
热门标签
热门文章
- 1win11出现安全中心空白和IT管理员已限制对此应用的某些区域的访问_win11被it管理员限制的原因
- 2Docker部署MinIO对象存储服务器结合内网穿透实现远程访问
- 3【愚公系列】2023年12月 Java教学课程 213-ElasticSearch(数据聚合、数据补全、数据同步)
- 4【2023 英特尔On技术创新大会直播 |我与英特尔的初次相遇】—— AIPC探索下一代的物联网时代
- 5计算机教师招聘笔试总结_大专计算机老师笔试
- 6基于Python的Selenium详细教程_pycharm安装selenium
- 7鸿蒙(HarmonyOS)应用开发——从网络获取数据(题目答案)_web组件onconfirm(callback: (event?: { url: string; m
- 8MacBook安装Golang Oracle数据库驱动程序_“libclntsh.dylib.19.1”不是来自app store的app。
- 9【记录】vue-cli+element-ui 制作一个侧边栏组件(抽屉Drawer)_vue3+抽屉
- 10基于Elasticsearch + Fluentd + Kibana(EFK)搭建日志收集管理系统_kibana fluentd
当前位置: article > 正文
python实战案例:采集某栈漫画数据,免费看完本_漫画采集
作者:程序质量控制师 | 2024-02-02 13:48:09
赞
踩
漫画采集

前言
漫画是什么?
丰子恺说:
“漫画是简笔而注重意义的一种绘画。

如今漫画深受大众喜欢,今天
我们就来采集一下漫画数据吧,免费看完本

环境使用:
Python 3.8及Pycharm
模块使用:
requests >>>
pip install requests 数据请求模块
parsel >>>
pip install parsel 数据解析模块
基本思路流程: <通用的>

二. 代码实现步骤
获取章节ID/章节名字/漫画名字:
请求链接: 漫画目录页url
获取数据, 获取服务器返回响应数据
3.解析数据, 提取我们想要的数据内容
4.保存数据
代码展示
( 完整源码点击此处跳转
+君羊,找管理员小姐姐领取呀~ )
- # 导入数据请求模块 --> 第三方模块, 需要安装 pip install requests
- import requests
- # 导入数据解析模块 --> 第三方模块, 需要安装 pip install parsel
- import parsel
- # 导入文件操作模块 --> 内置模块, 不需要安装
- import os
-
- # 请求链接 <目录页url>
- url = 'https://www.******.com/208707/'
- # 伪装模拟
- headers = {
- # user-agent 用户代理, 表示浏览器基本身份信息 Chrome 浏览器名字 101.0.0.0 浏览器版本 Windows 电脑系统
- 'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.0.0 Safari/537.36'
- }
- # 发送请求
