
- 1“用人荒”?IT企业的招不到人不妨换个思路
- 2ES操作通用类_es updateresponse
- 3专业的Web开发环境:MAMP PRO for Mac_web 服务器 mac
- 4JS正则表达式只能输入数字跟字母_js正则只能输入数字和字母
- 5C语言实现快速排序算法_c语言快速排序代码
- 6idea如何查看内存使用情况_idea显示内存占用
- 7C#——表达式_c#表达式详解
- 8byte数组转换成String_byte数组转string
- 9用CSS3实现动画进度条_css3实现进度条动画
- 10指针引用传参和指针传参,实参与形参,无法将参数从int*转换为int*&_“int ip_fixed_op(double &,const int &,const int &)
数学建模之Lingo基础知识与应用_lingo中j#lt#i什么意思
赞
踩
1. Lingo入门
安装:推荐微信公众号软件安装管家
(1) 界面分析:

(2) LINGO报告窗口
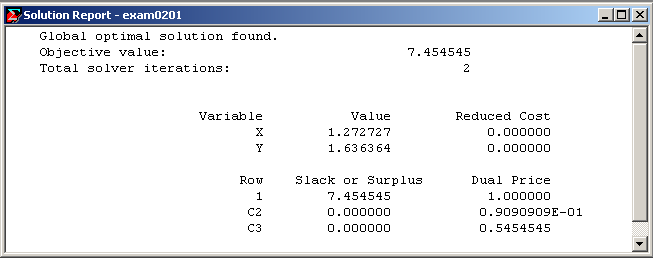
(3) 运行状态窗口
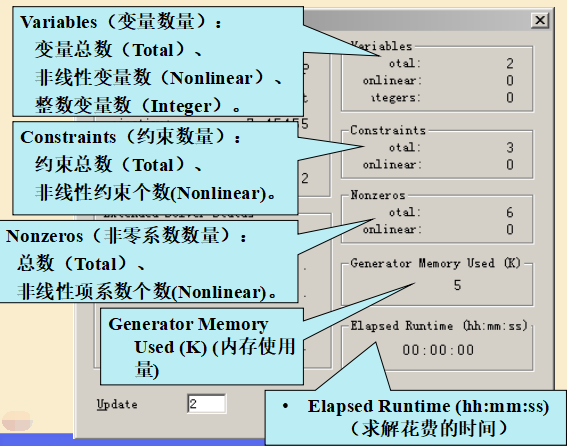
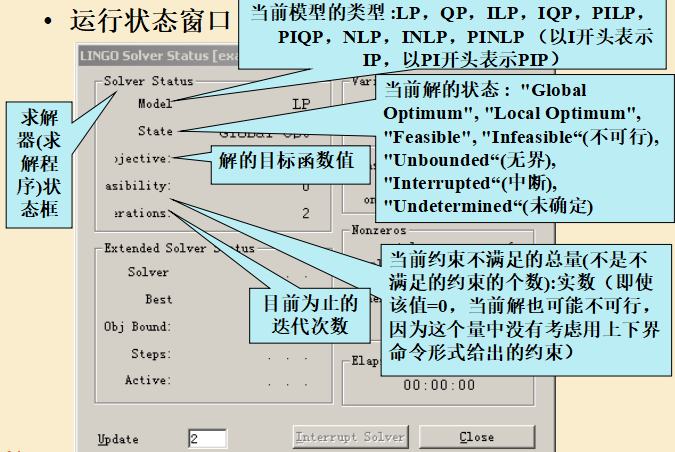
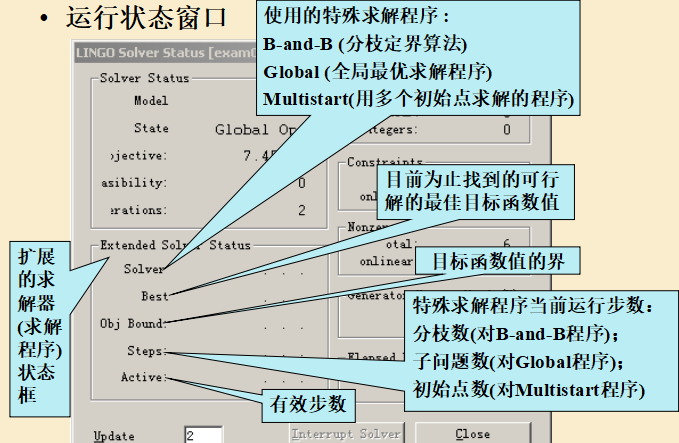
(4) 输出结果
基本用法注意事项:
- LINGO中不区分大小写字母;变量和行名可以超过8个字符,但不能超过32个字符,且必须以字母开头。
- 用LINGO解优化模型时已假定所有变量非负(除非用限定变量取值范围的函数
@free或@sub或@slb另行说明)。 - 变量可以放在约束条件的右端(同时数字也可放在约束条件的左端)。但为了提高LINGO求解时的效率,应尽可能采用线性表达式定义目标和约束(如果可能的话)。
- 语句是组成LINGO模型的基本单位,每个语句都以分号结尾,编写程序时应注意模型的可读性。例如:一行只写一个语句,按照语句之间的嵌套关系对语句安排适当的缩进,增强层次感。
2. 在LINGO中使用集合
LP模型一个典型的输入方式:

1. @SUM(集合(下标):关于集合的属性的表达式)
本例中目标函数也可以等价地写成
@SUM(QUARTERS(i): 400*RP(i) +450*OP(i) +20*INV(i) ),
“@SUM”相当于求和符号“∑”,
“QUARTERS(i)”相当于“iQUARTERS”的含义。
由于本例中目标函数对集合QUARTERS的所有元素(下标) 都要求和,所以可以将下标i省去。
2. @FOR(集合(下标):关于集合的属性的约束关系式)
对冒号“:”前面的集合的每个元素(下标),冒号“:”后面的约束关系式都要成立
