
- 1HCIA H12-211题库解析_如下图所示,主机a和主机b不能通信。
- 2求无向图中的三元环个数_枚举三元环
- 3python系列之炫酷新年烟花秀_importpygamefromrandomimportrandint,uniform,choice
- 4【Android辟邪】之:gradle——在项目间共享依赖关系版本
- 5RuntimeError: There were no tensor arguments to this function (e.g., you passed an empty list of Ten_notimplementederror: there were no tensor argument
- 6小米9开源linux内核,发布即开源:小米开源新机Mi 11内核源码
- 7如何写好大模型提示词?来自大赛冠军的经验分享(基础篇)_大模型帮忙写小结 提示词
- 8Android开发面试经——常见人事面试问题_android面试技术总监问什么
- 9中国人工智能城市排名榜TOP 10公布;宁德时代将授权现代摩比斯使用CTP技术 | 美通社头条...
- 10MVC、MVP、MVVM模式的概念与区别_mvc mvp mvvm区别
OpenMMLab-AI实战营第二期——2-1.人体关键点检测与MMPose_人体关键点检测 全连接分类
赞
踩
文章目录
视频链接:B站-人体关键点检测与MMPose
1. 人体姿态估计的介绍和应用

关键点提取,属于模式识别

人体姿态估计的下游任务:行为识别(比如:拥抱。。)
下游任务:CG和动画,这个是最常见的应用

下游任务:人机交互(手势识别,依据收拾做出不同的响应,比如:HoloLens会对五指手势(3D)做出不同的反应)
2-1. 2D姿态估计概述
包括:
- 自顶向下方法
- 自底向上方法
- 单阶段方法
- 基于Transformer的方法
2.1 任务描述

2D人体姿态估计的任务:
- 输入:一张包含人体的图像
- 输出:人体关键点(主要关节)的坐标(2D的)
注意,这里的输出是固定对应(预定义的)18个关节的坐标,就是要找这18个位置的坐标
2.2 基于回归
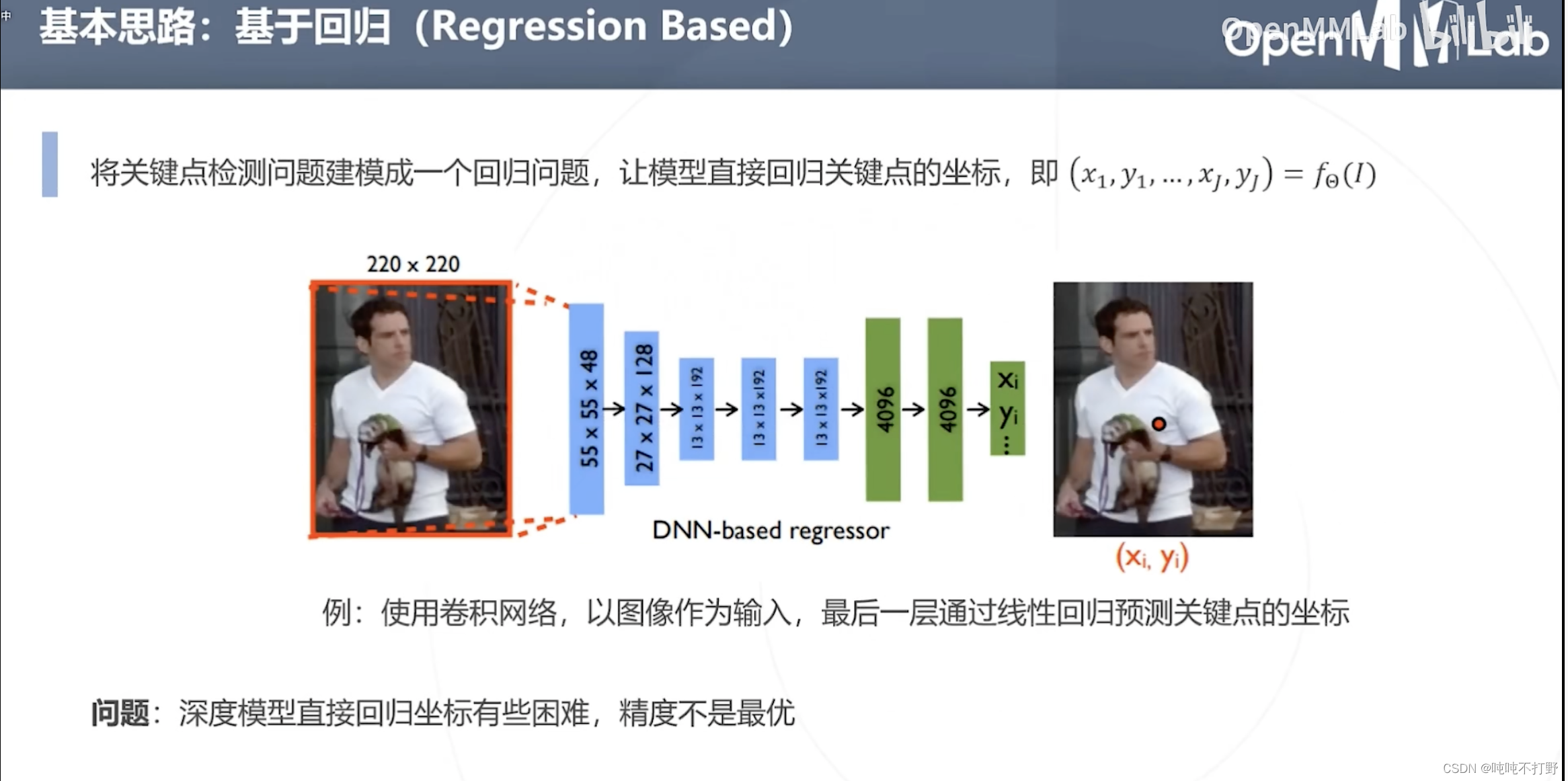
使用深度学习的模型直接回归坐标有些困难,精度不是最优(效果不好)
2.3 基于热力图
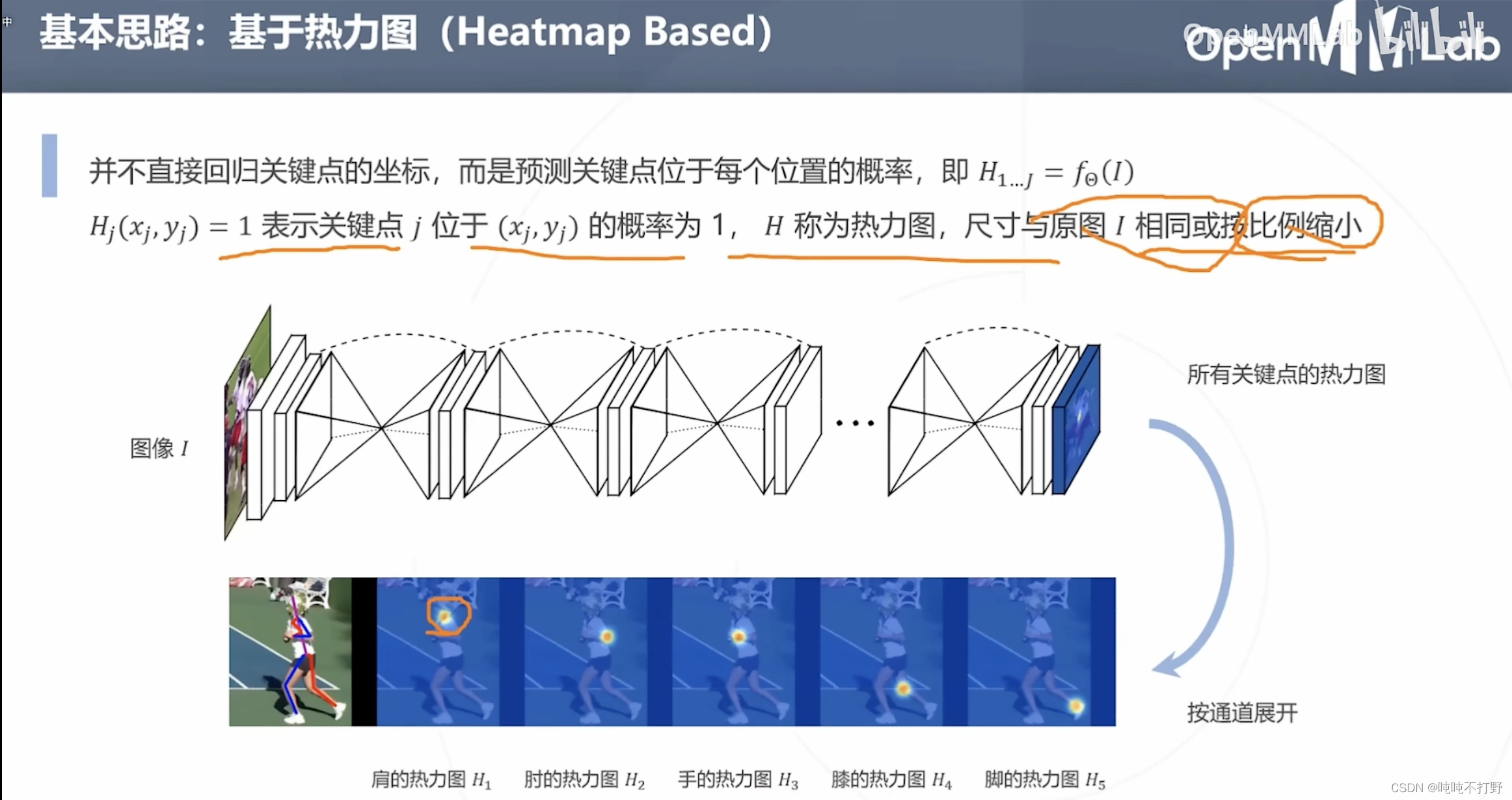
另一种思路是:不直接回归关键点的坐标,而是预测关键点位于每个位置的概率。
- 比如肩的热力图(越靠近肩膀的预定义的关键点,概率越高,颜色逐渐从黄色变成红色)
- 18个关键点,对应18个热力图

基于热力图天然符合神经网络的卷积算子(对每个像素都进行计算,得到每个像素的概率)
2.3.1 从数据标注生成热力图(高斯函数)
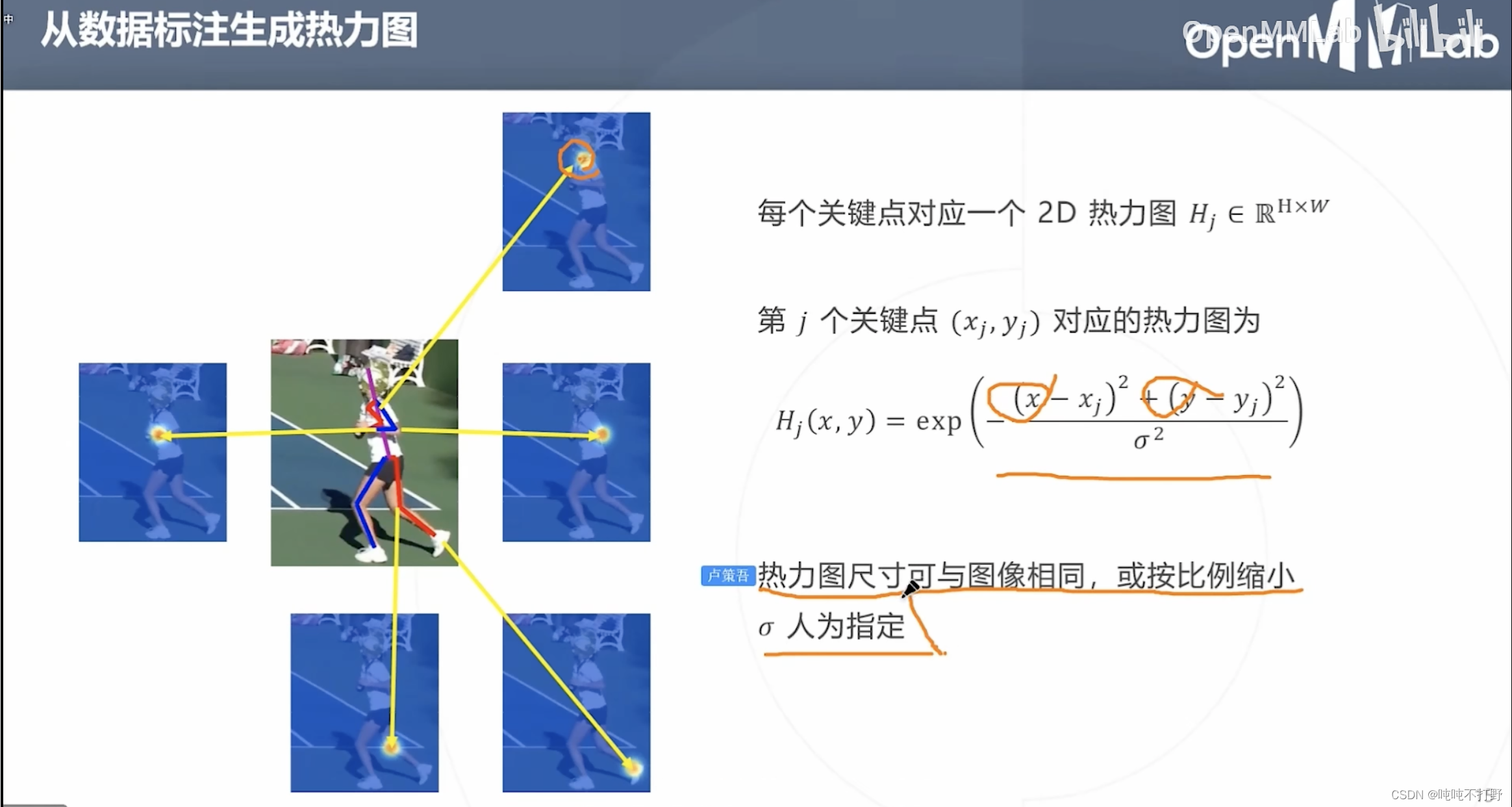
如果想要使用基于热力图的方式,那么首先要根据已有的标注数据生成热力图。
- 预定义的关键点附近区域的概率其实符合这一事实:
- 越靠近预定义的关键点,概率越高,如上图,颜色逐渐从黄色变成红色
- 假设上面这个热力图区域是个圆形,那么任意一个直径作为 x x x轴(距离预定义关键点的距离作为自变量),是关键点的概率作为 y y y轴(因变量),则可以用高斯函数来描述 x x x和 y y y的关系
- 所以这里是假设关键点区域的热力图符合高斯分布,来生成热力图(概率图),来进行训练。
- 所以这里说热力图的尺寸,即作为控制高斯函数图像钟的宽度的 σ \sigma σ参数,也就是控制热力图区域大小
复习一下高斯函数(红色线代表标准正态分布):

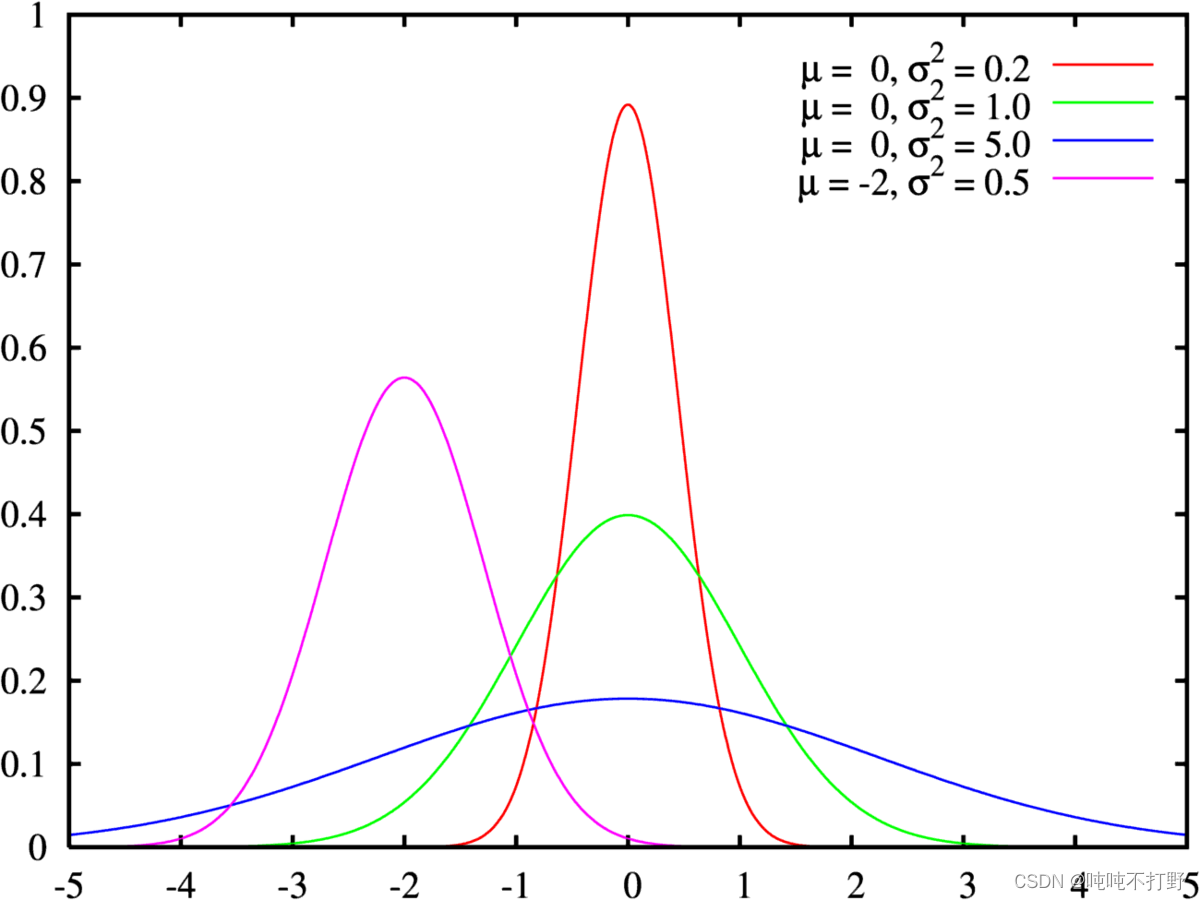
上图是用期望值及方差作为参数表示的高斯曲线
高斯函数是正态分布的密度函数,下图的红色是标准正态分布
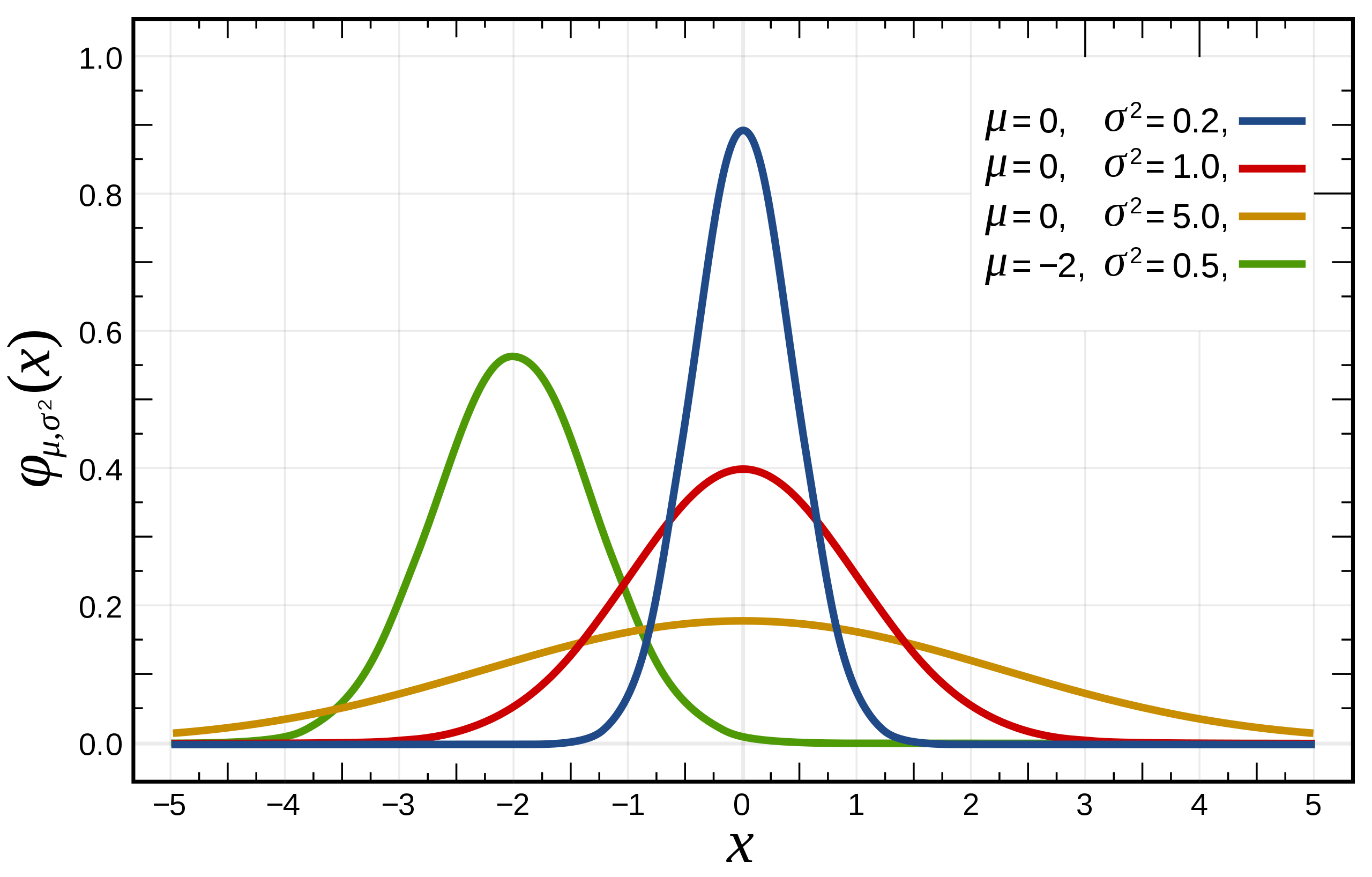
正态分布的数学期望值或期望值
μ
μ
μ等于位置参数,决定了分布的位置;其方差
σ
2
\sigma^2
σ2的开平方或标准差
σ
\sigma
σ 等于尺度参数,决定了分布的幅度。
可以直接看:
- 中文wiki百科-高斯函数
- 中文wiki百科-正态分布
- 打不开上面这个看下面转载的这个,旧了点,但是意思差不多:高斯分布(Gaussian distribution)/正态分布(Normal distribution)
2.3.2 使用热力图训练模型
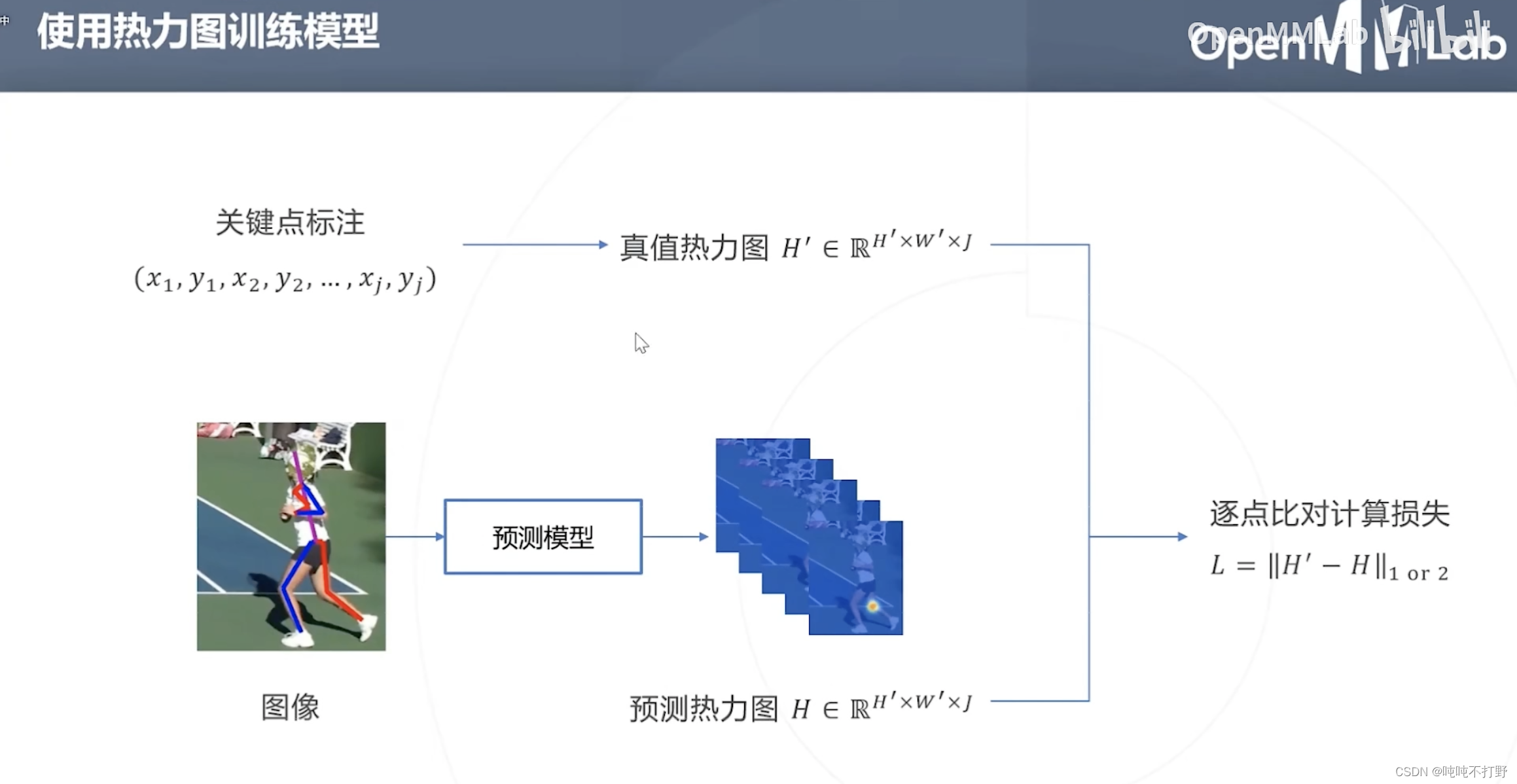
将通过关键点标注生成的真值热力图,作为True label,与预测模型预测出来的热力图Predict label逐点比对(就是关键点附近那一小片区域的热力图),计算损失
所以基于热力图的方法关键就是中心点位置
(
x
j
,
y
j
)
(x_j,y_j)
(xj,yj)(训练目标,优化的参数)和区域大小
α
\alpha
α(可以是超参,也可以基于图像缩放得到,缩放系数也是超参)
- 这里其实是一个2D的高斯函数, ( x j , y j ) (x_j,y_j) (xj,yj)其实就对应上面高斯函数图像的最高点
- 即,真值热力图的构建函数需要满足:距离关键点越近,概率越大,所以高斯函数天然满足这个性质
- 除此之外,其实只要是类似钟形都可以,下面这个抛物线函数,还有我随便造的一个绝对值函数,其实都满足这个条件(但是概率取值范围[0,1]需要进一步处理一下才行)
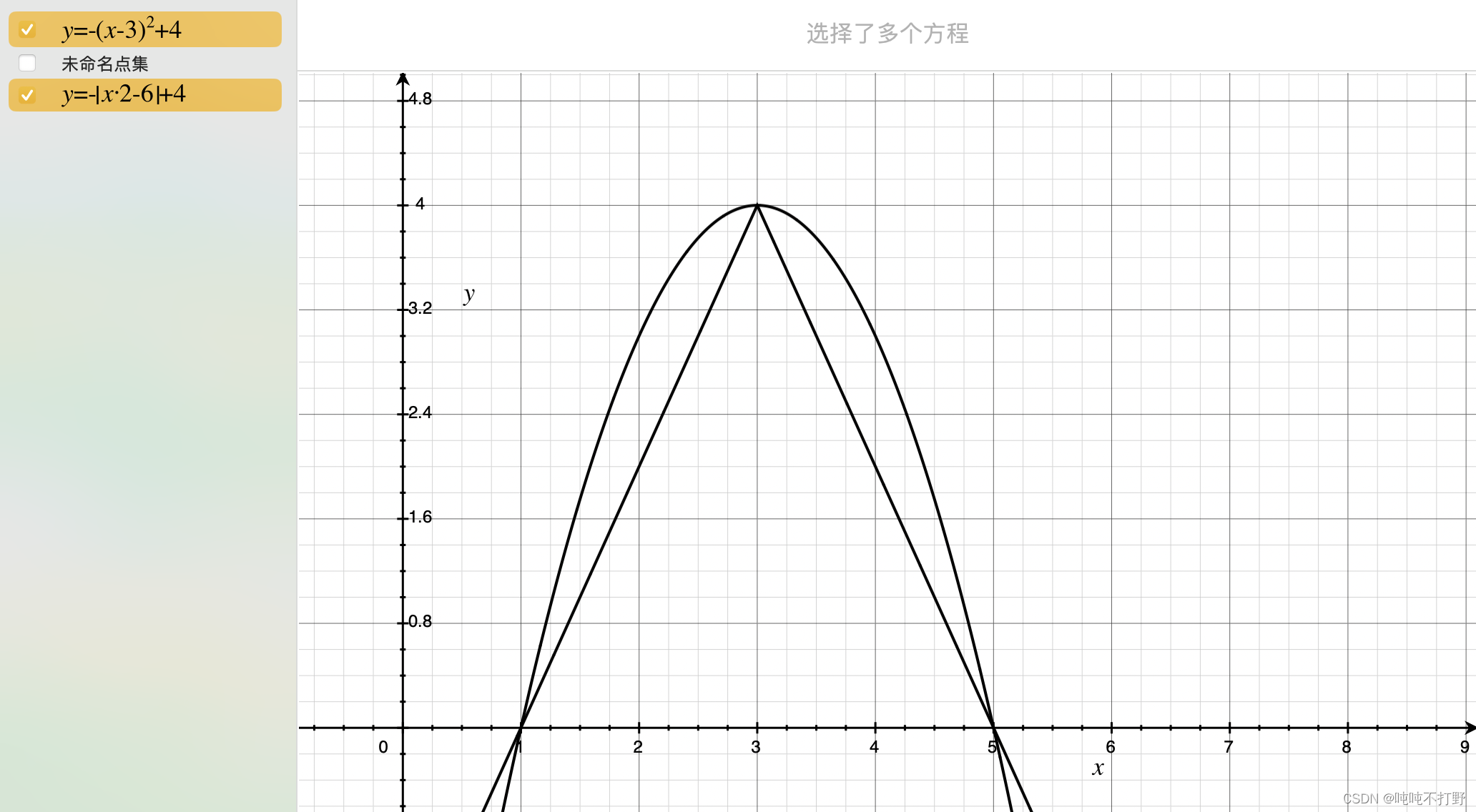
2.3.3 从热力图还原关键点

