
热门标签
热门文章
- 1知云文献翻译_知云文献安装步骤
- 2一、Selenium开篇之PyCharm安装selenium及浏览器驱动_pycham驱动
- 3区块链的共识与共识机制_区块链共识机制
- 4安卓系列机型 框架LSP 安装步骤 支持多机型 LSP框架通用安装步骤【二】_lsp框架和模块
- 5什么是自动化测试?自动化测试现状怎么样?_自动化测试行业现状
- 6【愚公系列】2023年12月 HarmonyOS应用开发者基础认证(完美答案)
- 7新版本android studio 2022.2.1 aidl的相关问题_android studio aidl灰色
- 8Go主流框架对比_go日志框架对比
- 92024华为OD机试真题目录汇总 B+C+D卷(484道)(Python语言)_java switch语句
- 10vue2引入Element UI组件去创建新页面的详细步骤--项目阶段2_新建vue页面
当前位置: article > 正文
OnnxRuntime TensorRT OpenCV::DNN性能对比(YoloV8)实测_yolo v8 dnn
作者:代码独立开发者 | 2024-02-03 18:54:17
赞
踩
yolo v8 dnn
1. 前言
之前把ORT的一套推理环境框架搭好了,在项目中也运行得非常愉快,实现了cpu/gpu,fp32/fp16的推理运算,同onnx通用模型在不同推理框架下的性能差异对比贴一下,记录一下自己对各种推理框架的学习状况
| 模型名称 | 参数量 |
|---|---|
| NANO | 3.2M |
| ... | ... |
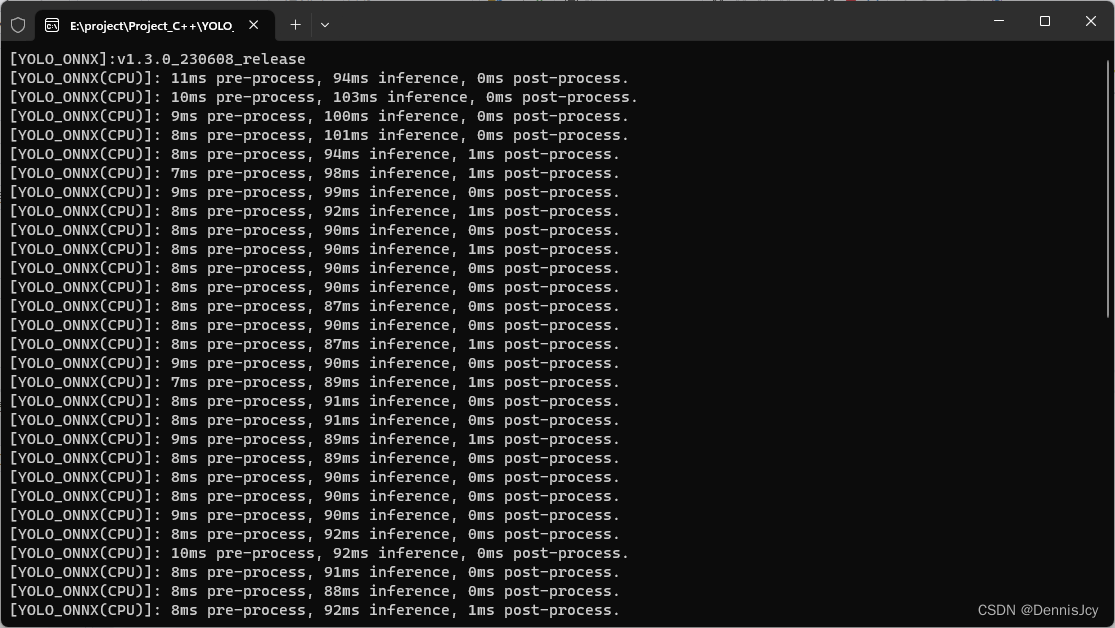
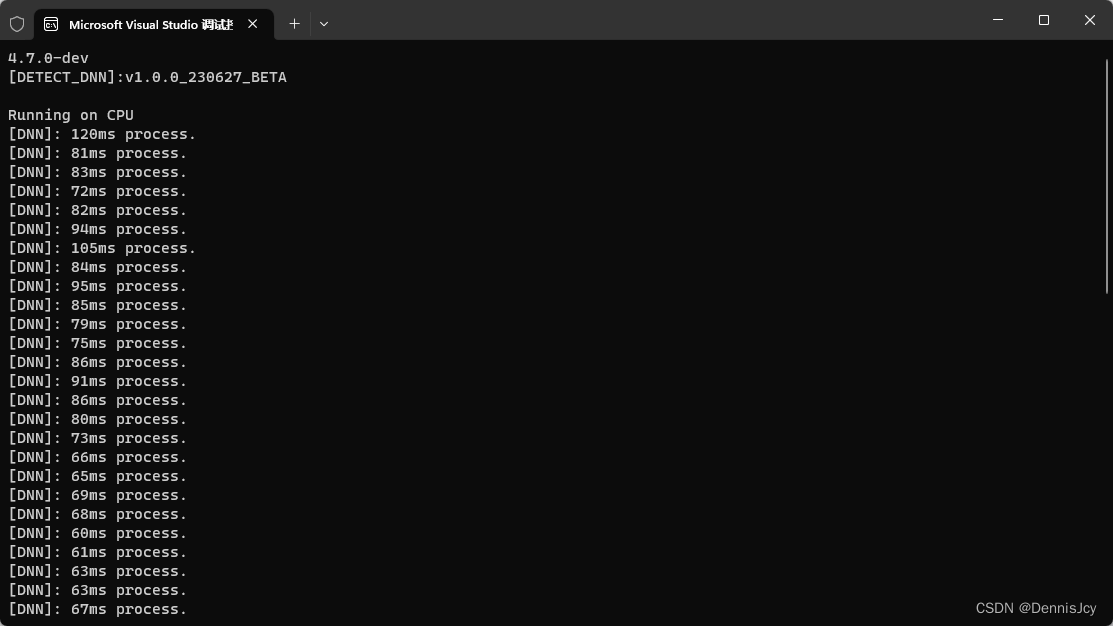
2. CPU篇
| 框架 | 推理耗时(i5-11400H@2.70GHz)/ms |
|---|---|
| OnnxRuntime | 95 |
| DNN | 80 |
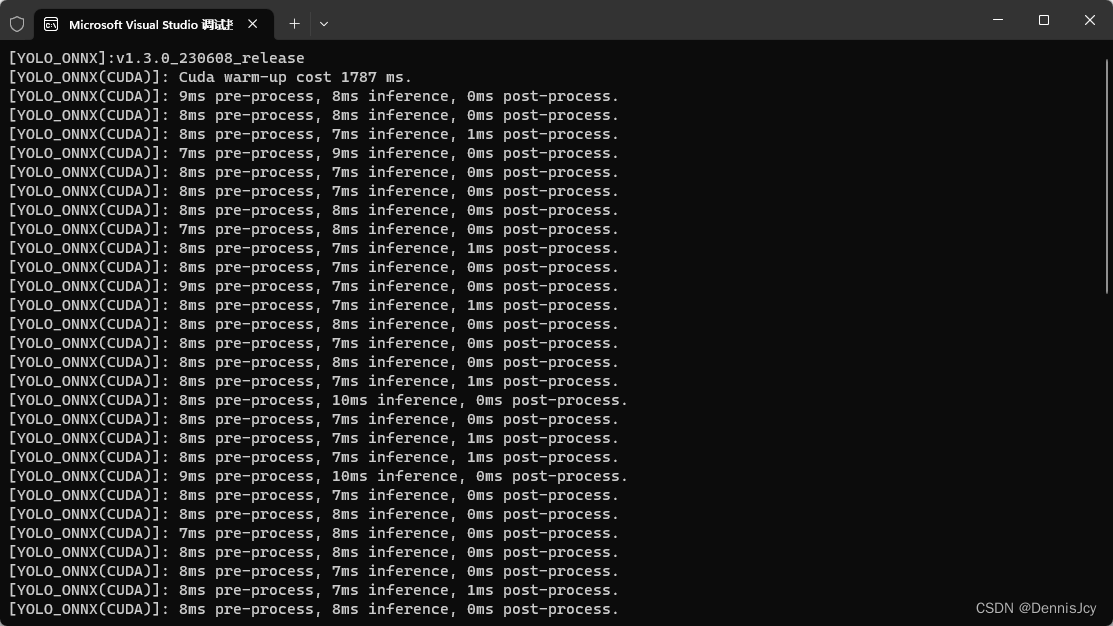
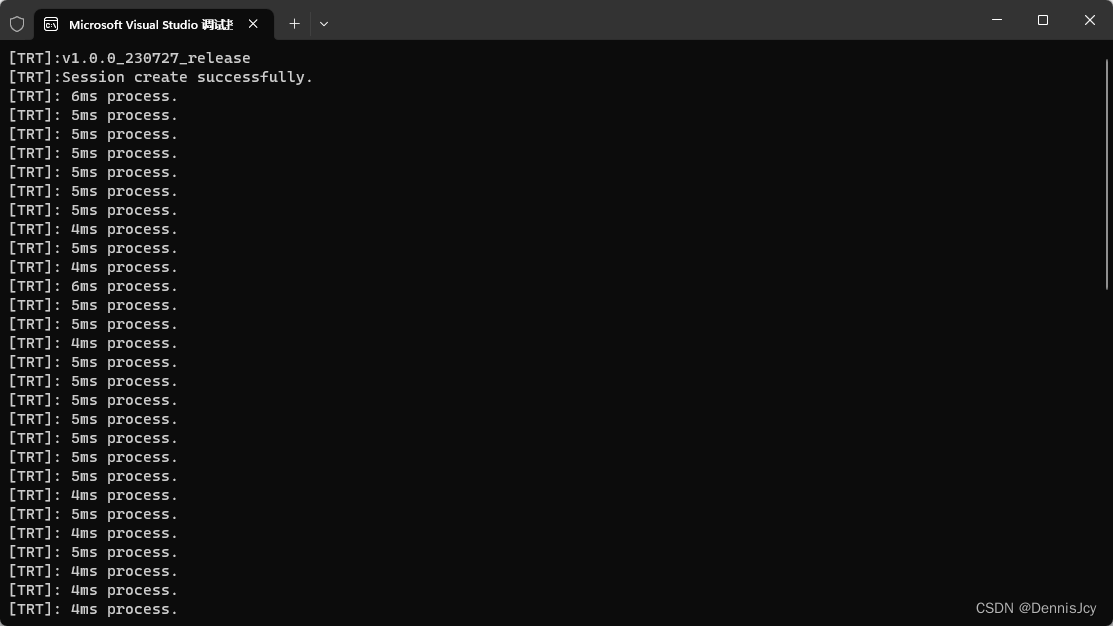
3. GPU篇
说明一下,懒得编译OpenCV的CUDA版了.也是菜,不想编译qwq
| 框架 | 推理耗时(RTX3050 LapTop)/ms |
|---|---|
| OnnxRuntime | 17 |
| TensorRT | 6 |
4. 总结
cpu选择onnxruntime或者dnn都可以,建议选择ort.gpu选择tensorrt,如果有兼容需求就只能选择onnxruntime了.