为了区别i=1和i=2,3,4,把i=1时的约束关系式单独写出,即“INV(1)=10+RP(1)+OP(1)-DEM(1);” ;
而对i=2,3,4对应的约束,对下标集合的元素(下标i)增加了一个逻辑关系式“i#GT#1”(这个限制条件与集合之间有一个竖线“|”分开,称为过滤条件)。
限制条件“i#GT#1”是一个逻辑表达式,意思就是i>1;“#GT#”是逻辑运算符号,意思是“大于(Greater Than的字首字母缩写)” 。
2.1 LINGO模型最基本的组成要素
一般来说,LINGO中建立的优化模型可以由五个部分组成,或称为五“段”(SECTION):
(1)集合段(SETS):以“ SETS:” 开始, “ENDSETS”结束,定义必要的集合变量(SET)及其元素(MEMBER,含义类似于数组的下标)和属性(ATTRIBUTE,含义类似于数组)。
(2)目标与约束段:目标函数、约束条件等,没有段的开始和结束标记,因此实际上就是除其它四个段(都有明确的段标记)外的LINGO模型。
这里一般要用到LINGO的内部函数,尤其是与集合相关的求和函数@SUM和循环函数@FOR等。
(3)数据段(DATA):以 “DATA:” 开始, “ENDDATA”结束,对集合的属性(数组)输入必要的常数数据。
格式为:“attribute(属性) = value_list(常数列表);”
常数列表(value_list)中数据之间可以用逗号“,”分开,也可以用空格分开(回车等价于一个空格),如上面对DEM的赋值也可以写成“DEM=40 60 75 25;”。
(4)初始段(INIT):以“INIT: ”开始, “ENDINIT”结束,对集合的属性(数组)定义初值(因为求解算法一般是迭代算法,所以用户如果能给出一个比较好的迭代初值,对提高算法的计算效果是有益的)。
如果有一个接近最优解的初值,对LINGO求解模型是有帮助的。定义初值的格式为:
“attribute(属性) = value_list(常数列表);”
(5)计算段(CALC):以“CALC: ”开始, “ENDCALC”结束,对一些原始数据进行计算处理。
在实际问题中,输入的数据通常是原始数据,不一定能在模型中直接使用,可以在这个段对这些原始数据进行一定的“预处理”,得到模型中真正需要的数据。
例如上例,如果希望得到全年的总需求和季度平均需求,可以增加这个段:
CALC:
T_DEM = @SUM(quarters: DEM); !总需求;
A_DEM = T_DEM / @size(quarters); !平均需求;
ENDCALC- 1
- 2
- 3
- 4
2.2 基本集合与派生集合
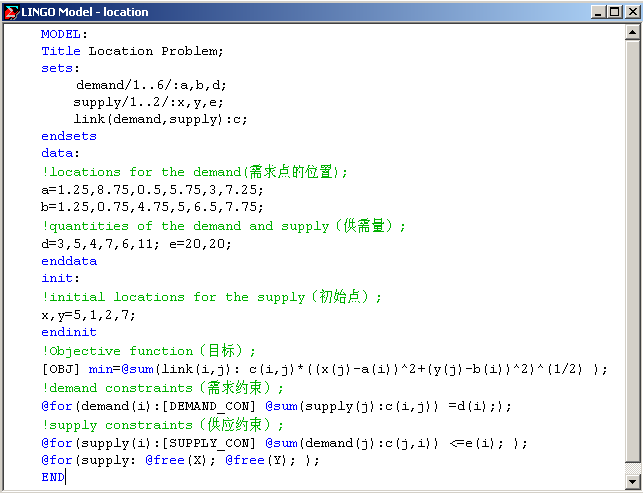
MODEL:
Title Location Problem;
