
2.配置选项
全局配置项实例:
- from pyecharts.charts import Line
- from pyecharts.options import TitleOpts, LegendOpts, ToolboxOpts, VisualMapOpts
- # 生成对象
- line = Line()
- # 定义x,y轴的数据
- line.add_xaxis(["中国", "英国", "美国"])
- line.add_yaxis("GDP", [30, 20, 10])
- # 设置全局配置项set_global_opts来设置
- line.set_global_opts(
- title_opts=TitleOpts(title="GDP展示", pos_left="center", pos_bottom="1%"),
- legend_opts=LegendOpts(is_show=True),
- toolbox_opts=ToolboxOpts(is_show=True),
- visualmap_opts=VisualMapOpts(is_show=True)
- )
- # 生成图像
- line.render()
3.地图绘制
- from pyecharts.charts import Map
- from pyecharts.options import VisualMapOpts
- # 准备地图对象
- map = Map()
- # 准备数据
- data = [
- ('北京', 99),
- ('上海', 199),
- ('湖南', 299),
- ('台湾', 399),
- ('广东', 499),
- ]
- # 添加数据
- map.add("测试地图", data, "china")
- # 设置全局选项
- map.set_global_opts(
- visualmap_opts=VisualMapOpts(
- is_show=True,
- is_piecewise=True,
- pieces=[
- {"min": 1, "max": 9, "lable": "1-9", "color": "#CCFFFF"},
- {"min": 10, "max": 99, "lable": "10-99", "color": "#FF6666"},
- {"min": 100, "max": 500, "lable": "100-500", "color": "#990033"}
- ]
- )
- )
- # 生成地图
- map.render()
4.基础柱状图绘制
- from pyecharts.charts import Bar
- from pyecharts.options import LabelOpts
- # 使用Bar构建基础柱状图
- bar = Bar()
- # 添加x,y轴数据
- bar.add_xaxis(["中国", "美国", "英国"])
- bar.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 翻转x,y轴
- bar.reversal_axis()
- # 绘图
- bar.render("基础柱状图.html")
5.创建时间线
- from pyecharts.charts import Bar, Timeline
- from pyecharts.options import LabelOpts
- from pyecharts.globals import ThemeType
- # 使用Bar构建基础柱状图
- bar1 = Bar()
- # 添加x,y轴数据
- bar1.add_xaxis(["中国", "美国", "英国"])
- # 设置数值标签在右侧
- bar1.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 翻转x,y轴
- bar1.reversal_axis()
- # 绘图
- # bar1.render("基础柱状图.html")
-
- # 使用Bar构建基础柱状图
- bar2 = Bar()
- # 添加x,y轴数据
- bar2.add_xaxis(["中国", "美国", "英国"])
- # 设置数值标签在右侧
- bar2.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 翻转x,y轴
- bar2.reversal_axis()
- # 绘图
- # bar2.render("基础柱状图.html")
-
- # 使用Bar构建基础柱状图
- bar3 = Bar()
- # 添加x,y轴数据
- bar3.add_xaxis(["中国", "美国", "英国"])
- # 设置数值标签在右侧
- bar3.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 翻转x,y轴
- bar3.reversal_axis()
- # 绘图
- # bar3.render("基础柱状图.html")
-
- # 使用Bar构建基础柱状图
- bar4 = Bar()
- # 添加x,y轴数据
- bar4.add_xaxis(["中国", "美国", "英国"])
- # 设置数值标签在右侧
- bar4.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 翻转x,y轴
- bar4.reversal_axis()
- # 绘图
- # bar4.render("基础柱状图.html")
-
- # 使用Bar构建基础柱状图
- bar5 = Bar()
- # 添加x,y轴数据
- bar5.add_xaxis(["中国", "美国", "英国"])
- # 设置数值标签在右侧
- bar5.add_yaxis("GDP", [30, 20, 10], label_opts=LabelOpts(position="right"))
- # 翻转x,y轴
- bar5.reversal_axis()
- # 绘图
- # bar5.render("基础柱状图.html")
-
- # 构建时间线对象
- timeline = Timeline({"theme": ThemeType.LIGHT})
- # 在时间线添加柱状图对象
- timeline.add(bar1, "点1")
- timeline.add(bar2, "点2")
- timeline.add(bar3, "点3")
- timeline.add(bar4, "点4")
- timeline.add(bar5, "点5")
- # 设置自动播放
- timeline.add_schema(
- play_interval=1000, # 自动播放的时间间隔,单位毫秒
- is_timeline_show=True, # 是否显示时间线
