
- 1程序员如何赚到自己人生中的第一桶金?是100万还会是1000万,大家不妨一起探讨一下!...
- 2区块链钱包分类及BIP协议
- 3ubuntu 20.04 WIFI适配器找不到问题_ubuntu20.04无wifi adapter
- 4怎样利用PowerBulider的Datawindow建立中国式的动态报表_powerbuilder datawindow 图表
- 5【Kubernetes 系列】 一文带你吃透 K8S 中Pod 的生命周期_简述下k8s pod 生命周期
- 6Python之Selenium知识总结_python selenium
- 7Spring boot 自定义banner的在线制作
- 8人工智能之配置环境教程二:在Anaconda中创建虚拟环境安装GPU版本的Pytorch及torchvision并在VsCode中使用虚拟环境_conda下载torchvision
- 9python文件操作_python 文件操作
- 10一文解读,网络安全行业人才需求情况《网络安全产业人才发展报告》_网络安全人才需求分析
自学大语言模型的应用程序框架Langchain(初入门)_langchain应用框架
赞
踩
目录
现阶段chatGPT非常火热。带动了第三方开源库:LangChain火热。它是一个在大语言模型基础上实现联网搜索并给出回答、总结 PDF 文档、基于某个 Youtube 视频进行问答等等的功能的应用程序。
什么是Langchain
LangChain 是一个用于开发由语言模型驱动的应用程序的框架。
langchain的目标:最强大和差异化的应用程序不仅会通过 API 调用语言模型,它主要拥有 2 个能力:
- Be data-aware:将语言模型连接到其他数据源
- Be agentic:允许语言模型与其环境交互
使用语言模型是迈出的重要第一步。通常,在应用程序中使用语言模型时,你并不会直接将用户输入发送给语言模型。相反,你可能会将用户输入组合成一个提示,并将该提示发送给语言模型。
例如,在前面的例子中,我们传递的文本是硬编码的,要求输入一个制造彩色袜子的公司的名称。在这个想象中的服务中,我们希望只使用用户提供的关于公司业务的描述,然后用这些信息来构建提示。
这在LangChain中非常容易实现!
LLM 模型:Large Language Model,大型语言模型
LangChain 中的链由链接组成,链接可以是像 LLM 这样的原始链,也可以是其他链。最核心的链类型是 LLMChain,它由 PromptTemplate 和 LLM 组成。
基础功能
LLM 调用
- 支持多种模型接口,比如 OpenAI、HuggingFace、AzureOpenAI …
- Fake LLM,用于测试
- 缓存的支持,比如 in-mem(内存)、SQLite、Redis、SQL
- 用量记录
- 支持流模式(就是一个字一个字的返回,类似打字效果)
Prompt管理,支持各种自定义模板
- 拥有大量的文档加载器,比如 Email、Markdown、PDF、Youtube …
- 对索引的支持
- 文档分割器
- 向量化
- 对接向量存储与搜索,比如 Chroma、Pinecone、Qdrand
Chains
LLMChain
各种工具Chain
LangChainHub
基本概念
Loader 加载器
这个就是从指定数据源中进行加载数据的。比如:文件夹 DirectoryLoader、Azure 存储 AzureBlobStorageContainerLoader、CSV文件 CSVLoader、印象笔记 EverNoteLoader、Google网盘 GoogleDriveLoader、任意的网页 UnstructuredHTMLLoader、PDF PyPDFLoader、 S3DirectoryLoader/S3FileLoader、
Youtube YoutubeLoader 等等,上面只是简单的进行列举了几个,官方提供了超级的多的加载器供你使用。
Document 文档