SETS:
demand/1..6/:a,b,d;
supply/1..2/:x,y,e;
link(demand,supply):c;
ENDSETS
DATA:
!locations for the demand(需求点的位置);
a=1.25,8.75,0.5,5.75,3,7.25;
b=1.25,0.75,4.75,5,6.5,7.75;
!quantities of the demand and supply(供需量);
d=3,5,4,7,6,11; e=20,20;
ENDDATA
INIT:
!initial locations for the supply(初始点);
x,y=5,1,2,7;
ENDINIT
!Objective function(目标);
[OBJ] min=@sum(link(i,j):c(i,j)*((x(j)-a(i))^2+(y(j)-b(i))^2)^(1/2));
!demand constraints(需求约束);
@for(demand(i):[DEMAND_CON]@sum(supply(j):c(i,j))=d(i););
!supply constraints(供应约束);
@for(supply(i):[SUPPLY_CON]@sum(demand(j):c(j,i))<=e(i););
@for(supply:@free(X);@free(Y););
END
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 定义了三个集合,其中LINK在前两个集合DEMAND 和SUPPLY的基础上定义
- 在程序开头用TITLE语句对这个模型取了一个标题“LOCATION PROBLEM;并且对目标行([OBJ])和两类约束(DEMAND_CON、SUPPLY_CON)分别进行了命名(请特别注意这里约束命名的特点)。
- INGO对数据是按列赋值的
语句的实际赋值顺序是X=(5,2), Y=(1,7), 而不是X=(5,1), Y=(2,7)
等价写法:
“X=5,2; Y=1,7;”
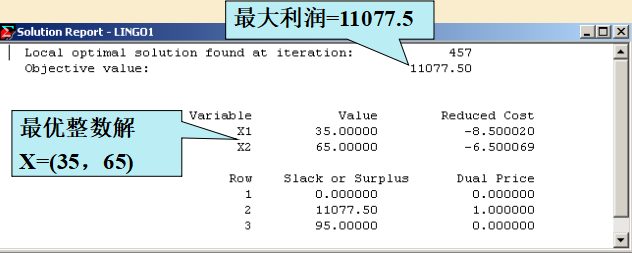
解得:

2.3 稠密集合与稀疏集合
包含了两个基本集合构成的所有二元有序对的派生集合称为稠密集合(简称稠集)。有时候,在实际问题中,一些属性(数组) 只在笛卡儿积的一个真子集合上定义,这种派生集合称为稀疏集合(简称疏集)。
例 (最短路问题) 在纵横交错的公路网中,货车司机希望找到一条从一个城市到另一个城市的最短路. 下图表示的是公路网, 节点表示货车可以停靠的城市,弧上的权表示两个城市之间的距离(百公里). 那么,货车从城市S出发到达城市T,如何选择行驶路线,使所经过的路程最短?