不得不说,gpu推理上TRT把ORT薄纱了,不需要warm-up,对工业生产环境非常友好,因为在实际生产环境中,都不是实时推理,而是有间隔的推理,ORT在一段间隔时间后cuda性能会有所衰减,当然也可能是我还没摸透ort这个框架,欢迎大佬指正.
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/blog/article/detail/57682
推荐阅读
- YOLOv8是一种物体检测算法,是YOLO系列算法的最新版本。YOLO(YouOnlyLookOnce)是一种实时物体检测算法,其优势在于快速且准确的检测结果。YOLOv8在之前的版本基础上进行了一系列改进和优化,提高了检测速度和准确性。Y... [详细]
赞
踩
- 全球麦穗检测是植物表型分析领域的一个挑战,主要目标是检测图像中的小麦麦穗。这种检测在农业领域具有重要意义,可以帮助农民评估作物的健康状况和成熟度。然而,由于小麦麦穗在视觉上具有挑战性,准确检测它们是一项艰巨的任务。全球麦穗检测的挑战在于准确... [详细]
赞
踩
 JetsonNano部署YOLOv5与Tensorrtx加速_jetsonyolojetsonyolo说在前面搞了一下Jetsonnano和YOLOv5,网上的资料大多重复也有许多的坑,在配置过程中摸爬滚打了好几天,出坑后决定写下这份教程供... [详细]
JetsonNano部署YOLOv5与Tensorrtx加速_jetsonyolojetsonyolo说在前面搞了一下Jetsonnano和YOLOv5,网上的资料大多重复也有许多的坑,在配置过程中摸爬滚打了好几天,出坑后决定写下这份教程供... [详细]赞
踩
- article
Jetson Xavier NX 下 yolov8 tensorrt模型部署(Jetpack5.1.2、CUDA11.4、Cudnn8.6.0、Tensorrt8.5.2)_yolov8在jetson上部署
JetsonXavierNX下yolov8tensorrt模型部署流程记录及问题处理,本文使用的是TensorRT-Alpha封装库,基于tensorrt+cuda,实现模型的gpu加速。_yolov8在jetson上部署yolov8在je... [详细]赞
踩
- yolov5+tensorrt+deepstream嵌入式平台加速推理目标检测。_jetsonyolov5jetsonyolov5JetsonNano学习——Yolov5+TensorRT+Deepstream前言一、安装torch&... [详细]
赞
踩
