
- 1Python江西南昌二手房源爬虫数据可视化分析大屏全屏系统 开题报告
- 2从4k到42k,软件测试工程师的涨薪史,给我看哭了
- 3linux centos 系统盘文件系统损坏-已解决_corruption of in-memory data detected
- 4【Linux】公网远程访问AMH服务器管理面板
- 5IOS 查看安装包的公钥 SHA1等信息
- 6IDEA常用插件(30个)_idea插件
- 7【微服务】服务网关----Gateway_gateway 服务覆盖
- 8代码随想录刷题题Day29
- 9什么是云服务器,阿里云优势如何?
- 10周志华:“数据、算法、算力”人工智能三要素,在未来要加上“知识”| CCF-GAIR 2020...
[爬虫] B站番剧信息爬取_抓取b站追番数据
赞
踩
申明:本文对爬取的数据仅做学习使用,不涉及任何商业活动,侵删
简述
本次爬取目标是:
- 番剧的基本信息(名字, 类型, 集数, 连载or完结, 链接等)
- 番剧的参数信息(播放量, 点赞, 投币, 追番人数等)
- 时间信息(开播时间, 完结时间)
前提条件
- 编程语言: Python 3
- 爬虫框架: Scrapy 1.6.0
- 编译器: Pycharm
- 平台: Windows
一丶页面分析
番剧索引页展示的番剧信息属于动态渲染, 因此要通过获取页面响应来得到我们想要的数据, 按F12到Network中找我们需要的响应数据:


来分析一下Request URL, 先无事其他的参数, 来看我们最需要的一部分: page=1&...&pagesize=20
page:表示当前页码pagesize:表示页面展示的番剧数
可以尝试访问Request URL, 来确认可以拿到我们需要的数据:

这一个请求并不能满足需求, 跟进番剧页链接, 并继续找响应数据:


几乎所有的数据都被我们得到了, 但唯独缺一个番剧类型
跟进番剧简介网址:https://www.bilibili.com/bangumi/media/md102392, 这是一个静态页面, 可以直接从响应中获取到我们需要的信息:
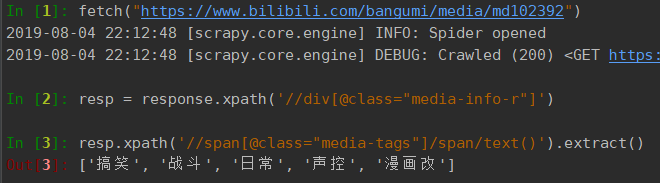
完成可数据源的分析, 接下来开始写代码
二丶创建爬虫
- 打开cmd控制台,然后cd+路径,移动到到期望的目录中,使用命令创建项目
scrapy startproject bilibili_spider,bilibili_spider为项目名称,创建完成后会自动生成下列文件:bilibili_spider__init__.pyscrapy.cfg#项目部署的配置文件bilibili_spider#项目目录, 包含了项目运行相关的文件__init__.pyitems.py#项目的目标文件middlewares.py#项目的中间件文件pipelines.py#项目的管道文件settings.py#项目的设置文件spiders#项目的爬虫目录__init__.py
- 创建爬虫文件,到bilibili_spider\bilibili_spider\spiders目录下,运行命令:
scrapy genspider bilibili bilibili.com,bilibili是爬虫文件的名称,后面是目标网站的域名, 由于本次爬取涉及的站点较多, 这里可以将www省略掉, 以避免出错
items.py
进入items.py文件中设置爬取的目标,基于python之禅简单生于复杂, 我将上述最后两次请求合并到一个, 即从番剧详情页获取评论数和评分
import scrapy class BilibiliSpiderItem(scrapy.Item): # 索引页的ajax 可以获得以下信息: season_id = scrapy.Field() # 番剧编号 media_id = scrapy.Field() # 媒体编号 title = scrapy.Field() # 标题 index_show = scrapy.Field() # 集数 is_finish = scrapy.Field() # 是否完结 video_link = scrapy.Field() # 链接 cover = scrapy.Field() # 封面图 pub_real_time = scrapy.Field() # 真实发布日期 renewal_time = scrapy.Field() # 最近更新日期 # 番剧信息的ajax请求: favorites = scrapy.Field() # 追番 coins = scrapy.Field() # 硬币 views = scrapy.Field() # 播放量 danmakus = scrapy.Field() # 弹幕 # 番剧详情页的ajax请求: cm_count = scrapy.Field() # 评论数 score = scrapy.Field() # 评分 media_tags = scrapy.Field() # 类型标签

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
爬虫文件