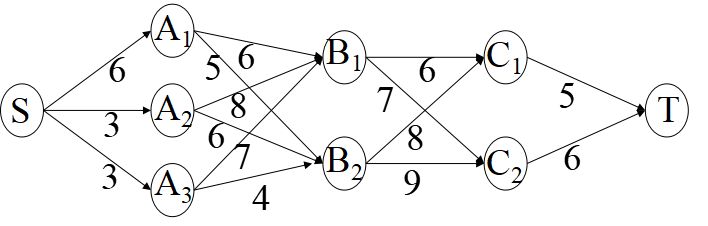
此例中可把从S到T的行驶过程分成4个阶段,即 S→Ai (i=1,2或3), Ai → Bj(j=1或2), Bj → Ck(k=1或2), Ck → T. 记d(Y,X)为城市Y与城市X之间的直接距离(若这两个城市之间没有道路直接相连,则可以认为直接距离为∞),用L(X)表示城市S到城市X的最优行驶路线的路长:
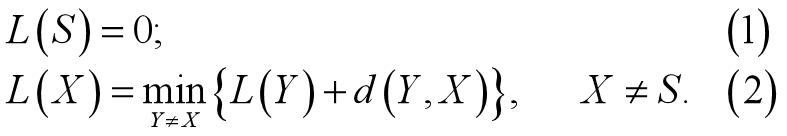
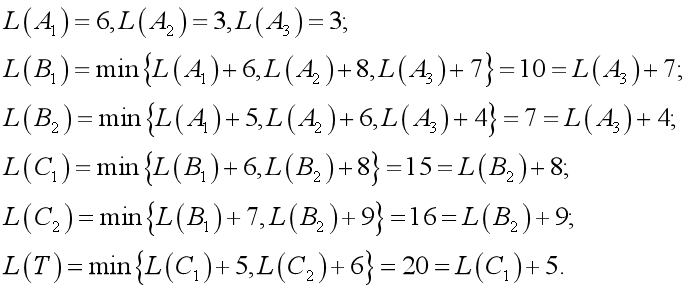
本例的LINGO求解:
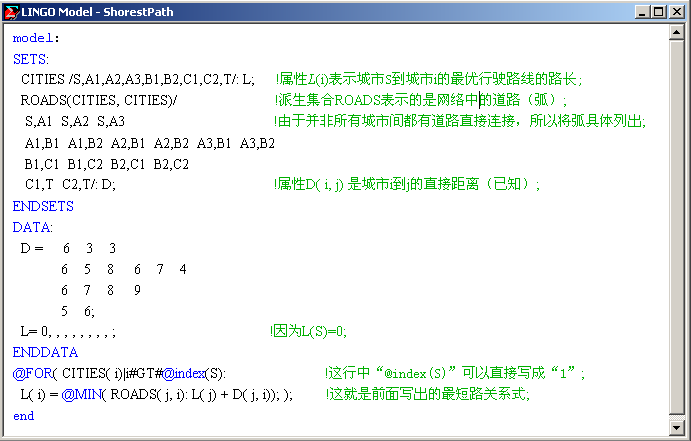
MODEL:
SETS:
CITIES /S,A1,A2,A3,B1,B2,C1,C2,T/:L; !属性L(i)表示城市S到城市i的最优行驶路线的路长;
ROADS(CITIES,CITIES)/ !派生集合ROADS表示的是网络中的道路(弧);
S,A1 S,A2 S,A3 !由于并非所有城市间都有道路直接连接,所以将弧直接列出;
A1,B1 A1,B2 A2,B1 A2,B2 A3,B1 A3,B2
B1,C1 B1,C2 B2,C1 B2,C2
C1,T C2,T/:D; !属性D(i,j)是城市i到j的直接距离(已知);
ENDSETS
DATA:
D= 6 3 3
6 5 8 6 7 4
6 7 8 9
5 6;
L=0, , , , , , , ,; !因为L(S)=0;
ENDDATA
@for(CITIES(i)|i#GT#@index(S):
L(i)=@MIN(ROADS(j,i): L(j)+D(j,i)););
END- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
运行结果:
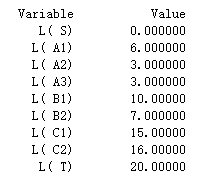
- “CITIES”(城市):一个基本集合(元素通过枚举给出)
- “ROADS”(道路):由CITIES导出的一个派生集合(请特别注意其用法),由于只有一部分城市之间有道路相连,所以不应该把它定义成稠密集合,将其元素通过枚举给出,这就是一个稀疏集合。
- 从模型中还可以看出:这个LINGO程序可以没有目标函数,这在LINGO中,可以用来找可行解(解方程组和不等式组)。
2.4 集合的使用小结
1. 基本集合的定义格式为(方括号“[ ]”中的内容是可选项, 可以没有):
setname [/member_list/] [: attribute_list];
其中setname为定义的集合名,member_list为元素列表,attribute_list为属性列表。元素列表可以采用显式列举法(即直接将所有元素全部列出,元素之间用逗号或空格分开),也可以采用隐式列举法。
2. 派生集合的定义格式为(方括号“[ ]”中的内容是可选项, 可以没有):
setname(parent_set_list) [/member_list/] [: attribute_list];
与基本集合的定义相比较多了一个parent_set_list(父集合列表)。
父集合列表中的集合(如 set1,set2,…,等)称为派生集合setname的父集合,它们本身也可以是派生集合。
3. 运算符和函数
3.1 逻辑运算符
在LINGO中,逻辑运算(表达式)通常作为过滤条件使用,逻辑运算符有9种,可以分成两类:
#AND#(与),#OR#(或),#NOT#(非):逻辑值之间的运算,它们操作的对象本身已经是逻辑值或逻辑表达式,计算结果也是逻辑值。
#EQ#(等于),#NE#(不等于),#GT#(大于),#GE#(大于等于),#LT#(小于),#LE#(小于等于):是“数与数之间”的比较,也就是它们操作的对象本身必须是两个数, 计算得到的结果是逻辑值。