- is_auto_play=True, # 是否自动播放
- is_loop_play=True # 是否循环自动播放
- )
- # 绘图
- timeline.render("基础时间线柱状图.html")
6.列表的sort方法
有名函数:
- my_list = [["a", 33], ["b", 55], ["c", 11]]
-
-
- def choose_sort_key(element):
- return element[1]
-
-
- my_list.sort(key=choose_sort_key, reverse=True)
- print(my_list)
匿名函数:
- my_list = [["a", 33], ["b", 55], ["c", 11]]
- my_list.sort(key=lambda element: element[1], reverse=True)
- print(my_list)
第十一章
类
1.类的定义和对象的创建
类的定义:
class 类名称:
类的属性
类的行为
创建对象:
对象 = 类名称()
成员方法调用成员属性,要self.属性
2.构造方法
def __init__(self, name, age, tel):
self.name = name
self.age = age
self.tel = tel
实例:
- class Student:
- name = None
- age = None
- tel = None
-
- def __init__(self, name, age, tel):
- self.name = name
- self.age = age
- self.tel = tel
- print("Student类创建了一个对象")
-
-
- stu = Student("周杰轮", 31, "1567883247")
构造方法的作用:
1.构建类对象的时候会自动运行
2.构建类对象的传参会传递给构造方法,借此特性可以给成员变量赋值
注意事项:
1.构造方法不要忘记使用self关键字
2.在方法内使用成员变量需要使用self
构造方法实例:
- class Student:
- name = None
- age = None
- ads = None
-
- def __init__(self, name, age, ads):
- self.name = name
- self.ads = ads
- self.age = age
-
-
- for i in range(1, 11):
- print(f"当前录入第{i}位学生信息,总共需要录入10位学生信息")
- na = input("请输入学生姓名:")
- ag = int(input("请输入学生年龄:"))
- ad = input("请输入学生地址:")
- stu = Student(na, ag, ad)
- print(f"学生{i},信息录入完成,信息为:【学生姓名:{na},年龄:{ag},地址:{ad}】")
3.魔法方法
__str__字符串方法:
- class Student:
- def __init__(self, name, age):
- self.name = name
- self.age = age
-
- def __str__(self):
- return f"Studetn类对象,name:{self.name}, age:{self.age}"
-
-
- stu = Student("周杰轮", 31)
- print(stu)
- print(str(stu))
4.__lt__小于符号比较方法
- class Student:
- def __init__(self, name, age):
- self.name = name
- self.age = age
-
- def __lt__(self, other):
- return self.age < other.age
- stu = Student("周杰轮", 31)
- stu2 = Student("马东没", 23)
- print(stu < stu2)
5.__le__小于等于比较符号方法、
- class Student:
- def __init__(self, name, age):
- self.name = name
- self.age = age
-
- # def __str__(self):
- # return f"Studetn类对象,name:{self.name}, age:{self.age}"
- def __le__(self, other):
- return self.age <= other.age
-
- # def __lt__(self, other):
- # return self.age < other.age
- stu = Student("周杰轮", 31)
- stu2 = Student("马东没", 23)
- print(stu >= stu2)
6.__eq__,比较运算符实现方法
- class Student:
- def __init__(self, name, age):
- self.name = name
- self.age = age
-
- def __eq__(self, other):
- return self.age == other.age
-
- stu = Student("周杰轮", 31)
- stu2 = Student("马东没", 31)
- print(stu == stu2)
封装
1.面相对像的三大特性
封装,继承,多态
2.私有成员
私有成员变量:变量名以__开头(2个下划线)
私有成员方法:方法名以__开头(2个下划线)
注意:私有成员不能被类对象使用,但是可以被其他的成员使用
继承
1.单继承语法格式
class 子类(父类):
内容体
2.多继承语法格式
class 子类(父类1,父类2,父类3,........):
内容体
注意:多继承中,如果父类有同名方法或属性,先继承的优先级高于后继承的
3.pass占位符
保证程序语法完整
4.复写以及调用父类成员
方式一:
使用成员变量:父类名.成员变量
使用成员方法:父类名.成员方法(self)
方式二:
使用super()调用父类成员
使用成员变量:super().成员变量
使用成员方法:super().成员方法
注意:
只可以在子类内部调用父类的同名成员,子类的实体类对象调用默认是调用子类复写的
类型注解(在有能力之前别用注解)
1.注解语法
语法1(首选):变量:类型 = 值
语法2:在注释中,# type:类型
2.注意事项(有事没事,别用注解)
类型注解只是提示性的,并非决定性的。数据类型和注解类型无法对应也不会导致错误
3.函数和方法的形参类型注解语法
def 函数方法名(形参名:类型,形参名:类型,.........)