当使用loader加载器读取到数据源后,数据源需要转换成 Document 对象后,后续才能进行使用。
Text Spltters 文本分割
用来分割文本的,因为每次不管是做把文本当作 prompt 发给 openai api ,还是还是使用 openai api embedding 功能都是有字符限制的。
Vectorstores 向量数据库
因为数据相关性搜索其实是向量运算。所以,不管我们是使用 openai api embedding 功能还是直接通过向量数据库直接查询,都需要将我们的加载进来的数据 Document 进行向量化,才能进行向量运算搜索。转换成向量也很简单,只需要我们把数据存储到对应的向量数据库中即可完成向量的转换。
Chain 链
一个 Chain 就是一个任务,当然也可以像链条一样,一个一个的执行多个链。个人感觉像是计算机的线程。
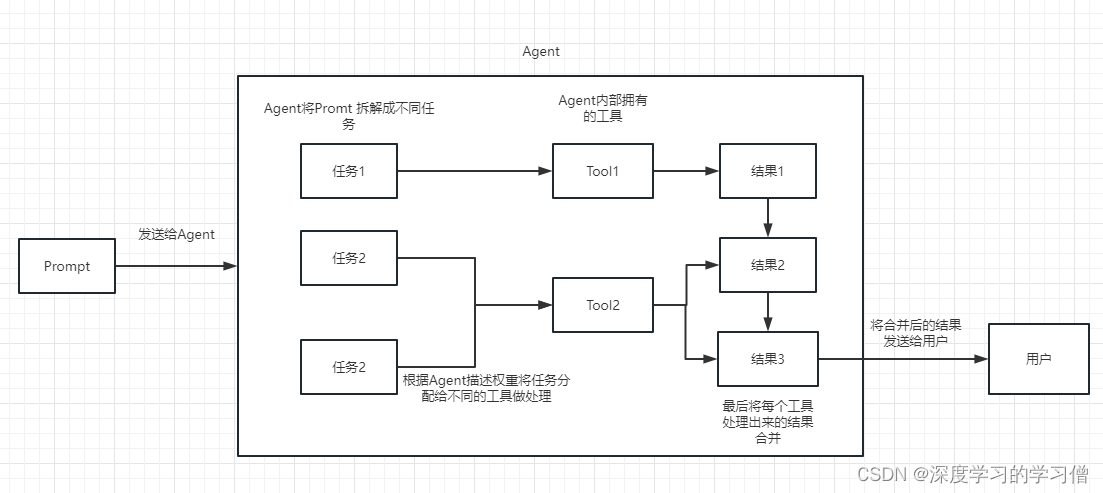
Agent 代理
可以简单的理解为他可以动态的帮我们选择和调用chain或者已有的工具。
执行过程可以参考下面这张图:
Embedding
用于衡量文本的相关性。这个也是 OpenAI API 能实现构建自己知识库的关键所在。
他相比 fine-tuning 最大的优势就是,不用进行训练,并且可以实时添加新的内容,而不用加一次新的内容就训练一次,并且各方面成本要比 fine-tuning 低很多。
入门指南
安装
- pip install langchain
- # or
- conda install langchain -c conda-forge
简单问答
- from langchain.llms import OpenAI
-
- llm = OpenAI(model_name="text-davinci-003",max_tokens=1024)
- llm("怎么评价人工智能")
\n\n人工智能是一个极具潜力的领域,它在推动着未来科技发展和社会进步。人工智能已经取得了一定的成就,但仍有很多需要改进的地方,其中包括提高技术的精确度和可靠性,提升人工智能的难度和复杂度,以及更好地理解人类的行为和心理。这些都将需要更多的研究和实践,才能实现人工智能的最终目标。’
Chains:在多步骤工作流程中结合 LLM 和 PromptTemplate
- from langchain.prompts import PromptTemplate
- from langchain.llms import OpenAI
-
- llm = OpenAI(temperature=0.9)
- prompt = PromptTemplate(
- input_variables=["product"],
- template="What is a good name for a company that makes {product}?",
- )
代理(Agents):基于用户输入的动态调用链
Agents使用 LLM 来确定采取哪些行动以及采取何种顺序。动作可以是使用工具并观察其输出,也可以是返回给用户。
在这里将展示如何通过最简单、最高级别的 API 轻松使用代理。
为了加载代理程序,您应该了解以下概念:
工具(Tool):执行特定任务的函数。这可以是谷歌搜索、数据库查询、Python REPL或其他链条。工具的接口目前是一个期望输入为字符串、输出为字符串的函数。
LLM(语言模型):为代理程序提供支持的语言模型。
代理程序(Agent):某些应用程序不仅需要预先确定的对 LLM/其他工具的调用链,还可能需要依赖于用户输入的未知链。在这些类型的链中,有一个“代理”可以访问一套工具。根据用户输入,代理可以决定调用这些工具中的哪一个。目前,主要有两种类型的代理:
行动代理人:这些代理人决定采取行动并一次采取该行动
“计划和执行代理”:这些代理首先决定要采取的行动计划,然后一次执行这些行动。
- pip install google-search-results
-
- import os
- os.environ["SERPAPI_API_KEY"] = "..."