3.2 基本的数学函数
在LINGO中建立优化模型时可以引用大量的内部函数,这些函数以”@” 打头。LINGO中包括相当丰富的数学函数,这些函数的用法非常简单,下面一一列出。
@ABS(X):绝对值函数,返回X的绝对值。
@COS(X):余弦函数,返回X的余弦值(X的单位是弧度)。
@EXP(X):指数函数
@FLOOR(X):取整函数,返回X的整数部分(向最靠近0的方向取整)。
@LGM(X):返回X的伽玛(gamma)函数的自然对数值(当X为整数时LGM(X)=LOG(X-1)!;当X不为整数时,采用线性插值得到结果)。
@LOG(X):自然对数函数,返回X的自然对数值。
@MOD(X,Y):模函数,返回X对Y取模的结果,即X除以Y的余数,这里X和Y应该是整数。
@POW(X,Y):指数函数,返回XY的值。
@SIGN(X):符号函数,返回X的符号值(X < 0时返回-1, X >= 0时返回+1)。
@SIN(X):正弦函数,返回X的正弦值(X的单位是弧度)。
@SMAX(list):最大值函数,返回一列数(list)的最大值。
@SMIN(list):最小值函数,返回一列数(list)的最小值。
@SQR(X):平方函数,返回X的平方(即X*X)的值。
@SQRT(X):开平方函数,返回X的正的平方根的值。
@TAN(X):正切函数,返回X的正切值(X的单位是弧度)。
3.3 集合循环函数
集合上的元素(下标)进行循环操作的函数, 一般用法如下:
@function(setname[(set_index_list)[|condition]]:expression_list);- 1
其中:
function 集合函数名,FOR、MAX、MIN、PROD、SUM之一;
Setname 集合名;
set_index_list 集合索引列表(不需使用索引时可以省略);
Condition 用逻辑表达式描述的过滤条件(通常含有索引,无条件时可以省略);
expression_list 一个表达式(对@FOR函数,可以是一组表达式。
五个集合函数名的含义:
@FOR(集合元素的循环函数): 对集合setname的每个元素独立地生成表达式,表达式由expression_list描述(通常是优化问题的约束)。
@MAX(集合属性的最大值函数):返回集合setname上的表达式的最大值。
@MIN(集合属性的最小值函数):返回集合setname上的表达式的最小值。
@PROD(集合属性的乘积函数): 返回集合setname上的表达式的积。
@SUM(集合属性的求和函数):返回集合setname上的表达式的和。
3.4 集合操作函数
@INDEX( [set_name,] primitive_set_element)
给出元素primitive_set_element在集合set_name中的索引值(即按定义集合时元素出现顺序的位置编号)。省略set_name,LINGO按模型中定义的集合顺序找到第一个含有该元素的集合,并返回索引值。如果没有找到该元素,则出错。
注: Set_name的索引值是正整数且只能位于1和元素个数之间。例:定义一个女孩姓名集合(GIRLS)和男孩姓名集合(BOYS) :
SETS:
GIRLS /DEBBIE, SUE, ALICE/;
BOYS /BOB, JOE, SUE, FRED/;
ENDSETS- 1
- 2
- 3
- 4
都有SUE,GIRLS在BOYS前定义,调用@INDEX(SUE)将返2,相当于@INDEX(GIRLS,SUE)。要找男孩中名为SUE的小孩的索引,应该使用@INDEX(BOYS, SUE),返3。
2. @IN( set_name, primitive_index_1 ,[primitive_index_2 ...])