- response = requests.get(url=url, headers=headers)
- 源码、解答、教程、资料加Q君羊:582950881##
- # 把获取下来html字符串数据内容<response.text>, 转换成可解析对象
- selector = parsel.Selector(response.text) # <Selector xpath=None data='<html>\n <head>\n <title>网游之近战法师_网游...'>
- # 提取漫画名字
- name = selector.css('.de-info__box .comic-title::text').get()
-
- # 自动创建文件夹 以漫画名字作为文件夹名
- file = f'{name}\\'
- if not os.path.exists(file):
- os.mkdir(file)
-
-
- # 第一次提取所有li标签, 返回是对象, 我不需要提取li标签里的内容
- lis = selector.css('.chapter__list .chapter__list-box .chapter__item')
- # 如何一个一个提取列表当中元素? for循环遍历
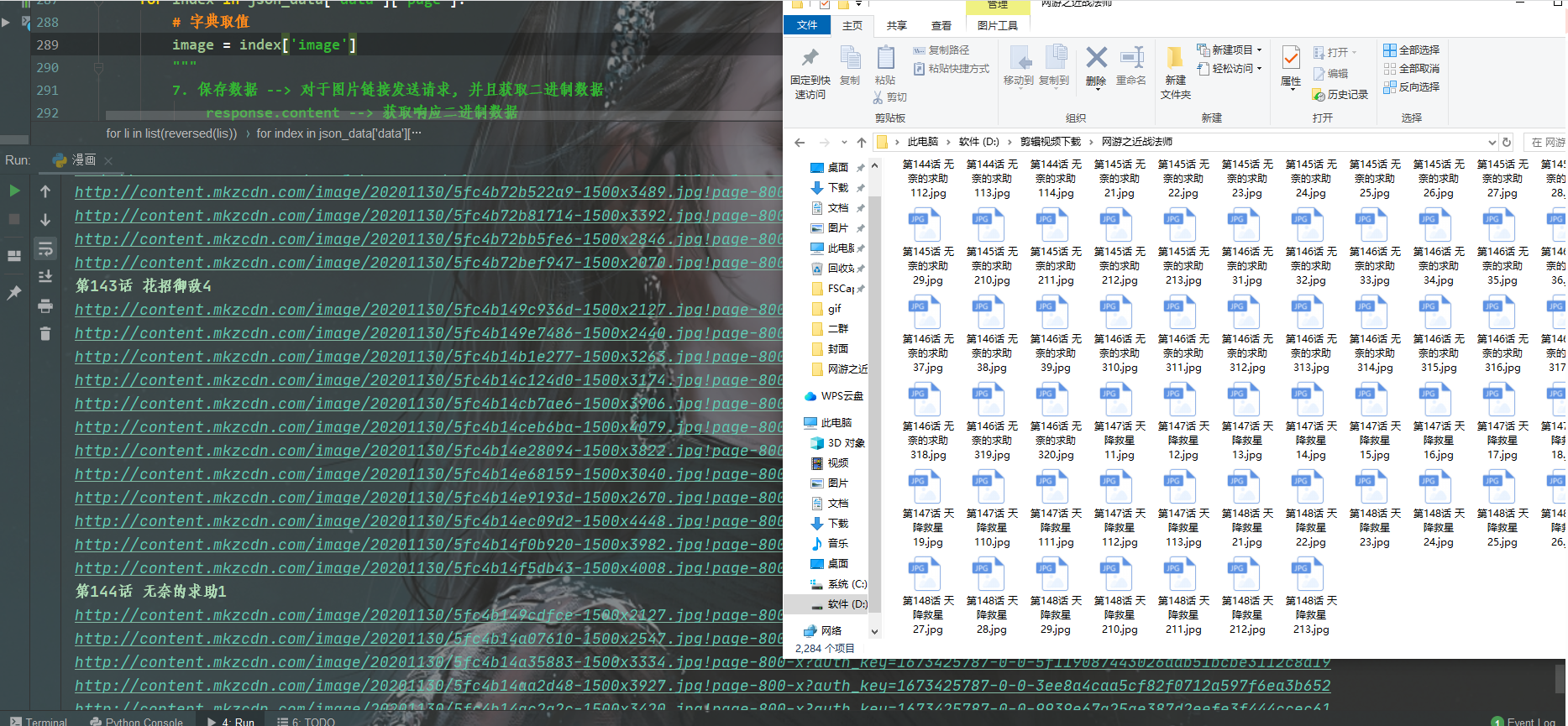
- for li in list(reversed(lis)):
- # 提取章节ID +为什么加的意思
- chapter_id = li.css('a::attr(data-chapterid)').get()
- # 提取章节名字
- chapter_title = li.css('a::text').getall()[-1].strip()
- # 请求链接: 漫画集合链接 --> f'{}' 字符串格式化方法, 相当于, 把chapter_id传入link这段字符串当中
- link = f'https://comic.******.com/chapter/content/v1/?chapter_id={chapter_id}&comic_id=208707&format=1&quality=1&sign=5a5b72c44ad43f6611f1e46dd4d457bf&type=1&uid=61003965'
- # 发送请求
- 源码、解答、教程、资料加Q君羊:582950881##
- json_data = requests.get(url=link, headers=headers).json()
- num = 1
- print(chapter_title)
- # for循环遍历, 一个一个提取列表元素
- for index in json_data['data']['page']:
- # 字典取值
- image = index['image']
- img_content = requests.get(url=image).content
- with open(file + chapter_title + str(num) + '.jpg', mode='wb') as f:
- f.write(img_content)
- num += 1
- print(image)