- from langchain.agents import load_tools
- from langchain.agents import initialize_agent
- from langchain.agents import AgentType
- from langchain.llms import OpenAI
-
- # 首先,让我们加载我们将用于控制代理程序的语言模型。
- llm = OpenAI(temperature=0)
-
- # 接下来,让我们加载一些要使用的工具。请注意,llm-math 工具使用了一个语言模型,所以我们需要传入该模型作为参数。
- tools = load_tools(["serpapi", "llm-math"], llm=llm)
-
-
- # 最后,让我们使用这些工具、语言模型和我们想要使用的代理类型来初始化一个代理
- agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
-
- # Now let's test it out!
- agent.run("What was the high temperature in SF yesterday in Fahrenheit? What is that number raised to the .023 power?")

Memory:将状态添加到链和代理中
为了让链或代理具有某种“记忆”概念,以便它可以记住有关其先前交互的信息。最清晰和简单的例子是在设计聊天机器人时——您希望它记住以前的消息,以便它可以使用来自该消息的上下文来进行更好的对话。这将是一种“短期记忆”。在更复杂的方面,你可以想象一个链/代理随着时间的推移记住关键信息——这将是一种“长期记忆”。有关后者的更具体想法,可以参阅MemPrompt: Memory-assisted Prompt Editing with User Feedback
论文的核心思想:
比如对于 GPT-3 将 “similar to” 理解为“发音相似”,而用户想要的是“意思相似”,于是用户可以将 “similar to means with similar meaning” 的反馈记录到 memory M 中,之后遇到类似的问题时,模型能够正确处理
memory M 是一个维护的键值对数据:key 是误解的问题;value 是用户修正该问题的反馈
遇到新问题时,在 memory M 中查询是否有类似的问题,找到了的话,将该问题的用户反馈加到 prompt 中
本文 contribution
展示了像GPT-3这样的大型模型可以在部署后得到改进,而不需要重新训练,通过内存辅助架构
实现 MemPrompt 是第一次证明这是可能的——这是真正使用 LMs 的重要一步,本文列出了其他人可以在此基础上构建的通用体系结构、特定的实现以及对多个任务的详细评估。
对于论文内容在百度或者CSDN上搜索也有中文版的翻译。
LangChain 为此提供了几个专门创建的链。本文介绍了如何使用这些链中的一个 (the ConversationChain) 和两种不同类型的内存。
默认情况下,ConversationChain有一种简单类型的内存,可以记住所有以前的输入/输出并将它们添加到传递的上下文中。让我们来看看使用这个链(设置verbose=True以便我们可以看到提示)。
- from langchain import OpenAI, ConversationChain
-
- llm = OpenAI(temperature=0)
- conversation = ConversationChain(llm=llm, verbose=True)
-
- output = conversation.predict(input="Hi there!")
- print(output)
–> Entering new chain…
Prompt after formatting:
The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
Current conversation:
Human: Hi there!
AI:
–> Finished chain.
’ Hello! How are you today?’
- output = conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
- print(output)
-
- > Entering new chain...
- Prompt after formatting:
- The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know.
-
- Current conversation:
-
- Human: Hi there!
- AI: Hello! How are you today?
- Human: I'm doing well! Just having a conversation with an AI.
- AI:
- > Finished chain.
- " That's great! What would you like to talk about?"