判断一个集合中是否含有某个索引值。如果集合set_name中包含由索引primitive_index_1, [ primitive_index_2 …]所对应元素,则返回1(逻辑值“真”),否则返回0(逻辑值“假”)。索引用“&1”、“&2”或@INDEX函数等形式给出,这里“&1”表示对应于第1个父集合的元素的索引值,“&2”表示对应于第2个父集合的元素的索引值。
例:定义一个集合STUDENTS(基本集合),派生出集合PASSED和FAILED,定义:
SETS:
STUDENTS / ZHAO, QIAN, SUN, LI/:;
PASSED( STUDENTS) /QIAN,SUN/:;
FAILED( STUDENTS) | #NOT# @IN( PASSED, &1):;
ENDSETS- 1
- 2
- 3
- 4
- 5
如果集合C是由集合A,B派生的,例如:
SETS:
A / 1..3/:;
B / X Y Z/:;
C( A, B) / 1,X 1,Z 2,Y 3,X/:;
ENDSETS- 1
- 2
- 3
- 4
- 5
判断C中是否包含元素(2,Y),则可以利用以下语句:
X = @IN( C, @INDEX( A, 2), @INDEX( B, Y));- 1
对本例,结果是X=1(真)。
3. @WRAP(I,N) 此函数对N<1无定义
当I位于区间[1, N]内时直接返回I;一般地,返回 J = I - K *N , 其中J位于区间[1, N ], K为整数。即@WRAP(I,N)= @MOD(I,N)。
但当@MOD(I,N)=0时@WRAP(I,N)=N.
此函数可以用来防止集合的索引值越界。
用户在编写LINGO程序时,应注意避免LINGO模型求解时出现集合的索引值越界的错误。
4. @SIZE (set_name)
返回数据集set_name中包含元素的个数。
3.5 变量定界函数
对变量的取值范围附加限制,共有以下四种:
@BND(L, X, U) :限制L <= X <= U。 注意LINGO中没有与LINDO命令SLB、SUB类似的函数@SLB和@SUB
@BIN(X) :限制X为0或1。注意LINDO中的命令是INT,但LINGO中这个函数的名字却不是@INT(X)
@FREE(X):取消对X的符号限制(即可取负数、0或正数)
@GIN(X):限制X为整数
3.6 概率相关函数
@PSN(X):标准正态分布函数,即返回标准正态分布的分布函数在X点的取值。
@PSL(X):标准正态线性损失函数,即返回 MAX(0, Z-X)的期望值, 其中 Z为标准正态随机变量。
@PPS(A,X):Poisson分布函数,即返回均值为A的Poisson分布的分布函数在X点的取值(当X不是整数时,采用线性插值进行计算)。
@PPL(A,X):Poisson分布的线性损失函数,即返回 MAX(0, Z-X)的期望值, 其中 Z为均值为A的Poisson随机变量。
@PBN(P,N,X):二项分布函数,即返回参数为(N,P)的二项分布的分布函数在X点的取值(当N和(或)X不是整数时,采用线性插值进行计算) 。
@PHG(POP,G,N,X):超几何(Hypergeometric)分布的分布函数。也就是说,返回如下概率:当总共有POP个球,其中G个是白球时,那么随机地从中取出N个球,白球不超过X个的概率。当POP,G,N和(或)X不是整数时,采用线性插值进行计算。
@PEL(A,X) :当到达负荷(强度)为A,服务系统有X个服务器且不允许排队时的Erlang损失概率。
@PEB(A,X):当到达负荷(强度)为A,服务系统有X个服务器且允许无穷排队时的Erlang繁忙概率。
@PFS(A,X,C) :当负荷上限为A,顾客数为C,并行服务器数量为X时,有限源的Poisson服务系统的等待或返修顾客数的期望值。(A是顾客数乘以平均服务时间,再除以平均返修时间。当C和(或)X不是整数时,采用线性插值进行计算)。
@PFD(N,D,X):自由度为N和D的F分布的分布函数在X点的取值。
@PCX(N,X): 自由度为N的分布的分布函数在X点的取值。
@PTD(N,X): 自由度为N的t分布的分布函数在X点的取值。
