
热门标签
热门文章
- 1ChatGPT高效提问—prompt常见用法(续篇三)
- 202机器学习基础-特征工程概念_特征值和目标值的区别
- 3python微信公众号推送_python爬虫_微信公众号推送信息爬取的实例
- 4b站尚品汇学习笔记_lodash uuid
- 5华为OD机试真题 Python实现【最小的调整次数】【2023Q1 100分】_特异性的双端队列 最小的调整次数python
- 6素数快速求法_素数 加速计算
- 72020年物联网发展现状与趋势预测
- 8全网最细!PyCharm 详细使用指南,果断收藏了_pycharm使用手册
- 9webstorm、vscode、HBuilder配置eslint检查
- 10Manjaro Linux 17.0.2 KDE环境安装、配置记录_pacman aria2
当前位置: article > 正文
Python爬取新浪微博实操_爬虫能看到私密微博吗
作者:数据可视化灵魂 | 2024-02-03 15:01:11
赞
踩
爬虫能看到私密微博吗
第一步:选择从手机端爬取
新浪微博手机端地址:https://m.weibo.cn/
登录自己的微博账号。
第二步:爬取刘亦菲的微博为例:
2.1获取需要爬取微博的Request_URL,以及构造网络请求的User_Agent和Cookies:
右键-检查,刷新网页,Network,size排序,
其中Request_URL就是我们需要爬取微博的请求地址,如图:
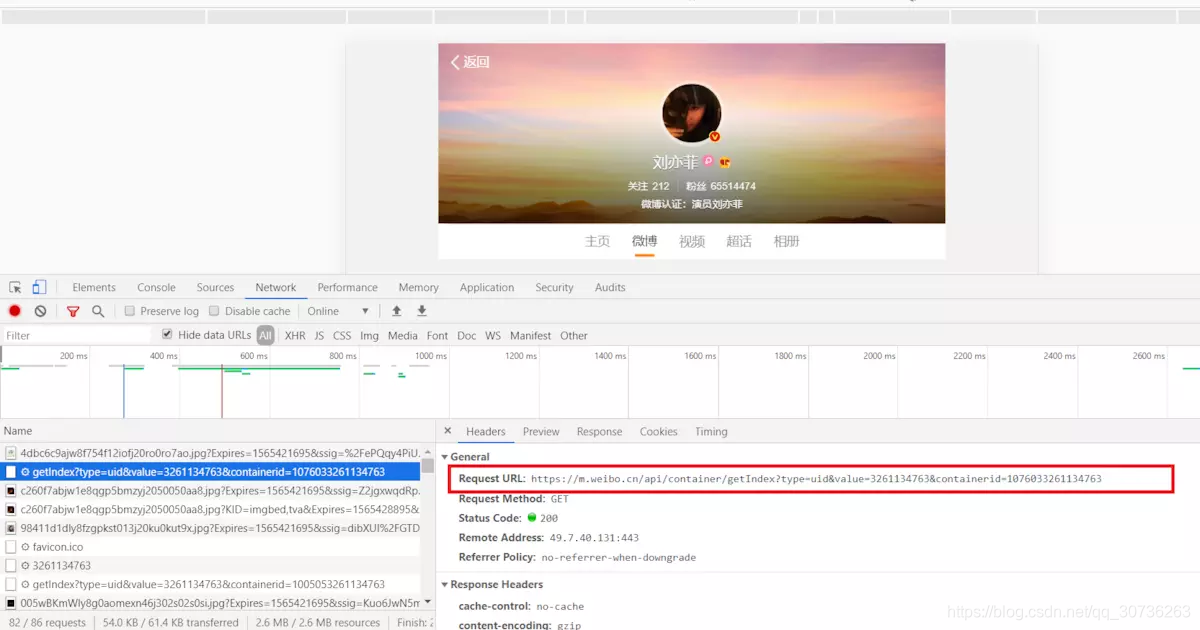
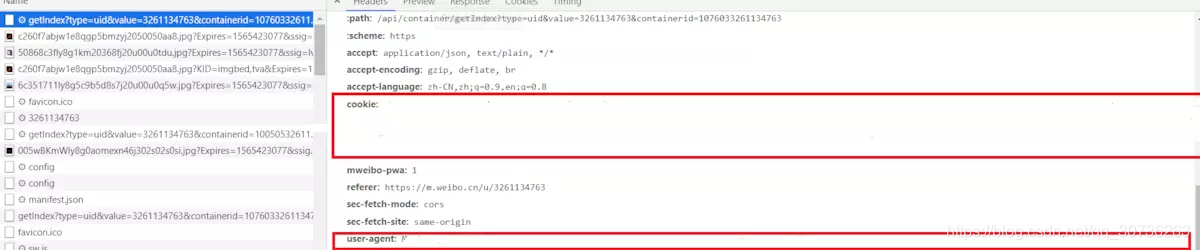
User_Agent和Cookies:
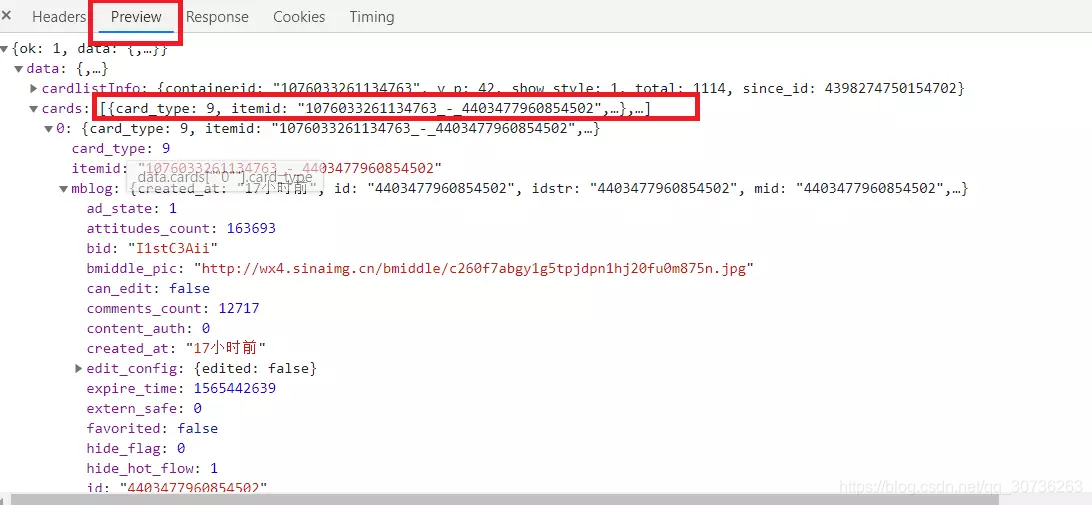
2.2点击Preview,微博的信息存储在card_type=9的列表中,
譬如刘亦菲的这条微博:
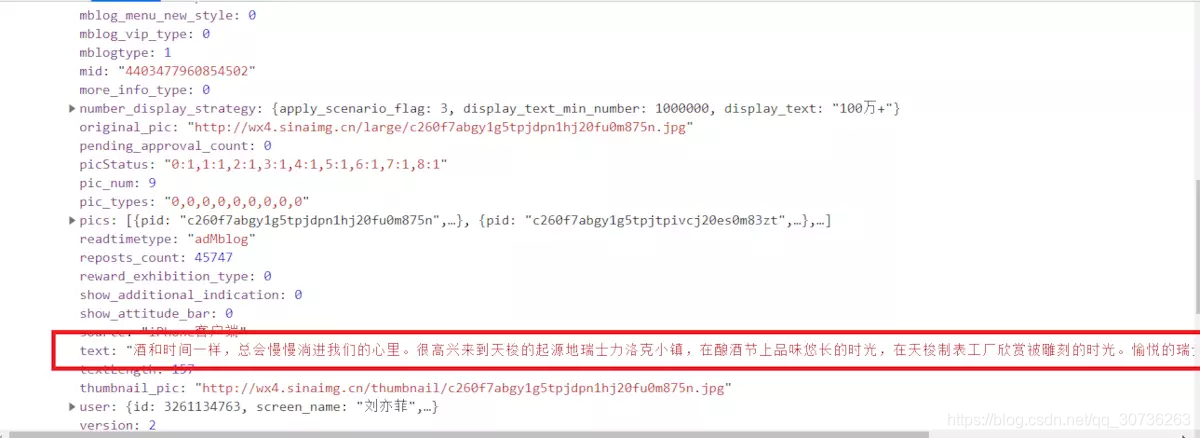
第三步:具体的代码如下:
import requests from bs4 import BeautifulSoup import json import re import time #1:使用正则表达之去除html标签 def filter_tags(htmlstr): #先过滤CDATA re_cdata=re.compile('//<!\[CDATA\[[^>]*//\]\]>',re.I) #匹配CDATA re_script=re.compile('<\s*script[^>]*>[^<]*<\s*/\s*script\s*>',re.I)#Script re_style=re.compile('<\s*style[^>]*>[^<]*<\s*/\s*style\s*>',re.I)#style re_br=re.compile('<br\s*?/?>')#处理换行 re_h=re.compile('</?\w+[^>]*>')#HTML标签 re_comment=re.compile('<!