构建语言模型应用程序:聊天模型
聊天模型是语言模型的变体。虽然聊天模型在底层使用语言模型,但它们公开的接口有点不同:它们公开的不是“文本输入、文本输出”API,而是“聊天消息”作为输入和输出的接口。
从聊天模型中获取消息补全
您可以通过将一条或多条消息传递给聊天模型来获得聊天完成。响应将是一条消息。LangChain 目前支持的消息类型有AIMessage, HumanMessage, SystemMessage, 和ChatMessage–ChatMessage接受任意角色参数。大多数时候,您只会处理HumanMessage、AIMessage和SystemMessage。
- from langchain.chat_models import ChatOpenAI
- from langchain.schema import (
- AIMessage,
- HumanMessage,
- SystemMessage
- )
-
- chat = ChatOpenAI(temperature=0)
通过传递一条消息来完成。
chat([HumanMessage(content=“Translate this sentence from English to French. I love programming.”)])
# -> AIMessage(content=“J’aime programmer.”, additional_kwargs={})
还可以为 OpenAI 的 gpt-3.5-turbo 和 gpt-4 模型传入多条消息。
messages = [
SystemMessage(content=“You are a helpful assistant that translates English to French.”),
HumanMessage(content=“I love programming.”)
]
chat(messages)
# -> AIMessage(content=“J’aime programmer.”, additional_kwargs={})
更进一步,使用 为多组消息生成补全generate。这将返回LLMResult带有附加message参数的
batch_messages = [
[
SystemMessage(content=“You are a helpful assistant that translates English to French.”),
HumanMessage(content=“I love programming.”)
],
[
SystemMessage(content=“You are a helpful assistant that translates English to French.”),
HumanMessage(content=“I love artificial intelligence.”)
],
]
result = chat.generate(batch_messages)
result
# -> LLMResult(generations=[[ChatGeneration(text=“J’aime programmer.”, generation_info=None, message=AIMessage(content=“J’aime programmer.”, additional_kwargs={}))], [ChatGeneration(text=“J’aime l’intelligence artificielle.”, generation_info=None, message=AIMessage(content=“J’aime l’intelligence artificielle.”, additional_kwargs={}))]], llm_output={‘token_usage’: {‘prompt_tokens’: 57, ‘completion_tokens’: 20, ‘total_tokens’: 77}})
聊天提示模板
与LLM类似,你可以使用MessagePromptTemplate来使用模板化。你可以通过一个或多个MessagePromptTemplate构建ChatPromptTemplate。你可以使用ChatPromptTemplate的format_prompt方法,它返回一个PromptValue,你可以将其转换为字符串或Message对象,具体取决于你是想将格式化后的值用作LLM还是Chat模型的输入。实现标准化或者格式化的消息中获取聊天完成
- from langchain.chat_models import ChatOpenAI
- from langchain.prompts.chat import (
- ChatPromptTemplate,
- SystemMessagePromptTemplate,
- HumanMessagePromptTemplate,
- )
-
- chat = ChatOpenAI(temperature=0)
-
- template = "You are a helpful assistant that translates {input_language} to {output_language}."
- system_message_prompt = SystemMessagePromptTemplate.from_template(template)
- human_template = "{text}"
- human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
-
- chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
-
- # 从格式化的消息中获取聊天完成。
- chat(chat_prompt.format_prompt(input_language="English", output_language="French", text="I love programming.").to_messages())
- # -> AIMessage(content="J'aime programmer.", additional_kwargs={})
在聊天模型中加入链
- from langchain.chat_models import ChatOpenAI
- from langchain import LLMChain
- from langchain.prompts.chat import (
- ChatPromptTemplate,
- SystemMessagePromptTemplate,
- HumanMessagePromptTemplate,
- )
-
- chat = ChatOpenAI(temperature=0)
-
- template = "You are a helpful assistant that translates {input_language} to {output_language}."
- system_message_prompt = SystemMessagePromptTemplate.from_template(template)
- human_template = "{text}"
- human_message_prompt = HumanMessagePromptTemplate.from_template(human_template)
- chat_prompt = ChatPromptTemplate.from_messages([system_message_prompt, human_message_prompt])
-
- chain = LLMChain(llm=chat, prompt=chat_prompt)
- chain.run(input_language="English", output_language="French", text="I love programming.")
- # -> "J'aime programmer."