- 就可以继续安装拉,当安装opencv时会出现Buildingwheelforopencv-python(pyroject.toml),就说明快要成功拉,但是会很慢,不要着急!8、安装torchvision,逐个执行以下命令(如果执行第三个命... [详细]
赞
踩
- 在JetsonOrinNanoCLB上安装Yolov5有必要记录一下过程,以便后续无脑重装,让我们开始。_jetsonnano部署yolov5jetsonnano部署yolov5 在网上找了好多... [详细]
赞
踩
- 为了在JetsonNano上部署YOLOv5,您需要以下步骤:安装NVIDIAJetsonNano开发套件。安装必要的依赖项,包括OpenCV、TensorFlow和其他库。下载YOLOv5源代码,并编译它。训练模型,或下载预先训练的模型。... [详细]
赞
踩
- 1)iAFF加入Neck替代Concat;2)Conv替换为GhostConv;3)加入C3Ghost;YOLOv8-Seg改进:特征融合系列篇|多尺度特征融合iAFF,提升小目标检测能力|轻量级创新高效结合GhostConv... [详细]
赞
踩
- article
YOLOv8/YOLOv7/YOLOv5/YOLOv4/Faster-rcnn系列算法改进【NO.77】引入百度最新提出RT-DETR模型中AIFI模块_yolov8、v5、 fasterrcnn 改进插件rt-detr
引入百度最新提出RT-DETR模型中AIFI模块_yolov8、v5、fasterrcnn改进插件rt-detryolov8、v5、fasterrcnn改进插件rt-detr 前言作为当前先进的深度学习目标检测算法YOLOv8,已... [详细]赞
踩
- yolov8的环境搭建,和自定义训练集如何训练_yolov8训练自己的数据集yolov8训练自己的数据集记录一下yolov8的环境搭建,后续会更新v8模型的代码详解以及涨点改进策略。conda环境直接去yolov8官网:... [详细]
赞
踩
- YOLOv8是Ultralytics最新的基于YOLO的目标检测模型系列,提供最先进的性能。_yolov8训练自己的数据集yolov8训练自己的数据集本文实现了俩种环境的设置,一种是windows的CPU版本,还有服务器上的GPU版本。CP... [详细]
赞
踩
- YOLOv8是一种基于深度神经网络的目标检测算法,它是YOLO(YouOnlyLookOnce)系列目标检测算法的最新版本。YOLOv8的主要改进包括:更高的检测精度:通过引入更深的卷积神经网络和更多的特征层,YOLOv8可以在保持实时性的... [详细]
赞
踩