--[^>]*-->')#HTML注释 s=re_cdata.sub('',htmlstr)#去掉CDATA s=re_script.sub('',s) #去掉SCRIPT s=re_style.sub('',s)#去掉style s=re_br.sub('\n',s)#将br转换为换行 s=re_h.sub('',s) #去掉HTML 标签 s=re_comment.sub('',s)#去掉HTML注释 s=s.replace('网页链接','') return s headers = {'user-agent': '自行补充' } cookies = {'cookies': '自行补充' } url_1 = input ( "请输入微博博主的url:" + str() ) i = 1 count = 1 while True: url = url_1 + '&page=' + str(i) req = requests.get(url, headers=headers, cookies=cookies) text = req.text try: content = json.loads(text).get('data') cards = content.get('cards') if (len(cards)>0): for j in range(len(cards)): card_type = cards[j].get('card_type') if (card_type == 9): mblog = cards[j].get('mblog') attitudes_count=mblog.get('attitudes_count') comments_count=mblog.get('comments_count') created_at=mblog.get('created_at') reposts_count=mblog.get('reposts_count') scheme=cards[j].get('scheme') text1=mblog.get('text') text2=filter_tags(text1) print ( str(count) + "\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text2+"\n") count = count + 1 i = i + 1 time.sleep(5) else: break except Exception as e: print (e) pass

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
第四:执行上段代码:

程序比较粗糙,仅做新手练习。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/57060
推荐阅读
 一、命令行安装pyecharts模块1、安装过程2、命令行验证pyecharts模块是否安装成功二、PyCharm安装pyecharts模块1、通过错误提示安装2、在Settings设置界面安装【Python】pyecharts模块②(命令... [详细]