在聊天模型中加入代理
初始化一个AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION作为代理类型,实现代理与聊天模型一起使用。
- from langchain.agents import load_tools
- from langchain.agents import initialize_agent
- from langchain.agents import AgentType
- from langchain.chat_models import ChatOpenAI
- from langchain.llms import OpenAI
-
- # 首先,让我们加载我们将用于控制代理的语言模型.
- chat = ChatOpenAI(temperature=0)
-
- # 接下来,让我们加载一些要使用的工具。请注意,llm-math 工具使用了一个 LLM,所以我们需要传入它。
- llm = OpenAI(temperature=0)
- tools = load_tools(["serpapi", "llm-math"], llm=llm)
-
-
- # 最后,让我们使用这些工具、语言模型和我们想要使用的代理类型来初始化一个代理。
- agent = initialize_agent(tools, chat, agent=AgentType.CHAT_ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
-
- # 运行得到测试结果
- agent.run("Who is Olivia Wilde's boyfriend? What is his current age raised to the 0.23 power?")
自定义agent中所使用的工具
自定义工具里面有个比较有意思的地方,使用哪个工具的权重是靠 工具中描述内容 来实现的,和我们之前编程靠数值来控制权重完全不同。
- from langchain.agents import initialize_agent, Tool
- from langchain.agents import AgentType
- from langchain.tools import BaseTool
- from langchain.llms import OpenAI
- from langchain import LLMMathChain, SerpAPIWrapper
-
- llm = OpenAI(temperature=0)
-
- # 初始化搜索链和计算链
- search = SerpAPIWrapper()
- llm_math_chain = LLMMathChain(llm=llm, verbose=True)
-
- # 创建一个功能列表,指明这个 agent 里面都有哪些可用工具,agent 执行过程可以看必知概念里的 Agent 那张图
- tools = [
- Tool(
- name = "Search",
- func=search.run,
- description="useful for when you need to answer questions about current events"
- ),
- Tool(
- name="Calculator",
- func=llm_math_chain.run,
- description="useful for when you need to answer questions about math"
- )
- ]
-
- # 初始化 agent
- agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
-
- # 执行 agent
- agent.run("Who is Leo DiCaprio's girlfriend? What is her current age raised to the 0.43 power?")
-
Memory: 将状态添加到链和代理中
- from langchain.prompts import (
- ChatPromptTemplate,
- MessagesPlaceholder,
- SystemMessagePromptTemplate,
- HumanMessagePromptTemplate
- )
- from langchain.chains import ConversationChain
- from langchain.chat_models import ChatOpenAI
- from langchain.memory import ConversationBufferMemory
-
- prompt = ChatPromptTemplate.from_messages([
- SystemMessagePromptTemplate.from_template("The following is a friendly conversation between a human and an AI. The AI is talkative and provides lots of specific details from its context. If the AI does not know the answer to a question, it truthfully says it does not know."),
- MessagesPlaceholder(variable_name="history"),
- HumanMessagePromptTemplate.from_template("{input}")
- ])
-
- llm = ChatOpenAI(temperature=0)
- memory = ConversationBufferMemory(return_messages=True)
- conversation = ConversationChain(memory=memory, prompt=prompt, llm=llm)
-
- conversation.predict(input="Hi there!")
- # -> 'Hello! How can I assist you today?'
-
-
- conversation.predict(input="I'm doing well! Just having a conversation with an AI.")
- # -> "That sounds like fun! I'm happy to chat with you. Is there anything specific you'd like to talk about?"
-
- conversation.predict(input="Tell me about yourself.")
- # -> "Sure! I am an AI language model created by OpenAI. I was trained on a large dataset of text from the internet, which allows me to understand and generate human-like language. I can answer questions, provide information, and even have conversations like this one. Is there anything else you'd like to know about me?"
执行多个chain
因为他是链式的,所以他也可以按顺序依次去执行多个 chain
- from langchain.llms import OpenAI
- from langchain.chains import LLMChain
- from langchain.prompts import PromptTemplate
- from langchain.chains import SimpleSequentialChain
-
- # location 链
- llm = OpenAI(temperature=1)
- template = """Your job is to come up with a classic dish from the area that the users suggests.