@QRAND(SEED): 返回0与1之间的多个拟均匀随机数(SEED为种子,缺省时取当前计算机时间为种子)。该函数只能用在数据段,拟均匀随机数可以认为是“超均匀”的随机数,需要详细了解“拟均匀随机数(quasi-random uniform numbers)” 请进一步参阅LINGO的使用手册。
@RAND(SEED) :返回0与1之间的一个伪均匀随机数(SEED为种子)。
3.7 文件输入输出函数
@FILE(filename) 当前模型引用其他ASCII码文件中的数据或文本时可以采用该语句(但不允许嵌套使用),其中filename为存放数据的文件名,该文件中记录之间用“~”分开。
@ODBC 提供LINGO与ODBC(Open Data Base Connection,开放式数据库连接)的接口。
@OLE 提供LINGO与OLE(Object Linking and Embeding)接口。
@POINTER( N) 在Windows下使用LINGO的动态连接库DLL ,直接从共享的内存中传送数据。
@TEXT(['filename']) 用于数据段中将解答结果送到文本文件filename中,当省略filename时,结果送到标准的输出设备(通常就是屏幕)。filename中可以带有文件路径,没有指定路径时表示在当前目录,如果这个文件已经存在,将会被覆盖。
3.8 结果报告函数
@ITERS() 只能在程序的数据段使用,调用时不需要任何参数,返回LINGO求解器计算所使用的总迭代次数。例如:
@TEXT() = @ITERS();- 1
将迭代次数显示在屏幕上。
@NEWLINE(n) 在输出设备上输出n个新行。
@STRLEN(string) 返回字串“string”的长度,如 @STRLEN(123)返回值为3。
@NAME(var_or_row_refernce) 返回变量名或行名。
@WRITE(obj1[, …, objn]) 只能在数据段中使用,输出一系列结果(obj1, …, objn),其中obj1, …, objn 等可以是变量(但不能只是属性),也可以是字符串(放在单引号中的为字符串)或换行(@NEWLINE)等。
结果可以输出到一个文件,或电子表格(如EXCEL),或数据库,这取决于@WRITE所在的输出语句中左边的定位函数。
例如:
DATA:
@TEXT() = @WRITE('A is', A, ', B is', B, ', A/B is', A/B);
ENDDATA- 1
- 2
- 3
其中A,B是该模型中的变量,在屏幕上输出A,B以及A/B的值(增加了一些字符串,使结果读起来更方便)。假设计算结束时A=10,B=5,则输出为:
A is 10,B is 5, A/B is 2- 1
@WRITEFOR( setname[ ( set_index_list) [ | condition]]: obj1[,…, objn]) 函数@WRITE在循环情况下的推广,输出集合上定义的属性对应的多个变量的取值。
例:(这里WH,C,X含义同上):
DATA:
@TEXT()=@WRITEFOR(ROAD(I,J)| X(I,J) #GT# 0:‘从仓库', WH(I),
'到顾客',C(J),'供货 ', X(I,J),'件 ',@NEWLINE(1));
ENDDATA- 1
- 2
- 3
- 4
对应的输出效果示意如下:
从仓库 WH1 到顾客 C1 供货 2件
…………………..
从仓库 WH3 到顾客 C3 供货21件
@FORMAT( value, format_descriptor)
在@WRITE和@WRITEFFOR函数中,@FORMAT对数值设定输出格式。value表示输出的值,format_descriptor(格式描述符)表示输出格式。格式描述符的含义与C语言中的格式描述类似,如“12.2f”表示十进制数,总共12位,其中有2位小数。
注:使用@FORMAT函数将把数值转换成字符串,所以输出的实际上是字符串,这对于向数据库,电子表中输出不一定合适。
@DUAL( variable_or_row_name)
@DUAL(variable)返回解答中variable的判别数(reduced cost);
@DUAL(row)将返回约束行row的对偶(影子)价格(dual prices)。
例:
DATA:
@TEXT() = @WRITEFOR( SET1( I): X( I), @DUAL( X( I), @NEWLINE( 1));