- 最直接的办法就是求最大概率(热力图最大值)对应的位置的坐标,
- 按照生成真值热力图的方式来倒推,是很合理的方式
- 但这是基于:预测的热力图符合高斯函数,这一假设下的推论
- 实际上,可能预测的热力图形状不会那么规整,可能会有多个最大值,所以直接求1个最大值这种方式不够鲁棒

另一种从热力图还原关键点的方式就是:
- 先对热力图的概率进行归一化(对概率用softmax,输出的还是概率),用归一化后的概率计算位置的期望
- 期望就是平均值,在1D的高斯函数图像中,高斯函数的最高点,对应的 x x x值,确实是 x x x取值范围的均值。
- 可能不一定能取到最高点,但是能取到"重心",这样利用了整个热力图的概率,相对于上面只看热力图的最大概率,就会比较鲁棒,
这种计算方式还有很好的一个性质:
- 可以进行端到端的训练,还原关键点的方式的公式,是可以求导的,所以能和整个训练过程串起来。
- 比如,一开始训练的时候,网络初始化时,使用的是随机数作为关键点来生成初始预测热力图,第一轮训练完成后,得到生成的热力图,就可以得到一个矫正过的关键点,以此来作为第二轮使用的热力图的初始值,继续迭代。
- ❓❓❓但是上面优化的时候只使用热力图的loss, 但是真实关键点和预测关键点也都可以拿到,关键点的loss其实也可以加上去。两种损失一起会更好吗??
2.4 自顶向下

上面讲的是单人的姿态估计,但是也会有多人姿态估计
最直观的一种方式(自顶向下):
- 先目标检测,得到每个人(检测器的精度需要保证)
- 再对每个人进行 单人姿态估计
模型串联的坏处,
- 姿态估计结果会过分依赖人体目标检测的结果
- 速度和计算量和画面中的人数成正比
2.5 自底向上

自底向上方法:先把关键点检测完,再去聚类其属于哪个人
优点:
- 推理速度和画面中的人数无关
- 关键点多,则检测速度肯定也会慢一些。但不会像自顶向下方法一样与人数成正比,人数越多的时候,自底向上比自顶向下方法快的越明显)
- 聚类耗时肯定是和人数成正比的
2.6 单阶段方法
2-2. 2D姿态估计详细说明
2.1 基于回归的自顶向下方法
2.1.1 经典方法

以分类网络为基础,将最后一层分类改为回归,一次性预测所有J个关键点的坐标
- 如果是人体姿态估计的话,就是18个关键点的坐标,在2D场景下,也就是要预测36个数字。。。(回归36个数字,可比分类36个类要难,目标检测里也有回归box四个坐标的方法)
- 原始论文是用AlexNet主干+回归头做的,主干(backbone)也可以换成ResNet等结构
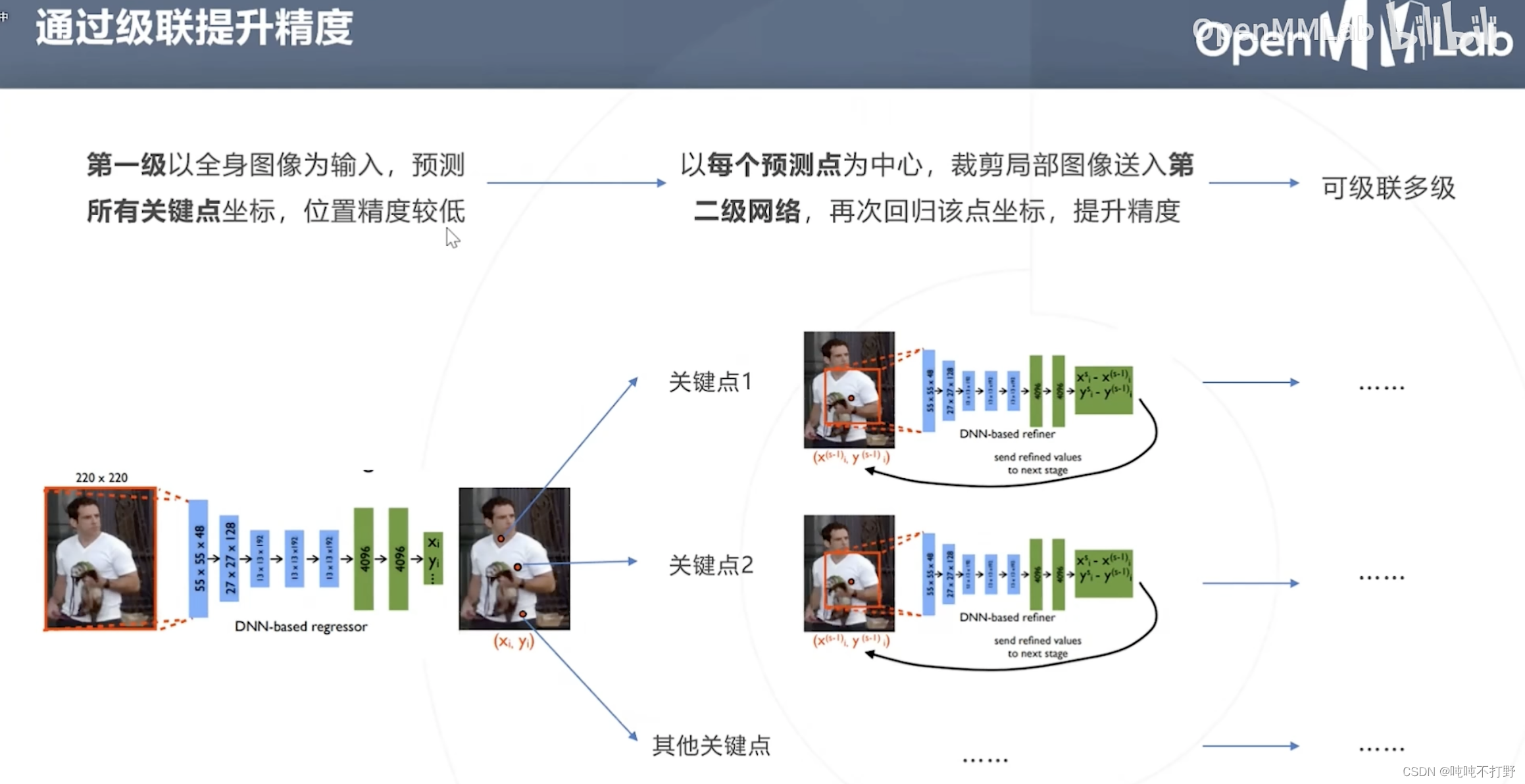
网络结构不变的情况下,使用级联模型的方式,来提高精度。
- 第一级,输入:全身图像
- 第二级,输入:第一步预测点为中心的裁剪后的局部区域
类似医疗影像分割里的级联:
- 第一级,输入:医疗影像
- 第二级,输入:医疗影像+第一级得到的概率图

优势:
- 回归模型理论上可以达到无限精度,热力图方法的精度受限于特征图的空间分辨率(也不一定,加个期望上去有时候也可以突破这个限制)
- 回归模型不需要维持高分辨率特征图,计算更高效。相比之下,热力图方法的特征图的size不能低于热力图的size,所以热力图方法确实要计算和存储高分辨率特征图,计算成本(硬件要求)更高
劣势:
- 图像到关键点坐标的映射是高度非线性的,导致直接回归坐标,比通过热力图(概率)得到坐标更难,同时回归方法的精度也低于热力图,因此DeepPose提出之后很长一段时间,2D关键点预测算法主要都是基于热力图的。
2.1.2 基于最大似然估计的改进(RLE)

之前的基于回归方法的姿态估计,
- 损失函数为:真实关键点位置
μ
g
\mu_g
μg与模型预测关键点位置
μ
~
\tilde\mu
μ~的误差作为损失
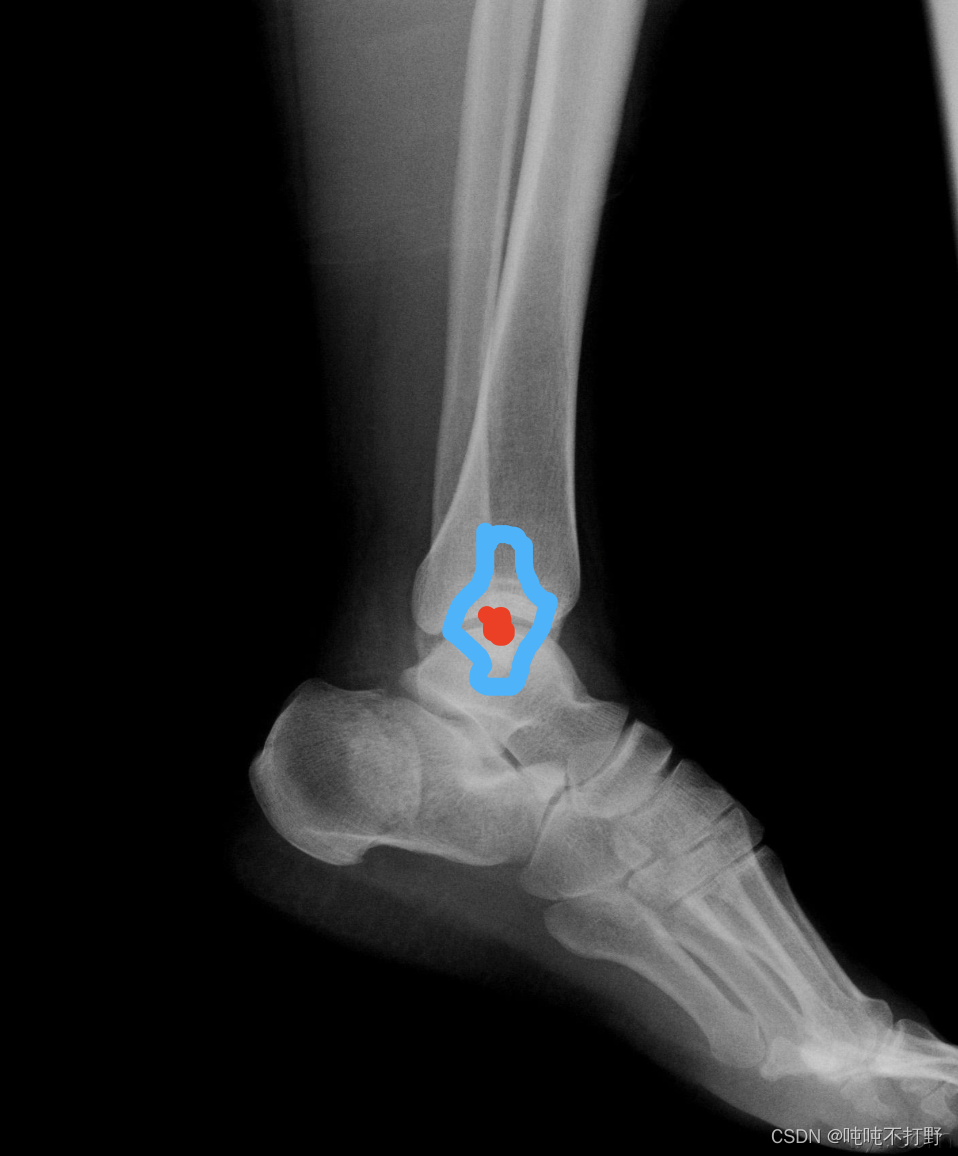
- 这背后隐含了高斯分布的假设,即:预测点距离关键点越近,就越好,因此以关键点为圆心,相同半径圆周上的点作为预测点,其误差都是一样的。即:认为预测点分布在真实点形成的一个圆形里。
- 但是实际上,人体的关节有不同的形状如下图:踝关节,红色是关键点,蓝色围成的区域就是分布,不是个圆形,不是只靠一个方向的距离就可以衡量误差的(每个方向距离引起的误差在损失函数中权重应该是不同的):
另外,下面这篇文章创新点的部分,要先去看下面的背景知识,看完就基本就懂这个创新点了。

- 模型给出基础分布的参数
- RLE模块基于标准化流,给出位置的分布
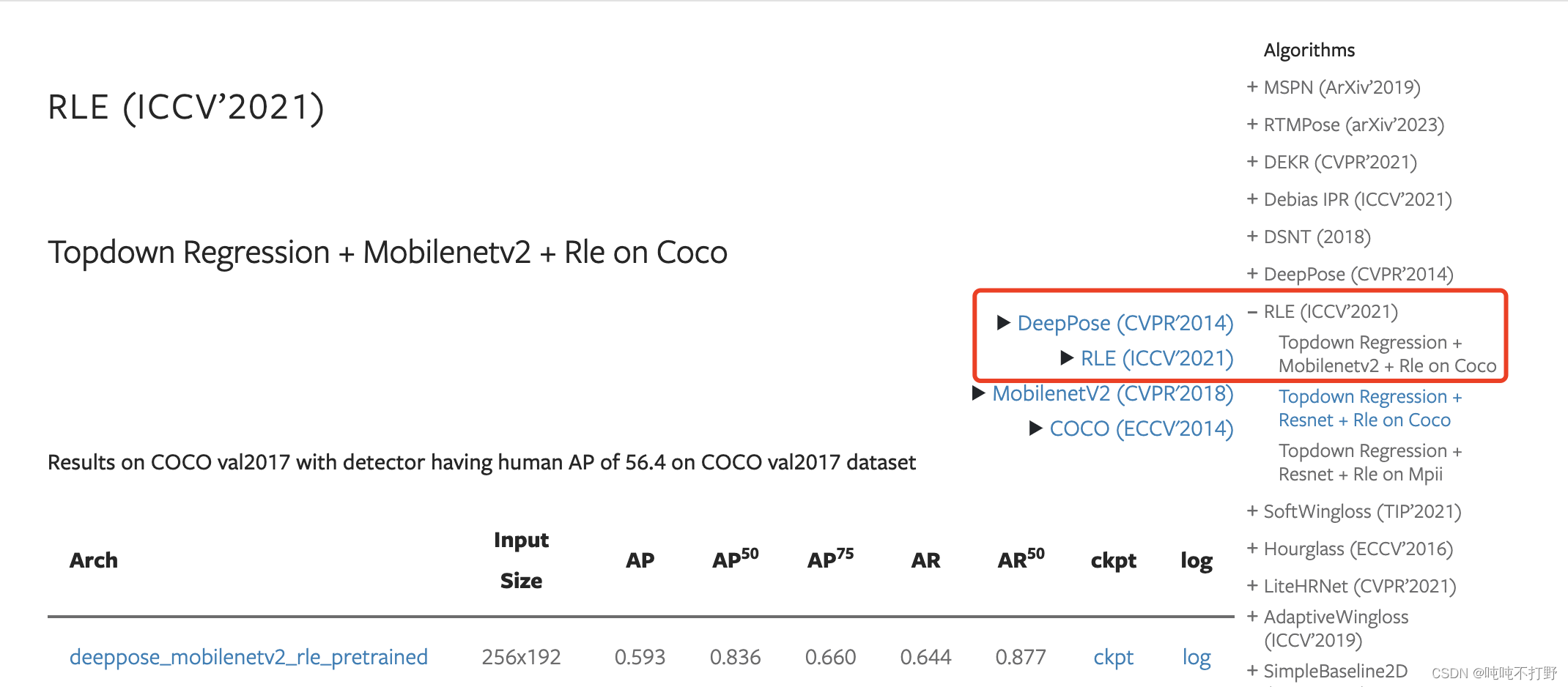
论文就直接在MMPose里找了,这里Topdown Regression + Mobilenetv2 + Rle on Coco
论文arxiv链接:Human Pose Regression with Residual Log-likelihood Estimation
2.1.2 背景知识-回归和最大似然估计的联系