pass
返回值类型注解的符号使用:
def 函数方法名(形参名:类型,形参名:类型,.........) -> 返回值类型
return None
4.Union类型
使用方式:
导包:from typing import Union
使用:Union[类型,......,类型]
多态
1.多态
同一行为,使用不同的对象获得不同的状态。
2.抽象类(接口)
没有具体实现的方法(pass)
数据分析案例
1.需求分析
读取数据 - > 封装数据对象 - > 计算数据对象 - > pyecharts绘图
设计FileReader类 设计数据封装类 对对象进行逻辑运算 以面向对象思想重新认知pyecahrts
2.具体实现
1.新建data_define.py文件
定义 Record类
定义 结构体方法
定义 魔法方法 __str__()
- """
- 数据定义的类
- """
-
-
- class Record:
-
- def __init__(self, data, order_id, money, province):
- self.data = data
- self.order_id = order_id
- self.money = money
- self.province = province
-
- def __str__(self):
- return f"{self.data}, {self.order_id}, {self.money}, {self.province}"
2.新建file_define.py文件
导包:
import json
from data_define import Record
定义抽象类 FileReader
定义抽象方法 read_data()
定义类 TextFileReader(FileReader) 继承父类 FileReader
重写父类方法
定义类 JsonFileReader(FileReader)继承父类 FileReader
重写父类方法
- """
- 和文件相关的类定义
- """
- import json
-
- from data_define import Record
-
-
- # 先定义一个抽象类用来做顶层设计,确定有哪些功能需要实现
- class FileReader:
-
- def read_data(self):
- """读取文件数据,读到的每一条数据都转换为Record对象,将它们都封装到list内返回即可"""
- pass
-
-
- class TextFileReader(FileReader):
-
- def __init__(self, path):
- self.path = path
-
- def read_data(self):
- f = open(self.path, "r", encoding="UTF-8")
- record_list = []
- for line in f.readlines():
- line = line.strip()
- data_list = line.split(",")
- record = Record(data_list[0], data_list[1], int(data_list[2]), data_list[3])
- record_list.append(record)
- f.close()
- return record_list
-
-
- class JsonFileReader(FileReader):
-
- def __init__(self, path):
- self.path = path
-
- def read_data(self):
- f = open(self.path, "r", encoding="UTF-8")
- record_list = []
- for line in f.readlines():
- data_dict = json.loads(line)
- record = Record(data_dict["data"], data_dict["order_id"], int(data_dict["money"]), data_dict["province"])
- record_list.append(record)
- f.close()
- return record_list
-
-
- if __name__ == '__main__':
- text_file_reader = TextFileReader("D:/2011年1月销售数据.txt")
- json_file_reader = JsonFileReader("D:/2011年2月销售数据JSON.txt")
- # json_file_reader.read_data()
- # list1 = text_file_reader.read_data()
- # print(list1)
- list1 = text_file_reader.read_data()
- list2 = json_file_reader.read_data()
- for l in list1:
- print(l)
- for l in list2:
- print(l)
3.新建 mian.py文件
导包:
from file_define import FileReader, TextFileReader, JsonFileReader from data_define import Record from pyecharts.charts import Bar from pyecharts.options import * from pyecharts.globals import ThemeType
通过bar对象实现绘图表
- """