一、命令行安装pyecharts模块1、安装过程2、命令行验证pyecharts模块是否安装成功二、PyCharm安装pyecharts模块1、通过错误提示安装2、在Settings设置界面安装【Python】pyecharts模块②(命令... [详细]赞
踩
- 最近,用Python给单位里用的“智慧食堂”系统编制了一个餐卡充值文件生成器,自动匹配餐卡号并快速生成导入数据用的Excel表格......使用tkinterToplevel控件弹出子窗口,用作设置备注的子窗口。_toplevelpytho... [详细]
赞
踩
- 随着软件规模和复杂性的增加,手动测试变得越来越繁琐且容易出错。自动化测试通过脚本化测试用例,能够更迅速、一致地验证软件的功能和性能。Selenium是一款强大的自动化测试工具,而Python语言则因其简洁性和易读性而成为自动化测试的首选之一... [详细]
赞
踩
 UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]
UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]赞
踩
- 爬取斗鱼直播照片保存到本地目录【附源码】【python】爬取斗鱼直播照片保存到本地目录【附源码+文末免费送书】一、导入必要的模块: 这篇博客将介绍如何使用Python编写一个爬虫程序,从斗鱼直播网站上获取图... [详细]
赞
踩
- 本文展示如何使用库在Python中使用Excel文件。openpyxl是用于读取和写入Excel2010xlsx/xlsm/xltx/xltm文件的Python库。_pythonopenpyxlpythonopenpyxl各位好,我是轩哥啊... [详细]
赞
踩
- 每2秒获取一次UI控件的内容,实测挂在后台对CPU和内存占用并无明显影响,结合Pythonuiautomation的各种用法,可以做成自动回复的功能。Pythonuiautomation是一个用于自动化GUI测试和操作的库,它可以模拟用户操... [详细]
赞
踩
- UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]
赞
踩
 如何使用Pycharm进行远程开发只要连接上服务器就能开始干活儿,不用折腾环境,不占用个人笔记本资源,最重要的是不用忍受笔记本的烂风扇噪音。PythonIDEPycharm服务器配置方法并结合内网穿透工具实现远程开发文章目录一、前期准备1.... [详细]
如何使用Pycharm进行远程开发只要连接上服务器就能开始干活儿,不用折腾环境,不占用个人笔记本资源,最重要的是不用忍受笔记本的烂风扇噪音。PythonIDEPycharm服务器配置方法并结合内网穿透工具实现远程开发文章目录一、前期准备1.... [详细]赞
踩
- 【代码】Python面试:单元测试unittesting。Python面试:单元测试unittesting&使用pytest1.对于函数进行单元测试calc.pydefadd(x,y):"""AddFunction"""returnx+yd... [详细]
赞
踩
 讲解Python实现串口通信的过程和代码,实现了发送字符串(utf-8)数据和十六进制(hex)数据的串口通信,并且与自制stm32核心板实现了串口通信,并在OLED屏上显示通信数据。文章中有完整项目的下载链接。_python串口通信pyt... [详细]