- 关于二范数(L2-norm损失函数)这个名词,可以看看:区分混淆概念之L2范数,L2范数损失,L2损失,均方误差
- 如上面的右图,使用二范数(最小二乘误差/最小平方误差)进行回归
- 其实隐含了 关键点位置 符合 固定方差的各向同性的高斯分布 的假设,但是实际上,在真实的人体关节,关键点的位置并不一定符合高斯分布
- 因此RLE的关键在于:
- 将简单的高斯分布替换为一个可学习的、表达能力更强的分布(用在损失函数上),来更好指导模型学习真实的关键点位置分布。
- 因为基于高斯分布假设的回归误差,和高斯似然下的最大似然估计是等价的
- 注意,这里的二范数误差回归的各向同性高斯分布,是基于回归的方法用在损失函数上的;但是原理和基于热力图的方法里,使用标注关键点生成热力图的思想是类似的。
2.1.2 背景知识-标准化流Normalizing Flow
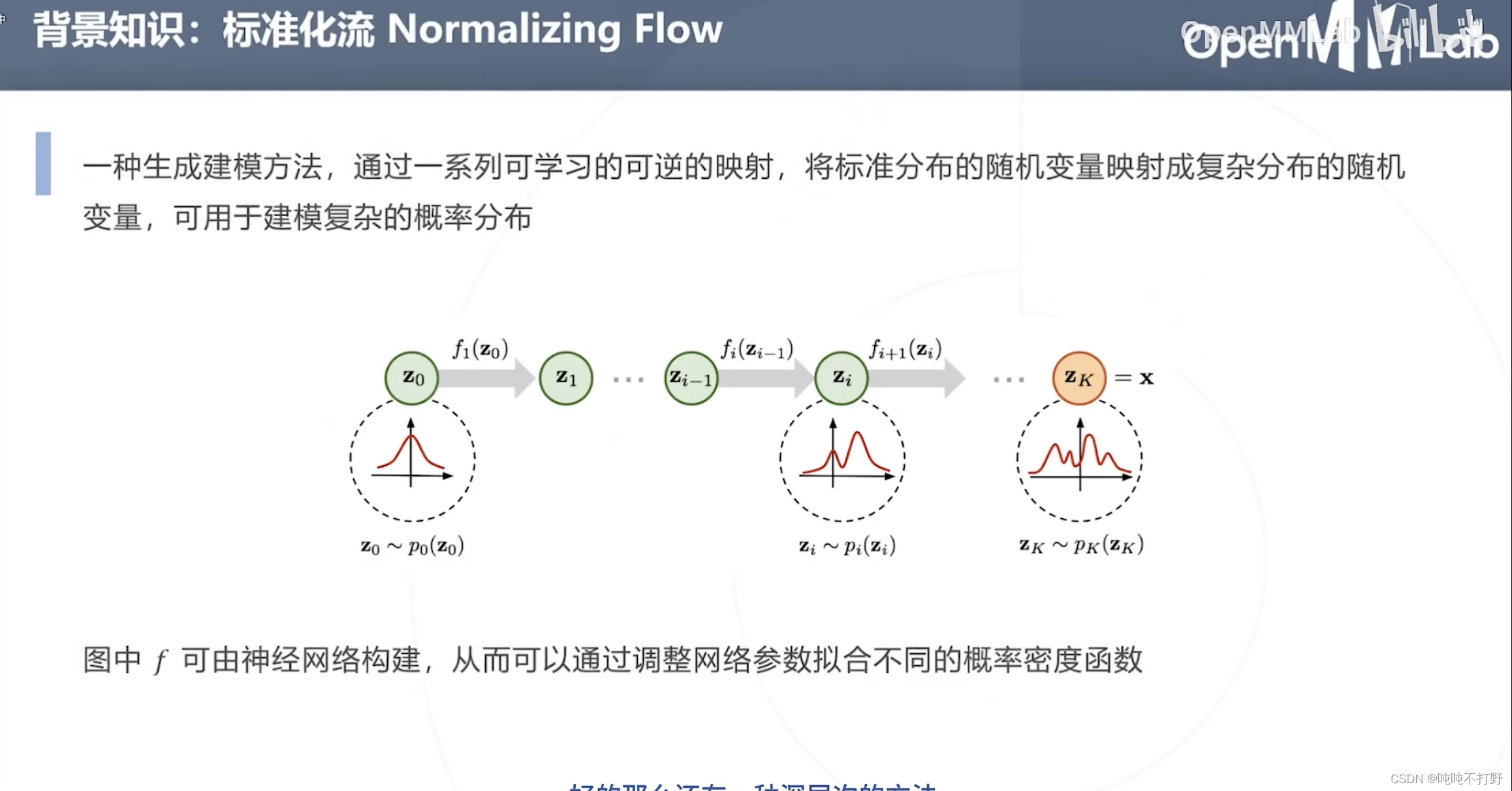
标准化流Normalizing Flow:
- 一种生成建模方法,通过一系列可学习的可逆的映射( f f f是学习出来的,同时要满足是可逆的),将标准分布的随机变量映射成复杂分布的随机变量,可用于建模复杂的概率分布
- p 0 p_0 p0是标准分布,解析式已知,可以计算其导数等性质
- 后面所有对 z 0 z_0 z0进行的变换 f f f,都是由神经网络构建的(学习得到所有的映射 f f f)
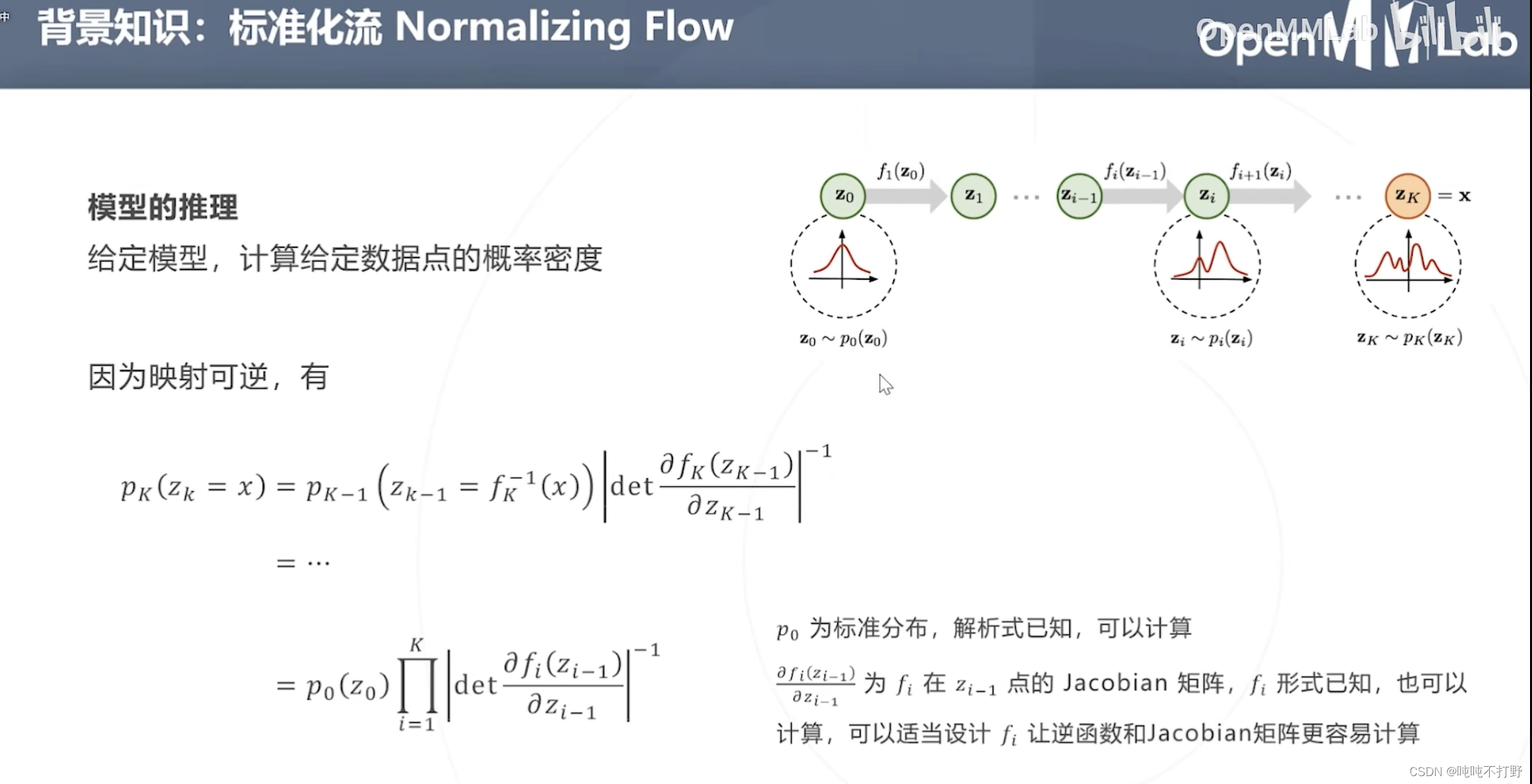
在学习确定所有
f
f
f的准确形式后,考虑根据
f
f
f反向推导出
p
0
(
z
0
)
p_0(z_0)
p0(z0)(模型推理),在模型参数确定(
f
f
f已知)后,计算给定数据点(例如:
x
x
x)的概率密度(
p
K
(
z
K
=
x
)
p_K(z_K=x)
pK(zK=x))
- 由于 f f f可逆,所以可以进行上述的推导(概率论知识)
- det:是行列式(Determinant)的缩写,表示计算一个矩阵的行列式,不记得的可以看看:


模型学习(求解损失函数,对损失函数进行化简)上述公式,对
p
k
(
x
)
p_k(x)
pk(x)取对数,
- 这样乘法 ∏ i = 1 k \prod^k_{i=1} ∏i=1k就变成了加法 ∑ i = 1 k \sum^k_{i=1} ∑i=1k(这个latex语法是’\prod’,product是乘积的意思),
- 注意,后面的det外面还套了个
-1,因此就变成 p 0 ( z 0 ) − ∑ i = 1 K l o g ∣ d e t ∂ f i ( z i − 1 ) ∂ ( z i − 1 ) ∣ p_0(z_0) - \sum^K_{i=1}log|det\frac{\partial f_i(z_{i-1})}{\partial (z_{i-1})}| p0(z0)−∑i=1Klog∣det∂(zi−1)∂fi(zi−1)∣了 - 全体参数
Φ
\Phi
Φ,latex-
\Phi
概率分布 p K p_K pK受到构建该分布的神经网络 f 1 , . . . , f K f_1,...,f_K f1,...,fK的全体参数 Φ \Phi Φ控制
- 可以通过梯度下降优化 Φ \Phi Φ,这里会涉及对Jacobian的行列式的梯度的计算,可以通过适当映射 f i f_i fi映射的函数形式,让这个计算变简单。
- RLE论文使用的标准化流模型是RealNVP
2.1.2 RLE的整体设计
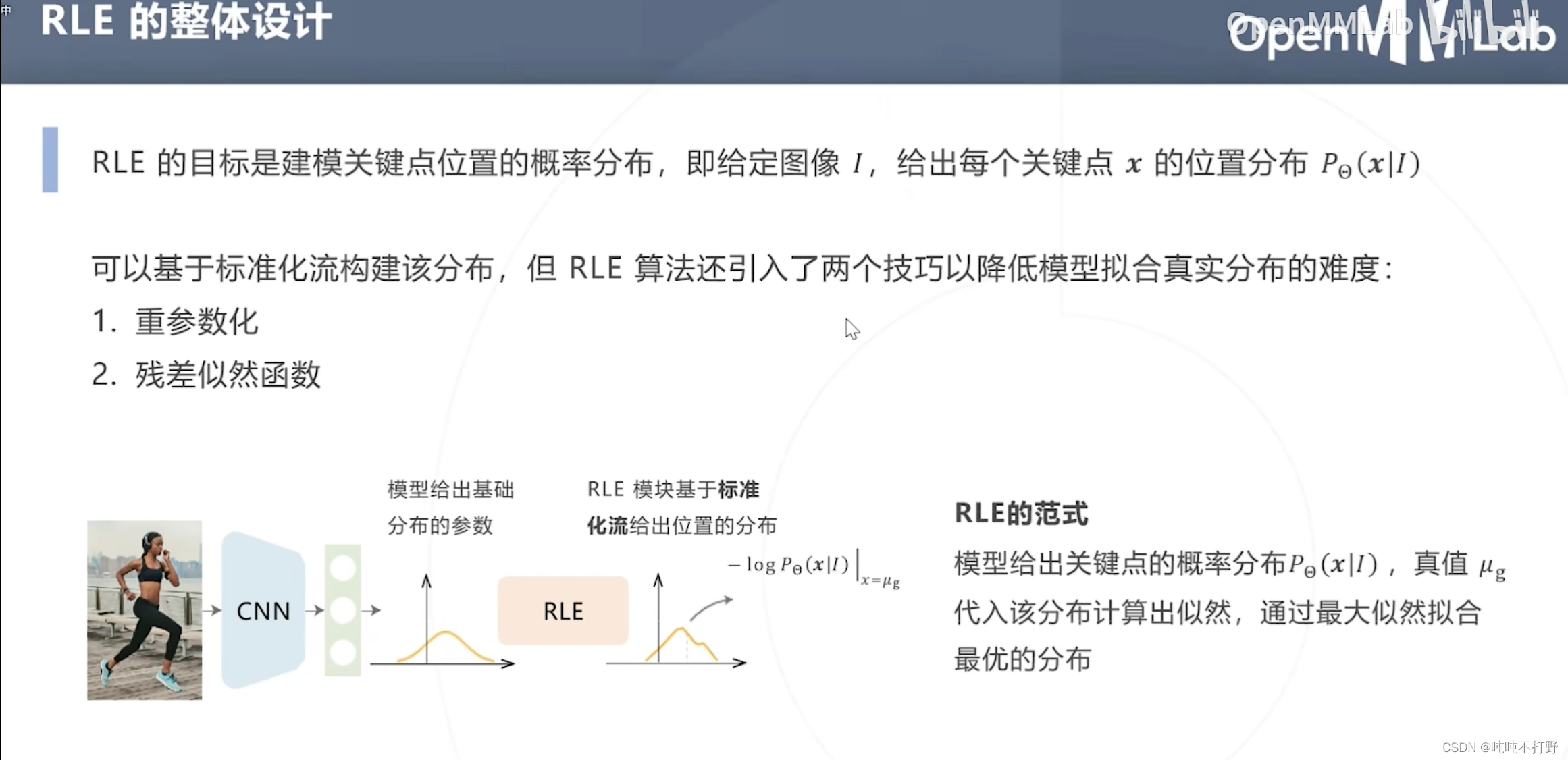
除了基于标准化流构建分布(RLE的主要目标,找出关键点的位置分布),RLE还使用了以下两个技巧来降低模型拟合真实分布的难度:
- 重(chong)参数化
- 残差似然函数

为降低建模分布的难度,假设所有关键点的分布属于同一个位置尺度族,即所有分布由某个零均值的基础分布通过平移缩放得来。(重参数化,重复一部分参数)
- 例如:所有一元正态分布
N
(
x
∣
μ
,
σ
)
\mathscr{N}(x|\mu,\sigma)
N(x∣μ,σ)构成位置尺度族,基础分布为标准正态分布。
对标准正态分布进行平移缩放,就可以得到任意其他的一元正态分布。 - 重参数化的思想,有点像,卷积层的参数共享(卷积核/模板参数共享),都是为了减少参数,所以公用了一部分参数
所以整体就是:
- 标准化流拟合基础分布 x ˉ \bar x xˉ
- 卷积网络预测平移缩放参数 μ ~ , σ ~ \tilde \mu,\tilde \sigma μ~,σ~
- 即上图右下侧的示意图
❓❓❓
推理阶段,则只需要卷积网络预测的平移(❓为什么不考虑缩放)参数,❓不用推理标准化流
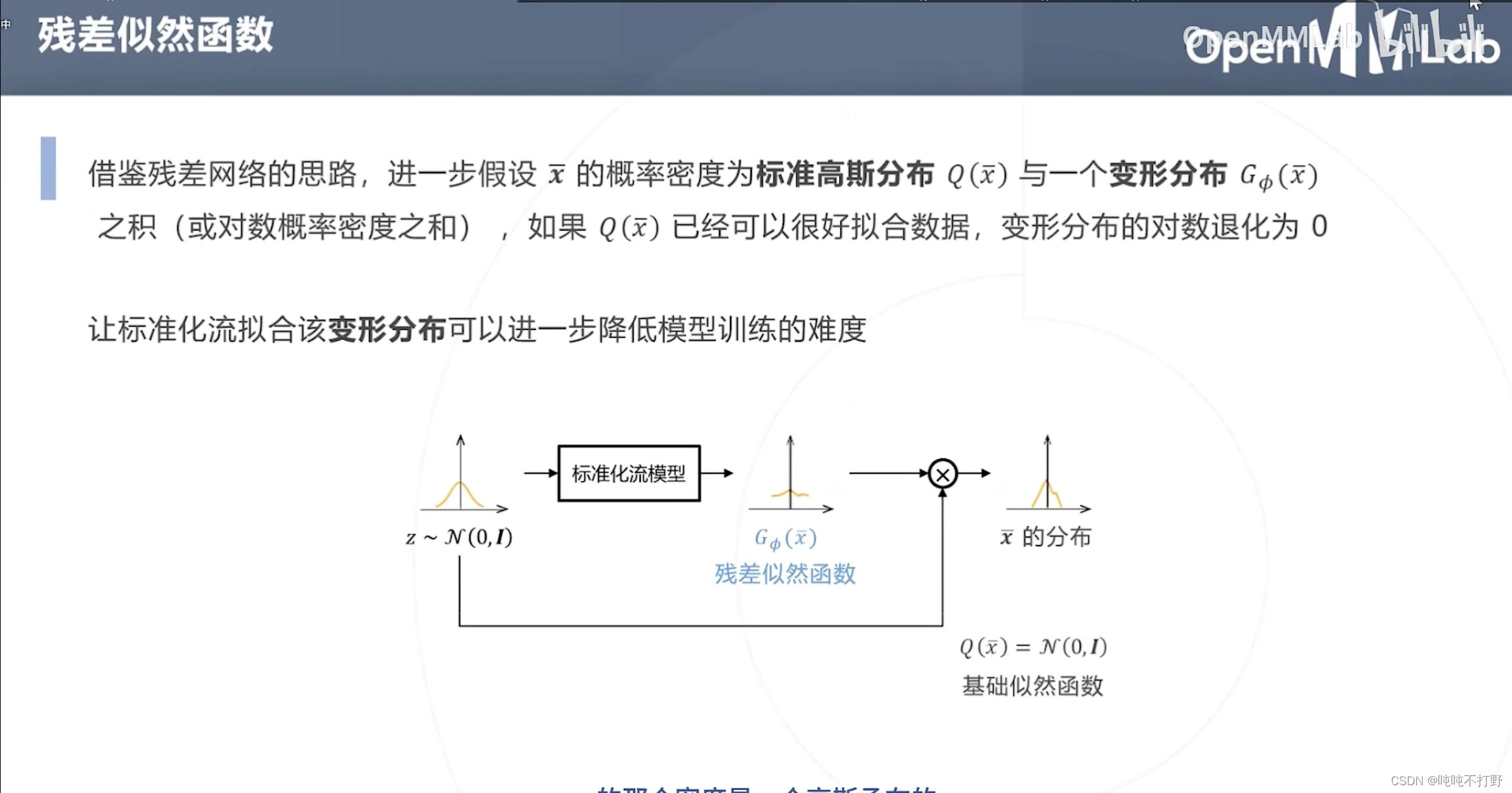
挺好理解的,看ppt就行
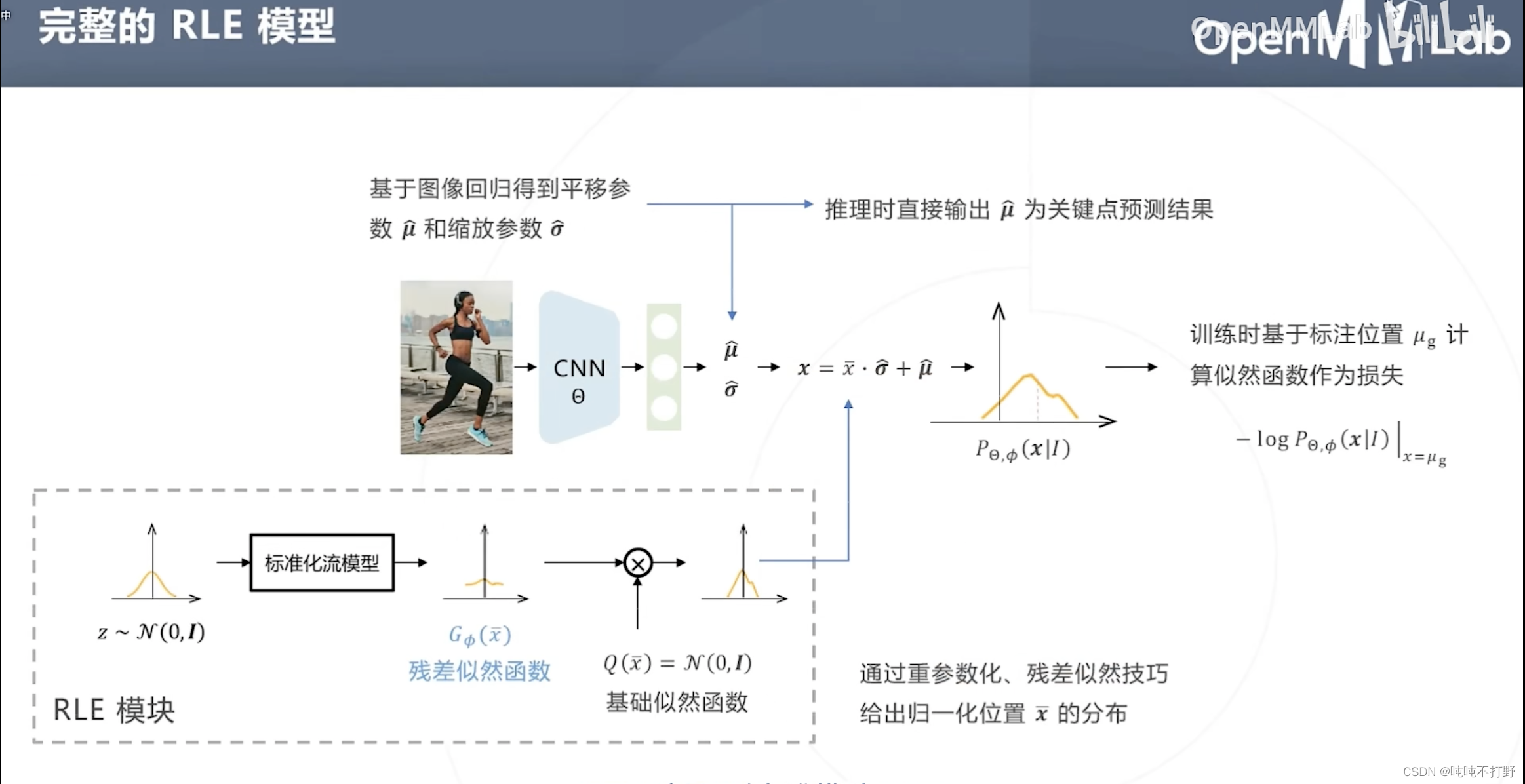
对标准化流模型得到的标准分布,进一步使用残差似然函数,就变成上图了
2.2 基于热力图的自顶向下方法
2.2.1 Hourglass论文地址(2016年)
MMPose中这个网络的位置:

论文:Stacked Hourglass Networks for Human Pose Estimation
2.2.2 Hourglass模型
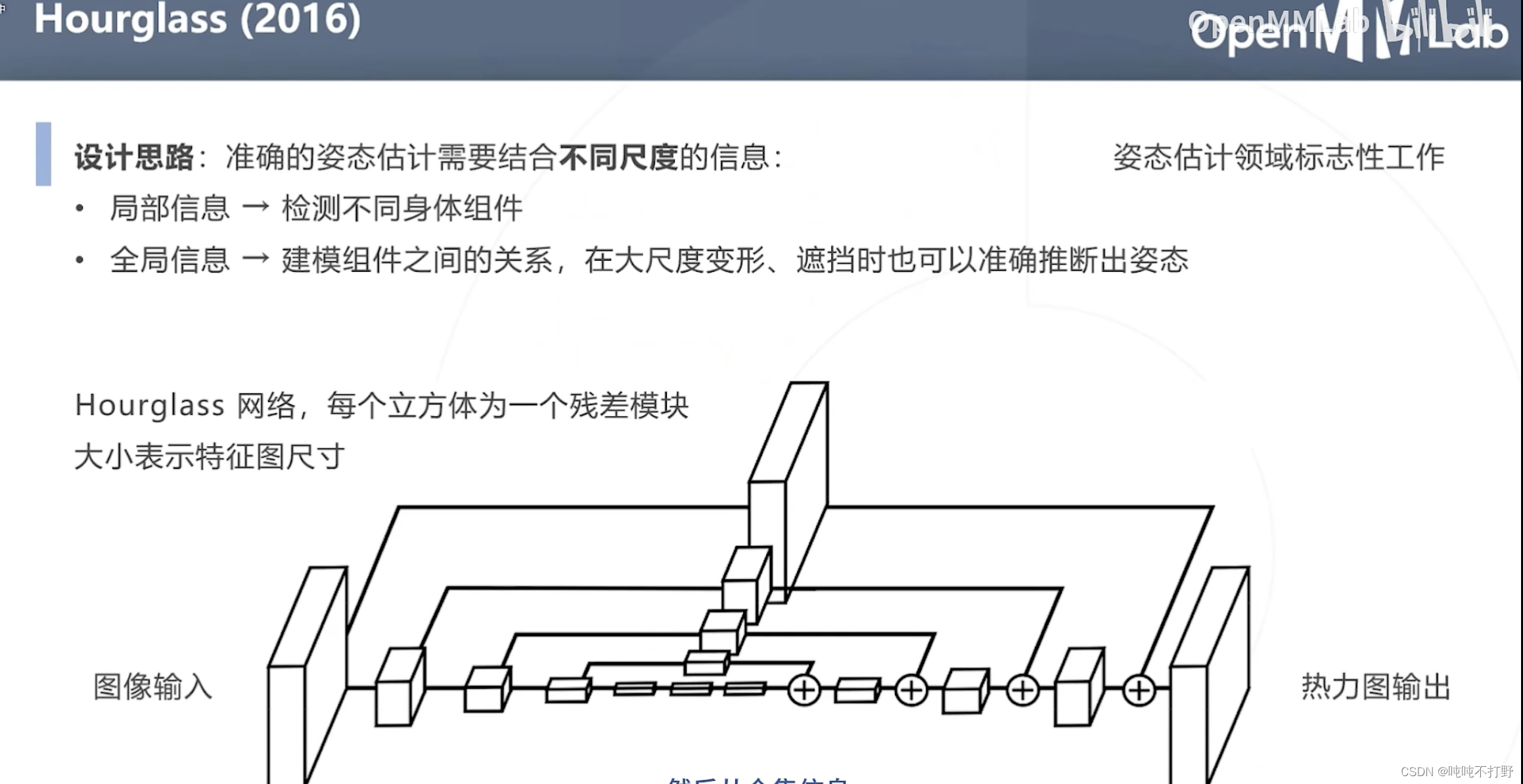
Hourgalss网络,是姿态估计领域标志性的工作
- 设计思路:准确的姿态估计需要结合不同尺度的信息
- 局部信息→检测不同的身体组件(不同部位的关键点)
- 全局信息→建模组件之间的关系,在大尺度变形、遮挡时也可以准确推断出姿态
上图的网络结构中,
- 每个立方体都是一个残差模块,大小表示特征图的尺寸
- 每个尺度,都有自己的残差
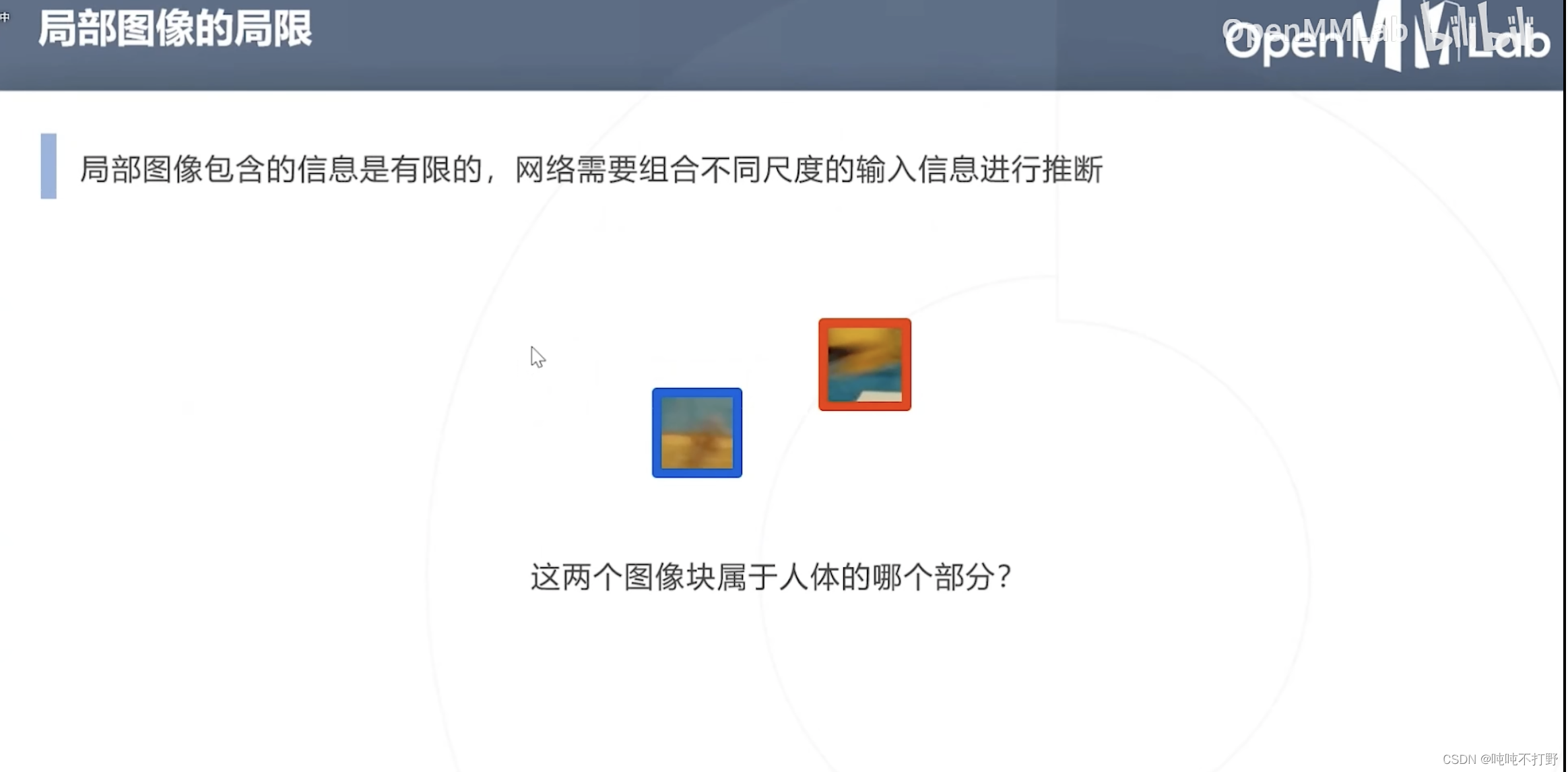
局部信息是有限的,单纯依赖这个尺度下的局部信息,无法做出有效判断

所以需要组合不同尺度的输入信息进行推断
- 对于上图蓝色框的小尺度局部,其实只要给一个输入包含手臂的一个尺度的局部,其实就可以判断出来是什么,黄色框同理,
- 不同尺度,看到的信息不一样,不同的尺度就可以得出不同的结论(甚至有些小尺度没有效的结论,或者某些特定尺度才能看到有效信息)
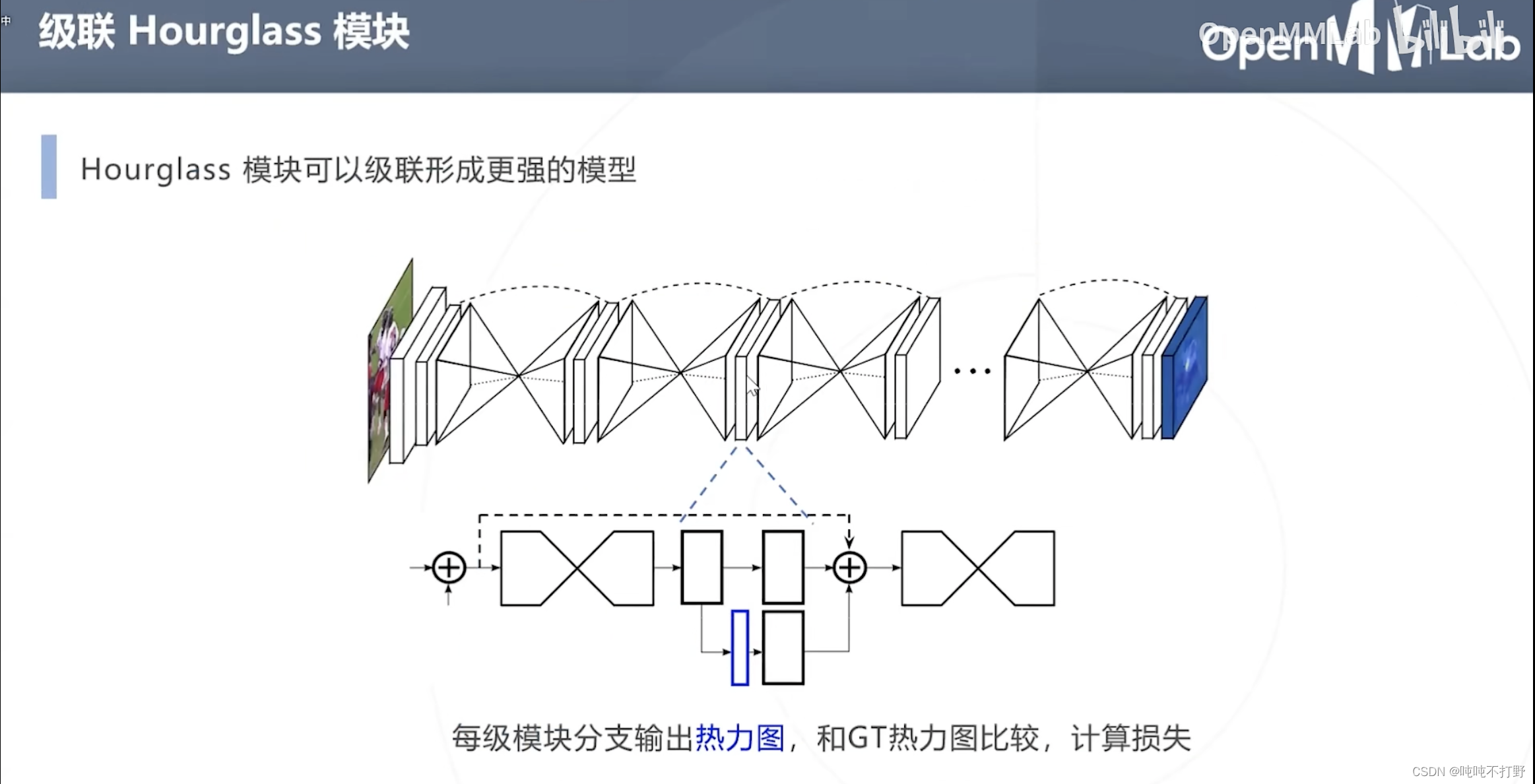
每级模块分支输出热力图,和GT热力图比较,计算损失。
- 上图蓝色部分就是这个模块输出的热力图,蓝色右边的就是真值
- 虚线的曲线括住的部分就是一层Hourglass模块,一般会有8层。。
也就是:每一级模块都可以分别进行损失函数的优化。
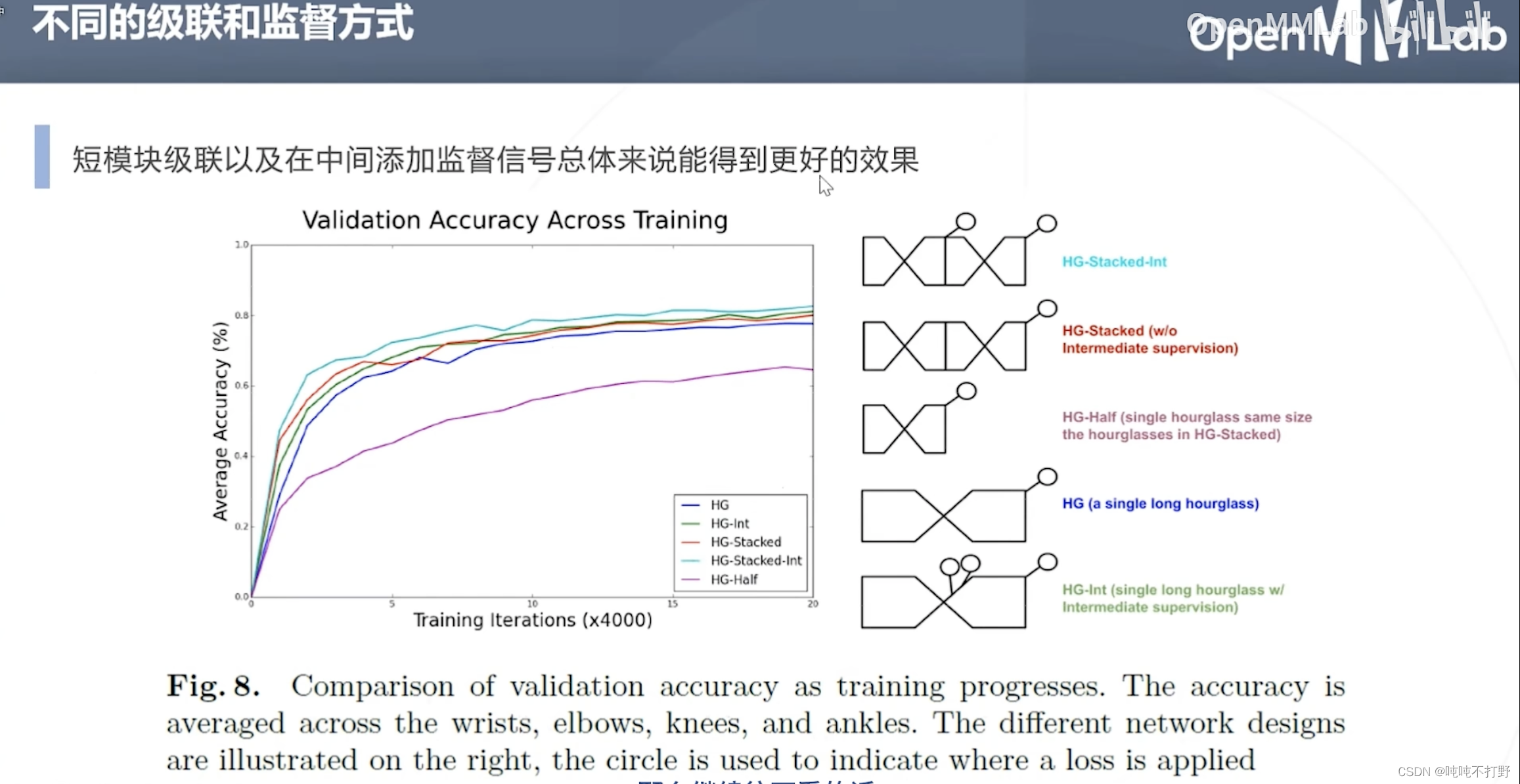
这个实验就是不同的级联方式和监督方式的消融实验效果。
从上到下依次进行的实验是:
- HG堆叠,也就是这个论文主推的方法,8个Hourglass模块堆在一起,每个模块输出的热力图都和真值比较(短模块级联+每层模块都添加监督信号)
- HG堆叠,但是只对最后输出的热力图和真值比较
- 不进行级联,只有HG堆叠中一层Hourglass模块
- Hourglass特征提取部分变大了(long hourglass),这个要去论文里看具体的
- 类似4,在中间添加了监督
蓝色和绿色最好,说明在中间添加监督信号是更有效的,但是级联和long hourglass的效果最后看起来似乎没有差很多
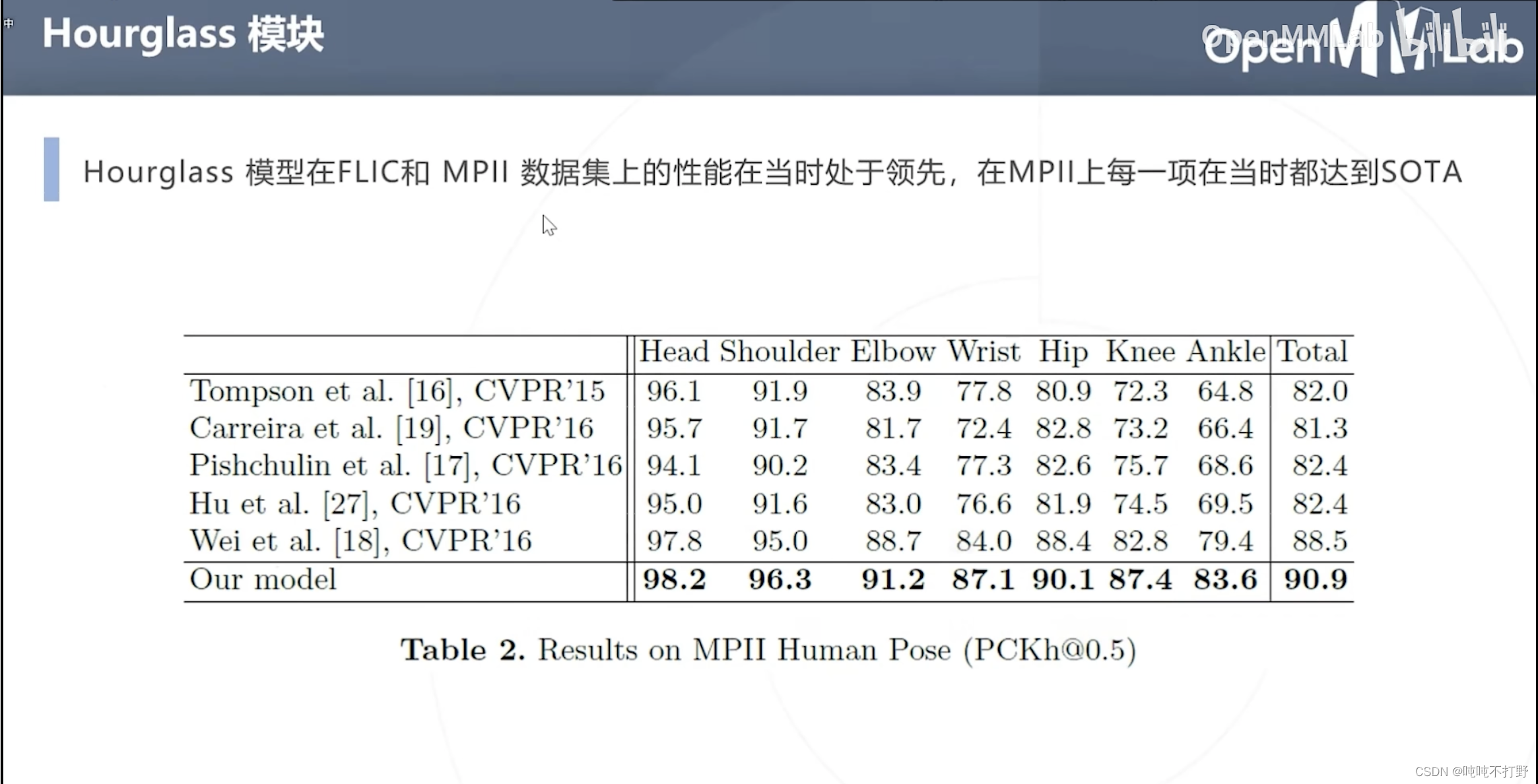
在当时是SOTA的水平,持续了一段时间。
2.2.3 Simple Baseline(2018年)
MMPose中这个网络的位置
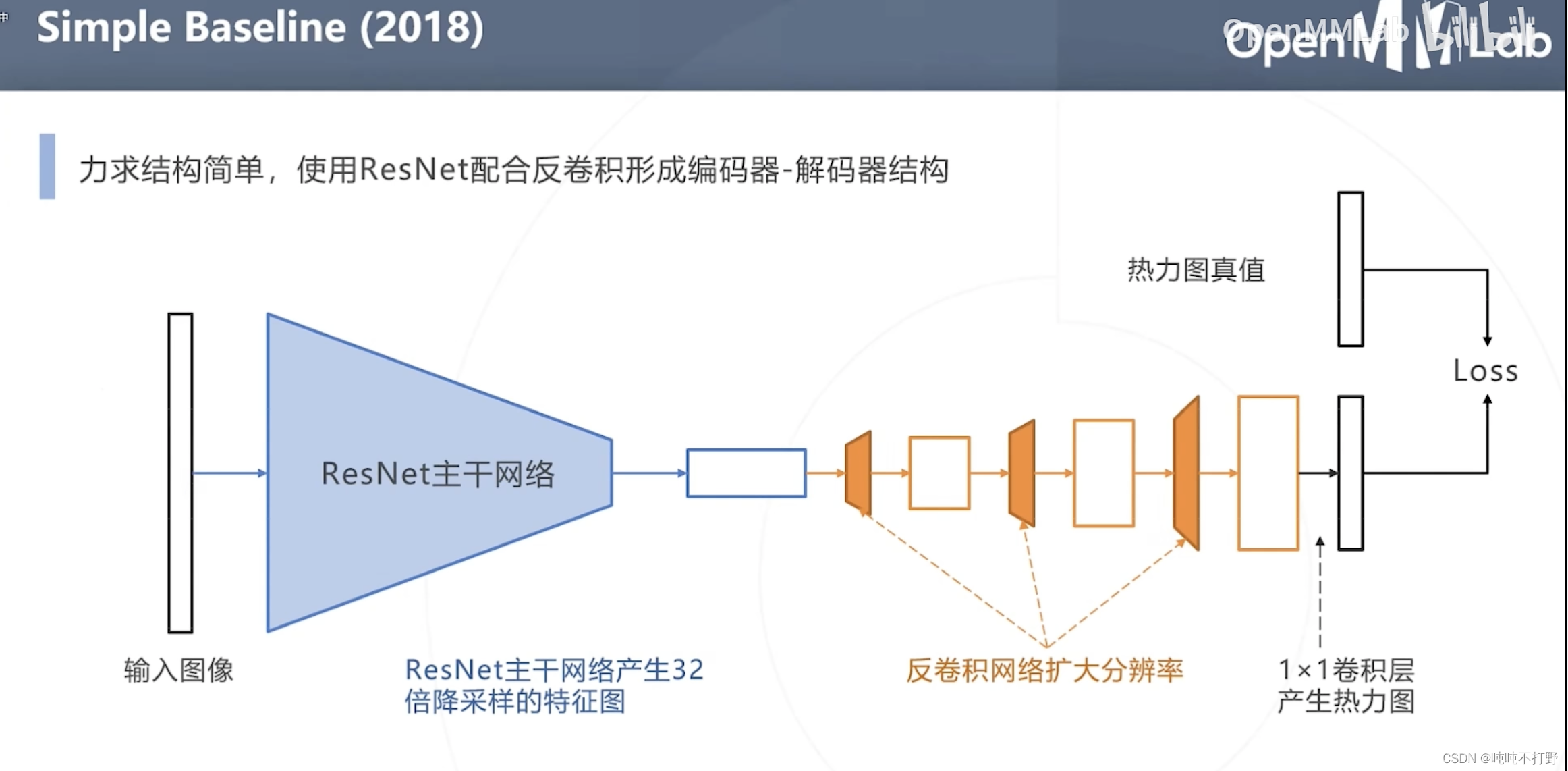
使用ResNet配合反卷积形成编码器-解码器结构
2.2.4 HRNet(2019)
位于MMPose的这里,链接
论文链接:Deep High-Resolution Representation Learning for Human Pose Estimation
可以看看这个讲解:陀飞轮-一文读懂HRNet
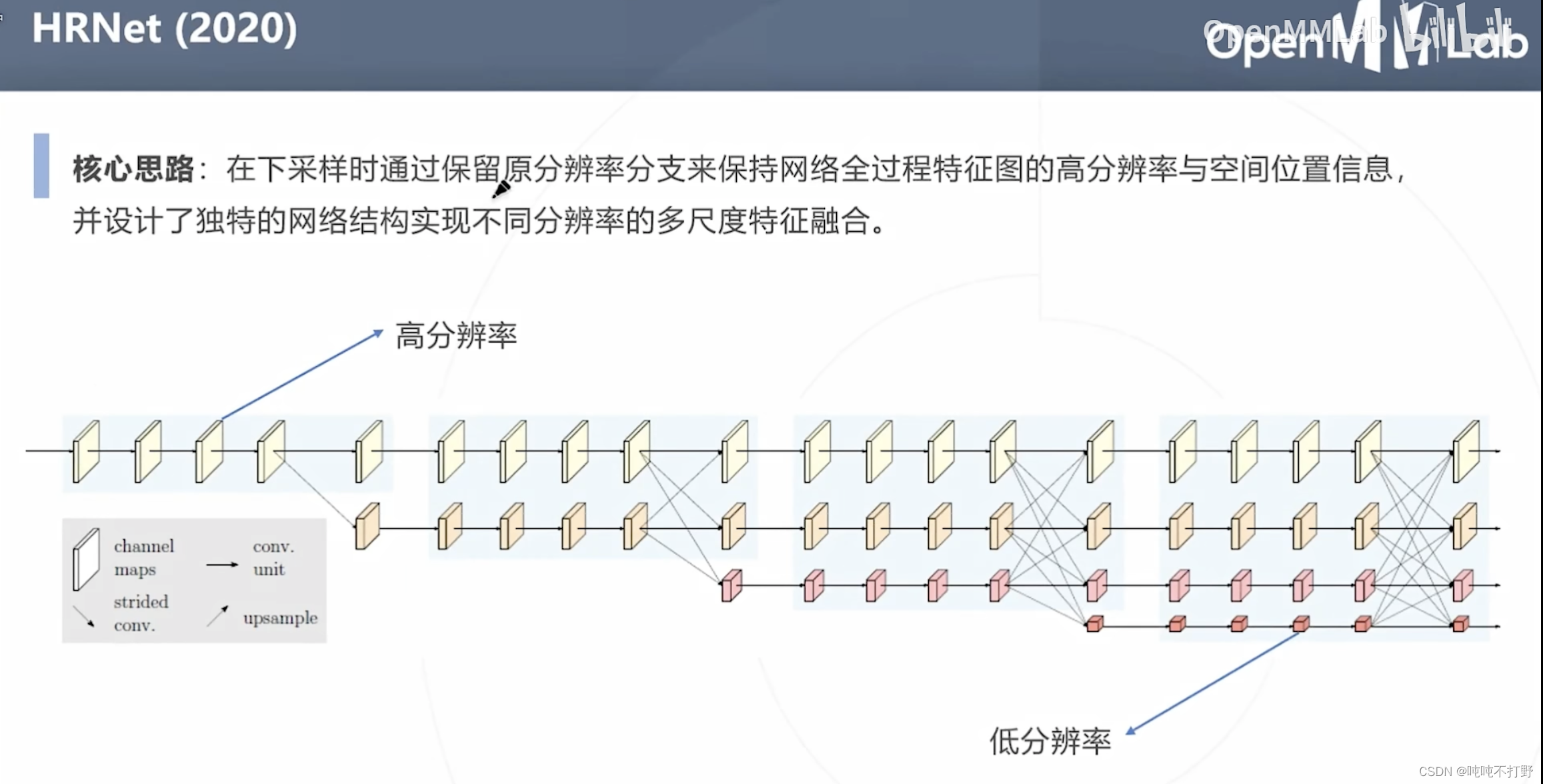
核心思路:
- 下采样时通过保留原分辨率分支,来保持网络全过程特征图的高分辨率与空间信息位置
- 设计了独特的网络结构实现不同分辨率的多尺度特征融合