尾语
好啦,本文章到这里就结束拉
有喜欢的小伙伴记得给博主一个三连哦~
希望你在学习的路上不忘初心,坚持不懈,学有所成
把时间和精力,放在自己擅长的方向,去坚持与努力,
如果不知道自己擅长什么,就尽快找到它。

声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/55487
推荐阅读
- DES(DataEncryptionStandard)是一种对称加密算法。本文详细解释DES的算法原理,以及不安全的原因。附Python的实现源码。_des原理des原理文章目录1、什么是DES2、DES的基本概念3、DES的加密流程4、D... [详细]
赞
踩
- 因为课程需要,第一次这么彻底地接触numpy。虽闻名已久,但是真正使用numpy才感受到它的强大,发现它尤其适合数据分析与处理。这里根据自己的使用经验简单总结一下numpy在矩阵运算中的应用,之后也会根据自己的实践经历不断更新。_pytho... [详细]
赞
踩
- 在Python中,我们常常会遇到需要将运行结果以CSV格式导出以供其他语言或工具使用的情况。本文将介绍如何使用Python将结果导出为CSV格式的两种主要方法。_python导出csv文件python导出csv文件在Python中,我们常常... [详细]
赞
踩
- 当直接运行包的时侯(pythonwm),wm不是作为一包来运行,因此包的路径wm没有被加入sys.path路径中。在__ini__.py中定义一个main()函数,在__main__.py中调用它,实现入口,最后调用了wm.main()函数... [详细]
赞
踩
- 但是,有时候会出现550错误,表示所请求的文件不可访问。在该代码中,我们首先连接FTP服务器,然后使用nlst()方法列出当前目录下的文件列表,再判断所请求的文件是否在列表中。如果文件存在,则输出“文件存在”,否则输出“文件不存在”。以上是... [详细]
赞
踩
- selenium添加带有账密的socks5代理我们都知道在使用selenium开发爬虫的时候不可避免的会使用socks5高匿名代理。,当然这是本地自己搭的socks5代理,不需要账号密码就可以使用,但是如果我们搞了一台服务器在上面搭建了so... [详细]
赞
踩
 《滑雪大冒险》是一款充满趣味性和挑战性的休闲竞技游戏,在游戏中,玩家将扮演一位勇敢的滑雪者,在雪山上展示他们的滑雪技巧,游戏采用2D图形界面,以第第三人称视角呈现_滑雪大冒险代码python滑雪大冒险代码python滑雪大冒险《滑雪大冒险》... [详细]
《滑雪大冒险》是一款充满趣味性和挑战性的休闲竞技游戏,在游戏中,玩家将扮演一位勇敢的滑雪者,在雪山上展示他们的滑雪技巧,游戏采用2D图形界面,以第第三人称视角呈现_滑雪大冒险代码python滑雪大冒险代码python滑雪大冒险《滑雪大冒险》... [详细]赞
踩
- PythonSelenium自动化PythonSelenium自动化的笔记1.常用的一些第三方库importsocketimportsysfromseleniumimportwebdriverfromselenium.webdriver.c... [详细]
赞
踩
- 在方法update()中,我们添加了一个if代码块而不是elif代码块,这样如果玩家同时按下了左右箭头键,将先增大飞船的rect.centerx值,再降低这个值,即飞船的位置保持不变。在处,我们修改了游戏在玩家按下右箭头键时响应的方式:不... [详细]
赞
踩
- article
已解决WARNING: pip is configured with locations that require TLS/SSL, however the ssl module in Python
已解决(pip升级报错)WARNING:pipisconfiguredwithlocationsthatrequireTLS/SSL,howeverthesslmoduleinPythonisnotavailable.Lookinginin... [详细]赞
踩
- 本文章利用Python实现一个简单的功能较为完善的区块链系统(包括区块链结构、账户、钱包、转账),采用的共识机制是POW。_python区块链python区块链本文章利用Python实现一个简单的功能较为完善的区块链系统(包括区块链结构、账... [详细]
赞
踩
- Tkinter是Python的标准GUI库,也是最常用的PythonGUI库之一,提供了丰富的组件和功能,包括窗口、按钮、标签、文本框、列表框、滚动条、画布、菜单等,方便开发者进行图形界面的开发。Tkinter库基于TkforUnix/Wi... [详细]
赞
踩
- article
Python flask跨域支持(Access-Control-Allow-Origin(CORS)跨域资源共享(访问控制允许来源:允许指定的来源进行跨域请求)浏览器同源策略、OPTIONS预检请求_flask cors
此外,还可以使用CORS(跨域资源共享)机制来明确指定允许跨域请求的规则,以减少潜在的安全风险。要检测一个Flask接口是否支持跨域请求,可以使用浏览器的开发者工具来查看请求和响应的相关信息。,那么只有GET请求会进入到对应的视图函数中,而... [详细]赞
踩
 一、命令行安装pyecharts模块1、安装过程2、命令行验证pyecharts模块是否安装成功二、PyCharm安装pyecharts模块1、通过错误提示安装2、在Settings设置界面安装【Python】pyecharts模块②(命令... [详细]
一、命令行安装pyecharts模块1、安装过程2、命令行验证pyecharts模块是否安装成功二、PyCharm安装pyecharts模块1、通过错误提示安装2、在Settings设置界面安装【Python】pyecharts模块②(命令... [详细]赞
踩
- 最近,用Python给单位里用的“智慧食堂”系统编制了一个餐卡充值文件生成器,自动匹配餐卡号并快速生成导入数据用的Excel表格......使用tkinterToplevel控件弹出子窗口,用作设置备注的子窗口。_toplevelpytho... [详细]
赞
踩
- 随着软件规模和复杂性的增加,手动测试变得越来越繁琐且容易出错。自动化测试通过脚本化测试用例,能够更迅速、一致地验证软件的功能和性能。Selenium是一款强大的自动化测试工具,而Python语言则因其简洁性和易读性而成为自动化测试的首选之一... [详细]
赞
踩
 UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]
UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]赞
踩
- 爬取斗鱼直播照片保存到本地目录【附源码】【python】爬取斗鱼直播照片保存到本地目录【附源码+文末免费送书】一、导入必要的模块: 这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图... [详细]
赞
踩
- 本文展示如何使用库在Python中使用Excel文件。openpyxl是用于读取和写入Excel2010xlsx/xlsm/xltx/xltm文件的Python库。_pythonopenpyxlpythonopenpyxl各位好,我是轩哥啊... [详细]
赞
踩
- 每2秒获取一次UI控件的内容,实测挂在后台对CPU和内存占用并无明显影响,结合Pythonuiautomation的各种用法,可以做成自动回复的功能。Pythonuiautomation是一个用于自动化GUI测试和操作的库,它可以模拟用户操... [详细]
赞
踩
相关标签