- % USER LOCATION
- {user_location}
- YOUR RESPONSE:
- """
- prompt_template = PromptTemplate(input_variables=["user_location"], template=template)
- location_chain = LLMChain(llm=llm, prompt=prompt_template)
-
- # meal 链
- template = """Given a meal, give a short and simple recipe on how to make that dish at home.
- % MEAL
- {user_meal}
- YOUR RESPONSE:
- """
- prompt_template = PromptTemplate(input_variables=["user_meal"], template=template)
- meal_chain = LLMChain(llm=llm, prompt=prompt_template)
-
- # 通过 SimpleSequentialChain 串联起来,第一个答案会被替换第二个中的user_meal,然后再进行询问
- overall_chain = SimpleSequentialChain(chains=[location_chain, meal_chain], verbose=True)
- review = overall_chain.run("Rome")
通过 Google 搜索并返回答案
目标:让 OpenAI api实现联网搜索,并返回答案给我们。
方法是借助 Serpapi 来进行实现,Serpapi 提供了 google 搜索的 api 接口。
- import os
- os.environ["OPENAI_API_KEY"] = '你的api key'
- os.environ["SERPAPI_API_KEY"] = '你的api key'
在agents 代码文件中提供了load_tools类方法
- from langchain.agents import load_tools
- from langchain.agents import initialize_agent
- from langchain.llms import OpenAI
- from langchain.agents import AgentType
-
- # 加载 OpenAI 模型
- llm = OpenAI(temperature=0,max_tokens=2048)
-
- # 加载 serpapi 工具
- tools = load_tools(["serpapi"])
-
- # 如果搜索完想在计算一下可以这么写
- # tools = load_tools(['serpapi', 'llm-math'], llm=llm)
-
- # 如果搜索完想再让他再用python的print做点简单的计算,可以这样写
- # tools=load_tools(["serpapi","python_repl"])
-
- # 工具加载后都需要初始化,verbose 参数为 True,会打印全部的执行详情
- agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)
-
- # 运行 agent
- agent.run("What's the date today? What great events have taken place today in history?")
-
构建本地知识库问答机器人
如何从我们本地读取多个文档构建知识库,并且使用 Openai API 在知识库中进行搜索并给出答案。比如可以很方便的做一个可以介绍公司业务的机器人,或是介绍一个产品的机器人。
- from langchain.embeddings.openai import OpenAIEmbeddings
- from langchain.vectorstores import Chroma
- from langchain.text_splitter import CharacterTextSplitter
- from langchain import OpenAI,VectorDBQA
- from langchain.document_loaders import DirectoryLoader
- from langchain.chains import RetrievalQA
-
- # 加载文件夹中的所有txt类型的文件
- loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
- # 将数据转成 document 对象,每个文件会作为一个 document
- documents = loader.load()
-
- # 初始化加载器
- text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
- # 切割加载的 document
- split_docs = text_splitter.split_documents(documents)
-
- # 初始化 openai 的 embeddings 对象
- embeddings = OpenAIEmbeddings()
- # 将 document 通过 openai 的 embeddings 对象计算 embedding 向量信息并临时存入 Chroma 向量数据库,用于后续匹配查询
- docsearch = Chroma.from_documents(split_docs, embeddings)
-
- # 创建问答对象
- qa = VectorDBQA.from_chain_type(llm=OpenAI(), chain_type="stuff", vectorstore=docsearch,return_source_documents=True)
- # 进行问答
- result = qa({"query": "今年中国第一季度GDP是多少?"})
- print(result)
构建向量索引数据库
上个案例里面有一步是将 document 信息转换成向量信息和embeddings的信息并临时存入 Chroma 数据库。
因为是临时存入,所以当我们上面的代码执行完成后,上面的向量化后的数据将会丢失。如果想下次使用,那么就还需要再计算一次embeddings,这肯定不是我们想要的。
那么,这个案例我们就来通过 Chroma 和 Pinecone 这两个数据库来讲一下如何做向量数据持久化。
Chroma
chroma 是个本地的向量数据库,他提供的一个 persist_directory 来设置持久化目录进行持久化。读取时,只需要调取 from_document 方法加载即可。