- 对于右图,第二列最下面最小的橙红色分辨率特征图,其实是来自前一层三种不同尺度的分辨率(三个虚线箭头),同理,其实第二层的所有不同尺度的分辨率特征图,都是从前一层的三个尺度里得到的。
- 橙红色就是上面说的跨层的额外融合输出,其余三个都是对应各自那个级别的分辨率

这个插图对应的还是上一页ppt,解释的是第一层的三种尺度的分辨率如何融合得到第二层的。(上图有一部分描述有问题) - 第一列分辨率(x) = 第二列分辨率( r) 的特征图,直接相等。 f x r ( R ) = R f_{xr}(R)=R fxr(R)=R
- 第一列分辨率(x) > 第二列分辨率( r) 的特征图,
f
x
r
(
R
)
f_{xr}(R)
fxr(R)将输入的
R
R
R经过
(
r
−
x
)
(r-x)
(r−x)次stride为2的
3
×
3
3\times 3
3×3卷积。
- O u t S i z e f e a t u r e m a p = ( I n p u t S i z e f e a t u r e m a p − K e r n e l S i z e + 2 P a d d i n g ) / S t r i d e + 1 OutSize_{featuremap}=(InputSize_{featuremap}-KernelSize+2Padding)/Stride+1 OutSizefeaturemap=(InputSizefeaturemap−KernelSize+2Padding)/Stride+1
- r = ( x − 1 ) / 2 + 1 r =(x-1)/2+1 r=(x−1)/2+1,stride为2,也就是每次卷积特征图size小1,经过r-x次,就刚好可以得到输出特征图为x的尺寸了
- 第一列分辨率(x) < 第二列分辨率( r) 的特征图,使用双线性插值进行上采样,再用1X1卷积对齐通道数。
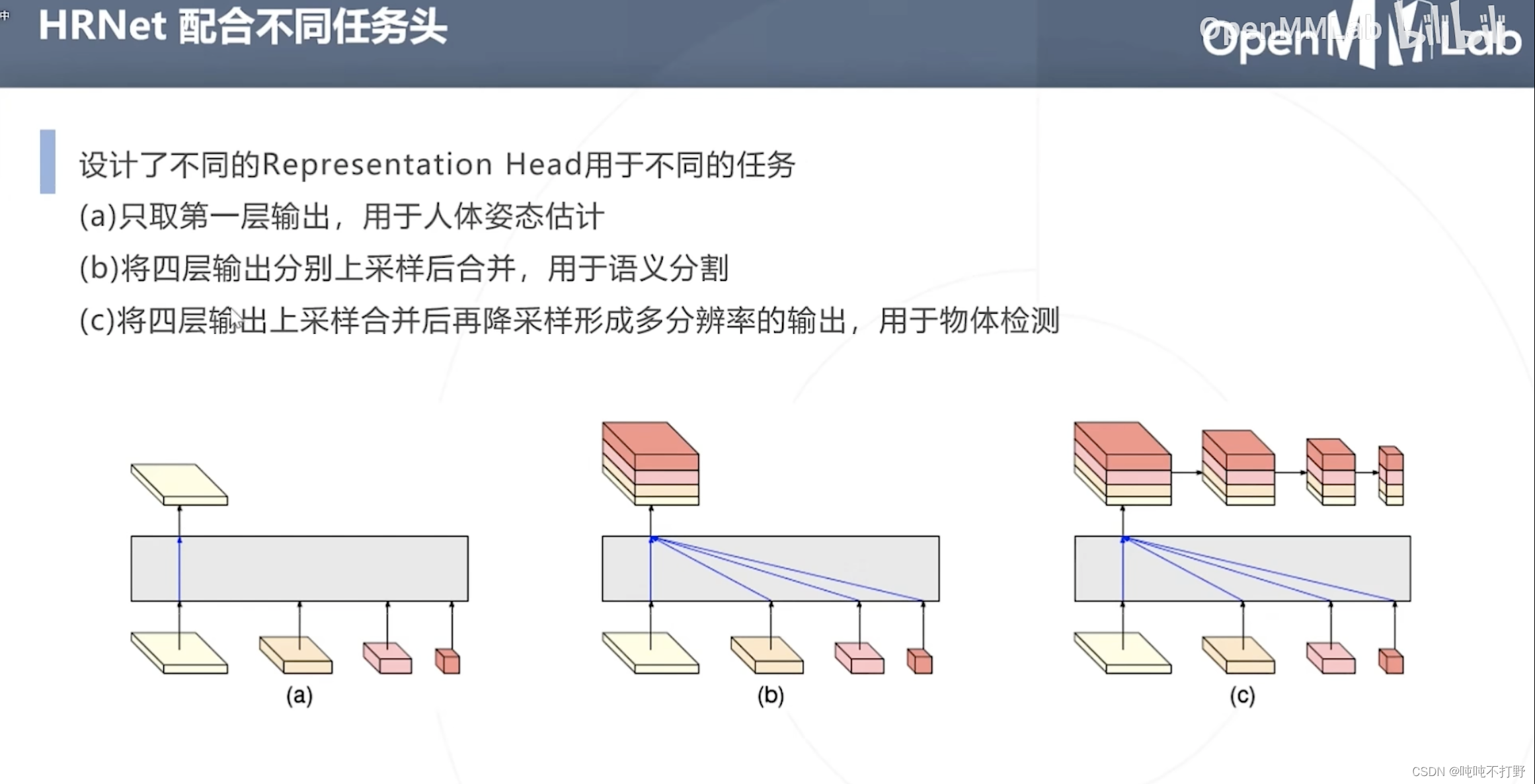
同时,除了进行人体姿态估计,配合不同的任务头,也可以用来做别的事情。
a. 只取第一层输出,用于人体姿态估计(HRNetV1的操作方式,只使用分辨率最高的feature map。)
b. HRNetV2的操作方式,将所有分辨率的feature map(小的特征图进行upsample)进行concate,主要用于语义分割和面部关键点检测。
c. HRNetV2p的操作方式,在HRNetV2的基础上,使用了一个特征金字塔,主要用于目标检测。
2.3 基于热力图的自底向上的方法
2.3.1 Part Affinity Fields & OpenPose(2016)
MMPose中这个网络的位置,没有找到这个文章

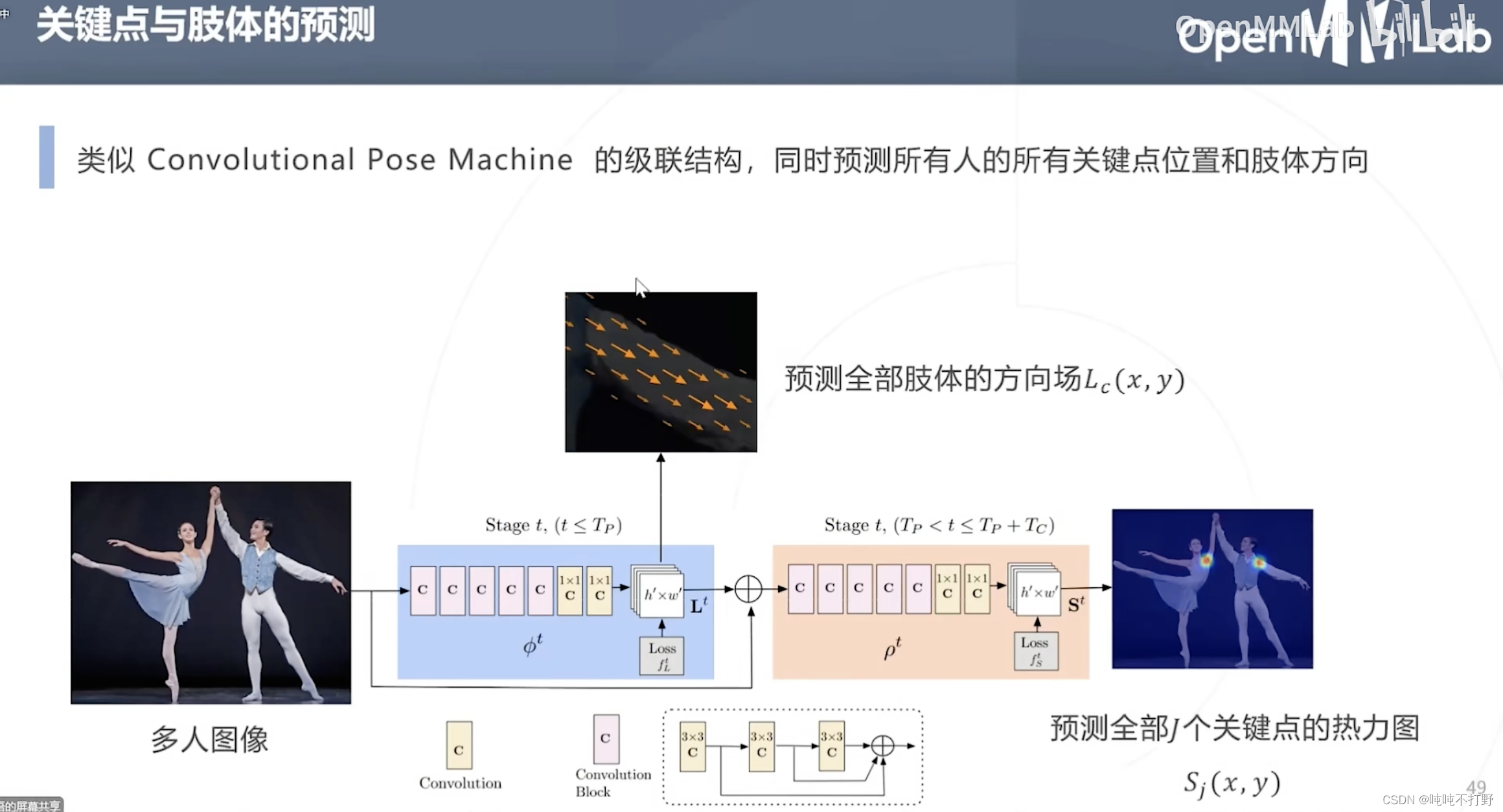
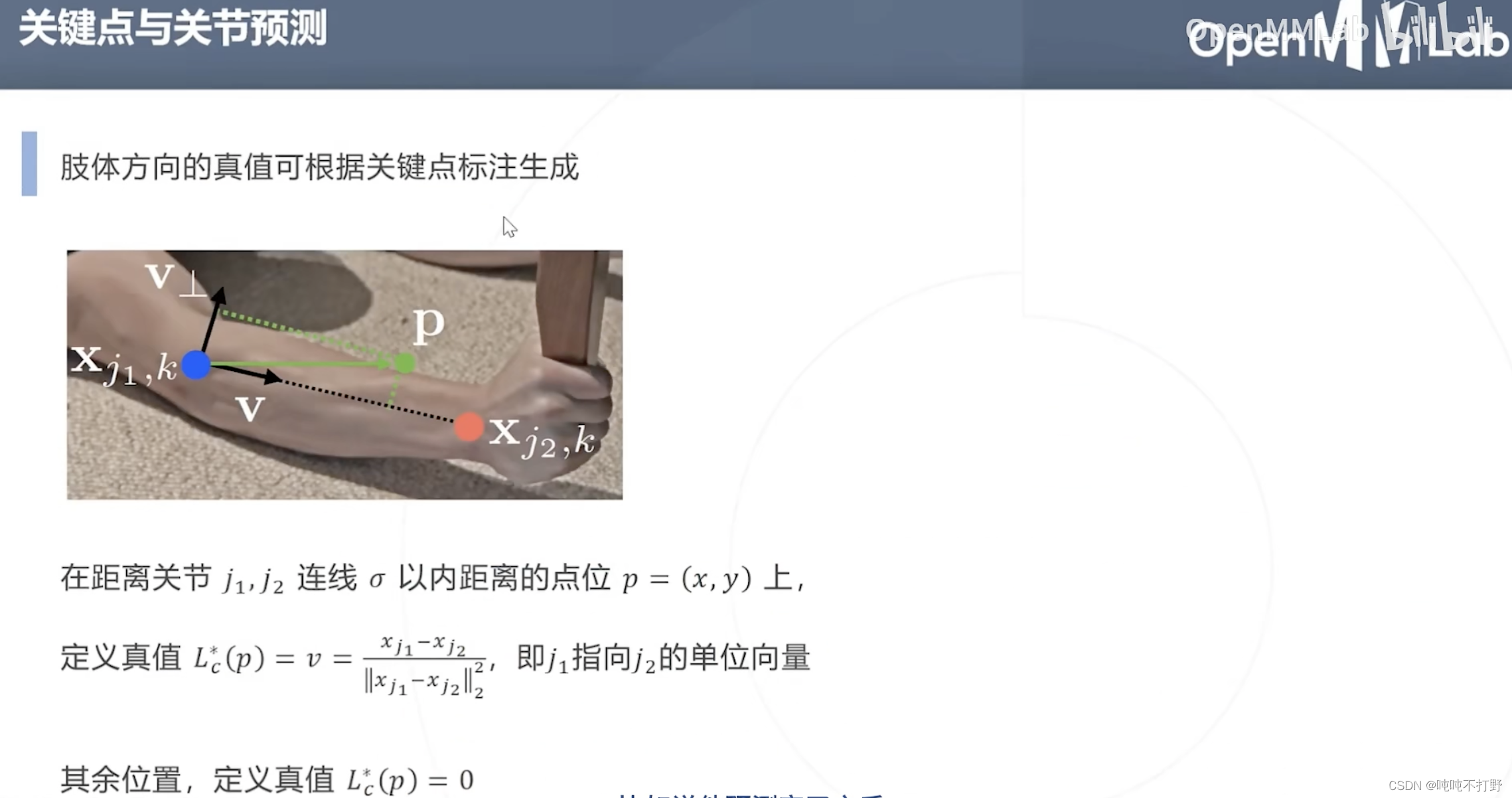
这个有很明显的缺陷啊。。。
σ
\sigma
σ以内距离,小孩和成年相同关节关键点的距离肯定有很大差距,这个
σ
\sigma
σ的距离设置,挺值得探讨的

另外,这里关于亲合度的定义,也有些问题:
这里的
L
c
L_c
Lc就是一个单纯的单位向量,只给出一个方向,那么在握手等多人某段肢体相连的情况,同时方向还类似的时候,就会被判定属于一个人??