ENDDATA- 1
- 2
- 3
@RANGED( variable_or_row_name)
为了保持最优基不变,目标函数中变量的系数或约束行的右端项允许减少的量。
@RANGEU( variable_or_row_name)
为了保持最优基不变,目标函数中变量的系数或约束行的右端项允许增加的量。
3.9 其他函数
@IF(logical_condition, true_result, false_result)当逻辑表达式logical_condition的结果为真时,返回true_result,否则返回false_result。
@WARN('text', logical_condition )
如果逻辑表达式“logical_condition”的结果为真,显示‘text’信息。
@USER(user_determined_arguments)
允许用户自己编写的函数(DLL或OBJ文件),可能应当用C或FORTRAN等其他语言编写并编译。
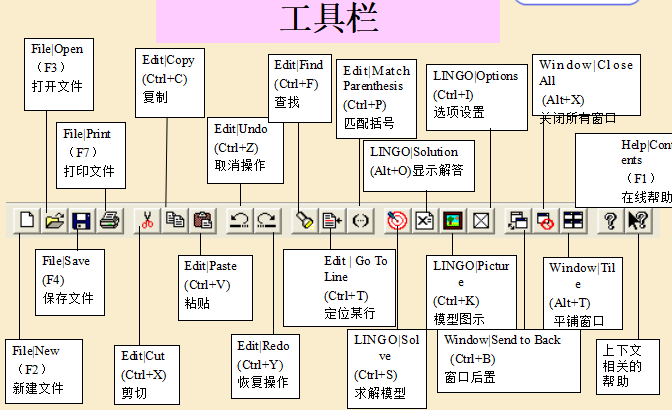
4. LINGO的主要菜单命令
 【好书推荐-第一期】《一书读懂物联网:基础知识+运行机制+工程实现》【好书推荐-第一期】《一书读懂物联网:基础知识+运行机制+工程实现》... [详细]
【好书推荐-第一期】《一书读懂物联网:基础知识+运行机制+工程实现》【好书推荐-第一期】《一书读懂物联网:基础知识+运行机制+工程实现》... [详细]赞
踩
 OTA是英文"Over-the-Air"的缩写,意为通过无线网络传输数据。在技术领域中,OTA通常指的是通过无线网络(如蜂窝网络或Wi-Fi)从远程服务器下载和安装软件更新或固件更新到设备上,而无需通过传统的有线连接或物理介质(如USB线或... [详细]
OTA是英文"Over-the-Air"的缩写,意为通过无线网络传输数据。在技术领域中,OTA通常指的是通过无线网络(如蜂窝网络或Wi-Fi)从远程服务器下载和安装软件更新或固件更新到设备上,而无需通过传统的有线连接或物理介质(如USB线或... [详细]赞
踩
- OTA是英文"Over-the-Air"的缩写,意为通过无线网络传输数据。在技术领域中,OTA通常指的是通过无线网络(如蜂窝网络或Wi-Fi)从远程服务器下载和安装软件更新或固件更新到设备上,而无需通过传统的有线连接或物理介质(如USB线或... [详细]
赞
踩
- 你评论我送书~参与方式:关注、点赞、收藏,评论"一书读懂物联网:基础知识+运行机制+工程实现"「小明赠书活动」2024第三期《一书读懂物联网:基础知识+运行机制+工程实现》⭐️赠书-《一书读懂物联网:基础知识+运行机制+工程实现》《一书读懂... [详细]
赞
踩
- 名称功能GND接地MOSI主机发送,从机接收MISO主机接收,从机发送CLK时钟线CS1(NSS1)片选线……多个设备时的片选线_spi电平spi电平目录概述电气连接接口定义 连接方式通信协议 片选信号时钟时钟极性(Cl... [详细]
赞
踩
- 一个完整大型项目的构建与开发,都是需要一个团队合作完成的,每个人分工不同。同时,每个人负责的岗位也会被其他人替代,在项目开发人员更新迭代的同时,为了确保整个项目中以往开发人员遗留的代码所使用的第三方库,框架与刚上岗的开发人员所写的代码用... [详细]
赞
踩
- 某食品公司经销的主要产品之一是糖果,他下面设有三个加工厂,每天的糖果生产量分别为A1-7t,A2-4t,A3-9t.该公司把这些糖果分别运往四个地区的门市部销售,各地区每天的销售量为B1-3t,B2-6t,B3-5t,B4-6t,已知每个... [详细]
赞
踩
- LINGO是用来解决优化问题的一个特别好用的软件,可以快速求解线性规划、非线性规划、线性和非线性方程组等等,是数学建模中求优化问题的解不可缺少的工具之一(1)LINGO的数学规划模型包含目标函数、决策变量、约束条件三个要素;(2)LINGO... [详细]
赞
踩
- 文章目录例子不同算法(lingo)不同算法(Matlab)例子我们由上可以得到线性规划式子:要如何解呢?不同算法(lingo)可以使用lingo软件:结果为14,x1为4,x2为2。然而,mac上没有lingo软件,用Matlab行不行?可... [详细]
赞
踩