- 面向对象,数据分析案例,主业务逻辑
- 实现步骤:
- 1. 设计一个类,可以完成数据的封装
- 2. 设计一个抽象类,定义文件读取的相关功能,并使用子类实现具体功能
- 3. 读取文件,生产数据对象
- 4. 进行数据需求的逻辑运算(计算每一天的销售额)
- 5. 通过PyEcharts进行图形绘制
- """
-
- from file_define import FileReader, TextFileReader, JsonFileReader
- from data_define import Record
- from pyecharts.charts import Bar
- from pyecharts.options import *
- from pyecharts.globals import ThemeType
-
- text_file_reader = TextFileReader("D:/2011年1月销售数据.txt")
- json_file_reader = JsonFileReader("D:/2011年2月销售数据JSON.txt")
-
- jan_data = text_file_reader.read_data()
- feb_data = json_file_reader.read_data()
-
- all_data = jan_data + feb_data
-
- data_dict = {}
- for record in all_data:
- if record.data in data_dict.keys(): # keys():返回一个字典所有的键
- # 当前日期已有记录,所以和老记录做累加即可
- data_dict[record.data] += record.money
- else:
- data_dict[record.data] = record.money
-
- # print(data_dict)
- bar = Bar(init_opts=InitOpts(theme=ThemeType.LIGHT))
-
- bar.add_xaxis(list(data_dict.keys()))
- bar.add_yaxis("销售额", list(data_dict.values()), label_opts=LabelOpts(is_show=False)) # 返回一个字典所有的值
- bar.set_global_opts(
- title_opts=TitleOpts(title="每日销售额")
- )
- bar.render("每日销售额柱状图.html")
Sql
语法特征
1.特征
1.大小写不敏感
2.sql可以单行或多行书写,最后以;号结束
2.sql支持注释
单行注释:-- 注释内容
单行注释:# 后面可以不加空格,推荐加上
多行注释:/* 注释内容*/
sql-DDL(定义)
1.查看数据库
show databases
2.使用数据库
use 数据库名
3.创建数据库
create database
4.删除数据库
drop database 数据库名
5.查看当前使用的数据库
select database();
sql-DML(操作)
1.数据插入insert
insert into 表
2.数据删除delete
delete from 表名称
where 判断条件
3.结果排序
select 列 | 聚合函数 | * from 表
where ...
group by ...
order by ... asc | desc
4.limit
select * from student limit 10,5;//前十条跳过,从第11条开始选取5条
5.python操作数据库
导包:
from pymysql import Connection
创建连接:
- conn = Connection(
-
- host="localhost",
-
- port=3306,
-
- user="root",
-
- password1=“123456”
-
- autocommit=True # 设置自动提交
-
- )
测试连接:
print(conn.get_server_info())
创建游标:
cursor = conn.cursor()
选择连接数据库:
conn.select_db("mysql")
执行sql语句:
cursor.execute("create table teacher(id int)")
关闭数据库:
conn.close()
提交更改:
conn.commit()
- 类型:字典。_python绩点计算python绩点计算绩点计算类型:字典描述平均绩点计算方法:(课程学分1绩点+课程学分2绩点+…+课程学分n*绩点)/(课程学分1+课程学分2+…+课程学分n)用户循环输入五分制成绩和课程学分,题目测试数据... [详细]
赞
踩
- 用tkinter做前端,通过qrcode模块,做出了一个根据网页生成二维码的小程序【Python】生成二维码创建了一个使用python创建二维码的程序。下面是生成的程序的图像。功能描述输入网址(URL)。输入二维码的名称。当单击QR码生成按... [详细]
赞
踩
- VScode中Python代码不高亮显示怎么办?_vscode的python语法不高亮vscode的python语法不高亮最近在用VScode写代码的时候,发现Python代码不高亮显示:这样用起来体验感不好,网上查询资料,可能存在的原因为... [详细]
赞
踩
- 本项目包括四个核心部分:数据爬取、数据存储、数据分析和数据可视化。首先,利用Python编写的网络爬虫从专业的历史天气网站上爬取大连市从2011年至2023年的天气数据,包括日期、最高气温、最低气温和天气状况等信息。爬取过程中应用了requ... [详细]