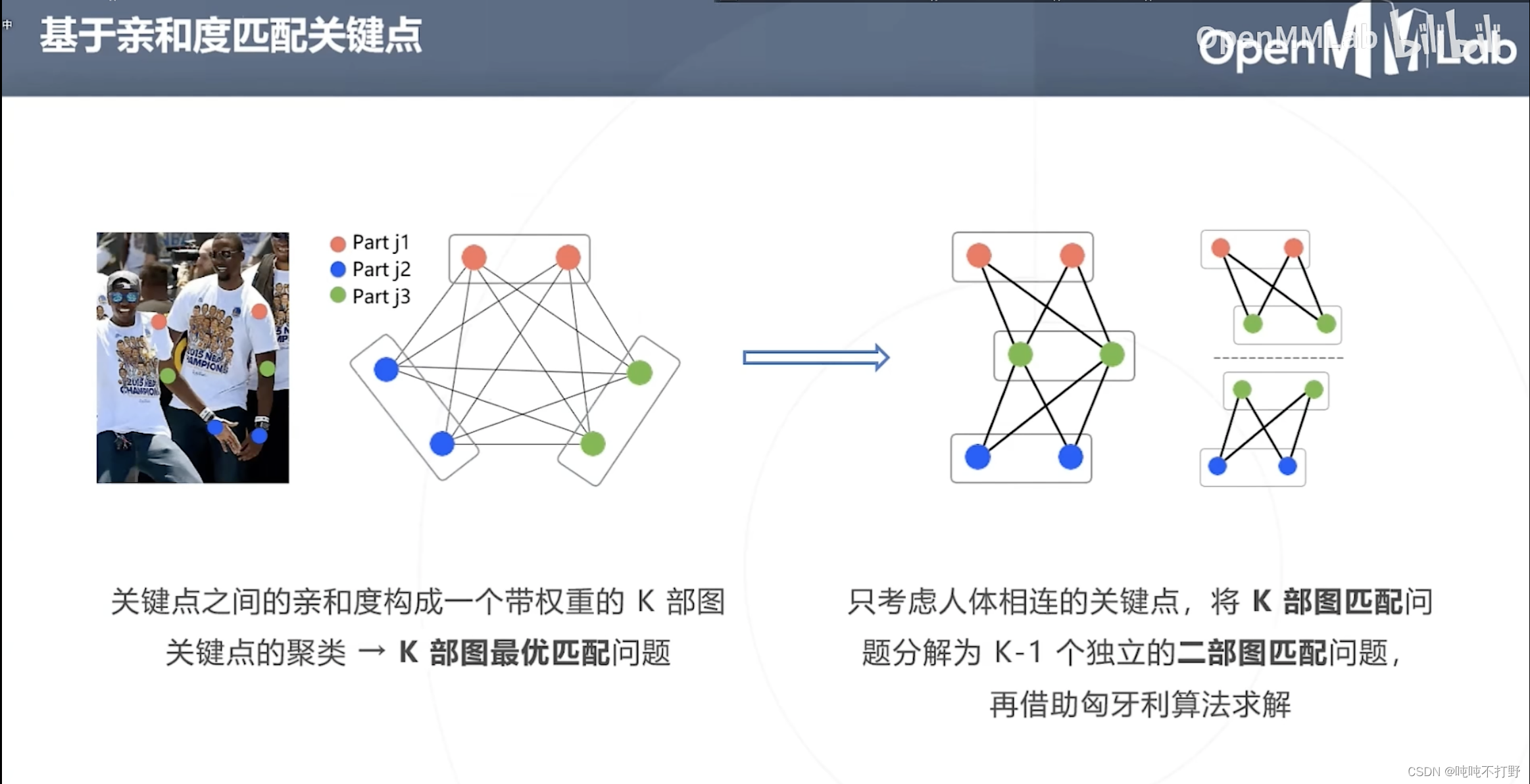
图论:
- 关键点就是图里的顶点,关键点之间的亲和度就是顶点连线的权重,构建出了一个带权的图(特殊的图,是K部图)
- 通过对图进行建模,就把关键点的聚类问题转换成K部图最优匹配的问题
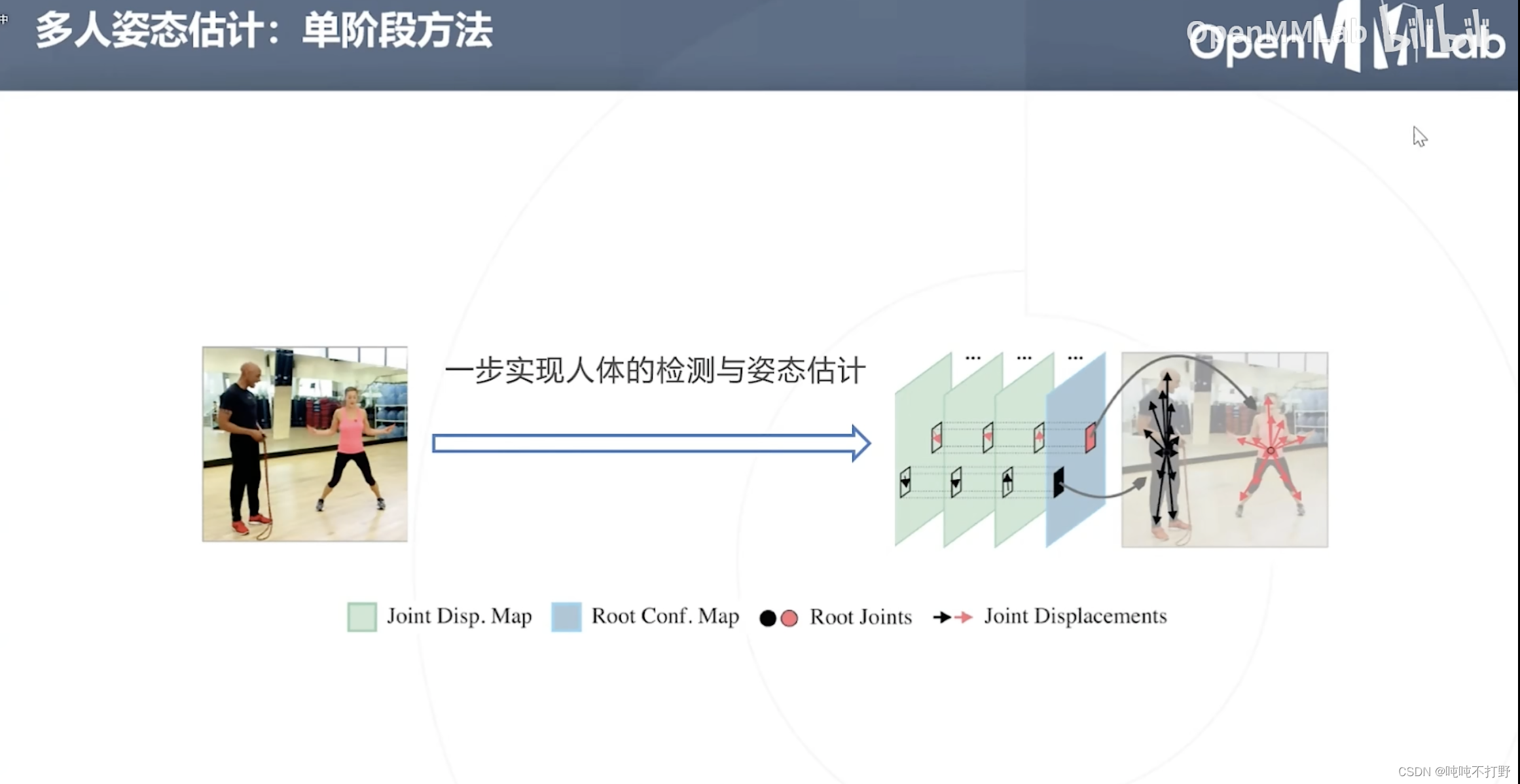
2.4 单阶段方法
2.4.1 SPM(2019)
目前在MMPose中也没看到这个网络
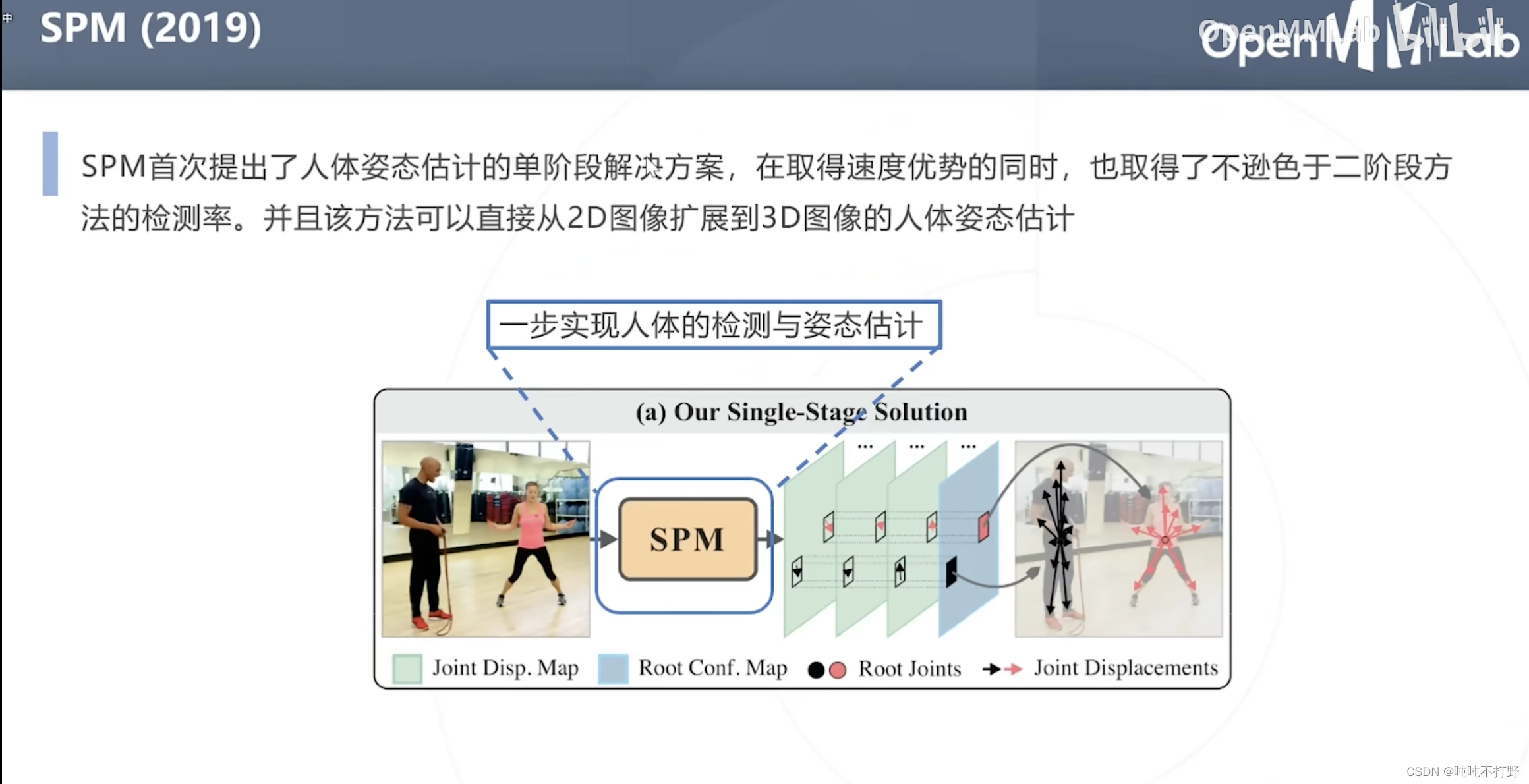
SPM首次提出单阶段解决方案,在取得速度优势的同时,也保留了很高的检测率,同时该方法可以直接从2D扩展到3D(有些坎坷)。
SPM的思想和Yolo很像。
- 目标检测是回归中心点和一个向量(主对角线)
- 这里是回归关键点,以及多个方向向量
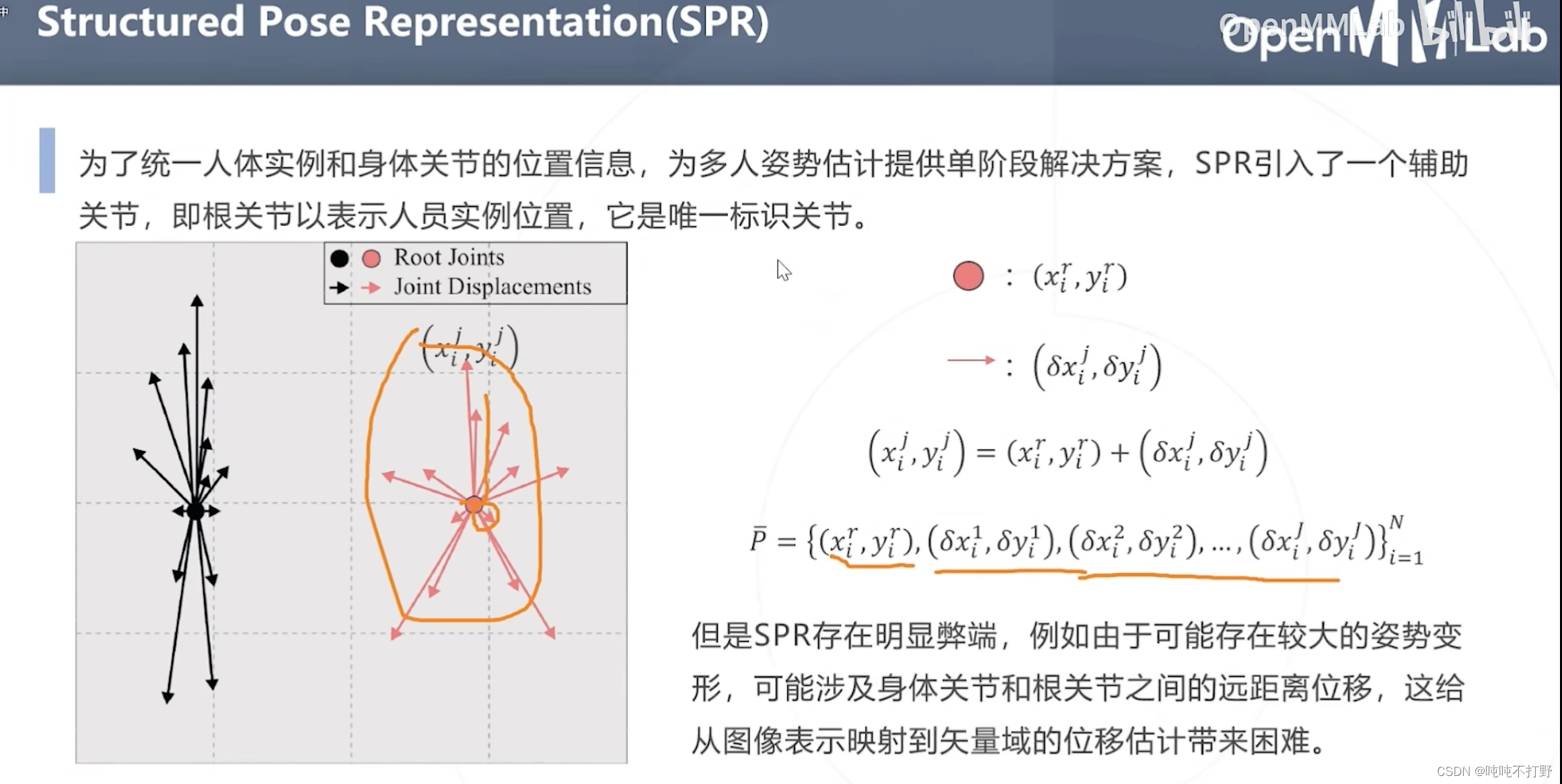
除了之前说的人体姿态估计固定的18个关键点,SPR引入了一个辅助关节(根关节点,Root Joints),来连接其他关键点,统一人体实例和身体关节的信息位置
- SPR会学习根关节的位置,其他关键点相对于根关键点的方向( δ \delta δ)
- 这样的弊端就是:如果有较大的姿势变形,涉及身体关节和根关节之间的远距离位移,就会给从图像表示映射到矢量域的位移估计带来困难
- (和上面的那个亲和度差不多),只要是单纯只使用方向向量的,都会产生这个问题
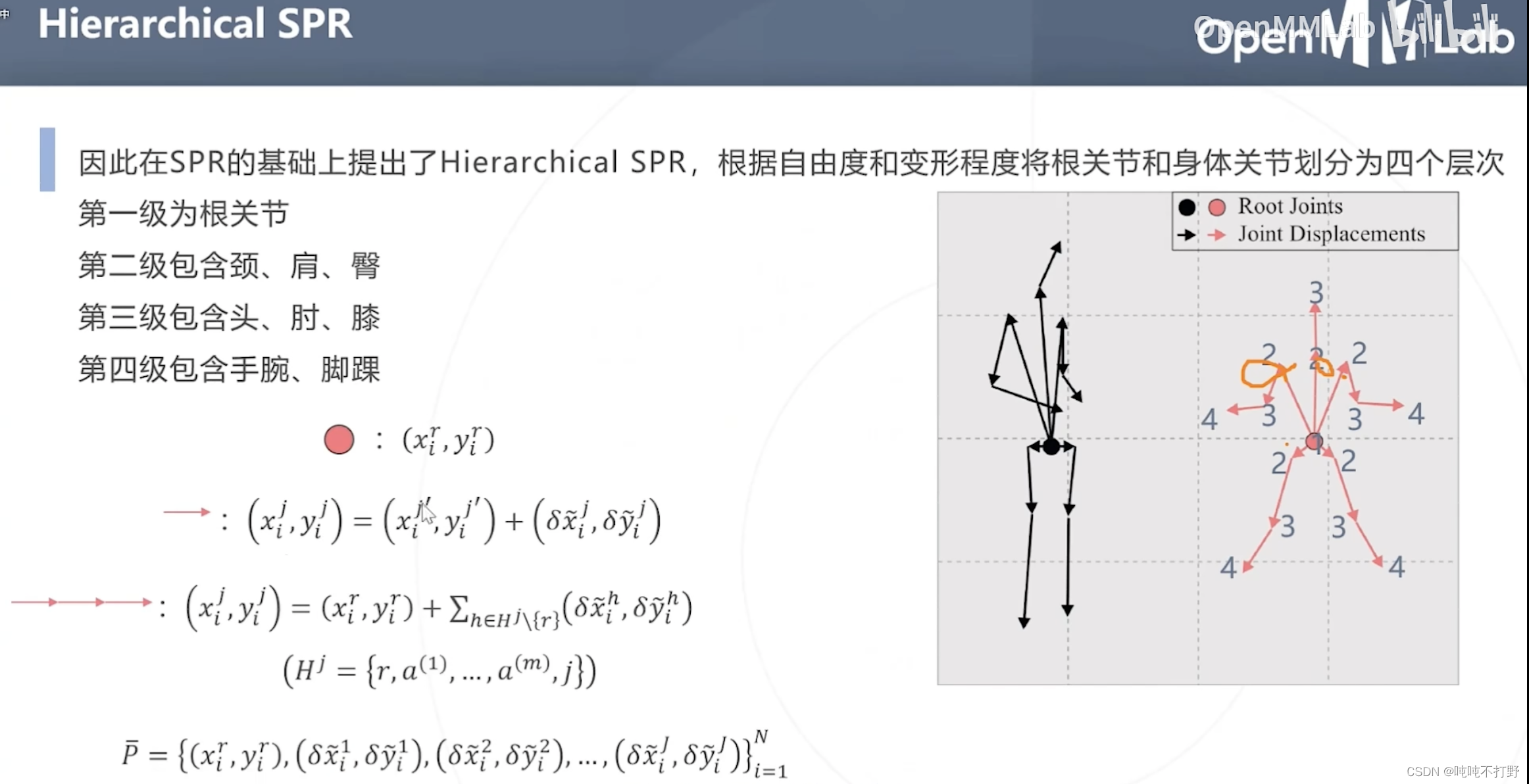
所以在SPR的基础上提出了Hierarchical SPR,其根据自由度和变形程度将根关节和身体关节划分为四个层次
- 第一级:根关节(自由度最低,基本不会变形)
- 第二级:颈、肩、臀(这些关节由于在人体的位置和构造,肩颈的活动范围有限。基本也不会有太大的位移)
- 第三级:手、肘、膝(会有些大的位移和形变)
- 第四级:手腕、脚踝(距离根关节最远,四肢还最灵活,形变程度和位移都最大)

- 置信回归分支,回归关节的热力图
- 额外延伸的一个位移回归分治,估计身体关节位移图(相对于根节点的其他18个关键点的位移)

- 根节点以热力图形式,进行概率回归
- 身体节点位移(方向向量)回归,通过对每个节点构建稠密的位移图,并规定位移量在一定的范围内(亲和度根据真值生成肢体方向的真值时,也是会规定关节之间的范围)后,对所有非零量取平均得到

同样,损失函数也是包含根关节和位移图的两部分loss,不难看出
- L C L^C LC是根关节置信度的L1 loss, L D L^D LD是位移图的L2 loss
-
β
=
0.01
\beta=0.01
β=0.01说明确定根关节的位置更重要。。。根关节确定后,位移图才有正确的可能
- 这个值的取法是有技巧的,可以思考一下
2.5 基于Transformer的方法
2.5.1 PRTR(2021)-两阶段算法(基于回归的)
MMPose的网络里没有

