
热门标签
热门文章
- 1【python】详解python函数定义 def()与参数args、可变参数*args、关键参数**args使用实例_python def
- 2Python 深度学习框架之keras库详解
- 3linux nohup命令如何使用?_linux中nohup怎么用
- 4解决高并发的几种方法_高并发三种解决方法
- 5Codeforces #704 (Div. 2) C. Maximum width Apare_xzc_c》maximum width
- 6R语言︱决策树族——随机森林算法_r语言ranger
- 7基于springboot高校社团管理系统_大学生社团管理系统 idea
- 8Linux 驱动开发基础知识——总线设备驱动模型(七)
- 9SpringbootSecurity登陆验证(前后端分离)_springsecurity前后端分验证码登录
- 10【亚马逊云科技】使用Vscode Amazon-Q完成GUI界面粉笔脚本开发
当前位置: article > 正文
Java操作Mongo数据库 依赖翻页-优化大数据量的翻页性能_java 优化mongodb翻页查询性能
作者:思考机器2 | 2024-02-02 19:08:37
赞
踩
java 优化mongodb翻页查询性能
大数量级mongo翻页Java代码
一、准备的基础环境
- 主要jar包依赖:
<mongo.version>3.12.7</mongo.version>
<dependency>
<groupId>org.mongodb</groupId>
<artifactId>mongo-java-driver</artifactId>
<version>${mongo.version}</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
- 6
-
mongo compass可视化工具

我这里大概40万数据,不算特别多mongo采用的是mongoCollection:
private static MongoCollection<Document> mongoCollection = MongoDBTemplate.getCollection("索引名", "集合名");
- 1
二、 传统skip 、limit 相同条件下遍历的性能对比
-
mongo操作的dao代码图片:

-
测试方法
/** * SkipAndLimit分页测试(20万数据12-14秒,40万数据大概43-50秒左右)------->也不推荐 */ @Test public void testMongoSkipAndLimitPage() { long startTime = System.currentTimeMillis()/1000; List<T> dataEntityList = new ArrayList<>(1000000); long totalSize = topicDao.getTotalSize(); log.info("totalSize:{}",totalSize); int page = 1; int pageSize = 1000; int pages = (int) Math.ceil(totalSize / (double) pageSize); while (page <= pages) { List<T> byPage = topicDao.findDataWithSkip(page, pageSize); dataEntityList.addAll(byPage); page++; log.info("size:{}",dataEntityList.size()); // if (page>200){ // break; // } } log.info("spend time:{} 秒",System.currentTimeMillis()/1000-startTime); }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
上面的T改为自己的实体类
测试结果:

3. 结论:
传统的skip与limit翻页性能在数据量很大的时候,遍历的时候就会花费非常久的时间,我这里只有40万数据,就已经花了将近50秒钟,当数据量更大几个量级,那就有的等了。
二、方式二:每次翻页之前,查询到上一页的最后一条数据,然后从刚好比这条数据大的地方开始下一页遍历
- 主要mongo操作的dao代码图片
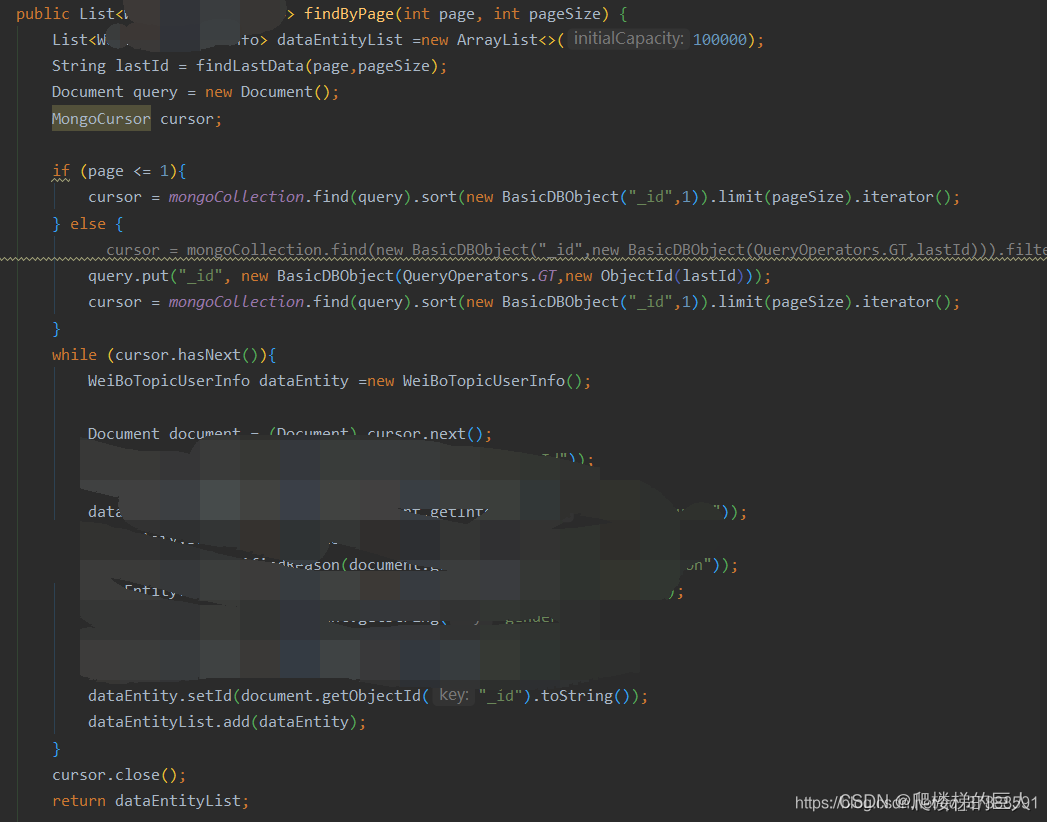
/** * 查询某一页最后一条数据的objectid * @return */ public String findLastData(int page, int pageSize) { try { //url,commentId,name,userId,time,level,source,content,commentNum,likerNum,disLikerNum,parentCommentId Document document = mongoCollection.find().skip((page - 1) * pageSize).limit(pageSize).sort(new BasicDBObject("_id", 1)).first(); String id = document.getObjectId("_id").toString(); // log.info("id: {}",id); return id; }catch (Exception e){ logger.error("mongo查询失败"); } return null; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 测试方法
/** * 依赖分页测试1(20万数据26-29秒,40万数据大概86-100秒左右)------->不推荐 */ @Test public void testMongoSomePage() { long startTime = System.currentTimeMillis()/1000; List<T> dataEntityList = new ArrayList<>(1000000); long totalSize = topicDao.getTotalSize(); log.info("totalSize:{}",totalSize); int page = 1; int pageSize = 1000; // String lastId = ""; int pages = (int) Math.ceil(totalSize / (double) pageSize); while (page <= pages) { List<T> byPage = topicDao.findByPage(page, pageSize); dataEntityList.addAll(byPage); log.info("size:{}",dataEntityList.size()); page++; // if (page>200){ // break; // } } log.info("spend time:{} 秒",System.currentTimeMillis()/1000-startTime); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
上面代码中的T换成自己的实体类就行
测试图片如下:

- 结论
这种方式是我第一次按照网上其他人的博客写的,但是很明显,每次翻页都需要查询一次上一页的最后一条objectid,本质上跟skip没什么区别,甚至多出了其他耗时的代码操作,最不推荐
三、大数据量依赖分页分页方式2:
- 翻页dao代码:
/** * 依赖翻页mongo (速度快,推荐) * @param lastId 上一页最后一个 ObjectId * @param pageSize 每页大小 * @return */ public List<T> queryDataByPage(String lastId, int pageSize) { List<T> dataEntityList =new ArrayList<>(3000); // DBCursor dbObjects=null; MongoCursor<Document> cursor; BasicDBObject query=new BasicDBObject(); if(StringUtils.isBlank(lastId)) { cursor = mongoCollection.find(query).sort(new BasicDBObject("_id",1)).limit(pageSize).iterator(); } else { query.put("_id", new BasicDBObject(QueryOperators.GT,new ObjectId(lastId))); cursor = mongoCollection.find(query).limit(pageSize).sort(new BasicDBObject("_id",1)).iterator(); } while (cursor.hasNext()){ TdataEntity =new T(); Document document = cursor.next(); dataEntity.setUserId(document.getString("userId")); ...... dataEntity.setId(document.getObjectId("_id").toString()); dataEntityList.add(dataEntity); } cursor.close(); return dataEntityList; }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
2. **测试代码:** ```java /** * 依赖分页性能测试(20万数据4-6秒,40万数据大概10-12秒)---------------->推荐 */ @Test public void testMongoQueryByPage() { long startTime = System.currentTimeMillis()/1000; List<T> dataEntityList = new ArrayList<>(1000000); long totalSize = topicDao.getTotalSize(); log.info("totalSize:{}",totalSize); int page = 1; int pageSize = 1000; //总页数 long totalPage = totalSize/pageSize==0?totalSize/pageSize:totalSize/pageSize+1; String lastId = null; while (page <= totalPage) { List<T> byPage = topicDao.queryDataByPage(lastId,pageSize); if (!byPage.isEmpty()){ dataEntityList.addAll(byPage); lastId = byPage.get(byPage.size()-1).getId(); page++; log.info("size:{}",dataEntityList.size()); // if (page>200){ // break; // } } } log.info("spend time:{} 秒",System.currentTimeMillis()/1000-startTime); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
同样,上面代码中的T换成自己的实体类就行
翻页花费时间的截图如下:
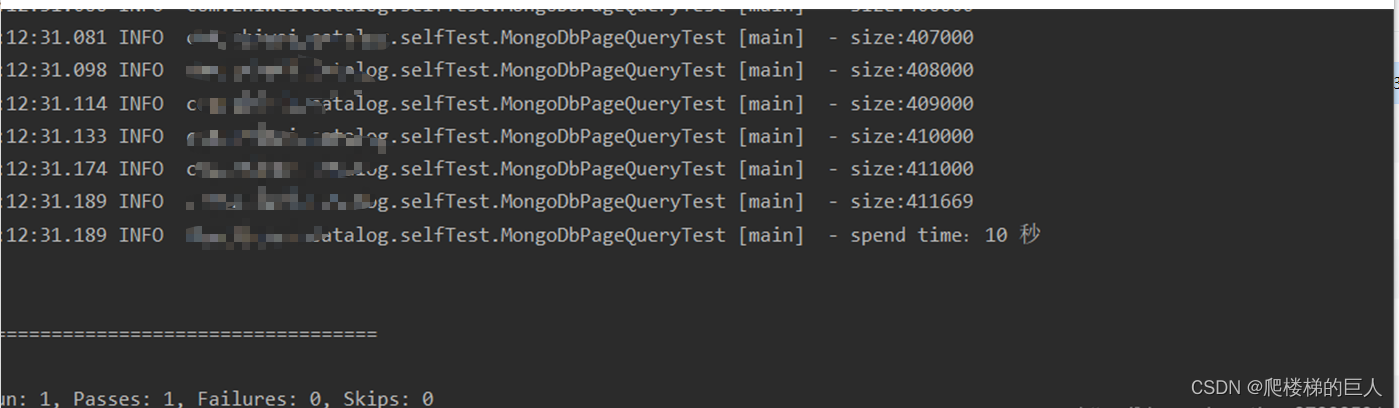
- 结论:
这里的逻辑跟第二种方法类似,只不过是每次翻页时直接返回最后一条数据,取其objectId(当然第一次的lastId为null,第一次翻页还是直接按照传统的skip与limit来翻页,当然如果你知道第一次翻页之前的objectId可以直接修改为传入就行),然后将其传入条件中,就可以达到更好的性能
我上面测试的都是以1000为一页的翻页大小,测试下来比之前的翻页快很多,当然如果你们有更好的方法,欢迎留言,留下代码,共同进步。