- from langchain.vectorstores import Chroma
-
- # 持久化数据
- docsearch = Chroma.from_documents(documents, embeddings, persist_directory="D:/vector_store")
- docsearch.persist()
-
- # 加载数据
- docsearch = Chroma(persist_directory="D:/vector_store", embedding_function=embeddings)
-
Pinecone
Pinecone 是一个在线的向量数据库。所以,我可以第一步依旧是注册,然后拿到对应的 api key。https://app.pinecone.io/
免费版如果索引14天不使用会被自动清除。
持久化数据和加载数据代码如下
- # 持久化数据
- docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
-
- # 加载数据
- docsearch = Pinecone.from_existing_index(index_name, embeddings)
- from langchain.text_splitter import CharacterTextSplitter
- from langchain.document_loaders import DirectoryLoader
- from langchain.vectorstores import Chroma, Pinecone
- from langchain.embeddings.openai import OpenAIEmbeddings
- from langchain.llms import OpenAI
- from langchain.chains.question_answering import load_qa_chain
-
- import pinecone
-
- # 初始化 pinecone
- pinecone.init(
- api_key="你的api key",
- environment="你的Environment"
- )
-
- loader = DirectoryLoader('/content/sample_data/data/', glob='**/*.txt')
- # 将数据转成 document 对象,每个文件会作为一个 document
- documents = loader.load()
-
- # 初始化加载器
- text_splitter = CharacterTextSplitter(chunk_size=500, chunk_overlap=0)
- # 切割加载的 document
- split_docs = text_splitter.split_documents(documents)
-
- index_name="liaokong-test"
-
- # 持久化数据
- # docsearch = Pinecone.from_texts([t.page_content for t in split_docs], embeddings, index_name=index_name)
-
- # 加载数据
- docsearch = Pinecone.from_existing_index(index_name,embeddings)
-
- query = "今年中国第一季度GDP是多少?"
- docs = docsearch.similarity_search(query, include_metadata=True)
-
- llm = OpenAI(temperature=0)
- chain = load_qa_chain(llm, chain_type="stuff", verbose=True)
- chain.run(input_documents=docs, question=query)
使用 HuggingFace 模型
- #设置环境变量
- import os
- os.environ['HUGGINGFACEHUB_API_TOKEN'] = ''
-
- #使用在线的 HuggingFace 模型
- from langchain import PromptTemplate, HuggingFaceHub, LLMChain
-
- template = """Question: {question}
- Answer: Let's think step by step."""
-
- prompt = PromptTemplate(template=template, input_variables=["question"])
- llm = HuggingFaceHub(repo_id="google/flan-t5-xl", model_kwargs={"temperature":0, "max_length":64})
- llm_chain = LLMChain(prompt=prompt, llm=llm)
-
- question = "What NFL team won the Super Bowl in the year Justin Beiber was born?"
- print(llm_chain.run(question))
-
- #将 HuggingFace 模型直接拉到本地使用
- from langchain.llms import HuggingFacePipeline
- from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoModelForSeq2SeqLM
-
- model_id = 'google/flan-t5-large'
- tokenizer = AutoTokenizer.from_pretrained(model_id)
- model = AutoModelForSeq2SeqLM.from_pretrained(model_id, load_in_8bit=True)
-
- pipe = pipeline(
- "text2text-generation",
- model=model,
- tokenizer=tokenizer,
- max_length=100
- )
-
- local_llm = HuggingFacePipeline(pipeline=pipe)
- print(local_llm('What is the capital of France? '))
-
-
- llm_chain = LLMChain(prompt=prompt, llm=local_llm)
- question = "What is the capital of England?"