人体姿态估计和物体检测都包含对图像内容的定位
- DETR中query通过注意力机制逐渐聚焦到特定物体上
- 类似的,姿态估计中也可以让query逐渐聚焦到特定人体关键点上
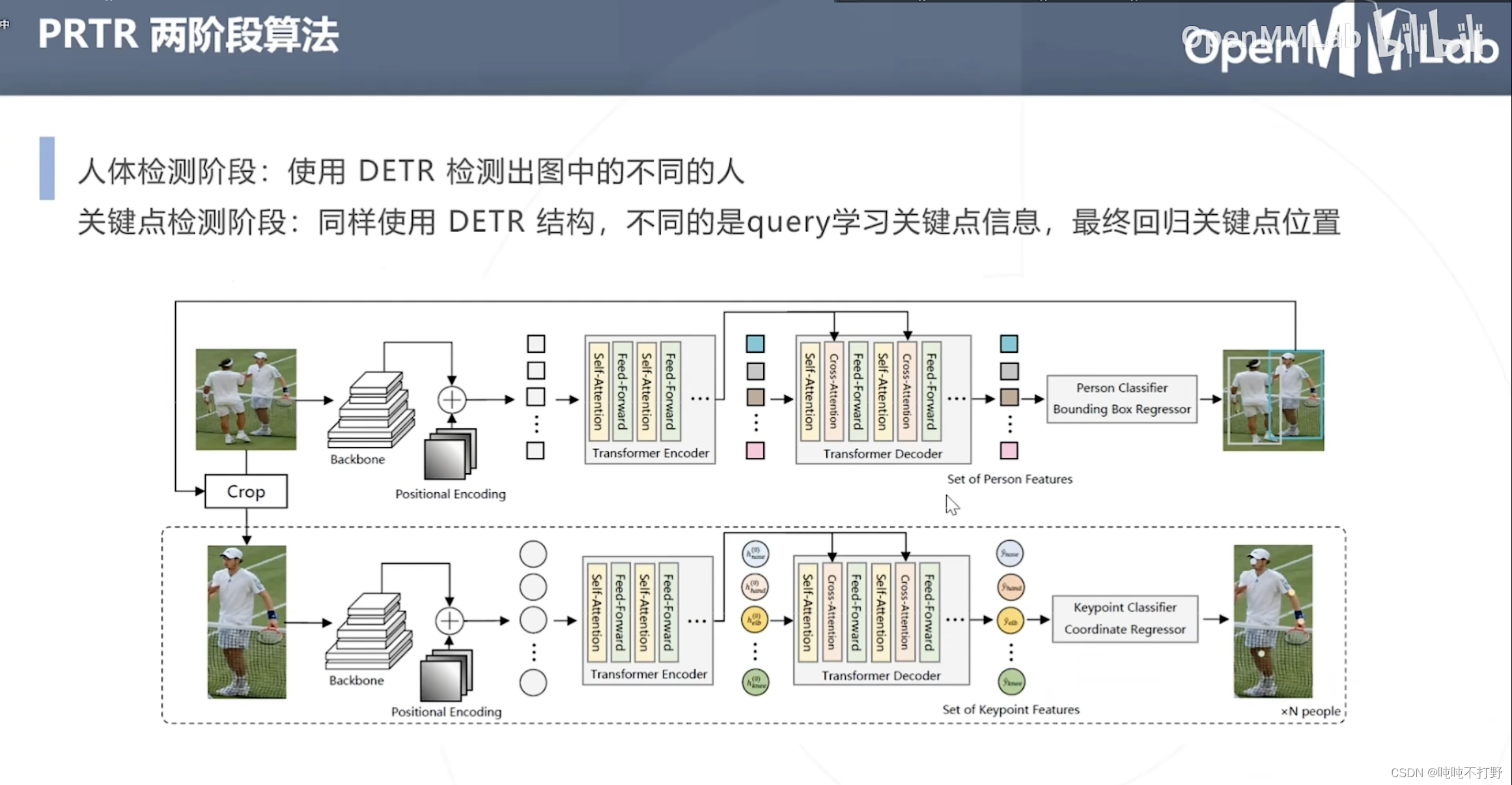
- DETR先检测出人体
- 同样使用DETR结构,只是此时query的不是人体的位置,而是关键点的信息,并最终回归关键点的位置
- 结构是是类似的,都是有个backbone+位置嵌入,然后Transformer的Encoder和decoder,
- 上面人体检测得到的是人体特征,是bounding box回归(中心点+方向,或者左上点坐标+高宽),
- 下面是关键点特征,是关键点回归
- 另外,这里有个Crop,就是从完整特征图中裁剪出单人对应的图像特征,用于后续关键点检测
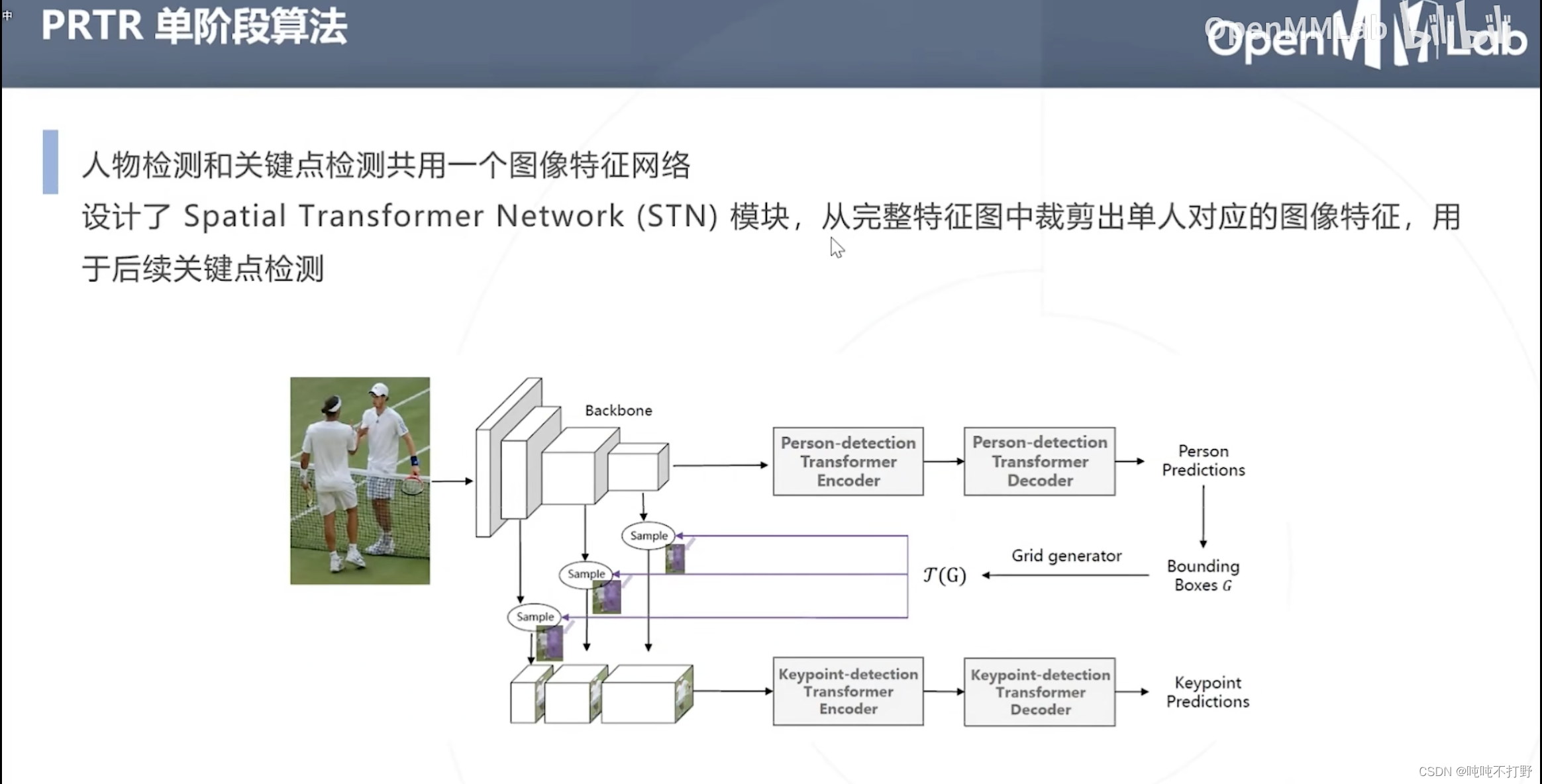
人体检测和关键点检测共用同一个图像特征网络(共用backbone,这和之前基于物体检测的姿态估计是很像的)
- 设计了Spatial Transformer Network(STN)模块,从完整特征图中裁剪出单人对应的图像特征,用于后续关键点检测
- 则关键点检测部分的backbone网络,就不用做重复训练了。
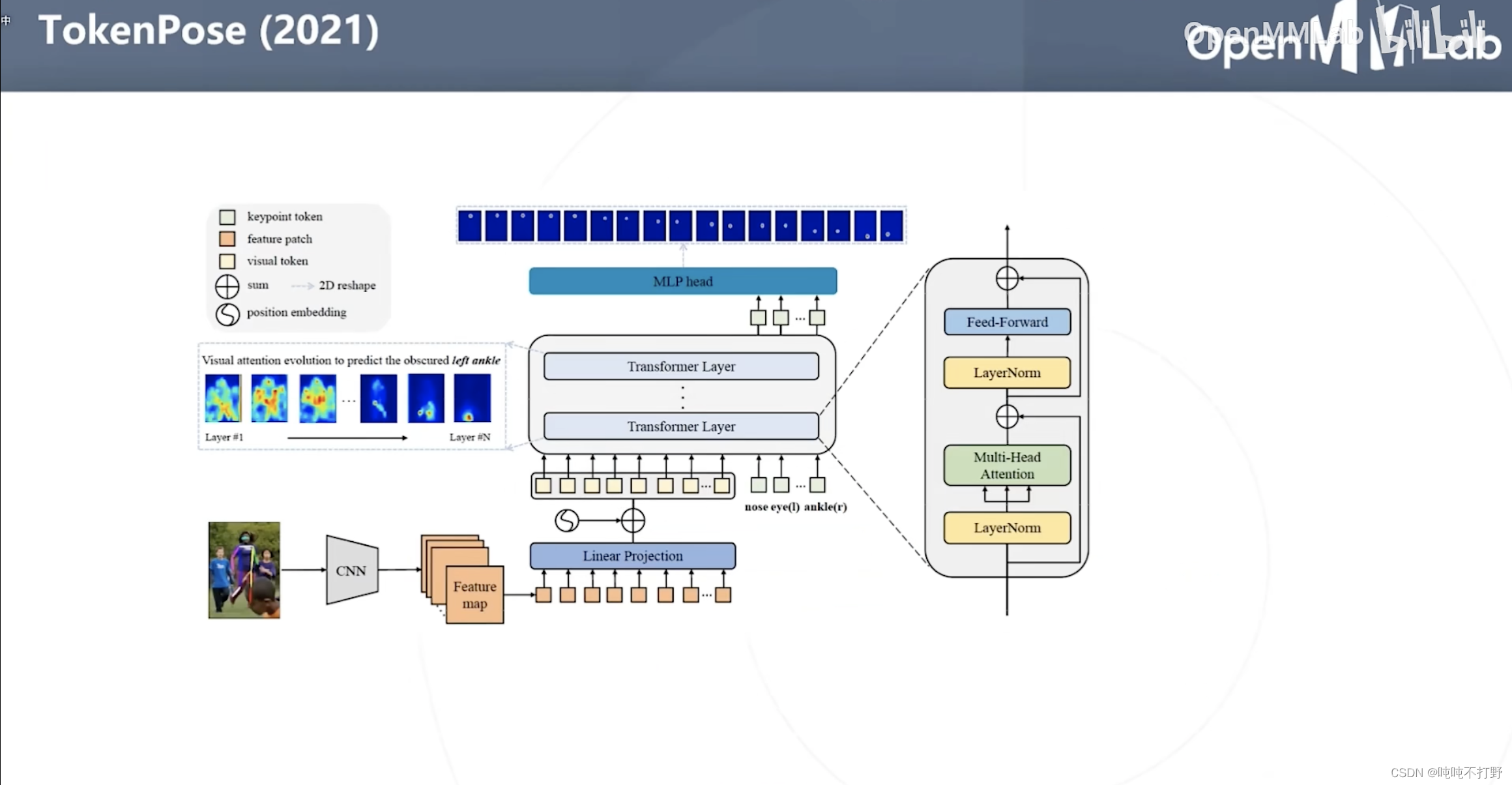
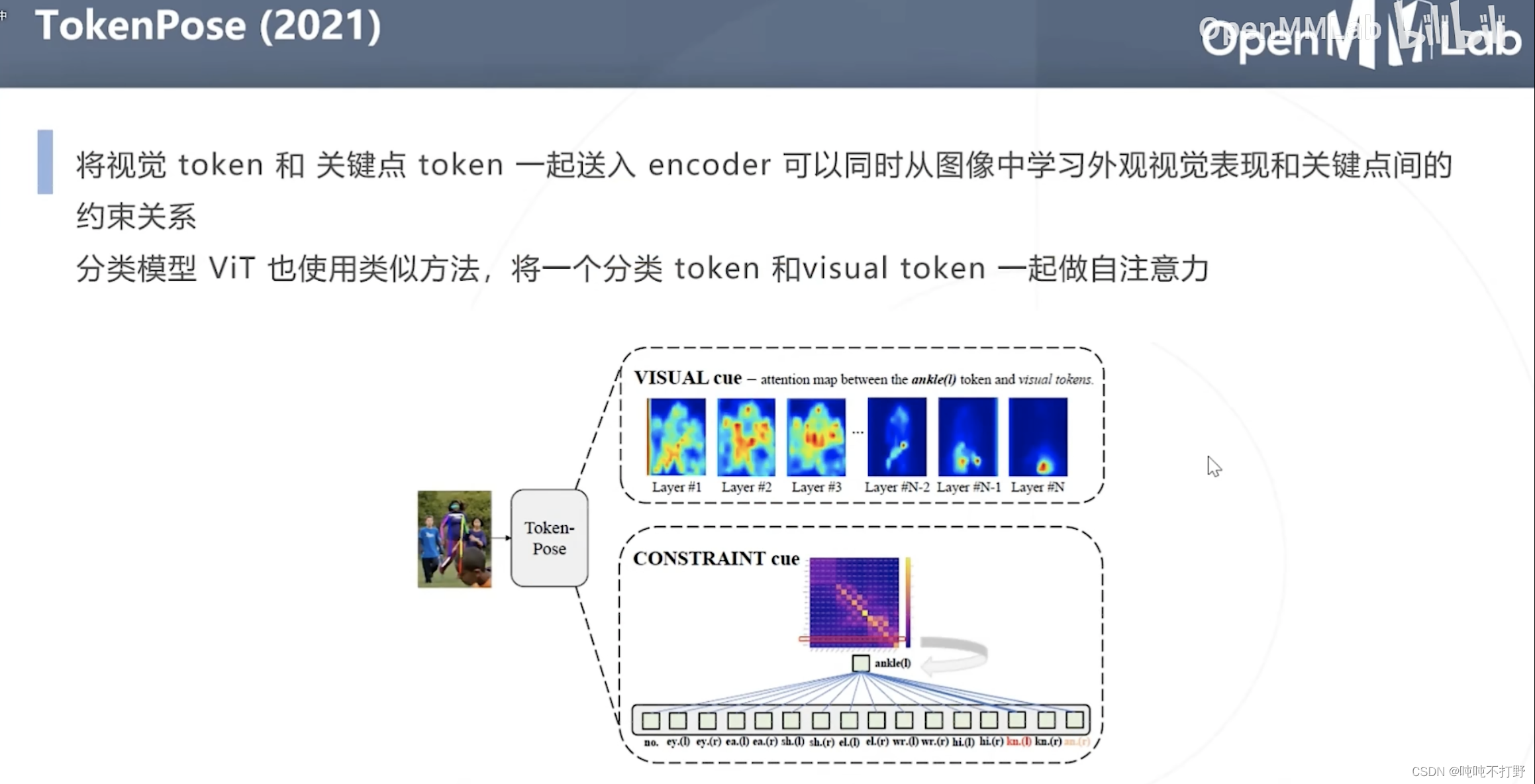
2.5.2 TokenPose(2021)(基于热力图的)
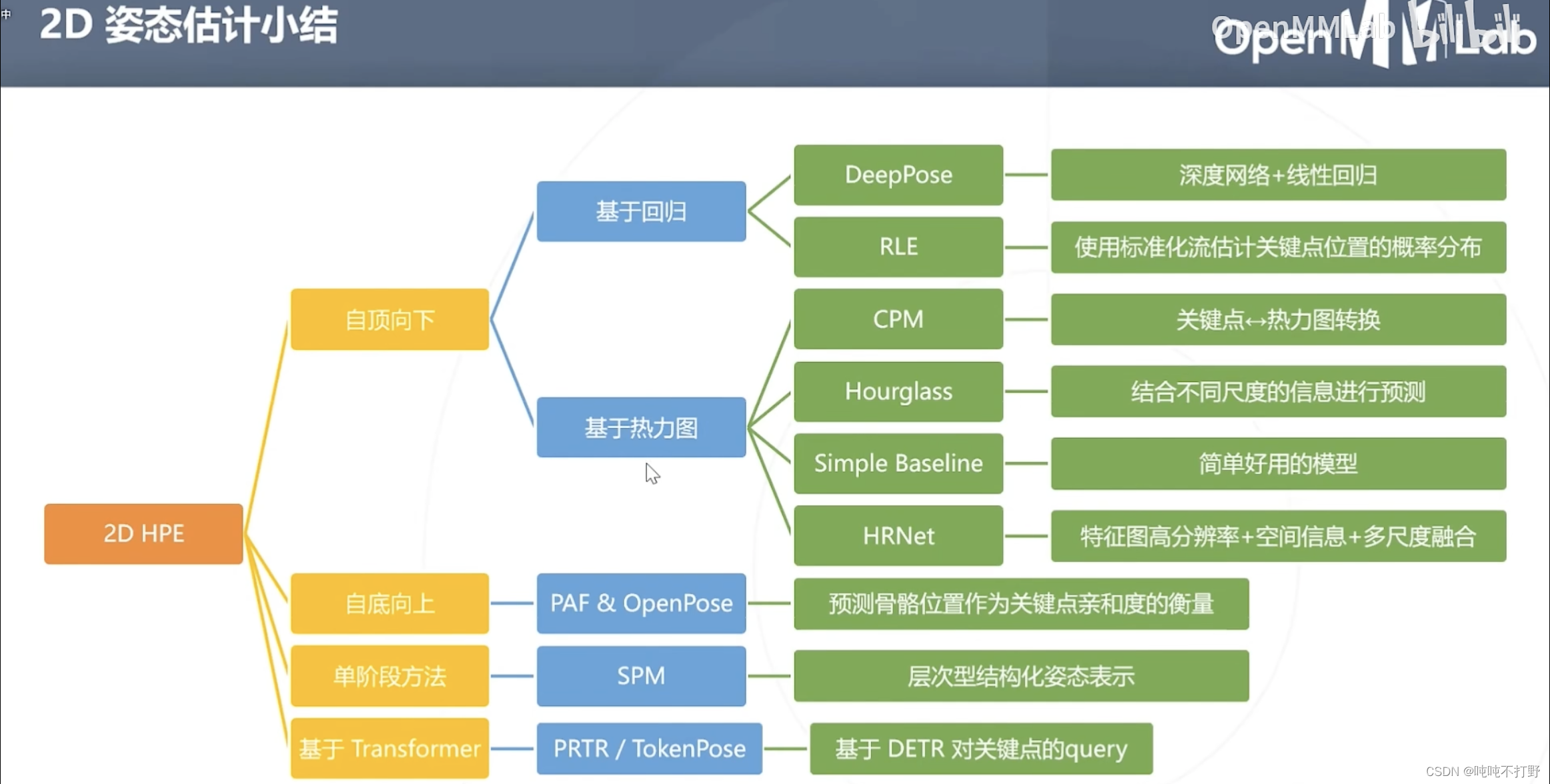
2.6 2D姿态估计小结
3. 3D姿态估计
3.1 任务描述

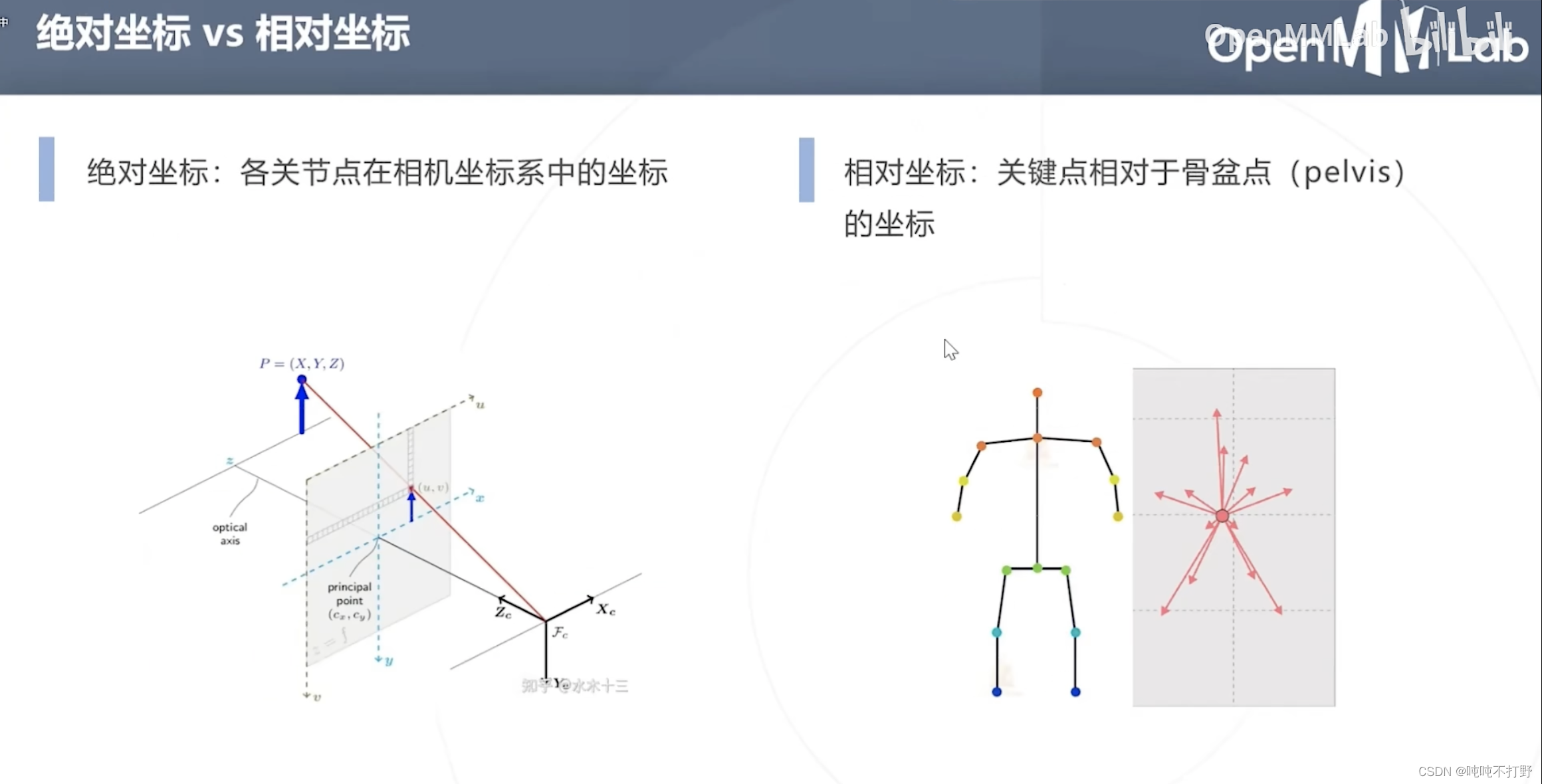
注意,
- 这里对3D的描述是相对的,给的如果是2D图,去生成3D本来也不太合适。。
- 并没有准确的深度信息

难点,如何从2D恢复3D信息
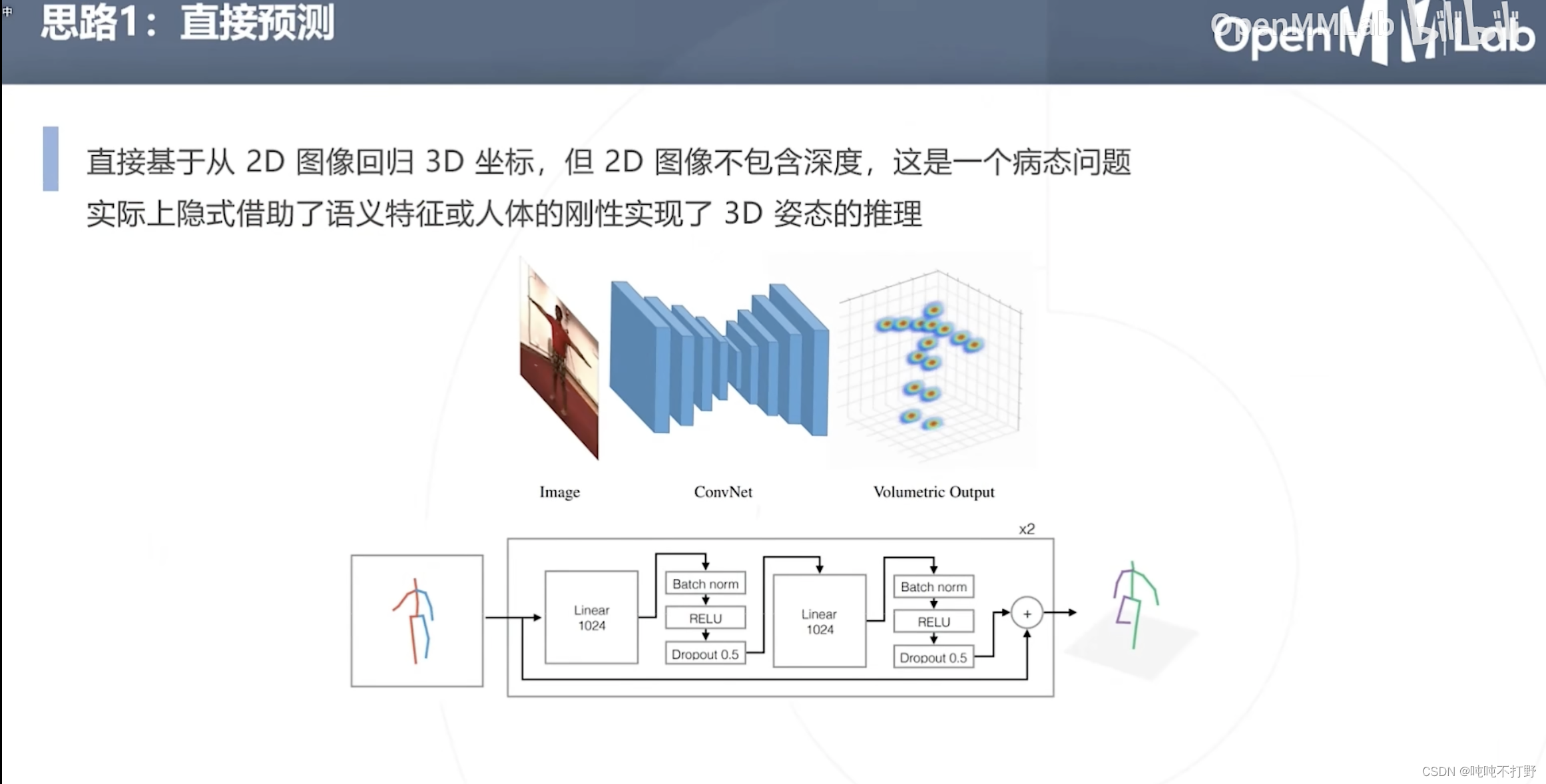
方式1:直接预测
- 直接从2D图像回归3D坐标,但是2D图像不包含深度,这是一个病态问题。
- 实际上可以借助语义特征(人体是有一个先验知识的),并且人体是刚性的来实现3D姿态的推理
- 对于一张2D图像,由于人体是先验且刚性的(可以理解为有个模板,同时这个模板不会发生太大的改变),人体的厚度/深度其实是一个可以推断的信息