参考文献与博客:
【1】参考博客:亿级别记录的mongodb分页查询java代码实现
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/56082
推荐阅读
- 1.0移除链表元素、2.0反转链表、3.0链表中倒数第k个节点、4.0合并两个有序链表、5.0链表的回文结构、6.0环形链表、7.0相加链表JavaLeetCode篇-深入了解关于单链表的经典解法 ... [详细]
赞
踩
- 因为项目不方便直接发上来,所以大家需要源码的话就私我叭~_java和sqlserver2012课程设计‘java和sqlserver2012课程设计‘本科参与项目文档合集:点击跳转~学生管理系统StudentManagementSystem... [详细]
赞
踩
- 在本博文中,我们将探讨如何使用Java检查指定的秘钥是否存在于亚马逊S3存储桶中。AmazonS3是一个非常流行的云存储服务,为存储和检索数据提供了可伸缩、安全和高可用的平台。就个人而言,后续很多的公有云平台或者一些SaaS服务,都或多或少... [详细]
赞
踩
- 进来!只花五分钟学懂!采用分布式架构时,一次请求报错难以定位,分布式链路追踪技术来解决。【JAVA】分布式链路追踪技术概论目录1.概述2.基于日志的实现2.1.实现思想2.2.sleuth2.2.可视化3.基于agent的实现4.联系作者1... [详细]
赞
踩
- web3j是一个轻量级、高度模块化、响应式、类型安全的Java和Android类库提供丰富API,用于处理以太坊智能合约及与以太坊网络上的客户端(节点)进行集成。可以通过它进行以太坊区块链的开发,而无需为你的应用平台编写集成代码。web3j... [详细]
赞
踩
- 在本文中,我们将探索如何利用Java编程与AmazonS3(即简单存储服务)存储系统进行互动。需要牢记,S3的结构异常简单:每个存储桶能够容纳大量的对象,这些对象可以通过SOAP接口或REST风格的API进行访问。接下来,我们将使用适用于J... [详细]
赞
踩
- article
java.net.NoRouteToHostException No route to host的排查与解决思路分享_caused by: java.net.noroutetohostexception: no rou
 那问题肯定就出在这个datanode22中了,经过简单的测试发现,在HiveSQL的执行过程中,hadoop的心跳时间经常很大,整个hadoop集群的心跳超时时间设置为600S(这个值设置的非常大,其实是有点不合理的),在web页面上能看见... [详细]
那问题肯定就出在这个datanode22中了,经过简单的测试发现,在HiveSQL的执行过程中,hadoop的心跳时间经常很大,整个hadoop集群的心跳超时时间设置为600S(这个值设置的非常大,其实是有点不合理的),在web页面上能看见... [详细]赞
踩
- article
解决思路:java.lang.IllegalArgumentException: Invalid character found in method name. HTTP method names
然后,我们设置了请求方法为POST,并设置了请求头部信息,包括Content-Type和Accept。通过检查代码中的方法名、使用合适的HTTP请求方法常量、使用第三方HTTP库、检查请求URL以及使用调试和日志工具,我们可以解决这个异常并... [详细]赞
踩
- Java中虽然已经内置了丰富的异常类,但是并不能完全表示实际开发中所遇到的一些异常,此时就需要维护符合我们实际情况的异常结构.if(!thrownewuserNameException("用户名错误");if(!thrownewpassWo... [详细]
赞
踩
- 假设第一个元素已经排序好了的,在已经排好的元素的后一个元素记录为low,这个low索引对应的元素需要用临时变量来接受,只要找到比这个索引对应的元素小的值,就可以插入到比它小的值的后一个索引位置了,当然,每一次对比之后,都需要往后移一个位置,... [详细]
赞
踩