# -*- coding: utf-8 -*- import json from datetime import datetime import scrapy from scrapy.spiders import CrawlSpider from bilibili_video.items import BilibiliSpiderItem class BilibiliSpider(CrawlSpider): name = 'bilibili' allowed_domains = ['bilibili.com'] # 索引页的ajax request_url = 'https://bangumi.bilibili.com/media/web_api/search/result?page={}&season_type=1&pagesize=20' page = 1 start_urls = [request_url.format(page)] # 番剧信息的ajax请求 season_url = 'https://bangumi.bilibili.com/ext/web_api/season_count?season_id={}&season_type=1&ts={}' # 番剧详情页的ajax请求 media_url = 'https://www.bilibili.com/bangumi/media/md{}' def parse(self, response): # if self.page == 2: # 限制爬取页数,用于测试爬取状态 # return list_data = json.loads(response.text).get('result').get('data') if list_data is None: # 如果响应中没有数据,则结束执行 return for data in list_data: ts = datetime.timestamp(datetime.now()) yield scrapy.Request(url=self.season_url.format(data.get('season_id'), ts), callback=self.parse_details, meta=data) self.page += 1 # 生成下一页的请求 yield scrapy.Request(url=self.request_url.format(self.page), callback=self.parse) def parse_details(self, response): item = BilibiliSpiderItem() meta_data = response.meta item['season_id'] = meta_data.get('season_id') item['media_id'] = meta_data.get('media_id') item['title'] = meta_data.get('title') item['index_show'] = meta_data.get('index_show') item['is_finish'] = meta_data.get('is_finish') item['video_link'] = meta_data.get('link') item['cover'] = meta_data.get('cover') item['pub_real_time'] = meta_data.get('order').get('pub_real_time') item['renewal_time'] = meta_data.get('order').get('renewal_time') resp_data = json.loads(response.text).get('result') item['favorites'] = resp_data.get('favorites') item['coins'] = resp_data.get('coins') item['views'] = resp_data.get('views') item['danmakus'] = resp_data.get('danmakus') yield scrapy.Request(url=self.media_url.format(item['media_id']), callback=self.parse_media, meta=item) def parse_media(self, response): item = response.meta resp = response.xpath('//div[@class="media-info-r"]') item['media_tags'] = resp.xpath('//span[@class="media-tags"]/span/text()').extract() item['score'] = resp.xpath('//div[@class="media-info-score-content"]/text()').extract()[0] item['cm_count'] = resp.xpath('//div[@class="media-info-review-times"]/text()').extract()[0] yield item
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
项目源码链接:https://github.com/zhanghao19/bilibili_spider
- 上一节中创建了一个initclient包,封装了授权的过程,通过获取的myAPIClient对象可以直接调用API接口进行微博操作,上一节中就调用了发微博的接口发了一条新微博。这一节还是直接使用initclient包,调用获取关注好友或粉丝... [详细]
赞
踩
- 项目运行环境配置:Pychram社区版+python3.7.7+Mysql5.7+HBuilderX+listpip+Navicat11+Django+nodejs。项目技术:django+python+Vue等等组成,B/S模式+pych... [详细]