方式2,利用视频信息
- 直接从2D推理到3D,可能会有病态的问题(生成的结果看起来不符合人体结构)
- 借助视频的帧间信息辅助判断,两帧视频之间,人体姿态并不会发生特别大的变化,
- 上面的原图(动态图)来自:https://dariopavllo.github.io/VideoPose3D/#demo

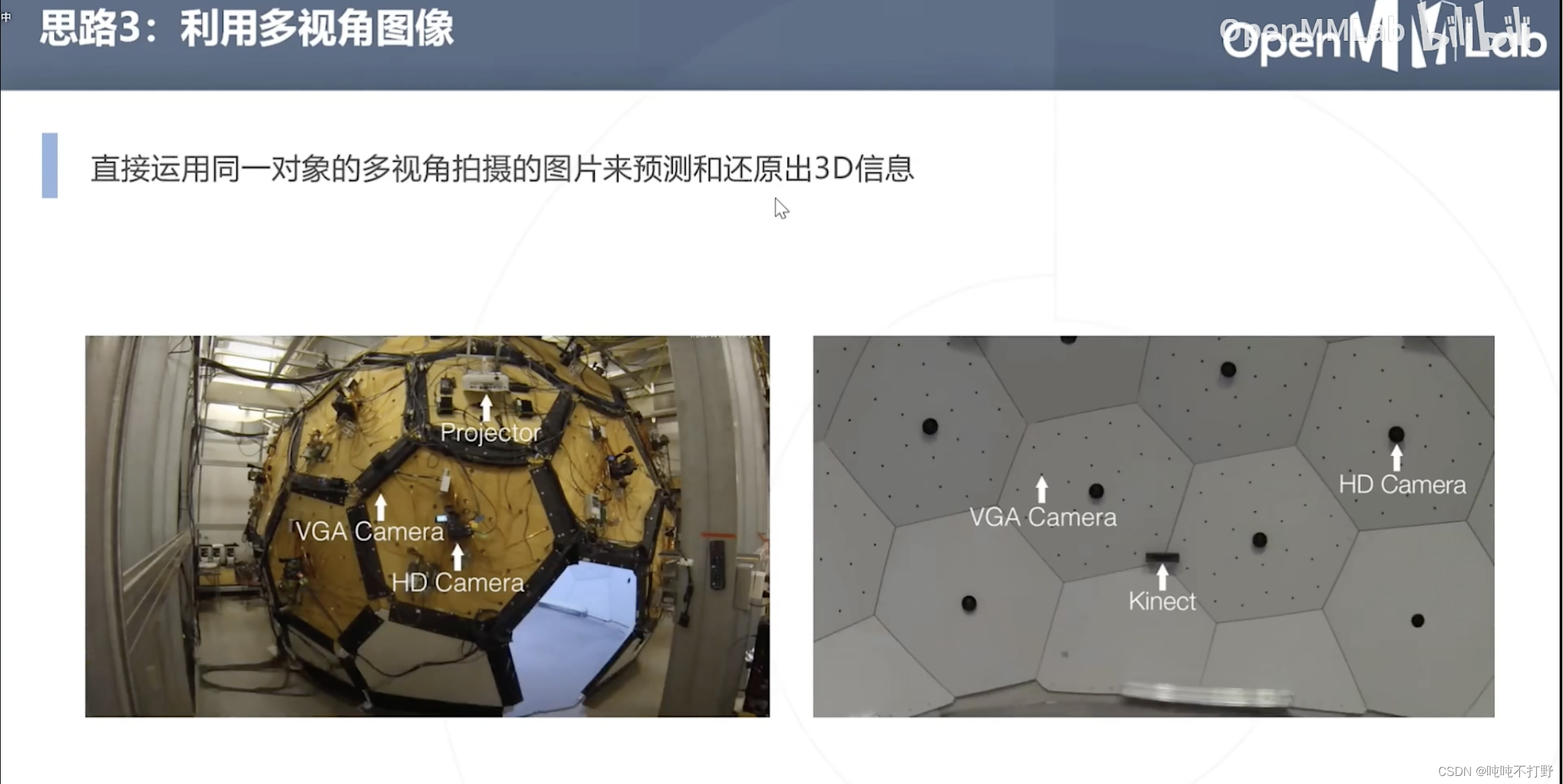
方式3:利用多视角图像
直接运用同一对象的多视角拍摄的图像来预测和还原出3D信息(2D图像生成3D模型)
3.2 方法介绍
3.2.1 Coarse-to-Fine Volumetric Prediction 2017
粗粒度到细粒度,体数据预测??
论文地址:Coarse-to-Fine Volumetric Prediction for Single-Image 3D Human Pose
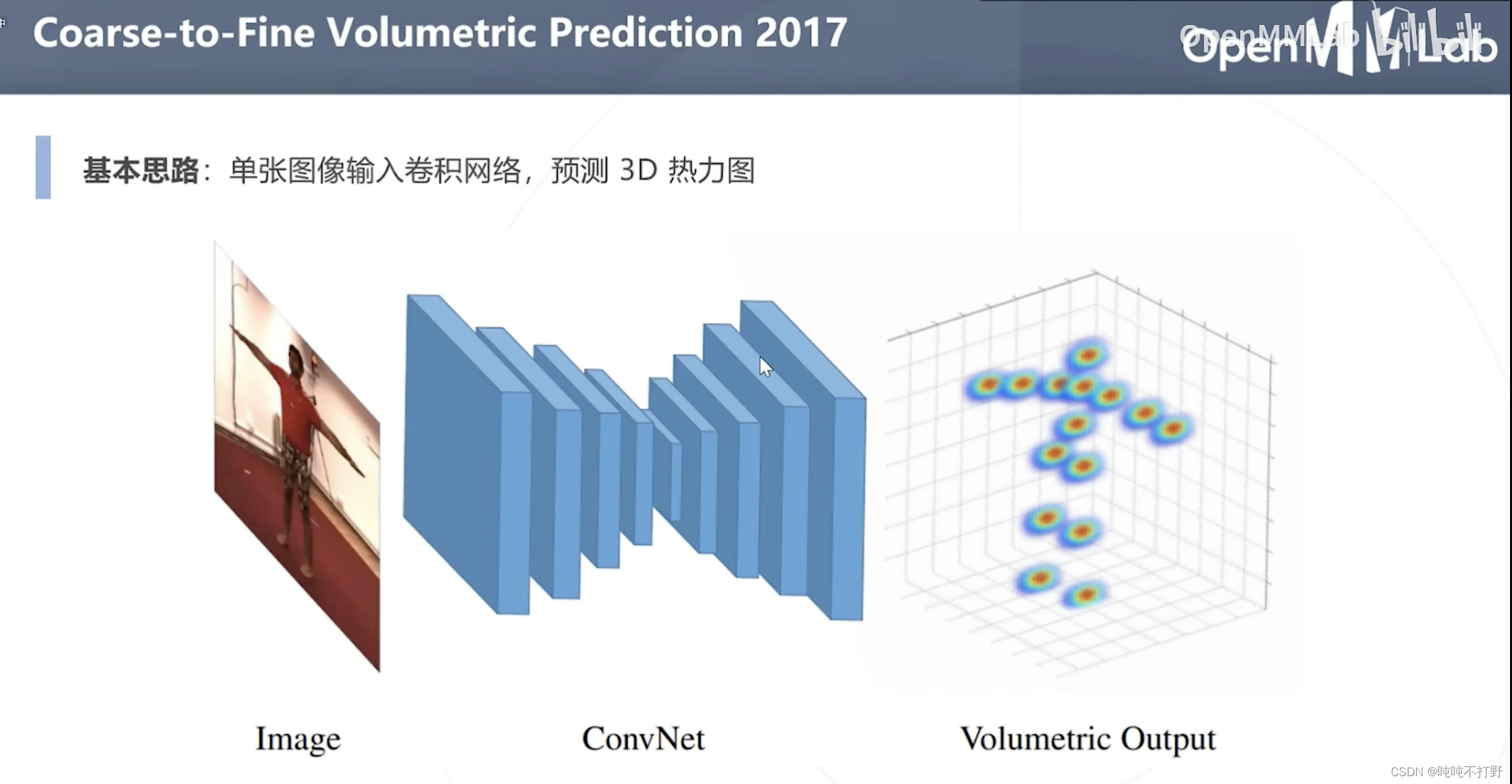
注意,这里输出的就是一个3D的热力图了(Volume 一般指体数据,3D数据)
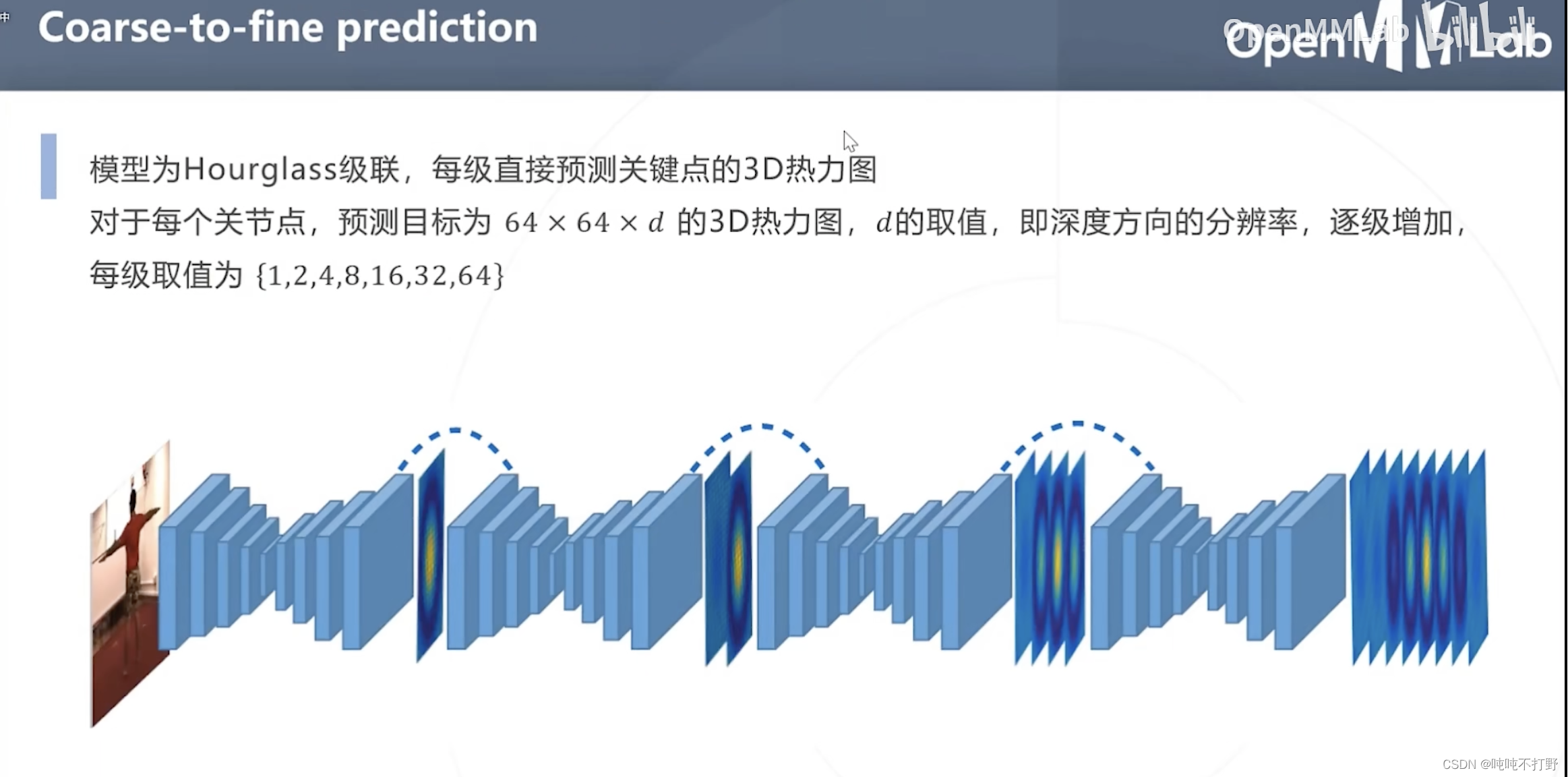
采用的是Hourglass级联,深度信息每次逐渐加深,8个Hourglass对应的输出的3D热力图的级联部分的深度大小依次为:{1,2,4,8,16,32,64},(
2
n
,
n
∈
[
0
,
6
]
2^n, n\in[0,6]
2n,n∈[0,6],7个输出),最后一个Hourglass没有级联了,就是自己最后的输出,也是64
3.2.2 Simple Baseline 3D(2017)
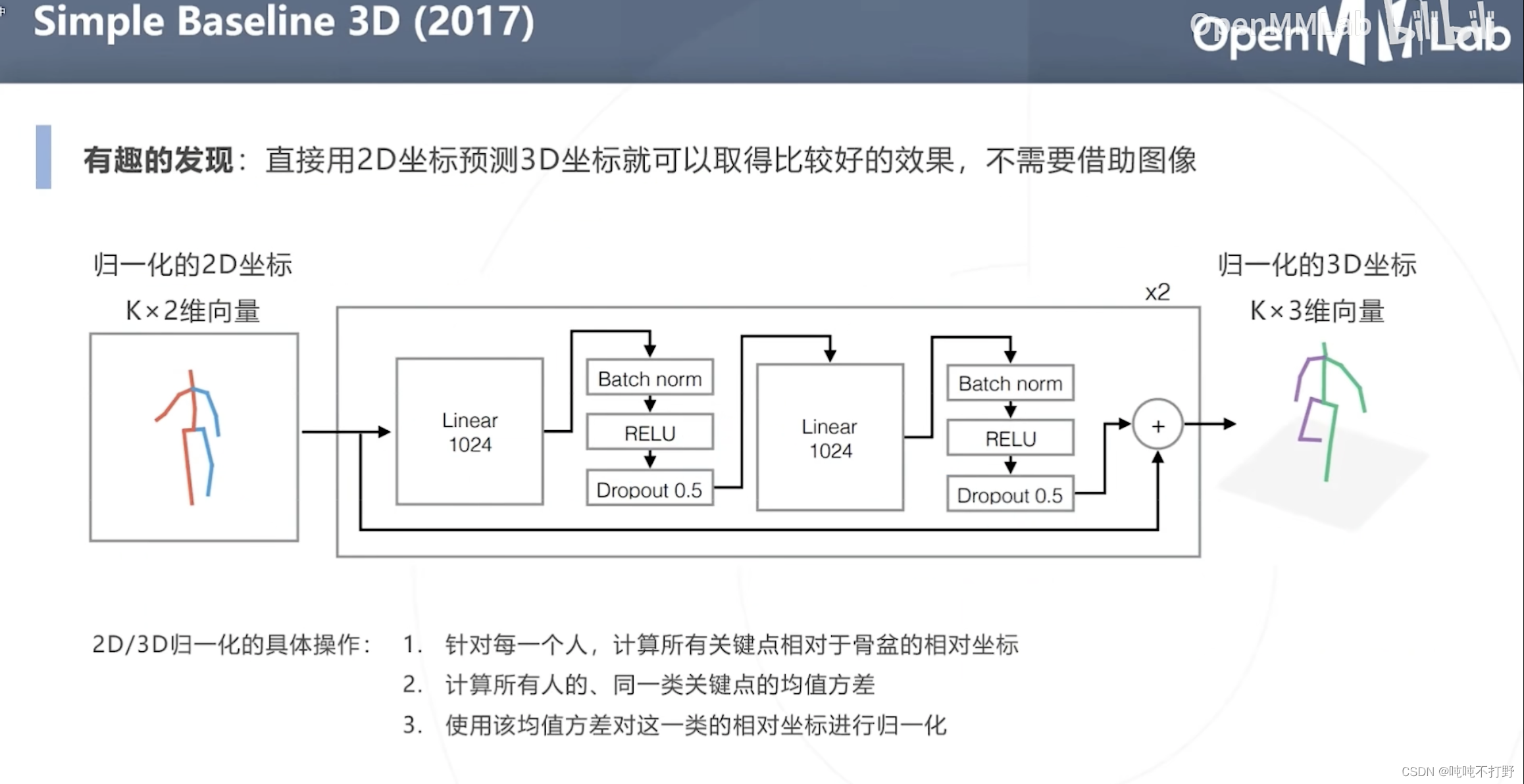
上面讲过一个Simple Baseline 2D,这里的Simple Baseline 3D的发现是:
直接用2D坐标预测3D坐标就可以取得比较好的效果,不需要借助图像
- 输入就是归一化的2D坐标,输出就是归一化的3D坐标,不需要使用图像信息。。用的网络也很简单,基本都是全连接层,用了一些防止过拟合的手段。。
- Amazing 本文内容由网友自发贡献,转载请注明出处:https://www.wpsshop.cn/blog/article/detail/59544
- ansible的常用模块配置说明及批量部署服务ansible的常用模块配置说明,在远程服务器批量配置清华大学的仓库文件,批量部署nginx,并启动服务。ansible的常用模块配置说明及批量部署服务ansible的常用模块配置说明及批量部署... [详细]
赞
踩
- 例题:与地址220.112.179.92匹配的路由表的表现是()。A220.112.145.32/22B220.112.145.64/22C220.112.147.64/22D220.112.177.64/22地址220.112.179.9... [详细]
赞
踩
- MACAddress(MediaAccessControlAddress)亦称为:硬件地址、物理地址(PhysicalAddress)。一个MAC地址唯一指定一台设备,全球唯一,并且通常烧写在固件中。结构MAC地址如图所示,其前3字节表示O... [详细]
赞
踩
- 品达通用权限系统1.项目概述1.1项目介绍对于企业中的项目绝大多数都需要进行用户权限管理、认证、鉴权、加密、解密、XSS防跨站攻击等。这些功能整体实现思路基本一致,但是大部分项目都需要实现一次,这无形中就形成了巨大的资源浪费。本项目就是针对... [详细]
赞
踩
- 问题描述更新wsl2后发现,机器的网络就有问题了。具体体现为启动后ifconfig内容是空的,但ipaddr却有网卡,通过ifconfigeth0up把显卡挂上也不行。解决方法问题出在从wsl1升级到wsl2,有一个参数被误配置了,就swa... [详细]
赞
踩
- 概述MAC地址学习虽然说起来比较简单,但是在工作中,还是经常看小伙伴不能正确的应用,遇到问题时也比较迷茫,不知道如何分析问题。究其原因,可能还是对MAC地址学习的工作原理了解的不够,所以我今天写一篇文章,给还迷糊的小伙伴在普及一下,如果是已... [详细]
赞
踩
- 读入一个数,输出翻转后的结果_数字反转c++语言程序数字反转c++语言程序读入一个数n,请输出把它翻过来以后的值。比如说,把12345翻过来以后是54321。输入格式第一行,一个整数n。输出格式输出一行,表示把n翻过来以后的值。样例输入12... [详细]
赞
踩
- 从桌面出现IE图标难以删除,经一翻折腾删除后,开机时浏览器无法启动,整个桌面全是黑屏,无奈!!!按DEL+ALT+CTRL调出“任务管理器”->点“文件”选项->“新建任务”->输入“explorer.exe”后桌面出现。再用“Window... [详细]
赞
踩
- 刚开始用parallelsdesktop确实会有些迷茫,因为如果已经有第一个虚拟机之后,再次点击paralleldesktop的图标就会直接启动第一个虚拟机,这时候怎么添加第二个虚拟机呢?找到parallelsdesktop,打开窗口,找到... [详细]
赞
踩
- 带你重回童年的经典系列——坦克大战3D版制作,感兴趣的可以看看呀~重回童年的经典系列☀️|【坦克大战3D版】游戏制作+解析... [详细]
赞
踩
- 而今天小编为大家还是带来了同系列软件,这是easyrecovery数据恢复软件中的技术员版本,不仅包含家庭版和专业版的所有功能,而且还旨在简化技术人员的数据恢复过程。软件拥有强大的数据恢复功能,支持使用的恢复场景有:删除恢复(意外删除、数据... [详细]
赞
踩
- 1、爬虫心得1、我们在写爬虫程序的时候可以采用面向对象的方式进行代码构造,使得代码结构更加清晰2、放我们发现某个网站的PC端网页比较难爬的时候,我们可以查看其手机端是否好爬3、本爬虫程序解析的文件为json数据文件2、爬虫页面展示原始jso... [详细]
赞
踩
- 1、在Mac上安装FridaMac系统的frida版本要与Android中的版本号保持一致。升级Mac系统中的frida为最新版本的命令:sudopipinstall--upgradefrida或者安装指定版本的frida,这里安装frid... [详细]
赞
踩
- 以给基准值x,将链表分割成2部分,所有小于x的结点排在大于或等于x的结点之前。请返回重新排列后的链表的头指针。注意:分割以后保持原来的数据顺序不变。【链表】-Lc86-基于基准值拆分链表(bigHead,bigTail,smallHead,... [详细]
赞
踩
- 前言什么是MAC地址表?MAC地址表有什么作用?MAC地址表里面包含了哪些要素?今天带你好好唠唠。我们以一个案例为例:如上图:PC1和PC2通过交换机SW1直连,此时PC1想要和PC2通信。1、根据TCP/IP参考模型,PC1想要和PC2通... [详细]
赞
踩
- 线段树、离散化技巧、懒更新算法41:掉落的方块(力扣699题)----线段树题目:https://leetcode.cn/problems/falling-squares/description/在二维平面上的x轴上,放置着一些方块。给你一... [详细]
赞
踩
- 2021,疫情本要缓解又变异的上半年,在五一快要到来之时,我已经苦逼了一月的996。前两天vue+iview的后台管理系统要改造成动态菜单,后台接口返回菜单,处理并生成路由。于是乎开始搞起来,(心态:第一次自己搞这个需求还是很崩溃的)~当当... [详细]
赞
踩
- 这里写目录标题项目搭建pd-tools-swagger2pd-tools-dozerpd-tools-validatorpd-tools-xsspd-tools-logpd-tools-jwtpd-tools-userpd-tools-co... [详细]
赞
踩
- 【例题2】微分方程解析解。【例题3】求解方程组。微分方程应用(MATLAB)【例题1】matlab求解微分方程的解析解closeallclearclct_final=100;x0=[0;0;1e-10];f=@(t,x)[-8/3*x(1)... [详细]
赞
踩
- 在TCP/IP协议中,我们以目的端口,目的IP源端口源IP协议号这样一个五元组来表示一段通信可以在cmd命令行窗口中使用netstat-n来查看计算机上正在通信的TCP协议应用程序。UDP/TCP协议特点1.前置知识定义应用层协议1.确定客... [详细]
赞
踩
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