- 至此,整个训练预测阶段完成。此过程同样可以在linux系统上进行,在数据准备过程中需要仔细,保证最后得到的数据准确,最好是用显卡进行训练。有问题评论区见!_yolov8训练自己的数据集yolov8训练自己的数据集目录0、引言1、环境准备2、... [详细]
赞
踩
- 准备一份YOLO系列的数据集,这里就不演示voc转txt了,自己准备一个现成的就好。如果玩过YOLOv5的,数据集直接可以拿来用。数据集放在YOLOv8的大目录下data.yaml文件放在如图目录下yaml的格式可以仿照YOLOv8里的co... [详细]
赞
踩
- 图1.1:YOLOv8初始测试YOLOv8????于2023年1月10日由Ultralytics发布。它在计算机视觉方面提供了进展,带来了对我们感知、分析和理解视觉世界的巨大创新。它将为各个领域带来前所未有的可能性。在速度、准确性和架构方面... [详细]
赞
踩
 基于opencvC++推理yolov8模型(onnx),完整代码_yolov8c++yolov8c++TensorRT系列之Windows10下yolov8tensorrt模型加速部署TensorRT系列之Linux下yolov8tenso... [详细]
基于opencvC++推理yolov8模型(onnx),完整代码_yolov8c++yolov8c++TensorRT系列之Windows10下yolov8tensorrt模型加速部署TensorRT系列之Linux下yolov8tenso... [详细]赞
踩
- TensorRT通过优化深度学习模型来提高推理速度,减少延迟。这对于实时处理应用(如视频分析、机器人导航等)至关重要。:TensorRT优化了模型以在GPU上高效运行,这意味着更低的内存占用和更高的吞吐量。对于资源受限的环境或在多任务并行处... [详细]
赞
踩
- 该文主要是对yolov8的检测、分类、分割、姿态应用使用c++进行dll封装,并进行调用测试。_c++部署分类c++部署分类该文主要是对yolov8的检测、分类、分割、姿态应用使用c++进行dll封装,并进行调用测试。0.模型准备openv... [详细]
赞
踩
- article
【Yolov8 Opencv C++系列保姆教程】Yolov8 opencv c++ 版本保姆教程,Yolov8训练自己的数据集,实现红绿灯识别及红绿灯故障检测 ,红绿灯故障识别。_用c++ 调用 yolov8
Yolov8OpencvC++系列保姆教程,通过一个红绿灯识别的案例,实现了Yolov8的应用全流程的过程,整个算法最终只依赖了opencv,部署会更加方便、易用。基于Yolov8训练自己的数据集,实现红绿灯识别及红绿灯故障检测,红绿灯故障... [详细]赞
踩
相关标签