- print(llm_chain.run(question))
通过自然语言执行SQL命令
通过 SQLDatabaseToolkit 或者 SQLDatabaseChain 都可以实现执行SQL命令的操作
- #SQLDatabaseToolkit的方法
- from langchain.agents import create_sql_agent
- from langchain.agents.agent_toolkits import SQLDatabaseToolkit
- from langchain.sql_database import SQLDatabase
- from langchain.llms.openai import OpenAI
-
- db = SQLDatabase.from_uri("sqlite:///../notebooks/Chinook.db")
- toolkit = SQLDatabaseToolkit(db=db)
-
- agent_executor = create_sql_agent(
- llm=OpenAI(temperature=0),
- toolkit=toolkit,
- verbose=True
- )
-
- agent_executor.run("Describe the playlisttrack table")
-
-
- #使用SQLDatabaseChain的方法
- from langchain import OpenAI, SQLDatabase, SQLDatabaseChain
-
- db = SQLDatabase.from_uri("mysql+pymysql://root:root@127.0.0.1/chinook")
- llm = OpenAI(temperature=0)
-
- db_chain = SQLDatabaseChain(llm=llm, database=db, verbose=True)
- db_chain.run("How many employees are there?")
参考内容:
快速入门指南:https://python.langchain.com/en/latest/getting_started/getting_started.html
LangChain 中文入门教程:https://liaokong.gitbook.io/llm-kai-fa-jiao-cheng/
————————————————
版权声明:本文为CSDN博主「深度学习的学习僧」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
- LLM(fastchat)+Langchain+Gradio/Streamlit各种框架基础点LLM预备知识、工具篇——LLM+LangChain+webUI的架构解析目录【常见名词】一、LLM的低资源模型微调二、向量数据库1、Milvus... [详细]
赞
踩
- article
【ChatGLM】基于 ChatGLM-6B + langchain 实现本地化知识库检索与智能答案生成: 中文 LangChain 项目的实现开源工作_chatglm-6b langchain
陈光剑简介:著有《ClickHouse入门、实战与进阶》(即将上架)《Kotlin极简教程》《SpringBoot开发实战》《Kotlin从入门到进阶实战》等技术书籍。资深程序员、大数据与后端技术专家、架构师,拥有超过10年的技术研发和管理... [详细]赞
踩
- 这是langchain的Java语言实现。大型语言模型(LLM)正成为一种变革性的技术,使开发人员能够构建以前无法构建的应用程序。但是,单个的使用LLM往往不足以创建真正强大的应用程序,当我们能够将它们与其他计算或知识来源相结合时,才会展现... [详细]
赞
踩
 例如,我们用4倍的数据进行了简单的测试,它大约是理论最大性能的80%(即6.5倍,而理论最大值比8个GPU快8倍)。我们有一组很棒的主题演讲者,包括来自OpenAI的JohnSchulman和来自Cohere的AidanGomez,关于Ra... [详细]
例如,我们用4倍的数据进行了简单的测试,它大约是理论最大性能的80%(即6.5倍,而理论最大值比8个GPU快8倍)。我们有一组很棒的主题演讲者,包括来自OpenAI的JohnSchulman和来自Cohere的AidanGomez,关于Ra... [详细]赞
踩
- 首先,我们定义PageId。与订单列表页面一样,将前缀设置为MEMBER。#(中略)MEMBER_ORDER_DETAIL=auto()#追加。仅使用Python创建的Web应用程序(前端版本)第11章_订单详细本章我们将实现订单列表页面。... [详细]
赞
踩
- 本文讲解了Langchain+本地大语言模型进行数据库操作的实战代码,希望能对尝试使用开源大语言模型进行SQL操作的同学们有所帮助。文章目录1.前言2.代码思路剖析3.实战代码_langchain执行sqllangchain执行sql 大... [详细]
赞
踩
- 总之,LangChain是一个强大的框架,它通过提供模块化和灵活的方法简化了构建高级语言模型应用程序的过程。LangChain的适应性和易用性使其成为开发人员的宝贵工具,使他们能够释放语言模型的全部潜力,并在广泛的用例中创建智能的、上下文感... [详细]
赞
踩
- 来源:AI研究局作者:张伟在日常生活中,我们通常致力于构建端到端的应用程序。有许多自动机器学习平台和持续集成/持续交付(CI/CD)流水线可用于自动化我们的机器学习流程。我们还有像Roboflow和AndrewN.G.的LandingAI这... [详细]
赞
踩