- 在文件的最上方加上一个package语句指定该代码在哪个包中.包名需要尽量指定成唯一的名字,通常会用公司的域名的颠倒形式例如包名要和代码路径相匹配.例如创建的包,那么会存在一个对应的路径来存储代码.如果一个类没有package语句,则该类被... [详细]
赞
踩
- Set接口继承自Collection接口,并添加了一些针对无序集合的操作。它不允许重复的元素,并提供了添加、删除和检查元素是否存在的方法。在Java中,Set接口有几个常见的实现类,每个实现类都具有不同的性能和用途。HashSet:基于哈希... [详细]
赞
踩
- 本人使用idea创建web工程后,运行tomcat服务器时出现报错:Error:CouldnotcreatetheJavaVirtualMachine.EDDisconnectedfromserverError:Afatalexceptio... [详细]
赞
踩
- article
Failed to obtain JDBC Connection; nested exception is java.sql.SQLException_failed to obtain jdbc connection; nested exception
FailedtoobtainJDBCConnection;nestedexceptionisjava.sql.SQLException_failedtoobtainjdbcconnection;nestedexceptionisjava.s... [详细]赞
踩
 该博客教程旨在帮助初学者了解如何在Java前端和MySQL数据库之间建立连接。通过简单易懂的指导,教程覆盖了从前端到后端的完整流程。首先,它介绍了Java编程语言的基础知识,为初学者提供了必要的背景。接着,教程引导读者学习如何使用Java中... [详细]
该博客教程旨在帮助初学者了解如何在Java前端和MySQL数据库之间建立连接。通过简单易懂的指导,教程覆盖了从前端到后端的完整流程。首先,它介绍了Java编程语言的基础知识,为初学者提供了必要的背景。接着,教程引导读者学习如何使用Java中... [详细]赞
踩
- 开发工具:Eclipse/IDEAJDK版本:jdk1.8Mysql版本:5.7Java+Swing+Mysql主要功能包括1.管理学生信息,其中包括添加,删除,修改等操作。2.管理课程信息,其中包括添加,删除,修改等操作。3.管理选课信息... [详细]
赞
踩
 掌阅科技:深耕优质内容优化数字阅读体验掌阅科技股份有限公司成立于2008年9月,专注于数字阅读,是全球领先的数字阅读平台之一。掌阅主营业务为互联网数字阅读服务及增值服务,同时从事网络原创文学版权运营,以及基于自有互联网平台的流量增值服务,服... [详细]
掌阅科技:深耕优质内容优化数字阅读体验掌阅科技股份有限公司成立于2008年9月,专注于数字阅读,是全球领先的数字阅读平台之一。掌阅主营业务为互联网数字阅读服务及增值服务,同时从事网络原创文学版权运营,以及基于自有互联网平台的流量增值服务,服... [详细]赞
踩
- 要出栈时,如果栈二不为空,就出栈二中的元素,如果栈二为空,将栈一中的所有元素一次性的全部push到栈二中,此时就将入栈的元素全部倒转过来了,(例如入栈时在栈中的入栈顺序依次排序为182535,栈二中此时的元素入栈顺序是352518,出栈时就... [详细]
赞
踩
 Java19的未来:新特性、性能优化和更多Java19的未来:新特性、性能优化和更多目录 前言 新特性的引入1.模式匹配的扩展 2.增强的模式匹配异常处理 3.基于记录的反射 4.引入静态方... [详细]
Java19的未来:新特性、性能优化和更多Java19的未来:新特性、性能优化和更多目录 前言 新特性的引入1.模式匹配的扩展 2.增强的模式匹配异常处理 3.基于记录的反射 4.引入静态方... [详细]赞
踩
- SSM框架是Spring、SpringMVC和MyBatis的集合,它简化了企业级应用的开发,提高了开发效率。通过微信平台,我们可以方便地进行沟通、协作和共享资源,为现代企业提供了一种高效、便捷的办公解决方案。管理员主要负责用户管理、部门管... [详细]
赞
踩
相关标签