赞
踩
- 写在前面虽然说FetchAPI已经使用率已经非常的高了,但是在一些老的浏览器还是不支持的,而且axios仍然每周都保持2000多万的下载量,这就说明了axios仍然存在不可撼动的地位,接下来我们就一步一步的去封装,实现一个灵活、可复用的一个... [详细]
赞
踩
- 本文将深入探讨搭建Java开发环境的关键步骤和最佳实践。我们将涵盖Java开发工具的选择、集成开发环境(IDE)的配置、构建工具的使用,以及其他开发辅助工具。通过详细的步骤和实用的建议,读者将能够建立一个高效、舒适的Java开发环境。_ja... [详细]
赞
踩
- STM32的三种Boot模式地址分配一、STM32的三种Boot模式1、主闪存存储器2、系统存储器3、内置SRAM二、三种模式地址分配验证三级目录一、STM32的三种Boot模式三种boot启动模式:一般来说就是指我们下好程序后,重启芯片时... [详细]
赞
踩
- 项目介绍:食堂管理、商户管理、菜品管理、订单管理、用户管理页面效果:_python和mysql的gui外卖点餐系统python和mysql的gui外卖点餐系统项目介绍:食堂管理、商户管理、菜品管理、订单管理、用户管理页面效果:... [详细]
赞
踩
- 》适合显示小文件【行数比较少】,如果行数较多,屏幕显示不完整(如果虚拟操作,是无法上下键的,或者滚动鼠标的,第三方xsheel,crt可以方向键查看),前面的内容就不显示了。tail-20文件后20行或tail-n20文件效果一样。tail... [详细]
赞
踩
- 目录demo介绍流程问题demo介绍这个demo是在线训练了mnist的网络,然后直接用torch的nn.Module.state_dict()方法把weights取出来,填充给builder创建的trt格式的network,然后利用这个被... [详细]
赞
踩
- 两个或两个以上的AndroidApp可同时向同一输出流(比如手机的蓝牙、手机的喇叭)播放音频,系统会将所有音频流(就是音频数据了)混合在一起。这是一项有意思的技术,但却会出现混音。为了避免所有音乐应用同时播放,Android引入了“音频焦点... [详细]
赞
踩
- whistle,拼音[wēisǒu])基于Node实现的跨平台web调试代理工具,类似的工具有Windows平台上的Fiddler,主要用于查看、修改HTTP、HTTPS、Websocket的请求、响应,也可以作为HTTP代理服务器使用,不... [详细]
赞
踩
- bilibili用户信息爬虫Github:Leopard-C/BiliUserSpider0.成果bilibili御坂网络计划:https://misaka.sisters.top备用网址:https://misakasisters.bil... [详细]
赞
踩
- Student(S#,Sname,Sage,Ssex)学生表Course(C#,Cname,T#)课程表SC(S#,C#,score)成绩表Teacher(T#,Tname)教师表问题:1、查询“001”课程比“002”课程成绩高地所有学生... [详细]
赞
踩
- 上次写了篇python3网络爬虫–爬取b站视频评论用户信息(附源码)效果良好,因此再写一篇爬取用户投稿视频的爬虫,思路简单一些。不过本次将数据存储到了MySQL数据库。本次要实现:手动输入用户id,程序根据这个id爬取此用户的所有投稿视频,... [详细]
赞
踩
- 你可以根据具体的应用程序和需求进行调整和优化。使用多阶段构建(Multi-stageBuilds):使用多阶段构建可以减小最终镜像的大小。在第一个阶段中,可以使用完整的开发环境来构建应用程序,然后在下一个阶段中只复制构建好的应用程序文件,避... [详细]
赞
踩
- nacos作为服务配置中心和注册中心,SpringCloudGateway进行微服务路由常见集中方式的总结,阐述了各种方式的优缺点,以及作者认为的最优方式实现。并且有对应的项目进行测试。即使拿着这个项目(包括feign接口调用和websoc... [详细]
赞
踩
- 今时不同往日,openai的api已经到了1.xx版本,webui王者gradio也早就推出了chat集成,写一个基于ai的chat变得如此简单。OK,打完收工,如果对界面有更多要求,可以对ChatInterface的参数自行修改。1.xx... [详细]
赞
踩
- 这里写自定义目录标题为什么STM32从Flash地址0x08000000的启动而不是0x00000000?这是STM32F103ZE芯片存储空间的地址映射关系图。在MDK编译程序设置ROM和RAM地址时候发现:IROM1为片上程序存储器,即... [详细]
赞
踩
- 代码问题及对策路线图常见代码问题常见的潜在代码问题是当前直接会导致BUG、故障或者产品功能不能正常工作的类别。空值空值恐怕是最容易出现的地方之一。常见错误有:a.值为NULL导致空指针异常;b.参数字符串含有前导或后缀空格没有Trim导致查... [详细]
赞
踩
- 了解Rust变量的工作原理_rust的变量rust的变量文章目录1.Rust中的变量2.Rust的默认不可变变量(immutable)3.Rust的可变变量(mutable)4.Rust的常量(Constants)4.1.不惯着他会怎样5.... [详细]
赞
踩
- 一、测试活动-FlowControlAction1、功能Pause(暂停)/Stop(停止)/StopNow(立即停止)/Gotonextloopiteration(转到下一个循环迭代)二、调试取样器--debugsampler1、功能说明... [详细]
赞
踩