讲解Python实现串口通信的过程和代码,实现了发送字符串(utf-8)数据和十六进制(hex)数据的串口通信,并且与自制stm32核心板实现了串口通信,并在OLED屏上显示通信数据。文章中有完整项目的下载链接。_python串口通信pyt... [详细]赞
踩
- 你还可以使用RGB颜色模式自定义颜色。要指定自定义颜色,可传递参数c,并将其设置为一个元组,其中包含三个0~1之间的小数值,它们分别表示红色、绿色和蓝色分量。值越接近0,指定的颜色越深,值越接近1,指定的颜色越浅。关于“Python”的核心... [详细]
赞
踩
- 可能性最大的点数不是一个,而是5个,这是因为导致出现最小点数和最大点数的组合都只有一种(1和1以及6和10),但面数较小的骰子限制了得到中间点数的组合数:得到总点数7、8、9、10和11的组合数都是6种。接下来,我们设置hist的属性tit... [详细]
赞
踩
- UI自动化测试实践,随着云计算时代的进一步深入,越来越多的中小企业企业与开发者需要一款简单易用、高能高效的云计算基础设施产品来支撑自身业务运营和创新开发。基于这种需求,华为云焕新推出华为云云服务器实例新品。这边文章由我带大家走一遍华为云云耀... [详细]
赞
踩
- YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。YOLO(YouOnlyLookOnce)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。Y... [详细]
赞
踩
- 大创项目推荐深度学习疲劳检测驾驶行为检测-pythonopencvcnn文章目录0前言1课题背景2相关技术2.1Dlib人脸识别库2.2疲劳检测算法2.3YOLOV5算法3效果展示3.1眨眼3.2打哈欠3.3使用手机检测3.4抽烟检测3.5... [详细]
赞
踩
- 全球麦穗检测是植物表型分析领域的一个挑战,主要目标是检测图像中的小麦麦穗。这种检测在农业领域具有重要意义,可以帮助农民评估作物的健康状况和成熟度。然而,由于小麦麦穗在视觉上具有挑战性,准确检测它们是一项艰巨的任务。全球麦穗检测的挑战在于准确... [详细]
赞
踩
- OD,全称(OutsourcingDispacth)模式,目前华为和德科联合招聘的简称。华为社招基本都是OD招聘,17级以下都是OD模式(13-17)。_华为od机试-2023真题-考点分类华为od机试-2023真题-考点分类华为OD机考:... [详细]
赞
踩
- 2022.11开始机试应该是换新题库了,优先更新最新的题目。_华为od机试好过吗华为od机试好过吗 各语言题库: 【Python+JS+Java合集】【超值优惠】:Py/JS/Java合集【Python】:P... [详细]
赞
踩
- 项目运行环境配置:Jdk1.8+Tomcat7.0+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:SSM+mybatis+Ma... [详细]
赞
踩
相关标签