赞
踩
- 探索Python函数的核心概念,从基础的函数定义和调用到高阶函数和装饰器。为初学者提供了详尽的指导和实用示例,让你更深入地理解Python的强大功能。【Python零基础入门】函数【Python零基础入门】第五课函数【Python零基础入门... [详细]
赞
踩
- sort()可以对列表进行「排序」_pythonsort函数pythonsort函数「作者主页」:士别三日wyx「作者简介」:CSDNtop100、阿里云博客专家、华为云享专家、网络安全领域优质创作者「推荐专栏」:小白零基础《Python入... [详细]
赞
踩
- 开门,意味着门的两个门板没有连通,对于外界是敞开的,对应“开”;而闭门,意味着门的两个门板连通到了一起,对于外界是关闭的状态,对应“闭”。_开运算开运算目录概要:正文部分:概念介绍: 何谓“开”与“闭”:如何实现开运算与闭运算:应... [详细]
赞
踩
- DES(DataEncryptionStandard)是一种对称加密算法。本文详细解释DES的算法原理,以及不安全的原因。附Python的实现源码。_des原理des原理文章目录1、什么是DES2、DES的基本概念3、DES的加密流程4、D... [详细]
赞
踩
- 因为课程需要,第一次这么彻底地接触numpy。虽闻名已久,但是真正使用numpy才感受到它的强大,发现它尤其适合数据分析与处理。这里根据自己的使用经验简单总结一下numpy在矩阵运算中的应用,之后也会根据自己的实践经历不断更新。_pytho... [详细]
赞
踩
- 在Python中,我们常常会遇到需要将运行结果以CSV格式导出以供其他语言或工具使用的情况。本文将介绍如何使用Python将结果导出为CSV格式的两种主要方法。_python导出csv文件python导出csv文件在Python中,我们常常... [详细]
赞
踩
- 当直接运行包的时侯(pythonwm),wm不是作为一包来运行,因此包的路径wm没有被加入sys.path路径中。在__ini__.py中定义一个main()函数,在__main__.py中调用它,实现入口,最后调用了wm.main()函数... [详细]
赞
踩
- 但是,有时候会出现550错误,表示所请求的文件不可访问。在该代码中,我们首先连接FTP服务器,然后使用nlst()方法列出当前目录下的文件列表,再判断所请求的文件是否在列表中。如果文件存在,则输出“文件存在”,否则输出“文件不存在”。以上是... [详细]
赞
踩
- selenium添加带有账密的socks5代理我们都知道在使用selenium开发爬虫的时候不可避免的会使用socks5高匿名代理。,当然这是本地自己搭的socks5代理,不需要账号密码就可以使用,但是如果我们搞了一台服务器在上面搭建了so... [详细]
赞
踩
 《滑雪大冒险》是一款充满趣味性和挑战性的休闲竞技游戏,在游戏中,玩家将扮演一位勇敢的滑雪者,在雪山上展示他们的滑雪技巧,游戏采用2D图形界面,以第第三人称视角呈现_滑雪大冒险代码python滑雪大冒险代码python滑雪大冒险《滑雪大冒险》... [详细]
《滑雪大冒险》是一款充满趣味性和挑战性的休闲竞技游戏,在游戏中,玩家将扮演一位勇敢的滑雪者,在雪山上展示他们的滑雪技巧,游戏采用2D图形界面,以第第三人称视角呈现_滑雪大冒险代码python滑雪大冒险代码python滑雪大冒险《滑雪大冒险》... [详细]赞
踩
- PythonSelenium自动化PythonSelenium自动化的笔记1.常用的一些第三方库importsocketimportsysfromseleniumimportwebdriverfromselenium.webdriver.c... [详细]
赞
踩
- 在方法update()中,我们添加了一个if代码块而不是elif代码块,这样如果玩家同时按下了左右箭头键,将先增大飞船的rect.centerx值,再降低这个值,即飞船的位置保持不变。在处,我们修改了游戏在玩家按下右箭头键时响应的方式:不... [详细]
赞
踩
- article
已解决WARNING: pip is configured with locations that require TLS/SSL, however the ssl module in Python
已解决(pip升级报错)WARNING:pipisconfiguredwithlocationsthatrequireTLS/SSL,howeverthesslmoduleinPythonisnotavailable.Lookinginin... [详细]赞
踩
- 本文章利用Python实现一个简单的功能较为完善的区块链系统(包括区块链结构、账户、钱包、转账),采用的共识机制是POW。_python区块链python区块链本文章利用Python实现一个简单的功能较为完善的区块链系统(包括区块链结构、账... [详细]
赞
踩
- Tkinter是Python的标准GUI库,也是最常用的PythonGUI库之一,提供了丰富的组件和功能,包括窗口、按钮、标签、文本框、列表框、滚动条、画布、菜单等,方便开发者进行图形界面的开发。Tkinter库基于TkforUnix/Wi... [详细]
赞
踩
- article
Python flask跨域支持(Access-Control-Allow-Origin(CORS)跨域资源共享(访问控制允许来源:允许指定的来源进行跨域请求)浏览器同源策略、OPTIONS预检请求_flask cors
此外,还可以使用CORS(跨域资源共享)机制来明确指定允许跨域请求的规则,以减少潜在的安全风险。要检测一个Flask接口是否支持跨域请求,可以使用浏览器的开发者工具来查看请求和响应的相关信息。,那么只有GET请求会进入到对应的视图函数中,而... [详细]赞
踩

